AI Agent 工程化实践:Skill as Prompt 与渐进式加载机制
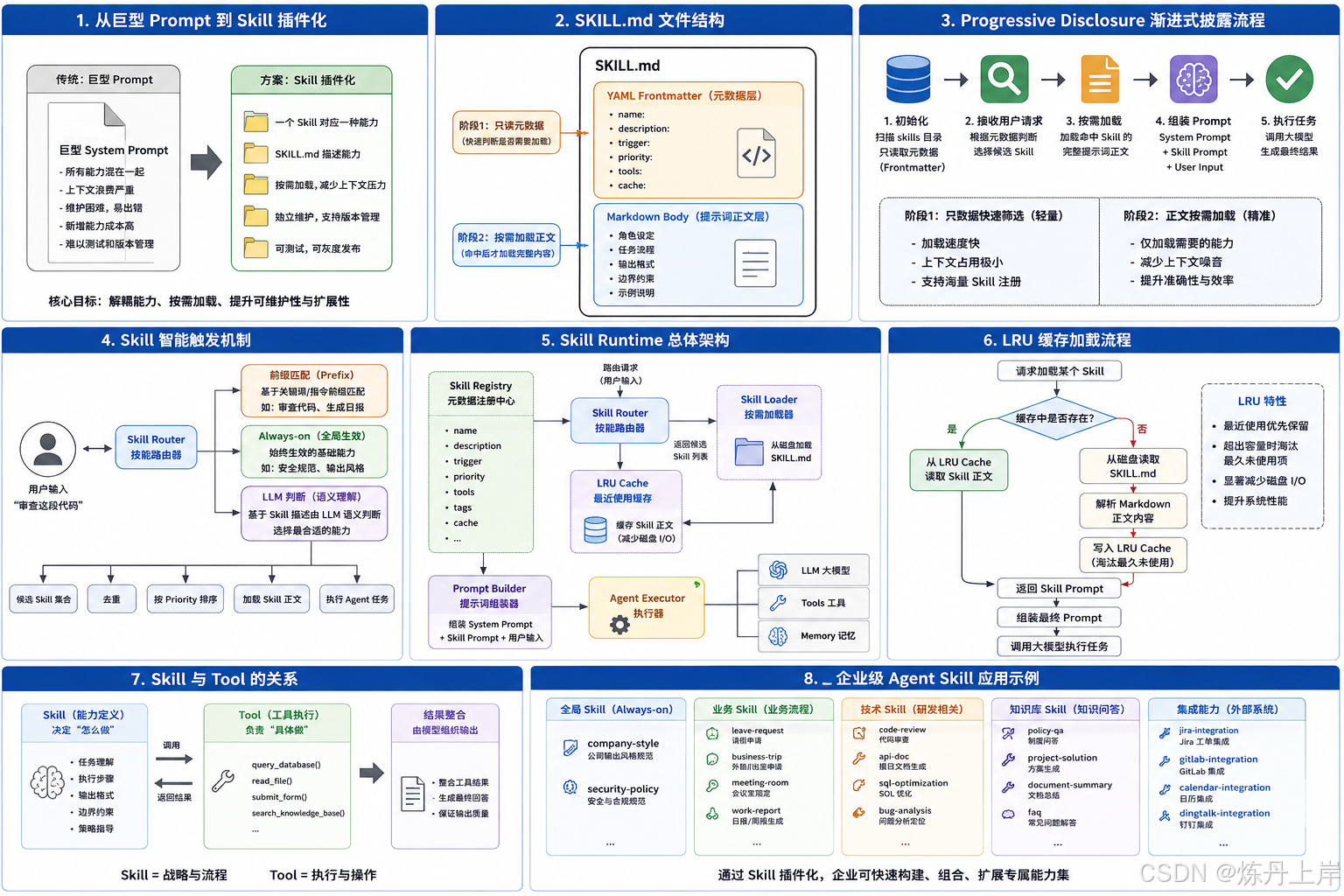
本文探讨了AI Agent系统中Prompt管理失控的问题,并提出Skill体系解决方案。传统方式将所有能力集中在一个系统Prompt中,导致上下文浪费、能力污染等问题。Skill体系将能力拆分为独立模块,每个Skill包含元数据和提示词正文,采用渐进式披露原则按需加载。这种设计减少初始化成本、节省上下文窗口、降低指令冲突,使Prompt工程更接近软件工程,提升复杂Agent项目的可维护性。
前言
在构建 AI Agent 系统时,我们经常会遇到一个非常现实的问题:
Agent 的能力越做越多,Prompt 越写越长,系统也越来越难维护。
一开始,我们可能只需要一个简单的系统提示词:
你是一个智能助手,请根据用户的问题进行回答。
但随着业务不断复杂,系统 Prompt 很快就会膨胀成这样:
你是一个智能助手。
你可以分析代码。
你可以读取文件。
你可以生成日报。
你可以编写接口文档。
你可以总结会议纪要。
你可以根据公司模板输出方案。
你可以调用 OA 系统。
你可以处理请假、外勤、会议室预定。
你需要遵守公司的输出规范。
你需要注意安全边界。
你需要……
最后,一个 Agent 的系统提示词会变成一个巨大的“提示词泥球”。
这种方式在 Demo 阶段问题不大,但一旦进入真实项目,尤其是企业级 Agent 场景,就会暴露出很多问题:
- Prompt 过长,浪费上下文窗口。
- 所有能力一次性加载,哪怕当前任务根本用不到。
- 不同能力的规则互相干扰,导致模型输出不稳定。
- 新增能力需要频繁修改主 Prompt,维护成本越来越高。
- 多人协作困难,很难进行版本管理、测试和灰度发布。
所以,我们需要一种更加工程化的方式来管理 Agent 的能力。
这就是本文要介绍的核心方案:
用一套 Skill 体系,把 Agent 的能力拆成一个个独立、可加载、可触发、可缓存的能力模块。
这套体系可以概括为四个关键词:
- Skill as Prompt
- Progressive Disclosure
- 智能触发
- LRU 缓存
Anthropic 在 Agent Skills 的设计中也采用了类似思路:Skill 可以被组织成包含 SKILL.md 的目录,SKILL.md 中包含 YAML frontmatter 和具体说明,系统可以根据任务动态加载相关能力。Claude Help Center 也将 Skills 描述为“可动态加载的指令、脚本和资源文件夹”,用于让模型更好地完成特定任务。(Anthropic)
一、传统 Agent Prompt 为什么会失控?
很多 Agent 项目最开始都是这样做的:
系统提示词 = 角色设定 + 所有工具说明 + 所有业务规则 + 所有输出规范 + 所有异常处理逻辑
这种写法简单直接,但扩展性很差。
假设我们正在做一个企业级 AI 助手,它可能需要支持:
- 代码审查
- 接口文档生成
- 项目日报生成
- 周报和月报总结
- RAG 知识库问答
- 数据库 SQL 分析
- OA 请假流程填报
- 外勤申请
- 会议室预定
- 项目方案生成
- 招投标文件分析
- API 测试用例生成
如果把所有能力都写进一个系统 Prompt,用户只是问一句:
帮我看一下这段 FastAPI 代码有没有问题。
模型却同时看到了:
日报规范
OA 请假流程
会议纪要模板
招投标方案格式
知识库引用规范
接口文档输出规范
数据库分析规则
……
这显然是不合理的。
它会导致两个核心问题。
1. 上下文浪费
模型每次推理都要处理大量无关内容。
这不仅会增加 token 成本,还会降低响应速度。
更严重的是,长 Prompt 会占用原本应该留给用户输入、工具结果、历史上下文和模型推理空间的上下文窗口。
2. 能力污染
不同任务的提示词规则可能互相冲突。
例如:
- “日报生成 Skill”要求输出固定日报格式。
- “代码审查 Skill”要求输出问题列表和修改建议。
- “方案生成 Skill”要求按照项目背景、建设目标、技术路线、实施计划输出。
- “知识库问答 Skill”要求必须引用检索来源。
如果这些规则同时进入上下文,模型就可能混用格式。
最后结果可能是:
用户让模型审查代码,模型却按照项目日报格式输出。
所以更合理的方式是:
当前任务需要什么能力,就只加载什么能力。
这就是 Skill 体系要解决的问题。
二、什么是 Skill as Prompt?
所谓 Skill as Prompt,就是把 Agent 的每一种能力封装成一个独立的提示词模块。
每个 Skill 对应一个目录,每个目录下有一个 SKILL.md 文件。
例如:
skills/
code-review/
SKILL.md
api-doc-generator/
SKILL.md
work-report/
SKILL.md
rag-answer/
SKILL.md
oa-form-fill/
SKILL.md
每个 SKILL.md 文件由两部分组成:
- frontmatter 元数据
- body 提示词正文
一个典型的 SKILL.md 可以这样写:
---
name: code-review
version: 1.0.0
description: 用于审查代码质量、发现潜在 bug、提出优化建议
trigger:
type: prefix
patterns:
- "审查代码"
- "帮我看看这段代码"
- "code review"
priority: 80
cache: true
tags:
- code
- review
- backend
---
# Code Review Skill
你是一个资深代码审查专家。
当用户提供代码时,你需要从以下角度进行分析:
1. 是否存在明显 bug
2. 是否存在性能问题
3. 是否存在安全风险
4. 命名是否清晰
5. 代码结构是否合理
6. 是否符合工程化最佳实践
输出格式:
## 总体评价
## 主要问题
## 优化建议
## 修改后的示例代码
这里的 frontmatter 是机器可读的元数据。
name: code-review
version: 1.0.0
description: 用于审查代码质量、发现潜在 bug、提出优化建议
trigger:
type: prefix
patterns:
- "审查代码"
- "帮我看看这段代码"
priority: 80
cache: true
它主要给 Agent Runtime 使用,用来判断:
- 这个 Skill 叫什么?
- 它适合解决什么问题?
- 它应该什么时候被触发?
- 它的优先级是多少?
- 是否允许缓存?
而 body 是真正给模型看的提示词正文。
你是一个资深代码审查专家。
当用户提供代码时,你需要……
这种设计的关键是:
Skill 既是一个 Prompt 文件,也是一个可调度的能力模块。
YAML frontmatter 本身是一种常见的 Markdown 元数据组织方式,GitHub Docs 也将它描述为位于 Markdown 文件顶部的 key-value 元数据块。(GitHub Docs)
三、Progressive Disclosure:渐进式披露
Skill 体系最核心的设计思想是 Progressive Disclosure,也就是“渐进式披露”。
它的原则非常简单:
初始化时只读取 Skill 的元数据,真正命中时才加载完整提示词正文。
也就是说,系统启动时不会把所有 SKILL.md 的完整内容都塞进上下文,而是只解析 frontmatter。
例如系统启动后只拿到类似这样的 Skill Registry:
[
{
"name": "code-review",
"description": "用于审查代码质量、发现潜在 bug、提出优化建议",
"trigger": {
"type": "prefix",
"patterns": ["审查代码", "code review"]
},
"priority": 80
},
{
"name": "work-report",
"description": "用于根据工作记录生成日报、周报、月报",
"trigger": {
"type": "llm"
},
"priority": 60
}
]
此时系统并没有读取完整的 Prompt 正文。
只有当用户输入:
审查代码:下面这段 FastAPI 代码有没有问题?
系统匹配到 code-review 之后,才会真正读取:
skills/code-review/SKILL.md
并把 body 部分加入本轮模型上下文。
这就是“渐进式披露”。
Anthropic 对 Agent Skills 的介绍中,也强调了 Skill 可以通过按需加载的方式扩展 Agent 能力,而不是一次性把所有任务说明塞进上下文。(Anthropic)
四、为什么 Progressive Disclosure 很重要?
1. 减少初始化成本
系统启动时只扫描元数据,不读取完整 Prompt。
当 Skill 数量很多时,这个优化非常明显。
假设系统里有 100 个 Skill,每个 Skill 的 Prompt 正文平均 2000 字,如果全部加载,就会变成一个非常庞大的上下文负担。
但如果只加载 metadata,系统只需要处理几十 KB 的轻量索引。
2. 节省上下文窗口
用户没有触发的 Skill,不应该进入模型上下文。
例如用户只是让 Agent 写接口文档,就不需要加载:
- 日报 Skill
- 会议纪要 Skill
- SQL 分析 Skill
- OA 请假 Skill
- 招投标方案 Skill
这样可以让模型把注意力集中在当前任务上。
3. 降低指令冲突
每次只加载相关 Skill,可以减少不同能力之间的提示词污染。
这对于复杂 Agent 非常重要。
尤其是企业场景中,不同业务的输出格式、审批逻辑、权限要求都不一样,如果全部放进系统 Prompt,很容易互相干扰。
4. 让 Prompt 工程变成软件工程
传统 Prompt 是一整坨文本。
Skill 体系则让 Prompt 拥有了类似软件模块的能力:
- 可以拆分
- 可以复用
- 可以版本管理
- 可以测试
- 可以灰度发布
- 可以按需加载
这才是复杂 Agent 项目长期可维护的关键。
五、Skill 的推荐文件结构
一个比较完整的 Skill 可以这样设计:
skills/
api-doc-generator/
SKILL.md
examples.md
output_schema.json
tests.yaml
其中:
SKILL.md 核心元数据和提示词
examples.md 示例输入输出
output_schema.json 结构化输出约束
tests.yaml 回归测试用例
SKILL.md 示例:
---
name: api-doc-generator
version: 1.0.0
description: 根据接口信息生成标准 API 文档
trigger:
type: prefix
patterns:
- "生成接口文档"
- "帮我写 API 文档"
- "生成 API 文档"
priority: 70
cache: true
tags:
- api
- document
- backend
---
# API 文档生成 Skill
你是一个专业的后端接口文档编写助手。
用户会提供接口路径、请求参数、响应结构、业务说明等内容。
你需要输出结构清晰、适合研发团队使用的 API 文档。
## 输出格式
### 1. 接口说明
### 2. 请求地址
### 3. 请求方式
### 4. 请求参数
### 5. 响应参数
### 6. 示例请求
### 7. 示例响应
### 8. 错误码说明
## 约束要求
- 参数说明要清晰。
- 字段类型要标明。
- 示例 JSON 要格式化。
- 如果信息缺失,需要明确指出缺失项。
- 不要自行编造不存在的字段。
这样做的好处是:
- frontmatter 负责调度。
- body 负责执行。
- examples 负责示范。
- schema 负责输出约束。
- tests 负责质量回归。
这时 Skill 就不再只是一个 Prompt,而是一个完整的能力包。
六、三种智能触发模式
Skill 体系的核心不只是“怎么存储”,更重要的是“怎么触发”。
一个实用的 Skill Runtime 至少应该支持三种触发模式:
- 前缀匹配
- always-on
- LLM 判断
1. 前缀匹配
前缀匹配是最简单、最快的触发方式。
适合命令式任务。
例如:
trigger:
type: prefix
patterns:
- "审查代码"
- "code review"
- "帮我看看这段代码"
当用户输入:
审查代码:下面这段代码有没有问题?
系统可以直接命中 code-review Skill。
伪代码如下:
def match_prefix_skill(user_input, skill_metadata_list):
matched = []
for skill in skill_metadata_list:
trigger = skill.get("trigger", {})
if trigger.get("type") != "prefix":
continue
patterns = trigger.get("patterns", [])
for pattern in patterns:
if user_input.startswith(pattern) or pattern in user_input:
matched.append(skill)
break
return sorted(
matched,
key=lambda x: x.get("priority", 0),
reverse=True
)
前缀匹配的优点是:
- 快
- 稳定
- 成本低
- 可控性强
适合这些任务:
生成日报:……
生成接口文档:……
审查代码:……
分析 SQL:……
总结会议纪要:……
但它也有缺点:对自然语言表达不够灵活。
例如用户说:
这段代码我总感觉哪里不对,你帮我看看。
这时候未必能命中前缀规则。
于是我们需要 LLM 判断。
2. always-on
有些 Skill 不是某个具体任务,而是全局规范。
例如:
- 安全规范
- 公司统一输出风格
- 禁止泄露敏感信息
- 所有技术方案都要包含风险说明
- 所有回答都要先给结论
- 所有不确定信息都要明确说明
这种 Skill 可以设计成 always-on。
示例:
---
name: company-style
version: 1.0.0
description: 公司统一输出风格规范
trigger:
type: always-on
priority: 100
cache: true
---
# 公司统一输出规范
所有回答都应该遵守以下规则:
1. 先给结论,再解释原因。
2. 技术方案要包含优点、缺点和适用场景。
3. 涉及生产环境时,需要补充风险点。
4. 不确定的信息要明确说明。
5. 不要编造接口、字段、数据和政策。
always-on Skill 会在每次对话中默认加载。
但这里必须注意:
always-on Skill 一定要克制。
如果 always-on 太多,系统又会退化成“巨型 Prompt”。
建议 always-on 只放:
- 安全边界
- 全局风格
- 项目级硬约束
- 用户长期偏好
- 输出底线规范
具体业务能力不要放 always-on。
3. LLM 判断
LLM 判断适合处理语义模糊的场景。
例如用户输入:
我这里有一段接口返回,你帮我看看这个设计合不合理。
这个请求可能命中:
- API 设计 Skill
- Code Review Skill
- 后端架构 Skill
- 接口文档 Skill
单靠关键词不一定准确。
这时候可以设计一个轻量级 Skill Router,让模型根据 Skill metadata 判断应该加载哪些 Skill。
注意:这个阶段只给模型看 metadata,不给完整 Prompt。
示例路由 Prompt:
你是一个 Skill 路由器。
请根据用户输入,从候选 Skill 中选择最适合的一个或多个。
你只能返回 JSON,不要输出多余内容。
用户输入:
{{user_input}}
候选 Skill:
{{skill_metadata_list}}
返回格式:
{
"matched_skills": [
{
"name": "skill_name",
"reason": "为什么选择它",
"confidence": 0.0
}
]
}
候选 Skill metadata:
[
{
"name": "code-review",
"description": "用于审查代码质量、发现潜在 bug、提出优化建议",
"tags": ["code", "review", "bug"]
},
{
"name": "api-design",
"description": "用于分析接口设计是否合理,包括参数、响应结构、错误码、幂等等",
"tags": ["api", "backend", "design"]
}
]
模型返回:
{
"matched_skills": [
{
"name": "api-design",
"reason": "用户关注接口返回结构和设计合理性,更符合 API 设计分析任务",
"confidence": 0.86
}
]
}
然后系统再加载 api-design 的完整 Skill body。
这就是一个比较优雅的两阶段加载流程:
先用轻量 metadata 判断是否需要
再按需加载完整 Prompt
七、Skill 加载流程设计
整体流程可以设计成这样:
系统启动
↓
扫描 skills 目录
↓
只解析每个 SKILL.md 的 frontmatter
↓
构建 Skill Registry
↓
用户输入
↓
执行 Skill 触发判断
↓
匹配到相关 Skill
↓
读取 Skill body
↓
加入模型上下文
↓
执行任务
可以抽象成下面这个架构:
+-------------------+
| User Input |
+---------+---------+
|
v
+-------------------+
| Skill Router |
| prefix / always |
| LLM judge |
+---------+---------+
|
v
+-------------------+
| Skill Registry |
| metadata only |
+---------+---------+
|
v
+-------------------+
| Load Skill Body |
| on demand |
+---------+---------+
|
v
+-------------------+
| LLM Execution |
+-------------------+
这里有一个关键点:
Skill Registry 只保存轻量级索引,不保存所有 Prompt 正文。
这也是它能够扩展到几十个、上百个 Skill 的基础。
八、LRU 缓存:避免重复磁盘 I/O
如果每次触发 Skill 都从磁盘读取 SKILL.md,在高并发场景下会产生额外开销。
因此可以引入 LRU 缓存。
LRU 是 Least Recently Used 的缩写,意思是“最近最少使用”。
它的策略很简单:
最近使用过的 Skill 保留在内存里,很久没用过的 Skill 被淘汰。
例如缓存容量设置为 32:
CACHE_SIZE = 32
当系统第一次加载 code-review Skill 后,把它放入缓存。
下次再次触发 code-review 时,就不需要重新读取磁盘,直接从内存获取。
Python 标准库中的 functools.lru_cache 就提供了类似能力,它可以缓存函数调用结果,并通过 maxsize 控制缓存容量。(Python documentation)
示例:
from functools import lru_cache
from pathlib import Path
import frontmatter
SKILL_DIR = Path("./skills")
@lru_cache(maxsize=32)
def load_skill_body(skill_name: str) -> str:
skill_file = SKILL_DIR / skill_name / "SKILL.md"
if not skill_file.exists():
raise FileNotFoundError(f"Skill not found: {skill_name}")
post = frontmatter.load(skill_file)
return post.content
也可以自己实现一个简单 LRU:
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity: int = 32):
self.capacity = capacity
self.cache = OrderedDict()
def get(self, key: str):
if key not in self.cache:
return None
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key: str, value: str):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)
使用方式:
skill_cache = LRUCache(capacity=32)
def get_skill_body(skill_name: str) -> str:
cached = skill_cache.get(skill_name)
if cached:
return cached
body = read_skill_body_from_disk(skill_name)
skill_cache.put(skill_name, body)
return body
这样可以减少重复磁盘读取,提高系统性能。
九、完整代码示例:实现一个简单 Skill Runtime
下面给出一个简化版本。
目录结构:
project/
main.py
skills/
code-review/
SKILL.md
work-report/
SKILL.md
company-style/
SKILL.md
main.py:
from pathlib import Path
from functools import lru_cache
import frontmatter
SKILL_DIR = Path("./skills")
def load_skill_metadata():
"""
系统启动时只加载每个 SKILL.md 的 frontmatter。
不读取完整 Prompt 正文。
"""
registry = {}
for skill_file in SKILL_DIR.glob("*/SKILL.md"):
post = frontmatter.load(skill_file)
metadata = dict(post.metadata)
skill_name = metadata.get("name") or skill_file.parent.name
registry[skill_name] = {
"name": skill_name,
"path": str(skill_file),
"description": metadata.get("description", ""),
"trigger": metadata.get("trigger", {}),
"priority": metadata.get("priority", 0),
"cache": metadata.get("cache", True),
"tags": metadata.get("tags", []),
"version": metadata.get("version", "0.0.0"),
}
return registry
@lru_cache(maxsize=32)
def load_skill_body(skill_path: str) -> str:
"""
只有 Skill 被命中时,才加载 body。
并且使用 LRU 缓存减少重复磁盘 I/O。
"""
post = frontmatter.load(skill_path)
return post.content
def match_always_on_skills(registry):
return [
skill for skill in registry.values()
if skill.get("trigger", {}).get("type") == "always-on"
]
def match_prefix_skills(user_input, registry):
matched = []
for skill in registry.values():
trigger = skill.get("trigger", {})
if trigger.get("type") != "prefix":
continue
patterns = trigger.get("patterns", [])
for pattern in patterns:
if user_input.startswith(pattern) or pattern in user_input:
matched.append(skill)
break
return matched
def select_skills(user_input, registry):
matched = []
# 1. always-on Skill 默认加载
matched.extend(match_always_on_skills(registry))
# 2. prefix Skill 根据用户输入匹配
matched.extend(match_prefix_skills(user_input, registry))
# 3. 去重
unique = {}
for skill in matched:
unique[skill["name"]] = skill
# 4. 按优先级排序
return sorted(
unique.values(),
key=lambda x: x.get("priority", 0),
reverse=True
)
def build_prompt(user_input, selected_skills):
skill_prompts = []
for skill in selected_skills:
body = load_skill_body(skill["path"])
skill_prompts.append(
f"## Skill: {skill['name']}\n\n{body}"
)
final_prompt = f"""
你是一个智能 Agent。
下面是本次任务需要使用的 Skill:
{chr(10).join(skill_prompts)}
用户输入:
{user_input}
请根据以上 Skill 完成任务。
"""
return final_prompt
if __name__ == "__main__":
registry = load_skill_metadata()
user_input = "审查代码:下面这段 FastAPI 代码有没有问题?"
selected_skills = select_skills(user_input, registry)
prompt = build_prompt(user_input, selected_skills)
print(prompt)
这个简化版实现了几个关键能力:
- 启动时只加载 metadata。
- 用户输入后进行 Skill 匹配。
- 命中 Skill 后才加载 body。
- 使用 LRU 缓存 Skill body。
- 动态组装最终 Prompt。
虽然它只是一个基础版本,但已经具备 Skill Runtime 的核心雏形。
十、Skill 不应该只是 Prompt,还可以绑定工具
在真实 Agent 系统中,Skill 不应该只是一段提示词。
它还可以声明自己需要哪些工具。
例如一个 OA 请假 Skill:
---
name: oa-leave-request
version: 1.0.0
description: 用于根据自然语言帮助员工填写请假申请
trigger:
type: llm
priority: 90
tools:
- get_user_profile
- query_leave_balance
- submit_leave_form
cache: true
---
# OA 请假申请 Skill
你是一个企业 OA 助手。
当用户表达请假意图时,你需要:
1. 识别请假类型。
2. 识别开始时间和结束时间。
3. 识别请假原因。
4. 查询用户剩余假期。
5. 检查信息是否完整。
6. 在用户确认后提交请假申请。
如果缺少必要字段,需要向用户追问。
在提交表单前,必须让用户确认。
这里的 frontmatter 中声明了工具:
tools:
- get_user_profile
- query_leave_balance
- submit_leave_form
这样 Agent Runtime 在加载 Skill 时,可以同步挂载对应工具。
也就是说:
Skill = Metadata + Prompt + Tools + Examples + Output Schema + Permissions
进一步可以扩展成:
Skill = 能力描述 + 触发规则 + 提示词 + 工具声明 + 输出协议 + 权限控制
这时 Skill 就成为 Agent 系统中的最小能力单元。
十一、Skill 的版本管理与测试
如果 Skill 要用于生产环境,就不能只靠“感觉可用”。
它应该像代码一样被管理。
建议每个 Skill 至少包含:
version: 1.0.0
author: ai-team
updated_at: 2026-05-18
并且放入 Git 仓库。
推荐目录:
skills/
code-review/
SKILL.md
examples.md
tests.yaml
CHANGELOG.md
tests.yaml 可以这样设计:
cases:
- name: "FastAPI 代码审查"
input: "审查代码:下面这段 FastAPI 代码有没有问题?"
expected_contains:
- "总体评价"
- "主要问题"
- "优化建议"
- name: "SQL 性能分析"
input: "分析 SQL:select * from user where name like '%abc%'"
expected_contains:
- "索引"
- "性能"
- "优化建议"
这样每次修改 Skill 后,可以跑一批回归测试。
目的不是保证模型每次输出完全一致,而是保证:
- 没有偏离任务目标。
- 没有丢失关键结构。
- 没有违反输出规范。
- 没有出现明显幻觉。
- 没有触发错误工具。
十二、Skill 体系中的安全问题
Skill 体系虽然优雅,但也会带来新的安全风险。
因为 SKILL.md 本质上是“可被模型读取并执行的自然语言指令”。
如果 Skill 来自第三方,或者可以被用户上传,就可能出现类似“Prompt Supply Chain Attack”的问题。
近期也有研究关注 SKILL.md 类机制中的语义供应链风险:攻击者可以通过 skill 描述、触发词、说明文本来影响 Agent 的发现、选择和加载过程。该研究指出,SKILL.md 并不只是被动文档,它会影响 Agent 如何发现、信任和使用第三方能力。(arXiv)
所以生产环境中要注意:
1. Skill 来源必须可信
不要随便加载未知来源的 Skill。
第三方 Skill 至少需要经过审核。
2. Skill 权限要隔离
不同 Skill 能调用的工具应该不同。
例如:
permissions:
tools:
- query_leave_balance
forbidden_tools:
- submit_payment
- delete_database
高风险工具必须要求用户确认。
3. Skill 不应该拥有无限权限
不要因为某个 Skill 被命中,就把所有工具都暴露给模型。
应该按 Skill 挂载最小工具集。
这符合最小权限原则。
4. Skill 修改要有审计
Skill 文件修改应该记录:
- 修改人
- 修改时间
- 修改原因
- 版本号
- diff 内容
因为 Skill 的变化可能直接影响 Agent 行为。
十三、Skill 设计的最佳实践
1. 一个 Skill 只解决一类问题
不要让一个 Skill 过于庞大。
例如下面这种就不好:
backend-all-in-one-skill
它同时处理:
- 代码审查
- 接口设计
- SQL 优化
- 架构设计
- 日志规范
- 部署方案
这会重新变成巨型 Prompt。
更合理的是拆成:
code-review
api-design
sql-optimization
backend-architecture
logging-best-practice
deployment-advice
2. Skill 也不能拆得太碎
过粗不好,过细也不好。
例如:
daily-report-skill
weekly-report-skill
monthly-report-skill
这三个其实可以合并成:
work-report-skill
然后在内部根据用户意图区分日报、周报、月报。
一个经验判断是:
如果多个任务共享同一套角色、规则、输出结构,只是参数不同,就可以放在同一个 Skill。
3. description 要写清楚
LLM Router 很依赖 Skill metadata。
尤其是 description。
不好的写法:
description: 用于处理代码
好的写法:
description: 用于审查用户提供的代码,发现 bug、性能问题、安全风险,并给出可执行的修改建议
description 越清晰,路由越准确。
4. trigger patterns 要覆盖常见表达
例如代码审查 Skill:
patterns:
- "审查代码"
- "帮我看看这段代码"
- "这段代码有没有问题"
- "code review"
- "review this code"
既要覆盖命令式表达,也要覆盖自然语言表达。
5. Prompt 正文要包含边界
每个 Skill 都应该明确告诉模型:
- 你擅长什么。
- 你不应该做什么。
- 信息不足时怎么办。
- 输出格式是什么。
- 是否允许猜测。
- 是否需要用户确认。
例如:
如果用户没有提供代码,不要直接开始审查。
你需要先提醒用户补充代码片段或文件内容。
这类边界非常重要。
十四、在企业 Agent 中的典型应用
这套 Skill 体系非常适合企业级 Agent。
例如一个企业 OA Agent 可以有:
skills/
company-style/
employee-profile-query/
leave-request/
business-trip-request/
meeting-room-booking/
todo-query/
schedule-query/
work-report/
policy-qa/
当用户输入:
我明天下午想请半天年假。
系统流程是:
1. 读取用户输入
2. Skill Router 判断命中 leave-request
3. 加载 leave-request/SKILL.md
4. 挂载 get_user_profile、query_leave_balance 等工具
5. 抽取请假类型、时间、原因
6. 缺字段则追问
7. 信息完整后让用户确认
8. 确认后调用 submit_leave_form
当用户输入:
帮我根据今天的工作内容生成日报。
系统则只加载:
work-report Skill
company-style Skill
而不会加载 OA 请假、会议室预定、SQL 分析等无关能力。
这就是 Skill 体系的价值:
让 Agent 根据任务动态“长出”需要的能力,而不是一开始就背上所有能力。
十五、和传统工具调用有什么区别?
很多人可能会问:
Skill 和 Tool 有什么区别?
可以这样理解:
Tool 解决“能做什么”
Skill 解决“怎么做得好”
Tool 是具体能力接口,例如:
query_database()
submit_form()
read_file()
search_knowledge_base()
Skill 是完成某类任务的方法论,例如:
如何分析 SQL
如何生成日报
如何填写请假单
如何根据知识库回答问题
Tool 更像函数。
Skill 更像操作手册。
在 Agent 系统里,两者应该配合使用:
Skill 决定任务策略
Tool 执行具体动作
例如:
请假 Skill:
- 识别请假意图
- 抽取请假字段
- 判断字段是否完整
- 让用户确认
- 调用 submit_leave_form 工具
所以,Skill 不是 Tool 的替代品,而是 Tool 的上层调度说明。
十六、最终推荐架构
一个比较完整的 Skill Runtime 可以分成五层:
+-----------------------------+
| User Input |
+-----------------------------+
|
v
+-----------------------------+
| Skill Router |
| prefix / always / llm judge |
+-----------------------------+
|
v
+-----------------------------+
| Skill Registry |
| metadata / version / tags |
+-----------------------------+
|
v
+-----------------------------+
| Skill Loader |
| body / examples / schema |
+-----------------------------+
|
v
+-----------------------------+
| Agent Executor |
| prompt + tools + memory |
+-----------------------------+
其中:
- Skill Router 负责判断加载哪些 Skill。
- Skill Registry 负责管理元数据。
- Skill Loader 负责按需读取完整 Skill。
- LRU Cache 负责优化重复加载。
- Agent Executor 负责最终模型调用和工具执行。
十七、总结
传统 Agent 系统最大的问题之一,是把所有能力都堆进一个巨大的 Prompt 里。
这种方式短期看简单,长期看一定会失控。
它会带来:
- 上下文浪费
- 响应变慢
- 能力污染
- 维护困难
- 扩展困难
- 测试困难
- 权限边界不清晰
而 Skill 体系提供了一种更加工程化的解决方案。
它的核心思想是:
- 使用 Skill as Prompt,把每个能力封装成独立的
SKILL.md文件。 - 使用 Progressive Disclosure,启动时只读取元数据,触发时才加载完整提示词。
- 使用 智能触发机制,支持前缀匹配、always-on 和 LLM 判断。
- 使用 LRU 缓存,缓存最近使用的 Skill,减少重复磁盘 I/O。
- 使用 版本管理、测试和权限控制,让 Skill 真正具备生产可用性。
一句话总结:
Skill 体系的本质,是把 Prompt 从“临时文本”升级为“工程化能力模块”。
对于复杂 Agent 项目来说,这一步非常关键。
因为未来的 Agent 不应该是一个塞满规则的超长 Prompt,而应该是一个能够按需加载能力、动态组合工具、具备清晰边界和可维护结构的智能运行时。
也就是说:
好的 Agent,不是把所有能力都写进 Prompt。
好的 Agent,是知道什么时候该加载什么能力。
这就是 Skill 体系真正优雅的地方。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)