Hermes Agent v0.14.0 发布:开源 Agent 正在补企业工程化底座
对个人用户来说,这是模型选择变多;今天很多 AI 前沿信息、开源项目动态、模型发布、论文讨论、工具踩坑,第一时间并不一定出现在正式文档里,而是出现在 X、GitHub、Discord、论坛、博客和 issue 区。如果你关心 AI 时代的数据治理、企业 AI 数据底座、RAG、Agent、元数据、血缘、质量、标准、知识图谱、本体论和企业 AI Agent 工程化,可以扫码订阅知识库。真正进入企业环
大家好,我是独孤风。
Nous Research 的 Hermes Agent 又发新版本了。
这次版本号是 v0.14.0,对应 GitHub tag 是 v2026.5.16,发布时间是 2026 年 5 月 16 日。
如果只看 release 规模,这次更新很夸张:从 v0.13.0 到 v0.14.0,官方统计有 808 个 commit、633 个合并 PR、1393 个文件变更、165061 行新增、545 个 issue 关闭。

但我不太想把这篇写成一篇“功能清单”。
因为 Hermes Agent 这次真正值得看的,不是又加了多少模型、多少平台、多少工具,而是它释放出一个比较清晰的信号:
开源 Agent 正在从“能跑起来”,继续往“能部署、能接入、能治理、能长期运行”走。
这和我一直关注的企业 AI Agent 工程化是同一条线。
Agent 不是一个聊天框,也不是一个演示视频。真正进入企业环境以后,它一定会遇到安装分发、模型接入、权限边界、协作渠道、工具调用、可观测、成本、升级和安全这些问题。
Hermes Agent v0.14.0 这次补的,正是这些看起来不性感、但决定它能不能长期跑下去的底层能力。

一、先说结论:这次不是小版本,而是一次“基础设施版本”
官方把 Hermes Agent v0.14.0 称为 The Foundation Release。
这个说法其实比较准确。
所谓 Foundation,不是说它发明了一个全新的 Agent 概念,而是说它在补一套 Agent 真正要作为运行环境时必须具备的基础能力。
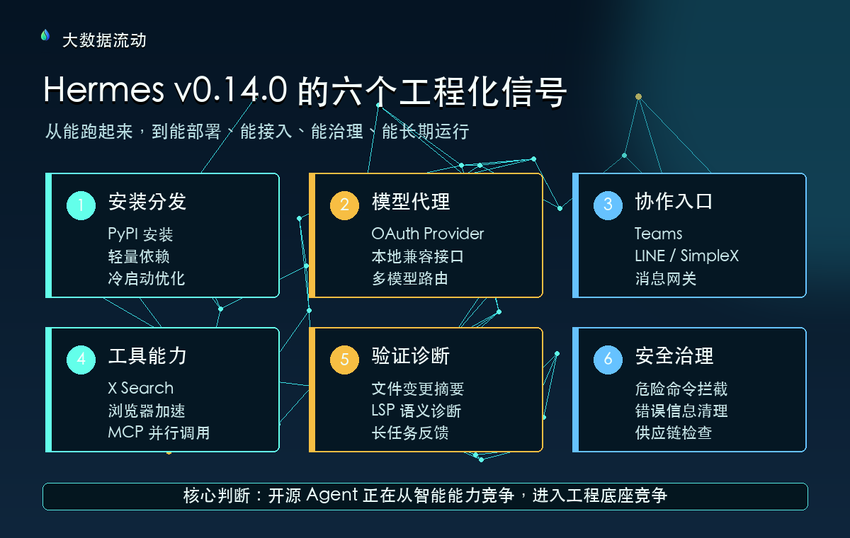
我把这次更新拆成六条主线:
-
第一,安装和分发变轻了;
-
第二,模型接入方式更灵活了;
-
第三,Agent 能进入更多真实协作渠道;
-
第四,工具调用和浏览器能力更接近生产使用;
-
第五,写代码、改文件和长任务执行开始补验证机制;
-
第六,安全、权限和供应链风险被更认真地处理。
如果站在个人工具角度,这些可能只是“体验更好了”。
但如果站在企业 AI 工程化角度,它们对应的是更现实的问题:
一个 Agent 能不能被团队安装?
能不能连接现有模型订阅?
能不能进入 Teams、Discord、Telegram、LINE 这些协作入口?
能不能调用浏览器、搜索、文件、代码诊断、MCP 工具?
能不能在执行动作时留下可检查的痕迹?
能不能避免一上来就把所有依赖、所有权限、所有风险都打包进来?
这才是我觉得 v0.14.0 值得写的原因。
二、pip install hermes-agent 的意义,比看起来更大
这次最基础、但很重要的一项变化,是 Hermes Agent 正式支持通过 PyPI 安装:
pip install hermes-agent
hermes以前很多开源 Agent 工具都停留在“clone 仓库、跑脚本、装一堆依赖”的阶段。
这对开发者没问题,但对更广泛的团队使用并不友好。
一个企业内部如果要试点 Agent,第一步通常不是研究它多智能,而是先面对几个很朴素的问题:
-
环境怎么装?
-
Windows 能不能跑?
-
macOS、Linux、WSL2 有没有差异?
-
依赖会不会太重?
-
升级怎么做?
-
出问题怎么诊断?
Hermes 这次不仅支持 PyPI,还继续优化了安装体积和冷启动性能。官方 release 里提到,很多重量级后端被改成“首次使用时再安装”,而不是一开始全部拉下来;hermes 启动路径也做了延迟加载,冷启动大约减少了 19 秒。
这类优化看上去不酷,但很工程化。
因为工具一旦进入团队环境,安装、启动、升级、依赖、磁盘占用、平台兼容,都会变成真实成本。
很多 AI 工具做 Demo 时很好看,一到企业内部试点,就卡在环境、依赖、代理、权限和版本兼容上。很多时候不是模型本身不行,而是工程基础不够稳。
所以 pip install hermes-agent 不是一个简单的安装命令变化。
它说明 Hermes 正在把自己从“开发者项目”,往“可分发的软件包”推进。
三、OpenAI-compatible local proxy,是一个很关键的工程化入口
这次另一个非常值得关注的能力,是 hermes proxy。
官方描述里说,Hermes 可以启动一个本地 OpenAI-compatible endpoint。也就是说,你本地起一个代理服务,它对外表现得像 OpenAI API,但背后可以连接你已经通过 OAuth 登录的 Claude Pro、ChatGPT Pro、SuperGrok 等 provider。
这次版本还加入了 xAI Grok 的 SuperGrok OAuth provider。官方同时提到,grok-4.3 的上下文窗口提升到 100 万 token。对个人用户来说,这是模型选择变多;对工程化团队来说,更值得看的,是 Hermes 正在把不同模型、不同订阅、不同认证方式放到一个统一运行环境里。
这件事为什么重要?
因为今天很多 AI 工具已经默认支持 OpenAI-compatible 接口。
比如代码工具、自动化脚本、IDE 插件、Agent 框架、评测脚本,很多都可以配置一个 base_url 和模型名称。
过去的问题是:
不同模型服务商有不同的认证方式、API 形态、模型名称和限制。一个团队如果想在多个工具里复用已有订阅,经常要做一堆适配。
Hermes 这次把这件事做成了一个本地代理层。
它的价值不只是“省一个 API Key”。
更重要的是,它把 Agent 运行环境变成了一个模型接入中间层:
-
上层工具继续按 OpenAI-compatible 方式调用;
-
下层可以切换不同 provider;
-
OAuth 登录、模型选择、会话管理、成本和权限可以由 Hermes 统一处理;
-
现有工具链不用大改,就能接入新的模型来源。
这在企业里很有意义。
企业 AI 工程化不是每个应用都各自接一遍模型,而是要逐步形成统一的模型网关、调用策略、权限策略和成本控制方式。
Hermes 的 proxy 还不能等同于完整企业级 AI 网关,但它指向了同一个方向:
Agent 平台不能只会调用模型,还要管理模型接入方式。
四、从 Teams 到 LINE:Agent 正在进入真实协作入口
这次 v0.14.0 对消息平台也做了很多更新。
比较明显的有三类:
第一,Microsoft Teams 端到端打通。
官方提到,Teams 相关能力包括 Microsoft Graph 认证、webhook listener、pipeline runtime 和 outbound delivery。简单说,就是 Hermes 不只是能发消息,而是开始具备从 Teams 接收事件、处理消息、再回写结果的完整链路。
第二,新增 LINE 和 SimpleX Chat。
加上这些平台后,官方说 Hermes 已经支持 22 个 messaging platforms。
第三,Telegram 和 Discord 上的 clarify 支持原生按钮,Discord 还支持频道历史回填。
这些变化看起来像“多接了几个聊天软件”,但背后其实是 Agent 落地形态的变化。
以前很多 Agent 工具默认入口是命令行或网页。
这适合开发者,但企业协作大多发生在 IM、群组、频道、工单和业务系统里。
如果 Agent 只能待在一个独立页面里,它很容易变成“又一个工具”;如果它能进入团队已经在用的协作入口,它才更可能成为工作流的一部分。
举个例子。
一个数据治理 Agent,如果只能在网页里问答,它的使用频率会受限。
但如果它可以进入 Teams 群组,读取上下文,接收任务,提醒责任人,回写处理结果,它就开始接近真实运营流程:
-
质量问题通知;
-
元数据补全提醒;
-
指标口径争议讨论;
-
数据标准评审;
-
周报自动生成;
-
风险事项跟进。
所以 Hermes 这次对消息平台的增强,不只是“入口更多了”。
它说明开源 Agent 框架正在认真处理一个问题:
Agent 要在人的协作场景里工作,而不是只在自己的对话框里工作。
五、x_search 和浏览器性能:Agent 的情报能力也在工程化
这次 Hermes 新增了一个一等公民工具:x_search。
也就是 Agent 可以直接搜索 X 上的信息,支持 OAuth 或 API Key 认证。
如果只从功能角度看,这是一个搜索工具。
但如果从知识工作和企业情报角度看,它的意义更大。
今天很多 AI 前沿信息、开源项目动态、模型发布、论文讨论、工具踩坑,第一时间并不一定出现在正式文档里,而是出现在 X、GitHub、Discord、论坛、博客和 issue 区。
一个 Agent 如果要做长期情报分析,不能只靠搜索引擎,也不能只靠静态知识库。它需要持续连接这些高频信息源。
Hermes 把 x_search 做成内置工具,说明它在强化 Agent 的“外部信息获取能力”。
与此同时,浏览器工具也有一项重要优化:官方说 browser_console 评估速度提升了 180 倍,因为它改为复用持久化的 Chrome DevTools 连接,而不是每次重新建立会话。
这类性能优化对普通聊天没什么感觉,但对 Agent 很关键。
因为 Agent 一旦真的开始操作网页、检查前端、读取控制台、验证页面状态,就会频繁调用浏览器工具。
一次慢两秒,十几次调用下来就很明显。
所以这里可以看到一条趋势:
AI Agent 的能力,不只是模型推理能力,也包括工具调用链路的效率。
一个企业级 Agent 如果要参与数据平台巡检、前端页面验证、后台系统操作、知识库更新,它一定会大量依赖外部工具。工具慢、工具不稳、工具返回不清楚,Agent 就很难稳定工作。
六、LSP 诊断和文件变更验证,是 Agent 自我纠错的基础
我觉得这次最有工程味的更新之一,是写文件之后的验证能力。
官方提到两个点:
第一,Per-turn file-mutation verifier footer。
也就是每一轮对话如果写入或修改了文件,Agent 会看到一个简短摘要,告诉它磁盘上到底变了哪些文件、变了多少行、实际 delta 是什么。
第二,LSP semantic diagnostics on every write。
也就是当 Agent 使用 write_file 或 patch 修改代码时,Hermes 会用真实语言服务器对文件做语义诊断,把新增错误反馈给 Agent。
这两件事很重要。
很多人用 Agent 写代码,最怕的不是它不会写,而是它“以为自己写了”。
比如:
-
它说已经改了文件,但实际上没写进去;
-
它改了一个函数,却漏了 import;
-
它拼错变量名;
-
它修改了类型,却没有同步调用处;
-
它自己没意识到这次改动引入了语义错误。
对人来说,这些错误可以靠 IDE、编译器、测试来发现。
对 Agent 来说,如果这些反馈没有被及时塞回上下文,它就很容易继续在错误假设上往下做。
所以文件变更摘要和 LSP 诊断的价值,不只是“更适合写代码”。
它们代表一种更重要的工程思想:
Agent 执行动作以后,必须获得可验证反馈。
这条原则放到数据治理和企业 Agent 里同样成立。
一个 Agent 生成数据质量规则以后,要知道规则有没有落库、有没有跑通、命中率是多少。
一个 Agent 补全元数据以后,要知道补了哪些字段、哪些被审核通过、哪些被退回。
一个 Agent 创建工单以后,要知道工单 ID、责任人、状态、后续处理记录。
没有反馈闭环的 Agent,本质上还停留在“建议系统”;有反馈闭环的 Agent,才有机会进入真实流程。
七、安全更新说明:开源 Agent 开始正视“工具权限”问题
这次 release 里还有不少安全相关更新。
比如:
-
sudo 暴力尝试阻断;
-
危险命令检测绕过修复;
-
工具错误信息在重新进入模型上下文前做清理;
-
skills hub 的 SSRF 风险路径覆盖;
-
dashboard 插件 API 路由认证;
-
供应链 advisory checker;
-
减少不必要的 shell=True 调用。
这些内容不一定适合普通用户逐条研究,但对企业 AI Agent 非常关键。
因为 Agent 和普通聊天机器人最大的区别,是它会调用工具。
一旦它能调用终端、读写文件、访问网页、请求 API、连接消息平台、调用 MCP 服务,它就不只是“生成文本”,而是在真实系统里行动。
这时候安全问题就不是抽象概念。
你要考虑:
-
哪些命令可以执行?
-
哪些命令必须审批?
-
工具返回的错误信息会不会变成提示注入入口?
-
插件接口是否需要认证?
-
第三方 skill 或依赖是否有供应链风险?
-
Agent 是否会被诱导访问不该访问的地址?
所以我一直说,企业 Agent 工程化不能只讨论 Prompt。
Prompt 能影响模型怎么说话,但不能替代权限、审计、沙箱、审批、日志和供应链治理。
Hermes v0.14.0 在安全和可靠性上的这些更新,说明它正在往这个方向补课。
八、从 v0.14.0 看开源 Agent 的一个趋势
把这次 Hermes Agent v0.14.0 连起来看,我觉得可以得到一个判断:
开源 Agent 框架正在从“智能能力竞争”,进入“工程底座竞争”。
前一阶段,大家更关心:
-
能不能调用模型;
-
能不能用工具;
-
能不能多 Agent;
-
能不能浏览网页;
-
能不能写代码;
-
能不能接聊天平台。
下一阶段,真正拉开差距的会是:
-
安装是否简单;
-
依赖是否可控;
-
平台是否可分发;
-
模型接入是否统一;
-
成本是否可管理;
-
权限是否能约束;
-
工具调用是否可审计;
-
错误是否能被及时发现;
-
长任务是否能稳定执行;
-
多渠道协作是否能进入真实流程。
这也是我为什么会把 Hermes、Dify、OpenClaw、MCP、OpenMetadata、RAG 和数据治理放在同一条内容线里看。
它们表面上是不同工具。
但底层都在回答同一个问题:
企业 AI 到底如何从“会回答”,走向“能协作、能执行、能治理、能复盘”?
Hermes 更像一个长期运行的个人或团队 Agent 运行环境。
Dify 更偏 AI 应用编排和工作流平台。
OpenClaw 更强调数字员工、工作区、记忆和 Skills。
OpenMetadata、DataHub、Atlas 这类工具则提供企业数据资产、元数据、血缘、语义和治理上下文。
未来真正有价值的企业 Agent,很可能不是单个工具完成的,而是由这些能力组合出来的:
-
模型负责理解和推理;
-
Agent 框架负责计划和执行;
-
工作流平台负责流程编排;
-
MCP 和工具接口负责系统连接;
-
数据治理平台负责语义、权限和可信上下文;
-
评测、监控和审计负责上线后的持续控制。
这才是企业 AI Agent 工程化真正要补的底座。

九、普通团队现在该怎么看 Hermes Agent
如果你只是想找一个简单聊天工具,Hermes 可能不是最轻的选择。
但如果你关心长期运行的 Agent、个人知识工作流、团队协作入口、多模型接入、工具调用、Skills、记忆和自动化任务,它值得继续跟踪。
我给几个建议。
第一,不要只看它接了多少模型。
模型接入当然重要,但更值得看的是它怎么管理 provider、OAuth、proxy、成本、缓存和路由。
第二,不要只把它当命令行工具。
Hermes 的价值不只在 CLI,而在 CLI、Gateway、Messaging、Skills、Memory、Cron、Tools 这些能力组合起来之后,能不能形成一个长期运行的智能体环境。
第三,企业试点时不要一上来放开高权限工具。
凡是涉及终端、文件、浏览器、外部 API、IM 群组、企业系统写入,都要先做权限、日志、审批和隔离。
第四,可以从低风险场景开始。
比如:
-
技术资料整理;
-
开源项目情报跟踪;
-
数据治理周报辅助;
-
文档问答和知识库维护;
-
issue 和 release 解读;
-
会议纪要整理;
-
数据质量问题清单归纳。
这些场景的共同点是:可以让 Agent 参与工作,但不直接修改核心业务数据。
等评测、权限、日志和人工确认机制跑顺以后,再逐步进入更深的流程。
十、最后说几句
Hermes Agent v0.14.0 这次更新很大,但真正值得关注的不是“大”,而是方向。
它没有只停留在“让 Agent 更聪明”,而是在补很多工程底座:
安装分发、启动性能、模型代理、消息平台、浏览器工具、文件验证、语言诊断、插件扩展、供应链检查、安全边界。
这些东西不一定适合做炫酷演示,但它们决定 Agent 能不能长期用。
对企业来说,AI Agent 最终拼的不是某一次回答多惊艳,而是它能不能在真实组织里持续工作:
-
接得进系统;
-
守得住权限;
-
查得到上下文;
-
做得了任务;
-
留得下记录;
-
经得起复盘。
这也是 Hermes Agent v0.14.0 给我的最大启发。
开源 Agent 的竞争,正在从“模型外面套一个壳”,走向真正的工程化基础设施。
后面我会继续跟进 Hermes、Dify、OpenClaw、MCP、RAG、数据治理平台这些方向。
因为我越来越确定一件事:
未来企业 AI 的落地,不会只属于会写 Prompt 的人,而会属于那些真正理解数据、流程、权限、工具和工程化的人。
我正在持续整理《AI时代数据治理实战库》。
它会围绕两条主线展开:
-
Data for AI:数据如何支撑 AI。
-
AI for Data:AI 如何反过来改造数据治理。
前者是基础,后者是新机会。
如果你关心 AI 时代的数据治理、企业 AI 数据底座、RAG、Agent、元数据、血缘、质量、标准、知识图谱、本体论和企业 AI Agent 工程化,可以扫码订阅知识库。

关注「大数据流动」,我们继续用大数据工程化和企业落地视角,拆解 AI 时代真正需要补的底层能力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)