CrewAI 多智能体协作实战:用 4 个 AI Agent 搭建自动化科研助手 — 从论文选题到初稿全流程
CrewAI多智能体协作实战教程,搭建4个AI Agent协作的自动化科研助手系统。包含Agent角色定义、Task任务编排、Crew协作流程、工具集成、LLM配置等完整Python代码,所有代码可直接运行。
·
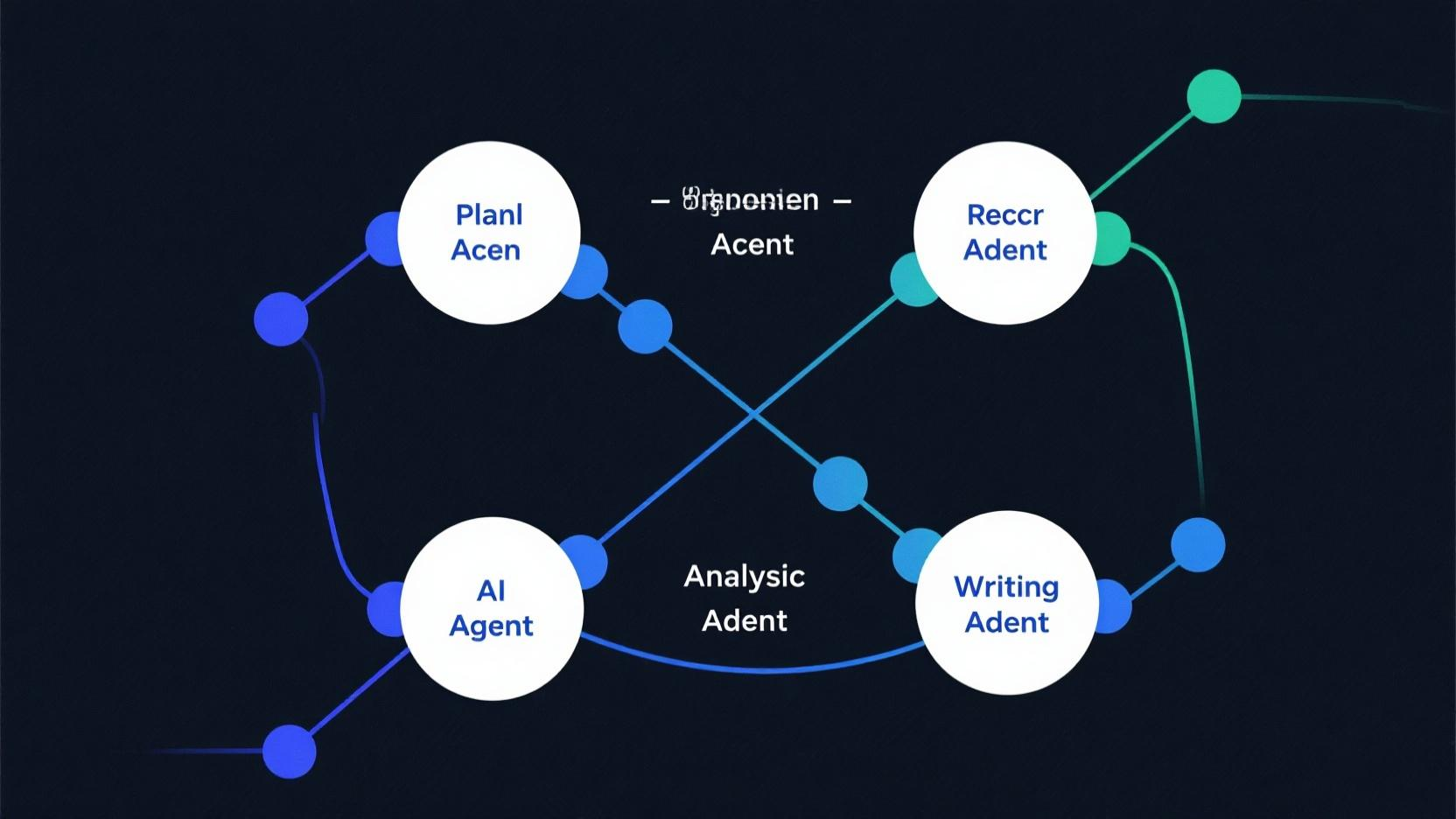
单个 AI Agent 做不了复杂的事。写一篇合格的综述论文,需要先规划大纲、再查文献、再分析数据、最后写作——一个人的脑子搞不定,一个 Agent 更搞不定。
多智能体系统就是把这件事拆给多个 AI Agent 各司其职。Gartner 把 Multi-Agent Systems 列为 2026 年十大战略技术趋势之一,不是没有道理。
这篇文章用 CrewAI 框架搭一个科研助手团队——4 个 Agent 协作完成从选题到初稿的全流程。核心代码 200 行,跑一遍你就知道 Agent 之间怎么协作。
1. 环境搭建
pip install crewai crewai-tools langchain-community
pip install openai python-dotenv arxiv
# config.py
import os
from dotenv import load_dotenv
load_dotenv()
LLM_CONFIG = {
"model": "deepseek-chat",
"api_key": os.getenv("DEEPSEEK_API_KEY"),
"base_url": "https://api.deepseek.com/v1",
"temperature": 0.7,
"max_tokens": 4096,
}
2. 定义 4 个 Agent 角色
每个 Agent 有自己的角色、目标、背景故事和可用工具。这是 CrewAI 最核心的设计。
# agents.py — Agent 角色定义
from crewai import Agent, Task, Crew, Process, LLM
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
from langchain_community.tools.arxiv.tool import ArxivQueryRun
# ── 1. 规划师 Agent ──
planner = Agent(
role="科研规划师",
goal="根据研究主题制定详细的论文大纲,拆解为可执行的子任务",
backstory=(
"你是一位资深学术导师,擅长将模糊的研究想法"
"转化为清晰的研究框架和可执行步骤。"
"你必须输出结构化的研究大纲(章节、小节、核心论点)。"
),
llm=LLM(**LLM_CONFIG),
verbose=True,
allow_delegation=True, # 可以把子任务委托给其他 Agent
)
# ── 2. 文献检索 Agent ──
searcher = Agent(
role="文献检索专家",
goal="从 arXiv 等学术数据库检索最相关、最新的论文,提取核心发现",
backstory=(
"你是一个文献综述专家,精通信息检索和文献管理。"
"你能快速定位领域内的关键论文,并用两句话概括每篇论文的核心贡献。"
"你无法容忍不精确的表述,会标注每篇论文的 arXiv ID 和发表年份。"
),
tools=[ArxivQueryRun(), SerperDevTool(), ScrapeWebsiteTool()],
llm=LLM(**LLM_CONFIG),
verbose=True,
)
# ── 3. 数据分析 Agent ──
analyst = Agent(
role="数据分析师",
goal="整合和对比多篇论文的方法与结果,识别研究趋势和空白",
backstory=(
"你擅长从大量论文中提取可对比的维度(方法、数据集、指标),"
"制作对比表格,并识别出研究 GAP。"
"你的分析总是基于具体数字和实验数据,不泛泛而谈。"
),
llm=LLM(**LLM_CONFIG),
verbose=True,
allow_delegation=False, # 分析师不委派,专注自己分析
)
# ── 4. 学术写作 Agent ──
writer = Agent(
role="学术写作者",
goal="将研究大纲和文献分析结果转化为流畅的学术论文章节",
backstory=(
"你是一位发表过 20+ 篇顶会的资深学术写作者。"
"你擅长用清晰的学术语言呈现复杂概念,遵循学术写作规范。"
"你的文章逻辑严密、过渡自然、引用精确。"
"你会严格遵循规划师提供的大纲结构。"
),
llm=LLM(**LLM_CONFIG),
verbose=True,
)
3. 编排任务流程
任务之间可以定义依赖关系——比如「分析」必须在「检索」完成后才能开始。
# tasks.py — 任务编排
from crewai import Task
def create_research_tasks(topic: str):
"""根据研究主题创建任务链"""
# ── Task 1: 规划 ──
plan_task = Task(
description=(
f"为研究主题「{topic}」制定一个详细的学术论文大纲。\n"
f"大纲必须包含:\n"
f"1. 引言(研究背景、问题陈述、贡献)\n"
f"2. 相关工作(至少 3 个研究方向)\n"
f"3. 方法论(如果有的话)\n"
f"4. 实验分析(对比关键方法和指标)\n"
f"5. 结论与未来方向\n"
f"每个章节列出 2-3 个小节标题和核心论点。"
),
expected_output="结构化的论文大纲,包含章节标题、小节标题和每部分的核心论点",
agent=planner,
)
# ── Task 2: 检索(依赖 plan_task) ──
search_task = Task(
description=(
f"基于规划师提供的大纲,从 arXiv 检索「{topic}」相关的论文。\n"
f"要求:\n"
f"- 检索范围:2024-2026 年的论文\n"
f"- 数量:每个子方向至少 3 篇\n"
f"- 输出格式:论文标题 | 作者 | 年份 | arXiv ID | 核心贡献(2句话)\n"
f"- 优先检索高引用论文和最新突破性工作"
),
expected_output="按研究方向分类的论文列表,每篇包含标题、作者、年份、arXiv ID 和核心贡献摘要",
agent=searcher,
context=[plan_task], # 依赖规划输出
)
# ── Task 3: 分析(依赖 search_task) ──
analyze_task = Task(
description=(
f"基于检索到的论文列表,对「{topic}」领域进行系统分析。\n"
f"请输出:\n"
f"1. 关键方法对比表(方法名、核心思路、优缺点、代表论文、关键指标)\n"
f"2. 研究趋势总结(2-3 个主要发展方向)\n"
f"3. 研究空白识别(至少 2 个可探索的方向)\n"
f"4. 未来工作建议"
),
expected_output="包含对比表格、趋势总结、研究空白和未来工作建议的分析报告",
agent=analyst,
context=[search_task],
)
# ── Task 4: 写作(依赖所有前置任务) ──
write_task = Task(
description=(
f"基于规划师的大纲、检索结果和分析报告,"
f"撰写「{topic}」论文的完整初稿。\n"
f"要求:\n"
f"- 严格遵循大纲结构\n"
f"- 每处观点必须有引用(引用格式:[Author, Year, arXiv:xxxx.xxxxx])\n"
f"- 分析报告中提到的对比表格要嵌入正文\n"
f"- 总字数 3000-5000 字\n"
f"- 学术语言,但避免过度使用被动语态\n"
f"- 在 conclusion 中明确指出未来的研究方向"
),
expected_output="完整的论文初稿,包含所有章节、引用和对比表格",
agent=writer,
context=[plan_task, search_task, analyze_task],
)
return [plan_task, search_task, analyze_task, write_task]
4. 启动 Crew 协作
# crew_run.py — 启动多 Agent 协作
from crewai import Crew, Process
def run_research_pipeline(topic: str):
tasks = create_research_tasks(topic)
crew = Crew(
agents=[planner, searcher, analyst, writer],
tasks=tasks,
process=Process.sequential, # 顺序执行(也可用 hierarchical)
verbose=True,
memory=True, # 启用跨任务记忆
planning=True, # CrewAI 自动规划优化
max_rpm=20, # 每分钟最大 API 调用数(限速保护)
)
print(f"\n{'='*60}")
print(f"开始研究: {topic}")
print(f"{'='*60}\n")
result = crew.kickoff()
print(f"\n{'='*60}")
print("研究完成!")
print(f"总使用 token: {crew.usage_metrics}")
print(f"{'='*60}")
return result
# ── 运行 ──
if __name__ == "__main__":
topic = "Large Language Model based Agents: Planning, Tool Use, and Memory"
output = run_research_pipeline(topic)
# 保存结果
with open(f"research_output_{topic[:30]}.md", "w", encoding="utf-8") as f:
f.write(str(output))
5. 自定义工具:让 Agent 能做的事更多
CrewAI 内置的工具有限。但你可以轻松封装自己的 Tool:
# custom_tools.py — 自定义 Agent 工具
from crewai_tools import tool
import requests
@tool("ReadPaperTool")
def read_paper(arxiv_id: str) -> str:
"""读取 arXiv 论文的摘要和元信息"""
url = f"http://export.arxiv.org/api/query?id_list={arxiv_id}"
resp = requests.get(url, timeout=10)
return resp.text[:2000] # 截取前 2000 字符
@tool("CompareResultsTool")
def compare_results(paper1_id: str, paper2_id: str) -> str:
"""对比两篇论文的实验结果和指标"""
# 实际实现:拉取两篇论文的摘要,用 LLM 提取对比维度
p1_abstract = read_paper(paper1_id)
p2_abstract = read_paper(paper2_id)
return f"Paper 1 ({paper1_id}):\n{p1_abstract[:500]}\n\nPaper 2 ({paper2_id}):\n{p2_abstract[:500]}"
# 使用时直接放进 Agent 的 tools 列表
searcher.tools.append(read_paper)
analyst.tools.append(compare_results)
6. 层次化协作 vs 顺序协作
CrewAI 支持两种协作模式:
# Process.sequential — 顺序执行(任务依次执行,结果传递)
crew_seq = Crew(
agents=[planner, searcher, analyst, writer],
tasks=tasks,
process=Process.sequential,
)
# Process.hierarchical — 层次化执行(指定一个 Agent 作为管理者,动态委派任务)
crew_hier = Crew(
agents=[planner, searcher, analyst, writer],
tasks=tasks,
process=Process.hierarchical,
manager_llm=LLM(**LLM_CONFIG), # 管理者用更好的模型
)
区别: - 顺序模式适合流程固定的场景(论文写作、数据处理流水线) - 层次化模式适合需要动态决策的场景(自动化客服、持续问题排查)
踩坑笔记
- token 消耗远超预期 — 4 个 Agent 跑一轮,每个 Agent 都有 system prompt + 角色描述 + 任务描述 + 上下文。我实测一次完整 run 大约消耗 15K-25K token。调 verbose=True 看看每个 Agent 实际说了什么,发现无效输出立刻优化 prompt。
- Agent 之间的上下文传递容易丢 —
context=[plan_task]传递的是这个 task 的完整输出。如果输出很长,后面的 Agent 可能忽略关键信息。解决办法:在 Task 的expected_output里约束输出格式和长度。 - ArXiv API 有时超时 —
ArxivQueryRun()底层调的是 arxiv.org 的 API,偶尔 10s+ 不返回。加timeout参数,或者用 SerperDevTool 搜索结果里的 PDF 链接做 fallback。 - 深度求索 API 偶发 503 — DeepSeek 在晚高峰时段会返回 service overload。CrewAI 有内置重试,但建议在非高峰时段跑长流程。
金句
"多智能体系统的本质不是让一个 AI 更强——而是让多个 AI 各司其职之后,整个系统的协作质量超过单个 AI 的上限。"
还有什么场景你想用多 Agent 搞定?评论区说说你的需求,我帮你设计 Agent 角色和任务编排。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 4
4 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)