给AI Agent一副身体:我用魔珐星云搭建具身智能数字人
当所有Agent都在卷"脑子",我开始思考——如果AI有一副身体,交互会变成什么样?
魔珐星云具身智能数字人开放平台:魔珐星云-具身智能数字人开放平台
这里写目录标题
当Agent拥有了"身体"
2025年到2026年的AI技术圈,一个词被反复提起——Agent。从Manus通用Agent引爆全网,到MCP协议让AI连接万物,再到各大厂商争相推出Agent框架,我们似乎达成了一个共识:AI的未来不只是问答,而是自主感知、决策、执行。
但一个问题始终困扰着我:几乎所有Agent都还困在"文字交互"的模式里。你打字,它回文字,偶尔丢你一张图。这种交互体验放在2024年还算新鲜,放到2026年就显得单薄了。
为什么?因为人类沟通的本质是多模态的。我们说话时会看对方的表情、肢体动作、眼神——这些非语言信息占了沟通总量的60%以上。纯文字Agent就像一个永远戴着面具的电话客服,你感受不到它的"在场感"。
所以当我第一次接触到魔珐星云这个平台时,我意识到这可能是一个有意思的解法——给AI Agent一副3D的"身体",让它不仅能思考,还能像真人一样自然地表达和交互。经过几个月的开发实践,我把踩过的坑、摸索出的技术方案和真实体验记录在这篇文章里,希望能给同样在做Agent交互探索的开发者一些参考。
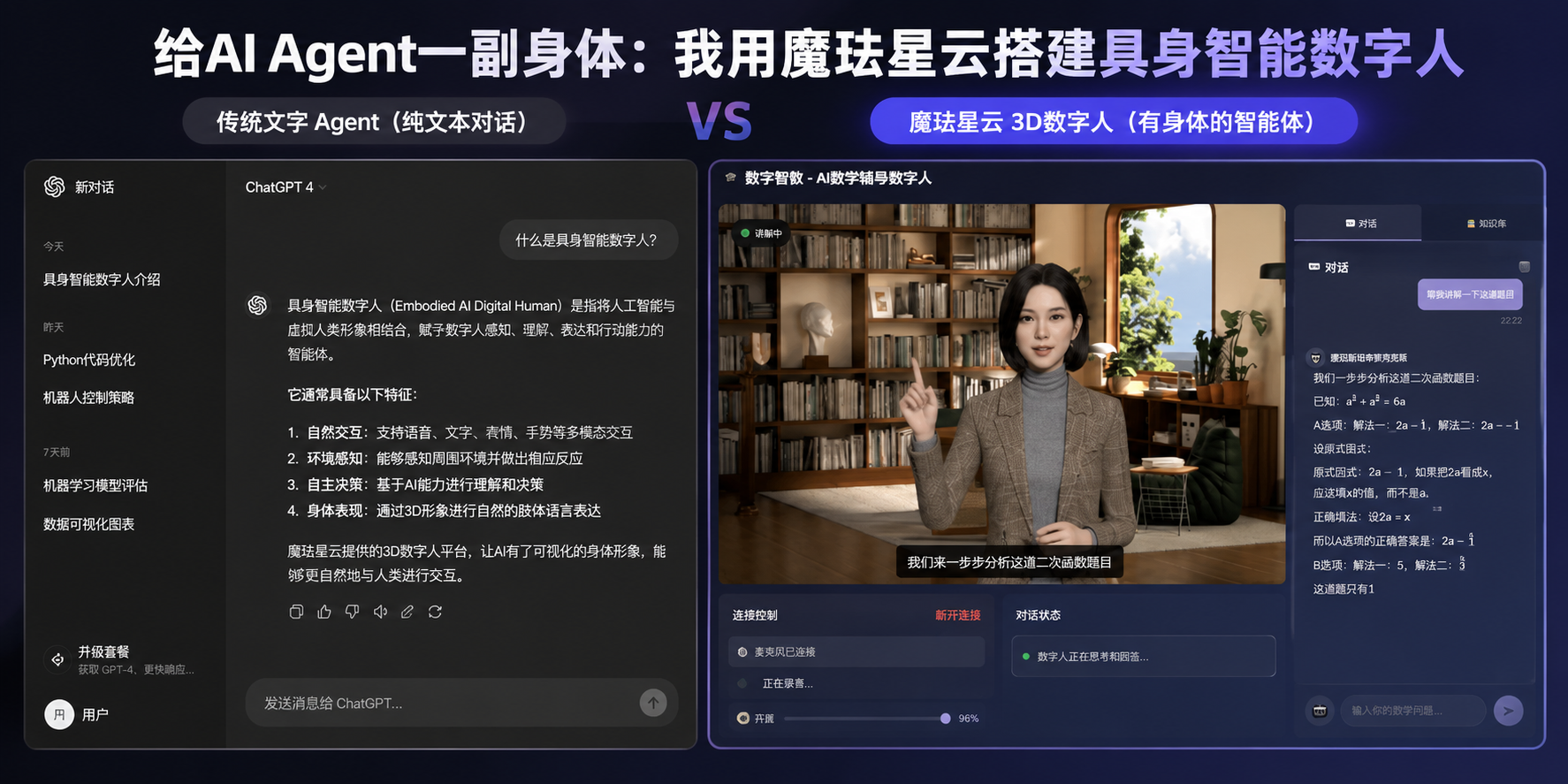
一、现有数字人方案的困境:为什么"能看"却"不能用"?
在深入技术细节之前,我们先看看当前数字人行业到底卡在哪了。
1.1 云端渲染的天花板:视频流的根本性缺陷
市面上绝大多数数字人产品,底层架构都是云端渲染+视频流推送。流程大概是:
用户输入 → 云端TTS生成语音 → 云端渲染3D动画 → 编码为视频流 → 推送到客户端
这条链路看起来很合理,但实际体验有几个致命问题:
延迟不可控。 视频编码、网络传输、客户端解码,每个环节都在叠加延迟。实际测试中,从用户说完话到数字人做出反应,往往需要2-5秒。对话中2秒以上的空白,用户体验直接崩塌——想象一下你跟朋友聊天,对方每次回应都要对着你发呆3秒。
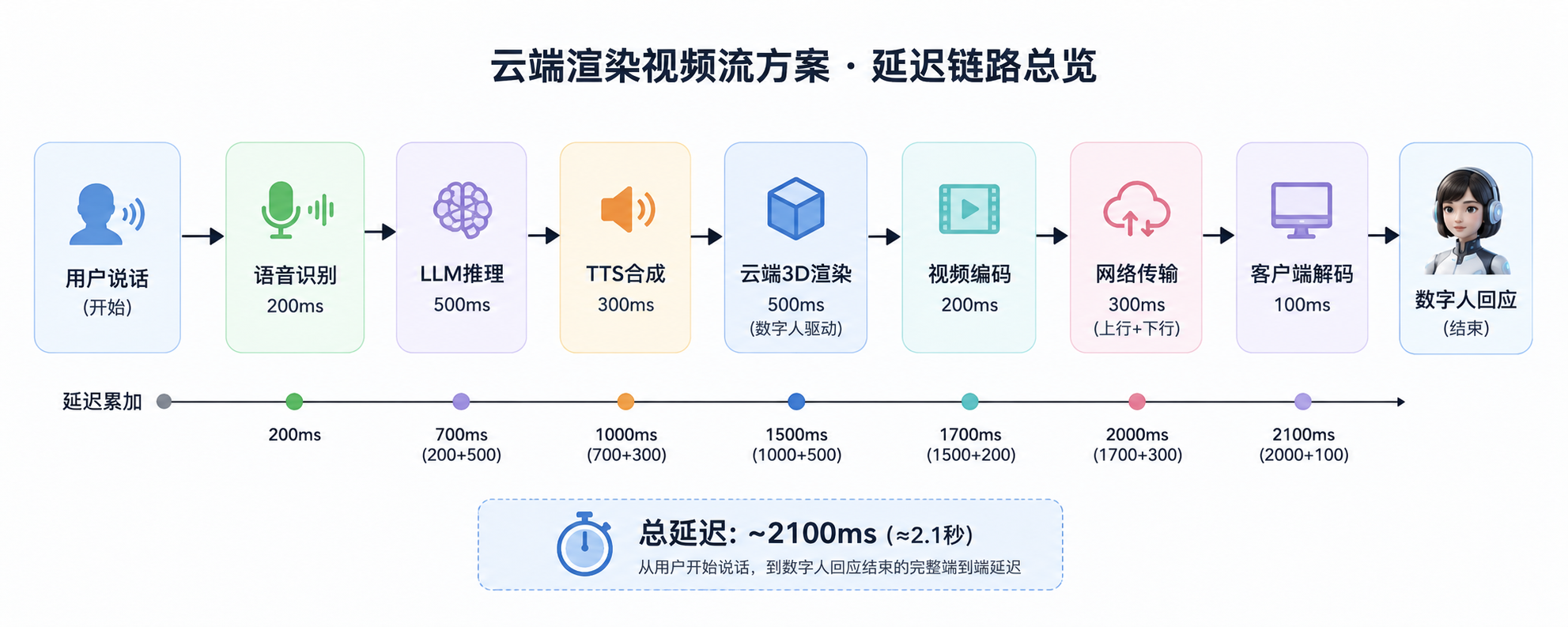
带宽成本高。 720p视频流每秒需要2-4Mbps带宽,一个并发用户就意味着持续的带宽消耗。当用户量上来的时候,服务器带宽费用直接爆炸。这也解释了为什么很多数字人产品要么按分钟收费(贵),要么限并发(体验差)。
表情动作僵硬。 云端渲染受限于计算资源,往往只能做简单的口型同步,肢体动作、微表情这类高精度动画要么直接砍掉,要么做成预设动画轮播。用户一眼就能看出是"假的"。
1.2 用户真实感受:从"新奇"到"出戏"
我之前在一个企业展厅项目中用过某款云端数字人产品。客户反馈很直接:“刚看觉得挺酷,对话两轮就出戏了。”
原因很简单——数字人受云端视频流架构限制,数字人存在响应延迟高、动作表情无法跟随语义动态变化等问题。用户在等数字人回应的3秒空白里,注意力已经跑了。这不是UI优化能解决的问题,是底层架构的天花板。
二、单点技术的局限:LLM/TTS/渲染各自的短板
很多团队的做法是"拼积木"——找个LLM做大脑、接个TTS做嗓子、再搞个3D渲染引擎做身体,用API把它们串起来。听起来很美好,但实际操作中会遇到什么?
2.1 LLM:能思考,但不能"表达"
大语言模型的输出是纯文本。它理解你的问题,生成精妙的回答,但这些回答只是一串字符串。用户看到的是文字,感受不到语气、表情、态度。
更关键的是,LLM的流式输出(Streaming)和数字人的实时驱动之间存在节奏不匹配。LLM一个token一个token地往外蹦,而数字人需要的是一个完整的句子才能驱动口型和表情。如果你等LLM把完整句子生成完再送给数字人,用户又要等;如果你边生成边送,又要处理句子切分、情感标注等一堆问题。
2.2 TTS:有声无形的语音合成
现代TTS技术已经能做到非常自然的语音合成,但它只有声音。没有表情、没有手势、没有眼神——就像听播客,你能获取信息,但感受不到"对话"。
而且TTS有一个容易被忽视的问题:延迟和质量的取舍。高质量的多发言人TTS通常需要更大的模型和更多计算量,这意味着更高的延迟。要做到实时对话级别的响应速度,往往需要在音质上做妥协。
2.3 3D渲染:会动但不"智能"的动画引擎
3D渲染引擎(如Unity、Unreal)能做出极其逼真的数字人,但它们本质上是被动的——你给它什么动画数据,它就播什么动画。它不理解对话的上下文,不知道什么时候该微笑、什么时候该皱眉、什么时候该用手势强调某个概念。
把动画做成预设(Idle状态微笑、说话时挥手)是一种方案,但用户很快就会发现这些动作跟对话内容毫无关系,像是一个背台词的木偶。
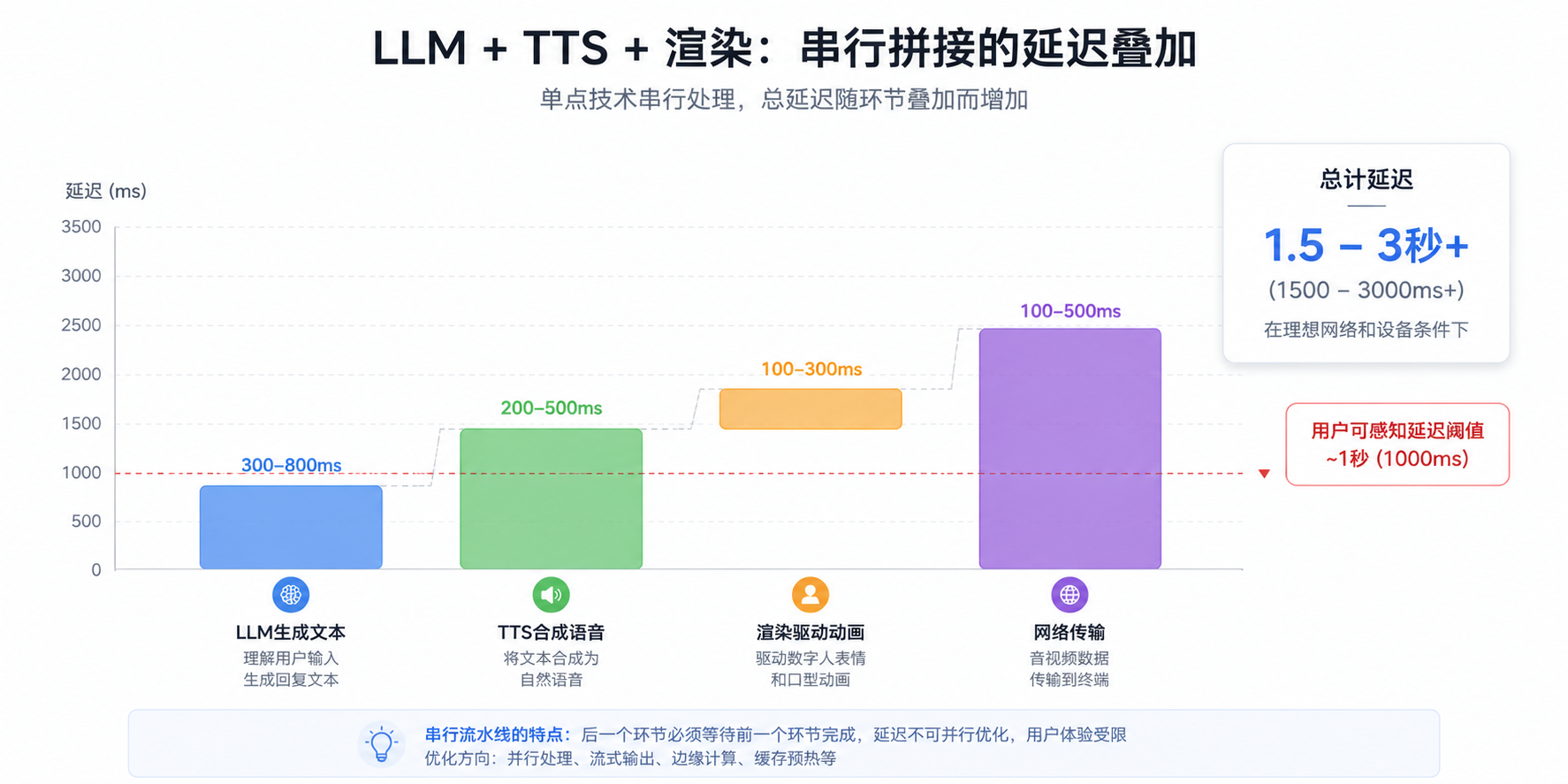
2.4 拼接困局:1+1+1 < 1
最致命的问题是延迟叠加。当你把LLM、TTS、渲染三个环节串行拼接时:
LLM生成文本(300-800ms) → TTS合成语音(200-500ms) → 渲染驱动动画(100-300ms) → 网络传输(100-500ms)
总延迟轻松超过1.5秒,甚至到3-5秒。每个环节单独看都很优秀,串起来体验就崩了。这不是某个单点技术的问题,而是架构层面的问题。
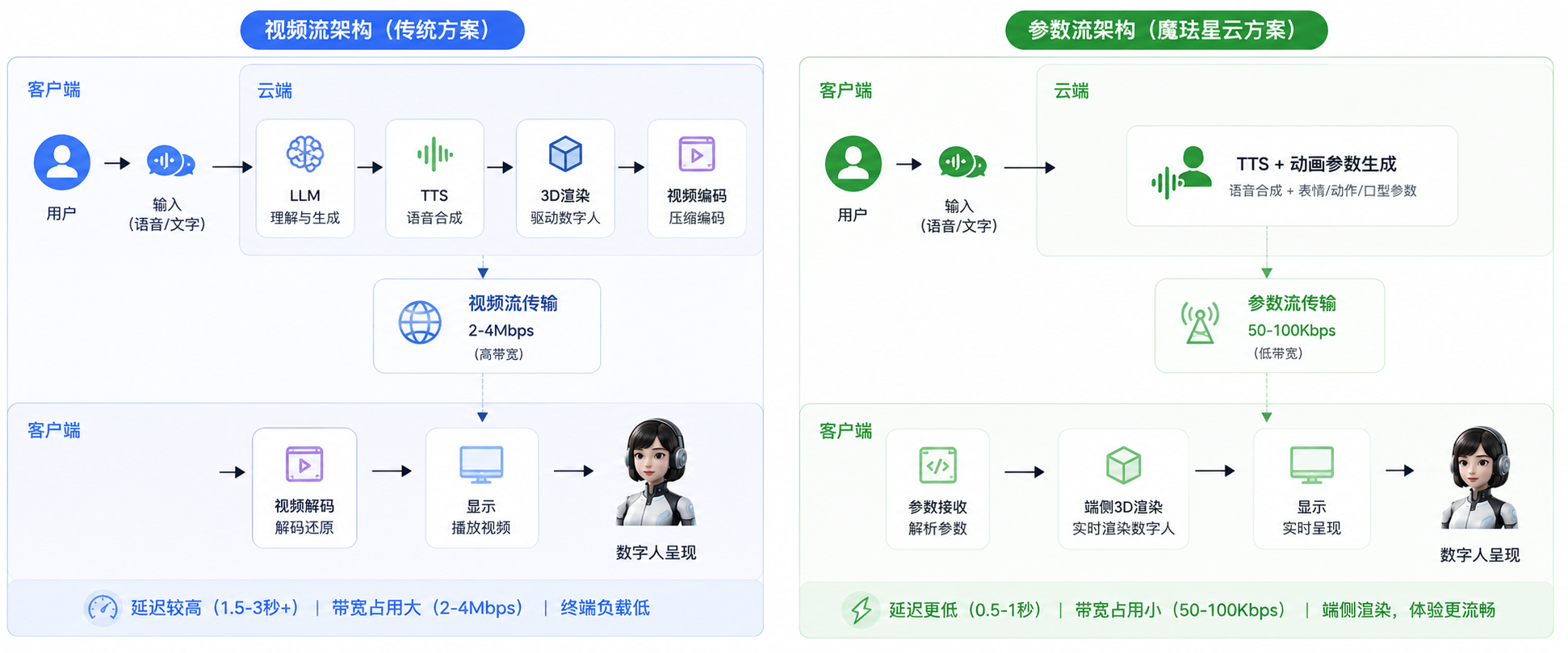
三、魔珐星云的端到端方案:参数流架构的范式转换
魔珐星云的技术路线跟上面说的完全不同。它没有走"云端渲染+视频流推送"的传统路线,而是选择了**参数流+**AI端渲和端侧解算技术。这个选择从根本上改变了延迟和成本的结构。
3.1 参数流 vs 视频流:一次关键的技术分岔
先解释两个概念:
视频流方案:云端把3D场景渲染成视频画面,编码后推送给客户端。客户端仅负责接收并呈现完整视频画面,交互能力受限。
参数流方案:云端只发送参数数据(音频数据、面部BlendShape参数、骨骼动画参数),客户端用本地GPU实时渲染3D数字人。
打个比方:视频流像是"远程桌面"——你在本地看到的是远端电脑的屏幕画面;参数流像是"游戏联机"——你的本地电脑运行完整的3D场景,服务器只同步必要的参数数据。
这个区别带来了几个本质优势:
| 维度 | 视频流 | 参数流(星云方案) |
|---|---|---|
| 带宽消耗 | 2-4 Mbps/路 | 约 50-100 Kbps/路 |
| 延迟结构 | 编码+传输+解码(高) | 传输+本地渲染(低) |
| 画质 | 受编码压缩影响 | 本地渲染,无损画质 |
| 并发成本 | 与用户数线性增长 | 端侧渲染,服务端成本低 |
| 硬件要求 | 低(只需解码视频) | 中(需GPU/WebGL) |
3.2 三层核心架构:从感知到表达的全栈打通
魔珐星云端到端方案的核心是打通了三层架构:
第一层:多模态感知层 用户可以通过文字、语音、甚至图片与数字人交互。这一层负责把用户的输入转化为结构化的语义信息。
第二层:大模型+智能体认知层 接入大语言模型进行推理决策。这里可以对接Qwen、DeepSeek等国产大模型,也可以对接GPT系列。星云提供的是驱动能力,认知层可以选择自己喜欢的大脑。
第三层:多模态具身表达层 这是星云的核心——把LLM的文本输出实时转化为语音(TTS)、面部表情(BlendShape)、身体动画(骨骼动画),并通过端侧渲染呈现给用户。
三层之间的衔接是端到端优化的,而不是简单拼接。这意味着从用户输入到数字人回应的整个链路是联合优化的,延迟可以控制在≤500ms。
3.3 关键技术指标
在实际开发中,我关注的核心指标:
- 端到端响应延迟 ≤ 500ms:从用户输入完成到数字人开始回应。这个数据我在开发中实测,在正常网络条件下确实能稳定在这个水平。相比传统方案动辄2-3秒的延迟,这个提升是体感级别的。
- 端侧渲染+参数流:服务端不再承担渲染压力,并发成本大幅降低。带宽消耗从Mbps级降到Kbps级。
- 低成本硬件兼容:RK3588芯片跑1080p,RK3566跑720p。百元级芯片就能部署,这意味着从手机、平板到智能屏、车载屏幕,几乎所有带屏幕的设备都能跑。
- 全兼容:PC(Mac/Win)、手机(Android/iOS)、平板(iPad),一个SDK全平台适配。
四、实战:搭建一个具身AI数学老师
说了这么多架构层面的东西,不如上手实操。下面我分享一个真实场景——用魔珐星云SDK搭建一个AI具身智能数学辅导老师。
4.1 场景设计
场景很简单:一个中学生在家做数学作业,遇到不会的题,打开网页就能跟一个3D AI老师面对面交流。老师能看到你上传的题目图片,能用语音和表情给你讲解,还会用手势强调重点。
这个场景的关键需求:
- 实时交互:学生提问后,老师要能快速回应,不能让中学生等得失去耐心
- 多模态输入:支持文字提问,也支持拍照上传题目
- 自然表达:老师说话时有口型同步、表情变化、手势配合
- 流式输出:LLM一边生成,数字人一边"说",不需要等完整回答
4.2 架构设计
┌─────────────────────────────────────────┐
│ 前端页面 │
│ ┌──────────┐ ┌───────────┐ │
│ │ 3D数字人 │ │ 对话面板 │ │
│ │ (星云SDK) │ │ (聊天UI) │ │
│ └──────────┘ └───────────┘ │
└──────────┬───────────────┬──────────────┘
│ │
WebSocket HTTP API
│ │
┌──────────▼──────┐ ┌────▼──────────────┐
│ 魔珐星云端服务 │ │ LLM服务 │
│ TTS+动画参数 │ │ (Qwen/DeepSeek) │
│ (参数流推送) │ │ (流式文本生成) │
└─────────────────┘ └────────────────────┘
核心流程:用户提问 → LLM流式生成回答 → 文本分块送入星云SDK → 星云实时生成TTS+动画参数 → 端侧渲染呈现。
4.3 极简Demo代码
下面是一个可以直接复制运行的最小化Demo,展示了魔珐星云SDK的核心集成模式。我在开发过程中使用了Claude Code(Anthropic的AI编程CLI工具)来辅助编码,同时用Qwen3-VL多模态大模型作为AI老师的"大脑"。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>具身AI数学老师 - 魔珐星云Demo</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body {
font-family: -apple-system, sans-serif;
background: #1a1a2e;
color: #e0e0e0;
display: flex;
height: 100vh;
}
/* 数字人容器 - 必须设置明确的宽高 */
#avatar-container {
width: 480px;
height: 720px;
flex-shrink: 0;
}
/* 右侧对话面板 */
.chat-panel {
flex: 1;
display: flex;
flex-direction: column;
padding: 20px;
}
.chat-messages {
flex: 1;
overflow-y: auto;
padding: 10px;
}
.message {
margin: 8px 0;
padding: 10px 14px;
border-radius: 12px;
max-width: 80%;
line-height: 1.6;
}
.message.user {
background: #533483;
margin-left: auto;
}
.message.assistant {
background: #16213e;
}
.chat-input {
display: flex;
gap: 8px;
padding: 12px 0;
}
.chat-input input {
flex: 1;
padding: 10px 14px;
border: 1px solid #533483;
border-radius: 8px;
background: #16213e;
color: #e0e0e0;
font-size: 14px;
}
.chat-input button {
padding: 10px 20px;
border: none;
border-radius: 8px;
cursor: pointer;
font-size: 14px;
}
.btn-connect {
background: #0f3460;
color: #e0e0e0;
}
.btn-send {
background: #533483;
color: white;
}
.status-bar {
padding: 8px;
text-align: center;
font-size: 12px;
color: #888;
}
.config-area {
display: flex;
gap: 8px;
padding: 8px 0;
}
.config-area input {
flex: 1;
padding: 6px 10px;
border: 1px solid #333;
border-radius: 6px;
background: #16213e;
color: #e0e0e0;
font-size: 12px;
}
</style>
</head>
<body>
<!-- 数字人渲染区域 -->
<div id="avatar-container"></div>
<!-- 对话面板 -->
<div class="chat-panel">
<div class="config-area">
<input id="app-id" placeholder="星云 App ID" />
<input id="app-secret" type="password" placeholder="星云 App Secret" />
<input id="llm-key" type="password" placeholder="ModelScope API Key" />
</div>
<div class="status-bar">
<span id="status">未连接</span>
<button class="btn-connect" onclick="toggleConnect()">连接数字人</button>
</div>
<div class="chat-messages" id="messages"></div>
<div class="chat-input">
<input id="user-input"
placeholder="问我一个数学问题,比如'勾股定理怎么证明?'"
onkeydown="if(event.key==='Enter')sendMessage()" />
<button class="btn-send" onclick="sendMessage()">发送</button>
</div>
</div>
<!-- 加载星云SDK -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script>
let sdk = null;
let isConnected = false;
// ============ 星云SDK连接管理 ============
async function toggleConnect() {
if (isConnected) {
await disconnect();
} else {
await connect();
}
}
async function connect() {
const appId = document.getElementById('app-id').value;
const appSecret = document.getElementById('app-secret').value;
if (!appId || !appSecret) {
addMessage('system', '请填写星云 App ID 和 App Secret(可在 xingyun3d.com 免费获取)');
return;
}
setStatus('正在连接...');
// 初始化星云SDK
sdk = new XmovAvatar({
containerId: '#avatar-container',
appId: appId,
appSecret: appSecret,
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
onStateChange: (state) => {
console.log('数字人状态:', state);
setStatus('数字人: ' + state);
},
onVoiceStateChange: (status) => {
// 语音播放结束,切回互动待机状态
if (status === 'end') {
sdk.interactiveidle();
}
},
onMessage: (msg) => {
if (msg.code >= 40000) {
console.error('SDK错误:', msg);
}
},
onNetworkInfo: (info) => {
console.log('网络延迟:', info.rtt + 'ms');
},
enableLogger: true
});
try {
// 下载资源并初始化(首次需要下载模型资源)
await sdk.init({
onDownloadProgress: (progress) => {
setStatus('资源加载: ' + progress + '%');
}
});
// 进入待机状态
await sdk.idle();
isConnected = true;
setStatus('已连接 - 数字人就绪');
addMessage('system', '数字人老师已上线,请提问吧!');
} catch (err) {
setStatus('连接失败: ' + err.message);
sdk = null;
}
}
async function disconnect() {
if (sdk) {
await sdk.destroy();
sdk = null;
}
isConnected = false;
setStatus('已断开');
}
// ============ LLM对话 + 数字人驱动 ============
async function sendMessage() {
const input = document.getElementById('user-input');
const question = input.value.trim();
if (!question || !isConnected) return;
input.value = '';
addMessage('user', question);
const llmKey = document.getElementById('llm-key').value;
if (!llmKey) {
addMessage('system', '请填写 ModelScope API Key(modelscope.cn 免费申请)');
return;
}
try {
// Step 1: 切换到倾听状态
await sdk.listen();
// Step 2: 切换到思考状态
await sdk.think();
// Step 3: 调用LLM流式生成回答
const response = await fetch(
'https://api-inference.modelscope.cn/v1/chat/completions',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + llmKey
},
body: JSON.stringify({
model: 'Qwen/Qwen3-VL-235B-A22B-Instruct',
messages: [
{
role: 'system',
content: '你是一位亲切耐心的中学数学老师。用简洁易懂的语言讲解数学知识,适当举例。回答控制在150字以内。'
},
{ role: 'user', content: question }
],
stream: true
})
}
);
// Step 4: 流式读取LLM输出并驱动数字人说话
const reader = response.body.getReader();
const decoder = new TextDecoder();
let fullAnswer = '';
let textBuffer = '';
let isFirstChunk = true;
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
// 解析SSE格式的流式数据
const lines = chunk.split('\n');
for (const line of lines) {
if (!line.startsWith('data:')) continue;
const data = line.slice(5).trim();
if (data === '[DONE]') continue;
try {
const parsed = JSON.parse(data);
const content = parsed.choices?.[0]?.delta?.content || '';
if (!content) continue;
fullAnswer += content;
textBuffer += content;
// 累积到一定长度后送给数字人说话
// 首块立即送出(降低首字延迟),后续按标点分块
if (isFirstChunk || textBuffer.length >= 30 || /[。!?;]/.test(textBuffer)) {
await sdk.speak(
textBuffer, // 要朗读的文本
isFirstChunk, // 是否是第一块(开始新语音)
false // 是否是最后一块
);
isFirstChunk = false;
textBuffer = '';
}
} catch (e) {
// 忽略解析错误
}
}
}
// 发送剩余文本并标记结束
if (textBuffer) {
await sdk.speak(textBuffer, false, true);
} else {
// 用空字符串标记结束
await sdk.speak('', false, true);
}
// 在聊天面板中显示完整回答
addMessage('assistant', fullAnswer);
} catch (err) {
addMessage('system', '出错了: ' + err.message);
if (sdk) await sdk.interactiveidle();
}
}
// ============ UI工具函数 ============
function addMessage(role, text) {
const container = document.getElementById('messages');
const div = document.createElement('div');
div.className = 'message ' + role;
div.textContent = text;
container.appendChild(div);
container.scrollTop = container.scrollHeight;
}
function setStatus(text) {
document.getElementById('status').textContent = text;
}
// 页面关闭时销毁SDK,释放资源
window.addEventListener('beforeunload', () => {
if (sdk) sdk.destroy();
});
</script>
</body>
</html>
使用方法:
- 到 魔珐星云官网 注册获取 App ID 和 App Secret
- 把上面的代码保存为
.html文件,用浏览器打开(注意:需要通过localhost或HTTPS访问,直接双击打开的file://协议不支持) - 填入密钥,点击连接,等资源下载完成后就可以对话了
4.4 代码解析:几个关键设计点
(1)状态机驱动的交互节奏
星云SDK的核心是状态机模式。数字人有明确的状态流转:
idle(待机) → listen(倾听) → think(思考) → speak(说话) → interactiveidle(互动待机)
每个状态对应数字人不同的行为表现:idle时自然呼吸,listen时微微前倾表示关注,think时皱眉思考,speak时配合手势讲解。这些状态转换不是简单的动画切换,而是SDK内部统一管理的连贯行为。
(2)流式驱动:LLM和数字人的节奏同步
核心挑战是让LLM的流式输出和数字人的实时驱动无缝衔接。Demo中的策略是:
- LLM的第一个token到达时,立即调用
speak(text, true, false)开始驱动数字人说话 - 后续按标点或固定长度分块送入,
speak(chunk, false, false)追加内容 - LLM生成完成后,
speak('', false, true)标记结束
这样数字人的"说话"和LLM的"生成"是并行进行的,用户几乎感觉不到等待。
(3)生命周期管理:别忘了 destroy()
这是我在开发中踩过的坑:页面关闭时如果不调用 sdk.destroy(),WebSocket连接不会断开,服务端的会话资源不会释放。连续刷新页面几次后就会触发并发限制(错误码10005)。所以 beforeunload 里必须调用 destroy()。
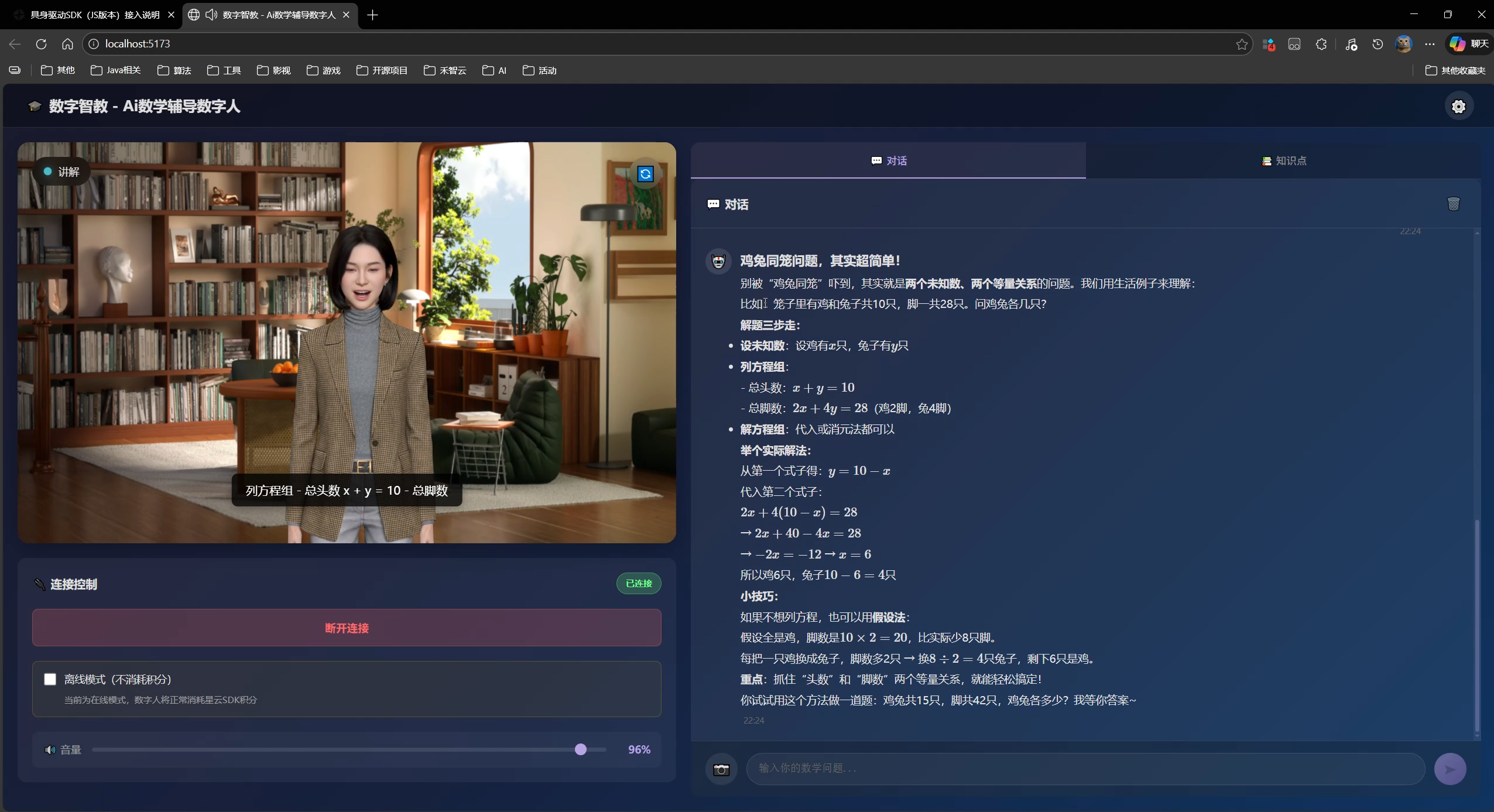
4.5 从Demo到产品:我的实际项目经验
上面的Demo是最小化版本。在真实项目中,我做了一个更完整的具身智能数学辅导系统,包含:
- 知识点学习模式:16个预设数学知识点(勾股定理、导数定义等),按分类和难度组织
- 多模态输入:支持拍照上传数学题目,用Qwen3-VL多模态模型识别和解析
- SSML动作系统:通过
<ue4event>标签在文本中嵌入手势指令(欢迎、讲解、鼓励),数字人说话时会配合语义做出对应动作 - 向量知识库:用Embedding模型构建语义检索,让AI老师的回答更有针对性
开发这个项目的过程中,我使用了 Claude Code 辅助SDK集成和前端开发。星云官方还提供了一个AI Coding Skill——一个结构化的Prompt文件,可以部署到Cursor、Windsurf等AI编辑器中,让AI自动生成符合最佳实践的SDK集成代码。
五、开发与落地:SDK、API和架构全览
5.1 SDK集成方式
魔珐星云目前提供了JS SDK(Web端)和Android SDK(移动端),通过CDN加载:
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
核心API只有几个,上手门槛很低:
| API | 用途 | 说明 |
|---|---|---|
new XmovAvatar(config) |
创建实例 | 传入容器、密钥、回调 |
sdk.init(options) |
初始化 | 下载资源,建立WebSocket |
sdk.speak(ssml, isStart, isEnd) |
驱动说话 | 支持流式,支持SSML嵌入动作 |
sdk.listen() |
倾听状态 | 数字人做出倾听姿态 |
sdk.think() |
思考状态 | 数字人做出思考表情 |
sdk.idle() |
待机状态 | 自然呼吸等基础动作 |
sdk.interactiveidle() |
互动待机 | 用于中断当前说话 |
sdk.destroy() |
销毁实例 | 释放资源,断开连接 |
5.2 AI Coding工具加持:从想法到Demo的加速器
Claude Code:我主要用它来处理SDK集成的架构设计和复杂逻辑。比如数字人状态机的管理、流式文本分块策略、错误处理等。Claude Code能够理解整个项目上下文,给出结构合理的代码方案。
Cursor + 星云AI Coding Skill:星云官方提供了一个 Xmov_Skill.md 技能文件,可以部署到Cursor、Windsurf等编辑器。部署后,AI编辑器就"学会"了星云SDK的最佳实践——包括正确的初始化流程、状态机管理、中断协议、生命周期保护等。输入"初始化项目",AI就能生成一个完整可运行的HTML Demo。
Qwen3-VL + DeepSeek:作为AI老师的"大脑"。Qwen3-VL支持多模态(文字+图片),适合教育场景中学生拍照提问的需求。DeepSeek-V3在数学推理方面表现也不错。通过ModelScope的API,这些模型都能以OpenAI兼容格式调用,对接成本低。
这种AI Coding + 星云SDK的开发模式,让整个项目的开发效率提升了一个量级。以前可能需要一周才能搞定的SDK集成和前端开发,现在一个下午就能跑通核心流程。
5.3 架构与落地方式
从架构角度看,魔珐星云的集成方式非常轻量:
┌─────────────── 你的应用 ──────────────┐
│ │
│ 前端(Web/Android) │
│ ├── 加载星云SDK (<script>) │
│ ├── 创建数字人容器 (div) │
│ └── 调用SDK API (状态机驱动) │
│ │
│ 后端(可选) │
│ ├── LLM API代理 │
│ ├── 知识库/RAG │
│ └── 业务逻辑 │
│ │
└───────────────────────────────────────┘
│ │
WebSocket HTTP API
│ │
┌────────▼──────┐ ┌───────▼─────────┐
│ 魔珐星云服务 │ │ LLM服务 │
│ TTS + 动画生成 │ │ Qwen/DeepSeek │
│ 参数流推送 │ │ 流式文本生成 │
└────────────────┘ └─────────────────┘
几个落地要点:
- 协议要求:必须通过
localhost或HTTPS访问。本地开发可以用npx serve或python -m http.server起一个本地服务器。生产环境需要HTTPS。 - 硬件加速:SDK支持
prefer-hardware(优先GPU)、prefer-software(纯CPU)和default(自动检测)三种模式。在低端设备上可以降级到软件渲染。 - SSML动作系统:通过SSML标签可以在文本中嵌入动作指令,让数字人的手势和语言内容同步。比如讲解数学时配合"讲解"手势,鼓励学生时配合"鼓励"动作。
- Widget系统:支持字幕、图片、PPT幻灯片等Widget组件。可以在数字人说话时同步展示相关内容(如数学公式、示意图)。
- 错误处理:SDK的错误码体系很清晰(10000-50000分段),从连接问题到渲染问题都有对应的错误码,方便定位和排查。
六、总结:从"能对话"到"能表达"的体验跃迁
写这篇文章的过程,也是我回顾开发经历的过程。总结几个真实的感受:
关于技术体验。 参数流+端侧渲染的架构不是小修小补的优化,而是从根本上的范式转换。当你第一次看到数字人在你面前实时说话、表情自然变化、手势跟内容配合——而这一切只有不到500ms的延迟——你会真切感受到"具身智能交互"和"文字聊天"之间的体验鸿沟。这不是锦上添花,是交互形态的质变。
关于开发体验。 星云SDK的设计对开发者很友好。核心API只有七八个方法,状态机的语义清晰,流式接口设计合理。配合AI Coding工具和官方Skill文件,从零到可运行Demo的时间可以压缩到30分钟以内。这种开发效率对于快速验证场景想法非常关键。
关于场景想象。 文章中我只展开了教育这一个场景,但实际想象空间大得多。金融领域的智能客服、医疗领域的健康咨询助手、文旅场景的智能讲解员、智能座舱的AI副驾——任何一块屏幕,都可能因为具身智能数字人而升级为一个AI具身智能体。这不是遥远的未来,而是现在就能落地的能力。
关于国产化闭环。 特别值得提的一点是,魔珐星云的参数流+端侧渲染技术,配合Qwen、DeepSeek等国产大模型,已经能形成完整的国产化AI闭环。从LLM推理到语音合成到3D具身表达,全部用国产技术栈走通,这在信创场景下有非常现实的意义。
如果用一个词来概括我的整体体验:具身。AI不只是"能回答问题",更能"像一个真实的存在一样和你对话"。这让我对AI Agent的未来多了一种期待——不只是更聪明的文字助手,而是能感知、能理解、能表达、能交互的AI具身智能体。
魔珐星云具身智能数字人开放平台,体验AI从"能思考"到"能表达"的跃迁:[魔珐星云PC端官方链接]
相关资源:
- 魔珐星云开发者文档:https://xingyun3d.com/developers/52-183
- 魔珐星云AI Coding Skill:https://rsjqcmnt5p.feishu.cn/wiki/ULNQwoiKwid2tVkTpAlcMb49nKg

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)