《200+技能、36个数据库接口:AI Agent的科研技能图谱,正在重写“做科研“的定义》
当200+Skill覆盖从单细胞测序到量子计算、从学术搜索到基金申请的完整光谱,当36个数据库接口让Agent“看见”而非“搜索”,当self-improvement让Agent学会“学会”——我们面对的已不是“科研助手”,而是正在进化中的“科研智能体”。

《200+技能、36个数据库接口:AI Agent的科研技能图谱,正在重写"做科研"的定义》
当Agent学会了调用AlphaFold和写国自然,科研的定义正在被重写。
📌 文章摘要
本文系统梳理了当前AI Agent科研技能生态的现状与趋势,基于对10个主要GitHub仓库的深入分析,揭示了以下核心发现:
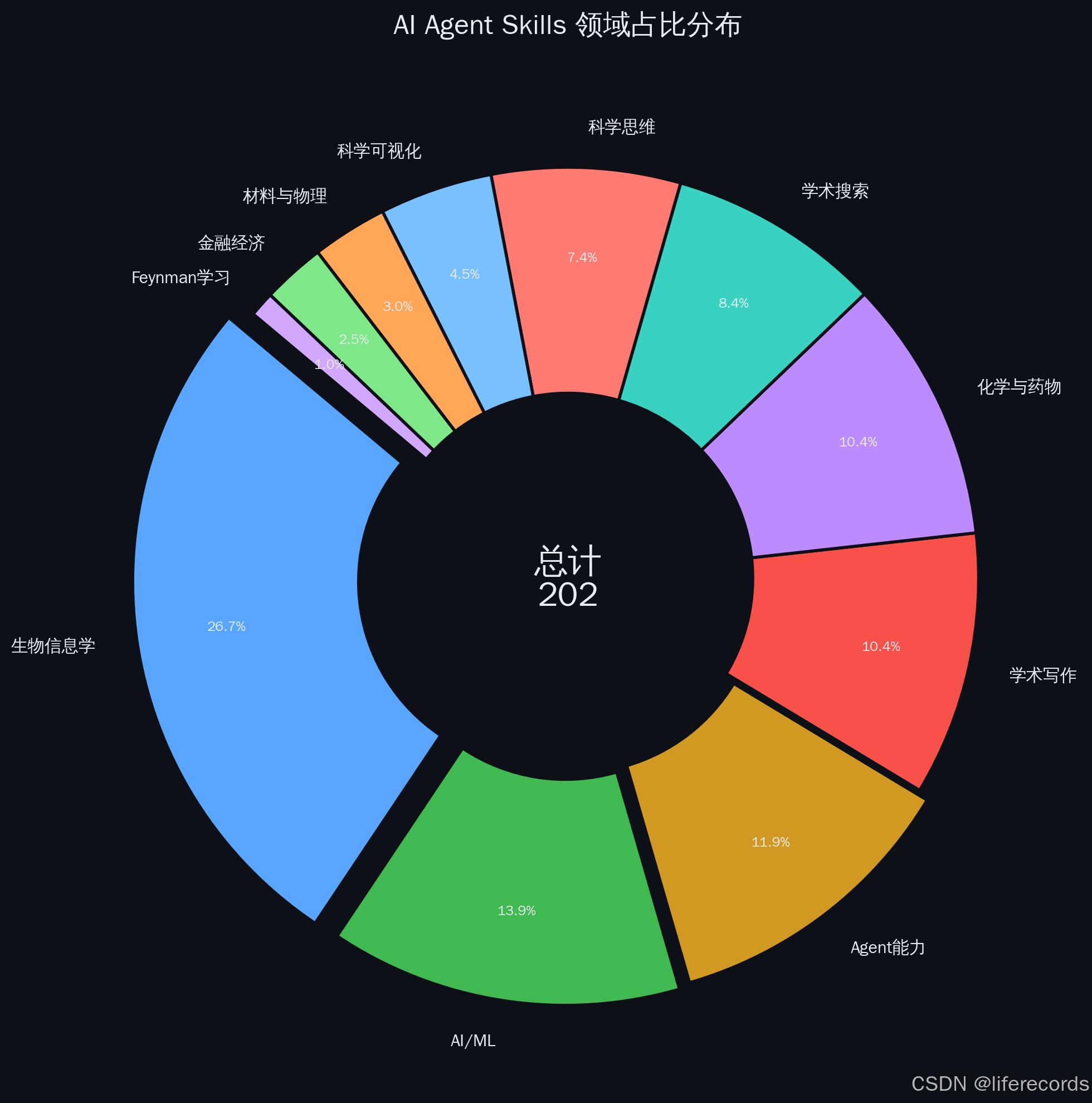
1. 规模与分布:共统计到202个标准化科研Skill,覆盖11大领域,其中生物信息学以54个Skill(27%)遥遥领先,AI/ML(28个)、化学(21个)、学术写作(21个)紧随其后,而材料科学(6个)、金融(5个)等领域仍处起步阶段。
2. 数据库接口革命:36个专业数据库接口(AlphaFold、UniProt、PDB、ChEMBL、DrugBank等)让Agent从“搜索信息”转向“直接查询结构化数据”,构成了Agent的感知系统。
3. 学术全链路闭环:从文献搜索(17个Skill)到论文撰写(21个)再到可视化与交付(9个),47个Skill覆盖了从发现到发表的完整科研流程,形成可编程的学术生产流水线。
4. 生物信息学深度渗透:54个生物信息学Skill细分为12个子领域,从单细胞分析(scanpy/scvelo)到蛋白质结构(AlphaFold/PDB)再到实验室自动化(Opentrons/Benchling),展现了生命科学数据爆炸背景下Agent作为“唯一出路”的必然性。
5. 化学-AI交叉前沿:化学领域21个Skill(计算工具+数据库)与AI/ML领域28个Skill(图神经网络、蛋白质语言模型等)结合,正在重塑药物发现范式——从虚拟筛选到活性预测再到分子对接的全流程自动化成为可能。
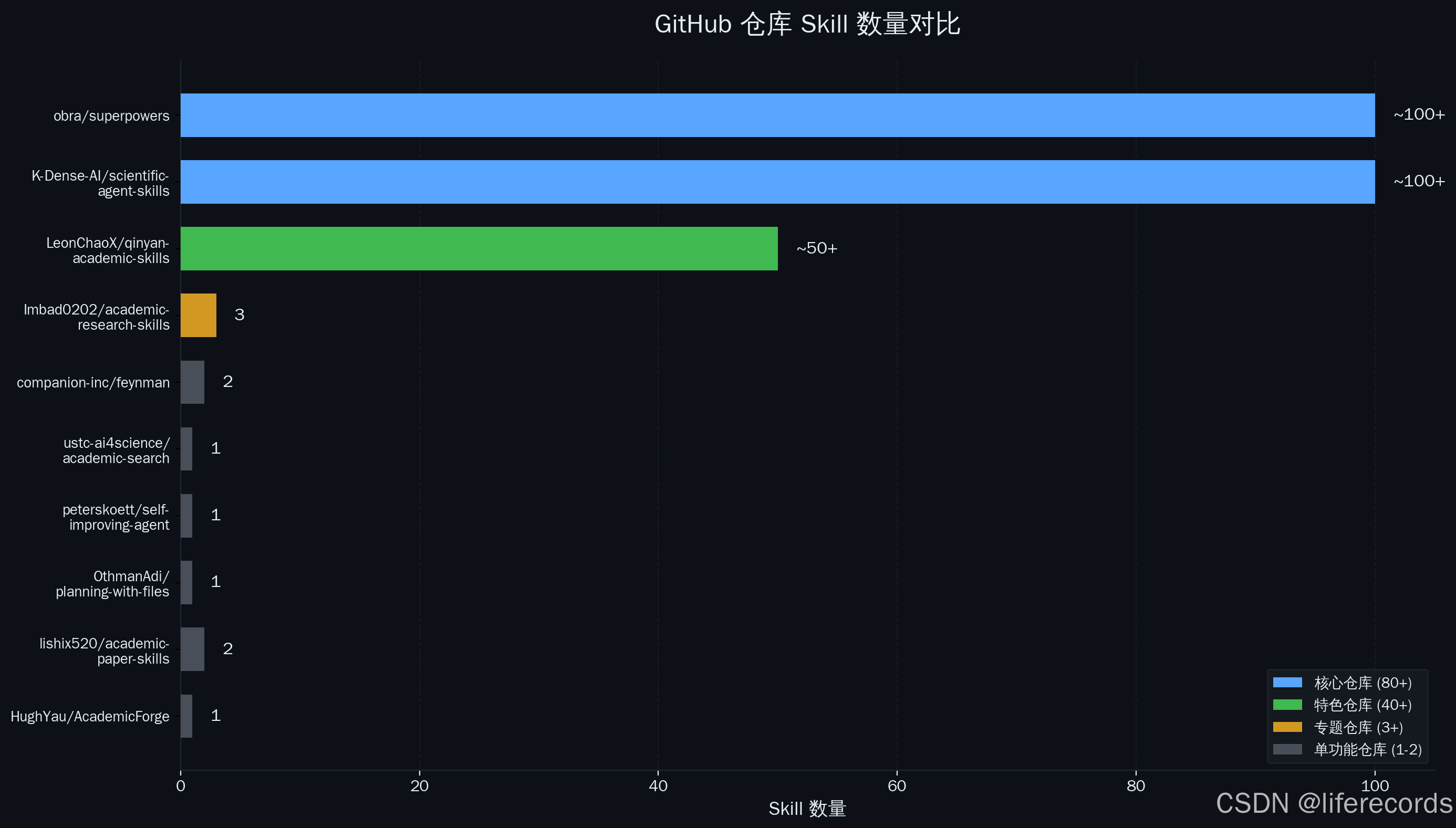
6. 生态格局:K-Dense-AI(~100+ Skill,全能型)与LeonChaoX(~50+ Skill,数据库之王)构成双巨头格局,合计贡献75%以上Skill,其他仓库多为单点精品。
7. Agent进化路径:从工具使用者(调用预定义Skill)→工具发现者(autoskill)→工具学习者(self-improvement)→未来可能的工具创造者,Agent正在获得“元认知”能力。
核心结论:当200+Skill覆盖从单细胞测序到量子计算、从学术搜索到基金申请的完整光谱,当36个数据库接口让Agent“看见”而非“搜索”,当self-improvement让Agent学会“学会”——我们面对的已不是“科研助手”,而是正在进化中的“科研智能体”。
一、200+技能意味着什么
2026年,如果你打开GitHub搜索"agent skills",会看到一个令人震惊的数字:超过200个经过标准化封装的科研技能,正以Skill的形式被AI Agent调用。
这不是一个抽象的统计。我们逐一梳理了10个主要仓库、11个领域分类下的每一个Skill——从学术搜索到量子计算,从单细胞测序到基金申请——最终确认的数字是202个。
202意味着什么?
意味着一个AI Agent理论上已经可以完成以下全部动作:搜索arXiv和CNKI上的论文、构建引用网络、撰写系统性文献综述、规划论文大纲、完成全文写作、生成LaTeX海报和PPT演示、提交同行评审——这是47个Skill覆盖的学术全链路。
意味着它可以调用36个专业数据库接口——AlphaFold、UniProt、PDB、ChEMBL、DrugBank、ClinVar、GWAS、GTEx、KEGG……从蛋白质结构到临床变异,从代谢通路到药物靶点,一键直达。
意味着它甚至可以帮你写国家自然科学基金申请书——LeonChaoX的沁言系列里,nsfc-proposal和nssfc-proposal两个Skill,分别面向自科和社科基金。
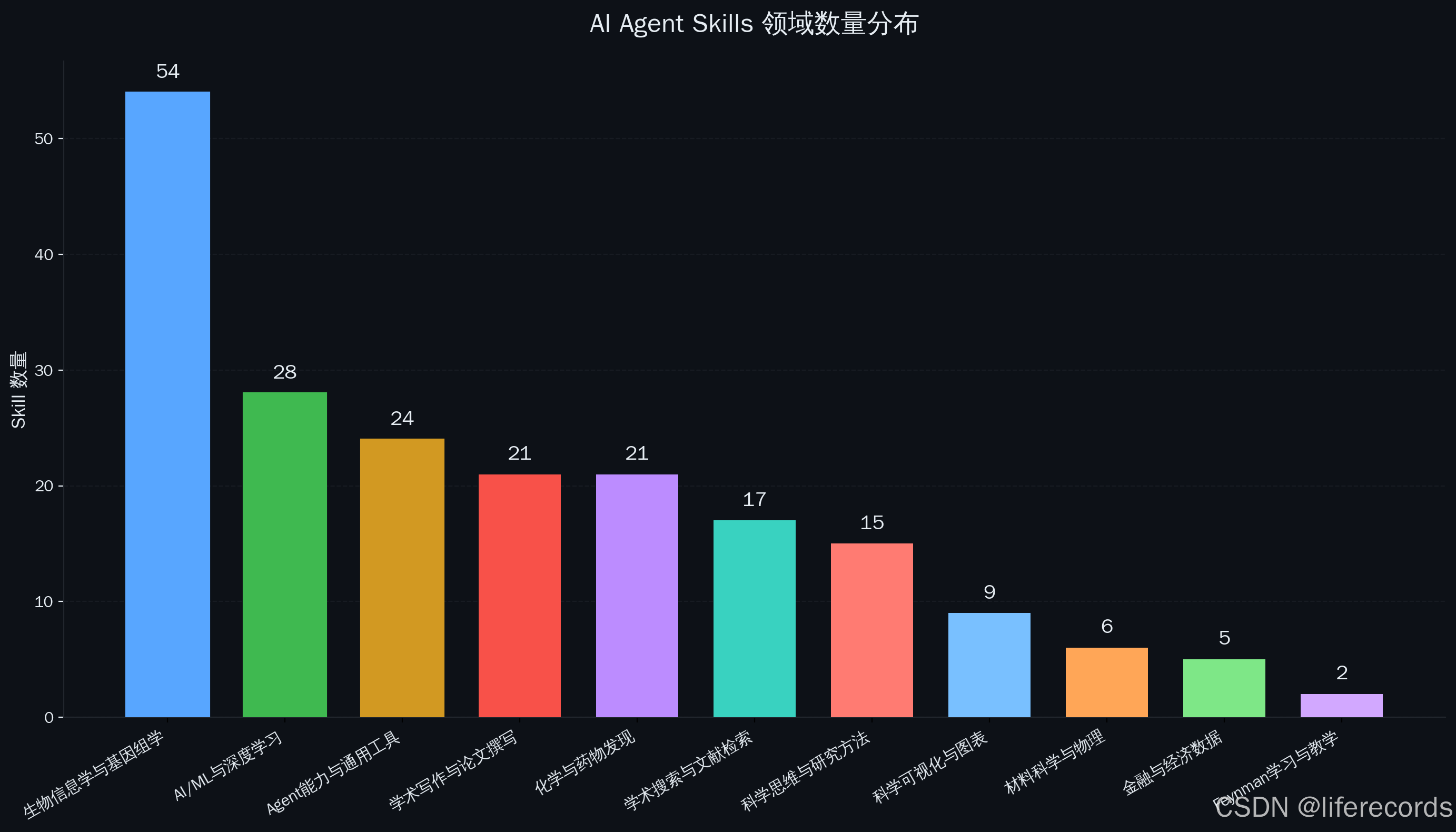
上图是11大领域的Skill数量分布。一个刺眼的事实跃然纸上:生物信息学以54个Skill独占27%,超过排名第二的AI/ML(28个)近一倍。这不是偶然,它折射的是生命科学数据爆炸的残酷现实——当基因组、蛋白质组、代谢组的数据量以指数级增长,人类研究者已经无法靠手动处理,Agent成了唯一的出路。
而在分布的另一端,金融数据(5个)、材料科学(6个)、Feynman教学(2个)这些领域,Skill数量还处于起步阶段。差距之大,本身就是一份科研自动化进度表。
二、领域全景:11大领域分布解读
让我们逐一审视这11个领域。数字背后,是科研自动化在不同学科的真实渗透率。
2.1 学术搜索与文献检索(17个Skill)
这是Agent最早被赋予的能力,也是目前最成熟的方向之一。17个Skill覆盖了从论文搜索到引用分析到文献管理的完整流程。
核心节点是academic-search——ustc-ai4science出品的这个Skill,支持arXiv、Semantic Scholar、OpenAlex、Crossref、Unpaywall、PubMed、Google Scholar、ACM DL、IEEE、CNKI等10+平台,还内置了CDP浏览器模式和学科路由策略,堪称学术搜索的"瑞士军刀"。
K-Dense贡献了7个搜索类Skill:citation-network(引用网络)、literature-review(系统性综述,支持PRISMA流程)、scholar-evaluation(学者评价)、venue-templates(期刊模板)、research-lookup(研究查找)、paper-lookup(论文查找)、pyzotero(Zotero文献管理)。
LeonChaoX的沁言系列则补上了中文生态的缺口:qinyan-paper-search(中文论文搜索)、qinyan-citation(中文引用分析),以及biorxiv-database、openalex-database、pubmed-database三个专业数据库接口。此外还有perplexity-search(AI搜索)、exa-search(语义搜索)、database-lookup(通用数据库查询)、offer-k-dense-web(K-Dense平台集成)。
关键洞察:17个搜索Skill中,有5个是数据库接口Skill(bioRxiv、OpenAlex、PubMed、database-lookup、offer-k-dense-web),说明"搜索"这个动作正在被"结构化数据访问"取代——Agent不是在搜索,而是在直接查询。
2.2 学术写作与论文撰写(21个Skill)
21个Skill,是数量第二大的领域。写作是科研的终极输出,也是Agent能力最密集的战场。
lishix520的academic-paper-strategist和academic-paper-composer构成了一条完整的论文生产流水线:前者负责三阶段战略规划(平台分析→理论框架→大纲优化),含AI驱动文献搜索和研究空白识别;后者负责从大纲到完整稿件的分阶段写作,含质量门控和审稿人视角自评。
K-Dense的写作工具链覆盖了输出格式的全光谱:scientific-writing(科学写作指导)、peer-review(审稿辅助)、latex-posters(LaTeX海报)、markdown-mermaid(Mermaid图表)、docx(Word文档)、pdf(PDF报告)、pptx(PPT演示)、pptx-posters(PPT海报)、xlsx(Excel表格)、markitdown(格式转换)。
LeonChaoX的沁言系列再次体现中文特色:qinyan-paper-analysis(论文解读)、qinyan-paper-polish(论文润色)、qinyan-topic-analysis(选题分析),以及paper-2-web(论文转网页)、paper-slide-deck(论文转PPT)、paperzilla(论文管理)。
Imbad0202贡献了3个简洁实用的Skill:academic-paper(论文写作)、academic-paper-reviewer(论文评审)、academic-pipeline(研究流程管理)。
关键洞察:21个写作Skill中,有8个涉及格式转换和输出生成(docx、pdf、pptx、xlsx、latex-posters、pptx-posters、paper-2-web、paper-slide-deck)。这说明Agent写作能力的瓶颈已经不在"写什么",而在"以什么格式交付"。
2.3 科学可视化与图表(9个Skill)
9个Skill,数量不多但覆盖精准。
HughYau的scientific-visualization是通用入口,支持matplotlib/seaborn。K-Dense提供了matplotlib(基础绑图)、seaborn(统计可视化)、plotly(交互可视化)、scientific-schematics(科学示意图)、scientific-slides(学术演示)、infographics(信息图)、scientific-visualization(通用可视化)。LeonChaoX有独立的plotly实现。
关键洞察:可视化领域存在明显的"工具绑定"特征——每个Skill对应一个具体的Python库。这意味着Agent的可视化能力直接受限于底层库的能力边界,尚未出现"智能选择最佳可视化方案"的元技能。
2.4 生物信息学与基因组学(54个Skill)
这是本文的重头戏,我们将在下一章深度拆解。
2.5 化学与药物发现(21个Skill)
化学领域的21个Skill,展现了一条从分子操作到药物发现的完整技术栈。
K-Dense贡献了13个核心工具:rdkit(化学信息学核心)、medchem(药物化学)、molfeat(分子特征工程)、datamol(分子数据处理)、matchms(质谱分析)、deepchem(深度学习药物发现)、diffdock(分子对接)、cobrapy(代谢建模)、molecular-dynamics(分子动力学模拟)、glycoengineering(糖工程)、rowan(量子化学)、pytdc(药物发现基准)、torchdrug(药物图神经网络)。
LeonChaoX贡献了8个数据库接口:bindingdb-database(结合亲和力)、brenda-database(酶数据)、chembl-database(生物活性分子)、drugbank-database(药物信息)、hmdb-database(人类代谢组)、pubchem-database(化学物质)、zinc-database(虚拟筛选化合物库)、uspto-database(化学专利)。
关键洞察:化学领域的Skill分布呈现清晰的"计算+数据"双轮驱动——13个计算工具负责分子建模和模拟,8个数据库接口提供化合物和反应数据。diffdock(分子对接)和deepchem(深度学习药物发现)的组合,意味着Agent已经可以完成从靶点识别到先导化合物优化的虚拟筛选全流程。
2.6 AI/ML与深度学习(28个Skill)
28个Skill,覆盖了从经典机器学习到量子计算的广阔光谱。
经典ML与统计:scikit-learn(通用ML)、statsmodels(统计建模)、pymc(贝叶斯建模)、sympy(符号计算)、statistical-analysis(统计分析)、shap(模型可解释性)。
深度学习框架:transformers(NLP/LLM)、pytorch-lightning(训练框架)、torch-geometric(图神经网络)、stable-baselines3(强化学习)、pufferlib(RL环境)。
量子计算三件套:qiskit(量子编程)、qutip(量子模拟)、pennylane(量子机器学习)——从编程到模拟到应用,形成完整闭环。
数据与计算基础设施:dask(并行计算)、polars(高性能数据帧)、vaex(十亿行数据可视化)、networkx(网络分析)、pymoo(多目标优化)、simpy(离散事件模拟)、optimize-for-gpu(GPU优化)、modal(云端计算)。
科学AI专用:esm(Meta蛋白质语言模型)、bgpt(BioGPT生物NLP)、hugging-science(HuggingFace科学模型)。
金融交叉:denario(量化金融),K-Dense和LeonChaoX各有一个实现。
关键洞察:量子计算三件套(qiskit、qutip、pennylane)的出现,标志着Agent的能力边界已经延伸到经典计算之外。而esm和bgpt这两个蛋白质/生物医学语言模型Skill,则是AI/ML与生物信息学的交叉接口——Agent不再只是"使用工具",而是在"调用另一个AI"。
2.7 材料科学与物理(6个Skill)
6个Skill,数量最少的基础科学领域之一:pymatgen(材料基因组计算)、astropy(天文数据)、primekg(生物医学知识图谱)、depmap(癌症依赖图谱)、tiledbvcf(基因组变异数据)、zarr-python(云存储多维数据)。
关键洞察:材料科学只有1个真正的材料计算Skill(pymatgen),其余5个更偏数据管理。物理领域只有astropy一个天文Skill。这两个基础学科的Agent化程度严重不足,与生物信息学的54个Skill形成鲜明对比——不是物理和材料不重要,而是这些领域的标准化工具生态还不够成熟。
2.8 金融与经济数据(5个Skill)
LeonChaoX独家贡献的5个Skill:alpha-vantage(股票数据)、fred-economic-data(美联储经济数据)、edgartools(SEC财务报告)、hedgefundmonitor(对冲基金监控)、datacommons-client(社会统计数据)。
关键洞察:金融领域5个Skill全部来自同一个仓库,且全部是数据接口类Skill,没有任何分析建模类Skill。这意味着Agent在金融领域还停留在"获取数据"阶段,距离"分析数据"和"生成策略"还有很长的路。
2.9 科学思维与研究方法(15个Skill)
这是一个容易被忽视但极其重要的领域——它关乎Agent能否"思考"。
K-Dense贡献了11个:scientific-brainstorming(头脑风暴)、scientific-critical-thinking(批判性思维)、hypothesis-generation(假设生成)、hypogenic(自动假设生成)、what-if-oracle(反事实分析/因果推理)、consciousness(意识研究)、research-grants(基金申请)、iso-13485(医疗器械合规)、clinical-decision(临床决策)、clinical-reports(临床报告)、treatment-plans(治疗方案)、open-notebook(开放科学笔记本)。
LeonChaoX贡献了3个中文特色Skill:nsfc-proposal(国家自然科学基金申请)、nssfc-proposal(国家社科基金申请)、research-proposal(通用研究提案)。
关键洞察:hypothesis-generation和hypogenic的出现,意味着Agent开始涉足科学发现的核心环节——提出假设。而what-if-oracle(反事实分析)更是触及了因果推理的深水区。当Agent学会了"如果……会怎样"的思考方式,它离真正的科研合作者又近了一步。
2.10 Agent能力与通用工具(24个Skill)
24个Skill,是Agent的"元能力"层——让Agent更好地成为Agent。
自我进化:self-improvement(peterskoett出品,跨会话学习、错误记录、模式检测、技能提取)——这是整个生态中最具哲学意味的Skill。
规划与发现:planning-with-files(文件化任务规划)、autoskill(自动技能发现)、get-available(工具发现)。
生成与抓取:generate-image(AI图像生成)、parallel-web(并行Web抓取)。
专业工具:matlab(工程计算)、geopandas(地理空间分析)、geomaster(地理数据)、timesfm-forecasting(时间序列预测)、usfiscaldata(美国财政数据)、market-research(市场研究)。
生物信息延伸:polars-bio(生物数据帧)、latchbio(生信工作流)、dnanexus(生信云平台)、dhdna(DNA分析)、geniml(基因组ML)、gtars(基因组注释)、ginkgo(合成生物)、deeptools(测序处理)。
其他:fluidsim(流体模拟)、adaptyv(自适应工具)、aeon(时序分析)、arboreto(特征选择)。
关键洞察:24个Agent能力Skill中,有8个是生物信息学的延伸工具(polars-bio、latchbio、dnanexus、dhdna、geniml、gtars、ginkgo、deeptools)。这意味着生物信息学的实际渗透比54这个数字还要深——它已经溢出到"通用工具"类别中了。
2.11 Feynman学习与教学(2个Skill)
companion-inc的feynman-learning和feynman-teaching,基于费曼学习法——通过"教"来"学"。
数量虽少,但意义深远:这是唯一一个面向"知识传授"而非"知识生产"的领域。当Agent学会了费曼技巧,它不仅能做研究,还能教人做研究。
三、生物信息学深度拆解:54个Skill的12个子领域
54个Skill。27%的占比。生物信息学是AI Agent Skills生态中当之无愧的"超级领域"。
为什么是生物信息学?答案很简单:生命科学的数据爆炸,已经超出了人类认知的带宽。一个人的基因组有30亿个碱基对,一个单细胞实验可以产生数十万个细胞的表达谱,一个蛋白质结构数据库包含数十万条3D结构记录——这些数据需要被清洗、对齐、注释、分析、可视化,而每一步都涉及专业工具和领域知识。Agent恰好擅长这种"工具链+领域知识"的组合。
我们将54个Skill拆解为12个子领域:
3.1 单细胞RNA-seq分析(6个Skill)
这是生物信息学最活跃的前沿方向。6个Skill构成了一条完整的单细胞分析流水线:
- scanpy:单细胞RNA-seq分析的核心框架,负责质控、聚类、差异表达
- scvelo:RNA速度分析,推断细胞的动态分化轨迹
- scvi-tools:基于深度学习的单细胞分析(scVI/scANVI),处理批次效应和跨数据集整合
- pydeseq2:差异基因表达分析,从bulk RNA-seq到单细胞均可
- anndata:单细胞数据结构管理,AnnData格式是scanpy生态的底层数据结构
- cellxgene:CellxGene数据门户访问,直接浏览和下载公开的单细胞数据集
单细胞+数据库双引擎:scanpy/scvelo/scvi-tools负责"算",cellxgene负责"查"。Agent可以先用cellxgene找到目标数据集,再用scanpy进行分析,用scvelo推断分化方向,用scvi-tools整合多批次数据——全流程无需人类介入。
3.2 基因组比对与序列分析(4个Skill)
- pysam:处理SAM/BAM基因组比对文件,是NGS数据分析的基础
- gget:基因组数据库查询,快速获取基因序列和注释
- scikit-bio:生物信息学序列分析,支持多序列比对和系统发育
- phylogenetics:系统发育和进化树分析
3.3 蛋白质结构与功能(4个Skill)
- alphafold-database:访问AlphaFold蛋白质结构预测数据库
- interpro-database:蛋白质家族和结构域分类
- pdb-database:蛋白质3D结构数据库
- uniprot-database:蛋白质序列和功能注释
36个数据库接口构成了Agent的感知系统——它不是在搜索,而是在看见。 这4个蛋白质相关数据库就是最好的例证:Agent不需要打开浏览器、输入关键词、筛选结果,而是直接查询结构化的蛋白质数据。AlphaFold的2亿+蛋白质结构预测,对Agent来说就是一个API调用。
3.4 基因组注释与表达(8个Skill)
- ensembl-database:基因组浏览器和注释
- ena-database:欧洲核酸档案
- gene-database:NCBI Gene基因信息
- geo-database:基因表达综合数据库
- gnomad-database:基因组变异频率
- gtex-database:基因型-组织表达
- gwas-database:全基因组关联研究
- jaspar-database:转录因子结合位点
8个数据库,覆盖了从基因组序列到基因表达再到遗传变异的完整信息链。特别值得注意的是gtex-database和gwas-database——前者提供基因在不同组织中的表达水平,后者提供基因与表型的关联证据。两者的组合,让Agent可以回答"这个基因在哪些组织中表达?它的变异与什么疾病相关?"这类复杂问题。
3.5 通路与互作网络(3个Skill)
- kegg-database:代谢和信号通路
- reactome-database:生物反应通路
- string-database:蛋白质-蛋白质相互作用
KEGG和Reactome是通路分析的两大权威数据库,STRING则提供蛋白质互作网络。三个Skill的组合,让Agent可以构建从分子到通路到网络的完整生物学图景。
3.6 疾病与临床基因组(8个Skill)
- opentargets-database:药物靶点与疾病关联
- cbioportal-database:癌症基因组学
- clinvar-database:临床相关变异
- clinpgx-database:药物基因组学
- cosmic-database:体细胞突变目录
- clinicaltrials-database:临床试验
- fda-database:药物审批
- monarch-database:表型-基因关联
8个Skill,从癌症基因组(cBioPortal、COSMIC)到临床变异(ClinVar)到药物基因组(ClinPGx)到临床试验(ClinicalTrials.gov)再到药物审批(FDA),构成了一条从基础研究到临床应用的转化医学链路。
3.7 代谢组学与蛋白质组学(2个Skill)
- metabolomics-workbench-database:代谢组学数据
- pyopenms:蛋白质组学质谱数据分析
3.8 医学影像与病理(4个Skill)
- pydicom:DICOM医学影像处理
- histolab:组织病理全切片图像处理
- pathml:数字病理图像分析
- medical-imaging-review:医学影像AI综述
病理AI是医学影像中最具商业价值的方向之一。histolab和pathml的组合,让Agent可以处理从组织切片的tile提取到全切片图像分析的完整流程。
3.9 生理信号与神经科学(2个Skill)
- neurokit2:生理信号分析(ECG/EMG等)
- neuropixels:电生理记录数据处理
3.10 流式细胞与生物成像(3个Skill)
- flowio:流式细胞术FCS数据处理
- imaging-data:生物成像数据分析
- omero:生物图像管理平台
3.11 实验室自动化与管理(6个Skill)
- opentrons:实验室自动化液体处理平台控制
- pylabrobot:实验室机器人控制
- benchling:实验室信息管理系统(LIMS)
- labarchive:电子实验记录本(ELN)
- lamindb:生物数据版本管理
- protocolsio:实验方案数据库
这是最被低估的子领域。 6个Skill覆盖了从实验设计(protocols.io)到实验执行(Opentrons、PyLabRobot)到数据管理(Benchling、LabArchives、LaminDB)的完整实验室流程。当Agent可以控制液体处理机器人、查询实验方案、管理实验记录,"无人实验室"就不再是科幻概念。
3.12 医疗AI与分析工具(4个Skill)
- pyhealth:医疗AI和临床预测建模
- umap-learn:UMAP降维分析
- bioservices:多生物信息学Web API集成
- scikit-survival:生存分析
四、学术全链路:从搜索到发表47个Skill的闭环覆盖
从搜索到发表47个Skill的完整链路,意味着科研全流程的每个环节都有了Agent的入口。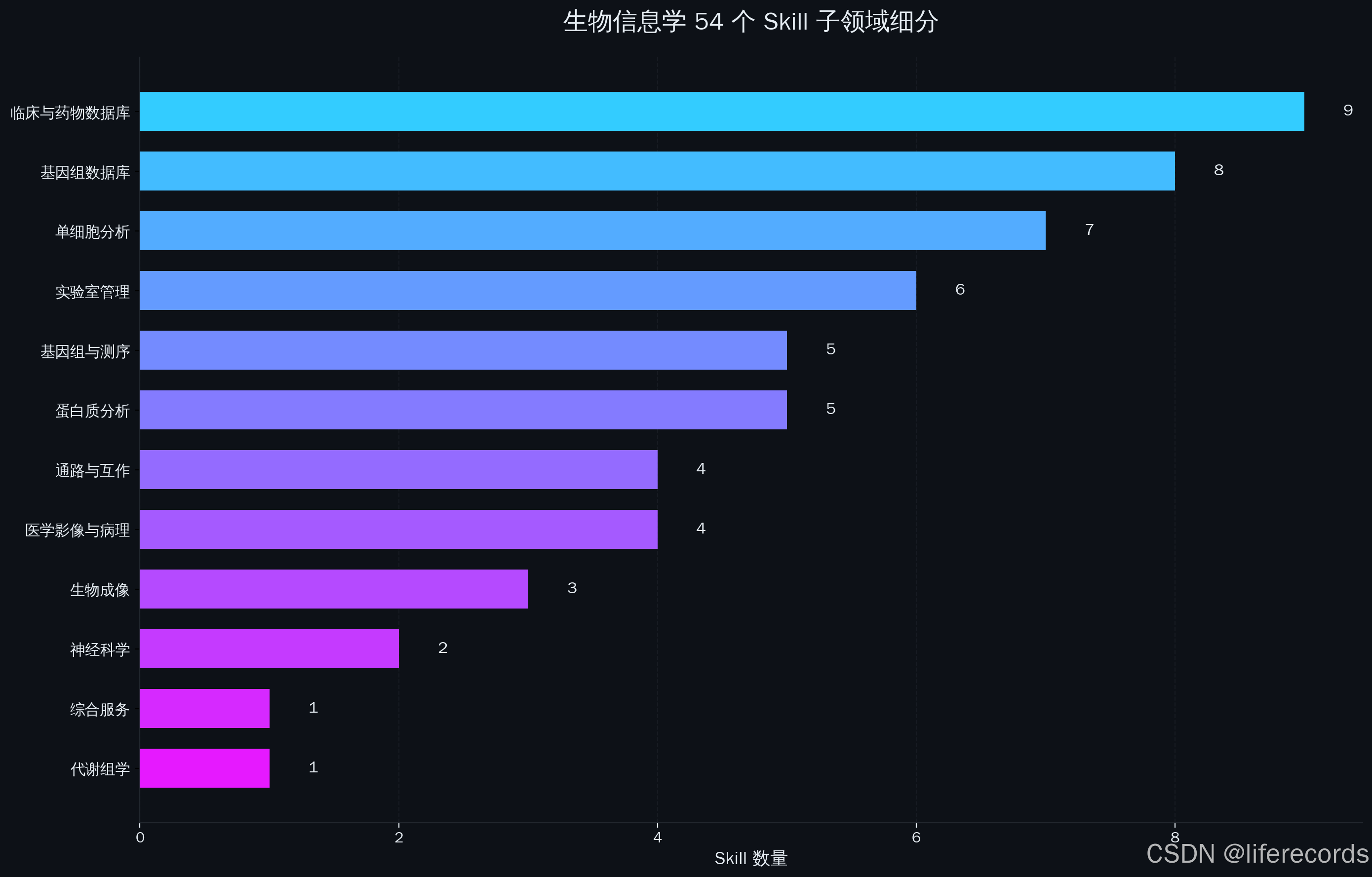
我们将学术搜索(17个)+ 学术写作(21个)+ 科学可视化(9个)= 47个Skill串联成一条完整的学术生产链路:
第一阶段:发现(Discovery)
academic-search → research-lookup → paper-lookup → citation-network → literature-review
Agent先用academic-search进行跨平台搜索,用research-lookup和paper-lookup精确定位,用citation-network构建引用关系图,最后用literature-review完成系统性综述。5个Skill,从"不知道"到"全知道"。
第二阶段:规划(Planning)
qinyan-topic-analysis → academic-paper-strategist → hypothesis-generation → qinyan-paper-analysis
选题分析→论文战略规划→假设生成→论文解读。4个Skill,从"想做什么"到"怎么做"。
第三阶段:执行(Execution)
academic-paper-composer → scientific-writing → qinyan-paper-polish → peer-review
从大纲到初稿到润色到自审。4个Skill,从"开始写"到"写完了"。
第四阶段:可视化(Visualization)
matplotlib → seaborn → plotly → scientific-schematics → scientific-visualization
5个Skill覆盖了从基础图表到交互可视化到科学示意图的全光谱。
第五阶段:交付(Delivery)
latex-posters / pptx-posters → pptx → docx → pdf → paper-2-web / paper-slide-deck
6个Skill覆盖了论文、海报、PPT、网页等多种输出格式。
第六阶段:管理(Management)
pyzotero → paperzilla → venue-templates → markitdown → xlsx
文献管理→论文管理→投稿格式→格式转换→数据表格。
47个Skill,6个阶段,从发现到交付的完整闭环。这不是"辅助工具"的堆砌,而是一条可编程的学术生产流水线。
五、化学与AI/ML:药物发现+深度学习的交叉前沿
化学领域21个Skill和AI/ML领域28个Skill的交叉,正在催生一种全新的药物发现范式。
5.1 从分子到药物:化学领域的完整工具链
化学领域的13个计算工具,构成了一条从分子表示到药物发现的完整技术栈:
分子表示层:rdkit(分子操作与描述符计算)→ molfeat(分子特征工程与表示学习)→ datamol(分子数据处理)
分子建模层:deepchem(深度学习药物发现)→ torchdrug(图神经网络药物建模)→ diffdock(分子对接预测)
药物优化层:medchem(药物化学与先导优化)→ pytdc(药物发现基准测试)
模拟层:molecular-dynamics(分子动力学模拟)→ rowan(量子化学计算)→ cobrapy(代谢建模)
分析层:matchms(质谱分析)→ glycoengineering(糖工程)
这条工具链的精妙之处在于:每一层的输出都是下一层的输入。RDKit生成的分子描述符,可以喂给molfeat做特征工程;molfeat的表示向量,可以喂给deepchem做活性预测;deepchem的预测结果,可以喂给diffdock做分子对接;diffdock的对接结果,可以喂给medchem做先导优化。
5.2 数据燃料:8个化学数据库
chembl-database(生物活性分子)、drugbank-database(药物信息)、pubchem-database(化学物质)、zinc-database(虚拟筛选化合物库)、bindingdb-database(结合亲和力)、brenda-database(酶数据)、hmdb-database(人类代谢组)、uspto-database(化学专利)。
8个数据库提供了从化合物结构到生物活性到专利信息的全维度数据。特别值得注意的是zinc-database——它提供了数十亿个可购买化合物的3D结构,是虚拟筛选的核心数据源。当Agent可以同时调用ZINC获取化合物库、用RDKit计算分子描述符、用DiffDock预测结合模式、用ChEMBL验证活性数据,一条从虚拟筛选到活性验证的药物发现流水线就闭环了。
5.3 AI/ML的交叉赋能
AI/ML领域的28个Skill,为化学和生物信息学提供了强大的建模能力:
torch-geometric(图神经网络)→ 分子图建模transformers(NLP/LLM)→ 化学文献挖掘esm(蛋白质语言模型)→ 蛋白质结构预测bgpt(BioGPT)→ 生物医学文本生成pennylane(量子ML)→ 量子化学机器学习shap(模型解释)→ 药物预测模型可解释性
当Agent学会了调用AlphaFold和写国自然,科研的定义正在被重写。 这不是夸张——当alphafold-database(蛋白质结构)+ diffdock(分子对接)+ deepchem(活性预测)+ chembl-database(活性验证)+ nsfc-proposal(基金申请)可以在同一个Agent的工作流中串联起来,从靶点发现到基金申请的整个转化医学链条,就有了被自动化的可能。
六、仓库生态暗战:K-Dense vs LeonChaoX vs 其他
202个Skill来自10个GitHub仓库,但真正的玩家只有两个。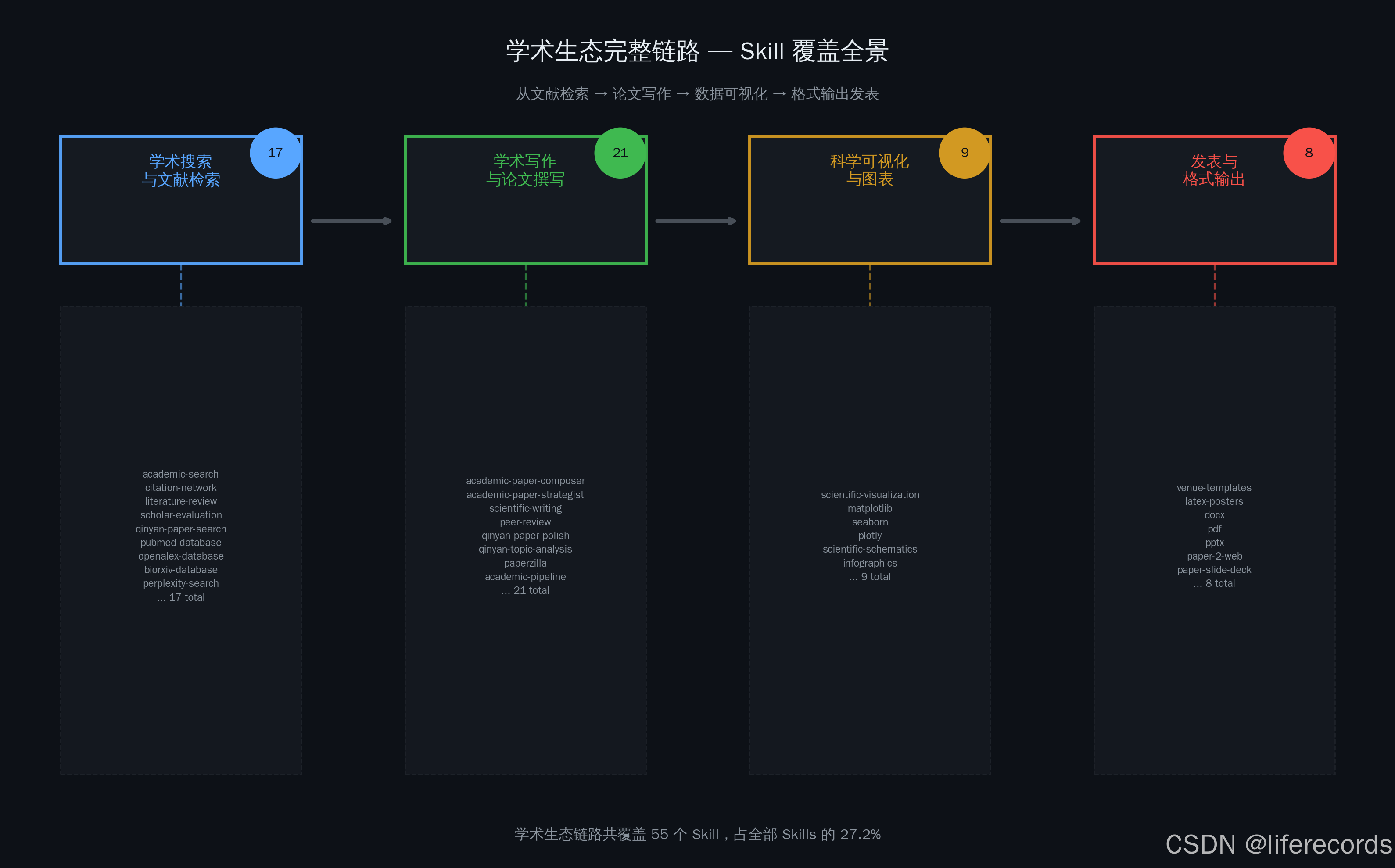
6.1 K-Dense-AI/scientific-agent-skills:全能型选手
~100+个Skill,覆盖科学计算、生物信息、化学、AI/ML、物理、写作等几乎所有领域。它是整个生态的"基础设施层"——如果你只能选一个仓库,选它就够了。
值得注意的是,K-Dense的上游是obra/superpowers,两者Skill完全重叠。superpowers是更早期的项目,K-Dense可以看作是superpowers在科学Agent方向的聚焦和重组。
6.2 LeonChaoX/qinyan-academic-skills:数据库之王
~50+个Skill,核心优势是30+专业数据库接口和中文学术特色。
LeonChaoX的策略很清晰:不做计算工具(那是K-Dense的领地),专攻数据接口和中文生态。30+个数据库接口Skill(从AlphaFold到ZINC,从NSFC到ClinicalTrials),加上沁言系列(qinyan-paper-search、qinyan-citation、qinyan-paper-analysis、qinyan-paper-polish、qinyan-topic-analysis),构成了一个"数据获取+中文处理"的差异化定位。
6.3 其他仓库:长尾贡献者
- lishix520/academic-paper-skills(2个):strategist + composer,论文写作的精品流水线
- Imbad0202/academic-research-skills(3个):论文写作+评审+流程管理,简洁实用
- companion-inc/feynman(2个):费曼学习法,教育方向
- ustc-ai4science/academic-search(1个):功能最全面的学术搜索Skill
- peterskoett/self-improving-agent(1个):Agent自我改进,哲学级Skill
- OthmanAdi/planning-with-files(1个):文件化任务规划
- HughYau/AcademicForge(1个):科学可视化
6.4 生态格局的三个趋势
趋势一:K-Dense + LeonChaoX = 事实标准。两个仓库合计贡献了150+个Skill,占总量的75%以上。其他仓库要么是单点精品(academic-search、self-improvement),要么是补充性贡献。
趋势二:数据库接口成为竞争焦点。LeonChaoX的30+数据库接口Skill,是它最大的护城河。K-Dense虽然在计算工具上占优,但在结构化数据访问上依赖LeonChaoX的补充。
趋势三:中文生态是蓝海。目前只有LeonChaoX的沁言系列和NSFC/NSSFC Skill覆盖了中文场景。随着中国科研AI市场的增长,这个方向的Skill数量有望快速增长。
七、终章:Agent自我进化——从工具使用者到工具创造者
在202个Skill中,有一个Skill值得单独拿出来讨论:self-improvement。
来自peterskoett/self-improving-agent,这个Skill的功能是"捕获学习、错误和纠正以实现持续改进,支持学习日志、错误记录、功能请求、模式检测和技能提取"。
self-improvement skill的出现,暗示Agent正在从工具使用者进化为工具创造者。
这不是一个比喻。让我们梳理一下Agent能力的进化路径:
Level 1:工具使用者。Agent调用预定义的Skill完成任务。202个Skill中的绝大多数都属于这个层级——scanpy分析单细胞数据,rdkit操作分子,matplotlib画图。Agent是"手",Skill是"工具"。
Level 2:工具发现者。autoskill和get-available让Agent可以自动发现和加载可用的Skill。Agent不再需要人类告诉它"你应该用哪个工具",而是自己去找。
Level 3:工具学习者。self-improvement让Agent可以跨会话学习——记录错误、检测模式、提取技能。这意味着Agent在完成任务的过程中,会变得越来越擅长完成这类任务。
Level 4:工具创造者(尚未实现,但方向明确)。如果Agent可以学习模式、提取技能,那么理论上它也可以创造新的Skill。当一个Agent在使用scanpy分析单细胞数据时发现了一个反复出现的分析模式,它可以将其封装为一个新的Skill——这就是从"使用工具"到"创造工具"的质变。
与self-improvement相呼应的,还有planning-with-files——基于文件的任务规划,将计划存储为文件以实现持久化和可追溯。这两个Skill的组合,意味着Agent开始具备了"元认知"能力:它不仅能执行任务,还能规划任务、反思任务、改进任务。
从工具使用者到工具创造者,这不是一条技术路线图,而是一条认知进化路线图。
当202个Skill覆盖了从单细胞测序到量子计算、从学术搜索到基金申请的完整科研光谱,当self-improvement让Agent开始学会"学会",当autoskill让Agent可以自主扩展能力边界——我们面对的已经不是一个"科研助手",而是一个正在进化中的"科研智能体"。
它还不会提出真正原创的科学问题。它还不能设计一个前所未有的实验。它还没有"品味"——那种在无数可能中选出最有价值方向的直觉。
但它已经在路上了。
附录:202个Skill完整分类清单
一、学术搜索与文献检索(17个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| academic-search | ustc-ai4science | 论文搜索,引用分析,PDF获取 | 支持10+平台的学术搜索,含CDP浏览器模式 |
| citation-network | K-Dense-AI | 引用网络,文献关系 | 分析论文引用关系,构建引用网络图 |
| literature-review | K-Dense-AI | 文献综述,系统性综述 | 辅助系统性文献综述,支持PRISMA流程 |
| scholar-evaluation | K-Dense-AI | 学者评价,h-index | 评估学者学术影响力和产出指标 |
| venue-templates | K-Dense-AI | 期刊模板,投稿格式 | 提供期刊/会议投稿模板和格式要求 |
| research-lookup | K-Dense-AI | 研究查找 | 快速查找特定研究主题的相关文献 |
| paper-lookup | K-Dense-AI | 论文查找 | 根据关键词/DOI/arXiv ID查找论文 |
| pyzotero | K-Dense-AI | Zotero,文献管理 | 集成Zotero文献管理工具 |
| qinyan-paper-search | LeonChaoX | 论文搜索,中文论文 | 沁言学术论文搜索,支持中文 |
| qinyan-citation | LeonChaoX | 引用分析,中文引用 | 沁言引用分析,支持中文文献 |
| biorxiv-database | LeonChaoX | bioRxiv,预印本 | 访问bioRxiv预印本数据库 |
| openalex-database | LeonChaoX | OpenAlex,跨学科 | 访问OpenAlex跨学科学术数据库 |
| pubmed-database | LeonChaoX | PubMed,生物医学 | 访问PubMed生物医学文献数据库 |
| perplexity-search | LeonChaoX | Perplexity,AI搜索 | 使用Perplexity AI进行实时学术搜索 |
| exa-search | LeonChaoX | Exa,语义搜索 | 使用Exa进行语义化学术搜索 |
| database-lookup | LeonChaoX | 数据库查询 | 通用学术数据库查询接口 |
| offer-k-dense-web | LeonChaoX | K-Dense,Web搜索 | 提供K-Dense Web搜索能力 |
二、学术写作与论文撰写(21个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| academic-paper-composer | lishix520 | 论文写作,manuscript | 系统性学术论文写作框架,含质量门控 |
| academic-paper-strategist | lishix520 | 论文规划,研究空白 | 三阶段战略规划,含AI文献搜索和原创性评估 |
| scientific-writing | K-Dense-AI | 科学写作,学术写作 | 辅助科学论文写作,结构和语言指导 |
| peer-review | K-Dense-AI | 同行评审,审稿 | 辅助同行评审,提供评审框架 |
| latex-posters | K-Dense-AI | LaTeX海报,学术海报 | 使用LaTeX创建学术会议海报 |
| markdown-mermaid | K-Dense-AI | Markdown,Mermaid | 使用Markdown和Mermaid创建学术图表 |
| docx | K-Dense-AI | Word文档,docx | 生成Word格式学术文档 |
| K-Dense-AI | PDF,文档生成 | 生成PDF格式学术报告 | |
| pptx | K-Dense-AI | PowerPoint,演示文稿 | 生成PowerPoint学术演示文稿 |
| pptx-posters | K-Dense-AI | PPT海报 | 使用PowerPoint创建学术海报 |
| xlsx | K-Dense-AI | Excel,数据表 | 生成Excel格式数据表格 |
| markitdown | K-Dense-AI | Markdown转换 | 将各种格式文档转换为Markdown |
| qinyan-paper-analysis | LeonChaoX | 论文分析,论文解读 | 沁言论文分析,辅助解读学术论文 |
| qinyan-paper-polish | LeonChaoX | 论文润色,学术英语 | 沁言论文润色,改进学术语言表达 |
| qinyan-topic-analysis | LeonChaoX | 选题分析,研究选题 | 沁言选题分析,评估和选择研究主题 |
| paper-2-web | LeonChaoX | 论文转网页 | 将学术论文转化为网页展示 |
| paper-slide-deck | LeonChaoX | 论文转PPT | 将学术论文转化为演示文稿 |
| paperzilla | LeonChaoX | 论文管理 | 论文管理和组织工具 |
| academic-paper | Imbad0202 | 学术论文,论文写作 | 学术论文写作辅助 |
| academic-paper-reviewer | Imbad0202 | 论文评审 | 学术论文评审辅助 |
| academic-pipeline | Imbad0202 | 学术流程,研究流程 | 学术研究全流程管理 |
三、科学可视化与图表(9个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| scientific-visualization | HughYau | 科学可视化,matplotlib | 科学数据可视化,支持matplotlib/seaborn |
| matplotlib | K-Dense-AI | matplotlib,绑图 | 使用matplotlib进行科学数据绑图 |
| seaborn | K-Dense-AI | seaborn,统计可视化 | 使用seaborn进行统计数据可视化 |
| plotly | LeonChaoX | plotly,交互图表 | 使用plotly创建交互式图表 |
| plotly | K-Dense-AI | plotly,交互可视化 | 使用plotly进行交互式数据可视化 |
| scientific-schematics | K-Dense-AI | 科学示意图,原理图 | 创建科学原理示意图和流程图 |
| scientific-slides | K-Dense-AI | 科学幻灯片 | 创建学术演示幻灯片 |
| infographics | K-Dense-AI | 信息图,数据展示 | 创建信息图和数据展示 |
| scientific-visualization | K-Dense-AI | 科学可视化,数据图表 | 科学数据可视化和图表制作 |
四、生物信息学与基因组学(54个)
| Skill名称 | 来源仓库 | 子领域 | 简介 |
|---|---|---|---|
| scanpy | K-Dense-AI | 单细胞分析 | 单细胞RNA-seq数据分析核心框架 |
| scvelo | K-Dense-AI | 单细胞分析 | RNA速度分析,推断细胞分化轨迹 |
| scvi-tools | K-Dense-AI | 单细胞分析 | 单细胞深度学习分析(scVI/scANVI) |
| pydeseq2 | K-Dense-AI | 单细胞分析 | 差异基因表达分析 |
| anndata | K-Dense-AI | 单细胞分析 | 单细胞数据结构管理(AnnData格式) |
| cellxgene | K-Dense-AI | 单细胞分析 | CellxGene单细胞数据门户访问 |
| pysam | K-Dense-AI | 基因组比对 | SAM/BAM基因组比对文件处理 |
| gget | K-Dense-AI | 基因组查询 | 基因组数据库查询 |
| scikit-bio | K-Dense-AI | 序列分析 | 生物信息学序列分析 |
| phylogenetics | K-Dense-AI | 进化分析 | 系统发育和进化树分析 |
| etetoolkit | K-Dense-AI | 进化分析 | ETE Toolkit进化树可视化和分析 |
| alphafold-database | LeonChaoX | 蛋白质结构 | AlphaFold蛋白质结构预测数据库 |
| interpro-database | LeonChaoX | 蛋白质结构 | InterPro蛋白质家族和结构域 |
| pdb-database | LeonChaoX | 蛋白质结构 | PDB蛋白质3D结构数据库 |
| uniprot-database | LeonChaoX | 蛋白质结构 | UniProt蛋白质序列和注释 |
| ensembl-database | LeonChaoX | 基因组注释 | Ensembl基因组浏览器和注释 |
| ena-database | LeonChaoX | 基因组注释 | 欧洲核酸档案(ENA) |
| gene-database | LeonChaoX | 基因组注释 | NCBI Gene数据库 |
| geo-database | LeonChaoX | 基因表达 | GEO基因表达综合数据库 |
| gnomad-database | LeonChaoX | 基因组变异 | gnomAD基因组变异频率 |
| gtex-database | LeonChaoX | 基因表达 | GTEx基因型-组织表达 |
| gwas-database | LeonChaoX | 遗传关联 | GWAS全基因组关联研究 |
| jaspar-database | LeonChaoX | 转录因子 | JASPAR转录因子结合位点 |
| kegg-database | LeonChaoX | 通路分析 | KEGG代谢和信号通路 |
| reactome-database | LeonChaoX | 通路分析 | Reactome生物反应通路 |
| string-database | LeonChaoX | 蛋白质互作 | STRING蛋白质-蛋白质相互作用 |
| opentargets-database | LeonChaoX | 疾病关联 | Open Targets药物靶点与疾病关联 |
| cbioportal-database | LeonChaoX | 癌症基因组 | cBioPortal癌症基因组学 |
| clinvar-database | LeonChaoX | 临床变异 | ClinVar临床相关变异 |
| clinpgx-database | LeonChaoX | 药物基因组 | ClinPGx药物基因组学 |
| cosmic-database | LeonChaoX | 癌症突变 | COSMIC体细胞突变目录 |
| clinicaltrials-database | LeonChaoX | 临床试验 | ClinicalTrials.gov临床试验 |
| fda-database | LeonChaoX | 药物审批 | FDA药物审批数据库 |
| monarch-database | LeonChaoX | 表型基因关联 | Monarch Initiative表型-基因关联 |
| metabolomics-workbench-database | LeonChaoX | 代谢组学 | Metabolomics Workbench代谢组学 |
| pyopenms | K-Dense-AI | 蛋白质组学 | 蛋白质组学质谱数据分析 |
| pydicom | K-Dense-AI | 医学影像 | DICOM医学影像处理 |
| histolab | K-Dense-AI | 病理分析 | 组织病理全切片图像处理 |
| pathml | K-Dense-AI | 病理分析 | 数字病理图像分析 |
| medical-imaging-review | LeonChaoX | 医学影像 | 医学影像AI综述和分析 |
| neurokit2 | K-Dense-AI | 生理信号 | 生理信号分析(ECG/EMG等) |
| neuropixels | K-Dense-AI | 电生理 | Neuropixels电生理记录数据处理 |
| flowio | K-Dense-AI | 流式细胞术 | 流式细胞术FCS数据处理 |
| imaging-data | K-Dense-AI | 生物成像 | 生物成像数据分析 |
| omero | K-Dense-AI | 图像管理 | OMERO生物图像管理平台 |
| opentrons | K-Dense-AI | 实验室自动化 | Opentrons液体处理平台控制 |
| pylabrobot | K-Dense-AI | 实验室自动化 | PyLabRobot实验室机器人控制 |
| benchling | K-Dense-AI | 实验室管理 | Benchling实验室信息管理系统 |
| labarchive | K-Dense-AI | 实验记录 | LabArchives电子实验记录本 |
| lamindb | K-Dense-AI | 数据管理 | LaminDB生物数据版本管理 |
| protocolsio | K-Dense-AI | 实验方案 | protocols.io实验方案数据库 |
| pyhealth | K-Dense-AI | 医疗AI | 医疗AI和临床预测建模 |
| umap-learn | K-Dense-AI | 降维分析 | UMAP降维分析 |
| bioservices | K-Dense-AI | API集成 | 多生物信息学Web API集成 |
| scikit-survival | K-Dense-AI | 生存分析 | 生存分析(Kaplan-Meier等) |
五、化学与药物发现(21个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| rdkit | K-Dense-AI | 化学信息学,分子描述符 | 化学信息学和分子操作核心 |
| medchem | K-Dense-AI | 药物化学,先导优化 | 药物化学和先导化合物优化 |
| molfeat | K-Dense-AI | 分子特征,表示学习 | 分子特征工程和表示学习 |
| datamol | K-Dense-AI | 分子数据 | 分子数据处理 |
| matchms | K-Dense-AI | 质谱,光谱匹配 | 质谱光谱匹配 |
| deepchem | K-Dense-AI | 深度化学,分子AI | 深度学习驱动的药物发现 |
| diffdock | K-Dense-AI | 分子对接,docking | 分子对接预测 |
| cobrapy | K-Dense-AI | 代谢建模,flux balance | 约束基代谢建模 |
| molecular-dynamics | K-Dense-AI | 分子动力学,MD模拟 | 分子动力学模拟 |
| glycoengineering | K-Dense-AI | 糖工程,糖基化 | 糖工程和糖基化分析 |
| rowan | K-Dense-AI | 量子化学,计算化学 | 量子化学计算 |
| pytdc | K-Dense-AI | TDC,药物发现基准 | 药物发现基准测试 |
| torchdrug | K-Dense-AI | 药物AI,图神经网络 | 药物发现图神经网络建模 |
| bindingdb-database | LeonChaoX | 结合亲和力 | BindingDB结合亲和力数据库 |
| brenda-database | LeonChaoX | 酶数据库 | BRENDA酶数据库 |
| chembl-database | LeonChaoX | 生物活性分子 | ChEMBL生物活性分子数据库 |
| drugbank-database | LeonChaoX | 药物信息 | DrugBank药物信息数据库 |
| hmdb-database | LeonChaoX | 人类代谢组 | HMDB人类代谢组数据库 |
| pubchem-database | LeonChaoX | 化学物质 | PubChem化学物质数据库 |
| zinc-database | LeonChaoX | 虚拟筛选 | ZINC虚拟筛选化合物库 |
| uspto-database | LeonChaoX | 化学专利 | USPTO专利和化学反应数据库 |
六、AI/ML与深度学习(28个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| scikit-learn | K-Dense-AI | 机器学习,分类,回归 | 通用机器学习建模 |
| transformers | K-Dense-AI | Transformers,NLP,LLM | HuggingFace Transformers NLP和大模型推理 |
| pytorch-lightning | K-Dense-AI | 训练框架,深度学习 | PyTorch Lightning深度学习训练 |
| torch-geometric | K-Dense-AI | 图神经网络,GNN | PyTorch Geometric图神经网络建模 |
| qiskit | K-Dense-AI | 量子计算,Quantum | Qiskit量子计算编程 |
| qutip | K-Dense-AI | 量子物理,量子模拟 | QuTiP量子物理模拟 |
| pennylane | K-Dense-AI | 量子ML,QML | PennyLane量子机器学习 |
| shap | K-Dense-AI | 可解释性,SHAP | 机器学习模型可解释性分析 |
| statsmodels | K-Dense-AI | 统计建模,计量经济学 | 统计建模 |
| pymc | K-Dense-AI | 贝叶斯统计,概率编程 | 贝叶斯统计建模 |
| sympy | K-Dense-AI | 符号计算,数学 | 符号数学计算 |
| statistical-analysis | K-Dense-AI | 统计分析,假设检验 | 统计分析和假设检验 |
| dask | K-Dense-AI | 并行计算,大数据 | 并行和分布式计算 |
| polars | K-Dense-AI | 数据帧,高性能数据 | 高性能数据处理 |
| vaex | K-Dense-AI | 大数据可视化 | 十亿行级数据处理和可视化 |
| networkx | K-Dense-AI | 网络分析,图论 | 网络和图论分析 |
| pymoo | K-Dense-AI | 多目标优化,进化算法 | 多目标优化 |
| simpy | K-Dense-AI | 离散事件模拟 | 离散事件模拟 |
| stable-baselines3 | K-Dense-AI | 强化学习,RL | Stable Baselines3强化学习 |
| pufferlib | K-Dense-AI | RL环境,游戏AI | PufferLib强化学习环境 |
| esm | K-Dense-AI | 蛋白质语言模型 | Meta ESM蛋白质语言模型 |
| bgpt | K-Dense-AI | 生物GPT,BioGPT | BioGPT生物医学文本生成 |
| hugging-science | K-Dense-AI | HuggingFace,科学AI | HuggingFace科学模型推理 |
| optimize-for-gpu | K-Dense-AI | GPU优化,CUDA | GPU加速优化 |
| modal | K-Dense-AI | 云端计算,serverless | Modal云端无服务器计算 |
| denario | K-Dense-AI | 量化金融,金融ML | 量化金融和机器学习 |
| denario | LeonChaoX | 量化金融,金融ML | 量化金融和机器学习(沁言版) |
| optimize-for-gpu | LeonChaoX | GPU优化,CUDA | GPU加速优化(沁言版) |
七、材料科学与物理(6个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| pymatgen | K-Dense-AI | 材料基因组,材料计算 | 材料基因组计算 |
| astropy | K-Dense-AI | 天文学,天文数据 | 天文学数据处理 |
| primekg | K-Dense-AI | 知识图谱,生物医学KG | PrimeKG生物医学知识图谱 |
| depmap | K-Dense-AI | 癌症依赖,CRISPR | DepMap癌症依赖性图谱 |
| tiledbvcf | K-Dense-AI | VCF,基因组变异 | TileDB-VCF基因组变异数据管理 |
| zarr-python | K-Dense-AI | Zarr,多维数据 | Zarr云存储多维数据管理 |
八、金融与经济数据(5个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| alpha-vantage | LeonChaoX | 股票数据,金融API | Alpha Vantage股票和金融数据 |
| fred-economic-data | LeonChaoX | 美联储,经济数据 | FRED美联储经济数据 |
| edgartools | LeonChaoX | SEC,EDGAR | SEC EDGAR财务报告 |
| hedgefundmonitor | LeonChaoX | 对冲基金,金融监控 | 对冲基金监控和分析 |
| datacommons-client | LeonChaoX | 统计数据,社会指标 | Data Commons统计数据访问 |
九、科学思维与研究方法(15个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| scientific-brainstorming | K-Dense-AI | 头脑风暴,创意 | 科学研究头脑风暴和创意生成 |
| scientific-critical-thinking | K-Dense-AI | 批判性思维,论证分析 | 科学批判性思维和论证分析 |
| hypothesis-generation | K-Dense-AI | 假设生成 | 生成和评估科学研究假设 |
| hypogenic | K-Dense-AI | 自动假设,假设挖掘 | 自动生成研究假设 |
| what-if-oracle | K-Dense-AI | 反事实,因果推理 | What-if反事实分析和因果推理 |
| consciousness | K-Dense-AI | 意识研究,认知科学 | 意识研究和认知科学分析 |
| research-grants | K-Dense-AI | 基金申请,grant writing | 研究资助申请撰写 |
| iso-13485 | K-Dense-AI | 医疗器械,质量管理 | ISO 13485医疗器械质量管理体系 |
| clinical-decision | K-Dense-AI | 临床决策 | 临床决策分析 |
| clinical-reports | K-Dense-AI | 临床报告 | 临床研究报告撰写 |
| treatment-plans | K-Dense-AI | 治疗方案 | 临床治疗方案制定 |
| open-notebook | K-Dense-AI | 开放笔记本,开放科学 | 开放科学笔记本和实验记录 |
| nsfc-proposal | LeonChaoX | 国家自然科学基金,NSFC | 国家自然科学基金申请书撰写 |
| nssfc-proposal | LeonChaoX | 国家社科基金,NSSFC | 国家社科基金申请书撰写 |
| research-proposal | LeonChaoX | 研究提案 | 通用研究提案撰写 |
十、Agent能力与通用工具(24个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| self-improvement | peterskoett | 自我改进,学习记录 | 跨会话学习、错误记录、模式检测、技能提取 |
| planning-with-files | OthmanAdi | 文件规划,任务管理 | 基于文件的任务规划和管理 |
| autoskill | K-Dense-AI | 自动技能,技能发现 | 自动技能发现和加载 |
| get-available | K-Dense-AI | 工具发现 | 发现和列出可用工具 |
| generate-image | K-Dense-AI | 图像生成,AI图像 | AI图像生成 |
| parallel-web | K-Dense-AI | 并行Web,web scraping | 并行Web抓取 |
| market-research | K-Dense-AI | 市场研究,商业分析 | 市场研究和商业分析 |
| matlab | K-Dense-AI | MATLAB,工程计算 | MATLAB工程计算集成 |
| geopandas | K-Dense-AI | GeoPandas,地理信息 | 地理空间分析 |
| geomaster | K-Dense-AI | 地理数据,GIS | 地理空间数据处理 |
| timesfm-forecasting | K-Dense-AI | 时间序列预测,TimesFM | TimesFM时间序列预测 |
| usfiscaldata | K-Dense-AI | 美国财政数据 | 美国财政数据分析 |
| polars-bio | K-Dense-AI | 生物数据,基因组 | Polars-bio生物数据处理 |
| latchbio | K-Dense-AI | 工作流,生信流程 | LatchBio生物信息工作流 |
| dnanexus | K-Dense-AI | 生信平台,云计算 | DNAnexus生物信息云平台 |
| dhdna | K-Dense-AI | DNA分析,核酸 | DHDNA DNA分析工具 |
| geniml | K-Dense-AI | 基因组ML | Geniml基因组机器学习 |
| gtars | K-Dense-AI | 基因组注释,区域分析 | GTARS基因组区域注释 |
| ginkgo | K-Dense-AI | 合成生物,synbio | Ginkgo合成生物学工具 |
| deeptools | K-Dense-AI | 测序分析,BAM处理 | deepTools测序数据处理 |
| fluidsim | K-Dense-AI | 流体模拟,CFD | FluidSim流体动力学模拟 |
| adaptyv | K-Dense-AI | 自适应,自动化 | Adaptyv自适应自动化工具 |
| aeon | K-Dense-AI | 时间序列,时序分析 | Aeon时间序列分析 |
| arboreto | K-Dense-AI | 特征选择,树模型 | Arboreto特征选择工具 |
十一、Feynman学习与教学(2个)
| Skill名称 | 来源仓库 | 关键词 | 简介 |
|---|---|---|---|
| feynman-learning | companion-inc | 费曼学习法,教学相长 | 基于费曼学习法的学习和教学 |
| feynman-teaching | companion-inc | 费曼教学,概念解释 | 基于费曼方法的科学概念教学 |
标签:#AI_Agent #科研自动化 #生物信息学 #药物发现 #Skill生态 #学术写作 #量子计算 #开源协作 #Agent进化 #AlphaFold
声明:本文数据基于2026年5月GitHub公开仓库的Skill分类统计,Skill数量和功能描述以各仓库最新版本为准。
联系:如果有更多信息,可以与我探讨
如有问题,欢迎来打扰

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)