08. 从入门到进阶:RAG系统核心痛点剖析与Advanced RAG优化实战
摘要:本文深入探讨了如何利用LangServe部署复杂的RAG(检索增强生成)应用。文章首先分析了RAG系统在索引构建和检索增强两个阶段的关键痛点,包括内容缺失、文档切分难题、检索召回不足等问题。针对这些痛点,提出了基础优化策略和进阶的AdvancedRAG架构解决方案。AdvancedRAG通过预检索阶段的索引优化、查询优化,检索阶段的混合检索,以及后检索阶段的结果精炼,全方位提升系统性能。文章强调优秀的RAG系统需要根据业务场景精心设计和持续迭代,为开发者提供了构建智能问答系统的实用指导。
引言
在探索大模型应用开发的道路上,我们常常会遇到一个痛点:如何将精心设计的 LangChain 逻辑快速、优雅地暴露为可供前端或其他服务调用的 API?手动编写 FastAPI 路由不仅繁琐,还容易出错。
在上一篇文章中,我们介绍了 LangServe 这一利器,它完美地解决了这个问题。通过 add_routes 这一行核心代码,LangServe 能够自动将你的 LangChain 组件(如 LLMChain)挂载到 FastAPI 应用中,并自动生成包含 /invoke(同步调用)和 /stream(流式输出)在内的完整 API 端点。这不仅极大地简化了开发流程,让我们能专注于核心的 AI 逻辑,还能零成本获得交互式 API 文档,并且无缝支持添加安全认证等进阶功能。
今天,我们将在此基础上更进一步,深入探讨如何利用 LangServe 部署更为复杂的 RAG(检索增强生成)应用,解锁其在真实业务场景中的强大潜力。
一、RAG系统全流程痛点分析
一个标准的RAG流程可以分为两个主要阶段:索引构建(Index Process) 和 检索增强(Query Process)。每个阶段都潜藏着影响最终效果的关键问题。
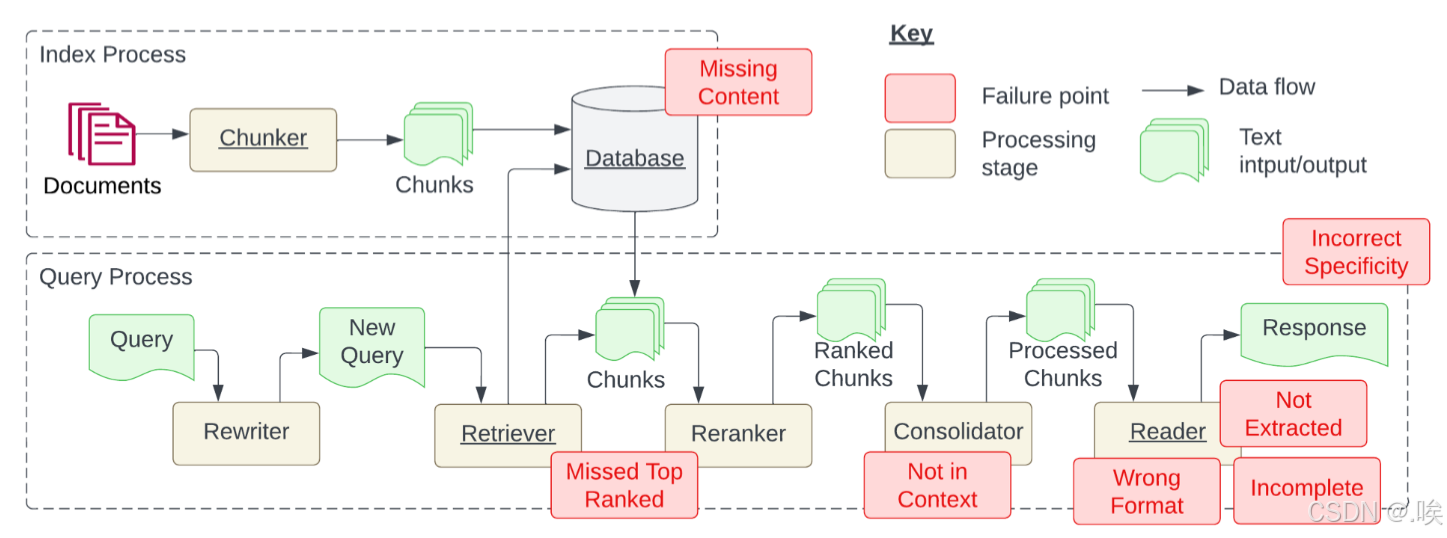
1. 索引构建阶段(Offline)
- 内容缺失(Missing Content):这是最根本的问题。如果知识库中压根就没有问题的答案,再强大的模型也无能为力。
- 文档加载的准确性与效率:现实世界的数据格式五花八门(PDF、Word、扫描件等),如何高效、准确地从中提取出有价值的文本和结构化信息(如表格),是保证后续流程质量的前提。
- 文档切分的粒度难题:文本切块过大,会引入大量无关噪声,稀释关键信息;切块过小,又可能破坏语义的完整性,导致上下文断裂。如何找到那个“恰到好处”的平衡点?
2. 检索增强阶段(Online)
- 错过排名靠前的文档(Missed Top Ranked):向量检索返回的Top-K结果并非总是最优。有时,排名第6的相关文档才是问题的关键,但它被无情地忽略了。
- 提取上下文与答案无关(Not in Context):检索到的文档看似相关,但其中并不包含问题的答案,导致模型只能“胡编乱造”。
- 格式错误(Wrong Format):当要求模型输出特定格式(如JSON、XML)时,它可能会返回纯文本,破坏下游系统的解析逻辑。
- 答案不完整(Incomplete):对于复合型问题,模型可能只回答了其中一部分,遗漏了其他要点。
- 未提取到答案(Not Extracted):检索到的上下文中明明有答案,但模型却视而不见,未能将其提炼出来。
- 答案不够具体或过于具体(Incorrect Specificity):模型的回答要么太过笼统,缺乏细节;要么钻入牛角尖,忽略了问题的整体意图。
二、基础优化策略:对症下药
针对上述痛点,我们可以采取一系列针对性的优化措施:
- 内容缺失:扩充知识库、进行严格的数据清洗,并通过精心设计的Prompt约束模型行为(如“若知识库中无答案,请明确告知用户”)。
- 文档加载与切分:为不同格式文档定制解析器;采用基于结构的分块、递归分块或内容重叠分块等策略,以保留语义完整性。
- 检索召回不足:适当增加
topK值,或引入重排(Reranking) 技术对初步检索结果进行二次精排。 - 格式与完整性问题:通过Prompt调优、结果格式验证(如Pydantic)甚至自动修复(Auto-Fixing) 来保证输出规范;对于复杂问题,可采用问题分解策略,化整为零。
- 答案提取失败:选用更强的基座模型,并在Prompt中强调“必须基于上下文作答”,或对关键信息进行加粗等聚焦处理。
三、进阶之道:Advanced RAG架构详解
当基础优化无法满足业务需求时,我们就需要引入更强大的Advanced RAG架构。它不再局限于简单的“检索-生成”两步走,而是将整个流程细分为预检索(Pre-Retrieval)、检索(Retrieval) 和后检索(Post-Retrieval) 三个阶段,进行全方位优化。
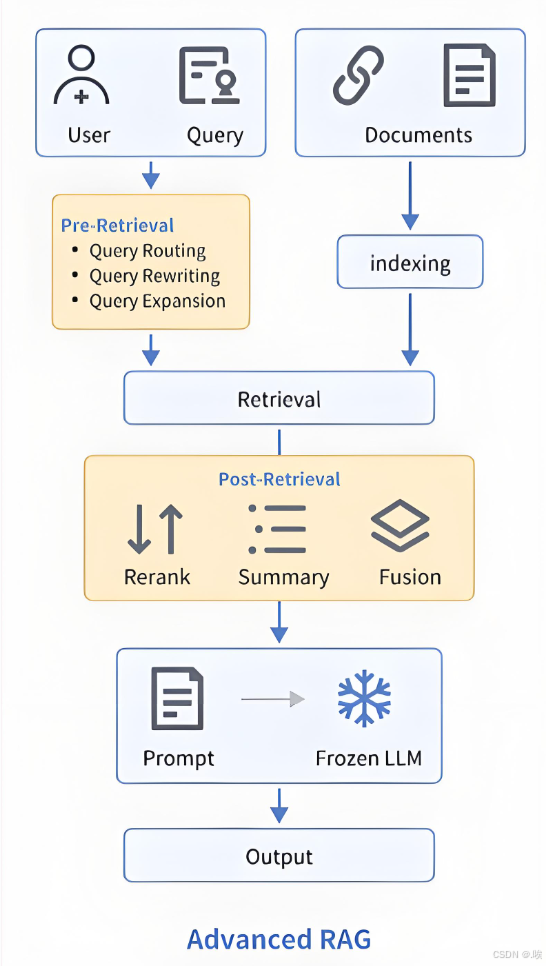
1. 预检索阶段:索引优化
此阶段的核心思想是在离线构建索引时,就为未来的高效、精准检索打下坚实基础。
- 摘要索引(Summary Indexing):让LLM为每个文档块生成摘要,并用摘要向量进行检索。这种方式特别适合处理长文档、高密度内容(如含表格的PDF),能显著提升检索速度和准确性,是工业级RAG的标配。
- 父子索引(Parent-Child Indexing):巧妙地解决了“小块利于检索,大块利于生成”的矛盾。检索时使用小的“子块”向量,召回后再聚合回大的“父块”作为上下文,兼顾了精度与完整性。
- 假设性问题索引(Hypothetical Question Indexing):让LLM为每个文档块生成多个可能的提问(假设性问题),并用这些问题的向量建立索引。这使得用户无论用何种方式提问,只要语义相近,都能被精准匹配,极大提升了召回率。
- 元数据索引(Metadata Indexing):为文档块添加标签(如来源、类型、日期等)。检索时先根据问题推理出所需元数据进行粗筛,再进行向量检索,有效避免了不同领域知识的相互干扰。
2. 预检索阶段:查询优化
在用户发起请求后、正式检索前,对查询本身进行智能优化。
- Enrich(完善问题):将用户口语化、模糊的提问,通过LLM提炼、补充和规范化,转化为一个语义完整、适配检索的标准问句。
- Multi-Query(多路召回):利用LLM从不同角度生成多个相关子问题,然后并行检索,最后合并结果。这能有效覆盖用户问题的多种表达形式,防止遗漏。
- Decomposition(问题分解):将复杂的复合问题拆解成一系列独立的子问题,通过并行或串行的方式逐一解决,最后整合答案,赋予RAG系统“推理”能力。
3. 检索阶段:混合检索
摒弃单一的向量检索,转而采用混合检索(Hybrid Search) 策略。将用户的查询同时送入向量检索器和关键词/全文检索器,取长补短,既能捕捉语义相似性,又能保证精确匹配。
4. 后检索阶段:结果精炼
在得到初步检索结果后,进行最后的“质检”和“提纯”。
- RAG Fusion:在Multi-Query的基础上,使用倒数排名融合(Reciprocal Rank Fusion) 等算法对来自多个查询的结果进行智能重排序,确保最相关的文档排在最前面。
- 上下文压缩与过滤:对于检索到的大块文档,利用查询本身作为指导,只提取其中与问题直接相关的句子或片段,去除冗余信息。这不仅能节省宝贵的LLM token,还能显著提升生成答案的质量。
四、总结
RAG技术虽然强大,但绝非开箱即用的银弹。从基础的文档切分、Prompt工程,到进阶的Advanced RAG架构,每一步都需要开发者深入理解其背后的原理,并根据具体的业务场景进行精心的设计和调优。
希望本文对RAG痛点的系统梳理和对Advanced RAG优化方案的详细解读,能为你在构建下一代智能问答系统的道路上提供清晰的指引。记住,优秀的RAG系统是“磨”出来的,而非“搭”出来的。不断实践、分析、迭代,方能打造出真正令人惊艳的产品。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)