从“模数共振”到AI Agent规模化:企业多模态数据融合不再是选择题
当大模型迭代进入全模态时代,当AI Agent从概念试点走向产业落地,一个现实问题摆在所有企业面前:我们不缺大模型、不缺AI应用场景,唯独缺能喂给模型、能支撑业务的高质量多模态数据。
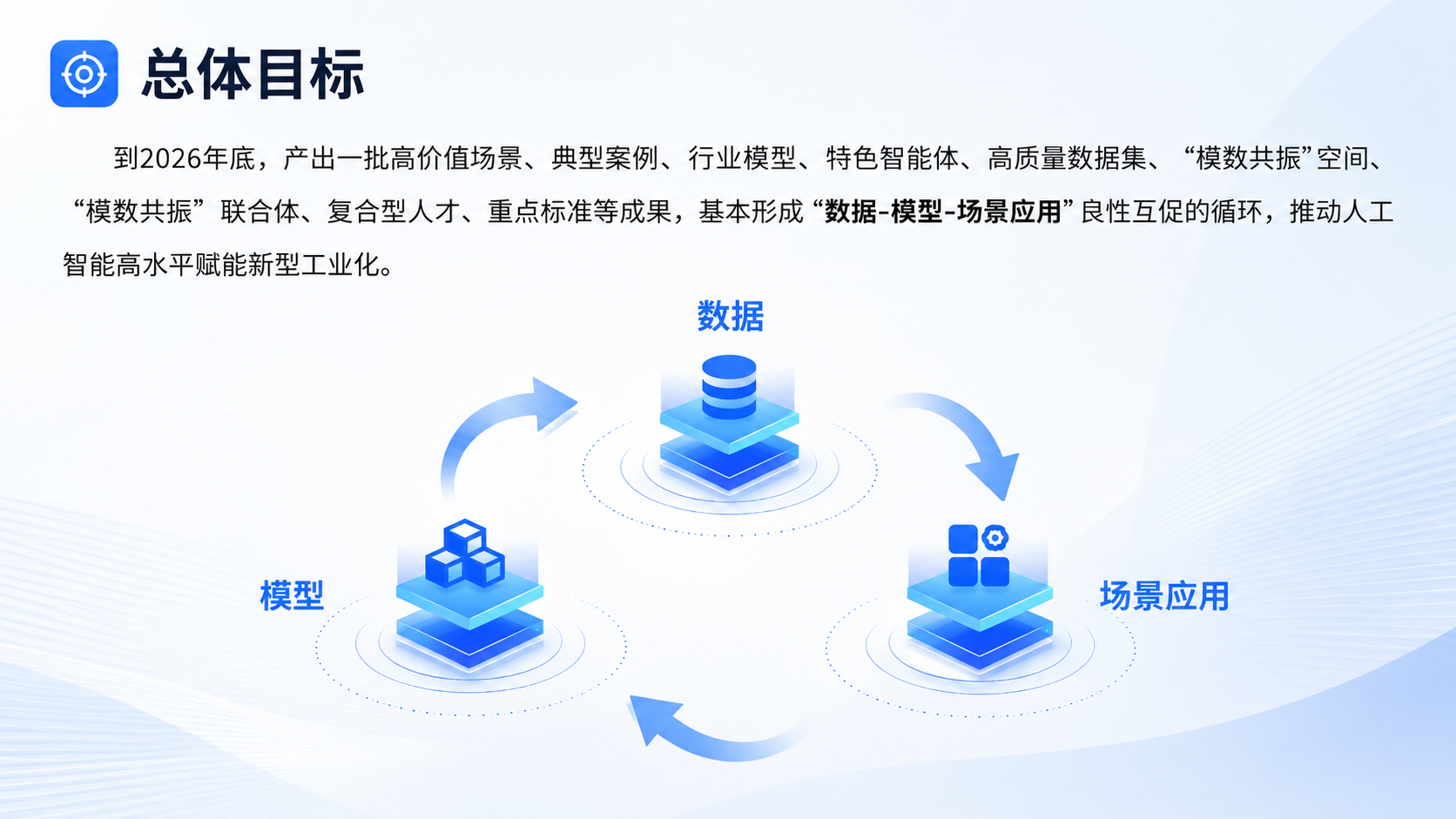
就在不久前,第九届数字中国建设峰会上,工信部、国家数据局正式联合启动2026年“模数共振”专项行动,明确提出以数据为基、模型为核,推动20大重点行业构建高质量数据集、培育行业专属大模型,形成“高质量数据→高效能模型→高价值应用”的正向飞轮。
一时间,“模数共振”成为产业最热关键词。但热潮之下,绝大多数企业仍陷入同一个困境:
坐拥海量数据,生产报表、业务台账、设备日志、巡检视频、运维文档、客户资料散落各处;结构化数据藏在数据库,非结构化数据堆在存储桶,各成孤岛、互不连通。
看似存了海量数据,实则数据归数据,模型归模型,业务归业务,模数无法同频、更谈不上共振。这也正是很多企业AI落地卡在最后一公里的核心症结。
行业现状:多数企业多模态建设,仍停留在“数据归集阶段”

当前,政企数字化、智能化建设持续提速,多数企业已完成多类型数据归集、初步搭建AI应用,迈出了多模态建设的第一步。但从行业整体落地情况来看,不少企业的多模态建设,还停留在基础归集、简单存储的浅层阶段,尚未形成深度治理与融合应用能力。
很多企业现阶段的建设现状普遍是:
将业务文档、设备视频、图片资料统一归集存储,完成多类型数据留存;上线通用大模型应用,实现基础智能问答能力;继续结构化数仓建设,保障传统数据分析需求。
这种建设模式,完成了数据数字化的基础积累,但在智能化深度落地的当下,仍存在三处普遍短板,难以适配“模数共振”与AI规模化落地的要求:
1. 模态数据相互独立,缺乏联动能力
表格数据、文本文档、音视频、图像等异构数据,格式、标准、存储口径各不统一,彼此独立运行,无法实现跨模态关联分析、联动建模,难以形成全域数据视角。
2. 非结构化数据价值难以释放
大量图片、文档、音视频数据仅完成存储留存,缺少智能解析、结构化转化能力,机器无法识别、业务无法调用、数据无法量化统计,海量非结构化数据长期处于价值沉睡状态。
3. 数据与AI应用适配度不足
未经深度治理、融合规整的多模态数据,数据标准不统一、有效信息密度低,难以适配大模型训练、AI Agent智能决策的需求。导致AI应用只能实现基础通用能力,无法深度贴合业务场景、实现精准预判与智能分析。
国家推动“模数共振”行动,核心目的正是引导企业升级建设思路,从传统的“重存储、轻治理、弱融合”,转向“强治理、深融合、重应用”。对于多模态建设而言,存储归集只是基础,融得通、用得好、能赋能AI,才是核心目标。
模数共振时代,企业到底需要什么样的数据底座

面对“模数共振”政策要求与AI规模化落地需求,企业想要打破数据孤岛、释放数据价值,首先要明确:什么样的数据底座,才能承接政策、适配模型、赋能业务?
从官方政策导向到行业建设痛点,不难看清核心需求:
模数共振的核心,是数据与模型的同频;而同频的前提,是多模态数据的深度融合。
传统数据平台只擅长结构化数仓,无法处理图片、音视频、文档等非结构化数据;单纯的对象存储只能存不能算,AI模型又缺高质量行业数据喂养。企业如果还是和以往一样分头搭建数仓、存储、AI多套平台,成本高、链路碎、治理复杂,将难以跟上政策和产业节奏。
真正适配模数共振时代的企业级多模态智能底座,核心要具备一站式全链路能力,无需多平台拼凑,就能一次性解决企业三大核心诉求:
- 对上:满足模数共振、数据要素合规建设的政策要求;
- 对中:打破数据孤岛,实现多模态异构数据深度融合;
- 对下:沉淀高质量数据集,持续供给大模型与AI Agent落地,真正释放数据生产力。
实战拆解:从制造行业案例,看懂模数共振如何落地

政策风口最终要落到业务实处。我们以高端装备制造典型场景为例,看看企业真实困境,以及数栈7.0如何一站式打通多模态融合,接住模数共振政策要求、支撑AI Agent落地。
某大型装备制造企业,常年积累四类核心数据:
- 结构化:生产报表、设备台账、能耗指标、维保记录;
- 时序日志:传感器实时采集的设备运行参数、异常日志;
- 视觉图像:现场设备巡检实拍图、仪表盘刻度图、零部件细节图;
- 非结构化文档:运维手册、故障案例PDF、检修记录文档。
企业原有痛点
四类数据分属不同系统,运维团队看视频、生产团队看报表、技术团队查文档,彼此互不打通。想要搭建设备健康管理数据集、训练运维AI Agent,却连最基础的数据关联、信息提取、标准规整都无法做到,完全跟不上“模数共振”行动中行业数据集建设的要求。
数栈7.0落地三步,完成全链路多模态融合
第一步:全域统一接入,对齐官方数据标准
摒弃多系统割裂建设模式,通过数栈一站式集成能力,把数据库报表、时序日志、巡检图片、运维文档全类型、多来源、多模态数据统一接入。
平台能自动完成基础技术元数据构建,同时基于管理员搭建的分类编目、标签体系可以快速进行业务元数据和管理元数据的配置,从源头统一数据口径、规范数据管理架构,直接贴合国家数据要素治理与模数共振的基础建设要求。
第二步:智能模态解析,让非结构化数据“可读懂、可计算”
这是突破浅层多模态建设的关键一步。
依托平台低代码可视化AI算子,无需算法团队深度编码,即可完成自动化解析转化:
- 图像类:通过OCR识别仪表盘、设备铭牌、参数实拍图,自动提取设备型号、运行参数、规格信息,转化为结构化字段;
- 文档类:对运维手册、故障案例做清洗分段、语义提炼,推送给标注平台打标故障类型、诱因、解决方案,形成标准化故障知识库;
- 时序日志:实时解析设备异常信号,按设备ID、时间戳规整,实现与生产台账精准匹配关联。
至此,原本较零散的图片、文档、日志,全部变成标准、可用、可建模的结构化数据,彻底打破模态壁垒。
第三步:全域融合建模,沉淀可复用高质量数据资产
以设备唯一编码为主键,将生产报表、运行日志、图像解析参数、文档故障标签四类异构数据深度关联,构建设备全生命周期多模态融合宽表。
同时配套全链路数据血缘、分级分类、脱敏授权、操作审计,既满足行业合规管控要求,又直接沉淀出可上报、可复用、可训模的高质量行业数据集。
落地实际价值
1. 合规层面:提前完成模数共振行动要求的行业高质量数据集建设,契合政策数字化考核标准;
2. AI层面:融合后的多模态数据直接供给运维AI Agent,实现设备故障智能预判、故障案例智能问答、检修方案自动推荐,故障识别准确率大幅提升;
3. 业务层面:非结构化数据利用率从个位数提升至五成以上,运维排查效率大幅降低,真正实现从“数据囤积”到“价值变现”。
结语:模数共振下,多模态融合是企业数字化的入场券
2026年,数字化早已不是可选项,智能化也不再是锦上添花。
国家以“模数共振”行动自上而下推动产业升级,全模态大模型、AI Agent自下而上重构业务场景,中间的核心支点,就是多模态数据的治理与融合。
企业需要尽快搭建能承接政策、能盘活数据、能支撑AI的统一底座。
存数据只是起点,融数据才是关键;
有模型只是表象,模数同频才是未来。
数栈7.0多模态数据底座,助力企业紧跟模数共振浪潮,把数据孤岛变成数据资产,把合规压力变成AI竞争力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)