LangGraph调试攻略:从本地stream到生产LangSmith,揭秘AI Agent黑盒执行轨迹!
摘要: LangGraph的执行轨迹可通过本地调试(stream()和streamEvents())或云端追踪(LangSmith)查看。stream()提供节点粒度的状态更新,适合调试;streamEvents()暴露LLM调用的Prompt、Token及工具调用细节,便于排查问题。生产环境中,LangSmith自动记录全链路数据,支持事后回溯。关键点包括:优先检查Prompt构建问题,通过元数
01 执行轨迹的本质:Graph 到底把什么信息藏着了
一个 LangGraph Graph 运行一次,内部发生的事情可以抽象成这样一棵树:
- 节点名称:走了哪个分支(planner → executor,还是走了 tools?)
- 输入 State:进入节点时的完整状态
- 输出 Patch:这个节点改了哪些字段(注意是增量,不是全量)
- 耗时:哪个节点是性能瓶颈
但默认的 invoke() 调用只给你最终结果,中间那些全被吃掉了。
要「看见」执行轨迹,有两种路径:本地调试(stream + streamEvents)和云端追踪(LangSmith)。
调试工具选型一览:
| 工具 | 适用场景 | 信息粒度 | 能否事后查 |
|---|---|---|---|
stream() |
本地开发,看节点粒度 | 节点输入/输出 | ❌ |
streamEvents() |
本地开发,看 LLM 调用细节 | LLM Prompt/Token/工具调用 | ❌ |
| LangSmith | 生产环境,事后回溯 | 全链路,含 Prompt 原文 | ✅ |
| Checkpoint History | 有持久化时,时间旅行 | 每步完整 State 快照 | ✅ |
02 本地调试:stream + streamEvents 双剑合璧
LangGraph 的 stream() 不只是给流式输出用的,它是「执行轨迹的可观测接口」。
stream() 有两种模式:streamMode: "values"(每个 chunk 是当前完整 State,调试推荐)和 streamMode: "updates"(默认,每个 chunk 只有当前节点输出的增量 Patch,生产省流量)。
下面这个完整示例,把 Graph 搭建、stream 调试、路由决策日志全部整合在一起:
importStateGraphAnnotationSTARTENDfrom"@langchain/langgraph"importChatOpenAIfrom"@langchain/openai"importHumanMessageBaseMessagefrom"@langchain/core/messages"importfrom"@langchain/core/tools"importToolNodefrom"@langchain/langgraph/prebuilt"importfrom"zod"constChatStateAnnotationRootmessagesAnnotationBaseMessagereducerconsttoolasyncquerystring`搜索结果:${query} 的相关数据`name"search"description"搜索最新信息"schemaobjectquerystringconstconstnewChatOpenAImodel"gpt-4o-mini"bindTools// ⚠️ 路由函数:最容易出问题的地方,每次路由都打印决策依据// 条件边走错了不报错,会静默跑偏,必须主动把依据打出来functionshouldContinuestate: typeof ChatState.State"tools"typeofENDconstmessagesmessageslength1const"tool_calls"inArrayisArraytool_callstool_callslength0consolelog`🔀 路由 → type: ${lastMessage._getType()}, hasToolCalls: ${hasToolCalls}`ifconsolelog" tool_calls:"JSONstringifytool_callsnull2return"tools"returnENDconstnewStateGraphChatStateaddNode"agent"asyncmessagesawaitinvokemessagesaddNode"tools"newToolNodeaddEdgeSTART"agent"addConditionalEdges"agent""tools"ENDaddEdge"tools""agent"compile// 用 stream 替代 invoke,每个节点执行完都会 yield 一次// streamMode: "values" → 每个 chunk 是当前完整 State(调试推荐,一眼看全量)// streamMode: "updates" → 默认,每个 chunk 只有这步的 Patch(生产省流量)forawaitconstofawaitstreammessagesnewHumanMessage"帮我搜一下Q1销售数据"streamMode"values"constmessageslength0constmessages1consolelog`\n✅ State 更新 | messages: ${msgCount}条 | 最新: ${lastMsg?.content?.toString().slice(0, 80)}`
运行后你会看到:每个节点执行完后当前的完整 State 是什么,路由函数每次决策时走了哪条边,工具调用了没有。这比单纯看最终结果直观十倍。
03 streamEvents:看穿 LLM 调用的黑盒
光看节点粒度不够。80% 的问题出在节点内部——Prompt 传错了?Tool Call 没触发?
streamEvents 把节点内部每一次 LLM 调用的入参和出参全都暴露出来:
// streamEvents 的 version 必须写 "v2"forawaitconstofstreamEventsmessagesnewHumanMessage"帮我分析销售数据"version"v2"// LLM 调用开始:这里能看到完整 Prompt,是调试的第一个切入点// LLM 回答不对时,先看这里——80% 是 Prompt 构建有 bug,不是模型的问题ifevent"on_chat_model_start"consolelog`\n🔵 [${event.metadata?.langgraph_node}] LLM 调用开始`consolelog" 完整 Prompt:"JSONstringifydatainputmessagesslice2null2// LLM 调用结束:看回复内容和 Token 消耗ifevent"on_chat_model_end"constdataoutputusage_metadataconsolelog`🟢 LLM 调用结束 | 回复: ${event.data.output.content?.toString().slice(0, 100)}`consolelog` Token: prompt=${usage?.input_tokens} completion=${usage?.output_tokens}`// 工具调用入参和结果ifevent"on_tool_start"consolelog`\n🔧 工具 [${event.name}] 调用,入参:`JSONstringifydatainputifevent"on_tool_end"consolelog`✅ 工具 [${event.name}] 结果:`dataoutput
关键事件类型速查:
| 事件名 | 触发时机 | 最有用的字段 |
|---|---|---|
on_chat_model_start |
LLM 调用前 | data.input.messages(完整 Prompt) |
on_chat_model_end |
LLM 调用后 | data.output.content、usage_metadata |
on_tool_start |
工具调用前 | name、data.input |
on_tool_end |
工具调用后 | data.output |
on_chain_start |
节点开始 | metadata.langgraph_node(节点名) |
排查「答非所问」的标准动作:先开 streamEvents,找到对应节点的 on_chat_model_start,把完整 Prompt 打印出来看,绝大多数情况问题就在那里。
04 LangSmith:生产环境的「飞行记录仪」
本地调试靠 console.log 够用。但生产环境有个致命问题:你不可能一直盯着日志,用户遇到问题时你已经不在场了。
LangSmith 是 LangChain 官方的追踪服务,原理是:Graph 运行时每一步都被自动上报保存,出问题了打开后台回放。接入方式:
// ─── 第一步:.env 文件加 4 个变量,代码零改动 ───// LANGCHAIN_TRACING_V2=true// LANGCHAIN_API_KEY=your-key # smith.langchain.com 获取// LANGCHAIN_PROJECT=my-agent-prod # 建议按 dev/prod 分组// OPENAI_API_KEY=your-openai-key// ⚠️ 关键坑:dotenv.config() 必须在所有 LangChain import 之前// LangChain 初始化时会读取 env,如果 dotenv 在后面加载就晚了importasfrom"dotenv"config// 第一行importChatOpenAIfrom"@langchain/openai"// 之后再 import// ─── 第二步:调用时加 metadata 和 tags,方便事后检索 ───constawaitinvokemessagesnewHumanMessageconfigurablethread_idmetadatauser_id// 方便按用户筛选:找「用户xxx投诉的那次」session_id// 方便按会话筛选environment"production"// 区分 dev/prodtags"production""agent-v2"// ─── LangSmith Trace 树结构(后台看到的样子)───// Graph Run (root)// ├── agent(第一次)// │ └── ChatOpenAI// │ ├── Input: { messages: [用户输入] } ← 完整 Prompt 在这里// │ └── Output: { tool_calls: [search] }// ├── tools → search → 结果返回// └── agent(第二次)// └── ChatOpenAI// └── Output: { content: "根据数据分析..." }//// 定位问题三步法:// 1. 用 user_id/session_id 找到那次出问题的 run// 2. 展开 Trace 树,找第一个红色(失败)或异常耗时节点// 3. 点进去看 LLM 的输入 Prompt
LangSmith 没数据,八成是 dotenv 加载顺序错了——dotenv.config() 放在 LangChain import 之后,LangChain 初始化时还没读到 env,LangSmith 没被激活。
另一种常见情况:LANGCHAIN_PROJECT 留空,数据全堆进 “default”,找起来很混乱。建议用 my-agent-dev / my-agent-prod 明确命名。
05 Checkpoint 调试:时间旅行还原「事故现场」
如果 Graph 用了 Checkpoint,你还有超强调试能力:从任意历史节点重新执行。
生产场景:用户聊了 20 轮,第 15 轮出错了,总不能让他重来。找到出错前的 checkpoint,修复 State,从那里继续跑。
importMemorySaverfrom"@langchain/langgraph"importPostgresSaverfrom"@langchain/langgraph-checkpoint-postgres"// ⚠️ MemorySaver 只适合本地调试,生产必须用 PostgresSaver// MemorySaver 把所有 checkpoint 存内存,长时间跑必然撑爆constnewMemorySaver// 生产环境替换为:// const checkpointer = PostgresSaver.fromConnString(process.env.DATABASE_URL!);// await checkpointer.setup(); // 首次运行建表constcompileconstconfigurablethread_id"debug-session-001"// 跑一次,产生 checkpoint 历史awaitinvokemessagesnewHumanMessage"帮我分析一下销售数据"// 查看这个 thread 的全部 checkpoint(按时间倒序)forawaitconstofgetStateHistoryconsolelog`step: ${snapshot.metadata?.step}``| next: ${snapshot.next}``| messages: ${snapshot.values.messages?.length}条``| checkpoint_id: ${snapshot.config?.configurable?.checkpoint_id}`// 从某个 checkpoint 重新执行// 拿上面打印的 checkpoint_id,填进去,就能精确「回滚到那一刻」重新调试constawaitinvokenullconfigurablethread_id"debug-session-001"checkpoint_id"填入目标 checkpoint_id"consolelog"从断点恢复结果:"
getStateHistory 给你每个节点之间的完整 State 快照。找到出问题的那步,拿 checkpoint_id,精确「回滚到那一刻」重新调试。
06 常见坑:调试本身也有陷阱
坑1:stream 模式没看清楚。 updates(默认)只有 Patch,values 才是全量 State。调试时务必传 { streamMode: "values" },否则看到的 chunk 只有变化的字段,不是完整状态。
坑2:LangSmith 没数据。 九成九是 dotenv 加载顺序问题,见第 04 章。dotenv.config() 必须在所有 LangChain import 之前,这是最常见的接入坑。
坑3:MemorySaver 线上跑内存炸了。 MemorySaver 只适合本地,生产必须切 PostgresSaver(见第 05 章代码示例)。
坑4:streamEvents 里 metadata.langgraph_node 为空。 原因是 LLM 在 Graph 外部初始化,没被 Graph 上下文捕获。解决方法:把 LLM 调用移到节点函数内部执行,或确保所有 LLM 调用都在 Graph 的 invoke/stream 上下文链路上。
坑5:全量 LangSmith 追踪费用暴涨。 用采样率控制,只追踪 10% 的请求:设置 if (Math.random() < 0.1) process.env.LANGCHAIN_TRACING_V2 = "true"; else delete process.env.LANGCHAIN_TRACING_V2;,或者只在 catch 块里开启追踪,发生错误才上报。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
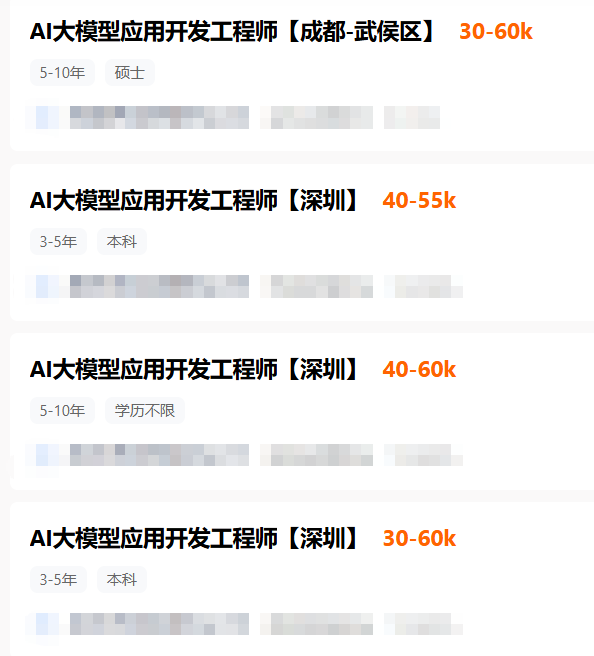
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 9
9 0
0- 0



 已为社区贡献130条内容
已为社区贡献130条内容

所有评论(0)