转载--AI Agent 架构设计:工具描述怎么写——名字、边界、错误消息决定 Agent 稳不稳(OpenClaw、Claude Code、Hermes Agent 对比)
摘要:Anthropic发布的工具设计指南强调,工具描述对AI模型至关重要,需像prompt工程一样精心设计。指南提出五个核心问题:1)工具命名需明确用途;2)描述需包含"何时不用";3)参数说明要具体;4)限制返回值大小;5)错误消息要有指导性。三大框架(ClaudeCode、OpenClaw、Hermes)对工具设计态度不同,其中ClaudeCode的标准最严格。优化工具描
原文:https://mp.weixin.qq.com/s/hZRTYJQLt2vvjd1vup6sHg
工具不是给人用的,是给模型用的
写传统 API,你在和其他工程师对话。接口文档写得模糊,工程师会去翻代码,会来问你,会自己推断。
工具描述不一样。模型读到工具描述,就必须知道什么时候用它、怎么用它、参数填什么、出了错怎么办。 没有追问的机会,没有翻代码的能力,描述是它唯一的参考。
Anthropic 在 2025 年底发布了一篇工具设计指南,总结了他们在 Claude Code、MCP 生态里踩过的坑。里面有一句话值得记下来:
"工具设计和 prompt 工程一样,需要同等程度的投入。"
这不是客套话。他们在 SWE-bench 的测试里,仅仅通过精调工具描述,就把错误率大幅降低,实现了当时的最优结果。工具描述改得好,比换更强的模型效果更直接。
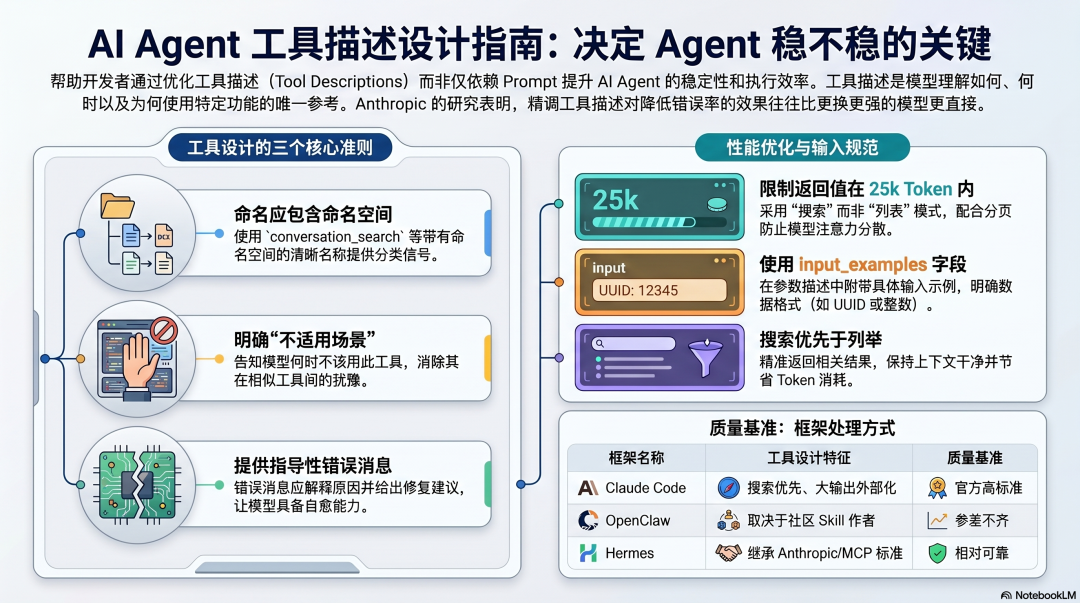
工具设计的五个核心问题
Anthropic 的指南把工具设计总结成五个维度,每个维度都有具体的对错对比。
问题一:工具名字说不说明用途
模型靠工具名字来判断"这个工具大概做什么"。名字含糊,模型要读完整段描述才能判断;名字清楚,模型扫一眼就知道。
差的命名:
chatget_conversationlist_conversations
好的命名:
agent_chatconversation_getconversation_search
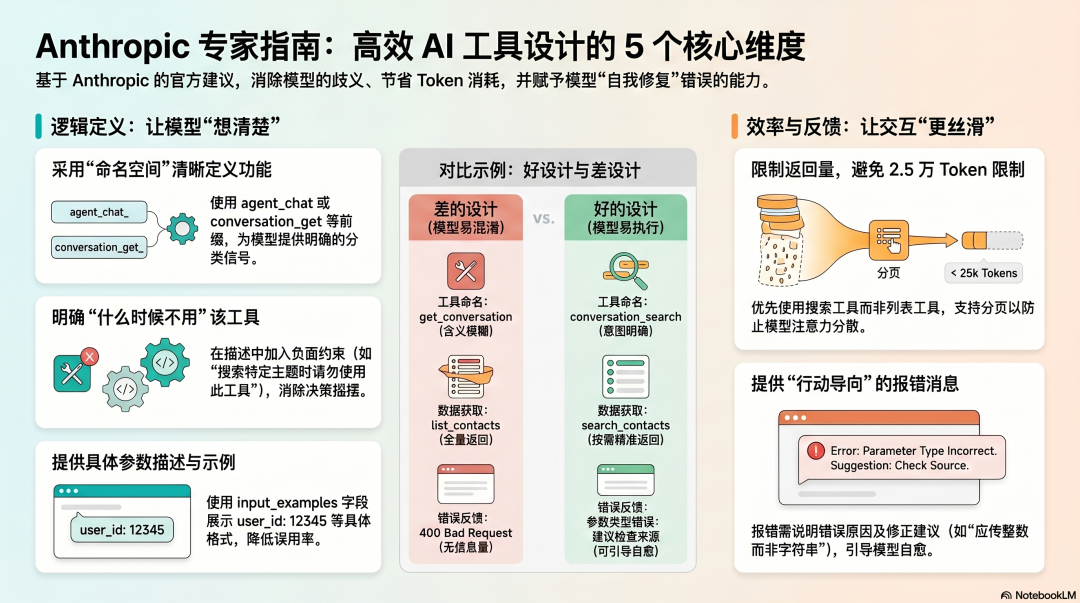
加上命名空间(agent_、conversation_),不只是让名字更清楚,还给了模型一个隐含的分类信号——这几个工具属于同一个领域,功能上有关联。
Anthropic 的测试发现,命名空间对评估结果有"不可忽视的影响",而且效果因模型而异。换了一个模型,同样的命名方案可能产生不同的效果。这意味着工具命名需要针对你用的模型来测试,而不是凭直觉定好就不改。
问题二:描述里有没有说清楚"什么时候不用"
大多数人写工具描述,只写"这个工具做什么"。但对模型来说,"什么时候不该用"和"什么时候该用"一样重要。
没有边界描述,模型会在不该用的场景下用这个工具。两个功能相近的工具,模型会摇摆不定,每次选择都不一样。
差的描述:
"获取用户的历史消息"好的描述:
"获取用户最近的对话历史。适用场景:需要回顾最近 5 轮对话内容时。不适用场景:如果需要搜索特定主题或关键词,请使用 conversation_search 而不是这个工具。"
这个"不适用"的说明,直接消除了模型在两个相似工具之间犹豫的情况。
问题三:参数描述够不够具体
参数描述写"用户 ID",模型不知道格式——是数字、UUID、还是邮箱?
写"用户 ID,格式为整数,例如:12345",模型知道怎么填。
这个道理简单,但实际上容易犯的错是:把对工程师清楚的东西当成对模型也清楚。 工程师看到 user_id: int,自然知道填整数。模型需要在参数描述里明确告诉它。
Anthropic 的官方文档里专门提到了 input_examples 字段——可以在工具定义里直接附上示例输入:
"input_examples": [{"user_id": 12345, "limit": 10},{"user_id": 67890, "limit": 5}]
对复杂工具,示例是最直接的"怎么用"说明。代价是每个示例增加 20-200 个 Token,但对降低误用率来说通常值得。
问题四:返回值有没有大小限制
这是最容易被忽视的一个设计问题。
工具返回了 5 万字的内容,全部注入上下文,后续所有推理都要带着这 5 万字。模型的注意力被分散,Token 消耗暴增,Lost in the Middle 问题加剧。
Anthropic 的建议是:限制返回值不超过 25,000 Token,并且支持分页。
response_format: "concise" → 约 500 Token(快,适合快速判断)response_format: "detailed" → 约 2,000 Token(完整,适合需要细节时)
让模型选择"要多少",而不是默认给它所有东西。多数情况下,模型需要的不是完整数据,而是足够做判断的信息。
这也是为什么 Anthropic 推荐"搜索型工具"而不是"列表型工具":
❌ list_contacts → 返回所有联系人✅ search_contacts → 返回匹配查询的联系人
列表工具返回一堆数据,模型再从里面找。搜索工具精准返回相关结果,上下文干净,Token 省。
问题五:错误消息能不能指导下一步
工具失败了,错误消息是模型判断"接下来怎么办"的唯一依据。
差的错误消息:
"Error: 400 Bad Request"好的错误消息:
"参数错误:user_id 必须是整数,当前传入的是字符串 'abc'。建议:检查 user_id 的来源,确认它是从数据库返回的整数 ID,而不是用户输入的邮箱或用户名。"
前者模型只知道"出错了",不知道改什么。后者模型知道哪里错了、为什么错了、怎么修。
好的错误消息,是让模型能够自己修正,而不是把问题抛给用户。
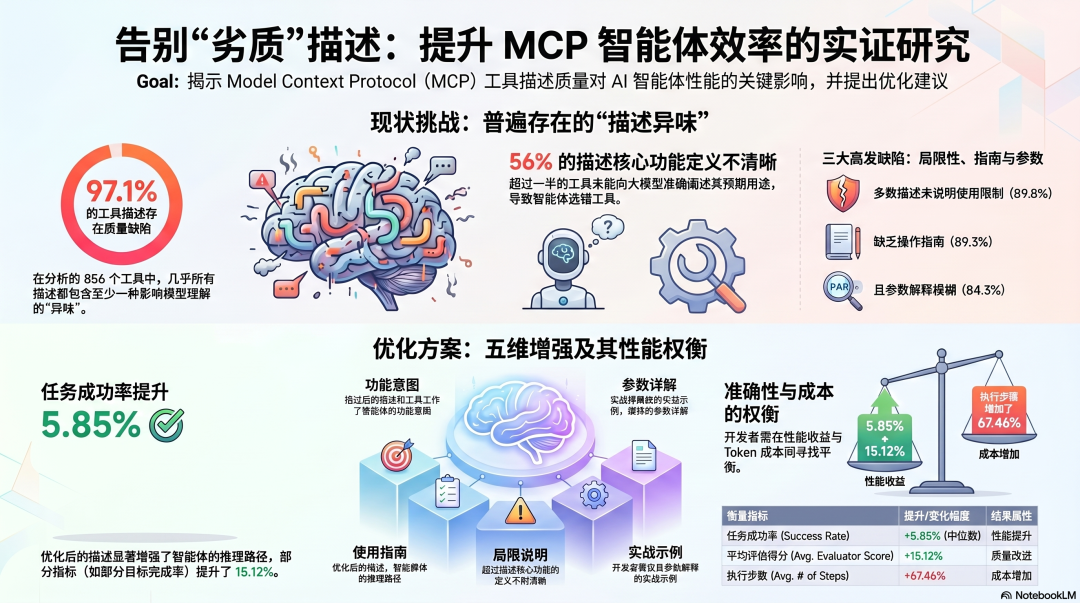
三个框架对工具设计的不同态度
Claude Code:工具是架构核心,设计有官方标准
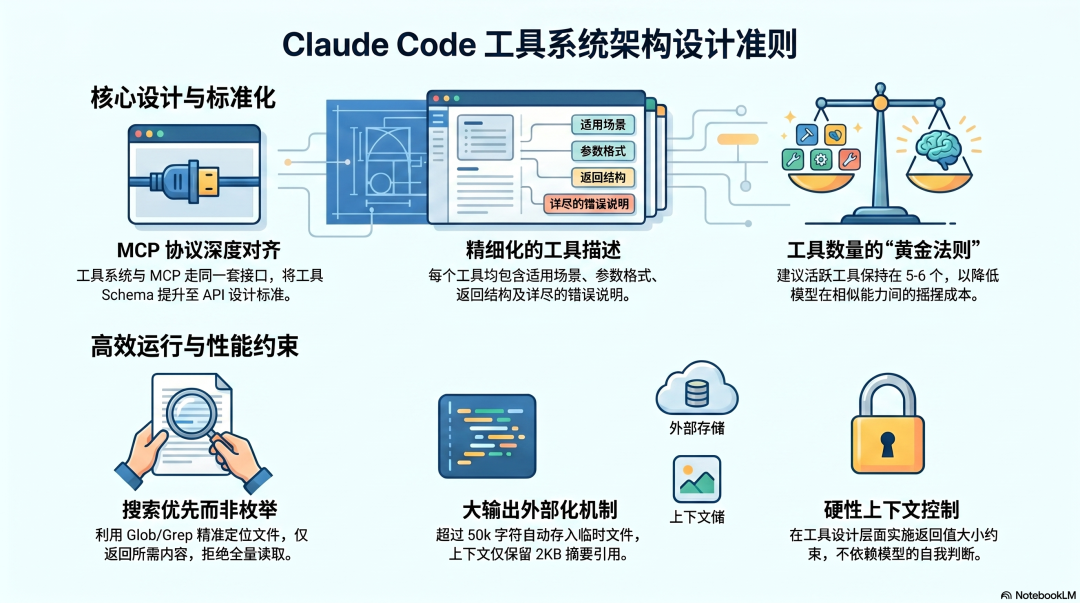
Claude Code 的内置工具——文件读写、Shell 执行、网页抓取——每一个都有精细的描述,包括适用场景、不适用场景、参数格式、返回结构、错误说明。
这不是偶然。Claude Code 的工具系统和 MCP 走的是同一套接口,工具的 schema 就是工具的"说明书",设计标准等同于 API 设计标准。
Claude Code 的工具有两个值得学习的具体设计:
搜索优先,不用列举:Glob 和 Grep 工具让 Agent 能精准定位相关文件,而不是把整个目录的内容一口气读进来。这是"搜索型工具"的实际体现——返回你需要的,不返回你不需要的。
大输出外部化:工具返回内容超过 50,000 字符时,自动写入临时文件,上下文里只注入 2KB 的摘要和引用。这是在工具设计层面对"返回值大小"的强制控制,不依赖模型的判断,是硬性约束。
Claude Code 对外部 MCP 工具也有明确建议:工具数量保持在 5-6 个活跃服务以内,不是因为技术限制,而是工具太多,模型在相似能力之间的摇摆成本超过了工具本身的价值。
OpenClaw:工具描述质量取决于 Skill 作者
OpenClaw 的工具通过 Skills 扩展,ClawHub 上有 31,000+ 个 Skills,每个 Skill 可以定义自己的工具。
问题在于:工具描述的质量完全由 Skill 作者决定,没有统一的设计标准,也没有审核。
你安装了一个质量差的 Skill,工具描述模糊,错误消息没有指导性,模型在调用时就会频繁出问题——误用工具、反复失败、产生意外行为。这个问题你可能会误以为是模型能力不够,但实际上是工具描述写得不好。
OpenClaw 生态里确实有高质量的 Skill,McPorter 等工具也在尝试提升工具描述的规范性。但整体上,这是一个"社区质量参差不齐"的现实问题。
安装 ClawHub 的 Skill 之前,值得花五分钟看一下它的工具描述:名字有没有明确含义,参数有没有格式说明,错误消息有没有指导性。这比看 Star 数更能判断 Skill 的实际质量。
Hermes:内置工具设计合理,MCP 扩展继承 Anthropic 标准
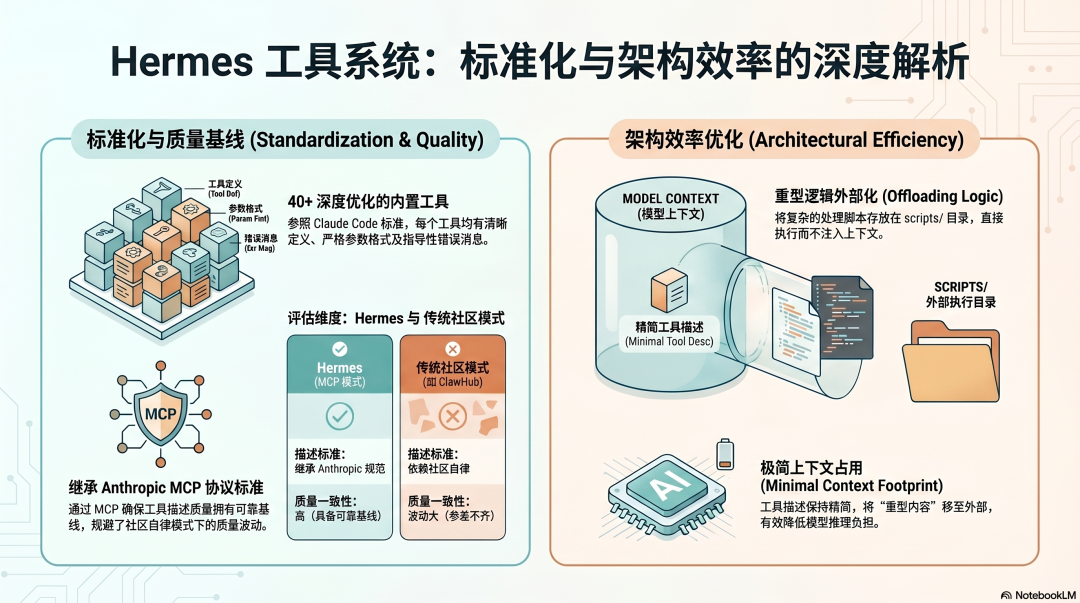
Hermes 的 40+ 内置工具,设计思路和 Claude Code 接近——每个工具有清晰的用途定义,参数有格式说明,错误消息有基本的指导性。
Hermes 的工具扩展主要通过 MCP,而 MCP 的工具描述标准直接继承自 Anthropic 的规范。这意味着:Hermes 接入的 MCP 工具,工具描述的质量有一个相对可靠的基线,不像 OpenClaw 的 ClawHub 那样完全依赖社区自律。
一个值得注意的细节:Hermes 的 Skills 系统里可以附带处理脚本(scripts/ 目录),这些脚本不注入上下文,直接执行。这本质上是把"工具的重型逻辑"从上下文里剥离出来——和 Claude Code 的大输出外部化是同一个设计思路:工具描述保持精简,重型内容放在外面。
一个实用的工具描述模板
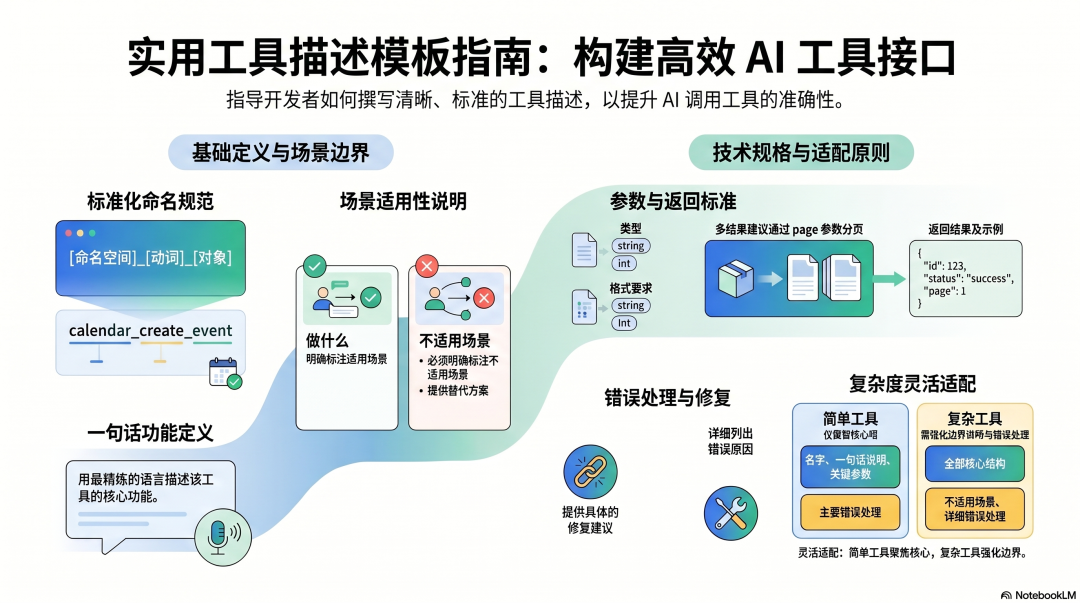
综合 Anthropic 的指南和三个框架的实践,一份好的工具描述应该包含以下内容:
工具名:[命名空间]_[动词]_[对象](例:calendar_create_event、contact_search、file_read_lines)一句话说明:这个工具做什么。适用场景:- 场景 A- 场景 B不适用场景(重要):- X 情况下,请用 [另一个工具] 代替- Y 情况下,直接用 Z 方式更合适参数说明:- param1:[类型],[格式要求],例:[具体示例]- param2:[类型],可选,默认值 [X]返回结果:- 成功:返回 [结构说明],最多 [N] 条- 如果结果太多:使用 page 参数分页获取错误处理:- 错误 A:[原因],建议 [修复方法]- 错误 B:[原因],建议 [修复方法]
这个模板不是要每个工具都写得这么长。简单工具可以精简,只保留名字、一句话说明、关键参数说明和主要错误处理。复杂工具才需要完整的结构,特别是"不适用场景"和"错误处理"这两部分。
工具描述是 Agent 最被低估的基础设施
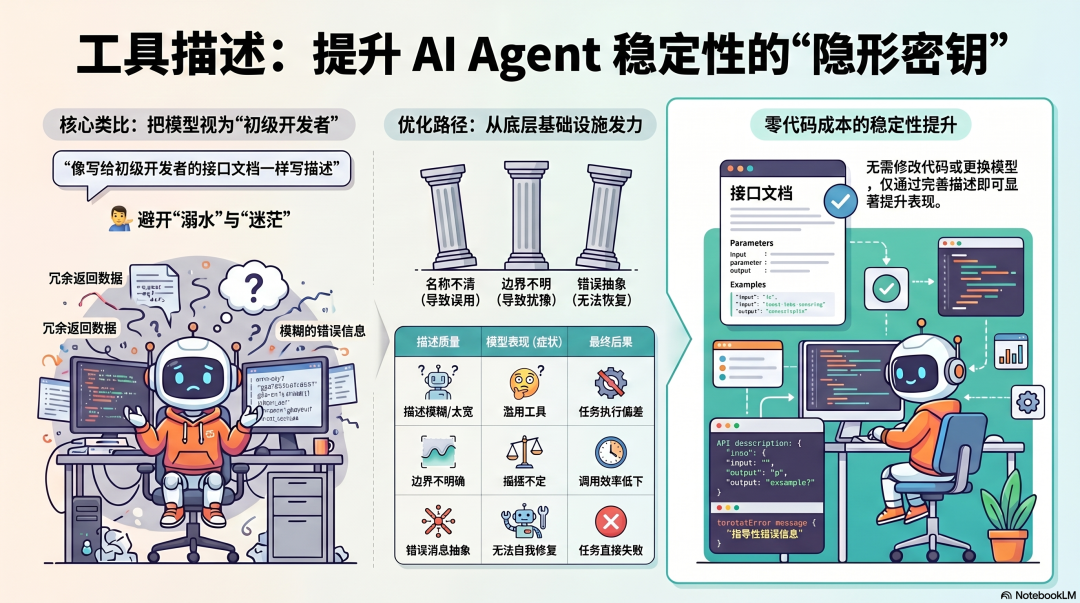
Anthropic 的工程师在指南里写了这样一句话:
"把工具描述当成给初级开发者写的接口文档——写宽了他会滥用,写窄了他不敢用,返回太多他会溺在数据里,错误消息太抽象他不知道怎么修。"
把"初级开发者"换成"语言模型",这句话完全成立。
很多 Agent 在生产中表现不稳定,被归因于模型能力不够、prompt 写得不好、任务太复杂。但相当一部分问题,根源是工具描述写得不够好——名字不清楚导致模型误用,边界不明确导致工具选择摇摆,错误消息没有指导性导致失败后不知道怎么恢复。
工具描述是 Agent 最被低估的基础设施。它不需要改代码,不需要换模型,改几行描述就能让 Agent 的稳定性显著提升。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)