深入拆解 Claude 的 DOCX Skill:一个 LLM 是如何学会操作 Word 文档的
本文从源码层面完整解析 Claude Code 中 DOCX Skill 的实现原理——它没有经过微调,没有做过强化学习,却能创建、编辑和分析 Word 文档。这背后是一套"预训练知识 + 运行时提示注入 + 工具链 + 验证系统"的工程架构。
一、开篇:AI 真的能操作 Word 文档了?
当你对 Claude Code 说"帮我创建一份带目录、页眉页脚和表格的季度报告 Word 文档",或者"把这份合同里的’30 天’改成’60 天’,用修订模式标记"——它真的能做到。不是输出一段 Markdown 让你自己复制粘贴,而是直接生成一个 .docx 文件,能在 Microsoft Word、Google Docs、WPS 中正常打开,格式完好无损。
这引出了几个核心问题:
- • Claude 是怎么获得操作 .docx 文件能力的?有没有对相关库做过微调?
- • 有没有通过强化学习(RL)让模型学会编辑 Word 文档的 XML?
- • 如果没有专项训练,这套系统是怎么保证输出文档不损坏的?
- • 我用小模型(比如 Qwen3.5 27B)能不能复现这个能力?
本文将从源码层面完整回答这些问题。
DOCX Skill 的组成
在深入细节之前,先来看一下这个 Skill 的整体结构。DOCX Skill 由两部分组成:一份提示词文件和一套脚本工具链。
skills/docx/├── SKILL.md ← 核心提示词(590 行),运行时注入到 Claude 上下文└── scripts/ ├── accept_changes.py ← 接受所有修订(调用 LibreOffice 宏) ├── comment.py ← 添加批注(协调写入 4-7 个 XML 文件) ├── templates/ ← 批注相关的 XML 骨架模板(5 个) └── office/ ├── unpack.py ← 解包:.docx → 可编辑的 XML 目录 ├── pack.py ← 打包:XML 目录 → .docx(含验证+修复) ├── validate.py ← 独立验证入口 ├── soffice.py ← LibreOffice 运行辅助(含沙盒 C shim) ├── helpers/ │ ├── merge_runs.py ← 合并碎片化的 <w:r> 元素 │ └── simplify_redlines.py ← 简化修订标记 ├── validators/ │ ├── base.py ← 基础验证器(8 项检查 + 39 个 XSD Schema) │ ├── docx.py ← DOCX 专用验证器(5 项检查 + 自动修复) │ ├── redlining.py ← 修订完整性验证器 │ └── pptx.py ← PPTX 验证器(架构复用) └── schemas/ ← 39 个 XSD Schema 文件 ├── ISO-IEC29500-4_2016/ (22 个) ├── ecma/fouth-edition/ (4 个) ├── microsoft/ (7 个) └── mce/ (1 个)
SKILL.md 是整个 Skill 的"大脑"——590 行的参考手册,包含了三大核心能力(创建、编辑、读取)的详细操作指南、15 条 Critical Rules(踩坑记录)、XML 元素参考。它在运行时被注入到 Claude 的上下文窗口中,相当于把一本操作手册放在程序员的桌子上。
scripts/ 是 Skill 的"手脚"——一套 Python 工具链,负责解包/打包 .docx 文件、验证 XML 合法性、自动修复常见错误、管理批注和修订。Claude 通过调用这些脚本来完成具体的文件操作。
本文正文聚焦于原理和流程。每个脚本的详细功能、参数和使用场景,见文末的附录:脚本工具链详解。
二、背景知识:.docx 文件的真面目
在深入 DOCX Skill 之前,需要先理解一个关键事实——SKILL.md 的开头就点明了这一点:
A .docx file is a ZIP archive containing XML files.
.docx 不是一种不透明的二进制格式,它本质上是一个 ZIP 压缩包,里面装着一组遵循 OOXML(Office Open XML)标准的 XML 文件。用任何解压工具打开一个 .docx,你会看到这样的目录结构:
document.docx (ZIP)├── [Content_Types].xml ← 声明每个文件的 MIME 类型├── _rels/│ └── .rels ← 顶层关系文件(入口点)├── word/│ ├── document.xml ← 文档主体:段落、表格、文本│ ├── styles.xml ← 样式定义(标题、正文、列表等)│ ├── numbering.xml ← 列表编号配置│ ├── comments.xml ← 批注内容│ ├── header1.xml / footer1.xml← 页眉 / 页脚│ ├── media/ ← 嵌入的图片│ └── _rels/│ └── document.xml.rels ← document.xml 的关系映射└── docProps/ ├── app.xml ← 应用属性 └── core.xml ← 文档元数据(作者、创建时间等)
OOXML 是一个 ISO 国际标准(ISO/IEC 29500),同时也是 ECMA-376 标准。微软在此基础上又增加了自己的扩展命名空间(如 Word 2010/2012/2016/2018 的扩展)。DOCX Skill 的 schemas/ 目录中包含了 39 个 XSD Schema 文件,覆盖了这三层标准:
| 标准层 | 文件数 | 覆盖内容 |
|---|---|---|
| ISO-IEC 29500-4:2016 | 22 个 | WordprocessingML、DrawingML、VML、共享类型 |
| ECMA-376 第四版 | 4 个 | OPC 包格式:Content Types、Relationships 等 |
| Microsoft 扩展 | 7 个 | Word 2010-2020 的扩展特性(评论 ID、符号扩展等) |
| MCE | 1 个 | 标记兼容性与可扩展性 |
这些 Schema 文件用 XSD(XML Schema Definition) 语言定义了每个 XML 文件的结构规范——规定了哪些元素必须出现、元素的嵌套关系、属性的数据类型和取值范围等。例如,在 wml.xsd 中定义了 <w:p>(段落)必须包含 <w:pPr>(段落属性)和 <w:r>(run),属性名必须以 w: 命名空间前缀开头等。在打包/验证阶段,这些 Schema 文件是 DOCX Skill 验证系统的基石,用来对比修改前后的 XML 是否遵循标准——后文会详细介绍。
为什么操作 .docx 比想象中复杂得多
以"给文档添加一条批注"这个看似简单的操作为例,实际需要同时操作:
word/comments.xml—— 写入批注文本word/commentsExtended.xml—— 写入扩展元数据(回复关系、完成状态)word/commentsIds.xml—— 写入持久化 IDword/commentsExtensible.xml—— 写入时间戳元数据word/_rels/document.xml.rels—— 注册上述 4 个文件的 Relationship[Content_Types].xml—— 注册 4 个文件的 MIME 类型word/document.xml—— 在正确的位置插入<w:commentRangeStart/>、<w:commentRangeEnd/>和<w:commentReference/>标记
任何一步出错——比如忘了注册 Content Type,或者把 commentRangeStart 放到了 <w:r> 内部而不是外部——Word 打开文档时就会报错或丢失批注。这就是为什么 DOCX Skill 需要如此复杂的工具链。
三、核心问题:Claude 的 DOCX 能力从何而来?
这是本文最重要的分析部分。答案可能出乎很多人的意料。
3.1 没有对 docx-js 做微调
DOCX Skill 使用 JavaScript 的 docx npm 包来创建新文档。Claude 对这个库的了解完全来自预训练阶段——docx 是一个开源库,在 GitHub 上有大量使用示例和文档,在 npm 上被广泛使用。Claude 在预训练语料中见过这些代码,就像它见过 React、Express、Pandas 一样。
这是通用编程能力,不是专项训练的结果。
3.2 没有针对 DOCX 编辑做强化学习
没有一个 reward model 来评估"这次 XML 编辑是否产生了合法文档"。模型不是通过 RL 学会了如何正确编辑 OOXML——它是通过工程手段来弥补自身不足的。
最直接的证据是:验证系统的存在本身就说明模型会犯错。如果经过 RL 优化,就不需要 39 个 XSD Schema + 11 项校验规则 + 自动修复机制这么重的"安全网"了。
3.3 没有对 DOCX 格式做专项训练
Claude 没有用 OOXML 相关的特殊数据集做过任何形式的微调。SKILL.md(590 行)是在运行时被注入到 Claude 的上下文窗口中的,作为 system prompt 的一部分:
┌────────────────────────────────────┐│ Claude 的上下文窗口 ││ ││ [System Prompt] ││ [SKILL.md 全文 ≈ 590行] ← 注入 ││ [用户消息] ││ [对话历史] │└────────────────────────────────────┘
这是 In-Context Learning(上下文学习),不是参数层面的学习。SKILL.md 相当于一本操作手册被"放在程序员的桌子上"让他对照着写。
3.4 真正的架构
DOCX Skill 的能力来源是一个四层架构:
┌─────────────────────────────────────────────┐│ 第一层:预训练知识 ││ Claude 从公开代码/文档中学到的通用编程能力 ││ → 知道 .docx 是 ZIP、<w:p> 是段落等基础概念 │├─────────────────────────────────────────────┤│ 第二层:SKILL.md 运行时注入 ││ 590 行参考手册,包含 API 用法、踩坑规则、XML 参考 ││ → 弥补预训练知识的模糊和不精确 │├─────────────────────────────────────────────┤│ 第三层:Python 工具链 ││ unpack.py / pack.py / comment.py 等脚本 ││ → 把"编辑二进制文件"转化为"编辑文本 XML" │├─────────────────────────────────────────────┤│ 第四层:验证系统 ││ 39 个 XSD Schema + 11 项校验 + 自动修复 ││ → 捕获模型犯的错误,确保输出文件可用 │└─────────────────────────────────────────────┘
这个架构意味着什么? 即使要增强 Claude 的 DOCX 能力,也不需要在预训练或后训练阶段做任何特殊处理。SKILL.md 的 590 行文本本身就是一份"运行时知识库"——任何大模型只要:
- • 有足够的上下文窗口(Claude 的 200K token)
- • 能理解和遵循详细的格式规范
- • 能进行精确的文本编辑
就能驾驭这个 Skill。如果在预训练或后训练阶段做专项训练,唯一的效果是降低对 SKILL.md 的依赖——但 SKILL.md 本身就很轻量、易更新,投入训练成本得不偿失。
3.5 预训练知识 vs SKILL.md 补充知识
下表直观展示了"大概知道"和"精确知道"的差距:
| 层面 | 预训练就知道的 | SKILL.md 必须额外告诉的 |
|---|---|---|
| 基本结构 | .docx 是 ZIP,里面有 XML |
— |
| 文件职责 | document.xml 是主体 |
— |
| 元素语义 | <w:p> 是段落,<w:t> 是文本 |
— |
| 元素顺序 | 不确定 | <w:pPr> 内必须按 pStyle → numPr → spacing → ind → jc → rPr 排列 |
| 删除标记 | <w:del> 包裹删除内容 |
里面必须用 <w:delText> 而非 <w:t> |
| 删除整段 | 不知道 | 必须在 <w:pPr><w:rPr> 内额外加 <w:del/>,否则留空段落 |
| 空白处理 | 不确定 | 前导/尾随空格的 <w:t> 必须加 xml:space="preserve" |
| ID 约束 | 不知道 | paraId < 0x80000000 ,durableId < 0x7FFFFFFF |
| 表格宽度 | 知道有 DXA 和 PERCENTAGE | 永远不要用 PERCENTAGE (Google Docs 崩溃) |
| 智能引号 | 不知道这是个问题 | 必须用 ’ 等 XML 实体 |
| 横版页面 | 设置 LANDSCAPE | 必须传竖版尺寸,docx-js 内部自动交换 |
SKILL.md 中的 15 条 Critical Rules 和 Common Pitfalls 就是工程师在实际使用中发现 Claude 会犯的错误后手工总结的踩坑记录。每一条规则背后都是一类真实的 bug。
四、三大核心能力详解
SKILL.md 中定义了三种操作 .docx 的路径:
| 任务 | 方法 |
|---|---|
| 读取 / 分析内容 | pandoc 或解包查看原始 XML |
| 创建新文档 | 使用 docx-js JavaScript 库 |
| 编辑已有文档 | 解包 → 编辑 XML → 重新打包 |
下面逐一展开。
4.1 创建新文档——基于 docx-js
当用户要求从零创建一个 .docx 文件时,Claude 会编写 JavaScript 代码,调用 docx npm 包。
完整流程
Claude 生成 JS 代码 → node 执行 → 生成 .docx → validate.py 校验 │ 如果有错误则解包修复
以下是一个创建带页眉、表格和目录的报告的完整示例:
const fs = require("fs");const { Document, Packer, Paragraph, TextRun, Table, TableRow, TableCell, Header, Footer, HeadingLevel, AlignmentType, BorderStyle, WidthType, ShadingType, PageNumber, PageBreak, TableOfContents } = require("docx");const border = { style: BorderStyle.SINGLE, size: 1, color: "CCCCCC" };const borders = { top: border, bottom: border, left: border, right: border };const doc = new Document({ // 样式定义:覆盖内建标题样式 styles: { default: { document: { run: { font: "Arial", size: 24 } } }, // 12pt paragraphStyles: [ { id: "Heading1", name: "Heading 1", basedOn: "Normal", next: "Normal", quickFormat: true, run: { size: 32, bold: true, font: "Arial" }, paragraph: { spacing: { before: 240, after: 240 }, outlineLevel: 0 } }, // outlineLevel 是目录(TOC)正常工作的必要条件 ] }, sections: [{ properties: { page: { size: { width: 12240, height: 15840 }, // US Letter(DXA 单位) margin: { top: 1440, right: 1440, bottom: 1440, left: 1440 } } }, headers: { default: new Header({ children: [new Paragraph({ children: [new TextRun("Acme Corp - Q3 Report")] })] }) }, footers: { default: new Footer({ children: [new Paragraph({ children: [new TextRun("Page "), new TextRun({ children: [PageNumber.CURRENT] })] })] }) }, children: [ // 标题 new Paragraph({ heading: HeadingLevel.HEADING_1, children: [new TextRun("Q3 2025 Quarterly Report")] }), // 目录(仅在 Word 中打开并"更新域"后生效) new TableOfContents("Table of Contents", { hyperlink: true, headingStyleRange: "1-3" }), new Paragraph({ children: [new PageBreak()] }), // 正文 new Paragraph({ children: [new TextRun("Revenue grew 15% year-over-year...")] }), // 表格:注意"双宽度"要求 new Table({ width: { size: 9360, type: WidthType.DXA }, // 总宽 = 页宽 - 左右边距 columnWidths: [4680, 4680], // 必须加和等于总宽 rows: [ new TableRow({ children: [ new TableCell({ borders, width: { size: 4680, type: WidthType.DXA }, // 必须和 columnWidths 匹配 shading: { fill: "D5E8F0", type: ShadingType.CLEAR }, // 必须用 CLEAR margins: { top: 80, bottom: 80, left: 120, right: 120 }, children: [new Paragraph({ children: [new TextRun({ text: "Metric", bold: true })] })] }), new TableCell({ borders, width: { size: 4680, type: WidthType.DXA }, shading: { fill: "D5E8F0", type: ShadingType.CLEAR }, margins: { top: 80, bottom: 80, left: 120, right: 120 }, children: [new Paragraph({ children: [new TextRun({ text: "Value", bold: true })] })] }), ]}), ] }), ] }]});Packer.toBuffer(doc).then(buf => fs.writeFileSync("report.docx", buf));
SKILL.md 中对各文档元素的详细规范
SKILL.md 用了约 300 行篇幅来描述创建文档时每种元素的用法和陷阱。这些不是"功能文档",而是针对 Claude 犯错模式优化过的防错手册。以下是各元素的关键点:
页面尺寸(DXA 单位)
OOXML 使用 DXA(Device Independent Pixel 的二十分之一)作为长度单位,1440 DXA = 1 英寸。SKILL.md 提供了明确的换算表:
| 纸张 | 宽度 (DXA) | 高度 (DXA) | 内容宽度(1英寸边距) |
|---|---|---|---|
| US Letter | 12,240 | 15,840 | 9,360 |
| A4(默认) | 11,906 | 16,838 | 9,026 |
关键陷阱:docx-js 默认使用 A4 而非 US Letter,必须显式指定。横版方向时,要传入竖版尺寸并设置 PageOrientation.LANDSCAPE——docx-js 内部会自动交换宽高。
列表
SKILL.md 明确禁止使用 unicode 符号字符来模拟列表:
// WRONG - 绝对不要手动插入项目符号new Paragraph({ children: [new TextRun("• Item")] }) // 错误new Paragraph({ children: [new TextRun("\u2022 Item")] }) // 错误// CORRECT - 使用 LevelFormat.BULLET 配合 numbering configconst doc = new Document({ numbering: { config: [{ reference: "bullets", levels: [{ level: 0, format: LevelFormat.BULLET, text: "•", alignment: AlignmentType.LEFT, style: { paragraph: { indent: { left: 720, hanging: 360 } } } }] }] }, sections: [{ children: [ new Paragraph({ numbering: { reference: "bullets", level: 0 }, children: [new TextRun("Bullet item")] }), ] }]});
表格(最容易出错的元素)
表格有 5 条 Critical Rules,是出错最多的区域:
- 双宽度要求:必须同时设置表格的
columnWidths数组和每个 cell 的width,两者必须匹配 - 只用 DXA:
WidthType.PERCENTAGE在 Google Docs 中会导致渲染异常,只能用WidthType.DXA - CLEAR 而非 SOLID:
ShadingType.SOLID会导致纯黑背景,必须用ShadingType.CLEAR - 宽度加和:表格总宽必须等于
columnWidths之和 - 不要用表格做分隔线:表格单元格有最小高度,在页眉页脚中会渲染为空盒子。应该使用
Paragraph的border属性
图片
new Paragraph({ children: [new ImageRun({ type: "png", // 必填!不填会生成无效 XML data: fs.readFileSync("image.png"), transformation: { width: 200, height: 150 }, altText: { title: "Title", description: "Desc", name: "Name" } })]})
其他元素
| 元素 | 关键要求 |
|---|---|
| 分页符 | PageBreak 必须放在 Paragraph 内部 |
| 超链接 | 外部用 ExternalHyperlink,内部用 Bookmark + InternalHyperlink |
| 脚注 | 在 Document 构造器的 footnotes 属性中定义,正文中用 FootnoteReferenceRun 引用 |
| Tab Stops | 右对齐用 TabStopType.RIGHT,圆点引导用 PositionalTab |
| 多栏布局 | 在 section.properties.column 中设置,强制换栏用 SectionType.NEXT_COLUMN |
| 目录 (TOC) | 标题必须用 HeadingLevel,不能用自定义样式;样式定义必须含 outlineLevel |
| 页眉页脚 | 不要用表格实现双栏页脚布局,用 Tab Stops 代替 |
15 条 Critical Rules
SKILL.md 结尾汇总了 15 条"创建文档必须遵守的规则"。这些规则的共同特点是:不查标准原文或不踩过坑,你不可能知道。以下列举几条代表性的:
- •
\n换行无效——必须创建新的Paragraph对象 - • docx-js 默认 A4——必须显式设置页面尺寸
- • 横版传竖版尺寸——docx-js 内部会交换
- • 样式覆盖用精确 ID——
"Heading1"而非自定义名称 - • TOC 要求
outlineLevel——没有这个属性,目录无法索引到标题
创建后验证
python scripts/office/validate.py report.docx
如果验证发现错误,Claude 会解包文档、修复 XML、重新打包。
4.2 编辑已有文档——Unpack → Edit XML → Pack
这是 DOCX Skill 中工程量最大、也最精妙的能力。核心思想是:把不透明的二进制格式转化为 Claude 能直接读写的文本 XML。
完整流程
原始文档 document.docx │ ▼ Step 1: unpack.py解包目录 unpacked/word/document.xml(格式化、可读的 XML) │ ▼ Step 2: Claude 用 Edit 工具做精确字符串替换修改后的 unpacked/word/document.xml │ ▼ Step 3: pack.py输出文档 output.docx(经过验证 + 自动修复)
Step 1: 解包(unpack.py)
python scripts/office/unpack.py document.docx unpacked/
解包不仅仅是 unzip,它做了四件关键的事:
- ZIP 解压:
zipfile.ZipFile.extractall() - XML 格式化:用
defusedxml.minidom的toprettyxml()把单行 XML 变成缩进格式。从:
<w:p><w:r><w:rPr><w:b/></w:rPr><w:t>The term is 30 days.</w:t></w:r></w:p>
变成 Claude 可读的:
<w:p> <w:r> <w:rPr> <w:b/> </w:rPr> <w:t>The term is 30 days.</w:t> </w:r></w:p>
- 合并碎片 Run(merge_runs.py):Word 经常因为拼写检查、光标位置、自动保存等原因,把连续文本拆成多个
<w:r>元素。例如,模板中的占位符{{borrower_name}}在 Word 中被拆成了这样:
<!-- 原始状态:被拆成 3 个 run,格式完全相同 --><w:r><w:t>{{</w:t></w:r><w:r><w:proofErr w:type="spellStart"/><w:t>borrower</w:t><w:proofErr w:type="spellEnd"/></w:r><w:r><w:t>_name}}</w:t></w:r>
此时用字符串替换无法找到完整的 {{borrower_name}}。merge_runs.py 会检测这三个 run 是否格式相同(都是默认格式),若是则合并为一个:
<!-- 合并后:现在可以找到完整的占位符 --><w:r><w:t>{{borrower_name}}</w:t></w:r>
同时会删除 <w:proofErr> 元素(拼写检查标记)和 rsid 属性(修订 session ID),确保解包后的 XML 足够干净。
- 智能引号转义:将
\u201c``\u201d``\u2018``\u2019转为 XML 实体“等,防止编辑过程中丢失。
Step 2: 编辑 XML
SKILL.md 明确要求:
Use the Edit tool directly for string replacement. Do not write Python scripts.
原因是:Edit 工具的每次调用都会在用户界面上清晰地展示 diff,用户可以审查每一处改动。而如果 Claude 写一个 Python 脚本去改 XML,用户无法直观地看到到底改了什么。
Claude 的实际操作是调用 Edit 工具,指定 old_string(要找的文本)和 new_string(替换为什么)。以将"30 days"改为"60 days"并添加修订标记为例:
old_string: new_string:<w:r> <w:r> <w:rPr><w:b/></w:rPr> <w:rPr><w:b/></w:rPr> <w:t>The term is 30 days.</w:t> <w:t>The term is </w:t></w:r> </w:r> <w:del w:id="1" w:author="Claude" ...> <w:r> <w:rPr><w:b/></w:rPr> <w:delText>30</w:delText> </w:r> </w:del> <w:ins w:id="2" w:author="Claude" ...> <w:r> <w:rPr><w:b/></w:rPr> <w:t>60</w:t> </w:r> </w:ins> <w:r> <w:rPr><w:b/></w:rPr> <w:t xml:space="preserve"> days.</w:t> </w:r>
注意几个关键细节:
- • 把原来的 1 个 run 拆成了 4 个部分:不变前缀、删除标记、插入标记、不变后缀
- •
<w:del>内用<w:delText>而非<w:t> - • 每个新 run 都保留了原始的
<w:rPr><w:b/></w:rPr>(保持粗体格式) - •
" days."前有空格,加了xml:space="preserve" - • 模型只输出变更的部分,不是整个文件的内容
Step 3: 打包(pack.py)
python scripts/office/pack.py unpacked/ output.docx --original document.docx
打包内部做了三件事:
-
- 验证 + 自动修复:运行 DOCXSchemaValidator(11 项检查)和 RedliningValidator(修订完整性),如果验证失败则拒绝打包。"自动修复"是指验证器发现某些固定模式的、可无歧义纠正的错误时,不要求 Claude 手工修改,而是由 pack.py 直接在打包过程中纠正。目前支持两类:
自动修复能处理两类问题:
- 验证 + 自动修复:运行 DOCXSchemaValidator(11 项检查)和 RedliningValidator(修订完整性),如果验证失败则拒绝打包。"自动修复"是指验证器发现某些固定模式的、可无歧义纠正的错误时,不要求 Claude 手工修改,而是由 pack.py 直接在打包过程中纠正。目前支持两类:
- •
durableId >= 0x7FFFFFFF→ 随机生成合法的新值 - • 缺失的
xml:space="preserve"→ 自动添加
自动修复不能处理:格式错误的 XML、无效的元素嵌套、缺失的 Relationship、Schema 违规。这类问题需要 Claude 手工修改后重新打包。
4.3 读取与分析文档
这是最简单的能力,有三种方式。决策逻辑是:根据任务目标选择——需要快速看文本内容和修订情况用 pandoc,需要精确理解 XML 结构用 unpack,需要看排版效果用 soffice 转图片。
方式一:pandoc 提取文本(快速、面向内容)
pandoc --track-changes=all document.docx -o output.md
pandoc 会把修订标记转为 Markdown 格式的增删标注。适用场景:
- • 快速浏览文档内容和修订变化
- • 提取文本做分析(统计字数、关键词提取、内容总结)
- • 需要看修订了什么、由谁修订、什么时候修订
优势:快速、输出可读,不需要理解 XML。
劣势:无法看到精确的 XML 结构、排版信息丢失。
方式二:解包查看原始 XML(精确、面向结构)
python scripts/office/unpack.py document.docx unpacked/
然后直接读取 unpacked/word/document.xml,可以看到完整的 XML 结构。适用场景:
- • 需要精确编辑文档结构
- • 分析特定的格式化信息(字体、颜色、缩进等)
- • 调试文档问题、理解修订的确切 XML 形式
优势:精确、可看到所有细节、为后续编辑做准备。
劣势:XML 体积大、需要理解 XML 语法。
方式三:转为图片查看排版(可视、面向效果)
python scripts/office/soffice.py --headless --convert-to pdf document.docxpdftoppm -jpeg -r 150 document.pdf page
用 LibreOffice 无头模式转 PDF,再用 poppler 的 pdftoppm 转 JPEG。Claude 是多模态模型,可以直接查看图片判断排版效果。适用场景:
- • 需要直观查看最终排版效果
- • 检查是否有排版问题(页码错位、表格断裂、超大字体等)
- • 跨版本验证(同一文档在 Word、Google Docs、WPS 中的显示差异)
优势:直观、易于发现排版问题。
劣势:需要调用 LibreOffice,比较耗时。
完整决策流程:
任务类型 选择方法├─ 快速读内容 → pandoc(最快)├─ 定点编辑文档 → unpack(需要 XML)├─ 修订后生成最终版 → unpack + accept_changes.py├─ 查看排版效果 → soffice 转 PDF/图片└─ 追踪谁改了什么 → pandoc --track-changes=all
五、评论与修订功能深度解析
评论和修订是 Word 最重要的协作功能。在 Word 的"审阅"选项卡中,"新建批注"用于添加评论,"修订"用于跟踪文档更改。DOCX Skill 完整支持这两个功能。
5.1 评论功能(Word 审阅 > 新建批注)
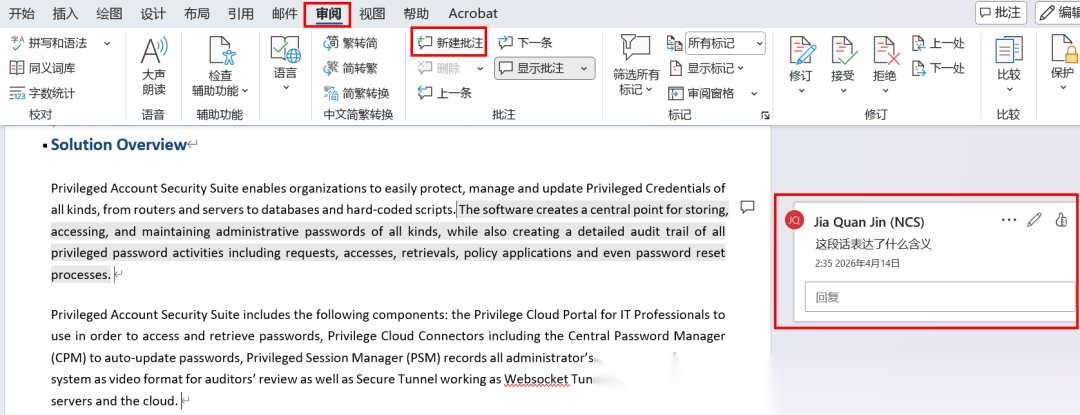
在 Word 中,点击"审阅 > 新建批注"会在文档侧边栏添加一条批注。这个看似简单的操作,在 OOXML 层面涉及 7 个文件的协调写入。
DOCX Skill 用 comment.py 脚本来自动化这个过程:
# 添加一条批注(ID=0)python scripts/comment.py unpacked/ 0 "这里需要修改措辞"# 添加回复(ID=1,父批注=0)python scripts/comment.py unpacked/ 1 "同意,建议改为..." --parent 0# 指定作者python scripts/comment.py unpacked/ 0 "批注内容" --author "张三"
comment.py 的完整执行流程:
1. 检查 word/comments.xml 是否存在 不存在 → 从 templates/ 复制骨架模板 → 在 document.xml.rels 中注册 4 个 Relationship → 在 [Content_Types].xml 中注册 4 个 Content Type2. 向 word/comments.xml 追加: <w:comment w:id="0" w:author="Claude" w:date="2025-07-01T00:00:00Z"> <w:p> <w:r><w:t>这里需要修改措辞</w:t></w:r> </w:p> </w:comment>3. 向 word/commentsExtended.xml 追加: <w15:commentEx w15:paraId="..." w15:done="0"/> (如果是回复,还有 w15:paraIdParent 指向父批注)4. 向 word/commentsIds.xml 追加: <w16cid:commentId w16cid:paraId="..." w16cid:durableId="..."/>5. 向 word/commentsExtensible.xml 追加: <w16cex:commentExtensible w16cex:durableId="..." w16cex:dateUtc="..."/>
运行完 comment.py 后,还需要在 document.xml 中手动(由 Claude 用 Edit 工具)插入批注标记:
<!-- 批注标记必须是 <w:p> 的直接子元素,绝不能放在 <w:r> 内部 --><w:commentRangeStart w:id="0"/><w:r><w:t>被批注的文本内容</w:t></w:r><w:commentRangeEnd w:id="0"/><w:r> <w:rPr><w:rStyle w:val="CommentReference"/></w:rPr> <w:commentReference w:id="0"/></w:r>
回复批注时,标记需要物理嵌套在父批注标记内部:
<w:commentRangeStart w:id="0"/> <!-- 父批注开始 --> <w:commentRangeStart w:id="1"/> <!-- 回复批注开始 --> <w:r><w:t>被批注的文本</w:t></w:r> <w:commentRangeEnd w:id="1"/> <!-- 回复批注结束 --><w:commentRangeEnd w:id="0"/> <!-- 父批注结束 --><w:r><w:rPr><w:rStyle w:val="CommentReference"/></w:rPr> <w:commentReference w:id="0"/></w:r><w:r><w:rPr><w:rStyle w:val="CommentReference"/></w:rPr> <w:commentReference w:id="1"/></w:r>
templates/ 目录下的 5 个 XML 骨架模板(comments.xml、commentsExtended.xml、commentsIds.xml、commentsExtensible.xml、people.xml)只包含根节点和完整的命名空间声明(涵盖 Word 2010-2024 所有扩展命名空间),确保生成的批注与任何版本的 Word 兼容。
5.2 修订功能(Word 审阅 > 修订)
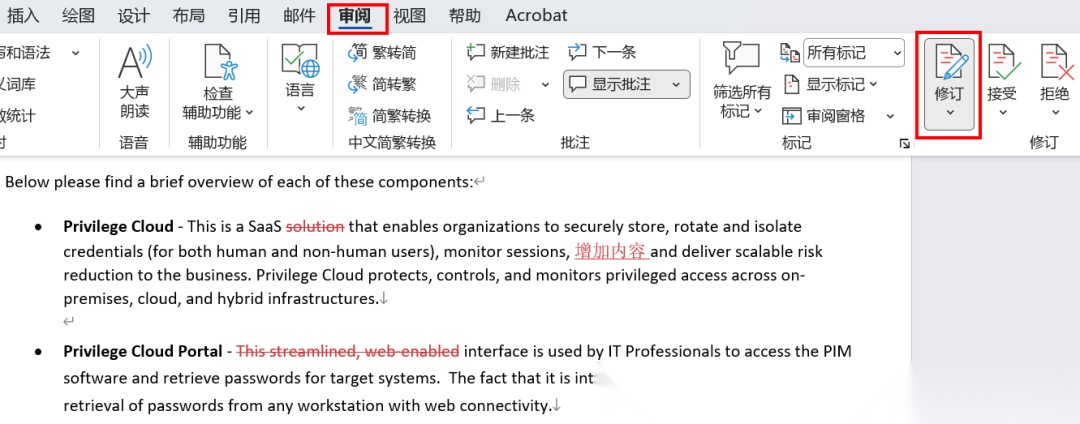
在 Word 中开启"审阅 > 修订"后,所有编辑操作都会被记录为插入和删除标记。在 OOXML 中,这对应两个核心元素:
插入(Insertion):
<w:ins w:id="1" w:author="Claude" w:date="2025-07-01T00:00:00Z"> <w:r><w:t>新插入的文本</w:t></w:r></w:ins>
删除(Deletion):
<w:del w:id="2" w:author="Claude" w:date="2025-07-01T00:00:00Z"> <w:r><w:delText>被删除的文本</w:delText></w:r></w:del>
关键规则:<w:del> 内部必须用 <w:delText> 而非 <w:t>,用 <w:delInstrText> 而非 <w:instrText>。这是 DOCX 验证器专门检查的一项。
最小编辑原则
SKILL.md 强调:只标记实际变化的部分,不要把整个段落包在修订标记里。以将"30 days"改为"60 days"为例:
<!-- 正确:只标记变化的部分 --><w:r><w:t>The term is </w:t></w:r><w:del w:id="1" w:author="Claude" w:date="..."> <w:r><w:delText>30</w:delText></w:r></w:del><w:ins w:id="2" w:author="Claude" w:date="..."> <w:r><w:t>60</w:t></w:r></w:ins><w:r><w:t> days.</w:t></w:r>
删除整段的特殊处理
当删除段落的全部内容时,还需要额外标记段落符号的删除,否则接受修订后会留下一个空段落:
<w:p> <w:pPr> <w:rPr> <!-- 标记段落符号本身被删除 --> <w:del w:id="1" w:author="Claude" w:date="2025-07-01T00:00:00Z"/> </w:rPr> </w:pPr> <w:del w:id="2" w:author="Claude" w:date="2025-07-01T00:00:00Z"> <w:r><w:delText>被删除的整段内容...</w:delText></w:r> </w:del></w:p>
多作者协作场景
SKILL.md 还规定了如何处理他人的修订:
拒绝另一位作者的插入——在其 <w:ins> 内部嵌套 <w:del>:
<w:ins w:author="Jane" w:id="5"> <w:del w:author="Claude" w:id="10"> <w:r><w:delText>Jane 插入的文本</w:delText></w:r> </w:del></w:ins>
恢复另一位作者的删除——在其 <w:del> 之后添加 <w:ins>(不修改原始删除标记):
<w:del w:author="Jane" w:id="5"> <w:r><w:delText>被 Jane 删除的文本</w:delText></w:r></w:del><w:ins w:author="Claude" w:id="10"> <w:r><w:t>被 Jane 删除的文本</w:t></w:r></w:ins>
接受所有修订
如果想从多轮修订的文档生成"最终版",有一个脚本可以调用:
python scripts/accept_changes.py input.docx output.docx
这个脚本调用 LibreOffice 的 StarBasic 宏来批量接受所有修订,输出一份干净的文档。
修订、评论关于脚本的使用:
- • 修订:由于
<w:ins>和<w:del>嵌套规则比较复杂,Claude 直接编辑 XML 即可(无需脚本)。accept_changes.py只是一个便利工具,如果用户要求"批量接受修订",就调用这个脚本而不是让 Claude 手工删除所有修订标记 - • 评论:由于涉及 4-7 个文件的协调,手工编辑容易出错,所以提供了
comment.py脚本来自动化
六、验证架构详解
验证系统是 DOCX Skill 的核心安全网。它的存在本身就说明了一个设计哲学:不试图让模型完美,而是构建足够强的防御来捕获模型的错误。
三层验证结构
┌─────────────────────────┐│ RedliningValidator ││ 修订完整性(文本对比) │└──────────┬──────────────┘ │┌──────────▼──────────────┐│ DOCXSchemaValidator ││ 5 项 DOCX 专用检查 ││ + 2 项自动修复 │└──────────┬──────────────┘ │ 继承┌──────────▼──────────────┐│ BaseSchemaValidator ││ 8 项通用检查 ││ + 1 项自动修复 ││ + 39 个 XSD Schema │└─────────────────────────┘
第一层:BaseSchemaValidator 负责通用检查——XML 格式正确性、命名空间声明、ID 唯一性、文件引用完整性、Content Types 声明、XSD Schema 合规性、Relationship ID 引用。这些是所有 Office 文档(DOCX、PPTX)共用的基础检查。
第二层:DOCXSchemaValidator 在基础检查之上增加 DOCX 特有的 5 项检查——空格保留属性、<w:del> 内的 <w:delText> 正确性、<w:ins> 内无误用的 <w:delText>、ID 范围约束、评论标记配对。
第三层:RedliningValidator 是最精妙的一层,专门用于修订完整性验证——确认 Claude 的所有编辑都被正确地用修订标记(<w:ins> / <w:del>)包裹了,没有"偷偷修改"原文。这在多作者协作场景(如法律文档审阅)中至关重要。
RedliningValidator 的算法原理:
修改后的 document.xml ──┐ ├──→ 各自去掉 Claude 的修订标记 ──→ 提取纯文本 ──→ 对比原始的 document.xml ────┘
具体步骤:
- 解析修改后和原始的
document.xml - 去掉 Claude 的修订标记:
- •
<w:ins w:author="Claude">→ 整个删除(含内容)→ 相当于没插入过 - •
<w:del w:author="Claude">→ 去掉包裹,把<w:delText>改回<w:t>→ 相当于没删除过
- 从两份文档中提取纯文本
- 对比:如果一致 → 所有变更都被正确跟踪;如果不一致 → 有未跟踪的修改
不一致时,验证器会调用 git diff --word-diff=plain 生成逐字差异报告,精确定位未被跟踪的修改位置。
验证在什么时候执行
- •
pack.py打包时自动执行(除非--validate false) - •
validate.py可独立执行用于调试 - • 验证失败时
pack.py拒绝生成文件,强制 Claude 修复后重试
增量校验策略
XSD 校验不是报告所有错误,而是:
修改后文档的 XSD 错误集合 - 原始文档的 XSD 错误集合 = 新增错误(只报告这些)
这避免了原始文档自身的历史问题阻断编辑流程。很多真实的 .docx 文件本身就存在轻微的 XSD 违规,增量策略确保只关注"Claude 新引入的问题"。
验证失败后模型怎么做
验证失败不是终点,而是一个反馈循环的起点。SKILL.md 要求 Claude 按以下流程处理:
pack.py 打包 → 验证失败 → 输出错误报告 │ ▼ Claude 阅读错误信息,定位问题 │ ▼ Claude 用 Edit 工具修改 XML │ ▼ 再次运行 pack.py → 验证通过 → 输出文件
具体来说:
- 可自动修复的错误(
xml:space缺失、durableId超限):pack.py 直接修好,不需要 Claude 介入 - Schema 违规(如无效的元素嵌套、缺少必需属性):Claude 阅读 XSD 校验报告,根据错误位置和描述,用 Edit 工具修改 XML,然后重新打包
- 修订完整性失败(RedliningValidator 报告有未跟踪的修改):Claude 查看
git diff输出,找到遗漏的位置,补上<w:ins>或<w:del>标记,然后重新打包 - XML 格式错误(标签未闭合、属性拼写错误等):Claude 定位错误行并修复
这种"生成 → 验证 → 修复 → 再验证"的循环,使得 Claude 不需要一次就写出完美的 XML——只要验证器足够强,模型就可以通过迭代收敛到正确结果。
七、使用场景与模型选择建议
7.1 适合使用 DOCX Skill 的场景
DOCX Skill 发挥最大价值的场景有几个共同特点:需要理解语义、生成内容、做灵活判断——这些正是 LLM 擅长的。
- • 从零创建复杂文档:报告、提案、合同——Claude 既能组织内容,又能正确设置格式
- • 带修订标记的编辑:法律审阅、编辑反馈——需要理解上下文来决定改什么
- • 添加审阅批注:对文档内容做点评、提建议
- • 分析文档内容:提取关键信息、总结修订变更
- • 格式转换:.doc → .docx、.docx → PDF
7.2 不适合使用的场景
- • 模板填充:如果任务是"把
{{borrower_name}}替换为张三",这是确定性的字符串替换,不需要 LLM 的理解能力。Python 脚本更可靠 - • 批量处理:每个文档的创建/编辑是一个多步交互过程,不适合大批量自动化
- • 纯格式调整:改字体大小、调页边距等——用 Word 或 python-docx 直接操作更高效
7.3 模型大小与能力要求
多大的模型能驾驭 DOCX Skill?
DOCX Skill 对模型能力有明确的要求:
- 上下文窗口:SKILL.md 有 590 行,加上解包后的 XML 内容、对话历史,20 多页文档的 XML 可能占用大量 token。建议至少 50K token 上下文
- 指令遵循能力:SKILL.md 中有 15 条 Critical Rules 和大量格式要求。模型必须严格遵循,不能"差不多就行"——一个错误的
<w:t>就能让文档损坏。Claude Opus/Sonnet 的指令遵循能力更强 - XML 编辑能力:模型需要精确地操作 XML 结构,保持标签配对、属性正确、命名空间完整。大模型的能力明显更好
DOCX Skill 是专门为 Claude 调试的吗?
不是。DOCX Skill 的整个架构都是通用的,包括 SKILL.md 本身。
先看工具链层:使用的都是标准的 Python 库(zipfile、xml.etree、defusedxml),遵循 ISO 标准,调用的是开源工具(pandoc、LibreOffice、poppler)。脚本和验证器是 100% 模型无关的,换任何模型都能直接使用。
再看 SKILL.md:它的核心内容是 OOXML 格式的通用知识——文件结构、编辑流程、XML 规范、命名空间规则。这些是客观的格式标准,不因模型而变。任何具备足够能力的模型,拿到同一份 SKILL.md 都能工作——这正是 Skill 架构"运行时注入"的核心优势:不需要为每个模型重新训练,一份提示词即可通用。
那么是否需要针对不同模型做调整?可以,但这是可选的性能优化,不是使用前提:
- 直接使用就能工作:SKILL.md 中的 15 条 Critical Rules 描述的是 OOXML 的客观约束(如
<w:del>必须用<w:delText>而不是<w:t>),任何模型都需要遵守,Claude 也不例外 - 优化可以提升效果:如果观察到某个模型经常犯特定类型的错误(比如忘记
xml:space="preserve"),可以在 SKILL.md 中把对应规则写得更突出、增加示例。这类似于给新员工的培训手册加几个重点标注——手册本身不需要重写 - Anthropic 的实践佐证:Anthropic 对不同代的 Claude 模型有略微调整的 SKILL 版本,但差异很小,主要是根据模型能力的提升精简了一些冗余说明
类比来说:同一本《交通规则》适用于所有驾驶员。新手可能需要在某些规则旁边加个"⚠️ 重点"标记,但不需要为每个驾驶员重写一本规则。SKILL.md 也是如此。
对于小模型(如 Qwen3.5 27B、Llama 70B)的实用建议:
不要直接使用完整的 DOCX Skill 流程。但可以复用工具链中的脚本,让确定性代码来处理格式操作:
import sysfrom pathlib import Path# 复用 skill 的 unpack/pack 脚本sys.path.insert(0, str(Path("skills/docx/scripts/office")))from unpack import unpackfrom pack import pack# 定义数据映射DATA = { "borrower_name": "张三", "loan_amount": "500,000", "loan_term": "36",}def xml_escape(text): """XML 特殊字符转义""" return text.replace("&", "&").replace("<", "<").replace(">", ">")# Step 1: 解包(merge_runs 会修复占位符碎片化)unpack("template.docx", "unpacked/", merge_runs=True, simplify_redlines=False)# Step 2: 批量替换for xml_file in Path("unpacked").rglob("*.xml"): content = xml_file.read_text(encoding="utf-8") for key, value in DATA.items(): content = content.replace(f"{{{{{key}}}}}", xml_escape(value)) xml_file.write_text(content, encoding="utf-8")# Step 3: 打包(自动验证 + 修复)pack("unpacked/", "output.docx", original_file="template.docx", validate=True)
核心原则:
LLM 负责:理解语义、提取信息、生成内容代码负责:格式操作、字符串替换、文件打包→ 把"AI 擅长的事"和"代码擅长的事"分开
如果小模型需要做比模板填充更复杂的 DOCX 操作(如根据内容决定插入什么表格),可以让模型只输出结构化数据(JSON),然后用 Python 代码根据 JSON 来操作 XML。这样模型不需要理解 OOXML,只需要理解业务逻辑。
八、总结:LLM 能力增强的一种工程范式
DOCX Skill 展示了一种务实的 AI 能力增强方案。它没有投入巨大成本去做专项训练或强化学习,而是用工程手段将一个"LLM 天然做不好的任务"分解为多个"LLM 能做好的子任务":
| 原始任务 | 转化后的子任务 | 谁来做 |
|---|---|---|
| 创建 .docx 文件 | 写 JavaScript 代码 | Claude(写代码是强项) |
| 编辑 .docx 文件 | 编辑 XML 文本 | Claude(文本操作是强项) |
| 确保格式正确 | XSD Schema 校验 | 验证系统(确定性检查) |
| 修复常见错误 | 自动修复规则 | Python 脚本 |
| 知道怎么写 | 参考手册 | SKILL.md(上下文注入) |
这个架构对 AI 应用开发者的启示是:
- 不要试图让模型完美——构建验证和防御系统,比投入训练成本更划算
- 工具链比微调更灵活——SKILL.md 可以随时更新,脚本可以随时修改,不需要重新训练模型
- 把不确定性隔离在最小范围——让模型只做它擅长的(理解语义、生成内容、编辑文本),把机械性的格式操作交给确定性代码
- 增量校验是关键设计——不追求"完美符合标准",而是确保"不比原始文档更差",大幅降低了实用门槛
这种"通用模型 + 领域提示词 + 工具链 + 验证系统"的范式,完全可以推广到 PDF、PPT、Excel 甚至更多格式的处理上。事实上,DOCX Skill 的验证器基类 BaseSchemaValidator 已经被 PPTX 验证器复用了。
在大模型能力不断增长的今天,围绕模型构建可靠的工程系统——而不是等模型自己变得可靠——可能是更务实的选择。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 8
8 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)