面试官:“Fable 5 一天干完两个月代码迁移,你怎么看?” 我:“长任务 Agent 开始能交付了。” 面试官:“那项目里怎么验收?”
跑完不等于交付
事情是这样的。
Anthropic 发了 Claude Fable 5。
别的跑分鸭鸭先放一边,最扎眼的是 Stripe 那个案例。
一个 5000 万行 Ruby 代码库迁移。
正常工程团队做,估两个月。
Fable 5 一天跑完。
看到这个数字,第一反应肯定是,太猛了。
两个月变一天。
老板眼睛会亮,工程师大概率会先沉默几秒。
因为干过老项目迁移的人都知道,迁移最烦的地方,往往不是把 A 写法改成 B 写法。
麻烦在那些没人敢动的地方。
一个老接口没人认领,偏偏还有客户在调。
一个脚本十年没人碰,结果每个月底还在跑账。
这种东西,你让 Agent 自己猜,它大概率猜不全。
所以鸭鸭看到 Fable 5 这个新闻,脑子里冒出来的不是程序员还要不要写代码。
那个问题太旧了。
鸭鸭更想问的是,AI 一天跑完之后,谁敢签字说它交付了。
以前 AI Coding 更像一个很快的助手。
你让它补个函数,改个报错。答得好,你夸一句;答错了,删掉重来。
损失还在你手边。
Fable 5 这种长任务 Agent 往前走一步,味道就不一样了。
它开始像一个能接活的外部团队。
你把任务包给它,它自己读上下文,改文件,跑测试,再把结果交回来。
听起来很爽。
但只要它开始接活,麻烦也跟着来了。你得提前想清楚一件事,结果交回来以后,谁敢接这个锅。
说真的,这就不是单纯的模型能力了。
以前买 AI,很多公司像买会员。一个月多少钱,开几个账号,大家随便用。到底省了多少时间,很多时候靠感觉。
长任务 Agent 起来以后,这个账会越来越难糊弄。
一次迁移跑了多少 Token,中间返工几次,最后有多少改动真的进了主干,这些东西都会被拿出来问。
老板不一定懂上下文窗口。
但老板听得懂两句话,花了多少钱,交回来的是不是能上线。
这才是 Fable 5 给职场带来的变化。
它会把一部分程序员往更像甲方项目经理的位置推。
以前你自己下场改,以后你要把活说清楚,还得看得懂交回来的东西。
为什么这次能合,为什么那次不能合,你得讲得出来。
这事听起来没那么酷,但很值钱。
因为很多公司现在不缺会点 Claude 的人。
会点 Claude 的人太多了。
缺的是能把 Claude 放进真实流程里,还能让业务和老板都听明白的人。
鸭鸭想到一个很土的场景,老房子改水电。
装修队说一天能干完,你当然开心,但你不会当天就搬进去。
墙封上之前,水电走线得拍照。
不然后面柜子装完、瓷砖贴完,再发现水管走错了,返工贵到想骂人。
这和信不信装修队没关系。
长任务 Agent 也是一样。
它干得越快,你越不能只看终点那个绿色通过。
中间如果没留下证据,交付时就会变成一句很尴尬的话。
它说跑完了。
然后呢?
面试官问到这题,别从参数开始背。
鸭鸭会先说,长任务 Agent 进项目,别急着让它撒开跑。
先给它划线。
至少把能改的目录和不能碰的接口写进任务说明里。
线没画清楚,Agent 跑得越快,后面越难收拾。
然后留证据。
真实项目里,大家不会只问你有没有用 Claude。
大家会问,你当时凭什么相信这个结果。
所以关键 diff 和测试结果要留得下来。
失败重试也别只留在聊天窗口里。
最后才是验收。
编译和单测只能说明眼前没炸。代码迁移这种活,还得补一轮回归,关键模块让人看一眼。
如果涉及核心链路,灰度和回滚也要提前讲。
面试官听到这里,问题就会往交付上走。简历里也别写得太轻。
写“接入 Claude,提升开发效率”,看着没错,但没法追问。
简历可以写成这样:
基于 Claude Code / Agent 设计代码迁移辅助流程,将迁移任务拆成可验收阶段,限制 Agent 可修改范围,记录关键 diff、测试结果和失败重试,并在合并前完成编译、单测和人工 review。
这句话不花哨,但它能接住追问。
面试官继续问权限和成本,你还能往下聊。
这些都准备过,面试里就不会只剩一句我会用 Claude。
跑得快是工具能力,敢不敢合并,才是项目经验。
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
【当需要处理超长大模型上下文窗口限制时,有哪些可行的工程解决方案? 】
回答重点
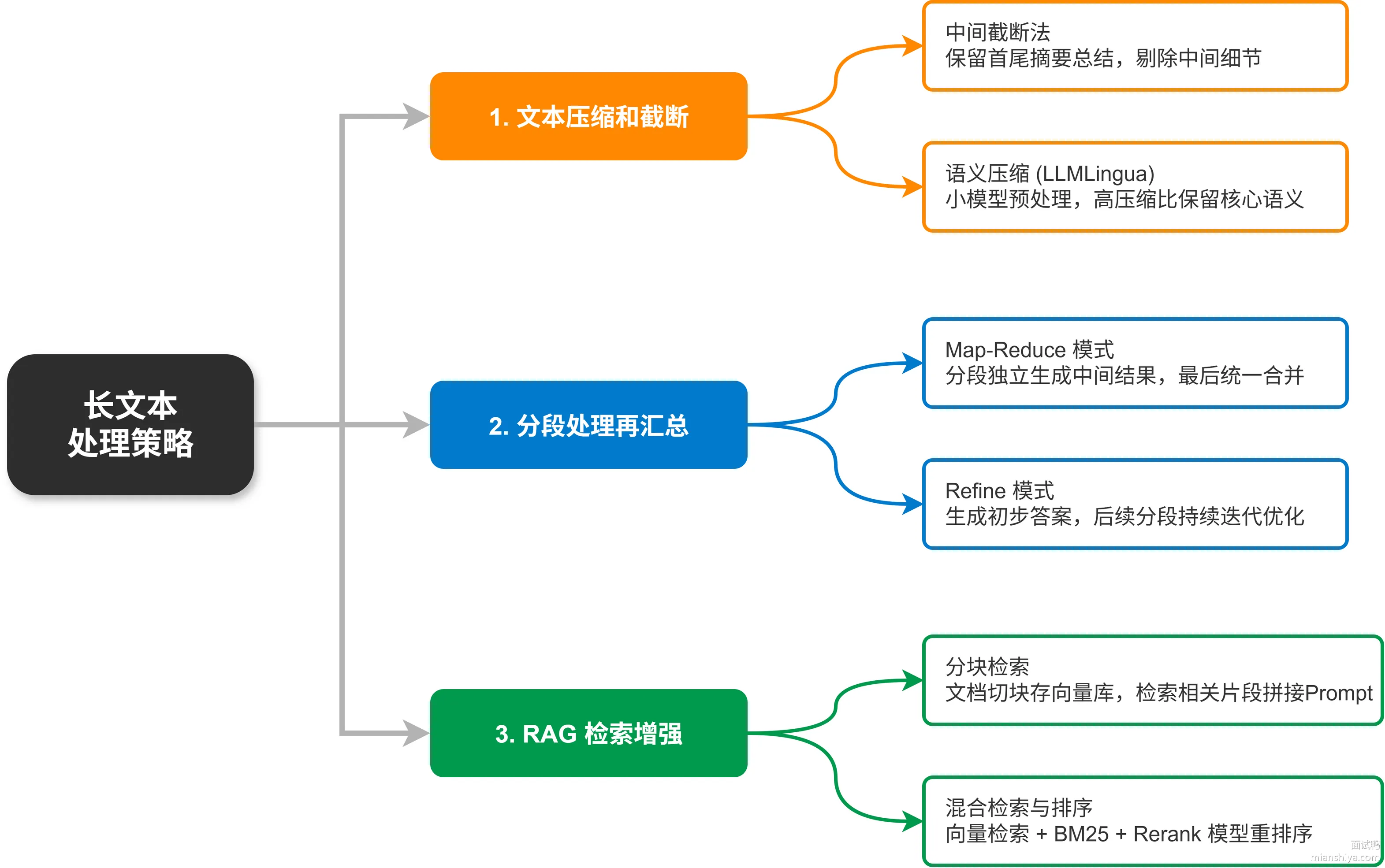
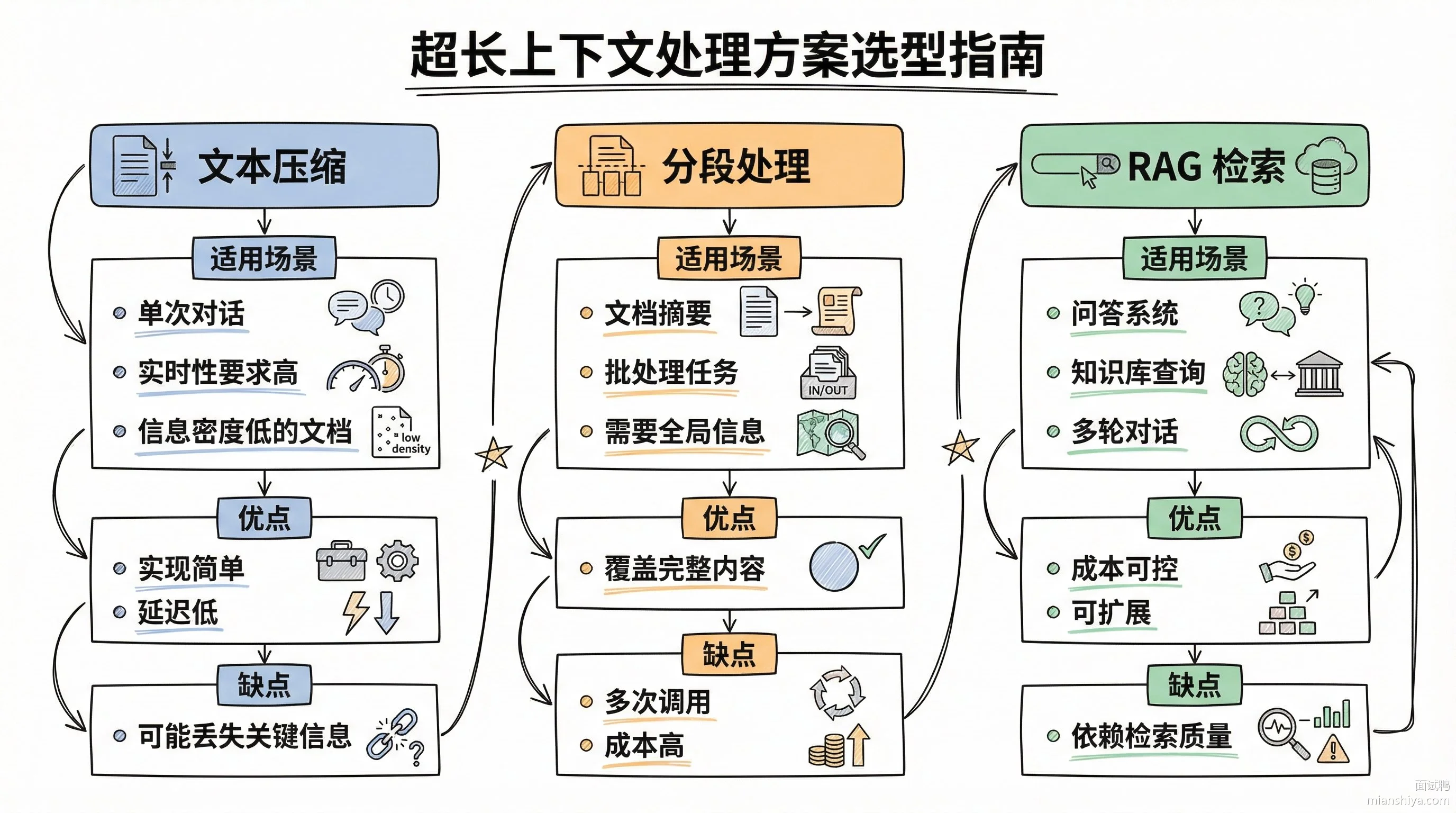
工程上主要有三条路:砍内容、分批喂、只检索相关的。
1)文本压缩和截断
最简单粗暴的办法就是砍。中间截断法是常用手段,因为很多文档开头是摘要、结尾是总结,中间是细节,砍中间影响最小。更聪明的做法是用 LLMLingua 这类工具做语义压缩,让小模型先过一遍,把冗余信息剔掉,压缩比能到 10 倍以上,核心信息还能保住。
2)分段处理再汇总
文档太长就切成多段,每段单独处理,最后把结果汇总。Map-Reduce 模式就是这个思路:Map 阶段每个分段独立生成摘要或中间结果,Reduce 阶段把所有中间结果合并成最终答案。还有 Refine 模式,第一段先出个初步答案,后面每段都在前一个答案基础上迭代优化。
3)RAG 检索增强
压根不用把整篇文档塞进去,先把文档切块存向量库,用户提问时只检索最相关的几个片段,拼进 Prompt 里就行。这是目前最主流的方案,几百 MB 的知识库也能秒级响应。检索质量决定了最终效果,向量检索加 BM25 混合检索,再配个 Rerank 模型,召回率能上一个台阶。
扩展知识
为什么上下文窗口是个硬限制
Transformer 的自注意力机制计算复杂度是 O(n²),n 是序列长度。4K token 的时候还好,到了 100K,显存和计算量都扛不住。虽然现在有 Flash Attention、Ring Attention 这些优化,能把窗口撑大,但成本还是随长度飙升。更关键的是,模型在超长上下文里容易"迷路",中间的内容注意力权重会被稀释,所谓的"Lost in the Middle"问题。
文本压缩方案详解
压缩有几个层次:
1)规则压缩:去掉 HTML 标签、重复空白、无意义符号,能省 20%-30% 的 token 2)摘要压缩:让模型先生成摘要,用摘要替代原文,适合不需要细节的场景 3)语义压缩:LLMLingua、Selective Context 这类工具,训练一个小模型来判断哪些 token 可以删,哪些必须保留
语义压缩的原理是计算每个 token 的困惑度,困惑度低的说明可预测性高,删了影响不大。实测下来,压缩到原来的 1/5 甚至 1/10,模型输出质量下降不明显。
分段处理的几种模式
| 模式 | 工作流程 | 适用场景 |
|---|---|---|
| Map-Reduce | 每段独立处理 → 结果汇总 | 文档摘要、信息抽取 |
| Refine | 逐段迭代更新答案 | 需要全局一致性的任务 |
| Map-Rerank | 每段独立处理 → 按相关性排序取最优 | 问答、事实查找 |
Map-Reduce 的问题是中间结果汇总时可能丢信息,Refine 的问题是串行处理慢。实际项目里可以混着用,先 Map 再 Refine。
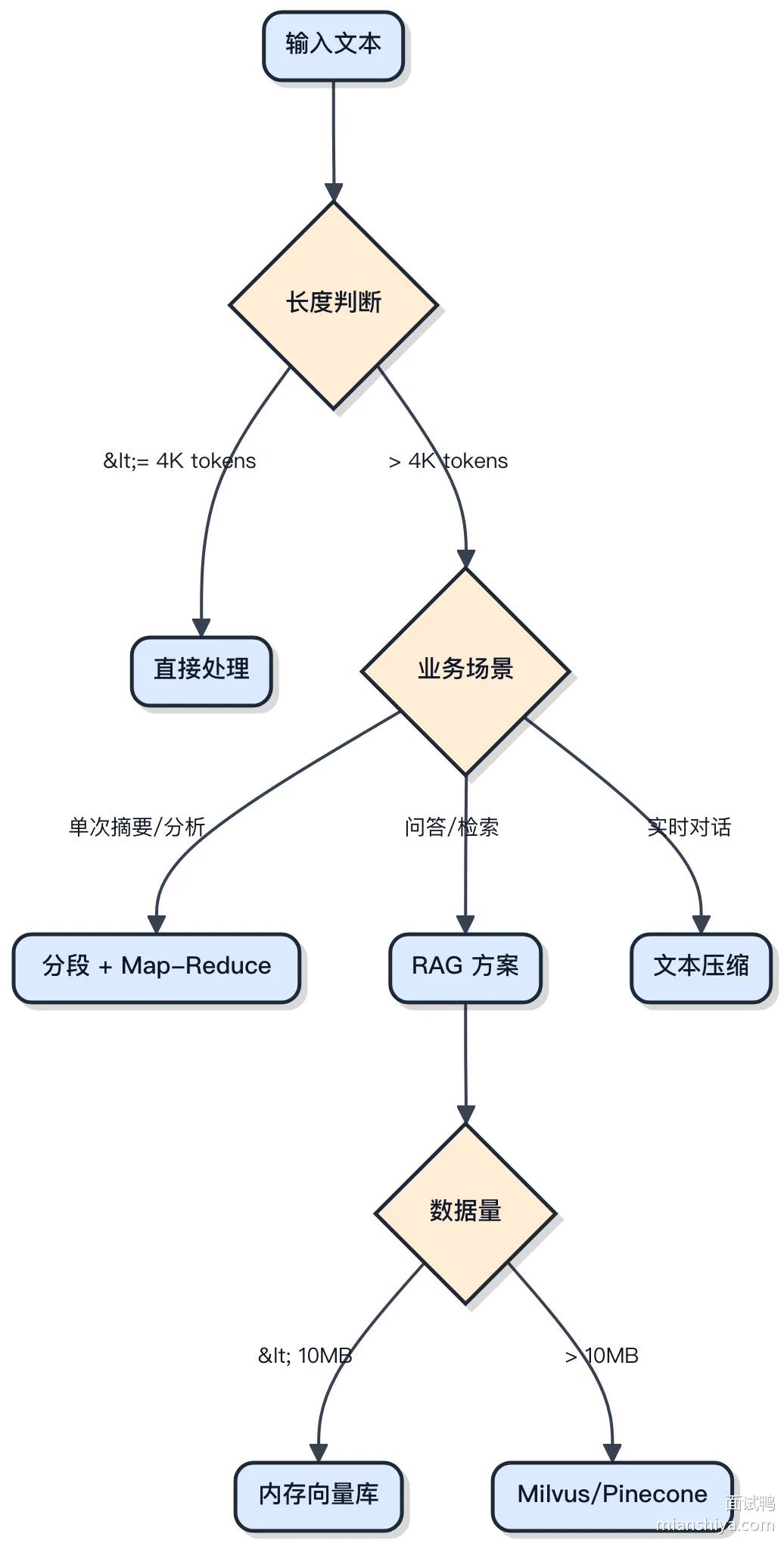
技术选型决策树
篇幅有限,更多 AI 大模型 相关面试题可以进入面试鸭进行查阅。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)