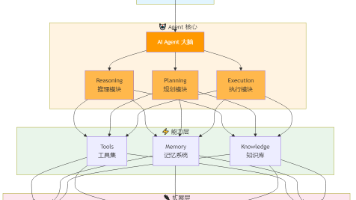
Hermes Agent 多 Agent / Subagent 实现分析
本文用场景解释 Hermes Agent 的多 agent 能力是怎么实现的,重点回答四个问题:
- 模型怎么知道什么时候创建 subagent?
- parent agent 把哪些上下文传给 child agent,哪些不会传?
- child agent 怎么运行、怎么隔离、怎么并发?
- child 的结果如何汇总回 parent,parent 又如何继续完成最终回答?
先给结论:
Hermes 的多 agent 不是一个独立调度中心。
它主要是一个普通 tool:delegate_task。
模型看到 delegate_task 的 tool description 后,
根据当前任务是否适合并行、是否会淹没上下文、是否需要推理重子任务,
决定是否调用 delegate_task。
delegate_task 在运行时创建一个或多个 child AIAgent。
每个 child 有自己的 system prompt、conversation、terminal session、toolset、iteration budget。
parent 不接收 child 的完整中间上下文,只接收 summary、status、tokens、tool_trace 等结构化结果。
所以它的核心数据流是:
用户提出复杂任务
↓
parent 模型看到 delegate_task tool schema
↓
模型语义判断:是否适合委托、拆成哪些子任务、给每个子任务什么 context/toolsets
↓
parent 发起 delegate_task tool call
↓
delegate_task 创建 child AIAgent
↓
child 在隔离上下文中执行自己的 tool loop
↓
delegate_task 收集 child final_response 和元数据
↓
结果以 JSON tool result 返回 parent
↓
parent 模型读取 JSON,综合多个 summary,形成最终回答;必要时再验证副作用
1. 场景:用户要求并行分析一个大项目
先看一个普通场景。
用户:帮我分析 Hermes 的安全机制、内存机制和 skills 机制。你可以并行看,最后给我一个整体架构总结。
这个请求天然可以拆成三个独立研究流:
子任务 A:安全机制
子任务 B:内存机制
子任务 C:skills 机制
模型为什么会想到使用 subagent?不是代码里写了 if 用户说并行 then delegate_task,而是模型在本轮请求中看到了 delegate_task 的 tool description。
1.1 模型看到的 delegate_task 工具描述
相关提示词 / Tool Description
英文原文:
Spawn one or more subagents to work on tasks in isolated contexts. Each subagent gets its own conversation, terminal session, and toolset. Only the final summary is returned -- intermediate tool results never enter your context window.
TWO MODES (one of 'goal' or 'tasks' is required):
1. Single task: provide 'goal' (+ optional context, toolsets)
2. Batch (parallel): provide 'tasks' array with up to delegation.max_concurrent_children items (default 3, configurable via config.yaml, no hard ceiling). All run concurrently and results are returned together. Nested delegation requires role='orchestrator' and delegation.max_spawn_depth >= 2.
WHEN TO USE delegate_task:
- Reasoning-heavy subtasks (debugging, code review, research synthesis)
- Tasks that would flood your context with intermediate data
- Parallel independent workstreams (research A and B simultaneously)
WHEN NOT TO USE (use these instead):
- Mechanical multi-step work with no reasoning needed -> use execute_code
- Single tool call -> just call the tool directly
- Tasks needing user interaction -> subagents cannot use clarify
- Durable long-running work that must outlive the current turn -> use cronjob (action='create') or terminal(background=True, notify_on_complete=True) instead. delegate_task runs SYNCHRONOUSLY inside the parent turn: if the parent is interrupted (user sends a new message, /stop, /new) the child is cancelled with status='interrupted' and its work is discarded. Children cannot continue in the background.
IMPORTANT:
- Subagents have NO memory of your conversation. Pass all relevant info (file paths, error messages, constraints) via the 'context' field.
- If the user is writing in a non-English language, or asked for output in a specific language / tone / style, say so in 'context' (e.g. "respond in Chinese", "return output in Japanese"). Otherwise subagents default to English and their summaries will contaminate your final reply with the wrong language.
- Subagent summaries are SELF-REPORTS, not verified facts. A subagent that claims "uploaded successfully" or "file written" may be wrong. For operations with external side-effects (HTTP POST/PUT, remote writes, file creation at shared paths, publishing), require the subagent to return a verifiable handle (URL, ID, absolute path, HTTP status) and verify it yourself — fetch the URL, stat the file, read back the content — before telling the user the operation succeeded.
- Leaf subagents (role='leaf', the default) CANNOT call: delegate_task, clarify, memory, send_message, execute_code.
- Orchestrator subagents (role='orchestrator') retain delegate_task so they can spawn their own workers, but still cannot use clarify, memory, send_message, or execute_code. Orchestrators are bounded by delegation.max_spawn_depth (default 2) and can be disabled globally via delegation.orchestrator_enabled=false.
- Each subagent gets its own terminal session (separate working directory and state).
- Results are always returned as an array, one entry per task.
中文对照:
生成一个或多个 subagents,在隔离上下文中工作。每个 subagent 都有自己的 conversation、terminal session 和 toolset。只有最终 summary 返回给你,中间工具结果不会进入你的上下文窗口。
两种模式(必须提供 goal 或 tasks 之一):
1. 单任务:提供 goal(可选 context、toolsets)。
2. 批量并行:提供 tasks 数组,数量上限由 delegation.max_concurrent_children 控制(默认 3,可在 config.yaml 配置,无硬编码上限)。所有任务并发运行并一起返回结果。嵌套 delegation 需要 role='orchestrator' 且 delegation.max_spawn_depth >= 2。
什么时候使用 delegate_task:
- 推理重的子任务,例如 debugging、code review、research synthesis。
- 会用中间数据淹没上下文的任务。
- 并行独立工作流,例如同时研究 A 和 B。
什么时候不要使用:
- 机械多步骤且无推理:用 execute_code。
- 单个工具调用:直接调用工具。
- 需要用户交互:subagents 不能使用 clarify。
- 需要跨当前 turn 存活的长期任务:用 cronjob(action='create') 或 terminal(background=True, notify_on_complete=True)。delegate_task 在 parent turn 中同步运行;如果 parent 被中断(用户发新消息、/stop、/new),child 会以 interrupted 状态取消,工作被丢弃。Child 不能后台继续。
重要:
- Subagents 没有你的对话记忆。必须通过 context 字段传入所有相关信息,例如文件路径、错误信息、约束。
- 如果用户使用非英语,或要求特定语言/语气/风格,要在 context 中说明,例如 "respond in Chinese"。否则 subagents 默认英文,它们的 summary 会用错误语言污染最终回复。
- Subagent summary 是自述,不是已验证事实。它说“上传成功”或“文件已写入”可能是错的。对有外部副作用的操作,例如 HTTP POST/PUT、远程写入、共享路径文件创建、发布,要求 subagent 返回可验证 handle(URL、ID、绝对路径、HTTP status),parent 自己验证后才能告诉用户成功。
- Leaf subagents(默认)不能调用 delegate_task、clarify、memory、send_message、execute_code。
- Orchestrator subagents 保留 delegate_task,可以生成自己的 workers,但仍不能使用 clarify、memory、send_message、execute_code。Orchestrator 受 delegation.max_spawn_depth 限制(默认 2),并可通过 delegation.orchestrator_enabled=false 全局禁用。
- 每个 subagent 有自己的 terminal session(独立工作目录和状态)。
- 结果总是数组,每个 task 一个 entry。
这段 tool description 是模型决策的主要来源。Hermes 没有额外注入一个“多 agent 总 system prompt”告诉模型必须委托;它把 delegate_task 暴露为工具,并在工具描述里写清楚适用/不适用场景。模型读到用户要求“并行看”“最后汇总”,结合 description 里的 “Parallel independent workstreams”,判断可以调用 delegate_task。
1.2 模型如何决定是否创建 subagent
可以把模型判断拆成五个语义问题:
1. 这个任务能不能拆成互不依赖的子任务?
2. 每个子任务是不是推理重、搜索重、代码阅读重?
3. 中间工具输出会不会污染 parent 的上下文?
4. 子任务是否不需要用户交互?
5. 子任务是否不需要跨当前 turn 持续运行?
如果答案大致是:
能拆。
每个子任务都需要读很多文件或做独立分析。
中间结果很大。
不需要问用户。
只需要在本轮内完成。
模型就适合调用 delegate_task。
反过来,如果只是:
用户:看一下 package.json 里版本是多少。
这就是单个工具调用,description 明确说 “Single tool call -> just call the tool directly”,模型不应该创建 subagent。
1.3 一次合理的 tool call 长什么样
对于上面的并行分析,模型可能发出:
{
"tasks": [
{
"goal": "Analyze Hermes security mechanisms and summarize the implementation design.",
"context": "Repo path: /home/tlinux/sdb/work/learn_ai/harness/hermes-agent. Focus on tools/approval.py, tools/terminal_tool.py, tools/url_safety.py, tools/file_tools.py. Respond in Chinese. Return file references and implementation flow, not a beginner tutorial.",
"toolsets": ["file", "terminal"],
"role": "leaf"
},
{
"goal": "Analyze Hermes memory system and summarize how memory is extracted, stored, retrieved, and injected.",
"context": "Repo path: /home/tlinux/sdb/work/learn_ai/harness/hermes-agent. Focus on memory-related prompts, tools, USER.md/MEMORY.md, session_search. Respond in Chinese.",
"toolsets": ["file", "terminal"],
"role": "leaf"
},
{
"goal": "Analyze Hermes skills evolution mechanism and summarize how skills are selected, loaded, created, updated, and guarded.",
"context": "Repo path: /home/tlinux/sdb/work/learn_ai/harness/hermes-agent. Focus on prompt_builder, skills_tool, skill_manager_tool, skills_guard. Respond in Chinese.",
"toolsets": ["file", "terminal"],
"role": "leaf"
}
]
}
这里最关键的是 context。因为 child 没有 parent 的完整聊天历史,如果 parent 不把“中文输出”“文档风格”“repo 路径”“重点文件”写进 context,child 就不会天然知道。
2. 场景:parent 把上下文传给 child
看一个容易出错的场景:
用户:继续按我们刚才 V6 文档的写法,分析多 agent。还是中文,prompt 和 tool description 要给中英文对照。
如果 parent 创建 subagent 时只写:
{
"goal": "Analyze multi-agent delegation"
}
child 不会知道“刚才 V6 文档的写法”是什么,也不会知道用户偏好“中文、场景化、prompt 就地展开、中英文对照”。这就是 Hermes 设计里反复强调的点:subagent 没有 parent conversation memory。
2.1 context 参数的工具描述
相关提示词 / Tool Schema
英文原文:
goal: What the subagent should accomplish. Be specific and self-contained -- the subagent knows nothing about your conversation history.
context: Background information the subagent needs: file paths, error messages, project structure, constraints. The more specific you are, the better the subagent performs.
toolsets: Toolsets to enable for this subagent. Default: inherits your enabled toolsets. Available toolsets: ... Common patterns: ['terminal', 'file'] for code work, ['web'] for research, ['browser'] for web interaction, ['terminal', 'file', 'web'] for full-stack tasks.
tasks: Batch mode: tasks to run in parallel (limit configurable via delegation.max_concurrent_children, default 3). Each gets its own subagent with isolated context and terminal session. When provided, top-level goal/context/toolsets are ignored.
中文对照:
goal:subagent 应完成什么。要具体、自包含,因为 subagent 不知道你的对话历史。
context:subagent 需要的背景信息,例如文件路径、错误信息、项目结构、约束。越具体,subagent 表现越好。
toolsets:为这个 subagent 启用哪些工具集。默认继承你的 enabled toolsets。常见模式:代码工作用 ['terminal', 'file'],研究用 ['web'],网页交互用 ['browser'],全栈任务用 ['terminal', 'file', 'web']。
tasks:批量模式,并行运行的 tasks(数量上限由 delegation.max_concurrent_children 控制,默认 3)。每个 task 都有自己的隔离上下文和 terminal session。提供 tasks 后,顶层 goal/context/toolsets 会被忽略。
这段 schema 直接告诉模型:child 的上下文不是自动共享的,parent 必须把必要信息显式写进 goal 和 context。
2.2 child-specific prompt:_build_child_system_prompt() 只是一层
delegate_task 创建 child 时,会先构造一段 focused subagent prompt。这个 prompt 很重要,但它不是 child 最终收到的完整 system prompt;它只是作为 ephemeral_system_prompt 追加到 child 的基础 AIAgent system prompt 后面。
先看这一层本身。对于默认的 leaf child,_build_child_system_prompt() 由这些内容组成:
固定 subagent 身份
↓
YOUR TASK: {goal}
↓
可选 CONTEXT: {context}
↓
可选 WORKSPACE PATH: {workspace_path}
↓
完成后 summary 格式要求
↓
不要猜 /workspace 路径的工作区规则
如果 parent 没有传 context,这一层就不会出现 CONTEXT: 块。如果 Hermes 没有解析出确定的本地工作区路径,也不会出现 WORKSPACE PATH: 块。
相关提示词 / Subagent System Prompt
英文原文:
You are a focused subagent working on a specific delegated task.
YOUR TASK:
{goal}
CONTEXT:
{context}
WORKSPACE PATH:
{workspace_path}
Use this exact path for local repository/workdir operations unless the task explicitly says otherwise.
Complete this task using the tools available to you. When finished, provide a clear, concise summary of:
- What you did
- What you found or accomplished
- Any files you created or modified
- Any issues encountered
Important workspace rule: Never assume a repository lives at /workspace/... or any other container-style path unless the task/context explicitly gives that path. If no exact local path is provided, discover it first before issuing git/workdir-specific commands.
Be thorough but concise -- your response is returned to the parent agent as a summary.
中文对照:
你是一个专注于特定委托任务的 subagent。
你的任务:
{goal}
上下文:
{context}
工作区路径:
{workspace_path}
除非任务明确另有说明,本地仓库/workdir 操作都使用这个精确路径。
使用你可用的工具完成任务。完成后给出清晰、简洁的 summary:
- 你做了什么
- 你发现或完成了什么
- 你创建或修改了哪些文件
- 遇到哪些问题
重要工作区规则:不要假设仓库位于 /workspace/... 或其他容器风格路径,除非任务/context 明确给出。如果没有精确本地路径,先发现路径,再发起 git/workdir 相关命令。
要 thorough 但 concise;你的回复会作为 summary 返回给 parent agent。
这段 prompt 的作用是约束 child 的局部工作方式:
- child 是 focused agent,不是完整复制 parent。
goal和context被写进 child-specific prompt。- workspace path 是运行时额外注入的提示,避免 child 乱猜
/workspace。 - child 最终产物不是给用户的完整文章,而是给 parent 的 summary。
- child 要报告做了什么、发现了什么、改了哪些文件、遇到什么问题,方便 parent 汇总。
如果 child 的角色是 orchestrator,这段 prompt 后面还会追加 “Subagent Spawning (Orchestrator Role)” 块,告诉它可以继续调用 delegate_task。这部分在第 5 节单独展开。
2.3 subagent 的完整输入由哪些部分组合
回到用户这个场景:
用户:继续按我们刚才 V6 文档的写法,分析多 agent。还是中文,prompt 和 tool description 要给中英文对照。
如果 parent 决定创建 child,child 模型真正看到的不是“只包含上面那段 focused prompt”。更准确地说,一次 child LLM call 的模型侧输入由三类内容组成:
1. system message
= child AIAgent 的基础 system prompt
+ "\n\n"
+ delegate_task 构造的 ephemeral child prompt
2. user message
= goal
3. tool schemas
= 根据 child_toolsets 加载出来的工具描述和参数 schema
如果 parent agent 配过 prefill_messages,这些 prefill messages 也会插到 system message 之后、conversation history 之前。普通 delegation 场景下,最需要理解的仍然是上面三块。
2.3.1 第一块:child AIAgent 的基础 system prompt
child 本质上还是一个新的 AIAgent 实例,所以它会先走 AIAgent._build_system_prompt()。代码注释里明确写了基础 prompt 的层级顺序。
相关提示词 / Runtime Prompt Assembly Comment
英文原文:
Layers (in order):
1. Agent identity — SOUL.md when available, else DEFAULT_AGENT_IDENTITY
2. User / gateway system prompt (if provided)
3. Persistent memory (frozen snapshot)
4. Skills guidance (if skills tools are loaded)
5. Context files (AGENTS.md, .cursorrules — SOUL.md excluded here when used as identity)
6. Current date & time (frozen at build time)
7. Platform-specific formatting hint
中文对照:
层级顺序:
1. Agent 身份:有 SOUL.md 时使用 SOUL.md,否则使用 DEFAULT_AGENT_IDENTITY
2. 用户 / gateway system prompt(如果提供)
3. 持久记忆(冻结快照)
4. Skills guidance(如果加载了 skills 工具)
5. Context files(AGENTS.md、.cursorrules;SOUL.md 作为身份使用时会从这里排除)
6. 当前日期和时间(构建 prompt 时冻结)
7. 平台特定格式提示
这段注释描述的是 AIAgent 通用 prompt 构造顺序。对 subagent 来说,还要结合 _build_child_agent() 传入的两个关键参数:
skip_context_files = True
skip_memory = True
因此 child 的基础 system prompt 不是 parent 的完整 prompt 副本:
AGENTS.md、.cursorrules等项目上下文文件不会自动注入,因为skip_context_files=True。- Hermes 内置的
USER.md/MEMORY.md记忆不会自动注入,因为skip_memory=True。 - 外部 memory provider 的 system prompt block 也不会按普通会话方式注入。
- 但 child 仍然会有 Hermes agent 的基础身份、工具使用约束、当前时间、环境提示、平台提示。
- 如果 child 的工具集中包含 skills 相关工具,它仍可能看到 skills guidance 和 available skills prompt;如果 child 没有 skills 工具,就不会注入这部分。
- 如果 child 是
orchestrator并保留了delegate_task,它会看到 delegation 工具 schema;如果是默认leaf,delegate_task会被剥离。
也就是说,skip_context_files=True 和 skip_memory=True 解决的是“不要把 parent 所在项目和长期记忆整包复制给 child”,不是让 child 变成没有任何系统提示的裸模型。
2.3.2 第二块:ephemeral child prompt 会在 API call 时追加
_build_child_system_prompt() 生成的 focused prompt 会作为 ephemeral_system_prompt 传给 child。
相关提示词 / AIAgent Constructor Description
英文原文:
ephemeral_system_prompt (str): System prompt used during agent execution but NOT saved to trajectories (optional)
中文对照:
ephemeral_system_prompt(字符串):agent 执行期间使用的 system prompt,但不会保存到 trajectories(可选)。
AIAgent._build_system_prompt() 里还有一条关键注释:
相关提示词 / Runtime Prompt Assembly Comment
英文原文:
Note: ephemeral_system_prompt is NOT included here. It's injected at
API-call time only so it stays out of the cached/stored system prompt.
中文对照:
注意:ephemeral_system_prompt 不包含在这里。它只会在 API call 时注入,
这样它就不会进入 cached/stored system prompt。
真正发请求前,Hermes 会把二者拼起来:
相关提示词 / Runtime Prompt Assembly
英文原文:
effective_system = self._cached_system_prompt or ""
if self.ephemeral_system_prompt:
effective_system = (effective_system + "\n\n" + self.ephemeral_system_prompt).strip()
if effective_system:
api_messages = [{"role": "system", "content": effective_system}] + api_messages
中文对照:
effective_system 先等于缓存的基础 system prompt。
如果存在 ephemeral_system_prompt,就把它用两个换行追加到基础 system prompt 后面。
如果最终 effective_system 非空,就作为 role=system 的消息放到 API messages 最前面。
所以 subagent 的完整 system prompt 可以理解成:
effective_system =
AIAgent._build_system_prompt()
+ "\n\n"
+ _build_child_system_prompt(goal, context, workspace_path, role, depth)
这个设计有两个目的:
- 基础
AIAgentprompt 保持稳定,可复用缓存,也可进入 session/system prompt 存储。 - 每个 child 的任务说明、context、workspace path 是临时的,只在 child 执行时生效,不污染长期轨迹。
2.3.3 第三块:goal 还会作为 child 的 user message 再发一次
child-specific prompt 里已经有 YOUR TASK: {goal},但 _run_single_child() 真正启动 child 时,还会把同一个 goal 作为本次对话的 user message。
相关实现说明 / Child Conversation Entry
英文原文:
return child.run_conversation(
user_message=goal,
task_id=child_task_id,
)
中文对照:
启动 child 对话时,把 goal 作为 user_message 传入,
同时使用 child_task_id 作为这次 child 执行的 task id。
这意味着 goal 在 child 输入中出现两次:
system prompt 里:
YOUR TASK:
Analyze multi-agent delegation...
user message 里:
Analyze multi-agent delegation...
这样做的实际效果是:即使不同 provider 对 system/user 的权重处理略有差异,child 的核心任务仍然会在普通用户消息里出现。context 则只来自 parent 写入的 context 参数和 child-specific prompt,不会自动从 parent 历史里补。
2.3.4 第四块:tool schema 不是 system prompt,但也是模型可见输入
很多误解来自这里:工具描述通常不在 system prompt 文本里,但模型请求会同时带上 tools schema。模型能不能调用 delegate_task、memory、terminal,主要取决于这次请求暴露了哪些工具 schema。
对 child 来说,工具 schema 来自 enabled_toolsets=child_toolsets。_build_child_agent() 里创建 child 的关键参数是:
enabled_toolsets = child_toolsets
quiet_mode = True
ephemeral_system_prompt = child_prompt
skip_context_files = True
skip_memory = True
clarify_callback = None
parent_session_id = parent.session_id
iteration_budget = None
中文解释:
child 只加载 child_toolsets 对应的工具;
它安静运行,不直接向用户输出;
child-specific prompt 作为 ephemeral_system_prompt 传入;
不自动加载项目 context files;
不自动加载 memory;
不能 clarify 问用户;
通过 parent_session_id 形成 session tree/tracing 关联;
使用新的 iteration budget,不消耗 parent 的同一个 iteration budget。
默认 leaf child 会从工具集中剥离这些能力:
delegate_task
clarify
memory
send_message
execute_code
所以 leaf child 的模型请求里通常没有这些工具 schema。模型不是“看到 prompt 说不能调用 memory 但工具还在”;更准确地说,runtime 在 toolset 层把它们移除了,模型根本不会拿到对应工具描述。orchestrator 是例外:它会重新保留 delegate_task,并看到第 5 节那段 orchestrator prompt。
2.3.5 用一个完整例子串起来
用户说:
用户:继续按刚才内存系统 V6 的写法,分析 Hermes 多 agent。中文输出,场景化组织,涉及 prompt 和 tool description 要中英文对照。
parent 如果要派 child,应该把历史偏好压缩进 context:
{
"goal": "Analyze Hermes multi-agent delegation implementation and explain how subagents are created, how context is passed, how results are aggregated, and how the model decides to delegate.",
"context": "Repo path: /home/tlinux/sdb/work/learn_ai/harness/hermes-agent. The user wants a Chinese implementation-analysis article for developers. Use scenario-first organization. Include relevant prompt/tool description excerpts inline with English original and Chinese translation. Explain behavior source: system prompt, tool schema, runtime parameters, or model semantic judgment. Do not compare versions.",
"toolsets": ["file", "terminal"],
"role": "leaf"
}
child 的完整模型输入会变成:
system:
Hermes/AIAgent 基础身份、工具使用约束、当前时间、环境提示等
+
You are a focused subagent working on a specific delegated task.
YOUR TASK:
Analyze Hermes multi-agent delegation implementation...
CONTEXT:
Repo path: ...
The user wants a Chinese implementation-analysis article...
WORKSPACE PATH:
/home/tlinux/sdb/work/learn_ai/harness/hermes-agent
...
user:
Analyze Hermes multi-agent delegation implementation...
tools:
file/terminal toolsets 对应的工具 schema
不包含 memory
不包含 clarify
不包含 delegate_task(因为 role=leaf)
child 执行后返回的是 summary,不是直接给用户的最终文章。parent 再读取这个 summary,结合自己当前对话上下文和用户偏好,写出最终回答或继续修改文档。
这就是 Hermes subagent prompt 设计里最核心的点:parent 的对话历史不会整包传给 child;完整输入靠 parent 在 goal/context 中显式重建,再由 runtime 加上基础 agent prompt 和工具 schema。
2.4 哪些上下文会传,哪些不会传
实际创建 child 的时候,Hermes 会新建 AIAgent(...),关键参数包括:
ephemeral_system_prompt = child_prompt
quiet_mode = True
enabled_toolsets = child_toolsets
skip_context_files = True
skip_memory = True
clarify_callback = None
parent_session_id = parent.session_id
iteration_budget = None
含义是:
| 内容 | 是否自动传给 child | 说明 |
|---|---|---|
| parent 的完整聊天历史 | 否 | child 不知道之前对话,必须靠 context |
| 用户本轮明确拆给 child 的 goal/context | 是 | goal 写入 child-specific prompt,并作为 user message;context 写入 child-specific prompt |
| 工作区路径 hint | 是 | 从 parent 的 cwd/terminal_cwd 等推断 |
| project context files | 否 | skip_context_files=True,避免重复/污染;需要时 parent 要写入 context |
| persistent memory | 否 | skip_memory=True,child 默认不注入 USER.md/MEMORY.md |
| clarify 能力 | 否 | clarify_callback=None,child 不能问用户 |
| parent toolsets | 部分继承 | child toolsets 与 parent toolsets 取交集 |
| parent provider/model/credential | 默认继承,可配置覆盖 | 可通过 delegation.provider/model/base_url/api_key 指定 child 模型 |
| parent fallback provider chain | 是 | child 可继承 fallback chain |
| parent session_id | 以 parent_session_id 关联 | 用于 session tree / tracing,不等于共享对话 |
| child tool schemas | 是 | 根据 child_toolsets 加载,并随模型请求发送;不是 system prompt 文本的一部分 |
这解释了为什么 context 的质量决定 subagent 质量。Hermes 并不会把 parent 当前上下文整体复制给 child,避免上下文爆炸,也避免 child 误读 parent 中间状态。
3. 场景:批量并行执行多个子任务
用户说:
用户:同时检查前端、后端、测试三个方向,最后告诉我风险。
模型如果调用:
{
"tasks": [
{"goal": "Review frontend changes", "context": "...", "toolsets": ["file", "terminal"]},
{"goal": "Review backend changes", "context": "...", "toolsets": ["file", "terminal"]},
{"goal": "Review tests", "context": "...", "toolsets": ["file", "terminal"]}
]
}
delegate_task 会走 batch 模式。
3.1 batch 模式如何创建 child agents
运行流程:
delegate_task 收到 tasks 数组
↓
读取 delegation.max_concurrent_children
↓
如果 tasks 数量超过上限,直接返回 tool_error
↓
在主线程构造所有 child AIAgent
↓
每个 child 得到自己的 child_prompt、toolsets、model、credential、progress callback
↓
如果只有 1 个任务,直接同步运行
↓
如果多个任务,用 ThreadPoolExecutor(max_workers=max_children) 并行运行
这里有两个限额:
单个 delegate_task 调用里的 tasks 数量不能超过 max_concurrent_children。
同一轮模型如果发出多个 delegate_task tool calls,run_agent 还会把超出的 delegate_task calls 截断到 max_concurrent_children。
parent 侧的截断逻辑在 AIAgent._cap_delegate_task_calls():
The delegate_tool caps the task list inside a single call, but the model can emit multiple separate delegate_task tool_calls in one turn. This truncates the excess, preserving all non-delegate calls.
中文解释:
delegate_tool 会限制单次调用里的 tasks 数组数量,但模型可能在同一轮响应里发出多个独立 delegate_task tool call。AIAgent 会截断多余的 delegate_task calls,同时保留其他非 delegate tool calls。
这样可以防止模型一次性生成过多 child,导致成本和并发失控。
3.2 并发执行时 parent 怎么不超时
child 运行可能很久。Hermes 在 _run_single_child() 里有 heartbeat 机制:
child 每隔一段时间把自己的 activity 触达 parent。
如果 child 在跑 tool,会显示当前 tool 和 iteration。
如果 child 没有进展,stale 计数累积。
超过 stale 阈值后停止 heartbeat,让 gateway timeout 可以正常触发。
这个机制解决 gateway 场景的问题:parent 一旦进入 delegate_task,自己的主循环看起来没有活动。如果没有 heartbeat,gateway 可能误判 parent idle,然后杀掉正在等待 child 的任务。
3.3 child 的超时和中断
每个 child 由独立 ThreadPoolExecutor(max_workers=1) 包起来,使用:
delegation:
child_timeout_seconds: 600
默认 600 秒,低于 30 秒会被提高到 30 秒。
如果 child timeout:
delegate_task 会 interrupt child。
如果 child 还没发出任何 API call,会写 diagnostic 到 ~/.hermes/logs/subagent-timeout-<sid>-<ts>.log。
返回 status=timeout,summary=None,error=...
如果 parent 被用户中断:
parent_agent.interrupt()
↓
遍历 self._active_children
↓
调用 child.interrupt(message)
↓
delegate_task 收集已完成 child;未完成 child 返回 interrupted entry
这说明 delegate_task 是同步工具调用,不是后台任务。父 turn 被中断,child 不会继续作为长期任务运行。
4. 场景:控制 child 能用哪些工具
用户要求:
用户:开一个子任务查网页资料,另一个子任务只读本地文件,不要让它访问网络。
模型可以给不同 task 设置不同 toolsets:
{
"tasks": [
{
"goal": "Search current docs on the web",
"context": "Find official docs only. Respond in Chinese.",
"toolsets": ["web"]
},
{
"goal": "Inspect local implementation",
"context": "Repo path: ... Use local source only. Respond in Chinese.",
"toolsets": ["file", "terminal"]
}
]
}
4.1 toolset 不是任意授权,而是和 parent 取交集
child toolsets 的计算逻辑是:
如果 parent 有 enabled_toolsets:
parent_toolsets = parent.enabled_toolsets
否则:
从 parent.valid_tool_names 反推出 parent_toolsets
如果模型显式传了 child toolsets:
child_toolsets = child toolsets ∩ parent_toolsets
否则:
child_toolsets = parent toolsets
再调用 _strip_blocked_tools(child_toolsets)
这意味着:
child 不能获得 parent 没有的工具。
模型不能通过 toolsets=["web"] 给 child 开启 parent 当前没有的 web 能力。
4.2 leaf 默认不能再 delegate
delegate_task 有两类角色:
leaf:默认,专注执行,不能再创建 subagent。
orchestrator:可以继续调用 delegate_task,但受 depth 限制。
Leaf 被剥离的工具包括:
delegate_task
clarify
memory
send_message
execute_code
含义:
- child 不能问用户,避免并行子线程等待交互。
- child 不能写 memory,避免子任务把未验证结论写成长记忆。
- child 不能 send_message,避免绕过 parent 对最终输出的控制。
- child 不能 execute_code,避免在子 agent 内再开编程式 tool loop。
- child 默认不能递归 delegate,避免失控 fan-out。
4.3 MCP toolsets 的保留
配置里有一个细节:
delegation:
inherit_mcp_toolsets: true
当 parent 已启用 MCP toolsets,而模型显式缩窄 child toolsets 时,Hermes 默认仍保留 parent 的 MCP toolsets。设计意图是:
toolsets=["web","browser"] 表达的是“我想要这些能力”,
不应该意外把 parent 已经启用的 MCP 工具全剔除。
如果想严格交集,可以设置:
delegation:
inherit_mcp_toolsets: false
5. 场景:让 subagent 再拆分任务
默认情况下,Hermes 是扁平 delegation:
parent -> leaf child
如果用户或模型想让 child 继续拆分:
用户:让一个 planner subagent 先拆任务,再让它开 worker 并行查不同模块。
需要两个条件:
role="orchestrator"
delegation.max_spawn_depth >= 2
5.1 orchestrator child 看到的额外 prompt
当 child 的有效角色是 orchestrator 时,_build_child_system_prompt() 会追加一段能力说明。
相关提示词 / Subagent Orchestrator Prompt
英文原文:
## Subagent Spawning (Orchestrator Role)
You have access to the `delegate_task` tool and CAN spawn your own subagents to parallelize independent work.
WHEN to delegate:
- The goal decomposes into 2+ independent subtasks that can run in parallel (e.g. research A and B simultaneously).
- A subtask is reasoning-heavy and would flood your context with intermediate data.
WHEN NOT to delegate:
- Single-step mechanical work — do it directly.
- Trivial tasks you can execute in one or two tool calls.
- Re-delegating your entire assigned goal to one worker (that's just pass-through with no value added).
Coordinate your workers' results and synthesize them before reporting back to your parent. You are responsible for the final summary, not your workers.
NOTE: You are at depth {child_depth}. The delegation tree is capped at max_spawn_depth={max_spawn_depth}. {child_note}
中文对照:
## Subagent 生成(Orchestrator 角色)
你可以访问 `delegate_task` 工具,并且可以生成自己的 subagents 来并行处理独立工作。
什么时候委托:
- 目标能拆成 2 个以上可并行的独立子任务,例如同时研究 A 和 B。
- 某个子任务推理重,并且会用中间数据淹没你的上下文。
什么时候不要委托:
- 单步机械工作,直接做。
- 一两个 tool calls 就能完成的小任务。
- 把整个分配给你的目标重新丢给一个 worker,这只是透传,没有增值。
你要协调 workers 的结果,并在报告给 parent 前自己综合。你负责最终 summary,不是你的 workers。
注意:你位于 depth {child_depth}。delegation tree 限制在 max_spawn_depth={max_spawn_depth}。{child_note}
这段 prompt 的作用是让 orchestrator child 明确:它可以继续 delegate_task,但不能把自己整个任务原样转交给 worker,必须做拆分和综合。
5.2 max_spawn_depth 如何限制树深度
配置:
delegation:
max_spawn_depth: 1
orchestrator_enabled: true
语义:
depth 0 = parent agent
max_spawn_depth = N 表示 depth 0..N-1 的 agent 可以 spawn
depth N 是 leaf floor
默认 max_spawn_depth=1:
parent(depth 0) 可以 spawn child(depth 1)
child(depth 1) 不能再 spawn
如果设为 2:
parent(depth 0) 可以 spawn orchestrator child(depth 1)
orchestrator child(depth 1) 可以 spawn leaf worker(depth 2)
worker(depth 2) 不能再 spawn
代码会把配置 clamp 到 [1, 3]。如果 orchestrator_enabled=false,即使模型传 role="orchestrator",也会降级为 leaf。
6. 场景:child 执行完成后,结果怎么汇总
用户问:
用户:三个方向都查完后,最后给我一个整合结论,不要把每个子任务的流水账都贴出来。
这正是 Hermes 的默认结果模型:child 的中间工具结果不会进入 parent 上下文,parent 只收到每个 child 的最终 summary 和元数据。
6.1 child 运行结束后提取哪些信息
_run_single_child() 调用:
child.run_conversation(user_message=goal, task_id=child_task_id)
child 返回后,delegate tool 取:
summary = result.get("final_response") or ""
completed = result.get("completed", False)
interrupted = result.get("interrupted", False)
api_calls = result.get("api_calls", 0)
messages = result.get("messages") or []
然后构造 entry:
{
"task_index": 0,
"status": "completed",
"summary": "子任务最终总结...",
"api_calls": 7,
"duration_seconds": 42.31,
"model": "模型名",
"exit_reason": "completed",
"tokens": {
"input": 12345,
"output": 678
},
"tool_trace": [
{
"tool": "read_file",
"args_bytes": 128,
"result_bytes": 4096,
"status": "ok"
}
]
}
如果失败或超时,会是:
{
"task_index": 1,
"status": "timeout",
"summary": null,
"error": "Subagent timed out after 600s ...",
"exit_reason": "timeout",
"api_calls": 0,
"duration_seconds": 600.0,
"diagnostic_path": "~/.hermes/logs/subagent-timeout-..."
}
6.2 tool_trace 是什么,不是什么
tool_trace 不是完整工具输出。它只是从 child messages 里提取的工具调用摘要:
tool 名称
参数字符串长度 args_bytes
结果字符串长度 result_bytes
结果状态 ok/error
这样 parent 能知道 child 做过什么,但不会把 child 读过的大文件、网页、终端输出全部灌进 parent 上下文。
如果 TUI/overlay 需要更细观察,delegate tool 还会为 UI 事件准备 output_tail:
最多取最近 N 个 tool result
每个预览限制字符数
用于 overlay 的 Output 区域
但返回给模型的主要结果仍是 summary + metadata。
6.3 多个 child 的汇总结构
单个 delegate_task 的最终 tool result 是 JSON:
{
"results": [
{
"task_index": 0,
"status": "completed",
"summary": "...",
"api_calls": 4,
"duration_seconds": 18.4,
"model": "...",
"exit_reason": "completed",
"tokens": {"input": 1000, "output": 200},
"tool_trace": []
},
{
"task_index": 1,
"status": "completed",
"summary": "...",
"api_calls": 6,
"duration_seconds": 25.7,
"model": "...",
"exit_reason": "completed",
"tokens": {"input": 2200, "output": 300},
"tool_trace": []
}
],
"total_duration_seconds": 26.2
}
注意结果会按 task_index 排序,所以 parent 看到的顺序和输入 tasks 顺序一致,不会因为并发完成顺序而乱掉。
6.4 parent 如何形成最终回答
这里没有单独的“汇总器模型”。汇总仍然由 parent agent 的下一轮模型完成:
delegate_task 返回 JSON tool result
↓
tool result 被加入 parent messages
↓
parent 模型继续下一轮推理
↓
它读取 results 数组里的 summary/status/error
↓
综合成最终回答;如果某个 summary 声称有副作用成功,parent 应自行验证
所以 Hermes 的多 agent 汇总是:
child 负责局部总结。
delegate_tool 负责结构化收集。
parent 模型负责语义综合和最终输出。
6.5 子任务结果会通知 memory provider,但不是 child 自己写 memory
delegate_task 汇总后,如果 parent 有 _memory_manager,会调用:
parent_agent._memory_manager.on_delegation(
task=子任务 goal,
result=entry.summary,
child_session_id=child.session_id
)
这表示外部 memory provider 可以观察 delegation 结果。但 child 本身默认 skip_memory=True,leaf 也不能调用 memory,所以不是 child 自己把东西写进长期记忆。
这个设计降低了“子任务把未验证中间结论持久化”的风险。
7. 场景:subagent 修改了 parent 读过的文件
看一个容易出 bug 的协作场景:
parent 先读了 src/config.py。
parent 让 subagent 去修复配置加载问题。
subagent 修改了 src/config.py。
parent 继续基于旧 read_file 结果编辑 src/config.py。
如果没有协调,parent 可能用旧内容覆盖 child 修改。
Hermes 用 file_state 做跨 agent 文件状态提醒:
parent 运行 tool 前设置 _current_task_id。
child 使用自己的 stable subagent_id 作为 task_id。
child 写文件后 file_state 记录写入。
_run_single_child 在结束时检查:
parent 之前读过哪些路径?
child 或兄弟任务是否在 child 运行期间写过这些路径?
如果有,把提醒追加到 child summary。
追加内容类似:
[NOTE: subagent modified files the parent previously read — re-read before editing: src/config.py]
这不是自动 merge,也不是冲突解决器。它的作用是把“parent 的局部上下文可能过期”暴露给 parent 模型,让 parent 在继续编辑前重新读取文件。
8. 场景:subagent 要执行危险命令
用户说:
用户:让子任务清理所有旧构建目录。
child 可能调用 terminal("rm -rf ...")。这里有一个特殊问题:child 在 worker thread 中运行,如果它触发危险命令审批,不能直接 input() 等用户,否则会和 parent TUI 争 stdin,造成死锁。
Hermes 的做法是给 subagent worker thread 安装非交互 approval callback。
相关实现说明 / Runtime Constraint
英文原文:
Fix: install a non-interactive callback into every subagent worker thread
via ThreadPoolExecutor(initializer=_set_subagent_approval_cb, initargs=(cb,)).
The callback is chosen by the `delegation.subagent_auto_approve` config:
false (default) → _subagent_auto_deny (safe; matches leaf tool blocklist)
true → _subagent_auto_approve (opt-in YOLO for cron/batch)
Both emit a logger.warning for audit; gateway sessions are unaffected
because they resolve approvals via tools/approval.py's per-session queue,
not through these TLS callbacks.
中文对照:
修复方式:给每个 subagent worker thread 安装一个非交互 callback,
通过 ThreadPoolExecutor(initializer=_set_subagent_approval_cb, initargs=(cb,))。
callback 由 `delegation.subagent_auto_approve` 配置决定:
false(默认)→ _subagent_auto_deny(安全;匹配 leaf tool blocklist)
true → _subagent_auto_approve(为 cron/batch 提供 opt-in YOLO)
两者都会写 logger.warning 作为审计;gateway sessions 不受影响,
因为它们通过 tools/approval.py 的 per-session queue 处理审批,
不是通过这些线程本地 callback。
默认配置:
delegation:
subagent_auto_approve: false
含义:
child 遇到 dangerous command,默认自动 deny。
如果用户明确把 subagent_auto_approve 设为 true,child 才会自动 approve once。
hardline block 仍不能绕过。
9. 场景:给 subagent 使用不同模型或 provider
多 agent 的一个常见工程需求是:
parent 用强模型做规划和最终综合。
child 用便宜/快模型做并行搜索或代码阅读。
Hermes 支持在配置里覆盖 delegation provider/model。
delegation:
model: "google/gemini-3-flash-preview"
provider: "openrouter"
base_url: ""
api_key: ""
reasoning_effort: ""
实现逻辑:
如果 delegation.provider/model/base_url/api_key 未配置:
child 默认继承 parent 的 provider/model/credential。
如果配置了 delegation.provider:
通过运行时 provider 系统解析 child credential bundle。
child 使用 direct API,不继承 parent ACP transport。
如果配置了 acp_command:
child 使用 ACP subprocess transport,例如 claude --acp --stdio。
这意味着 Hermes 的 subagent 不是只能复制 parent 模型。它可以作为“低成本并行 worker”运行,也可以桥接到 Claude Code、Codex ACP 类工具。
但注意:模型/provider 变了,不等于权限变大。child toolsets 仍然受 parent toolsets 交集、blocked tools、role/depth 限制。
10. 场景:模型错误地创建太多 subagents
用户可能只要求一个简单任务,但模型过度调用:
delegate_task(...)
delegate_task(...)
delegate_task(...)
delegate_task(...)
Hermes 有两层治理:
10.1 单个 delegate_task 调用内的 tasks 上限
delegate_task() 内部读取:
delegation:
max_concurrent_children: 3
如果 tasks 数量超过上限,直接返回错误:
Too many tasks: {len(tasks)} provided, but max_concurrent_children is {max_children}. Either reduce the task count, split into multiple delegate_task calls, or increase delegation.max_concurrent_children in config.yaml.
中文含义:
任务太多:提供了 {len(tasks)} 个,但 max_concurrent_children 是 {max_children}。请减少任务数量、拆成多个 delegate_task 调用,或提高 config.yaml 中的 delegation.max_concurrent_children。
10.2 同一轮多个 delegate_task tool calls 截断
run_agent.py 的 _cap_delegate_task_calls() 会统计同一轮模型响应里的 delegate_task 数量。如果超过 max_concurrent_children,只保留前 N 个 delegate calls,非 delegate calls 保留。
这解决的是模型不是用一个 tasks 数组,而是发出多个独立 delegate_task tool calls 的情况。
10.3 高并发成本提示
_get_max_concurrent_children() 允许用户把并发调高,但如果超过 10,会 warning:
delegation.max_concurrent_children={n}: each child consumes API tokens independently. High values multiply cost linearly.
中文含义:
每个 child 都独立消耗 API tokens。高并发会线性放大成本。
11. 管理和扩展:多 agent 的可调参数
常见配置:
delegation:
model: "" # 空表示继承 parent model
provider: "" # 空表示继承 parent provider + credentials
base_url: "" # subagents 的 OpenAI-compatible endpoint
api_key: "" # delegation.base_url 的 API key,默认可回退 OPENAI_API_KEY
inherit_mcp_toolsets: true
max_iterations: 50 # 每个 subagent 独立上限
child_timeout_seconds: 600
reasoning_effort: "" # 空表示继承 parent reasoning level
max_concurrent_children: 3
max_spawn_depth: 1
orchestrator_enabled: true
subagent_auto_approve: false
每个参数对应的工程含义:
| 参数 | 控制什么 | 风险 |
|---|---|---|
model/provider/base_url/api_key |
child 用哪个模型/端点 | 便宜模型可能质量不足;外部 provider 有数据边界 |
inherit_mcp_toolsets |
缩窄 toolsets 时是否保留 MCP | true 更方便,false 更严格 |
max_iterations |
每个 child 的 tool loop 上限 | 太小会半途停,太大成本高 |
child_timeout_seconds |
child 最大运行时间 | 太小误杀慢任务,太大阻塞 parent |
reasoning_effort |
child reasoning 强度 | 高 reasoning 成本高 |
max_concurrent_children |
并行 child 数 | 高值线性放大 token 和并发压力 |
max_spawn_depth |
delegation 树深度 | 高值增加 fan-out 风险 |
orchestrator_enabled |
是否允许 orchestrator role | 打开后需要更强治理 |
subagent_auto_approve |
child 危险命令是否自动批准 | true 是高风险自动化 |
12. 这套多 agent 设计的边界
Hermes 的 multi-agent delegation 很实用,但边界要清楚:
它适合并行独立子任务、推理重任务、会污染上下文的研究任务。
它不适合单步工具调用、机械批处理、需要用户交互的任务、需要跨 turn 存活的长期任务。
几个关键边界:
- child 没有 parent 完整对话历史,context 写不好,child 就会做偏。
- child summary 是 self-report,不是事实证明;有副作用要 parent 验证。
- child 中间工具输出不会进入 parent 上下文,这节省 token,但也意味着 parent 看不到全部证据。
- child 默认不能写 memory、不能 clarify、不能 send_message,降低风险但也限制能力。
- 并发不是免费:每个 child 独立消耗 tokens、API calls、工具资源。
- 默认
max_spawn_depth=1是扁平多 agent;真正树状 orchestrator 需要显式配置。 - subagent 修改文件后只提醒 parent re-read,不自动做冲突 merge。
delegate_task是同步工具,不是后台 job;需要长期运行应使用cronjob或terminal(background=True, notify_on_complete=True)。
最终可以把 Hermes 的多 agent 机制概括成一句话:
模型通过 delegate_task 的工具描述决定是否拆任务;
parent 只把必要 goal/context/toolsets 交给 child;
runtime 创建隔离的 child AIAgent 并并行执行;
child 只把 summary 和元数据返回;
parent 再做最终综合和必要验证。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)