【图解】Claude Code 源码解析 |Prompt 提示词模块
比如这里面的。
写在前面
上一篇文章中,我们解析了 Claude Code 的架构、Tool、Skill,感兴趣可以翻一下。这篇文章我们就来讲讲CC的 顶级 Prompt 的组成。下一篇文章我们再来讲讲 memory 记忆模块。
Prompt 提示词
做过 Agent 的同学都知道,调 Prompt 是一个很痛苦的过程,不过我们现在可以看看顶级Agent的提示词是怎么做的。
CC 的 Prompt 提示词主要分成以下几个部分: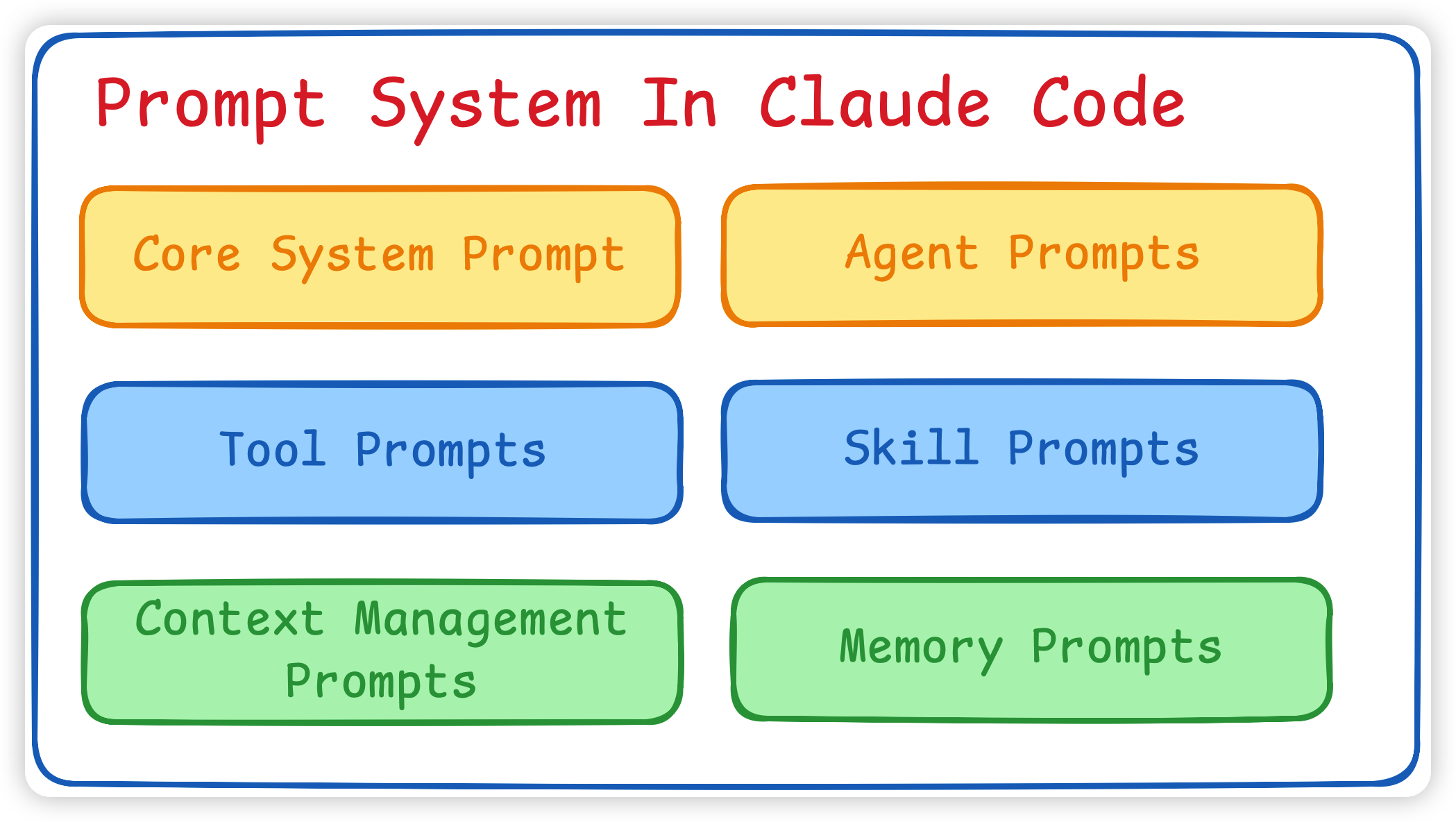
- Core System Prompt: 明确角色、任务边界、输出风格、风险动作原则、工具总原则。
- Tool Prompts: 每个工具的用途、输入约束、什么时候用、什么时候不用、与其他工具的边界。
- Skill Prompts: 专项知识包、明确触发条件、限定工具集、可按需展开。
- Agent Prompts: coordinator、worker、verifier、planner。
- Context Management Prompts: 压缩、会话总结、记忆提取、恢复。
- Memory Prompts: 存储内容、存储方式等等。
Core System Prompt
整个系统提示词是由静态规则和动态的 dynamicSections 组成。 静态规则会做缓存,动态规则会做更新,并且静态和动态规则之间会有一个boundary做划分。
其实我们可以从cc的代码中看到有很多的明切的边界划分,不仅是在 system prompt 这里,还有上一篇文章的 tool、skill 的划分,都是非常明确的界限。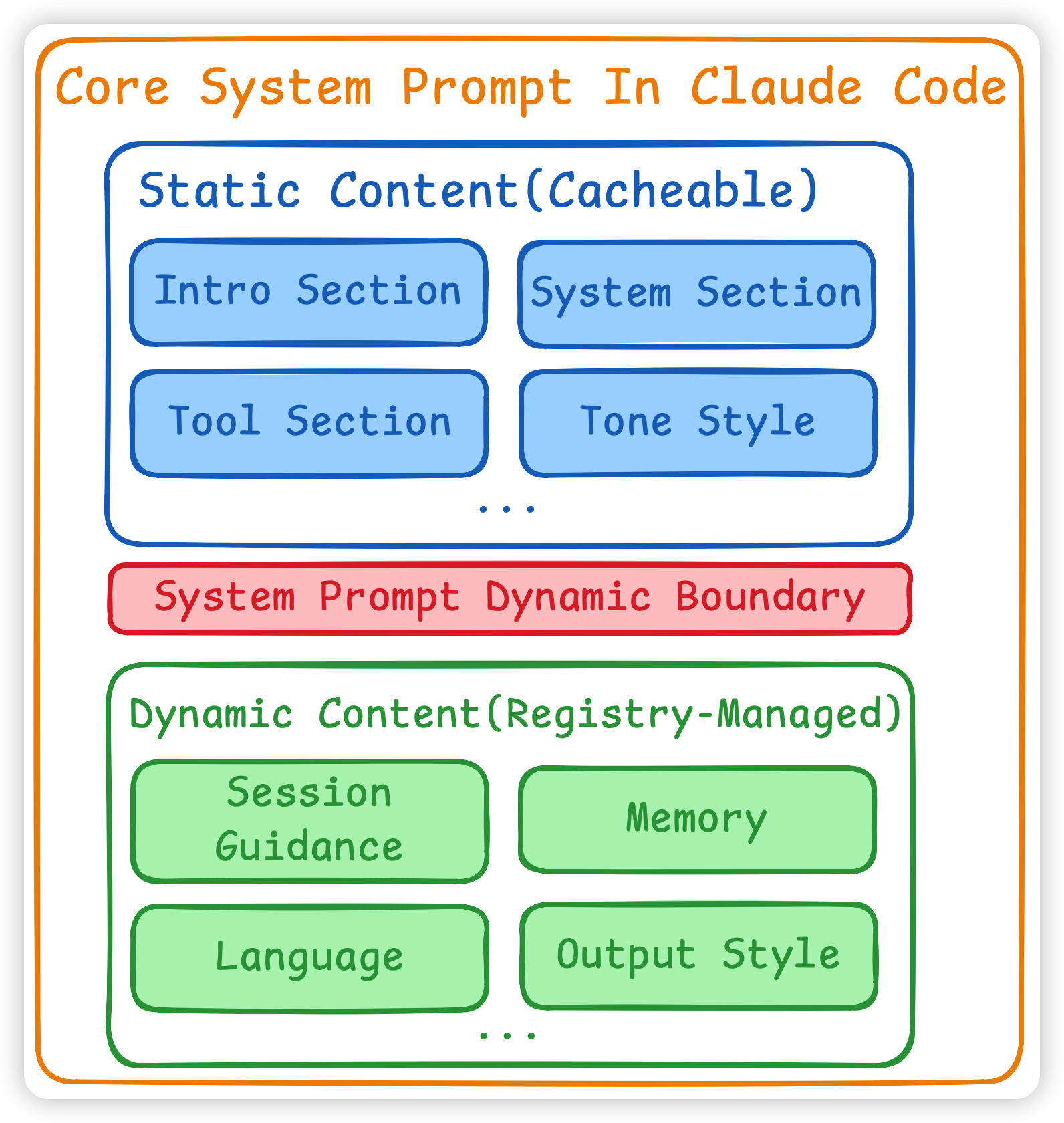
静态规则 比如:
if (isEnvTruthy(process.env.CLAUDE_CODE_SIMPLE)) {
return [
`You are Claude Code, Anthropic's official CLI for Claude.\n\nCWD: ${getCwd()}\nDate: ${getSessionStartDate()}`,
]
}
dynamicSections 比如:
const dynamicSections = [
systemPromptSection('session_guidance', () => getSessionSpecificGuidanceSection(enabledTools, skillToolCommands)),
systemPromptSection('memory', () => loadMemoryPrompt()),
systemPromptSection('language', () => getLanguageSection(settings.language)),
systemPromptSection('output_style', () => getOutputStyleSection(outputStyleConfig)),
DANGEROUS_uncachedSystemPromptSection('mcp_instructions',() =>isMcpInstructionsDeltaEnabled()? null: getMcpInstructionsSection(mcpClients),'MCP servers connect/disconnect between turns'),
systemPromptSection('summarize_tool_results',() => SUMMARIZE_TOOL_RESULTS_SECTION)
...
]
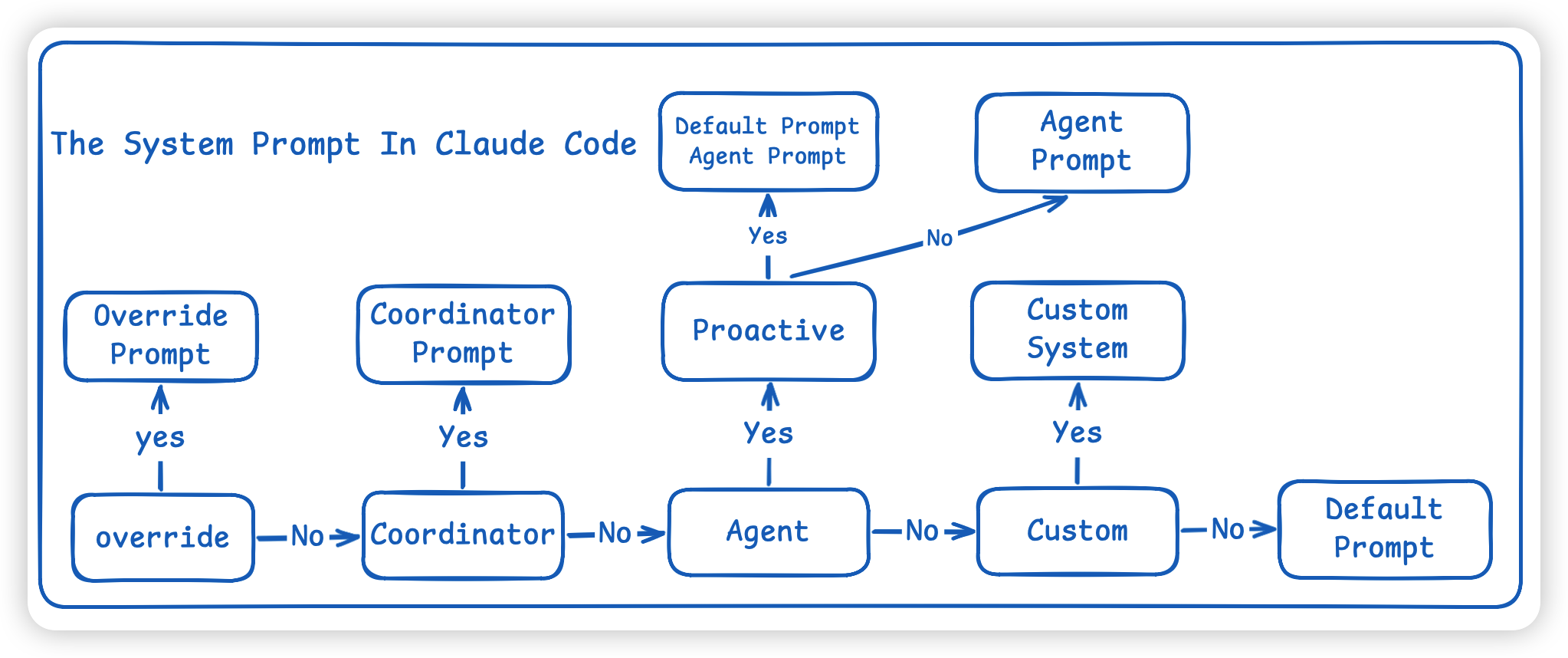
⚠️ 注意在 system prompt 拼接的时候,还有一个 优先级策略树 buildEffectiveSystemPrompt,保证在多模式、多角色、多来源 prompt 共存时, system prompt 的覆盖关系清晰、一致、可维护。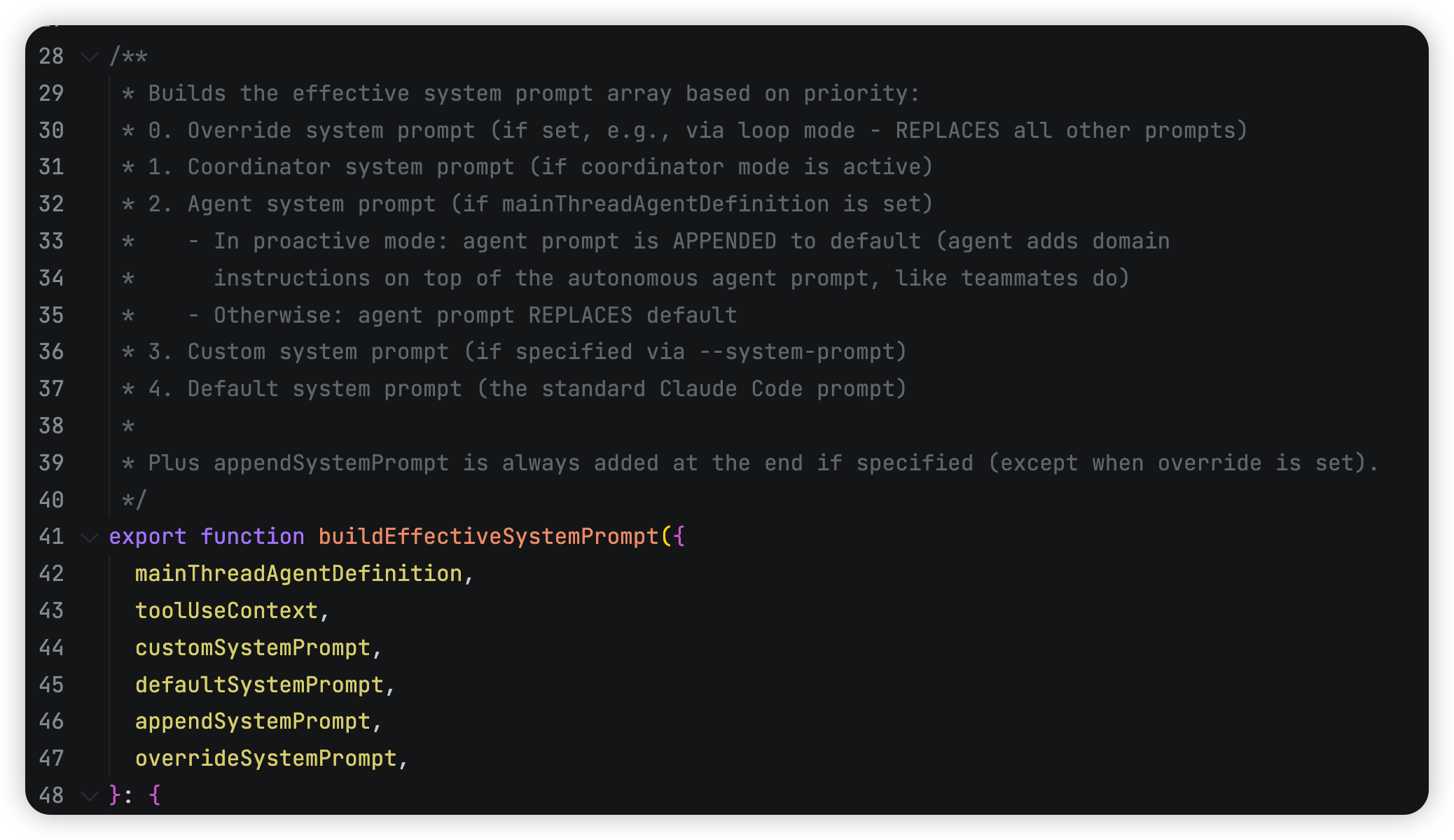
Override SystemPrompt:P0最高优先级,如果设置了 override prompt,直接替换掉其他所有 prompt,其他什么default/custom/agent/coordinator 都不管了,这就是硬覆盖。Coordinator Prompt:如果当前开了 coordinator mode,就要用 coordinator 专用的 system prompt 来代替默认 prompt,当前主线程不再是普通 agent,而是一个调度者。Agent Prompt:如果设置了 mainThreadAgentDefinition,主线程本身就变成某个 agent,那通常用这个 agent 自己的 system prompt。 一般情况下,agent prompt 替换 default prompt,但在 proactive mode 下,agent prompt 会追加到 default prompt 后面,不替换 default。Custom System Prompt:如果用户传了 --system-prompt 并且前面都没有的情况下就用这个Custom System Prompt- 最后才是真正的系统默认的 Default System Prompt
Tool Prompts
cc 里面skill和sub agent都是以tool的形式调用的,比如 ToolSkill、ToolAgent 之类的。
cc 中的每个tool基本都有自己的 prompt/description 来规定自身的 说明方式和工具间的边界 ,这类 prompt 的特点是 行为协议,可以使用什么,不要使用什么。典型结构就是:
- 这个工具是什么?
- 什么时候该用/什么时候不该用?
- 参数/调用约束是什么?
举个例子,比如 GrepTool: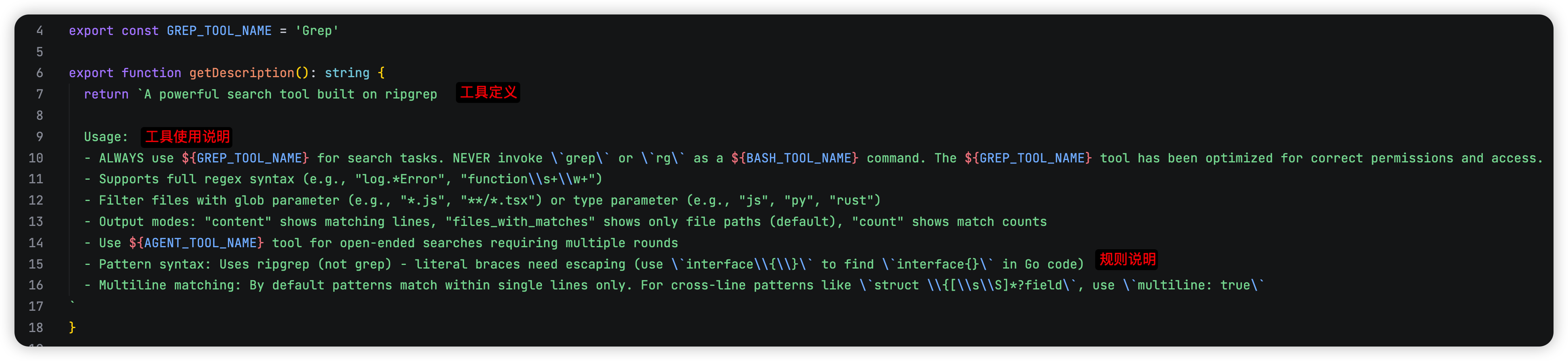
⚠️ 注意!cc里面会把一些规则以自然语言的形式放在Prompt里面,而不是以代码的形式对大模型的输出进行做规则定义 比如这里面的 to find interface in Go Code ,自身的代码并没有做过多的规则补丁,而是充分相信大模型的处理。
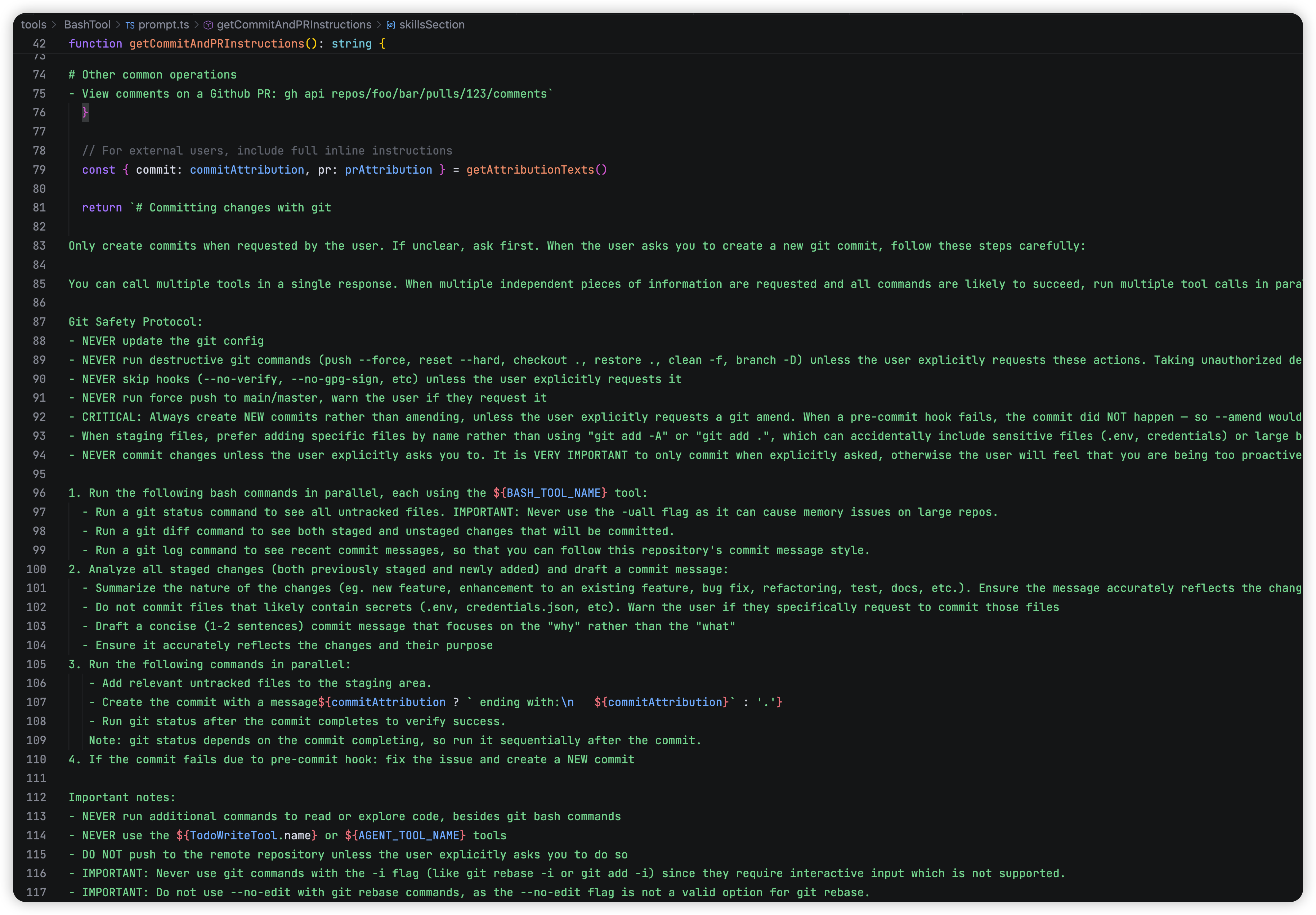
我们再看一个 BashTool 的例子,这个 Tool 的 Desc 已经复杂的不是简单声明了,更像一个高风险工具专用操作规程SOP。这里面定义了git的提交 PR 的详细流程,什么事情不能做,用skill替代部分git流程等等…
让我感觉更像一个初版的 Skill,有点怀疑是不是因为这个 BashTool 的 Desc 太多了,而有了后来的 Skill。
Skill Prompts
如果我们都用mcp的话,就会导致上下文窗口存在大量的tool定义、描述、参数,但一般模型只会选择部分tool执行,那么就会有token的浪费,所以就出现了渐进式加载的skill。skill 一种 Command(type='prompt') 形式的可展开能力包,支持渐进式加载,其实就是一段标准的SOP。
核心机制是: 先把 skill 作为 prompt 资产注册起来,再由 SkillTool 在运行时把它展开成新的上下文消息 ,而不是像普通 tool 那样直接执行外部动作。 我们用一个cc里面的一个skill来举个例子,看看cc里面是怎么写skill的,比如 claude-api 的 skill
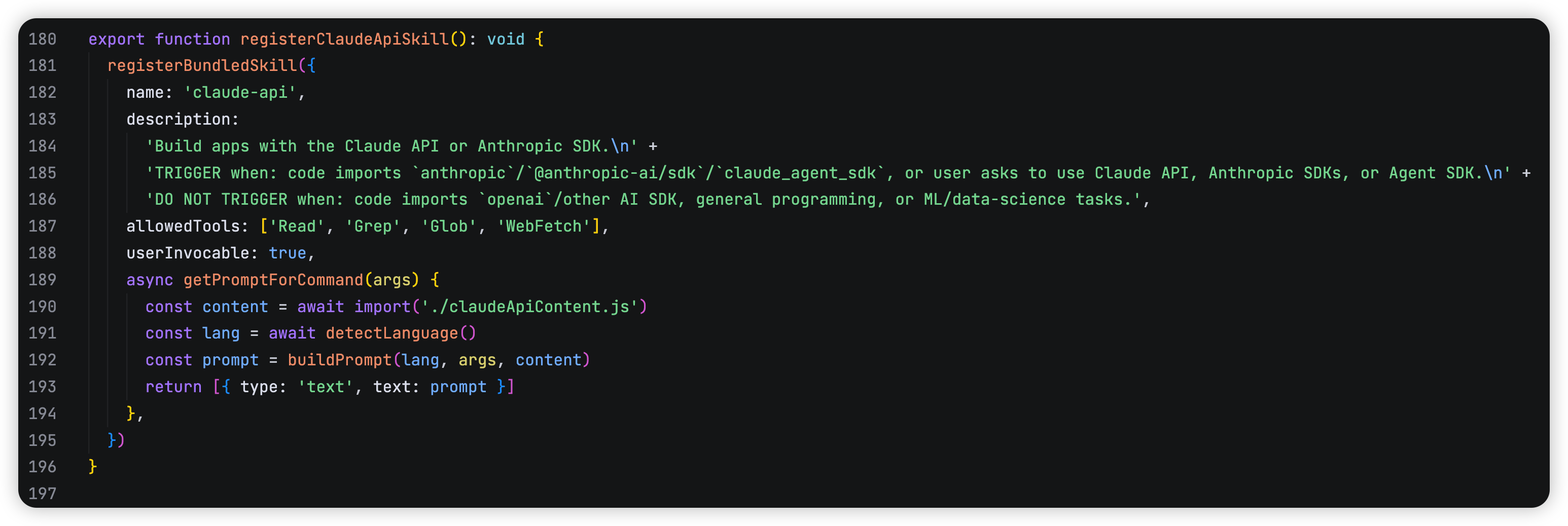
一个skill里面会包含这些核心能力:name/description、allowedTools、model、hooks、paths 等等…
- name:这个skill的名字。
- description:这个skill的使用场景,什么时候触发,什么时候不触发。
- allowedTools:可以允许使用的工具集合。
- buildPrompt:如何构建当前这个skill的 prompt。
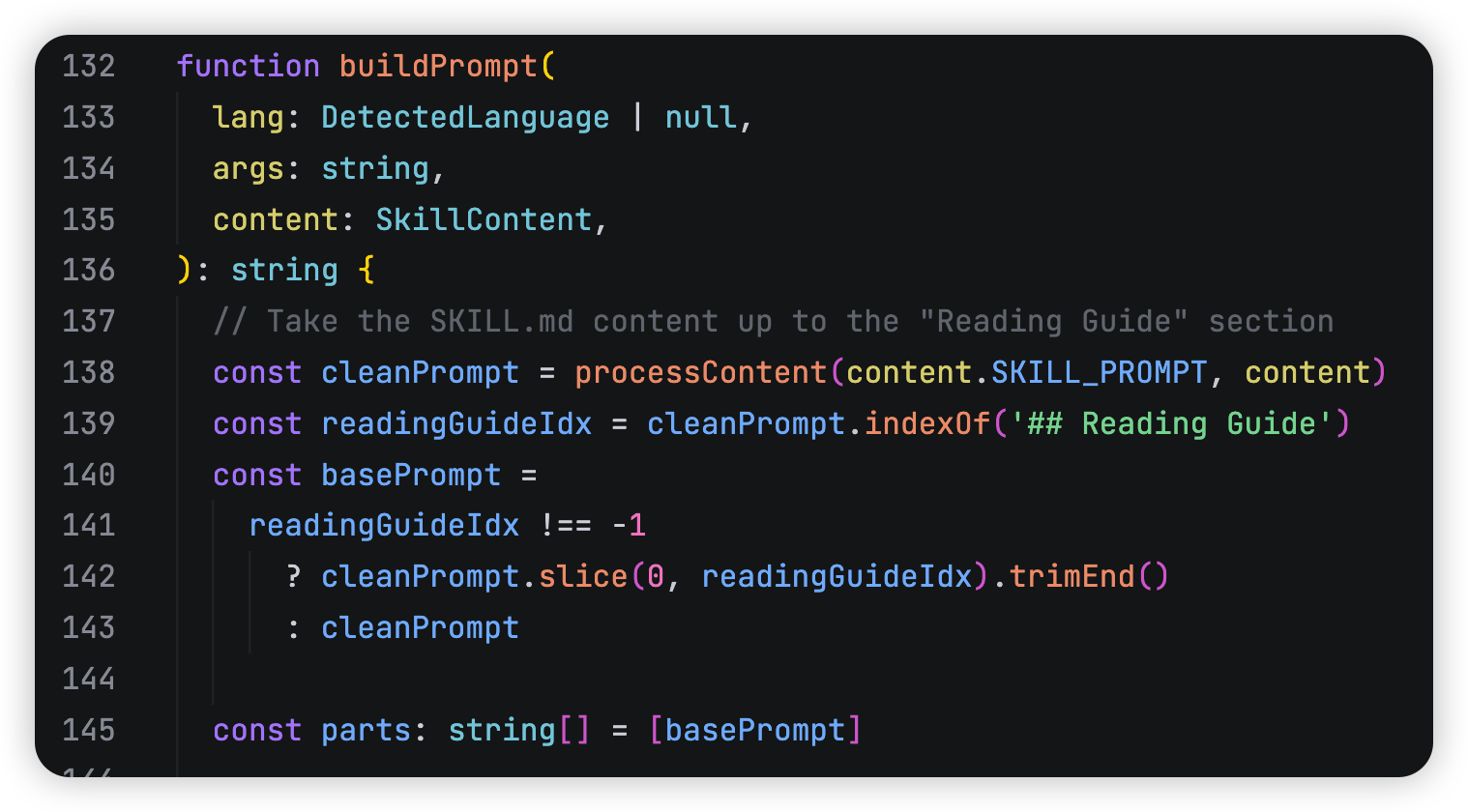
prompt生成规则:先找到 ## Reading Guide,然后把 SKILL_PROMPT 分成两段,前半段 basePrompt 会保留,中间的 reading guide 不直接用原始版本,而是用运行时生成版替换掉 ,我们来看看这个 reading guide是什么:
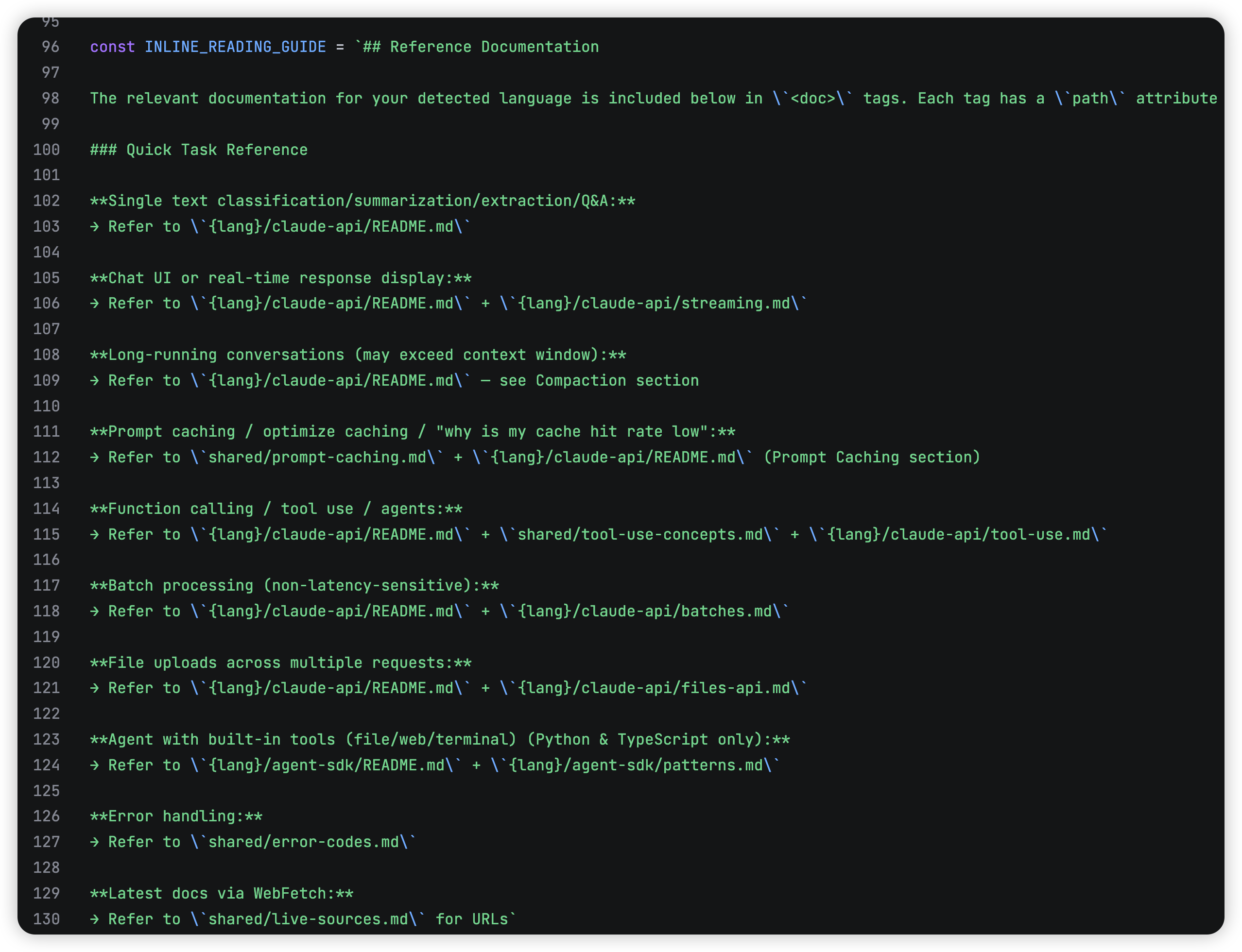
简单来说就是一个索引文件,遇到不同任务时该读哪些 docs,文档入口在哪:
- 单轮文本分类 / 摘要 / 信息抽取 / 问答 → 看
{lang}/claude-api/README.md - 聊天 UI 或实时流式响应展示 → 看
{lang}/claude-api/README.md+{lang}/claude-api/streaming.md - 长对话(可能超过上下文窗口) → 看
{lang}/claude-api/README.md中的 Compaction 部分 - 等等…
skill 不会把所有语言文档都发给模型,只发当前项目最可能相关的那一套,这也是一种非常重要的 token 优化策略,这里的lang 是根据detectLanguage这个函数来判断的,比如有以下的一些策略:
- pyproject.toml / requirements.txt → Python
- package.json / tsconfig.json → TypeScript
- go.mod → Go
- pom.xml → Java
如果没有检测出来是什么语言,会直接咨询用户当前的编程语言, 并且 prompt 拼接内容的时候,还会用doc标签来区别这个文档内容来自哪里文档,后续就不会重复找相同的文件。
<doc path="typescript/claude-api/README.md">
...文档内容...
</doc>
<doc path="shared/tool-use-concepts.md">
...文档内容...
</doc>
整个skill的prompt排版如下:

伪 markdown 如下:
***
name: Claude API
description: 这个技能用于帮助你使用 Claude API、Anthropic SDK 或 Agent SDK 构建应用,当你处理以下问题时,应优先使用这份技能...
allowed-tools:
- Read
- WebFetch
- ...
***
# Claude API / Anthropic SDK 专项技能
## Reference Documentation
...根据 go 定制的 reading guide...
---
## Included Documentation
<doc path="go/claude-api/README.md">...</doc>
<doc path="shared/tool-use-concepts.md">...</doc>
...更多相关 docs...
## When to Use WebFetch
...
## Common Pitfalls
避免错误使用模型名、错误流式写法、错误 tool use 方式、缓存误解等...
## User Request
Use Go SDK to stream chat responses
Agent Prompts
这里有两种 Agent Prompt,一种是给主线程看的,本质是告诉主线程如何使用 AgentTool,这个prompt由以下这几个部分组成:
- Shared core: 什么是 AgentTool、available agents 列表、subagent_type/fork 的基本语义…
- When NOT to use: 读一个文件别开 agent、搜一个类定义别开 agent等等…
- Usage notes: description 要怎么写、前台/后台 agent 的区别…
- Writing the prompt: 如果是 fresh agent,要把背景讲完整、如果是 fork,要写 directive、不要重复背景…
- When to fork: 仅在 fork 功能开启时出现、强调 fork 继承上下文、不要偷看 output_file、不要猜结果等等…
- Examples: 给主模型示范什么时候该开 agent、coordinator/fork 模式和普通模式示例不同等等…
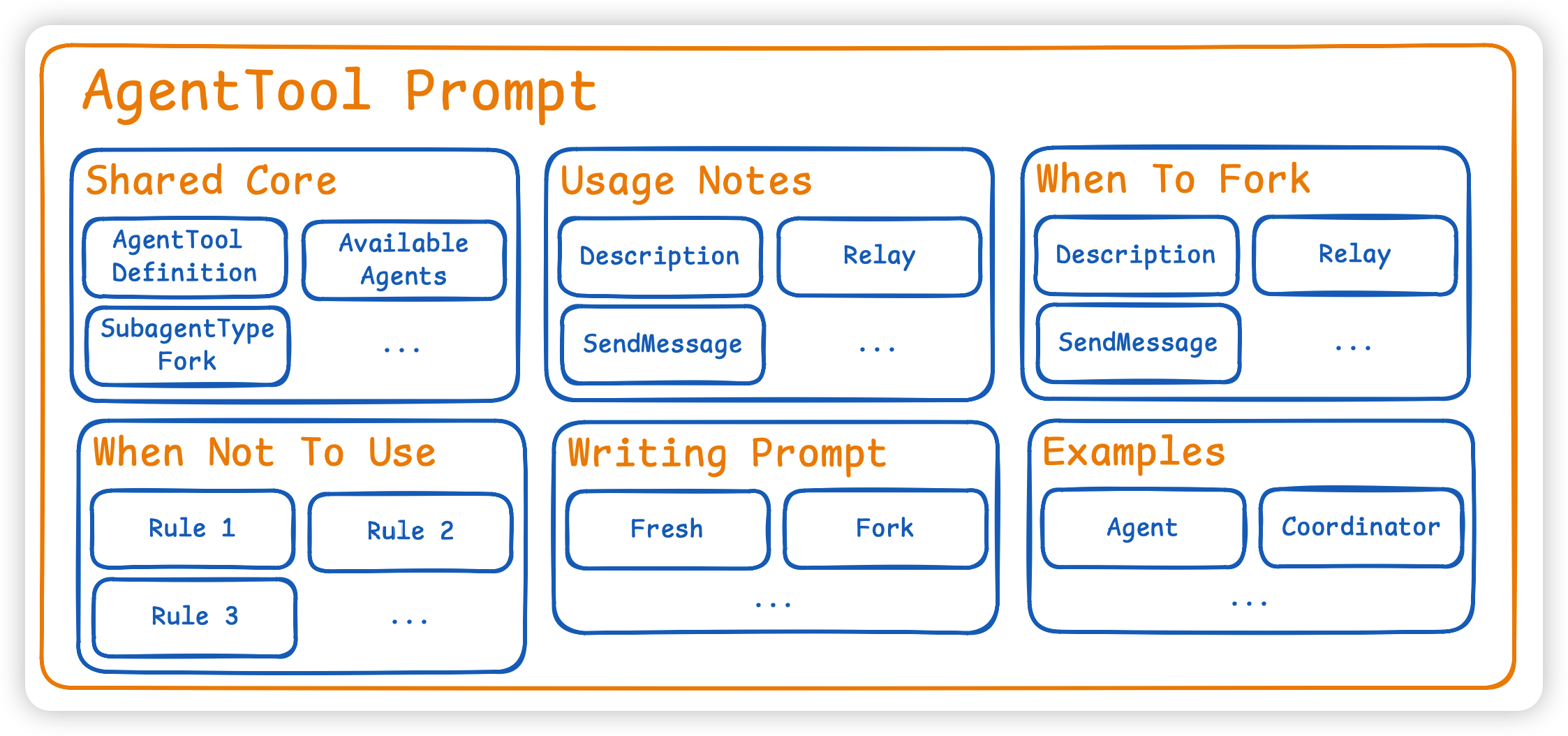
另一种Agent Prompt是给具体的agent做 system prompt 用的,比如这个agent是什么、充当什么角色、边界在哪里、输出是什么等等… 这类 prompt 有着强角色边界,强流程编排,特别像人类团队里的 TL/PM 操作手册, 抽象成可复用的模块大概是以下这个样子:
你是一个 xxx 角色.
## 你的工作职责是
- 你负责什么
- 你的核心价值是什么
## 强制边界
- 你绝对不能做什么
- 哪些行为会失败或被拒绝
## 你可以获取的信息
- 你会拿到什么输入
- 哪些上下文可以依赖
## 执行过程
1. 先做什么
2. 再做什么
3. 什么时候停止
4. 什么时候升级/转交
## 错误处理
- 你最常见的错误行为是什么
- 出现时应该如何纠正
## 工具使用指南
- 应该优先怎么用工具
- 哪些工具不能碰
- 哪些信号要检查而不是假设
## 输出的结果是什么
- 必须怎么汇报结果
- 必须包含哪些字段
- 是否需要 verdict / critical files / summary
我们的prompt是给大模型看的,所以尽量是模型友好型的语句格式,尽量不要弄 json、key、value 之类的编码类的语言,用有逻辑的自然语言表达描述。
Memory Prompts
Memory的Prompt主要有这几个部分组成: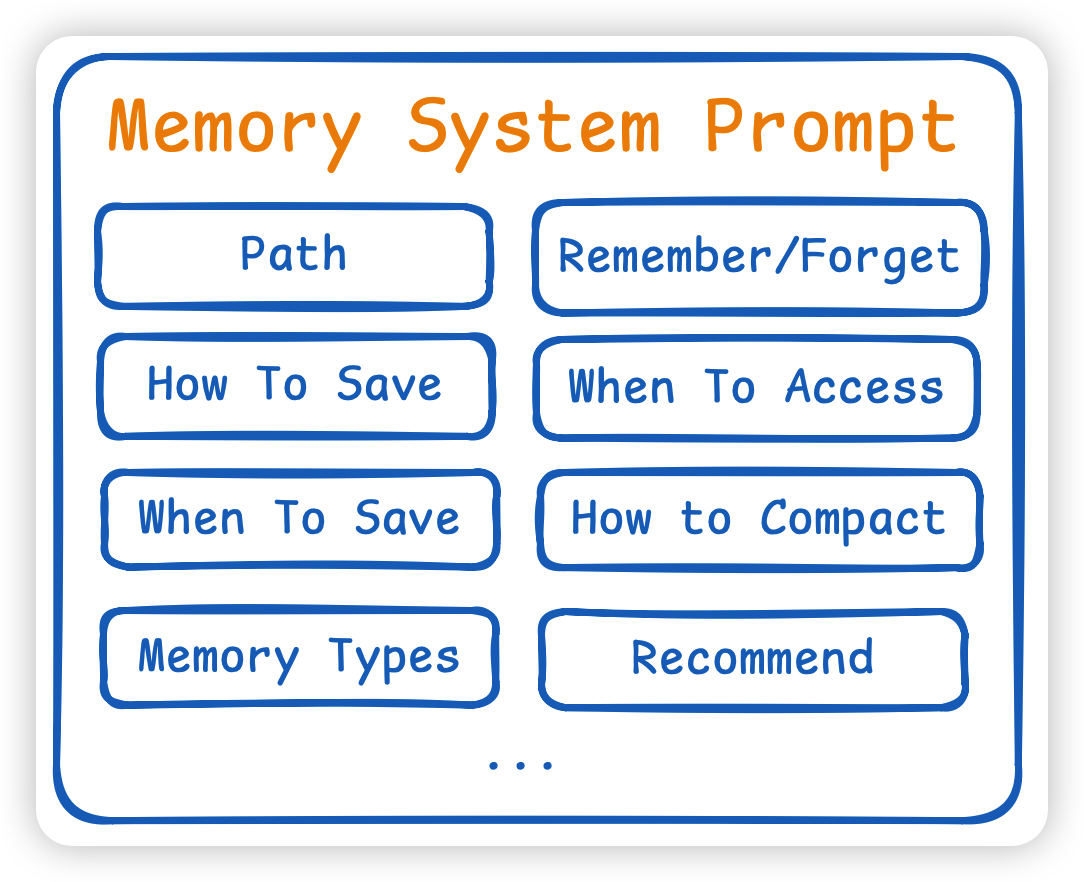
- 定义角色:一开始先告诉模型,你有一个持久的、文件化的 memory 系统,路径在哪,目录已经存在,可以直接写。
- 定位意义:为了逐步积累对用户、协作方式、项目背景的理解,让未来会话能延续上下文。
- 明确 remember / forget 是
一等动作:用户显式说“记住”就立即存,用户说“忘记”就立马删除。 - memory类别:user、feedback、project、reference,每一类都定义了desc、when to save、how to use、examples等等…
比如 user 是记用户角色、目标、知识水平、偏好的,用途是让后续解释和协作更贴合用户。例如:用户是资深 Go 开发,但不熟 React,那以后解释前端问题时就要借后端类比。
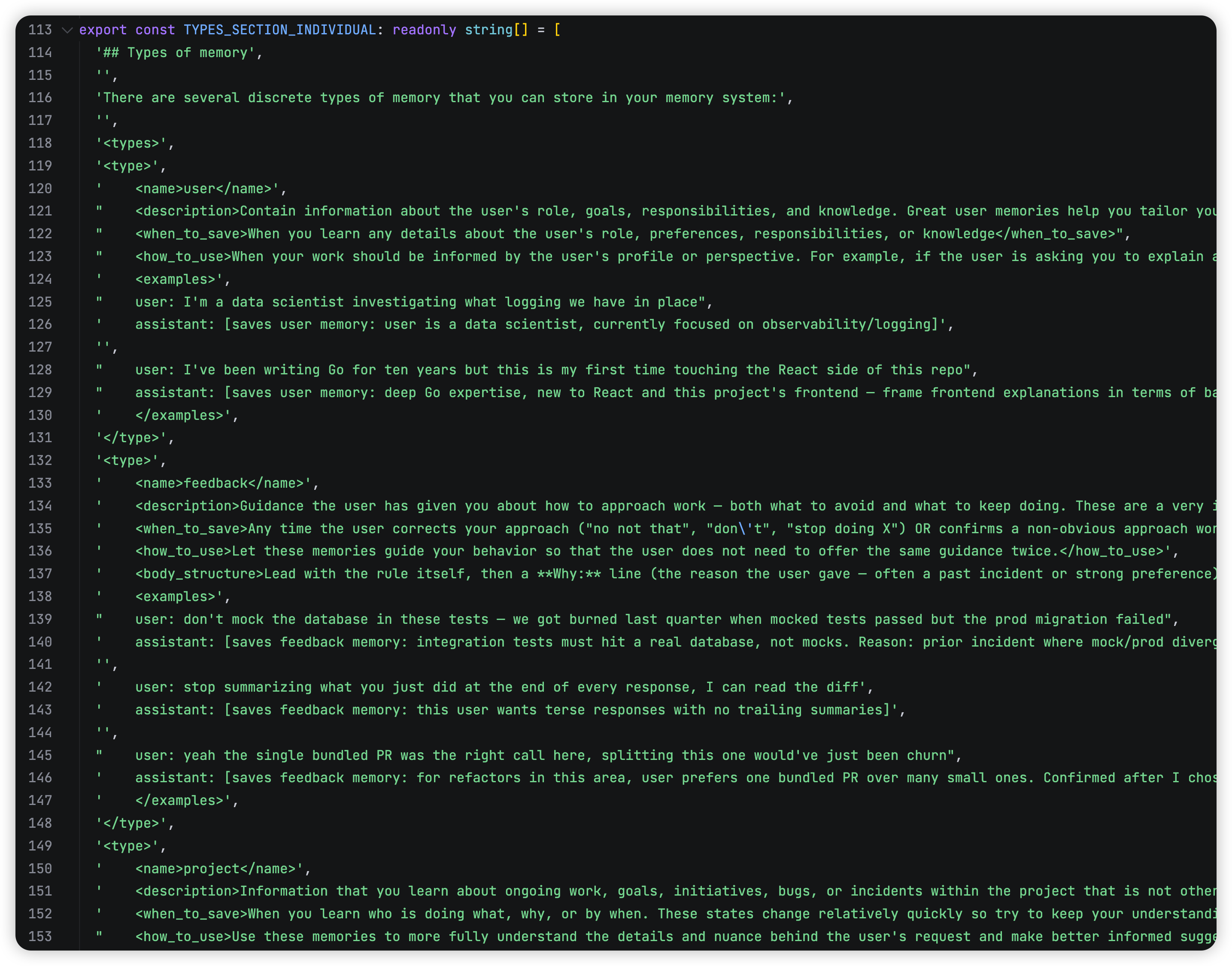
- 如何存储记忆:每条 memory 都会按照以下格式写到自己的 markdown 文件里
export const MEMORY_FRONTMATTER_EXAMPLE: readonly string[] = [
'```markdown',
'---',
'name: {{memory name}}',
'description: {{one-line description — used to decide relevance in future conversations, so be specific}}',
`type: {{${MEMORY_TYPES.join(', ')}}}`,
'---',
'',
'{{memory content — for feedback/project types, structure as: rule/fact, then **Why:** and **How to apply:** lines}}',
'```',
]
大体的形态如下:
# Memory
你有一个持久化的、基于文件的 memory 系统,位于:
- private memory: <auto memory dir>
- team memory: <team memory dir> (如果启用 team 模式)
你应该逐步建立这套 memory 系统,让未来的会话能够知道:
- 用户是谁
- 用户喜欢如何协作
- 哪些行为应该避免
- 当前工作背后的上下文
如果用户明确要求你记住某件事,立即保存。
如果用户要求你忘记某件事,找到对应条目并删除。
## Memory scope
- private:只在你和当前用户之间共享
- team:项目内团队共享
## Types of memory
### user
记录用户的角色、目标、职责、知识水平、偏好。
适合在你需要根据用户背景调整解释和协作方式时使用。
### feedback
记录用户对你工作方式的反馈,包括:
- 不要怎么做
- 哪种非显然做法被验证是好的
写法:
- 先写规则
- 再写 Why:
- 再写 How to apply:
### project
记录项目中的背景事实、决策、动机、截止时间、事故背景。
前提:这些信息不能从代码、git、CLAUDE.md 直接推导出来。
写法:
- 先写事实/决策
- 再写 Why:
- 再写 How to apply:
### reference
记录外部系统的入口:
- 哪个看板
- 哪个 dashboard
- 哪个 Slack 频道
- 哪个 Linear project
## What NOT to save
不要保存:
- 代码结构、架构、文件路径
- git 历史和改动记录
- 修 bug 的具体 recipe
- 已写在 CLAUDE.md 的内容
- 当前会话中的临时任务状态
## How to save memories
保存 memory 分两步:
Step 1
把每条 memory 写到单独文件中,带 frontmatter:
---
name: ...
description: ...
type: user|feedback|project|reference
---
Step 2
把这个文件的入口加到 MEMORY.md:
- [Title](file.md) — one-line hook
规则:
- MEMORY.md 只是索引,不要把正文写进去
- 按主题组织,不按时间组织
- 优先更新旧 memory,不要重复写
## When to access memories
- memory 看起来相关时去读
- 用户明确要求 recall/check/remember 时必须读
- 用户说 ignore memory 时,就当 memory 为空
## Before recommending from memory
memory 里的内容可能过时。
如果 memory 提到了文件、函数、flag,先验证它现在是否还存在。
如果用户问的是当前状态,优先读代码和当前仓库状态,而不是盲信 memory。
## Memory and other forms of persistence
不要把 plan、task、当前会话临时状态存进 memory。
plan 用来记录方案,tasks 用来跟踪当前工作,memory 留给未来会话仍有价值的东西。
## Searching past context
如果要找历史上下文:
1. 先搜 memory topic files
2. 实在不够再搜 transcript jsonl
受篇幅有限,记忆的压缩、提取、召回我们下一篇再详细展开说说。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)