RAG系统的检索质量评估:从命中率到答案忠实度的量化方法
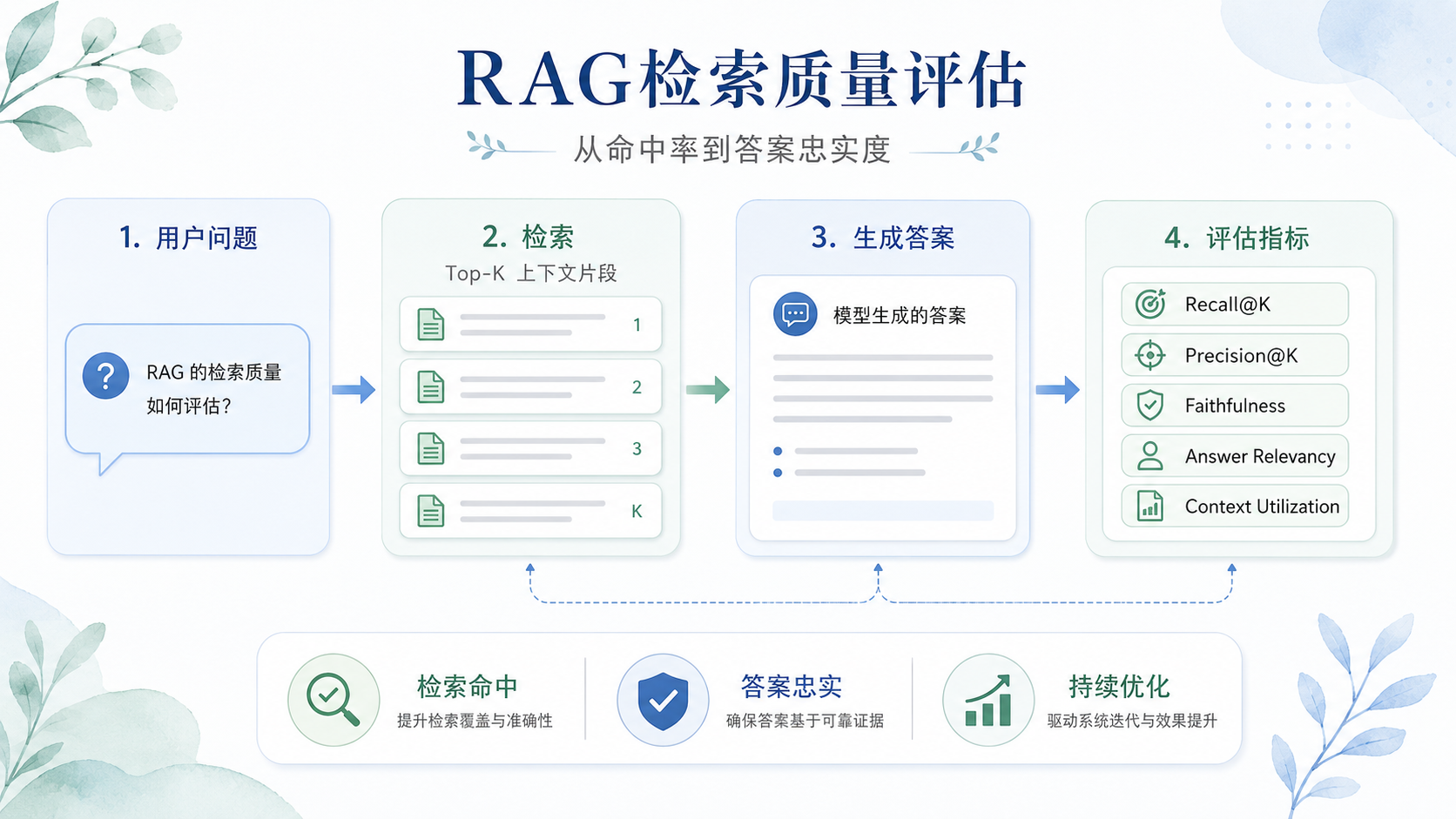
一、当"搜得对"不再等于"答得好"
检索增强生成(RAG)已成为大模型落地应用的主流范式:先从一个知识库或网络中检索相关文档片段,再交由语言模型整合成最终答案。但很多团队在搭建RAG系统的初期,会把评估重心几乎全部放在模型的生成质量上——答案是否流畅、是否像人写的。却不知,RAG系统有一条残酷的铁律:检索阶段的信息缺失或偏差,会在生成阶段被不可逆地放大。
换句话说,如果检索器拉回来的片段本来就不包含正确答案、或者混入了误导性内容,再强大的语言模型也巧妇难为无米之炊。因此,系统性地量化RAG的检索质量,并建立从检索到生成的全链路评估体系,是RAG工程中不可或缺的一环。
本文将拆解RAG检索质量评估的核心指标体系,从传统的排序度量到专为生成场景设计的忠实度与相关性评估,并给出可落地的评估框架与代码示例。
二、检索质量评估的第一层:经典排序指标
在RAG管线中,检索模块通常是一个向量搜索引擎或稀疏检索器(如BM25),它负责从海量文档库中返回Top-K个与查询最相关的片段。即使我们最终关心的是答案质量,也首先需要确保这些"原材料"本身是合格的。
1. 召回率(Recall@K)
衡量在Top-K个返回片段中,有多少个真正的相关文档被成功捞出。
公式:
对于需要多文档支撑的复杂问题(如"对比A和B的优缺点"),Recall@K至关重要。常用设定K=5到20。
2. 精确率(Precision@K)
衡量Top-K个片段中真正相关的比例。在RAG中,精确率的高低直接影响上下文中的噪声比例——噪声越多,模型越容易被干扰产生幻觉。
3. 平均倒数排名(MRR)
当存在多个相关文档时,关注第一个相关文档出现在第几位。
公式:
其中 rank_i 是第i个查询下第一个相关文档的排名。MRR特别适用于答案只位于单一文档中的事实型问题(如"谁是某某公司的CEO")。
4. 归一化折损累计增益(NDCG@K)
不仅考虑文档是否相关,还考虑相关程度的分级(如高度相关、部分相关、不相关)。RAG场景中,部分相关片段有时也能辅助模型推理,NDCG能更细腻地反映排序质量。
实现示例(Python)
这些指标早已用于搜索引擎评估,但它们存在两个明显局限:第一,它们只衡量"片段是否相关",无法判断"片段组合在一起是否足以生成正确答案";第二,它们需要人工标注的相关文档集合,而RAG的真实使用场景往往缺乏这样的标注。因此,我们需要第二层面向生成的评估。
三、从检索到生成的桥梁:答案忠实度与上下文利用度
经典排序指标关心的是"检索器是否找到了好东西",而生成式评估关心的则是"模型用这些好东西是否生成了正确且诚实的答案"。这一类评估通常不需要对检索结果本身做标注,而是利用大模型作为评判者来分析最终答案与检索上下文之间的关系。
1. 答案忠实度(Faithfulness)
这是RAG评估中最核心的指标之一,定义为:答案中的所有事实主张,是否都能在检索到的上下文片段集合中找到支持证据。
实现方法: 将生成的答案拆解为一组原子化的事实断言(claims),然后逐条让一个评估用LLM判断该断言是否能从给定的上下文片段集合中推导出来。
公式:
如果忠实度低,说明模型产生了幻觉——它"编造"了检索内容中没有的信息。这是检索质量不佳的直接信号:可能是因为检索漏掉了关键信息,导致模型不得不用参数化知识"脑补";也可能是检索到的片段噪声过高,诱使模型混合了不相关事实。
2. 答案相关性(Answer Relevancy)
答案不仅要忠实,还要切题。答案相关性衡量生成的回答与原始问题的语义匹配程度。
实现方法: 让评估LLM基于生成的答案,逆向生成若干可能的问题,然后计算这些生成的问题与原始问题之间的语义相似度(通常用词向量余弦相似度或专门的自然语言推理模型打分)。如果相似度低,意味着答案可能答非所问——这往往是因为检索器返回了大量与问题表层匹配但内涵偏离的片段,模型被"带偏"了。
3. 上下文利用度(Context Utilization)
这是一个更精细的指标,关注上下文片段是否被有效利用:在检索到的k个片段中,有多大比例真正被模型用于构建答案?
实现方法: 同样将答案拆分为主张,追溯每个主张对应的源片段;统计至少被一条主张引用的片段数,除以总检索片段数。这个指标揭示了检索结果的信息密度——如果检索器拉回了很多片段,但最终答案只参考了其中一小部分,说明可能存在重复或低价值片段,检索池需要优化。
四、实战评估:借助RAGAS框架
从头实现上述所有指标需要大量工程工作。开源框架RAGAS(Retrieval Augmented Generation Assessment)提供了开箱即用的评估工具链,是目前最流行的RAG评估利器。
快速上手:
RAGAS的几个实用特性:
- 上下文召回率和上下文精确率不需要人工标注的相关文档,而是使用参考答案(ground truth)作为代理——计算检索上下文中有多少语义成分覆盖了参考答案。
- 内置对OpenAI、Hugging Face、本地模型等多种评估后端的支持,你甚至可以用开源小模型(如Mistral-7B)来做裁判,降低使用成本。
- 支持自定义提示词和评估标准,方便适配垂直领域。
评估流程建议:
- 准备测试集:准备一个包含50-200条典型用户问题的测试集,并为每条问题准备至少一个参考答案(可由领域专家编写,或由现有文档中的相关段落充当)。
- 生成答案:配置你的RAG管线(检索器+大模型),对测试集生成答案。
- 计算指标:用RAGAS计算忠实度、答案相关性、上下文召回率和精确率。
- 诊断问题:根据指标短板诊断问题:
- 忠实度低 → 检查检索器是否遗漏关键信息或模型是否过度"脑补"
- 答案相关性低 → 检查查询改写和检索策略是否被表层词误导
- 上下文利用率低 → 精简索引库或增加多样性过滤
五、构建自定义评估流水线:精细化的诊断
预置指标虽方便,但某些垂直场景需要更精细的诊断。这里给出一个轻量级自定义评估流水线的设计。
步骤一:原子化拆解
使用一个小型、快速的LLM(如GPT-3.5或本地开源模型)将答案拆分为原子事实列表。
步骤二:证据匹配
对每个原子事实,遍历所有检索上下文片段,调用NLI(自然语言推理)模型判断"该片段是否蕴含这一事实"。可使用Hugging Face上的roberta-large-mnli等模型,输出entailment/neutral/contradiction。
步骤三:聚合统计
计算:
- Faithfulness = 标记为entailment的原子事实 / 总原子事实
- Hallucination Rate = 标记为contradiction或neutral的原子事实 / 总原子事实(其中contradiction代表与上下文直接冲突的幻觉,需重点关注)
步骤四:溯源与热点分析
对幻觉率高的原子事实做聚类,找出常出错的查询类型或文档类别,指导针对性优化。
六、局限与未来方向
当前RAG评估体系仍面临诸多挑战:
1. 评判者偏差
用大模型做裁判,本身可能引入系统性的评分偏好。研究表明,GPT-4作为评估器对自身生成的内容会打出偏高的忠实度分数。使用多模型交叉验证、或定期用人工标注校准,可缓解这一问题。
2. 细粒度评估缺失
大多数指标停留在答案级别,无法定位到"答案中第几句的哪个数字是胡编的"。未来的评估应走向token级或span级的精细定位,并结合归因技术直接高亮答案中的可疑片段。
3. 多跳推理和隐性知识评估困难
当正确答案需要跨多个片段进行多步推理时,即便每个片段单独看都相关,最终的忠实度也可能因为逻辑链断裂而变差。现有的评估方式对这类"组合推理"的覆盖仍然薄弱。
4. 线上评估闭环
离线测试集毕竟有限。真正的RAG系统需要建立线上监控——对真实用户查询进行抽样,同时记录检索结果、生成答案及用户后续行为(点赞/举报/追问),形成闭环的评估数据流。这是工程化落地的关键一步。
七、结语
RAG系统的质量不是"生成得好"这四个字能简单概括的。它是一条从检索精确性、上下文完整性,到答案忠实度与相关性的评价链条。把这个链条上的每个环节都量化、可视化和持续监控,才能将RAG从"看上去还行"变成"严格可靠的系统"。
对于正在实战RAG的工程师来说,接入RAGAS、部署自定义NLI流水线、建立测试集与线上指标看板,应当成为与代码开发同等优先级的工程任务。毕竟,在一个越来越大、越来越复杂的RAG Pipeline里,你无法优化你无法测量的东西。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)