Claude Fable 5 首发实测:强到离谱但贵到心痛,对比GPT-5.5和Opus 4.8
·
摘要:本文基于真实全栈项目与长程复杂任务(重构Claude Code泄露源码)的零人工干预测试,对比Fable 5、Opus 4.8和GPT-5.5在UI审美、编码能力、验证深度、交付质量以及成本消耗上的表现。最终给出按需选择的模型建议。
目录
1. 模型定位与定价
| 模型 | 安全护栏 | 定价(每百万token) | 备注 |
|---|---|---|---|
| Fable 5 | 松(有安全分类器) | 输入$10 / 输出$50 | 面向公众,能力与Opus 4.8相同 |
| Opus 4.8 | 较紧 | 输入$5 / 输出$25 | 同等底层,安全限制更严 |
| Mythos 5 | 无护栏 | 更高(未公开) | 仅限特定机构,普通人接触不到 |
| GPT-5.5 | 中等 | 约Fable 5的1/8 | 用于对比参考 |
| DeepSeek V4 | 中等 | 约Fable 5的1/50 | 性价比极高 |
Fable 5是当前主流模型中最贵的,官方称已比之前的Mythos版本便宜一半多。
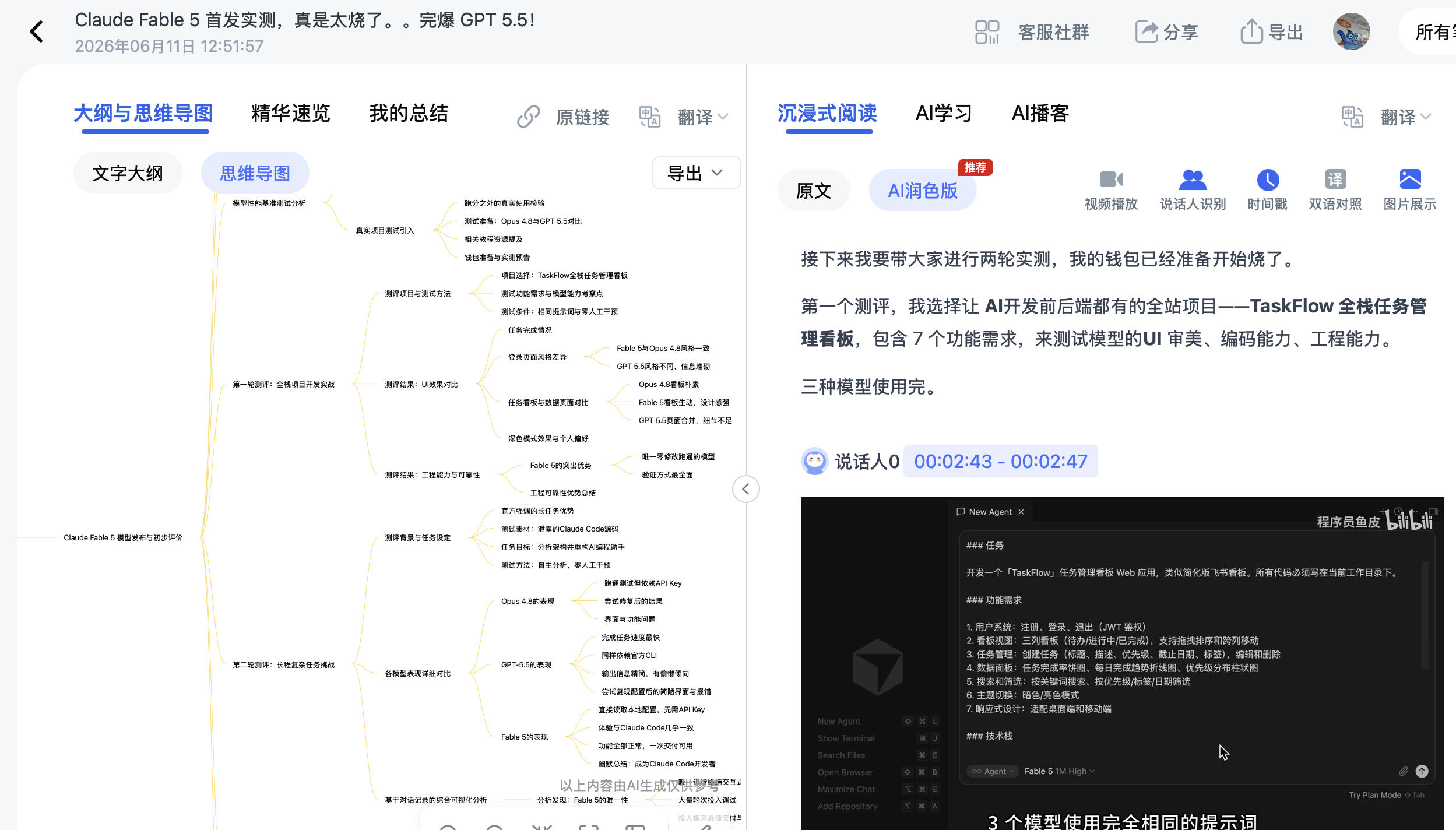
2. 第一轮:全栈项目开发实测
测试项目:TaskFlow全栈任务管理看板(前后端,7个功能需求)
条件:相同提示词、高思考强度档位、零人工干预
2.1 UI效果对比
| 模型 | 登录页风格 | 看板/数据页 | 深色模式 |
|---|---|---|---|
| Fable 5 | 经典居中卡片,色调动感 | 状态区分清晰,圆弧点缀,图表协调 | 整体效果最佳 |
| Opus 4.8 | 与Fable 5一致 | 排版整齐但朴素,背景色少 | — |
| GPT-5.5 | 左侧大面积文案,信息堆砌 | 看板与数据合并,任务列标题用英文 | 细节粗糙 |
2.2 工程可靠性与验证
| 模型 | TypeScript编译 | 后端启动 | API测试 | 实测验证 | 开箱即用 |
|---|---|---|---|---|---|
| Fable 5 | 一次通过 | 一次成功 | 全部通过 | 拖拽持久化实测 | ✅ 唯一零修改 |
| Opus 4.8 | 需小修 | 需调整 | 部分通过 | 未做 | ❌ |
| GPT-5.5 | 通过 | 通过 | 通过 | 未做 | ❌ |
Fable 5是唯一真正做到零修改、开箱即用的模型,验证方式最全面。
3. 第二轮:长程复杂任务挑战
任务:分析泄露的Claude Code源码(50万行工业级AI架构),从零重构一个终端可运行的命令行AI编程助手“YupiCode”
条件:自主分析、零人工干预、禁止手动修复
3.1 各模型表现
| 模型 | 依赖与配置 | 运行体验 | 功能完整性 | 最终交付 |
|---|---|---|---|---|
| Fable 5 | 直接复用本地Claude配置,无需API Key | 与原版Claude Code几乎一致(对话/Agent/工具调用) | 全部正常 | 一次交付可用 |
| Opus 4.8 | 需Anthropic API Key,模拟server跑通流程 | 界面与原版有差异,输出内容无法正确显示 | 部分功能缺失 | 不可用 |
| GPT-5.5 | 同样需官方CLI,依赖外部Key | 界面简陋,读取本地文件报错 | read工具报错 |
不可用 |
3.2 验证深度分析
- Fable 5:唯一进行了终端交互式测试,大量轮次投入命令调试和UI上下文压缩。
- Opus 4.8:验证层次丰富,但受限于API Key。
- GPT-5.5:验证最浅,输出信息精简,有偷懒倾向😂。
4. 成本消耗与综合对比分析
4.1 实际成本
| 模型 | 费用倍率 | 绝对成本(约) |
|---|---|---|
| Fable 5 | 1× | 200+元 |
| Opus 4.8 | 0.33× | 约70元 |
| GPT-5.5 | 0.125× | 约25元 |
Fable 5贵在思考消耗巨大,且大量轮次花在UI交互调试上,但这是其唯一能交付可用产品的原因。
4.2 功能覆盖矩阵与综合评分
| 能力 | Fable 5 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| UI上下文压缩 | ✅ | ❌ | ❌ |
| 自动复用本地配置 | ✅ | ❌ | ❌ |
| 终端交互测试 | ✅ | 部分 | ❌ |
read工具正常 |
✅ | ✅ | ❌(报错) |
| 零人工干预交付 | ✅ | ❌ | ❌ |
综合评分(交付角度):Fable 5 > Opus 4.8 > GPT-5.5
从“拿到直接能用的成果”来看,Fable 5实至名归。
5. 模型选择建议
| 需求场景 | 推荐模型 | 理由 |
|---|---|---|
| 追求速度和低成本,快速原型验证 | GPT-5.5 | 速度最快,成本最低 |
| 兼顾代码质量与成本,中等复杂度项目 | Opus 4.8 | 平衡之选,质量尚可 |
| 复杂长任务,要求极致交付质量,省心省力 | Fable 5 | 唯一能做到零修改可用,但成本高昂 |
| 预算有限、日常辅助编码 | DeepSeek V4 | 性价比极高 |
💡:不要盲目追星,按真实需求选择!最贵的未必最适合你。
6. 参考资源
- 本文基于B站@程序员鱼皮《Claude Fable 5 首发实测…》视频归纳整理,由Ai好记提取关键对比数据和结论。如果你也关注AI、想要了解AI知识,想通过长视频、音频进行学习,可以用 Ai好记将视频转为图文笔记+思维导图,亲测用起来顺手,笔记生成很清晰!
如有问题欢迎评论区交流。如果本文对你有帮助,点赞、收藏、转发支持~

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)