2026年AI大模型本地部署完全指南:从零门槛到上手实战
2026年6月,AI圈又炸了。先是150万Token超长上下文模型密集发布,接着DeepSeek V4以万亿参数强势开源,国产大模型全面崛起。很多人看着这些新闻心里痒痒:本地跑个AI助手,数据不用上传云端,还不用交API月费,岂不是美滋滋?

但一搜教程,满屏都是命令行、Docker、conda环境配置……直接劝退。
今天这篇文章,就来给你讲清楚:2026年本地部署AI大模型,到底需要什么配置?有哪些工具可选?以及,如果你跟我一样不想敲代码,怎么做到开箱即用。
一、为什么2026年一定要关注本地部署?
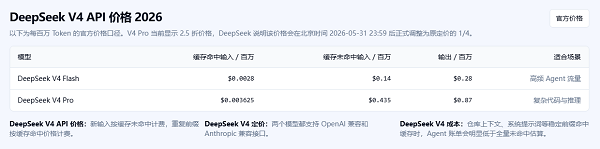
1.2026年4月,DeepSeek V4开源,万亿参数,推理能力直接对标国际顶流模型,而且完全免费商用。
2.6月发布潮中,多家厂商推出150万Token超长上下文模型,本地跑长文档总结成为可能。
3.Qwen3、Gemma 4、Llama 4等开源模型百花齐放,4GB到24GB显存都有对应的选择。
本地部署的核心优势就三个:
- 数据隐私零泄露——公司文档、个人日记、敏感代码,全留在本地硬盘,不上传任何服务器。
- 零API费用——不用充ChatGPT Plus,不用买Claude Pro,一次性投入硬件,长期免费使用。
- 离线可用——内网环境、断网场景、出国差旅,照样能聊。
二、你的电脑能跑什么模型?2026年配置对照表
很多人最关心的问题:我的电脑能不能跑?能跑多大的?
| 显存/内存 | 推荐模型 | 适用场景 | 体验等级 |
| 4GB显存 | Phi-4-mini、Qwen3-1.8B | 简单问答、代码补全 | 入门级 |
| 8GB显存 | Qwen3-8B、Gemma2-9B | 日常办公、写作辅助 | 流畅可用 |
| 16GB显存 | Qwen3-32B、Llama 4-17B | 复杂推理、代码生成 | 优秀 |
| 24GB显存 | DeepSeek-V3-lite、Qwen3-72B | 专业开发、长文档处理 | 旗舰级 |
注意:显存不够可以用内存+量化(4bit/8bit)来弥补,只是速度和精度会打折扣。对大多数人来说,8GB显存已经能跑得很好了。
三、主流部署方案对比:哪个最适合你?
目前市面上主流方案不少,我按门槛高低排个序:
方案一:Ollama + Open WebUI(开发者首选)
Ollama算是最知名的本地部署工具,一行命令拉模型,配合Open WebUI能有漂亮的聊天界面。优点是生态成熟、模型多;缺点是纯命令行操作,Windows用户配环境容易踩坑,新手劝退率不低
方案二:LM Studio(可视化界面)
LM Studio有图形界面,不用敲命令行,对小白更友好。但模型下载速度不稳定,高级功能要付费,而且国内的网络环境经常连不上模型库。
方案三:OpenClaw部署助手(零门槛开箱即用)
如果你跟我一样,不想折腾命令行,也不想因为网络问题下载不了模型,不妨试试OpenClaw部署助手。
它本质上是一个图形化的AI部署和管理工具,把Ollama、模型下载、服务配置这些繁琐步骤全部封装好了。安装完打开控制面板,点几下就能跑起来。我目前用的是最新版本(v1.4.0),几个功能确实省心:
- 一键健康检查——自动诊断运行环境,缺什么依赖、GPU驱动对不对,一目了然,不用自己排查。
- AI模型管理——模型列表直接展示,下载、切换、更新都是点按钮,不用记命令。
- 命令行工具——高级用户想敲命令也行,内置openclaw命令,不用额外配环境变量。
- Skill市场——可以扩展各种功能插件,比如知识库、文档解析、代码助手,按需加装。
最关键的是,它把"本地部署"这件事真正做到了零门槛。我之前给朋友装过一次,从头到尾他没敲过一行命令,10分钟后就在跟他本地的DeepSeek模型聊天了。
四、手把手实战:5分钟跑通本地AI
以OpenClaw为例,演示一个最简单的部署流程(其他工具逻辑类似):
第1步:安装OpenClaw部署助手
点击下载安装,按向导一路下一步。安装完桌面会出现控制面板图标,双击打开。
OpenClaw部署助手![]() https://www.160.com/qddownload/3007/openclawtool-windows.exe
https://www.160.com/qddownload/3007/openclawtool-windows.exe
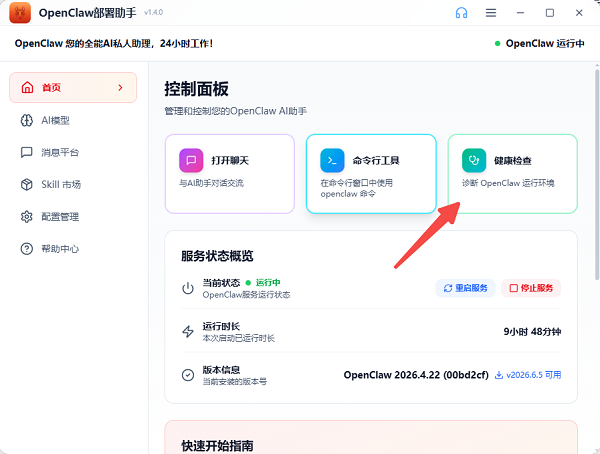
第2步:运行健康检查
控制面板首页点击"健康检查",系统会自动扫描:GPU驱动是否正常、CUDA版本是否兼容、内存和显存是否够用。如果有问题,会给出具体修复建议。
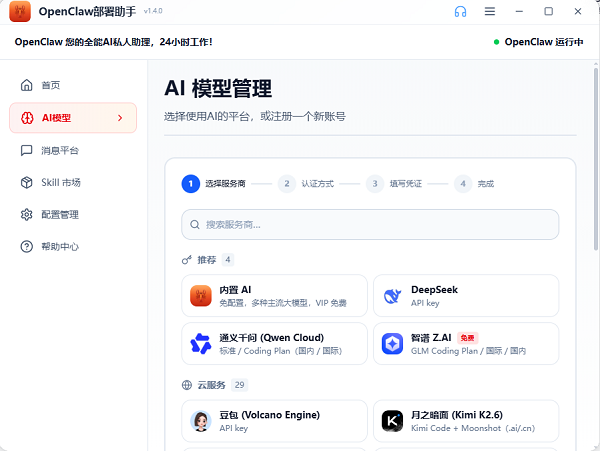
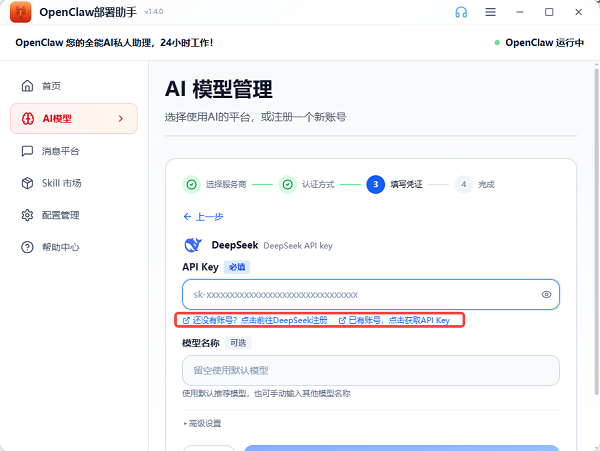
第3步:配置AI模型
进入"AI模型"页面,根据你的显存选择对应模型(8GB显存推荐Qwen3-8B,16GB推荐Qwen3-32B),点击下载。模型文件会自动拉取并配置好。
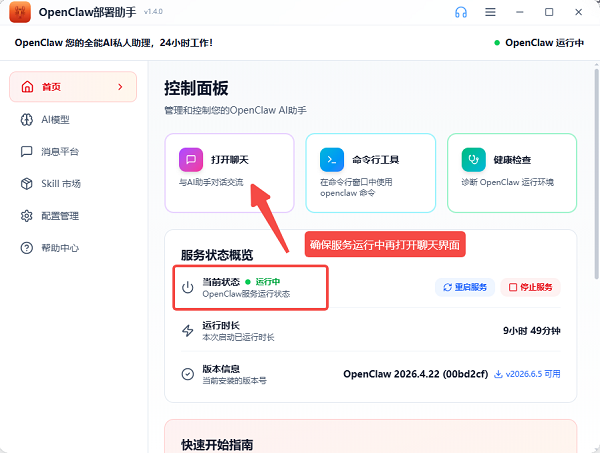
第4步:开始聊天
回到首页点击"打开聊天",界面跟网页版ChatGPT差不多,直接输入问题就能对话。所有数据都在本地,断网也能用。
整个过程不超过5分钟。如果用的是Ollama,大致流程类似,只是需要在命令行里执行ollama run qwen3:8b这样的指令,对小白来说多了一道门槛。
五、常见问题答疑
Q:没有独显,核显/CPU能跑吗?
A:能跑,但很慢。纯CPU运行7B模型,生成一句话可能要等十几秒。建议至少有一张8GB显存的独显(RTX 3060/4060级别),体验才会比较流畅。
Q:模型文件占多大空间?
A:Qwen3-8B大约5GB,32B大约20GB,72B大约45GB。建议预留至少100GB硬盘空间,方便多装几个模型对比。
Q:Windows和Linux哪个更适合本地部署?
A:Linux(尤其是Ubuntu)对GPU支持更原生,性能略好。但2026年的工具链(包括OpenClaw)对Windows优化已经很好了,普通用户用Windows完全没问题,不用为了跑AI特意装双系统。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)