别只盯着 ElevenLabs,这个开源配音工作台能本地跑
我最近看到一个开源项目,第一反应不是模型又强了,而是这东西终于开始像个真正的工作台了。它叫 OmniVoice Studio。项目自己给自己的定位很直接,开源版 ElevenLabs 替代品。实时听写、零样本声音克隆、电影级视频配音,都在本地桌面里跑。README 里写得更狠一点,开源、不需要 API Key、完全本地,还支持 646 种语言。坦率的讲,看到这种描述,我第一反应一般会先打个折。因为
我最近看到一个开源项目,第一反应不是模型又强了,而是这东西终于开始像个真正的工作台了。
它叫 OmniVoice Studio。
项目自己给自己的定位很直接,开源版 ElevenLabs 替代品。实时听写、零样本声音克隆、电影级视频配音,都在本地桌面里跑。README 里写得更狠一点,开源、不需要 API Key、完全本地,还支持 646 种语言。
坦率的讲,看到这种描述,我第一反应一般会先打个折。
因为过去这类项目我见得太多了。模型能力很强,论文也很漂亮,但普通人真要用起来,往往要先装环境、拉权重、配 CUDA、改脚本、补依赖。最后声音也许合成出来了,但你已经忘了自己本来想做什么。
所以 OmniVoice Studio 真正让我感兴趣的地方,不只是它能合成声音。
而是它把「做一条配音视频」这件事,从模型能力包装成了一个产品流程。
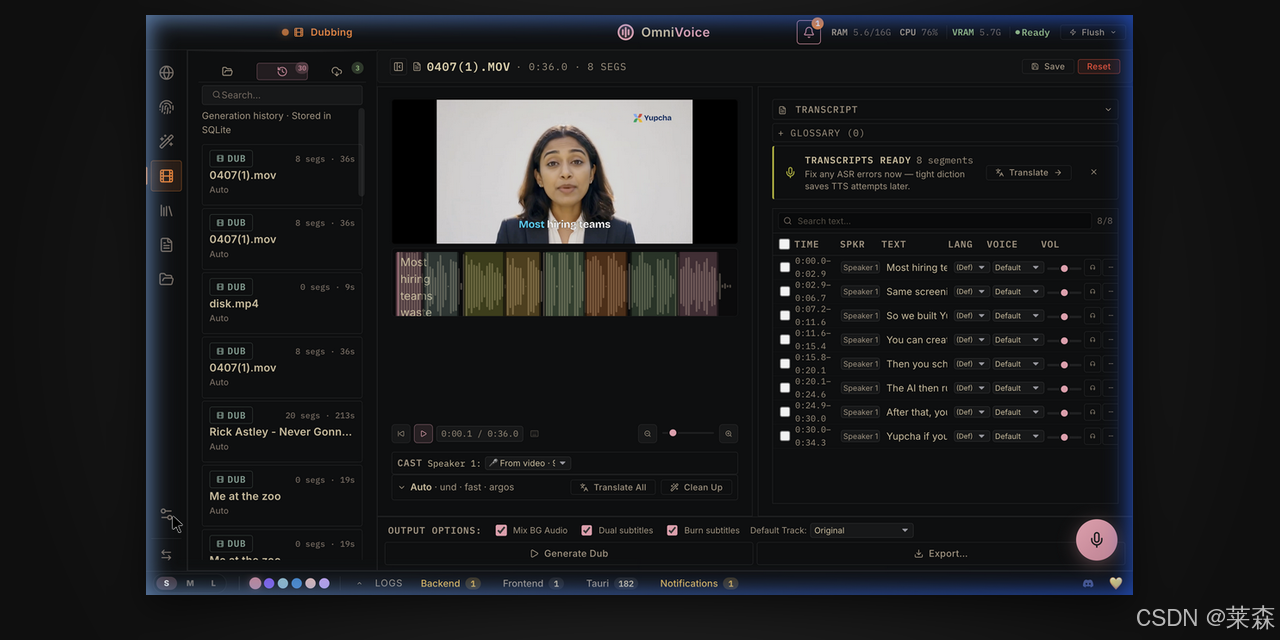
它不是一个单点 TTS 工具
很多人提到 AI 配音,脑子里想到的是一句话,输入文字,生成音频。
这个当然重要,但如果你真的做过视频,就会知道它只占工作流里很小的一块。你真正要处理的是一整条链路,原视频从哪里来,声音怎么分离,字幕怎么识别,翻译怎么做,角色怎么对应,配音怎么回填,最后怎么导出成一个能发的平台视频。
OmniVoice Studio 的产品思路,正好是围着这条链路展开的。
它有声音克隆,3 秒音频片段就可以做 zero-shot 克隆。它有声音设计,不给参考音频也可以用性别、年龄、口音、音高、情绪这类属性去捏一个声音。它有视频配音工作台,可以从 YouTube URL 或本地文件开始,走转写、翻译、重新配音、导出 MP4。它还有听写小组件,可以在任何 app 里用快捷键唤起,转写之后自动粘贴。
这些东西单独看都不新鲜。
但把它们放在一个本地桌面工作台里,味道就不一样了。
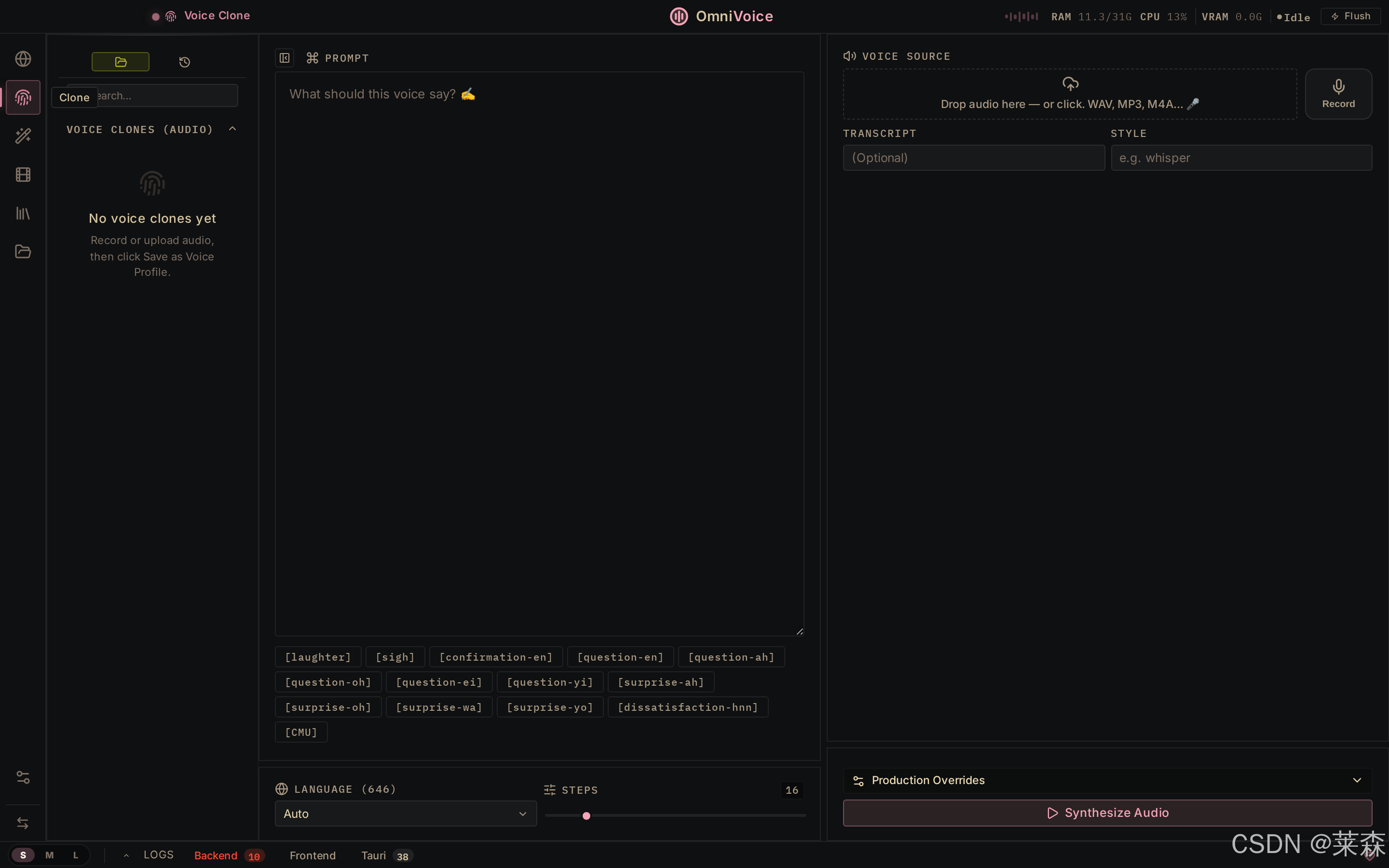
你想想看,一个内容创作者最怕的不是没有工具,而是工具之间互相不认识。A 工具转字幕,B 工具翻译,C 工具配音,D 工具剪音轨。中间任何一步出问题,你就开始手动搬文件,手动改时间轴,手动对齐。
这时候所谓 AI 能力再强,也会被流程损耗吃掉。
OmniVoice Studio 打动我的点就在这里。它不是在炫耀一个合成按钮,而是在努力把这堆脏活收进同一个地方。
最像产品的地方,是它知道改视频有多痛
我最喜欢 README 里的一组能力,不是 646 种语言,也不是开源本地。
而是它在路线图里反复讲的两个词,Directorial AI 和 Incremental re-dub。
前者大概可以理解成「导演式 AI」。你可以对某个片段说,让第 14 段更急一点,让这句更温柔一点,它会把这个方向同时影响翻译语气、TTS instruct 和语速目标。
后者更实用,叫增量重配音。改一个两小时视频里的一句话,只重新生成受影响的片段,再和原来的音轨重新拼起来。
这个设计特别现实。
因为做视频配音最折磨人的瞬间,通常不是第一次生成,而是你发现某一句翻译不顺,某一个发音不对,某个角色语气不贴。你只想改这一句,但很多工具会让你像重开一局游戏一样,从头再来。
如果增量重配音真的跑顺了,它省的不是几秒钟,而是一个创作者的心理成本。
你会更敢改。
你会更敢试不同声音、不同语气、不同翻译版本。因为每一次尝试不再像一次大工程,而像是在时间线上改一个局部。
这一点我觉得非常关键。AI 工具进入创作流程以后,最重要的变化不是「一次出片」,而是「试错变便宜」。一旦试错便宜,人的创造力才会真的被放出来。
它把隐私和成本这件事说得很明白
OmniVoice Studio 明确拿 ElevenLabs 做对比。
ElevenLabs 是云服务,按月收费,README 里写的价格区间是每月 5 到 330 美元。OmniVoice Studio 的思路则是,本地运行,不需要 API Key,不需要账号,音频不离开你的机器。
我不觉得这能简单得出谁更好的结论。
云服务的优势很明显,开箱即用,质量稳定,接口成熟,商业支持也更强。很多团队就是需要这种东西,花钱买省心。
但本地工具解决的是另一类焦虑。
比如你做的是内部培训视频、客户访谈素材、还没公开的产品 demo,甚至是有真人声纹的原始音频。你未必愿意把这些东西传到云端。再比如你只是个人创作者,每个月偶尔做几条视频,不想被订阅和额度绑住。
这时候本地优先就不是情怀,而是一种很实际的选择。
OmniVoice Studio 支持 CUDA、Apple Silicon 的 MPS、ROCm 和 CPU。README 里写的最低要求也不算离谱,8GB 内存,4GB VRAM 起步,没 GPU 也能跑,只是会慢一些。第一次运行会下载模型权重,大约 2.4GB 到 4GB,这个等待成本还是要接受。
所以我会把它推荐给两类人。
一类是想折腾本地 AI 音频工作流的人。你有机器,有耐心,想把视频配音、声音库、听写、批处理打通。
另一类是对隐私比较敏感的创作者。你不一定追求最快,但希望素材尽量不出本机。
怎么用,路径其实很清楚
README 里给了三条入口。
最简单的是桌面安装包,macOS、Windows、Linux 都有。下载之后启动,第一次会自动准备 Python 环境和模型。这个路径适合大多数普通用户,别先上来就源码编译,真的没必要。
第二条是 Docker。
如果你习惯容器,直接拉镜像,映射 3900 端口,数据挂到 volume 里。CPU 和 NVIDIA GPU 都支持。它默认只绑定本机 127.0.0.1,这点挺好,至少不会一启动就把一个没有鉴权的服务暴露到局域网。
第三条是源码启动。
git clone https://github.com/debpalash/OmniVoice-Studio.git
cd OmniVoice-Studio
bun install
bun run dev
跑起来之后,后端在 localhost:3900,前端在 localhost:3901。如果你要改代码、加自己的 TTS 引擎、接 MCP,这条路更合适。
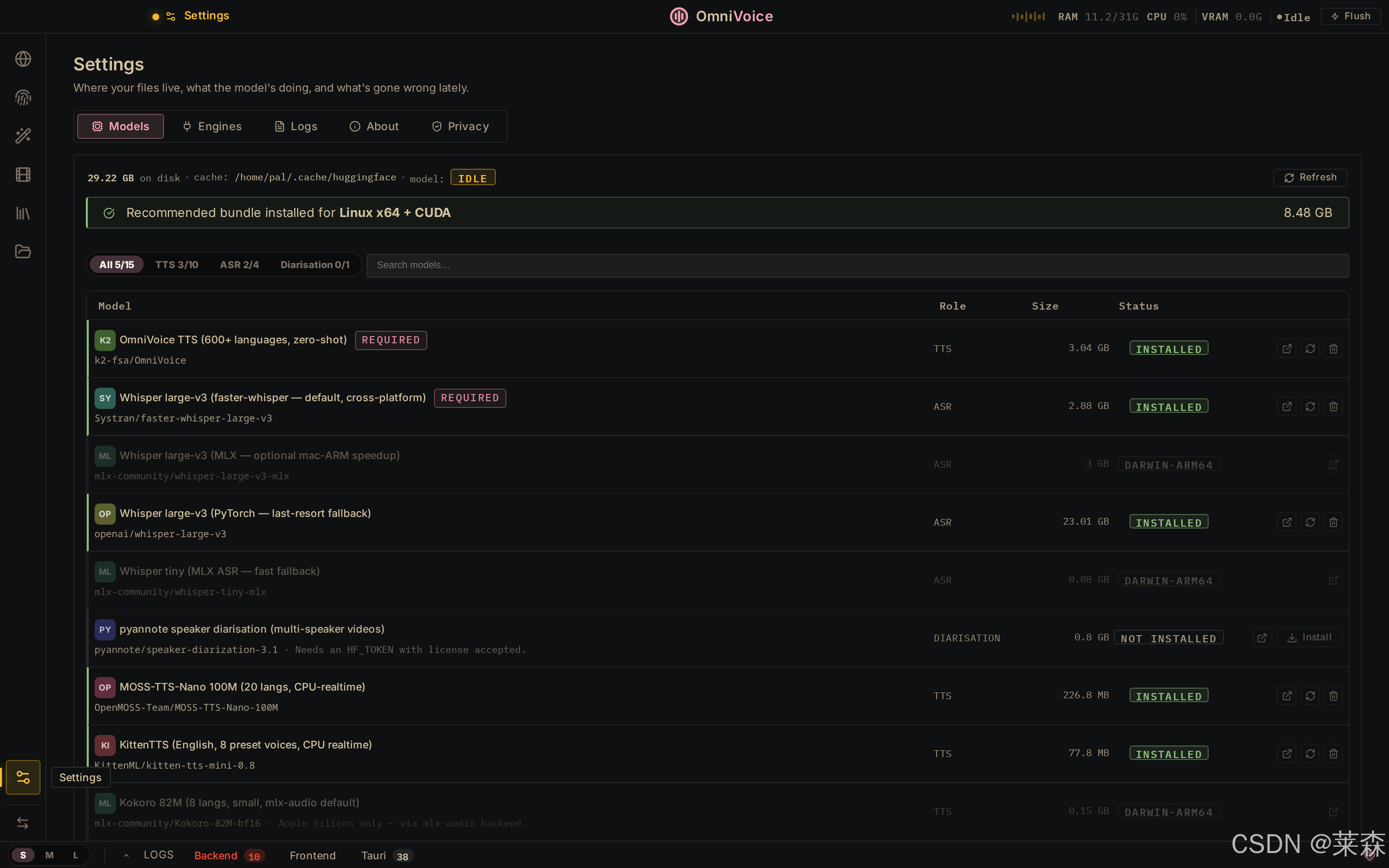
它还有一个挺工程化的点,TTS 后端是可插拔的。默认 OmniVoice,另外还列了 CosyVoice 3、MLX-Audio、VoxCPM2、MOSS-TTS-Nano、KittenTTS 等。README 里说,想加自己的引擎,大概就是继承一个 TTSBackend,再注册进去。
这就很适合开源社区继续长。
因为声音模型这块更新太快了。一个封闭产品很难同时追所有路线,但如果底层引擎能插拔,前端工作台就有机会变成稳定入口,后面的模型可以不断换。
但它还不是一个无脑神器
这块需要讲清楚。
OmniVoice Studio 现在仍然是 active beta。README 也提醒了,版本之间可能会坏,想要最新特性和修复,最好从源码运行。
这句话对普通用户来说很重要。
如果你期待的是打开网页、上传视频、五分钟后拿到商业级配音成片,那云服务可能还是更省心。如果你完全不想碰模型下载、依赖安装、显卡兼容、CPU 速度这些问题,本地工具也可能会让你烦。
另外,本地运行的真实体验很依赖机器。8GB 内存和 16GB 内存不是一个体验,CPU 和 8GB 以上显存的 GPU 也不是一个体验。README 里说 4GB VRAM 可以起步,8GB 以上更推荐,这个建议我觉得挺诚实。
所以它不是那种「所有人都该立刻迁移」的工具。
更准确的说法是,如果你愿意用一点折腾成本,换更强的本地控制权,它很值得看。
我真正期待的是创作方式的变化
过去我们聊 AI 配音,很容易只盯着声音像不像。
但对视频创作者来说,声音像只是第一层。更深一层是,这个工具能不能帮你把流程变短,把返工变少,把试错变便宜。
OmniVoice Studio 最让我感兴趣的,恰恰是它在往这件事上走。
声音克隆解决的是「像谁说」。
声音设计解决的是「用什么人设说」。
视频配音工作台解决的是「怎么把整条视频跑完」。
增量重配音和导演式控制解决的是「改起来别那么痛」。
这些能力加在一起,它才不只是一个 TTS demo,而开始像一个真正给创作者用的本地工作台。
我不知道它最后会不会成为所谓开源 ElevenLabs 替代品。这个判断现在下还太早。
但我很喜欢它代表的方向。
AI 音频工具不应该只停在模型页面里。它应该进入时间线,进入项目库,进入字幕和翻译,进入那些每天重复、琐碎、容易出错的创作细节里。
说真的,模型变强当然让人兴奋。
但工具终于开始理解人的工作流,这件事可能更让人兴奋。
希望它继续长好。
也希望我们每个人,都能少一点被流程折磨的时间,多一点真正创作的时间。
永远对世界保持好奇。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)