深度解码 Gemini CLI:状态栏那个跳动的 Memory 到底是什么?
揭秘 Gemini CLI 状态栏中的 Memory 指标,深入探讨其背后的分层记忆系统、JIT 加载与自动压缩机制。
在使用 Gemini CLI(尤其是在开启了实验性功能后)时,细心的开发者可能会注意到状态栏右下角出现了一个 memory: XXX MB 的指标。这个数字有时是 100 多 MB,有时甚至达到 200 MB 以上,而且在对话过程中会“跳动”甚至逐渐减小。
这到底是已用 RAM 内存?还是某种磁盘缓存?为什么它不像上下文 Token 数那样稳定增长?今天我们就来拆解 Gemini CLI 分层记忆系统 (Memory V2) 的核心机制。
核心定义:它是“工作记忆”的物理体积
简单来说,状态栏显示的 Memory 数值代表的是 当前会话活跃上下文(Active Context)的序列化物理大小。
与传统的 LLM 聊天界面不同,Gemini CLI 是一个高度集成的工程工具。你的每一轮对话不仅仅包含文字,它更像是一个精密打包的数据包,其构成如下:
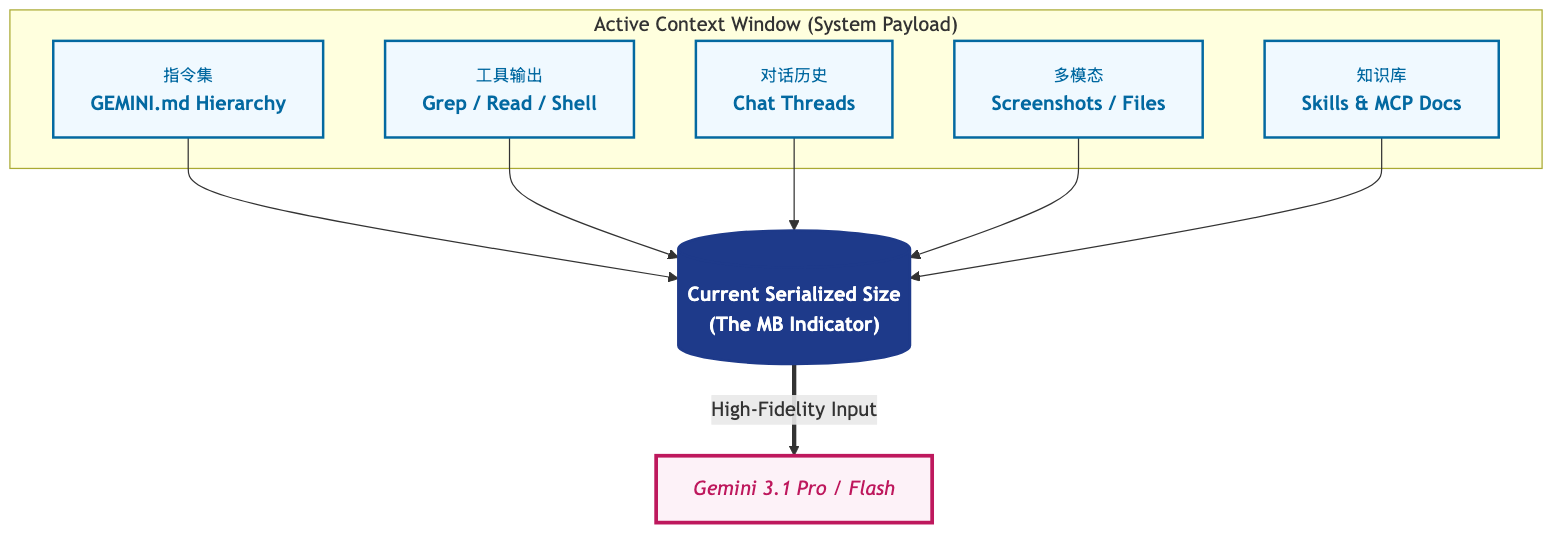
- 多层级指令:来自全局、项目、子目录的
GEMINI.md文件。 - 工具输出:数千行的代码搜索结果(Grep)、文件内容(Read)、Shell 命令输出。
- 多模态数据:你上传的屏幕截图或图片。
- 技能与 MCP 数据:已加载的 33 个技能(Skills)及其背后的 API 文档。
当这些数据被打包准备发给 Gemini 模型时,CLI 会计算它们的物理体积。152.8 MB 的数值说明你的“大脑”里此时正装着相当庞大的背景资料。
为什么数字会变小?——按需加载与自动压缩
用户经常观察到一个有趣的现象:开始工作后,Memory 数字会逐渐变小,且不稳定。 这主要归功于两项核心技术:
1. jitContext (Just-In-Time Context)
如果你的项目有几百个文件,全部塞进上下文会瞬间挤爆 Token 限制。jitContext 开启后,CLI 不会一次性加载所有 GEMINI.md。
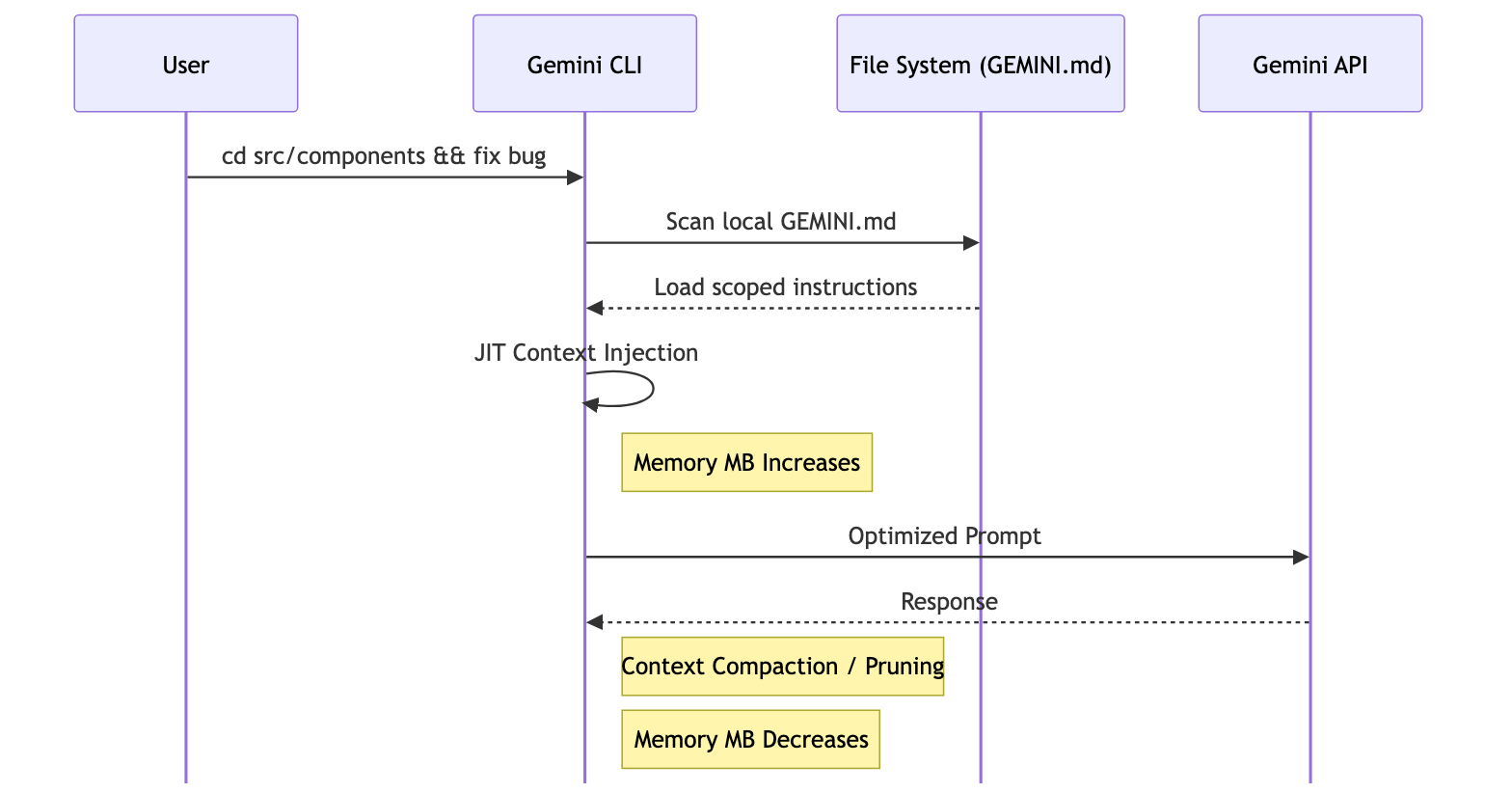
当你切换到不同的子目录工作,或者任务目标改变时,CLI 会动态地“卸载”不再相关的背景指令,并“装载”当前需要的指令。这种“快进快出”的机制导致了 Memory 数值的上下波动。
2. Context Compaction (上下文压缩)
为了节省昂贵的 Token 费用并提高响应速度,Gemini CLI 内置了类似“压路机”的机制。它会自动检测历史对话中的冗余信息,将巨大的中间日志输出进行摘要化(Summarization)或直接剪枝(Pruning)。当你深入讨论某个问题时,CLI 正在后台帮你清理掉那些过时的过程数据。
Memory V2:像代码一样管理记忆
在配置中,我们经常能看到 memoryV2: true。这代表了 Gemini CLI 最新的记忆架构。它将记忆从“黑盒子数据库”改成了透明的、可提交到 Git 的 Markdown 文件体系。
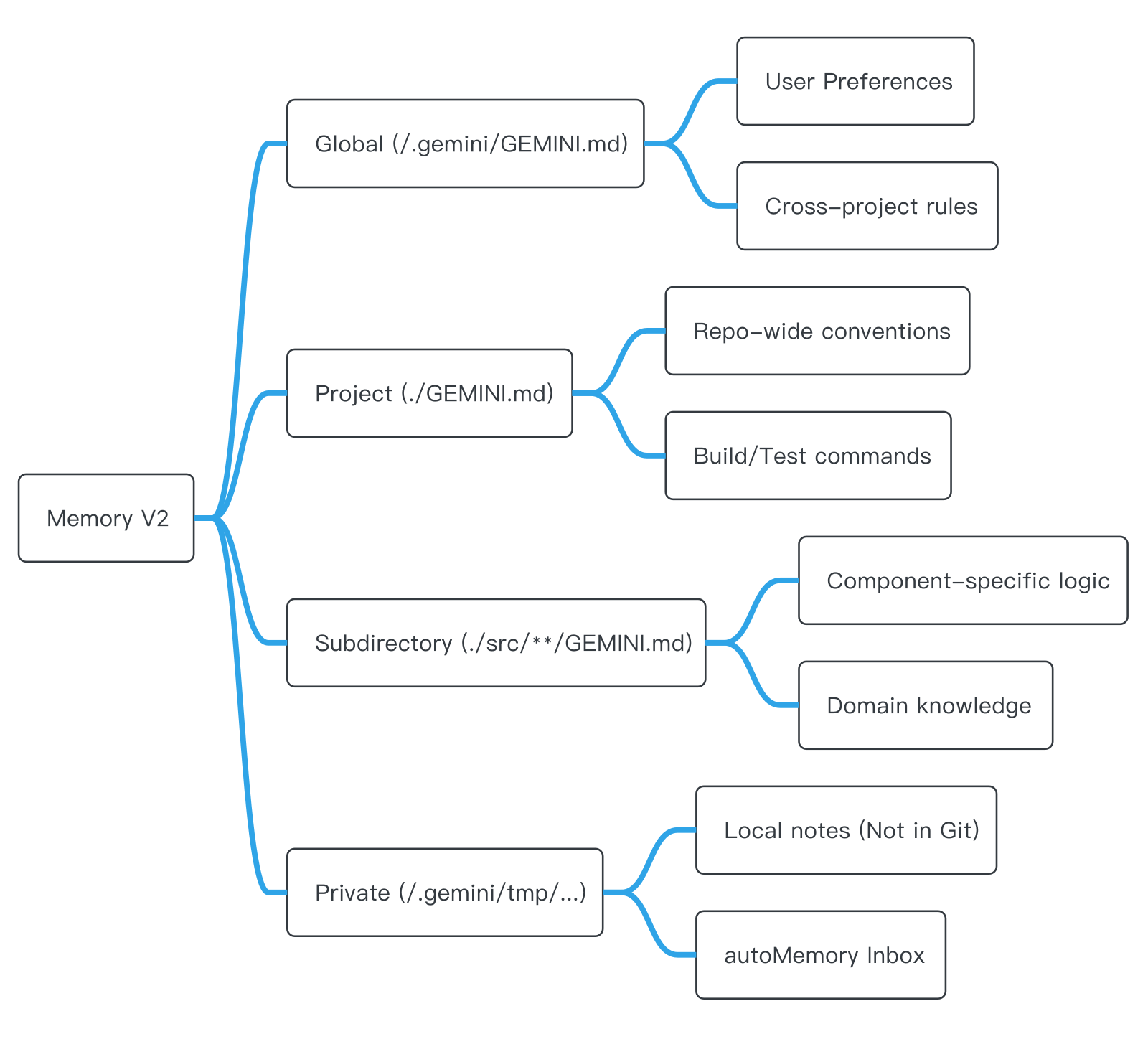
- Global:全局偏好(如“我喜欢用 TypeScript”)。
- Project:项目规范(如“本仓库使用 Vitest”)。
- Subdirectory:子模块知识。
- Private:本地私有笔记(如本地测试环境 IP)。
常用管理命令
如果你想看看 AI 现在到底“记得”什么,或者觉得上下文太重了,可以使用以下交互式命令:
/memory show:展示当前模型能看到的所有指令和事实。/memory inbox:查看autoMemory帮你自动挖掘出来的经验片段。/memory prune:手动清理那些不再需要的持久化记忆。
总结
那个跳动的 MB 数值,其实是 Gemini CLI 动态管理上下文健康度 的体现。它不是传统的资源占用指标,而是你与 AI 协作时的信息通量。
下次看到数字变小,请不必担心,那通常意味着 CLI 成功地帮你精简了知识负担,让模型能更专注地解决当下的问题。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)