Hermes Agent 接入 Obsidian 实践:让 AI 成为你的第二大脑
Hermes Agent 接入 Obsidian 的实践,本质上是将 AI 的推理能力与个人知识管理进行深度绑定。知识分散:通过统一入口检索所有笔记语义断裂:通过双向链接关联碎片化信息上下文缺失:AI 能够理解文档的背景和历史。
Hermes Agent 接入 Obsidian 实践:让 AI 成为你的第二大脑
作者:系统架构之路
作为企业开发者或 AI 工程化实践者,你是否遇到过这样的场景:
项目中积累了大量技术文档、会议纪要和架构设计笔记,散落在各个系统里,每次需要检索某个知识点时,要在飞书、Confluence、邮件附件之间来回切换。
有没有一种可能,让 AI Agent 直接理解、检索、关联你的个人笔记库?
本文将介绍如何基于 Hermes Agent 的 Obsidian Skill,实现 AI 与笔记系统的深度集成。整套方案已在多个项目中落地验证,文中所有案例均已脱敏处理。
一、为什么需要让 AI Agent 接入笔记系统
1.1 知识分散是工程团队的隐形杀手
在一个典型的大型项目中,技术债务文档可能存在 JIRA,架构决策记录在 Confluence,团队成员的个人思考散落在 Notion 或飞书云文档。每次技术方案评审,工程师需要花费大量时间在不同平台间检索上下文。
更关键的是,这些文档之间缺乏语义关联。AI 无法理解「这篇文档提到的 XXX 方案」和「那篇文档里的 XXX 模块」实际上是同一个东西。
1.2 笔记系统是个人知识管理的原点
相比企业级协作工具,笔记系统(如 Obsidian、Logseq)更适合个人知识管理:
- 低门槛:任何人都可以快速记录
- 高自由度:不受企业IT限制
- 易关联:通过双向链接形成知识图谱
当 AI Agent 能够读写这个知识库时,它就成为了一个真正理解你思考脉络的助手,而不仅仅是执行指令的工具。
1.3 Hermes Agent 的 Obsidian Skill 设计目标
Hermes Agent 的 Obsidian 集成并非简单的文件读写,而是要实现:
- 语义检索:不仅按文件名搜索,还能理解文档内容
- 上下文关联:自动追踪文档间的引用关系
- 增量更新:感知笔记变化,实时同步到 AI 上下文中
- 双向通道:AI 既能读取已有笔记,也能生成新笔记反哺知识库
二、架构设计:双向同步的技术实现
2.1 整体架构
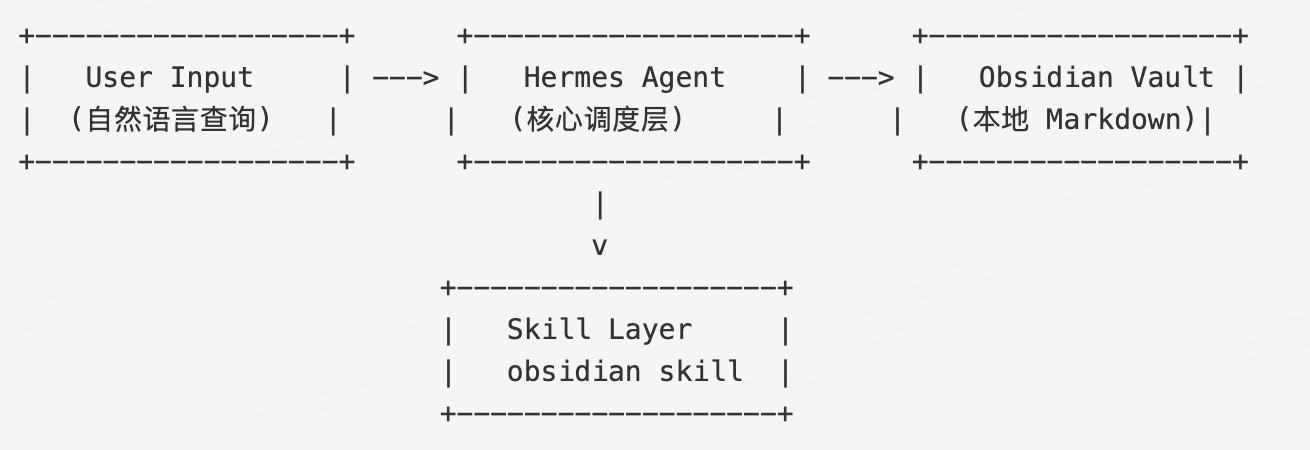
Hermes Agent 扮演调度核心,Obsidian Skill 负责与本地笔记库交互。Skill 层屏蔽了文件系统操作的细节,提供语义级别的接口供上层调用。
2.2 核心模块划分
整个集成方案分为三个层次:
接口层:对外暴露统一的笔记操作 API,包括查询、创建、更新、关联四大能力。
逻辑层:处理复杂的业务逻辑,如语义相似度计算、链接关系解析、上下文窗口管理。
存储层:直接操作 Obsidian 的 Markdown 文件及元数据,不依赖 Obsidian 的闭源插件协议。
2.3 双向同步的关键设计
让 AI 读写笔记容易,但要做到「语义一致」却很难。这里有三个关键设计:
设计一:版本化存储
每次 AI 对笔记的修改不是直接覆盖,而是生成带有时间戳的新文件。这避免了 AI 误操作导致的信息丢失,同时保留了完整的修改历史。
# 伪代码示例:版本化写入
def write_note_with_version(vault_path, filename, content):
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
versioned_filename = f"{filename}.v{timestamp}.md"
# 保留最新版本为原文件名
latest_path = os.path.join(vault_path, f"{filename}.md")
version_path = os.path.join(vault_path, "versions", versioned_filename)
# 写入逻辑...设计二:双向链接索引
Obsidian 的核心特性是双向链接。AI 不仅要会创建 [[链接]],还要能追踪一个知识点被哪些文档引用过。
# 伪代码示例:反向链接索引构建
def build_backlink_index(vault_path):
index = defaultdict(list)
for md_file in glob.glob(os.path.join(vault_path, "**/*.md"), recursive=True):
content = read_file(md_file)
# 提取所有 [[wikilink]]
links = re.findall(r'\[\[([^\]]+)\]\]', content)
for link in links:
index[link].append(md_file)
return index设计三:上下文窗口管理
当笔记库达到一定规模后,一次查询可能返回大量相关内容。上下文窗口管理模块负责裁剪、摘要和优先级排序,确保 AI 每次只处理最相关的信息。
三、核心代码逻辑说明
3.1 Skill 入口设计
Obsidian Skill 对外提供四个核心指令:
note_search:在笔记库中检索相关内容note_read:读取指定笔记的完整内容note_create:创建新笔记或向已有笔记追加内容note_link:在两篇笔记之间建立关联
每个指令都遵循统一的返回格式:
{
"status": "success|error",
"data": { ... },
"message": "操作描述"
}3.2 检索逻辑的实现
检索是整个 Skill 最核心的部分。它分为两个阶段:
第一阶段:粗筛
基于文件名和标签进行初步过滤。Obsidian 支持在 YAML front matter 中定义标签,这为粗筛提供了结构化索引。
# 伪代码逻辑
1. 扫描笔记库下所有 .md 文件
2. 解析每个文件的 front matter,提取 tags、created、modified 等元数据
3. 根据查询关键词匹配文件名和标签
4. 返回候选文件列表(通常 10-50 个)第二阶段:精排
对候选文件进行内容级别的语义匹配。这里可以接入文本嵌入模型计算相似度,也可以使用关键词密度等简单策略。
# 伪代码示例:简单相似度计算
def content_similarity(query, document):
query_terms = set(query.lower().split())
doc_terms = set(document.lower().split())
intersection = query_terms & doc_terms
union = query_terms | doc_terms
return len(intersection) / len(union) # Jaccard 相似度3.3 创建和更新逻辑
笔记创建不是简单的文件写入。为了保持笔记库的健康度,需要处理以下场景:
场景一:同名文件检测
如果已存在同名笔记,需要询问用户是覆盖、合并还是新建。
场景二:自动标签推断
根据笔记内容自动推荐标签。例如,如果笔记提到「微服务」「API 网关」,系统会自动建议添加这些标签。
场景三:模板填充
创建特定类型笔记(如技术方案、会议纪要)时,可以指定模板,确保格式统一。
3.4 链接关联逻辑
链接关联是 Obsidian 的精髓。当用户说「把这两篇笔记关联起来」,系统需要:
- 理解两篇笔记的核心主题
- 在适当前置位置插入
[[wikilink]]语法 - 如果目标笔记不存在,提供创建建议
# 伪代码示例:智能插入链接
def insert_link(source_note, target_note, insert_position="auto"):
source_content = read_note(source_note)
# 找到最相关的段落
best_paragraph = find_most_related_paragraph(source_content, target_note)
# 在段落末尾插入链接
link_syntax = f"[[{target_note}]]"
# 追加到该段落...四、实际应用场景举例
4.1 场景一:技术方案评审助手
在评审一个新系统设计方案时,工程师通常需要了解:
- 团队过去是否有过类似实践
- 某项技术选型背后的决策记录
- 相关系统的依赖关系
传统方式是翻阅历史文档。接入 Hermes Agent 后,只需一句自然语言查询:
「查询笔记库中与分布式事务相关的技术方案和决策记录」
系统会自动检索相关笔记,并呈现一个包含所有相关文档和它们之间引用关系的信息图谱。
4.2 场景二:代码审查知识辅助
代码审查时,AI 可以根据审查的代码片段,自动关联:
- 对应的架构设计文档
- 相关的性能测试报告
- 以往类似问题的修复记录
这让审查者能够快速了解代码的上下文,而不是仅从代码本身判断其合理性。
4.3 场景三:个人知识问答
当团队成员向 AI 提问时,AI 不仅能从互联网检索答案,还能从个人笔记库中寻找该成员自己记录的经验和思考。这种个性化的知识检索大大提升了 AI 回答的相关性。
五、避坑指南
5.1 坑点一:Vault 路径中的空格
Obsidian 的 Vault 路径可能包含空格(如 My Notes/)。在所有文件操作中,必须对路径加引号。实践中建议在环境变量中统一配置 Vault 路径,并在 Skill 代码中强制校验。
5.2 坑点二:Wikilink 的大小写敏感性
不同操作系统的文件系统对大小写敏感性不同。Obsidian 本身支持模糊匹配(如输入 [[架构]] 可以打开 系统架构设计.md),但 Skill 层的路径操作必须严格区分。建议在索引构建时统一转为小写,查询时做标准化处理。
5.3 坑点三:Front Matter 与正文的冲突
Markdown 的 YAML front matter 使用 --- 分隔符。如果 AI 生成的内容中也包含 ---,会导致解析错误。解决方案是在写入前检测内容中的分隔符,并做转义或移动到正文之后处理。
5.4 坑点四:大文件导致内存溢出
当笔记库包含大量文档时,一次性加载所有内容会消耗大量内存。建议使用流式读取和分页检索,只在需要时加载特定文件。
5.5 坑点五:并发写入冲突
如果多个 Agent 实例同时对同一笔记进行写入,可能导致内容丢失。建议使用文件锁机制或在写入前检查文件的修改时间戳。
六、总结与延伸
6.1 核心价值回顾
Hermes Agent 接入 Obsidian 的实践,本质上是将 AI 的推理能力与个人知识管理进行深度绑定。它解决了三个核心问题:
- 知识分散:通过统一入口检索所有笔记
- 语义断裂:通过双向链接关联碎片化信息
- 上下文缺失:AI 能够理解文档的背景和历史
6.2 进阶方向
如果你对本实践感兴趣,可以进一步探索以下方向:
方向一:多 Vault 支持
目前方案针对单一 Vault 设计。进阶方向是支持多个 Vault(如个人笔记、工作笔记、项目笔记)的联合检索。
方向二:与向量数据库结合
当前的检索基于关键词匹配。进阶方案可以引入向量嵌入,实现语义级别的相似度检索。
方向三:自动知识图谱构建
基于笔记间的链接关系,自动绘制知识图谱,辅助可视化思考。
方向四:与团队知识库打通
将个人笔记与团队知识库(如 Confluence、飞书)进行双向同步,让个人沉淀也能贡献到团队知识资产中。
实践指引
如果你想立即尝试这个方案,可以按照以下步骤操作:
- 在本地部署 Hermes Agent 并配置 Obsidian Skill
- 指定你的 Obsidian Vault 路径作为知识库根目录
- 用
note_search指令测试基本检索功能 - 尝试用
note_create创建一篇测试笔记 - 用
note_link将新笔记与已有笔记建立关联
完整的 Skill 源码和技术文档,可以在项目仓库中查阅。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)