告别抓狂的Prompt!工程师必备的5层Agent架构开发套件(Claude Code实战)
文章提出5层Agent架构解决LLM应用问题:CLAUDE.md规则层固化规范,Skills知识层按需加载,Hooks质量层硬性约束,Subagents任务层隔离执行,Plugins团队层协作分发。配合MCP Servers扩展工具边界和Agent Teams横向协作,该架构通过基础设施而非Prompt优化确保Agent行为一致性,是生产级系统的必要设计。
文章指出,将架构规则全部压在Prompt上会导致效果差、上下文溢出等问题。Claude Code提出5层Agent Development Kit解决LLM自身无法处理的问题:CLAUDE.md规则层、Skills知识层、Hooks质量保障层、Subagents任务委托层、Plugins团队分发层。同时搭配MCP Servers扩展工具边界,Agent Teams实现横向协作。文章强调5层架构是生产级Agent系统的必要基础设施,而非可选功能增强,通过架构设计而非单纯优化Prompt可大幅提升Agent行为一致性。
一个让工程师抓狂的场景
你花了两个小时精心设计了一份 Prompt,Agent 跑起来了,效果不错。第二天重新开一个会话,它又开始乱来——删错文件、无视你的命名规范、在不该调工具的地方调了工具。
你能做的,只有继续往 Prompt 里加内容。
Prompt 越来越长,上下文越来越满,效果反而越来越差。
这不是模型的问题。是你把应该「架构」的事情,全部压在了「提示词」上。
Claude Code 给出了一套系统性答案:5 层 Agent Development Kit,每一层解决一个 LLM 本身解决不了的问题,而且 4 层跟 Prompt 没有任何关系。
全景架构:5 层 + 2 个外部系统
先建立整体的方位感:
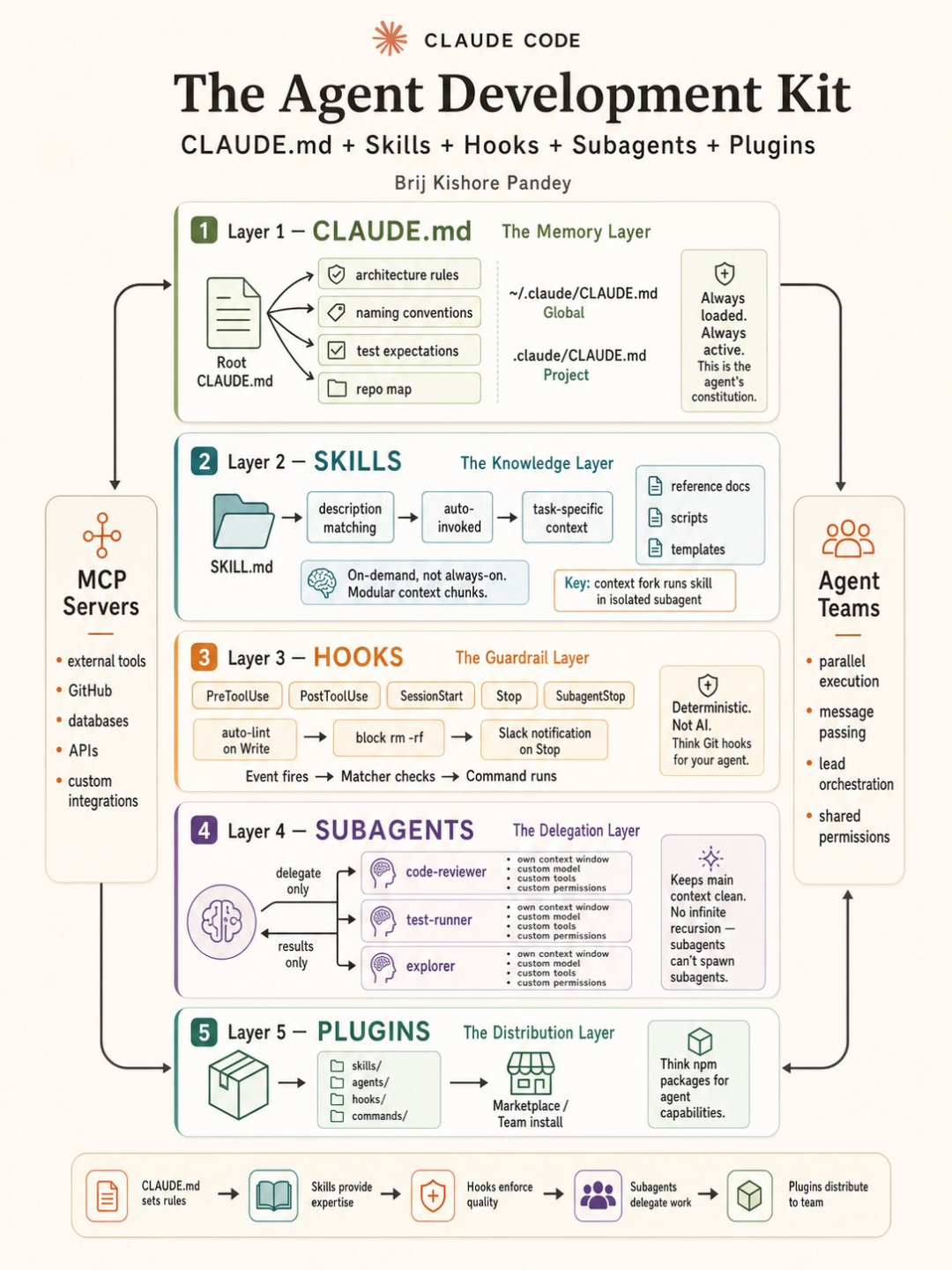
5 层架构用一句话串起来:
CLAUDE.md 设定规则 → Skills 提供专业知识 → Hooks 保障质量 → Subagents 分发任务 → Plugins 分发给团队
两侧的外部系统各有职责:
- • 左侧 MCP Servers:扩展工具边界,接入 GitHub、数据库、第三方 API、自定义集成
- • 右侧 Agent Teams:多 Agent 横向协作,并行执行、消息传递、共享权限
接下来逐层深挖。
Layer 1 — CLAUDE.md:记忆层
大多数工程师用 Claude Code 的第一反应是把规则加进 Prompt。加着加着,上下文窗口溢出,Agent 开始"选择性失忆"——它不是故意不听你的,而是 token 太多,早期的指令被稀释了。
核心问题:你把常驻知识当成了一次性输入。
CLAUDE.md 的职责就是解决这个问题——让 Agent 在每次会话开始时自动加载你的规则,无需重复输入。
它有两个作用域,分别对应不同的覆盖范围:
~/.claude/CLAUDE.md ← 全局(所有项目生效).claude/CLAUDE.md ← 项目(仅当前项目生效)
这个分层设计很有意思:个人的编码习惯和偏好放全局,团队共识和项目约定放项目级,互不干扰。
一个完整的项目级 CLAUDE.md 示例:
# 架构规则- 所有对外服务必须通过 API Gateway,禁止直接暴露内部 Service 接口- 数据库操作必须走 Repository 层,禁止在 Service 层直写 SQL- 禁止在代码里硬编码任何密钥、Token、IP 地址# 命名规范- 接口命名:IXxxService,实现类:XxxServiceImpl- 常量统一放在 constants/ 目录,按业务域分文件# 测试期望- 核心业务逻辑单测覆盖率 ≥ 80%- 所有外部 HTTP 调用必须有 Mock 测试,禁止直接调真实接口# 仓库地图- src/core/ → 核心域逻辑(业务规则在这里)- src/infra/ → 基础设施适配层(DB、MQ、外部 API 的具体实现)- src/interfaces/ → 对外接口层(Controller、DTO)
写一次,后续每个 Agent 会话自动遵守。不需要每次对话都说"注意,我们项目里不能直接写 SQL"。
工程价值:30 人的团队,如果把架构规范、命名约定、安全禁令都写进 CLAUDE.md,Agent 的行为一致性会有质的提升——不靠每个人的 Prompt 水平,靠基础设施约束。
这是 Agent 的「宪法」。始终加载,始终生效,任何会话都不例外。
Layer 2 — Skills:知识层
Layer 1 解决了「规则记忆」问题。Layer 2 解决的是「专业知识按需加载」问题。
不是所有知识都需要常驻内存。写后端代码时不需要前端组件规范,做 Code Review 时不需要数据库调优细节,做性能分析时不需要 API 设计指南。
把所有知识都塞进 CLAUDE.md 或系统 Prompt,后果是:上下文膨胀 → 关键推理能力下降 → Agent 开始「顾此失彼」。
解决方案:把知识按任务打包成 SKILL.md,按需触发,不污染主上下文窗口。
一个数据库优化 Skill 的结构示例:
---name: database-optimizerdescription: "当用户需要优化 SQL 查询、分析慢查询日志、设计数据库索引时使用此技能。 触发关键词:慢查询、索引优化、EXPLAIN、查询性能、N+1 问题"---# 数据库性能优化技能## 慢查询分析标准流程1. 用 EXPLAIN / EXPLAIN ANALYZE 分析执行计划2. 重点关注:type = ALL(全表扫描)、rows 估算值、Extra 中的 Using filesort3. 检查联表字段是否有索引4. 评估索引选择性:cardinality / total_rows > 0.1 才值得建索引## 常见反模式- 在 WHERE 子句的索引列上用函数:WHERE DATE(created_at) = '2024-01-01'(索引失效)- 隐式类型转换:WHERE user_id = '123'(user_id 是 int,字符串比较导致全表扫描)- 联表时 ON 条件字段类型不一致
关键机制:Claude 在运行时做 description 匹配,匹配到后将 Skill fork 到一个独立的子 Agent 运行,完成后结果返回主 Agent。
下面这张图说明了为什么要 fork 而不是直接加载:
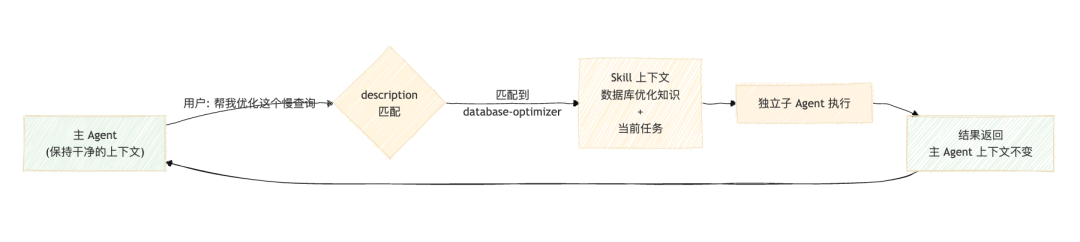
如果每个 Skill 都加载进主上下文,数据库优化、前端规范、API 文档、安全审计……一起堆进去,主 Agent 的推理质量会显著下降。
好的架构就是好的边界管理。Skill 是知识的边界单元,按需调用,用完即释放。
Layer 3 — Hooks:护栏层
这是整篇文章最重要的一层,也是被忽视最多的一层。
团队里 Agent 出问题,第一反应往往是「优化 Prompt,让 AI 记住不该做什么」。这是方向性错误。
有些质量保障不该靠 AI,该靠基础设施。把安全边界放进 Prompt,等于把防盗门钥匙放在门口的花盆下面。
Hooks 是事件驱动的确定性 Shell 命令,不是 AI,不会被模型的「理解偏差」影响,不会被上下文稀释。
支持 5 种事件类型:
| 事件 | 触发时机 | 典型用途 |
|---|---|---|
PreToolUse |
Agent 调用任何工具之前 | 危险命令拦截、权限预检 |
PostToolUse |
Agent 调用任何工具之后 | 代码 lint、格式检查、日志记录 |
SessionStart |
会话开始时 | 环境检查、变量注入 |
Stop |
Agent 完成任务停止时 | 通知推送、结果归档 |
SubagentStop |
子 Agent 完成时 | 子任务结果校验 |
执行逻辑是固定的三步,没有 AI 参与,完全可预测:
Event fires → Matcher checks → Command runs
三个典型场景配完整示例:
场景一:写 Python 文件后自动 lint
{ "hooks": { "PostToolUse": [ { "matcher": "tool_name == 'write_file' && file_path.endswith('.py')", "command": "ruff check ${file_path} --fix && ruff format ${file_path}" } ] }}
不管 Agent 生成的代码格式多乱,写完就自动修正。这不依赖 Agent「记住要格式化」,是硬性管道保障。
场景二:阻断危险的 rm -rf
{ "hooks": { "PreToolUse": [ { "matcher": "tool_name == 'bash' && command.contains('rm -rf')", "command": "echo 'BLOCKED: rm -rf is prohibited. Use trash-cli instead.' && exit 1" } ] }}
返回非零退出码,命令被直接 block,Agent 无法绕过。不管 Prompt 里写没写「不要删文件」,这条规则在基础设施层就生效了。
场景三:任务完成后推送 Slack 通知
{ "hooks": { "Stop": [ { "matcher": "*", "command": "curl -s -X POST $SLACK_WEBHOOK_URL -H 'Content-type: application/json' -d '{\"text\": \"Agent task completed in session ${session_id}\"}'" } ] }}
所有任务完成自动通知,不需要 Agent「记得」发通知,不会漏发。
Hooks 就是把 Git hooks 的思路移植到 Agent 系统里。质量不靠自觉,靠流程卡控。这是大多数团队跳过的一层,也是他们第一个后悔跳过的一层。
Layer 4 — Subagents:委托层
当任务足够复杂,单个 Agent 会遇到两个瓶颈:上下文窗口被撑满,以及并行任务的串行执行效率问题。
Subagents 的设计很干净:
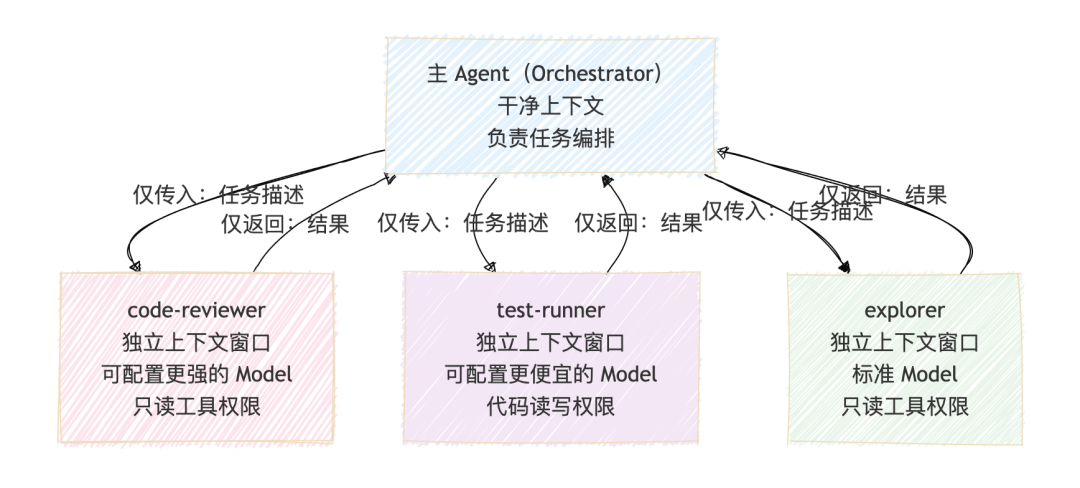
每个 Subagent 完全隔离:
- • 独立上下文窗口:互不污染,主 Agent 始终保持干净
- • 独立 Model:code-reviewer 用更强的模型,test-runner 用更便宜的,按任务选型
- • 独立工具集:最小权限原则,explorer 只需要读权限,writer 才给写权限
- • 独立权限管控:细粒度控制,防止权限扩散
有一个关键的硬性约束:Subagents 不能再 spawn Subagents,禁止无限递归。
这是有意为之的架构决策,不是技术限制。无限递归的后果是:
- • 上下文链路失控膨胀
- • 任务追踪无法管理
- • 错误传播链在哪里断裂变得不可预测
树形委托结构,而非无限深度递归,是生产级 Agent 系统的必要约束。能力边界清晰,才是可维护的系统。
一个真实的任务分解场景:
用户:帮我 review 这个 PR,写测试,然后提 MR主 Agent 分解: ├── 派遣 explorer → 读取代码结构,返回代码摘要(只读权限) ├── 派遣 code-reviewer → 基于摘要做 Review,返回问题列表(只读权限) ├── 派遣 test-runner → 根据问题列表生成测试用例(写权限,仅限 test/ 目录) └── 派遣 git-agent → 基于以上结果提 MR(git 操作权限)
每个子 Agent 只需要自己那块的上下文,主 Agent 的上下文始终干净,不随任务复杂度膨胀。
Layer 5 — Plugins:分发层
前 4 层解决的都是单个 Agent 或单台机器的问题。第 5 层解决的是团队协作问题。
假设你花了一周时间配好了:
- • 覆盖架构规范的 CLAUDE.md
- • 5 个专业 Skill(数据库优化、API 设计、安全审计……)
- • 覆盖所有危险场景的 Hooks
- • 合理分工的 Subagent 配置
你的同事想用同样的配置——他能复制你的文件结构,但无法复制你一周的调试过程。口头同步更不可能保证一致性。
Plugin 就是把这一切打包成一个可安装的能力单元。一次安装,整个团队继承所有行为。
Plugin 的目录结构:
backend-team-plugin/├── skills/│ ├── database-optimizer.md ← 数据库优化专业知识│ ├── api-designer.md ← API 设计规范与最佳实践│ └── security-auditor.md ← 安全审计检查清单├── agents/│ ├── code-reviewer.json ← 预配置的 Code Review 子 Agent│ └── test-generator.json ← 预配置的测试生成子 Agent├── hooks/│ ├── auto-lint.json ← 自动 lint 规则│ └── danger-block.json ← 危险命令拦截规则└── commands/ └── deploy-check.sh ← 自定义部署检查命令
类比:就像 npm 包管理一样,但管理的不是代码依赖,是 Agent 的能力依赖。
团队开发后端服务,发布 backend-team-plugin,所有人安装后自动获得:
- • 统一架构规范(不再有人用 Agent 写出违反分层原则的代码)
- • 专业技能(数据库优化、安全审计无需每人自己配置)
- • 防护规则(危险操作在基础设施层就被拦截)
- • 预配置子 Agent(不需要每人重复调试 code-reviewer 的参数)
能力的积累不再停留在个人 Prompt 里,沉淀成了可复用、可版本控制的团队基础设施。
MCP Servers + Agent Teams:两侧的扩展点
架构图两侧的系统值得单独说明,它们和 5 层 Kit 是正交关系。
左侧:MCP Servers(工具层扩展)
Model Context Protocol 是 Claude 访问外部工具的标准协议。5 层架构定义的是 Agent 的内部能力,MCP 定义的是 Agent 连接外部世界的接口。
通过 MCP,Agent 可以直接操作真实的外部系统:
GitHub → 读写 PR、Issues、Review Comments,直接操作代码仓库数据库 → 执行 SQL 查询,读取 schema,分析慢查询日志Jira/Linear → 管理任务和工单,自动更新状态自定义 API → 任何你能包装成 MCP Server 的内部接口
不需要 Agent 通过 bash 脚本间接操作,MCP 是一等公民的工具接口。
右侧:Agent Teams(多 Agent 横向协作)
当单机 Agent 架构不够时,Agent Teams 提供了横向扩展能力。和 Subagents 的树形委托不同,Agent Teams 是网络化的对等协作:
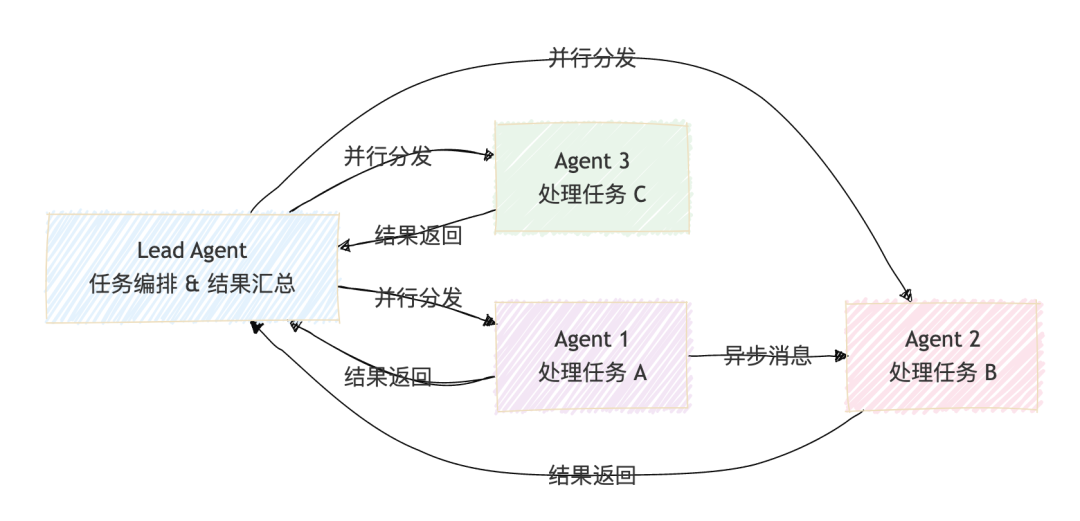
Agent Teams 的 4 个核心特性:
- • 并行执行:多 Agent 同时处理不同任务,不再串行等待
- • 消息传递:Agent 之间可以异步通信,A1 的中间结果可以传递给 A2
- • Lead 协调:Lead Agent 负责全局任务编排和最终结果汇总
- • 共享权限:团队级别的权限池,不需要每个 Agent 单独配置
哪一层是你系统里的缺口?
用一张图把 5 层定位总结清楚:
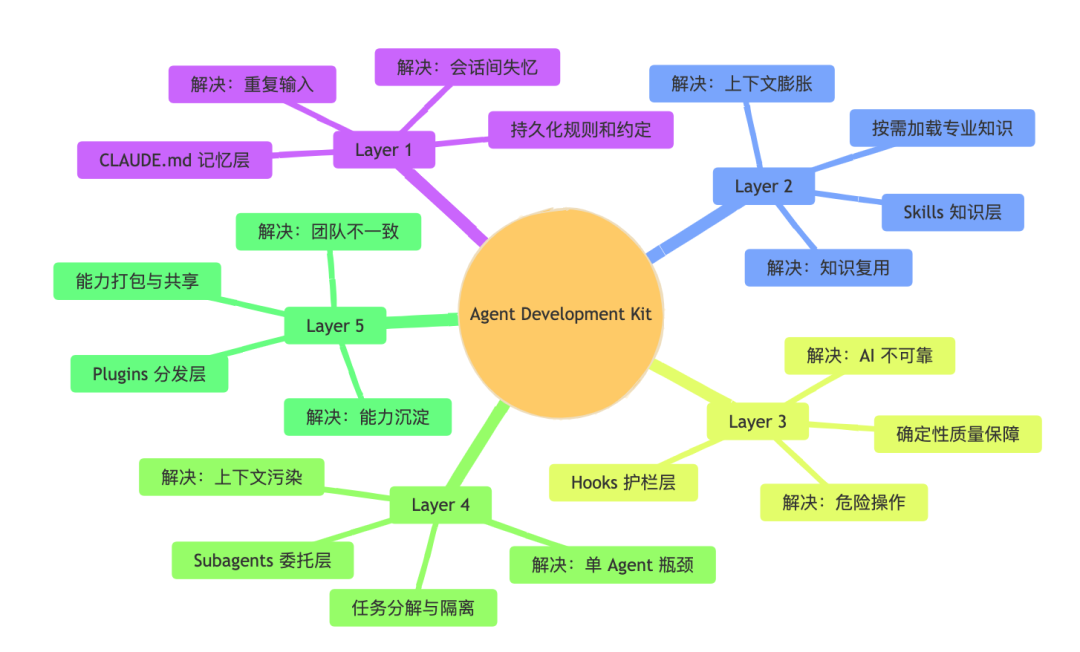
大多数工程师的 Agent 系统只有 Layer 1,甚至 Layer 1 也没有——规则直接粘在 Prompt 里,换个会话就清零。
生产级 Agent 系统的 90% 失控问题都可以追溯到某一层的缺失:
| 症状 | 根因 | 缺失的层 |
|---|---|---|
| Agent 乱删文件、执行危险命令 | 质量保障靠 Prompt,不靠基础设施 | Layer 3 Hooks |
| 不同工程师用 Agent 效果差异巨大 | 能力停留在个人 Prompt | Layer 5 Plugins |
| 上下文塞满后 Agent 开始犯低级错误 | 知识常驻,没有按需分配 | Layer 2 Skills |
| 复杂任务 Agent 开始互相干扰 | 缺乏任务隔离机制 | Layer 4 Subagents |
| 换个会话就忘记所有规则 | 规则是临时输入,不是持久配置 | Layer 1 CLAUDE.md |
5 层不是可选的功能增强,是生产级 Agent 系统的必要基础设施。把它们当 feature 一个个加,还是从第一天就按架构设计——这两条路三个月后的结果差距,远比你想象的大。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 10
10 0
0- 0



 已为社区贡献129条内容
已为社区贡献129条内容

所有评论(0)