LangChain
此外,LangChain 不断增加对各种 LLM 模型的支持,从最初的 OpenAI API 扩展到 Anthropic、HuggingFace 等模型提供商,以及本地部署的模型(如 Llama 等),并提供了统一的接口来调用这些模型。LangChain 0.1.0 版本(2024 年 1 月发布),也是第一个稳定版本,其引入了 langchain-core 库,其中包含稳定的抽象接口和核心功能,
是连接AI模型和实际AI应用的“桥梁”之一。
AI模型提供了一些原生接口,可以通过API调用来使用;
langchain就类似桥梁,无需通过接口使用模型,优化封装了接口调用。
核心问题即,如何让大模型不仅是一个百科全书,而成为一个能行动,能思考,能融入我们业务流程的智能伙伴。Agent
(Langchain让我们更好使用AI模型。)
- 深入理解大模型的工作原理与核心能力边界
- 认识他的固有缺陷,如“幻觉”问题
- 建立思维框架,思考如何将问题翻译成大模型才能懂的语言
模型
模型是一个从数据中学习规律的“数学函数”或“程序”。
- 特定任务:一个模型通常只擅长一件事。
- 需要“标注数据”:
- 参数较少:
大模型(大语言模型Large Language Model,LLM)
不仅只能处理一件事情。大模型是基于大模型神经网络(参数规模通常达数十亿至万亿级别,例如GPT-3包含1750亿参数),通过自监督或半监督方式,对海量文本进行训练的的语言模型。
神经网络:一个极其高效的“团队工作流程”或“条件反射链”。神经网络模仿人脑的工作方式,神经元一层层传递组合信息判断。
例如教⼀个⼩朋友识别猫:
不会只给⼀条规则(⽐如“有胡⼦就是猫”),因为兔⼦也有胡⼦。
我们会让他看很多猫的图⽚,他⼤脑⾥的视觉神经会协同⼯作:
- 有的神经元负责识别“尖⽿朵”,
- 有的负责识别“胡须”,
- 有的负责识别“⽑茸茸的尾巴”。
这些神经元⼀层层地传递和组合信息,最后⼤脑综合判断:“这是猫!”
- 由大量虚拟的“神经元”(也就是参数)和连接组成。
- 每个神经元都像一个小处理单元,负责处理一点点信息,无数个神经元分成很多层,前一层的输出作为后一层的输入。
- 通过海量数据的训练,这个网络会自己调整每个“神经元”的重要性(即参数的值),最终形成一个非常复杂的“判断流水线”。比如,一个识别猫的神经网络,某些参数可能专门负责识别猫的眼睛,另一些参数专门负责识别猫的轮廓。
简单来说,神经网络就是一个通过数据训练出来的,由大量参数组成的复杂决策系统。
自监督学习:“完形填空”超级大师
例如我们想学会⼀⻔外语,但没有⽼师给出题和批改。怎么办?
- 我们可以拿⼀本该语⾔的⼩说,⾃⼰玩“完形填空”:随机盖住⼀个词,然后根据上下⽂猜测这个词是什么。
- ⼀开始猜得乱七⼋糟。
- 但不断地重复这个过程,看了成千上万本书后,对这个语⾔的语法、词汇搭配、上下⽂逻辑了如 指掌。现在不仅能轻松猜对被盖住的词,甚⾄能⾃⼰写出流畅的⽂章。
⾃监督学习就是这个过程。
- 模型⾯对海量的、没有标签的原始⽂本(⽐如互联⽹上的所有⽂章、⽹⻚)。
- 它⾃⼰给⾃⼰创造任务:把⼀句话中间的某个词遮住,然后尝试根据前后的词来预测这个被遮住 的词。
- 通过亿万次这样的练习,模型就深刻地学会了语⾔的规律。它不需要⼈类⼿动去给每句话标 注“这是主语”、“这是谓语”。
简单说:⾃监督就是让模型从数据本⾝找规律,⾃⼰给⾃⼰当⽼师。
半监督学习:“师父领进门,修行在个人”
先⽤少量带标签的数据让模型“⼊⻔”,掌握⼀些基本规则,然后再让它去海量的⽆标签数据中⾃我 学习和提升。这对于⼤语⾔模型来说也是⼀种常⽤的训练⽅式。
简单说:半监督就是“少量指导+⼤量⾃学”的结合模式。
语言模型:一个“超级自动补全”或“语言预测器”
语⾔模型的核⼼任务就是预测下⼀个词。⼀个强⼤的语⾔模型,能够根据⼀段话,预测出最合理、最通顺的下⼀个词是什么,这样⼀个个词接下去,就能⽣成⼀整段话、⼀篇⽂章。
简单说:语⾔模型就是⼀个计算“接下来最可能说什么”的模型。
现在,我们再回头看那段描述,就一目了然了。翻译成大白话就是: ⼤语⾔模型是⼀个:
- ⽤“超级团队⼯作流程”(⼤规模神经⽹络)搭建的,拥有数百亿甚⾄上万亿个“脑细胞”(参 数的“超级⾃动补全系统”(语⾔模型)。
- 它学习的⽅式,主要是通过⾃⼰玩“海量完形填空”(⾃监督学习),或者“少量名师指导+海量 ⾃学”(半监督学习)……
- 从互联⽹上所有的⽂本数据中学会了语⾔的规律。
因此,它具有以下几个核心特点:
- 规模巨⼤:它的“脑细胞”(参数)特别多(通常达到数⼗亿甚⾄万亿级别),所以思考问题更复 杂、更全⾯,就像⼀⽀百万⼤军和⼀个⼩分队的区别。
- 通⽤性强:它不是为单⼀任务训练的。因为它通过“完形填空”学会的是整个语⾔世界的底层规律 (语法、逻辑、知识关联),而不是只背会了“猫的图⽚”。所以它能举⼀反三,把底层能⼒灵活 应⽤到聊天、翻译、写代码等各种任务上。这种“涌现”能⼒,就像孩⼦通过⼤量阅读后,突然能 写出意想不到的优美句⼦⼀样。
- 训练⽅式不同:主要使用自监督学习,从海量⽆标注的原始⽂本中学习。它不依赖⼈⼯⼀张张地给 图⽚标“这是猫”,而是直接从原始文本中⾃学,效率极⾼,规模可以做得⾮常⼤。
- 交互⽅式⾰命:我们不用点按钮、写代码,直接像对⼈说话⼀样给它指令(Prompt)它就能听懂 并执行,比如你直接说“写⼀⾸关于春天的诗”,它就能给你写出来。
主流的大语言模型
括号里是厂商。。
- GPT-5(OpenAI):支持400k背景信息长度,128k最大输出标记,在多轮复杂推理、创意写作中表现突出
- DeepSeekR1(深度求索):开源,专注于逻辑推理与数学求解,支持128K长上下文和多语言(20+语言),在科技领域表现突出
- Qwen2.5-72B-Instruct(阿里巴巴):通义千问开源模型家族重要成员,擅长代码生成结构化数据(如JSON)处理角色扮演对话等,尤其适合企业级复杂任务,支持包括中文英文法语等29种语言
- Gemini 2.5 Pro(Google):多模态融合标杆,支持图像/代码/文本混合输入,适合跨模态任务(如图文生成、技术文档解析)
其他参考:HuggingfaceLLM性能排行榜:https://huggingface.co/spaces/ArtificialAnalysis/LLMPerformance-Leaderboard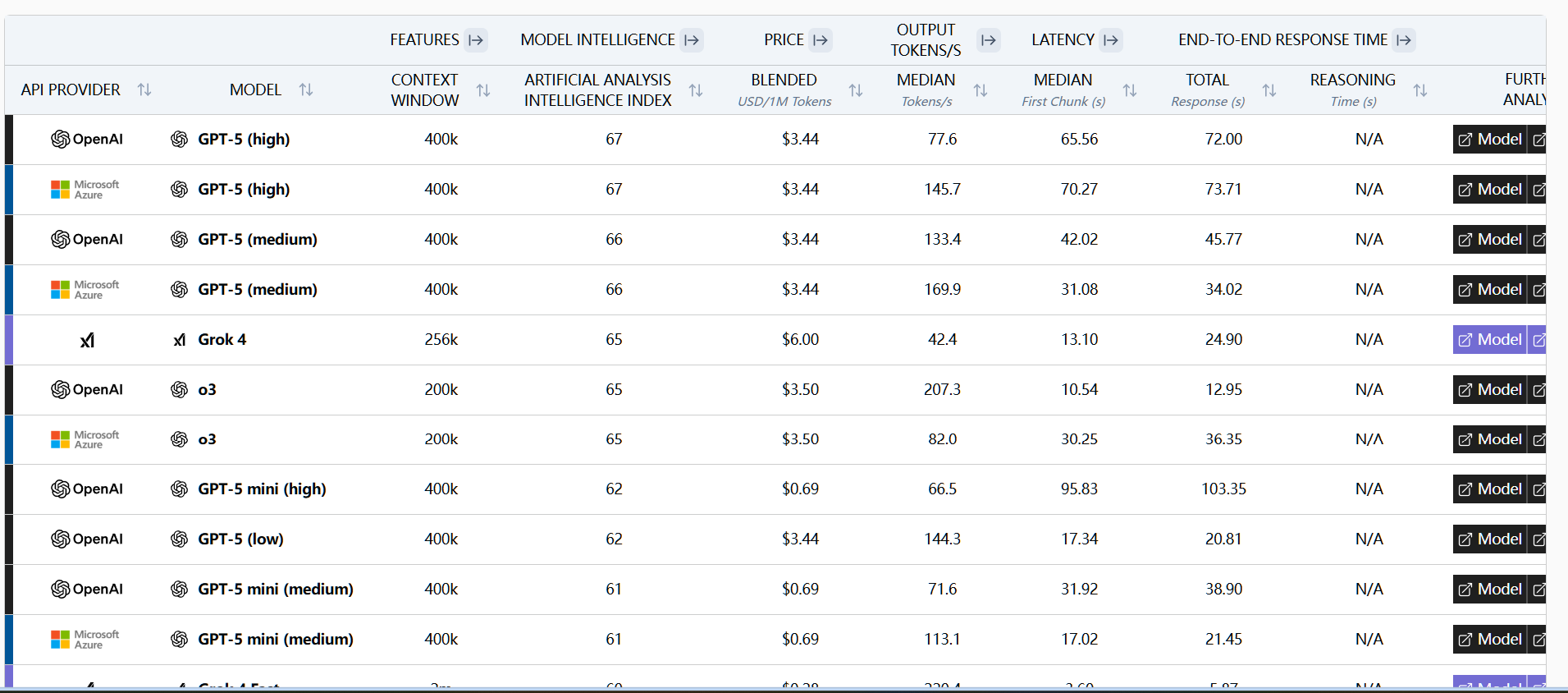
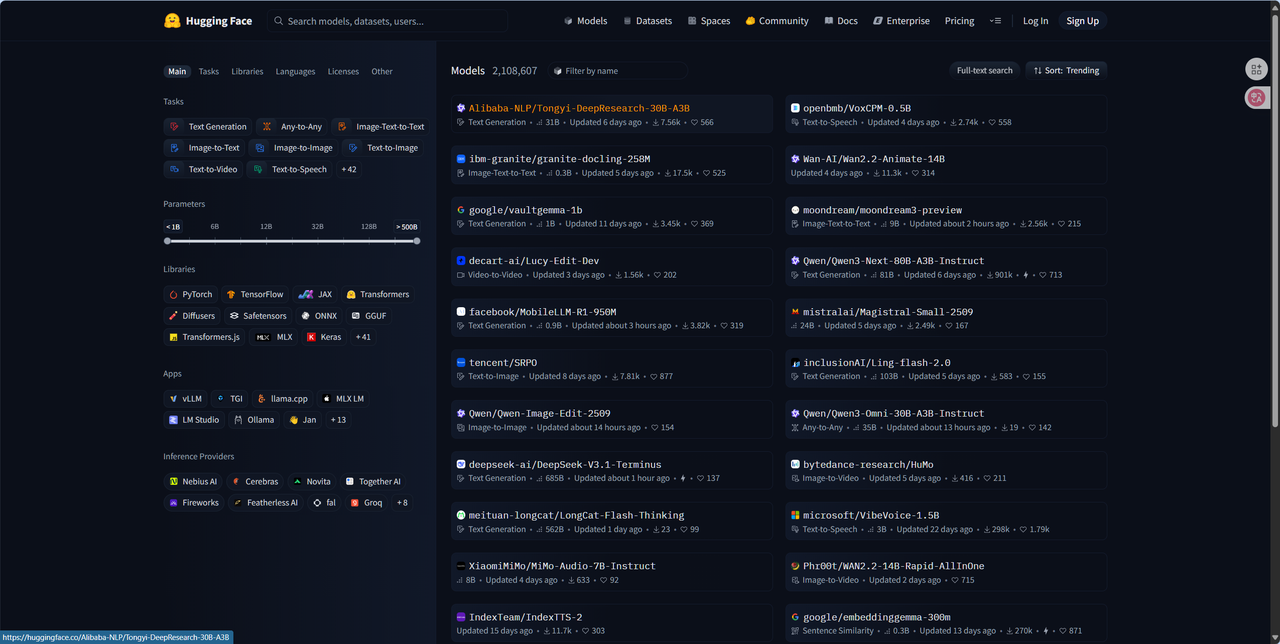
Hugging Face(国外)
Hugging Face是一个知名的开源库和平台,该平台以其强大的Transformer模型库和易用的应用程序编程接口而闻名,为开发者和研究人员提供了丰富的预训练模型、工具和资源。对于从事人工智能研究的人来说,其重要性不亚于GitHub。
官网:https://huggingface.co/魔搭社区(国内)
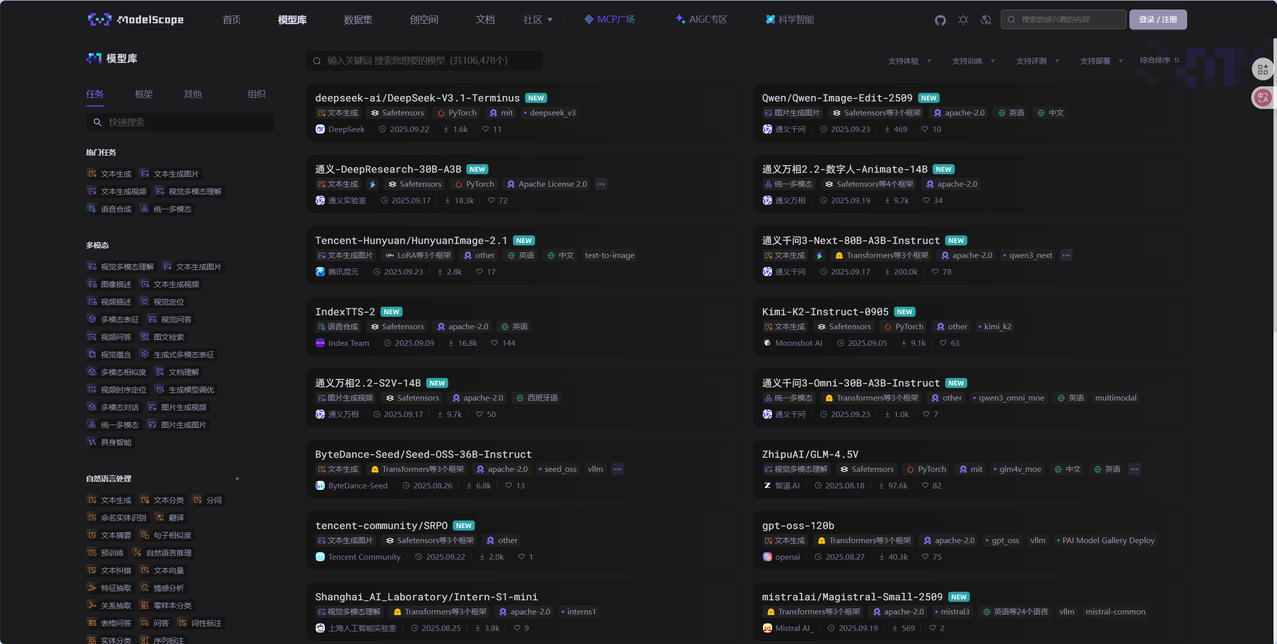
魔搭(ModelScope)是由阿里巴巴达摩院推出的开源模型即服务(MaaS)共享平台,汇聚了计算机视觉、自然语言处理、语音等多领域的数千个预训练AI模型。其核心理念是"开源、开放、共创",通过提供丰富的工具链和社区生态,降低AI开发门槛,尤其为企业本地私有化部署提供了一条高效路径。
官网:https://www.modelscope.cn/ (界面和HuggingFace设计的基本一样)
发展历程参考:https://segmentfault.com/a/1190000046532208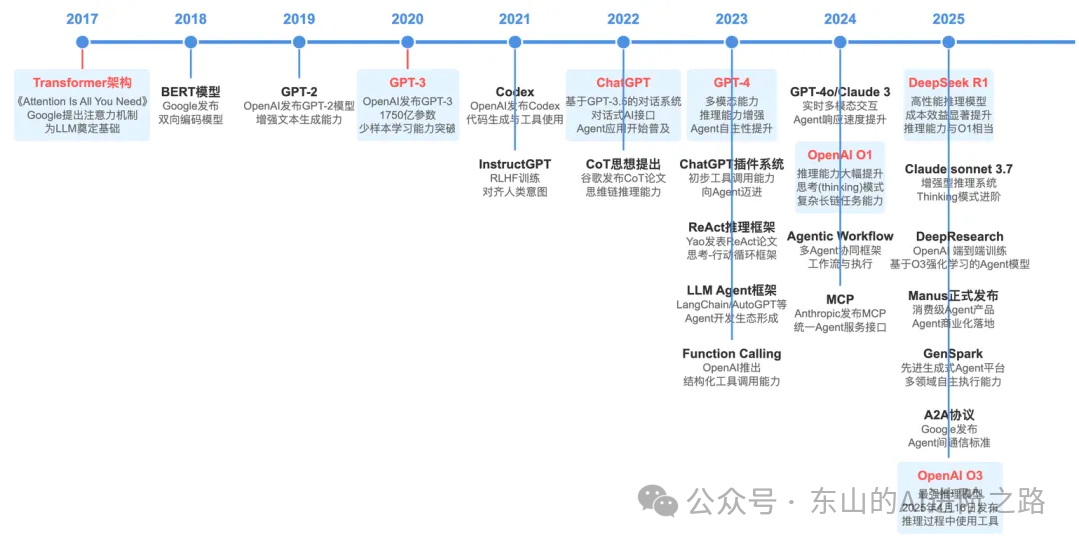
LLM的能力;
语⾔⼤师:理解与创造的⾰命
- 论⽂的开头:告诉⼤模型你的主题和观点,它能为你⽣成⼏个不同⻛格的引⾔段落。例如: "写⼀ 篇关于《基于深度学习的晶粒度智能评级⽅法》的⼤学⽣论⽂开头供我参考。"
- 投诉邮件:把情况告诉它,它即刻⽣成,你稍作修改就能发送。例如: "帮我写⼀封礼貌⼜坚决的 投诉邮件,事情的经过是:xxx"
我们发现,它真正“读懂”了⼈类语⾔的千变万化,并能进⾏⾼质量创作。这不是简单的关键词匹 配,⽽是理解了上下⽂、情感甚⾄潜台词。
知识巨⼈:拥有“全互联⽹”的记忆
- 我们可以问它: “⽤物理学原理解释为什么猫咪总能四脚着地?” 。它不仅能回答,还能类⽐。
- 我们可以让它: “对⽐⼀下古希腊哲学和春秋战国百家争鸣的异同” 。它能为我们提供清晰的思路。
可以看出,⼤模型是⼀个被压缩的、可对话的“互联⽹知识库”。它通过学习海量数据,将知识内在 关联,形成了⼀个⽴体的知识⽹络,⽽不仅仅是存储。
逻辑与代码巫师:从思维到实现的跨越
- ⼀个复杂的功能,对程序员来说,只需⽤中⽂描述:“写⼀个Python函数,能⾃动爬取某个⽹⻚的最 新标题并保存到Excel⾥。”代码瞬间⽣成。
- 我们可以把⼀道复杂的数学题丢给它,如 “微分⽅程y"-3y'+2y=3x-2e^x的特解y*的形式为?” , 它不仅能给出答案,还能⼀步步展⽰解题过程,成为你的私⼈家教。
可以看出,⼤模型不仅能处理语⾔,还能处理严格的逻辑和编程语法。这证明了它的能⼒超越了“⽂ 科”,进⼊了需要精确和推理的“理科”领域。
多模态先知:开启“全感知”AI的⼤⻔
- 想象⼀下,上传⼀张照⽚,再加⼊⼀段描述,AI可实现快速的对话式创意⼯作流程。 https://nanobanana.im/
- AI婴⼉预测和⽣成: “⽣成他们的宝宝的样⼦ - ⽗⺟双⽅特征的融合。专业的照⽚质量。”
- 3D图形: “请把这张照⽚变成⼀个⼈物。在它后⾯,放置⼀个印有⻆⾊形象的盒⼦。在它旁边, 添加⼀台计算机,其屏幕显⽰ Blender 建模过程。在盒⼦前⾯,为⼈偶添加⼀个圆形塑料底 座,让它站在上⾯。底座的 PVC 材质应具有晶莹剔透、半透明的质感,并将整个场景设置在室 内。”
可以看到,它打破“⽂本”的界限,连接视觉、听觉的世界,让AI更接近⼈类的感知⽅式。这是⽬前 最前沿、最令⼈兴奋的能⼒,它让AI真正成为“全能型”助⼿。
提示词编写技巧
编写合理且有效的提⽰词,是我们与AI进⾏有效对话的第⼀步,好的提⽰词能显著提升模型输出的质量和相关性。宗旨就是:将你的问题限定范围,让AI知道你要的答案具体要包含什么,提⽰词效果会⼤幅提升。
核⼼在于换位思考:想象AI对你提供的信息⼀⽆所知,你需要清晰、具体、⽆歧义地告诉它你要什 么、在什么背景下、以什么⽅式呈现。善⽤⽰例、⻆⾊扮演、具体约束和迭代优化。
提⽰技巧不⽌⼀种,掌握多种技巧,并根据不同任务灵活组合使⽤,才是成为提⽰词⾼⼿的秘诀。
CO-STAR结构化框架
在⽬标设定和问题解决的场景下,清晰性和结构性是⾄关重要的。⽽有⼀种⽅法论,在这些⽅⾯表现都⾮常出⾊,那就是CO-STAR框架。这个提⽰词编写框架,由新加坡政府技术局(GovTech)的数据科学与AI团队开发,重点在于确保提供给LLM的提⽰词是全⾯且结构良好的,从⽽⽣成更相关和准确的回答。
CO-STAR可以拆解为六个维度。
| 模块 | 说明 | 示例 |
| Context | 任务背景和上下文 | “你是电商客服,需解答⽤⼾关于iPhone17的咨询,知识库包含最新价格和库存” |
| Object | 核心目标 | “准确回答价格、发货时间,推荐适配配件” |
| Steps | 执行步骤 | “1.识别⽤⼾问题类型;2.检索知识库;3.⽤亲切语⽓整理回复” |
| Tone | 语言风格 | “⼝语化,避免专业术语,使⽤‘亲~’‘呢’等语⽓词” |
| Audience | 目标用户 | “20-35岁年轻消费者,对价格敏感,关注性价⽐” |
| Response | 输出格式 | “价格:XXX元\n库存:XXX件\n推荐配件:XXX(链接)” |
少样本提示/多示例提示
这种⽅式通过给AI提供⼀两个 输⼊-输出 的例⼦,让它“照葫芦画瓢”。
核⼼思想:你不是在给它下指令,⽽是在“教”它你想要的格式、⻛格和逻辑。
适⽤场景:格式固定、⻛格独特、逻辑复杂的任务,如⻛格仿写、数据提取、复杂格式⽣成。
思维链提示
提⽰⼯程的关键⽬标是让AI更好地理解复杂语义。这种能⼒的⾼低,可以直接通过模型处理复杂逻辑推理题的表现来检验。
可以这样理解:当好的提⽰词能帮助模型解决原本解决不了的难题时,就说明它确实提升了模型的推理⽔平。并且,提⽰词设计得越出⾊,这种提升效果就越显著。通过设置不同难度的推理测试,可以很清晰地验证这⼀点。
翻译⼀下问题:
杂耍者可以杂耍16个球。其中⼀半的球是⾼尔夫球,其中⼀半的⾼尔夫球是蓝⾊的。请问总共有多少个蓝⾊⾼尔夫球?推理结果:
8个蓝⾊⾼尔夫球
可以看到,答案错误。该逻辑题的数学计算过程并不复杂,但却设计了⼀个语⾔陷阱,即⼀半的⼀半是多少。
为了解决类似的逻辑问题,可以使⽤思维链提⽰。思维链提⽰相较于少样本提⽰是⼀种更好的提⽰⽅法,思维链提⽰最常⽤的两种⽅式:
• Few-shot-CoT:少样本思维链
• Zero-shot-CoT:零样本思维链
相⽐于少样本提⽰(Few-shot),与少样本思维链(Few-shot-CoT)的不同之处只是在于需要在提⽰样本中不仅给出问题的答案、还同时需要给出问题推导的过程(即思维链),从⽽让模型学到思维链的推导过程,并将其应⽤到新的问题中。此技巧主要⽤于解决复杂推理问题,如数学、逻辑或多步骤规划。
核⼼思想:要求AI“展⽰其⼯作过程”,⽽不是直接给出最终答案。这模仿了⼈类解决问题时的思考⽅式。
适⽤场景:数学题、逻辑推理、复杂决策、需要解释过程的任务。
⾃动推理与零样本链式思考
零样本思维链(Zero-shot-CoT)这是少样本思维链(Few-shot-CoT)的简化版。只需在提⽰词末尾
加上⼀句魔法短语,即可激发AI的推理能⼒。
核⼼思想:通过指令 “请⼀步步进⾏推理并得出结论” ,强制AI在给出答案前先进⾏内部推理。
适⽤场景:任何需要⼀点逻辑思考的问题,即使你不太清楚具体步骤。
“⼀步步进⾏推理” 这个指令,相当于在引导模型的“注意⼒机制”。它告诉模型:“在⽣成最终答案之前,请先在你的‘脑海’⾥(即⽣成的⽂本序列中)模拟出⼀个缓慢、有序的推理上下⽂。”当模型开始输出“第⼀步...第⼆步...”时,它实际上是在为⾃⼰创造⼀个更丰富、更逻辑化的上下⽂。它在这个⾃⼰创造的优质上下⽂中进⾏推理,最终得出的结论⾃然⽐在贫瘠的上下⽂中(只有原始问题)更准确。
根据《LargeLanguageModelsareZero-ShotReasoners》论⽂中的结论,从海量数据的测试结果来
看,Few-shot-CoT⽐Zero-shot-CoT准确率更⾼。
⾃我批判与迭代
要求AI在⽣成答案后,从特定⻆度对⾃⼰的答案进⾏审查和优化。
核⼼思想:将“⽣成”和“评审”两个步骤分离,利⽤AI的批判性思维来提升内容质量。适⽤场景:代码审查、⽂案优化、论证强化、安全检查。
在实际应⽤中,这些技巧常常是组合使⽤的。例如,我们可以:
1. 使⽤CO-STAR框架设定基本结构和⻆⾊。
2. 在框架的“Steps”或“Response”部分,融⼊思维链指令。
3. 对于格式复杂的输出,在最后附上少样本⽰例。
4. 最后,要求AI进⾏⾃我审查。
我们更多使⽤LLM的场景⼤都是编写代码,如果你们⽤过Cursor、Trae这样的AI IDE。应该不陌⽣在AI帮我们编码之前,需要配置相关的“编码规则”--Rules。它其实就是这些IDE输⼊给LLM的提⽰词,告诉LLM编写代码时的注意事项与要求。
Cursor官⽅提⽰词:https://cursor.directory/rules
为什么LLM如此重要?
⽣产⼒⾰命的“加速器” ⾃动化所有基于语⾔和知识的⼯作:撰写、总结、翻译、编码、答疑……它将⼈类从重复性的脑⼒劳 动中解放出来,让我们能更专注于创造、决策和战略思考。 它的核⼼价值不是替代⼈类,⽽是增强⼈类(HumanAugmentation)。
⼈机交互的“新范式” 从“⼈适应机器”到“机器适应⼈”:我们不再需要学习复杂的软件菜单或编程语⾔,⽤最⾃然 的“说话”⽅式,就能指挥机器完成任务。技术的使⽤⻔槛被极⼤地降低了。
产业智能化的“核⼼引擎” 赋能千⾏百业:
- 教育:提供⼀对⼀、⽆限耐⼼的AI家教。
- 医疗:辅助医⽣看影像资料、查阅最新⽂献病历。
- 法律:快速分析海量卷宗,提炼关键信息。
- ⽂创:提供⽆限的故事灵感、设计草图、配乐⽅案。
它正在成为和互联⽹、移动⽀付⼀样重要的数字化基础设施。
LLM的接入方式
前面我们演示的都是通过现成的客户端,来进行AI行为,如聊天、生图等。如果现在要我们自己写一个AI应用来实现相关AI行为,无法直接使用客户端,则需要我们自行接入LLM。
常见的原生LLM(不经过第三方平台或复杂的代理层,直接与大语言模型提供方进行交互的方法)接入方式有三种:
- API远程调用
- SDK和官方客户端库(SDK接入)
- 开源模型本地部署(本地部署是我的服务器部署,运营商部署是API接入。。?
前两个是部署到运营商调用,本地部署需要大模型的源代码,还包括模型的参数。权重、训练数据等。。

API接入
这是目前最主流、最便捷的接入方式,尤其适用于快速开发、集成到现有应用以及不想管理硬件资源的场景。
通过HTTP请求(通常是RESTful API)直接调用模型提供商部署在云端的模型服务。代表厂商:OpenAI(GPT-4o),Anthropic(Claude),Google(Gemini),百度文心一言,阿里通义千问,智谱AI等。
典型流程就是:
- 注册账号并获取API Key:在模型提供商的平台上注册,获得用于身份验证的密钥。
- 查阅API文档:了解请求的端点、参数(如模型名称、提示词、温度、最大生成长度等)和返回的数据格式。
- 构建HTTP请求:在你的代码中国,使用HTTP客户端库(如Python的requests)构建一个包含API Key(通常在Header中)和请求体(JSON格式,包含你的提示和参数)的请求。
- 发送请求并处理响应:将请求发送到提供商指定的API地址,然后解析返回的JSON,提取生成的文本。
接入方式,可以通过curl方式,python方式或者node.js都可以
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Write a one-sentence bedtime story about a unicorn."
}'curl是常用的命令行工具,原来请求Web服务器。它的名字就是客户端client的URL工具的意思。详细看:https://blog.csdn.net/Lakers2015/article/details/128627020?fromshare=blogdetail&sharetype=blogdetail&sharerId=128627020&sharerefer=PC&sharesource=2401_82607598&sharefrom=from_link
-H请求头header
-d请求内容body。。
这个¥OPENAI_API_KEY占位符就是填写密钥的地方
http。。。是前置url,然后后面跟的是路径。。
用apifox或postman能发起HTTP请求的客户端即可。。
输出结果
{
"id": "resp_68da0ae40f40819c8f33465a1d923fcb0b003ac22034ffda",
"object": "response",
"created_at": 1759120100,
"status": "completed",
"background": false,
"billing": {
"payer": "developer"
},
"error": null,
"incomplete_details": null,
"instructions": null,
"max_output_tokens": null,
"max_tool_calls": null,
"model": "gpt-4o-mini-2024-07-18",
"output": [
{
"id": "msg_68da0ae4ab90819cb9544144353167060b003ac22034ffda",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"logprobs": [],
"text": "你好!我是⼀个⼈⼯智能助⼿,旨在回答你的问题和提供帮助。有什么我可以为你做的呢?"
}
],
"role": "assistant"
}
],
"parallel_tool_calls": true,
"previous_response_id": null,
"prompt_cache_key": null,
"reasoning": {
"effort": null,
"summary": null
},
"safety_identifier": null,
"service_tier": "default",
"store": true,
"temperature": 1.0,
"text": {
"format": {
"type": "text"
},
"verbosity": "medium"
},
"tool_choice": "auto",
"tools": [],
"top_logprobs": 0,
"top_p": 1.0,
"truncation": "disabled",
"usage": {
"input_tokens": 11,这里用的现成客户端演示,实际上可以写客户端发起。。
外国软件需使用系统代理。。
API远程调用,SDK和官方客户端库(SDK接入),开源模型本地部署都是接入厂商提供的大模型。
LangChain也可以接入大模型。langchain把这些方式封装了的。
本地接入
大模型本地部署,这种方式就是将开源的大型语言模型(如Llama、ChatGLM、Qwen等)部署在你自己的硬件环境(本地服务器或私有云)中,核心概念就是,将下载模型的文件(权重和配置文件),使用专门的推理框架在本地服务器或GPU上加载并运行模型,然后通过类似API的方式进行交互。
典型流程是:
- 获取模型:从HuggingFace(国外)、魔搭社区(国内)等平台下载开源模型的权重。(平台参 考本篇章第四节)
- 准备环境:配置具有⾜够显存(如NVIDIA GPU)的服务器,安装必要的驱动和推理框架。
- 选择推理框架:使⽤专为⽣产环境设计的框架来部署模型,例如:
vLLM:特别注重⾼吞吐量的推理服务,性能极佳
TGI:Hugging Face推出的推理框架,功能全⾯。
Ollama:⾮常⽤⼾友好,可以⼀键拉取和运⾏模型,适合快速⼊⻔和本地开发。
LM Studio:提供图形化界⾯,让本地运⾏模型像使⽤软件⼀样简单。 - 启动服务并调用:框架会启动⼀个本地API服务器(如http://localhost:8000 ),你可以 像调⽤云端API⼀样向这个本地地址发送请求。
SDK接入
相当于API接入的封装和简化,由厂商封装。模型提供商通常会发布官方编程语言SDK,为我们封装好底层的HTTP请求细节,提供一个更符合编程习惯的、语言特定的函数库。
典型流程(以OpenAI Python SDK为例):
安装库:
pip install openai安装OpenAI SDK 后,可以创建⼀个名为example.py 的⽂件并将⽰例代码复制到其中:
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.responses.create(
model="gpt-5",
input="介绍⼀下你⾃⼰。"
)
print(response.output_text)相⽐直接构造HTTP请求,代码更简洁、更易读、更易维护。
对于以上三种接⼊⽅式,我们该如何选择?
• 看数据敏感性:如果数据极其敏感,必须留在内部,本地部署是唯⼀选择。
• 看技术实⼒和资源:如果团队没有强⼤的MLops(机器学习运维)能⼒,也没有预算购买和维护GPU服务器,云端API是更实际的选择。
• 看成本和规模:如果应⽤规模很⼤,⻓期来看,本地部署的固定成本可能低于持续的API调⽤费 ⽤。反之,⼩规模应⽤ API更划算。
• 看定制需求:如果只是使⽤模型的通⽤能⼒,云端API⾜够。如果需要⽤⾃⼰的数据微调模型,则 需要选择⽀持微调的API或直接本地部署。
实际上,只要是原⽣LLM,⽆论怎么接⼊都有限制。为什么?
1. 输⼊⻓度限制:所有LLM都有固定的输⼊⻓度(如4K、8K、128K、400KToken)。我们⽆法将 ⼀本⼏百⻚的PDF或整个公司知识库直接塞给模型。
2. 缺乏私有知识:模型的训练数据有截⽌⽇期,且不包含我们的私⼈数据(如公司内部⽂档、个⼈笔 记等)。让它基于这些知识回答问题,⾮常困难。
3. 复杂任务处理能⼒弱:原⽣API本质是⼀个“⼀问⼀答”的接⼝。对于需要多个步骤的复杂任务 (如“分析这份财报,总结要点,并⽣成⼀份PPT⼤纲”),我们需要⾃⼰编写复杂的逻辑来拆解 任务、多次调⽤API并管理中间状态。
4. 输出格式不可控:虽然可以通过提⽰词要求模型输出JSON或特定格式,但它仍可能产⽣格式错误 或不合规的内容,需要我们⾃⼰编写后处理代码来校验和清洗。
像LangChain这样的框架,正是为了系统性地解决这些问题⽽诞⽣的。
嵌入模型
之前的如chatgpt是生成式模型(大语言模型);问题->答案
(嵌入模型)表示型模型;“你好。。。”->[0.1,0.3。。](向量)为输入文本生成一个最佳、富含语义的数值表示
“喜悦” 【0.6,-0.9。。】
“愉快” 【0.6,-0.8。。】
由文本经嵌入模型生成了向量,我们就可以通过数学来度量语义。说明他们语义相似。。
既然有向量,就可以用空间维度来表示。。生成的不止几维,多维度向量。。
用数学度量语义:
- 欧式距离:距离。。
- 余弦相似度:方向。。。
方向代表含义;长度代表文本的长度,词汇。。。维度越高能捕捉的的语义就越精确,更细致,复杂度就越强。
嵌入模型可以根据相似性进行匹配,而不是基于精确匹配的查询(Mysql)
⼤语⾔模型是⽣成式模型。它理解输⼊并⽣成新的⽂本(回答问题、写⽂章)。它内部实际上也使⽤ 嵌⼊技术来理解输⼊,但最终⽬标是“创造”。
⽽嵌⼊模型(EmbeddingModel)是表⽰型模型。它的⽬标不是⽣成⽂本,⽽是为输⼊的⽂本创建 ⼀个最佳的、富含语义的数值表⽰(向量)。
由于计算机天⽣擅⻓处理数字,但不理解⽂字、图⽚的含义。嵌⼊(Embedding)的核⼼思想就是将 ⼈类世界的符号(如单词、句⼦、产品、⽤⼾、图⽚)转换为计算机能够理解的数值形式(即向量, 本质上是⼀个数字列表),并且要求这种转换能够保留原始符号的语义和关系。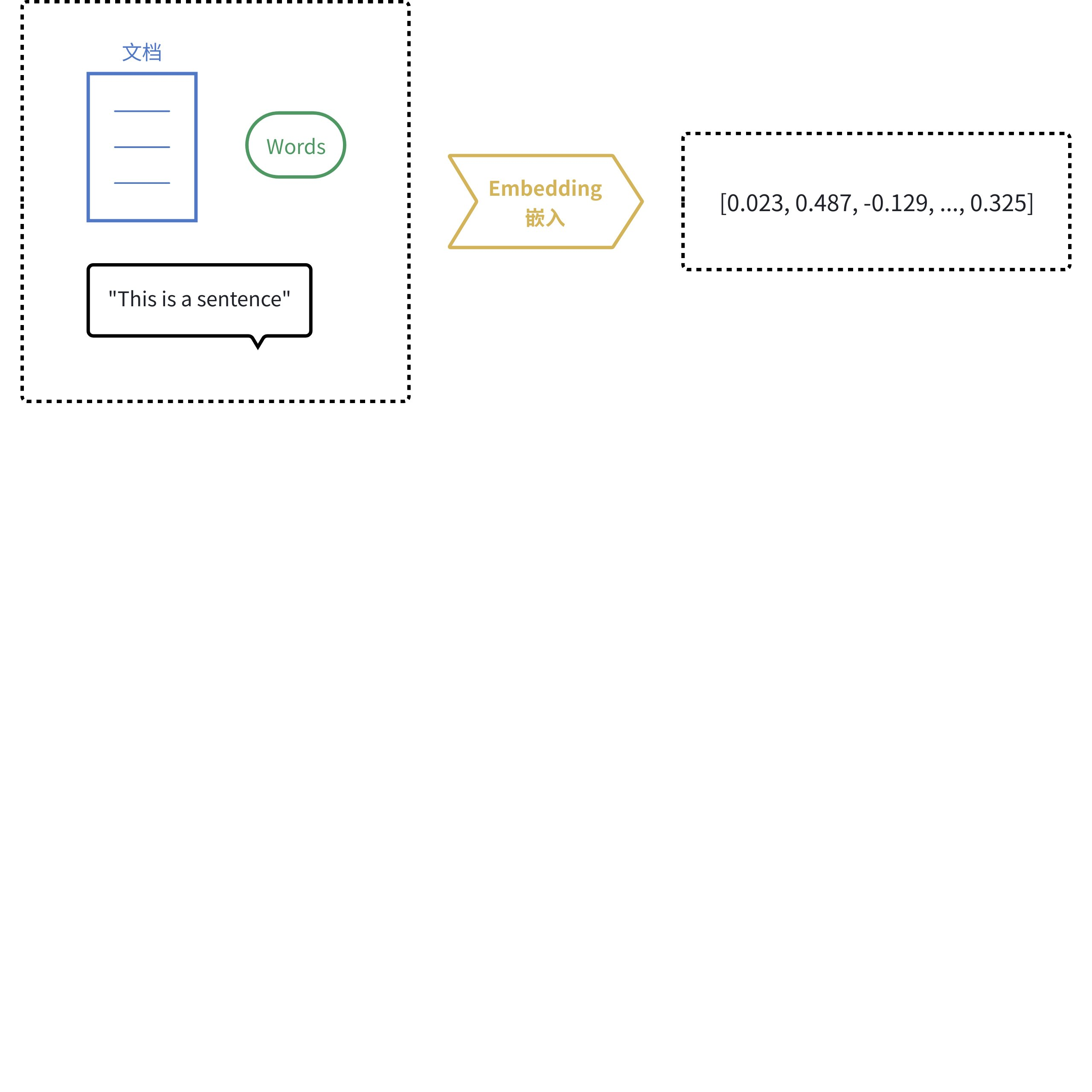
嵌入模式应用场景
- 语义搜索(Semantic Search)
传统搜索:依赖关键词匹配(搜 “苹果” ,只能找到包含 “苹果” 这个词的⽂档)。
语义搜索:则能将查询和⽂档都转换为向量,通过计算向量间的相似度来找到相关内容,即使⽂档中 没有查询的确切词汇也能被检索到。如下图所⽰,即使知识库中并未直接出现 “笔记本电脑⽆法充 电” 这个词组,语义搜索也能通过向量相似度精准地找到该⽂档。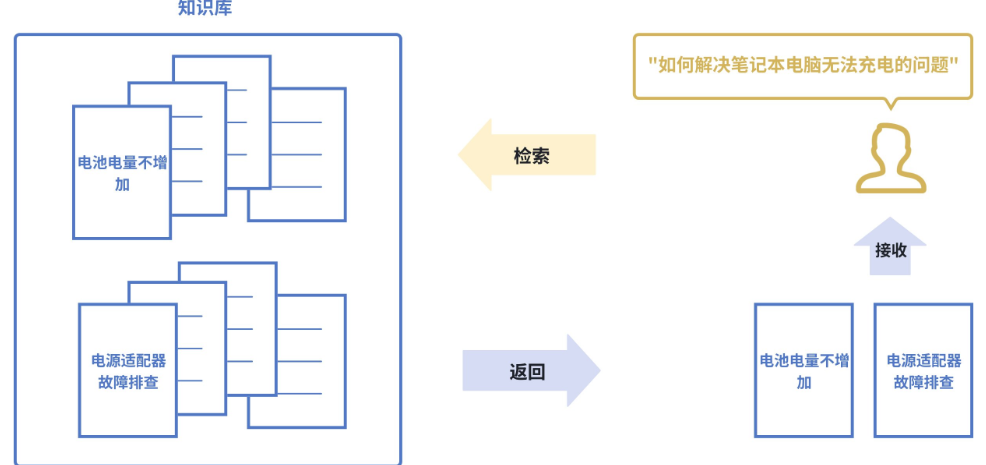
- 检索增强⽣成(Retrieval-AugmentedGeneration,RAG)
这是当前⼤语⾔模型应⽤的核⼼模式。当⽤⼾向LLM提问时,系统⾸先使⽤嵌⼊模型在知识库(如公司内部⽂档)中进⾏语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给LLM来⽣成答案。这极⼤地提⾼了答案的准确性和时效性。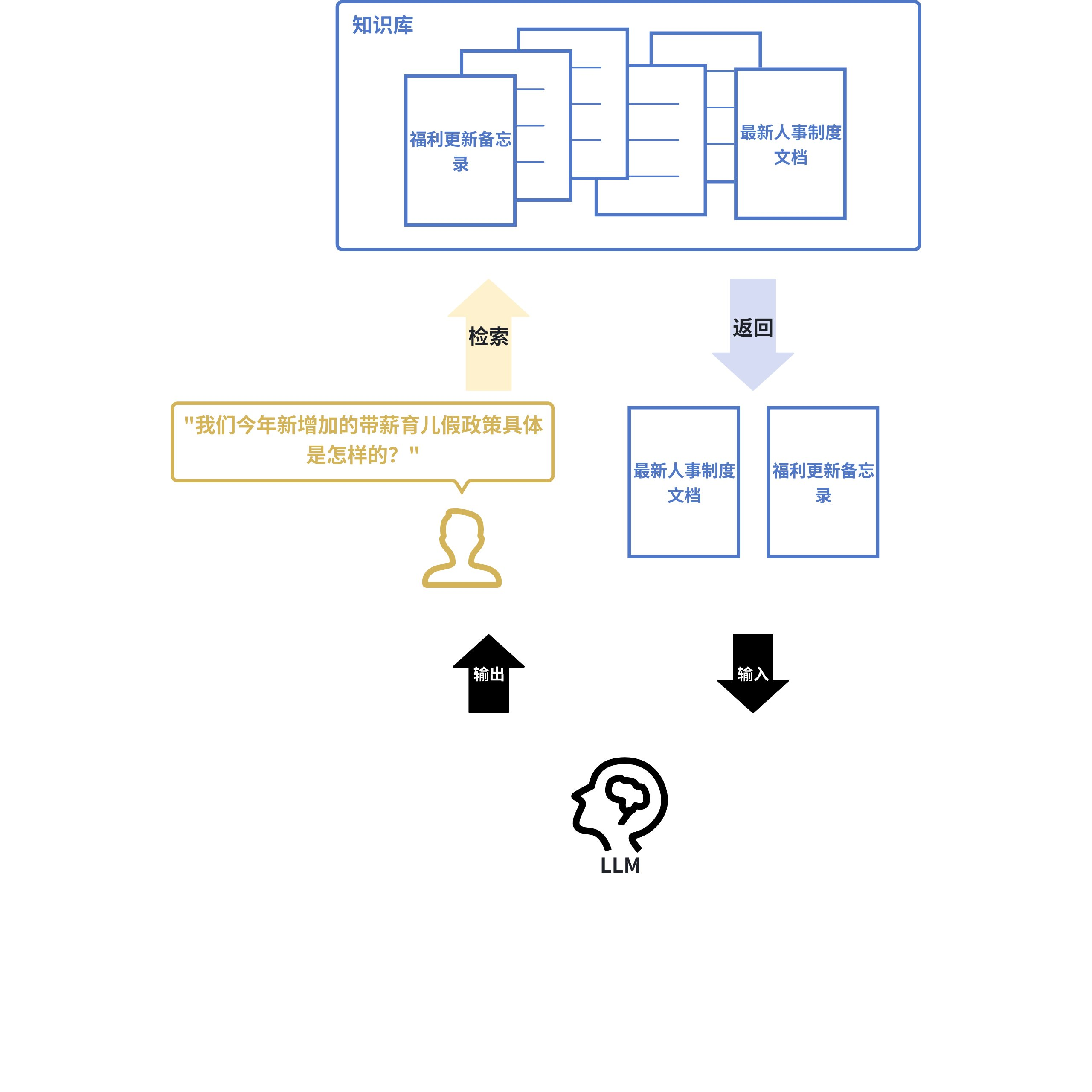
- 推荐系统(Recommendation Systems)
将⽤⼾(根据其历史⾏为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的⽤ ⼾,其向量会接近;相似的物品,其向量也会接近。通过计算⽤⼾和物品向量的相似度,就可以进⾏ 精准推荐。
- 异常检测(Anomaly Detection)
正常数据的向量通常会聚集在⼀起。如果⼀个新数据的向量远离⼤多数向量的聚集区,它就可能是⼀ 个异常点(如垃圾邮件、欺诈交易)。
主流的嵌⼊模型
• text-embedding-3-large(OpenAI):OpenAI最强⼤的英语和⾮英语任务嵌⼊模型。默认维度 3072,可降维如1024维;输⼊令牌⻓度⽀持为8192
• Qwen3-Embedding-8B(阿⾥巴巴):开源模型,⽀持100+种语⾔;上下⽂⻓度32k;嵌⼊维度最⾼4096,⽀持⽤⼾定义的输出维度,范围从32到4096。推理需要⼀定的GPU计算资源(例如, ⾄少需要16GB以上显存的GPU才能⾼效运⾏)。
• gemini-embedding-001(Google):⽀持100+种语⾔;默认维度3072,可选降维版本:1536维 或768维;输⼊令牌⻓度⽀持为2048
Huggingface的MTEB评测:https://huggingface.co/spaces/mteb/leaderboard Huggingface的MTEB(MassiveMultilingualTextEmbeddingBenchmark)评测,是业界⽐较公认的标准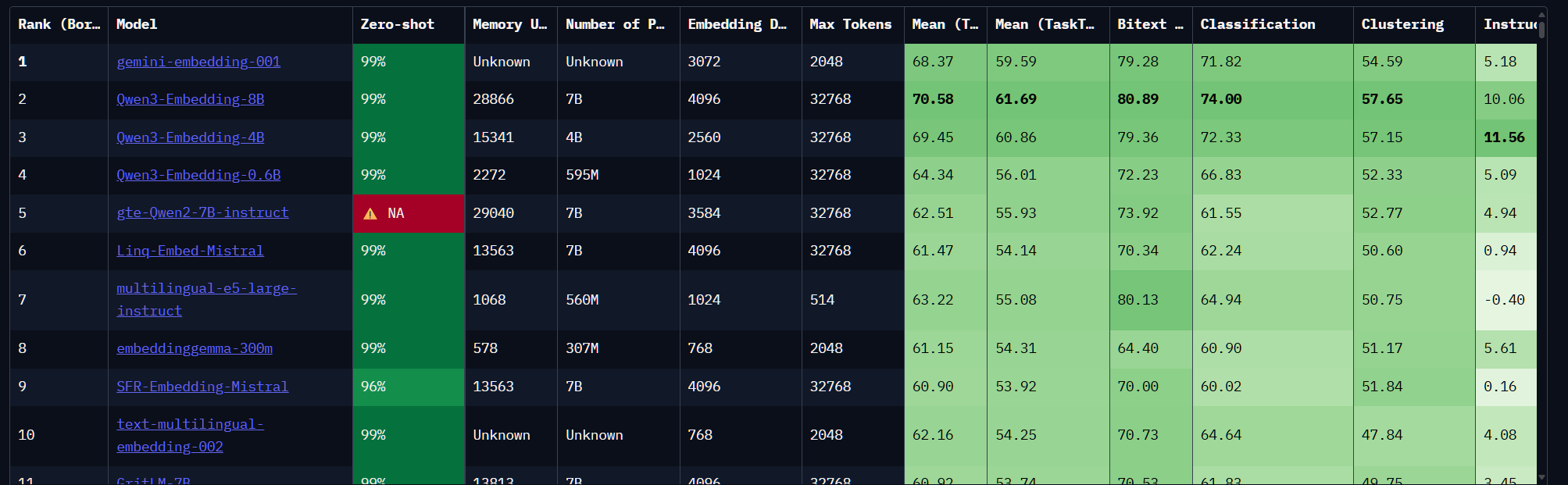
嵌入模型接入方式
嵌⼊模型接⼊和使⽤⽅式根据模型类型(开源或闭源)有根本性的不同。下图清晰地展⽰了两种典型的接⼊流程: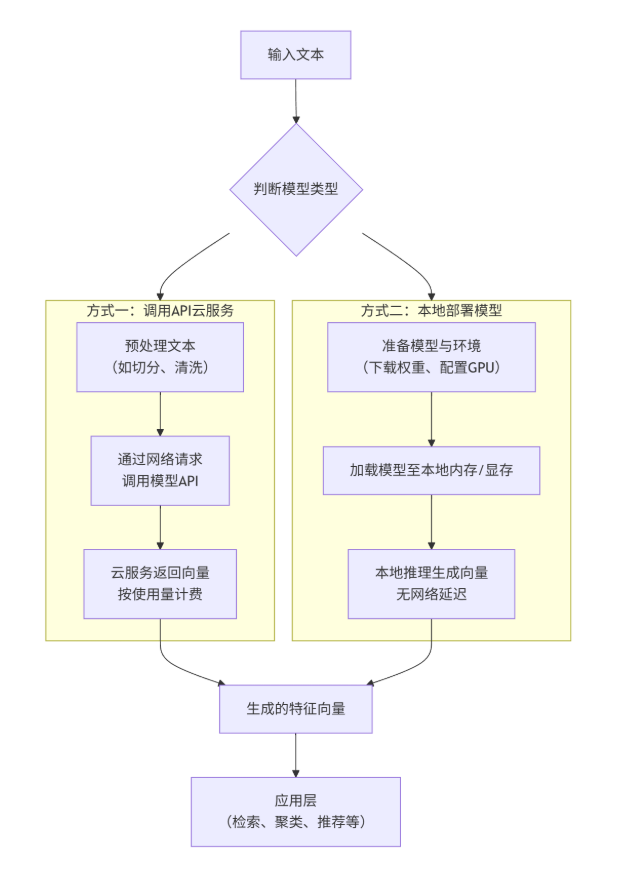
API接⼊(闭源)
这是最快速、最简单的⽅式,⽆需管理任何基础设施。只需要向模型提供商的服务端发送⼀个HTTP请求即可。 适⽤模型:text-embedding-3-large ,gemini-embedding-001 等。
通⽤步骤:
1.注册账号并获取API Key:在对应的云服务平台(如OpenAI Platform,Google AI Studio/Vertex AI)上注册账号,获取⽤于⾝份验证的API Key。
2. 安装SDK或构造HTTP请求:使⽤官⽅提供的SDK(如 openai ,google-generativeai ) 或直接构造HTTP请求。
3. 调⽤API并处理响应:发送⽂本,接收返回的JSON格式的向量数据。
curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'响应包含嵌⼊向量(浮点数列表)以及⼀些其他元数据:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}接入SDK
pip install openai# 使⽤ OpenAI Python SDK
from openai import OpenAI
import os
# 1. 设置 API Key
client = OpenAI(api_key="your-api-key")
# 2. 准备输⼊⽂本
text = "这是⼀段需要转换为向量的⽂本。"
# 3. 调⽤ API
response = client.embeddings.create(
model="text-embedding-3-large", # 指定模型
input=text,
dimensions=1024 # 可选:指定输出维度,例如从3072降维到1024
)
# 4. 获取向量
embedding = response.data[0].embedding
print(f"向量维度:{len(embedding)}")
print(embedding)还有本地部署(开源)
。。。。。
在实际应⽤中,直接调⽤嵌⼊模型获取结果,与直接调⽤原⽣LLM存在相似的问题:⽆论是通过API 还是本地部署获得向量,下⼀步通常都是将它们存⼊向量数据库(如Chroma,Milvus,Pinecone等) 以供后续检索。为了便于切换不同的嵌⼊模型,很多项⽬会使⽤像LangChain这样的框架,它们提供 了统⼀的嵌⼊模型接⼝。
这个医疗助手例子集中体现了所有描述中的难题。为了解决它们,业界正在形成一整套称为 “LLM 应用工程” 的最佳实践和技术栈:
- ・针对幻觉、提示词规范:采用 “提示词工程” 和 “检索增强生成(RAG)”。为医疗助手设计严谨、系统的提示词模板,并强制模型在回答前先从权威、实时的医疗知识库中检索信息,而不是仅凭记忆回答。
- ・针对模型切换:使用 LLMAPI 抽象层(如 LangChain)。这些中间件统一了不同模型的接口,让开发者通过配置而非修改代码来切换模型。
- ・针对非结构化输出:采用 “输出解析” 技术。强制要求模型以 JSON 等格式输出,并在提示词中严格定义 JSON 的 Schema。一些框架(如 LangChain)可以自动将模型输出解析为预定义的 Pydantic 对象。
- ・针对知识陈旧:主要依靠 RAG 来注入实时、外部的知识。
- ・针对连接外部工具:采用 “智能体(Agent)” 框架。让 LLM 作为大脑,根据用户请求规划步骤、选择工具(如计算器、数据库 API、搜索引擎),并执行任务。
最终,一个成熟的 “智能医疗咨询助手” 不会是直接调用原生大模型,而是一个由精心设计的提示词、RAG 系统、外部工具 API、输出解析器等共同组成的复杂系统。原生大模型只是这个系统的核心引擎之一,而非全部
LangChain 可以解决上述所有问题!
LangChain 是一个用于开发由大语言模型 (LLM) 驱动的应用程序的框架。它通过将自然语言处理(NLP)流程拆解为标准化组件,让开发者能够自由组合并高效定制工作流。
- 组件(Components):用来帮助当我们在构建应用程序时,提供一系列的核心构建块,例如语言模型、输出解析器、检索器等。
- 自然语言处理流程(NLP):指的是完成一个特定 NLP 任务所需的一系列步骤。例如,构建一个 “基于公司文档的问答机器人” 的流程可能包括:读取文档、分割文本、将文本转换为向量(嵌入)、存储向量、接收用户问题、搜索相关文本段、将问题和文本段组合发送给大语言模型(LLM)、解析模型输出并返回答案等。
LangChain 的技术特点
LangChain 框架的设计精髓在于以链式 (Chain) 的方式整合多个组件,从而构建出功能丰富的大语言模型应用。链式表示 LangChain 允许将多个步骤或多个组件串联起来,无需各个组件各自完成其能力,而是一次性执行这个 "链" 上的所有流程!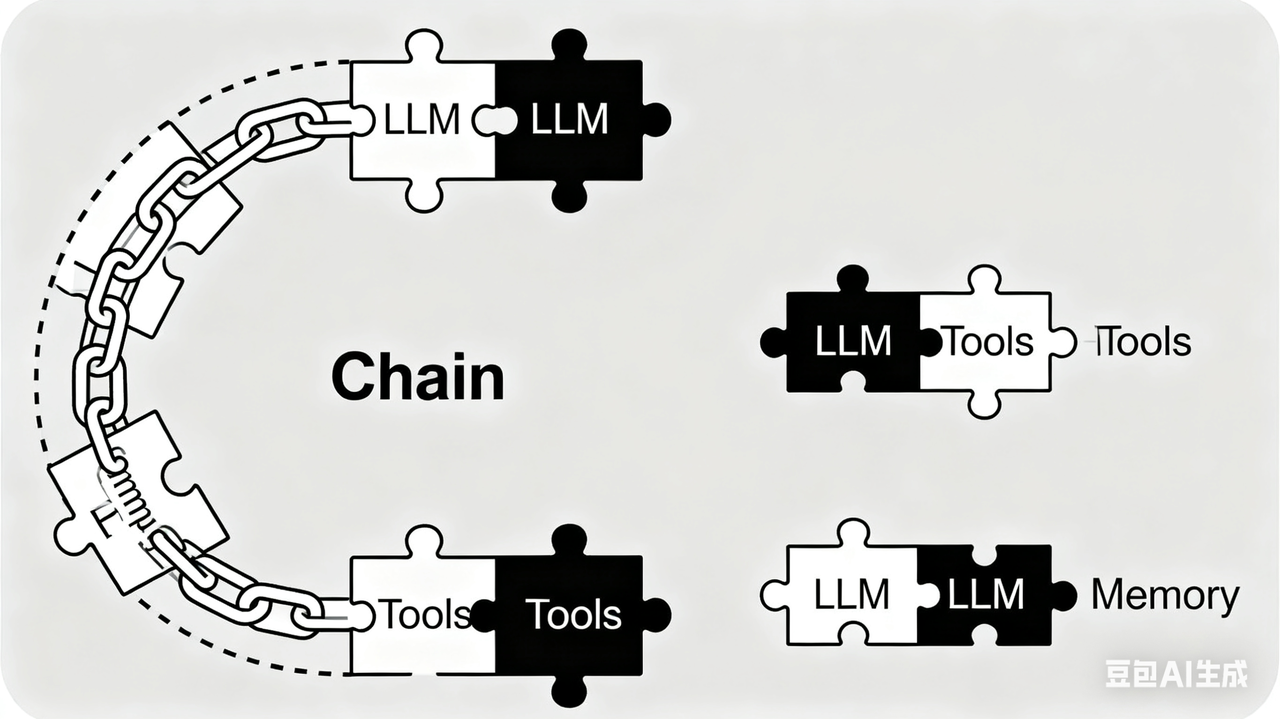
举一个最简单的例子,若我们想借助提示词完成一次对于 LLM 的提问,在 LangChain 中至少需要定义两个组件:
・提示词模板组件
・大模型组件
使用时,我们可以: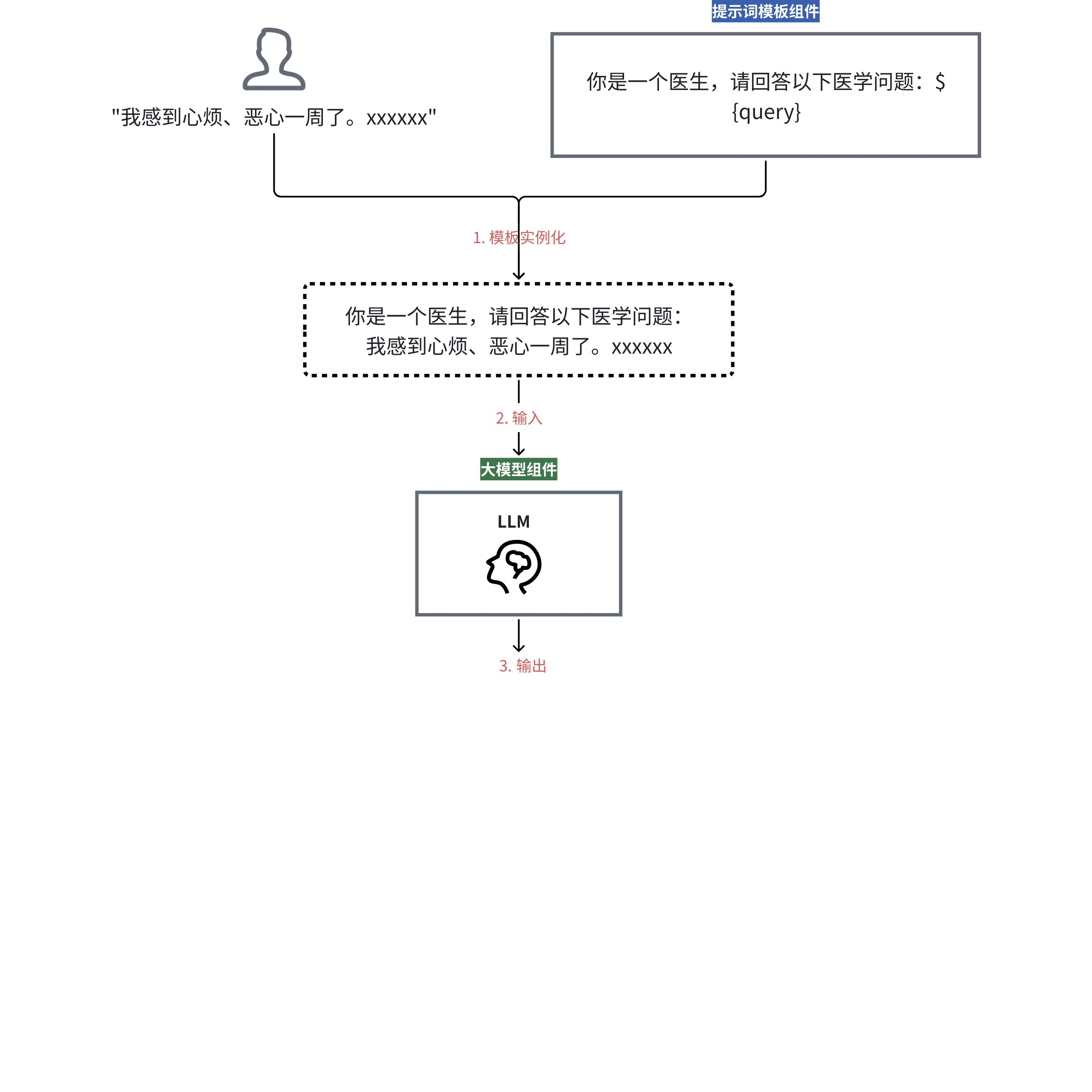
这相当于,提示词模板组件执行了一次,大模型组件也执行了一次。而对于链式执行来说,只需执行一次链即可:
LangChain框架提供了一系列标准化模块与接口,主要包括以下方面:
• 统一的模型调用:通过抽象化的接口支持多种大语言模型(例如OpenAI GPT-4/5、Anthropic Claude等)和嵌入模型,使开发者可以灵活切换不同模型供应商。
• 灵活的提示词管理:提供提示词模板(Prompt Templates),支持动态生成输入内容,并可管理少样本示例与提示选择策略,以提升模型响应质量。
• 可组合的任务链(Chains):允许将多个步骤串联成完整流程,如先检索文档再生成回复,或组合多次模型调用。开发者能够通过自定义链实现复杂的任务编排。
• 上下文记忆机制(Memory):用于存储多轮对话中的状态信息。LangChain曾提供多种记忆管理方案(如对话历史记忆和摘要记忆),以实现连贯的交互体验(注:该功能目前已由LangGraph支持,原有实现已过时)。
• 检索与向量存储集成:支持从外部加载文档,经分割和向量化处理后存储至向量数据库,在查询时检索相关信息并输入大语言模型,帮助构建检索增强生成(RAG)类应用。LangChain兼容多种主流向量数据库(如FAISS、Pinecone、Chroma)和文档加载工具,简化知识库应用的开发流程。
对于上述技术内容,LangChain的开源组件和第三方集成可以轻松支持快速上手,帮助我们构建应用程序。
除此之外,使用LangGraph可以构建支持人机交互的有状态代理。LangChain公司也在围绕框架构建完整的生态系统,包括推出LangSmith(一个用于调试、监控和评估LLM应用的平台)以及LangGraph Platform(用于LangChain应用的部署、运维)等,为开发者提供从开发到生产的一站式支持。
起源与发展LangChain 由 Harrison Chase 于 2022 年 10 月开源发布,旨在解决开发者在使用 LLM(如 GPT-3)时遇到的核心问题。
项目迅速获得社区关注,2023 年成立 LangChain 公司并获数千万美元融资,估值达 2 亿美元。2023 年中,LangChain 推出了对 JavaScript/TypeScript 的支持,使其开发者社区从 Python 扩展到前端和全栈开发者。此外,LangChain 不断增加对各种 LLM 模型的支持,从最初的 OpenAI API 扩展到 Anthropic、HuggingFace 等模型提供商,以及本地部署的模型(如 Llama 等),并提供了统一的接口来调用这些模型。2023 年底至 2024 年初,LangChain 进行了重大的架构调整,将核心代码与第三方集成解耦。LangChain 0.1.0 版本(2024 年 1 月发布),也是第一个稳定版本,其引入了 langchain-core 库,其中包含稳定的抽象接口和核心功能,而将具体的第三方集成移至 langchain-community 或独立的伙伴包中。这一拆分提高了框架的模块化程度和依赖管理的清晰度。这一版本还带来了许多新功能和改进,例如 LangChain 表达式语言 (LCEL),支持用户高度定制链(Chains)的执行流程。2024 年 5 月,LangChain 发布了 0.2.0 版本,引入了一系列新特性和改进,同时也包含一些 API 的调整。0.2.0 版本进一步增强了对异步调用、流式输出的支持,并优化了与向量数据库、检索系统的集成。2024 年下半年,LangChain 发布了 0.3.x 版本,持续改进性能和增加新的集成(如更多的向量存储、工具插件等)。2025 年 9 月,LangChain 发布了 1.x Alpha 内测版,在各提供商之间统一了现代 LLM 功能,包括推理、引用、服务器端工具调用等。还新增了预构建的 Langgraph 链和代理。Langchain 包的范围已缩小,专注于流行和重要的抽象概念。为保持向后兼容性,新增了 langchain-legacy 包。版本发布:https://github.com/langchain-ai/langchain/releases
LangChain 的局限性
LangGraph 是 LangChain 生态系统中晚些出现的一个框架,其诞生背景与大型语言模型应用日益增长的复杂性密切相关。随着开发者尝试构建更高级的 AI 代理和多轮对话系统,传统链式结构的局限性逐渐显现:
- ・链式流程通常是线性的、预先定义好的步骤,难以处理需要循环、分支或长期状态维护的复杂场景。
- ・此外,在构建多智能体协作、需要人工介入(Human-in-the-loop)或长时间运行的任务时,需要更灵活的工作流管理和状态持久化支持。
举个例子,假设我们要构建一个 AI 代理,来自动处理用户提交的客服工单(例如:退货请求、产品咨询、投诉等)。一个理想的流程是: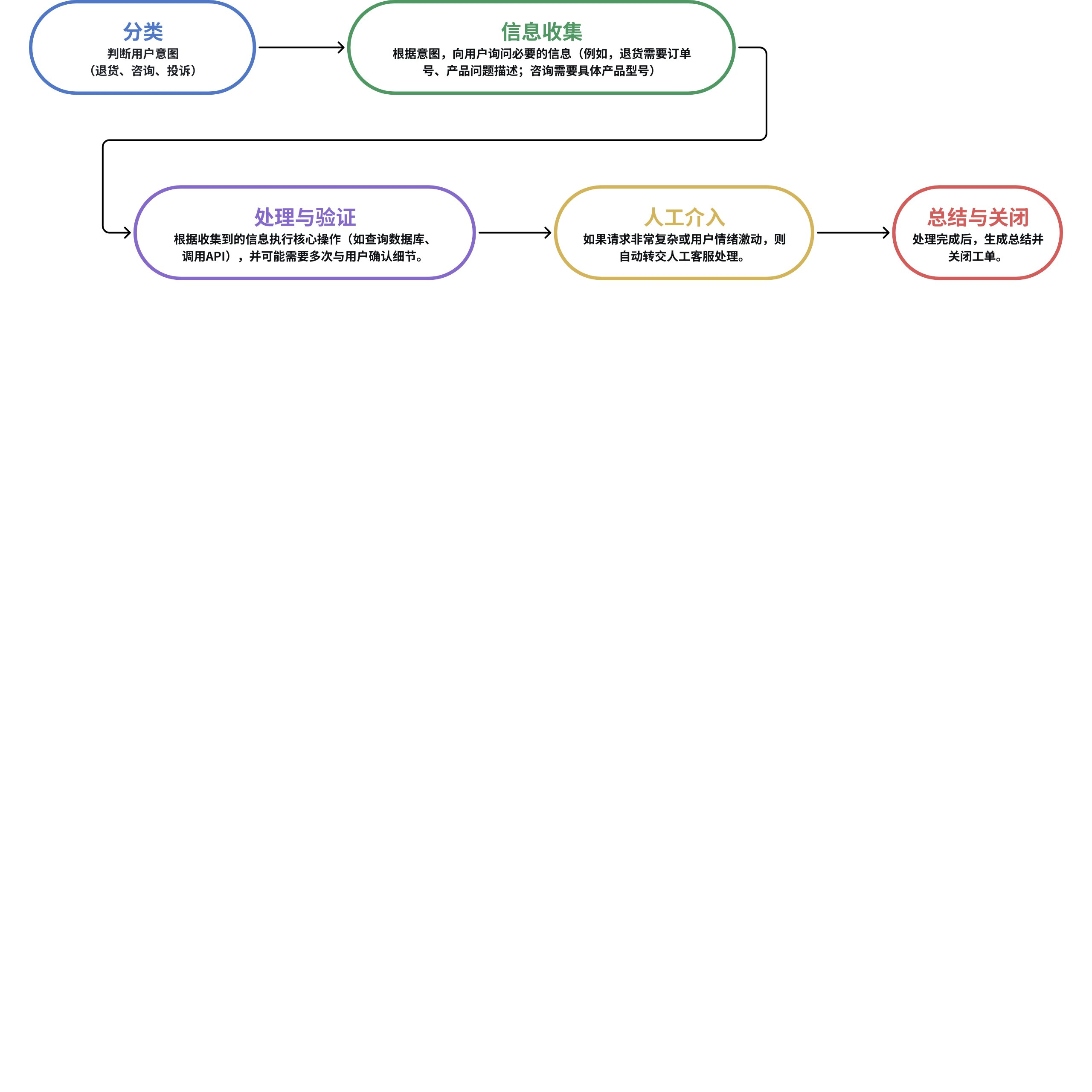
如果用传统的 Chain A -> Chain B -> Chain C 的线性结构来构建,会遇到以下具体问题:
问题1:难以处理循环和分支(无法动态路由和多次询问) 在“信息收集”阶段,用户第一次可能提供了一个不完整的订单号。链式流程是单向的,它无法自动“跳回”上一步再次请求用户补充信息。 结果:只能让整个链失败,或者生成一个僵硬的错误消息,用户体验非常差。无法实现“只要信息不完整,就持续询问直到完整”这样的逻辑。
问题2:状态维护困难(无法长时间运行和记忆上下文) 客户服务对话通常是多轮的,可能持续几分钟、几小时甚至几天。传统的链在每次调用时都是“无状态”的。 结果:状态管理(记忆)的重担完全落在了开发者身上,需要依赖外部数据库或缓存来手动存储和读取对话状态,代码会变得非常臃肿和脆弱。
问题3:难以融入人工介入(Human-in-the-loop) 当AI无法处理时,需要无缝地转交给人。在链式流程中,这意味着链的执行到此中断。无法优雅地实现暂停AI流程,等待人工处理完毕,再将结果返回,继续执行后续自动化步骤。 结果:整个流程会断裂成两半:AI部分和人工部分。你需要构建另外的系统来通知人工、接收人工处理结果,并重新触发后续的链,这完全破坏了工作流的完整性和可管理性。
问题4:僵化的流程(无法根据条件动态跳转) 不同的用户意图需要完全不同的子流程。例如判断用户意图: • 是“投诉”。我们的链可能预先设计为走 A->B->C 路径。 • 是“产品咨询”,可能需要走 A->D->E 路径。 在链式结构中,实现这种条件分支非常笨拙,通常需要编写一个巨大的“主链”,内部用一系列 if-else 语句来调用不同的子链。
结果:流程图的逻辑变成了代码中的控制流语句,而不是清晰可见的图形化结构。这使得工作流难以设计、调试和可视化。
LangGraph:解决痛点
为了解决这些问题,LangChain团队于2024年推出了LangGraph框架,旨在提供一种图结构的、状态化的方式来构建复杂的AI代理应用。
LangChain团队将LangGraph定位为“低层次的编排框架”,用于构建可控、可靠的AI代理工作流。目前,LangGraph已经在一些生产环境中得到应用,例如LinkedIn、Uber、GitLab等公司据报道使用LangGraph来构建复杂的生成式AI代理系统。
例如,我们将上述链式示例改为图结构: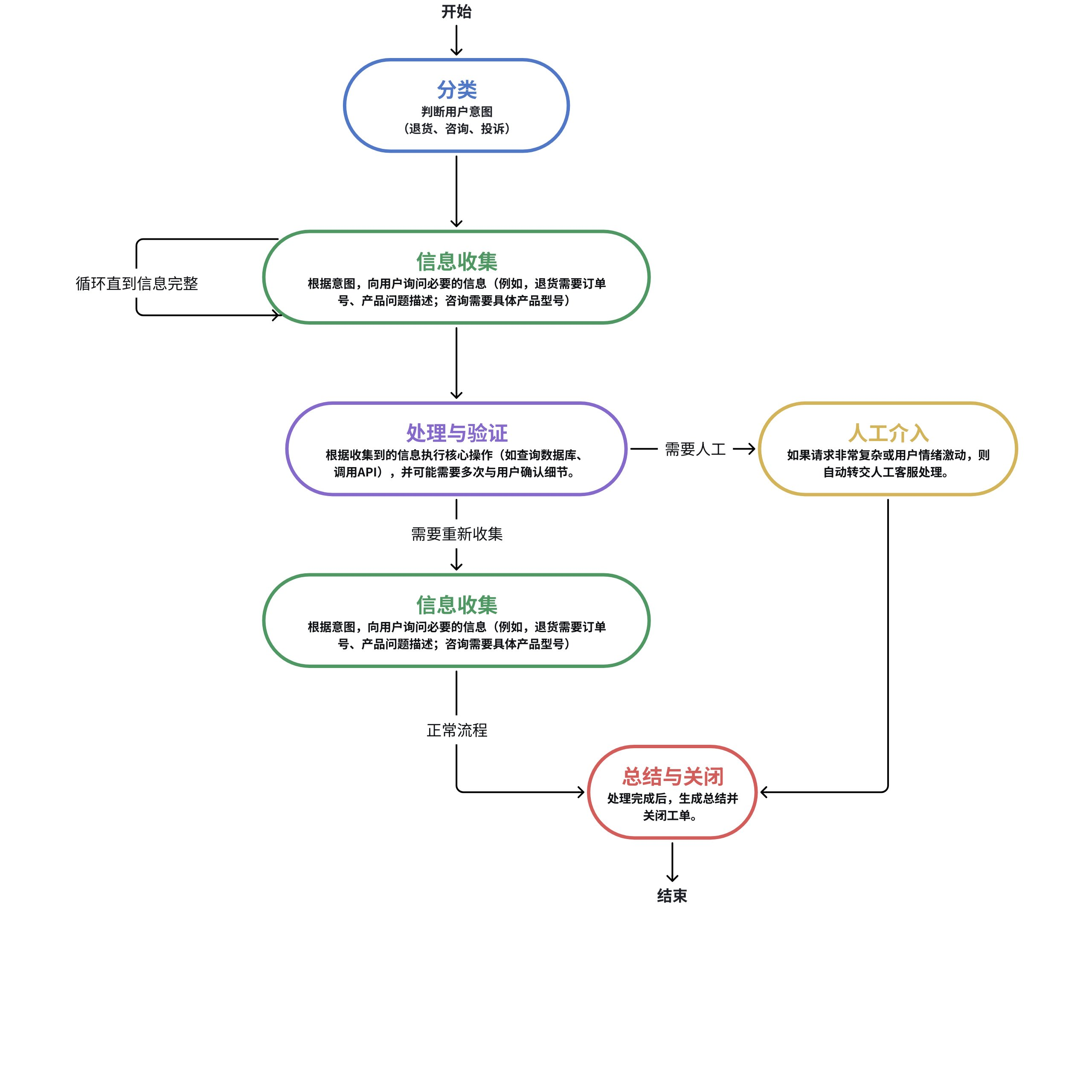
在上述示例中,我们可以定义图状态,用于存储流程中的临时数据和决策点,例如:
- intent: 用户意图(字符串,如"return","inquiry","complaint")。
- collected_info: 字典,存储收集到的信息(如订单号、问题描述)。
- needs_human: 布尔值,表示是否需要人工介入(默认False)。
- is_verified: 布尔值,表示信息是否已验证(默认False)。
- is_complete: 布尔值,表示流程是否完成(默认False)。
- message_history: 列表,存储对话历史,用于多轮交互。
- LangGraph并不是要取代LangChain,而是对LangChain的扩展和补充。
LangGraph底层大量复用了LangChain的组件(如模型接口、工具、记忆等),开发者可以在LangGraph的节点中直接使用LangChain的链或代理作为子流程。因此,LangGraph与LangChain是互补关系:
- 对于简单的线性任务,LangChain的链式结构已经足够高效;
- 而对于需要复杂控制流、长期状态和多智能体的场景,LangGraph提供了更强大的支持。
LangGraph的技术特点
LangGraph将应用逻辑建模为图(Graph)结构,其中:
- 节点:表示操作或状态
- 边:表示节点之间的转移和数据流。
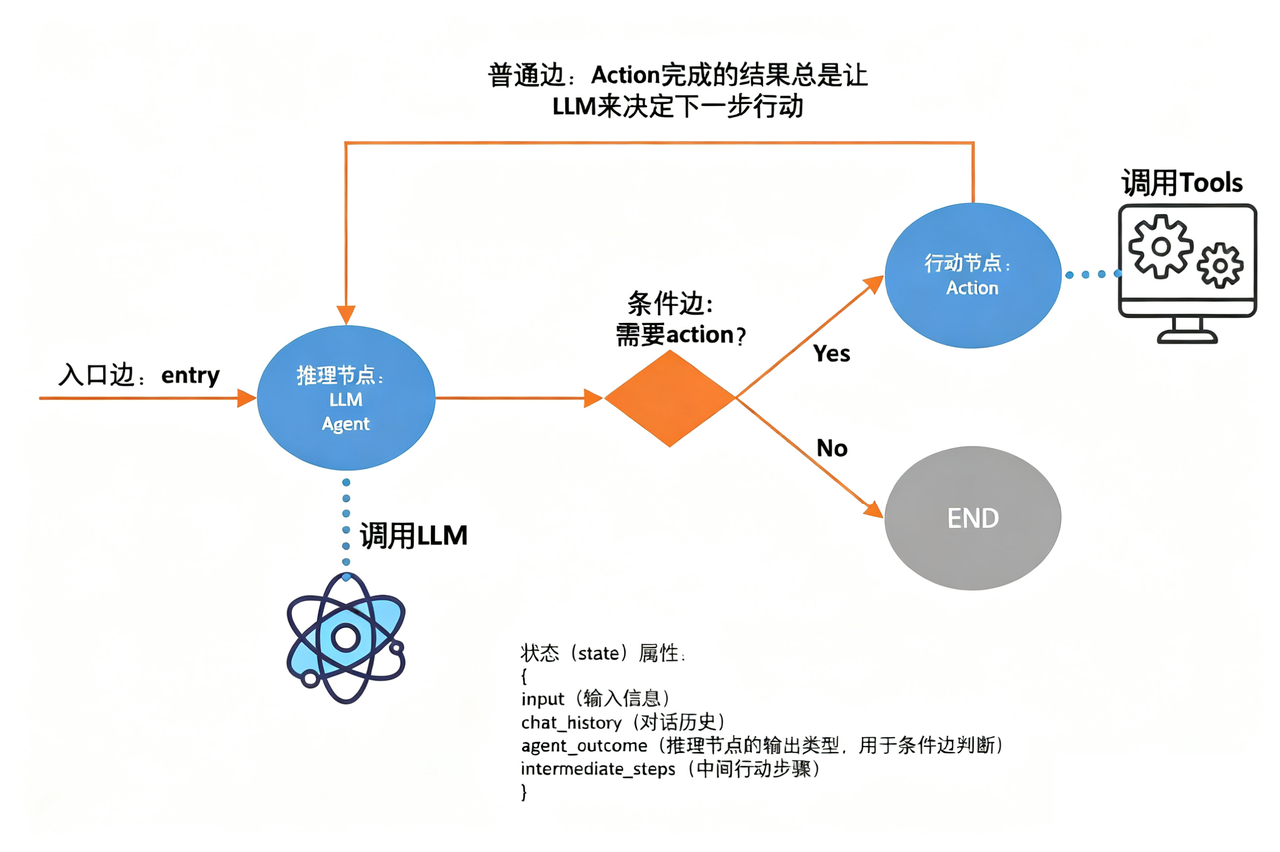
这种图式架构相比 LangChain 的链式结构更加灵活,主要体现在:
- 循环与分支:LangGraph 中的节点(Node)可以连接到其他任何节点,包括自己。你可以轻松设置一个 “信息收集” 节点,如果信息不完整,就让流程再次循环回这个节点本身,直到条件满足为止。
- 动态路由:通过条件边,可以根据当前状态的值,动态决定下一个要执行的节点。例如,在 “分类” 节点之后,可以根据分类结果,自动路由到 “处理退货”、“处理咨询” 或 “处理投诉” 等完全不同的子图中去。
- 状态维护:LangGraph 有一个核心的状态对象,在整个图的执行过程中自动持久化和传递。每个节点都可以读取和修改这个状态。这意味着用户的对话历史、已收集的信息都会自动保留,轻松支持长时间运行的任务。
- 持久执行:构建能够经受住故障并能长时间运行的代理,自动从上次中断的地方恢复。
- 人机协作:通过在执行过程中的任何时刻检查和修改代理状态,无缝融入人工监督。
- 全面记忆:创建真正具有状态的代理,兼具用于持续推理的短期工作记忆和跨会话的长期持久记忆。
- 使用 LangSmith 进行调试:借助可视化工具深入洞察复杂代理行为,这些工具可追踪执行路径、捕获状态转换并提供详细的运行时指标。
- 生产级部署:借助专为处理有状态、长时间运行工作流的独特挑战而设计的可扩展基础设施,自信地部署复杂的代理系统。
总结来说,构建 AI 代理应用时,如果用传统链式结构构建,会变成一个僵硬、脆弱、难以维护的 “面条代码”。而 LangGraph 则能将其建模为一个灵活、可靠、可视化程度高、且支持复杂逻辑(循环、分支、人工)的工作流图,这正是它为了解决日益复杂的 LLM 应用而诞生的价值所在。
LangChain团队于2024年推出了LangGraph框架,旨在提供一种图结构的、状态化的方式来构建复杂的AI代理应用。 LangGraph最初作为LangChain 0.1.0版本的一部分被引入,标志着LangChain从链式架构向图式架构的扩展。 在2024年初,LangGraph作为实验性功能发布,随后在2024年中开始独立演进。LangChain团队为LangGraph建立了专门的文档和代码仓库,并逐步将其打造为一个独立于LangChain主框架的工具集。在2024年中发布的版本中,LangGraph引入了Checkpoint(检查点)机制,允许将执行状态定期保存,以便故障恢复和审计。 2024年下半年,LangGraph发布了多个版本(如0.2.x、0.3.x等),不断改进其核心功能和稳定性。2024年底的版本增强了对异步执行和并发的支持,并提供了更完善的类型定义和错误处理。 2025年,LangGraph发布了0.4.x、0.5.x等版本,发展出完善的Python和JavaScript实现,并推出了LangGraph Platform等配套产品,用于简化复杂代理应用的部署和管理。 2025年6月,LangGraph发布了0.6版本,并启动了LangGraph v1.0的路线图计划,收集社区反馈以确定正式版的功能特性。 可以预见,LangGraph将在未来继续演进,成为构建高级AI代理和复杂工作流的重要框架。 版本发布:https://github.com/langchain-ai/langgraph/releases

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)