转载--AI Agent 架构设计:工具数量的陷阱——5 个边界清楚的工具胜过 20 个模糊工具(OpenClaw、Claude Code、Hermes Agent 对比)
AI工具泛滥导致效率下降:演示中的全能助手在实际部署时因工具过多(134,000 Token的"工具税")而变慢变贵,决策质量降低。Anthropic建议控制在5-10个边界清晰的工具,并提出"工具搜索+按需加载"的解决方案。三大框架处理方式不同:ClaudeCode通过延迟加载最优,OpenClaw缺乏约束,Hermes采用任务激活制。核心结论:工具贵精不
一个典型的演示场景
演示里的 AI 助手看起来很强大。
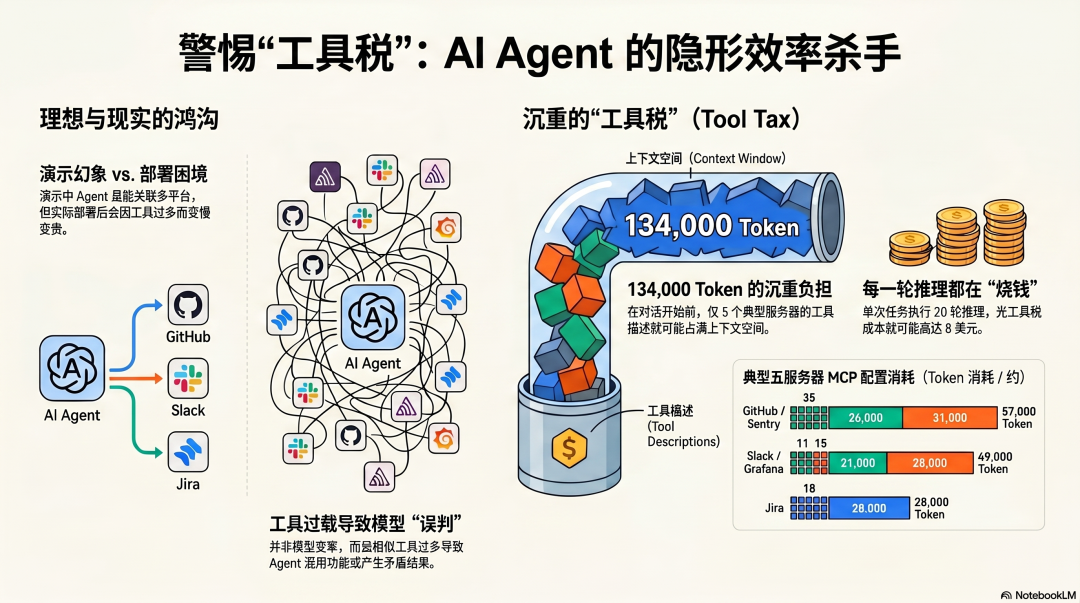
它连接了 GitHub、Slack、Sentry、Grafana、Jira、CI 系统、内部日志平台……你问"这次生产事故的根本原因是什么",它魔法般地拉取日志、关联 Issue、提出修复方案。
演示结束。你开始真正部署。
然后你发现:Agent 越来越慢,越来越贵,有时候明明该用 GitHub 的工具,它却去调了 Slack 的搜索,或者把两个功能相近的工具混用,产生了矛盾的结果。
这不是模型变笨了。是工具太多了。
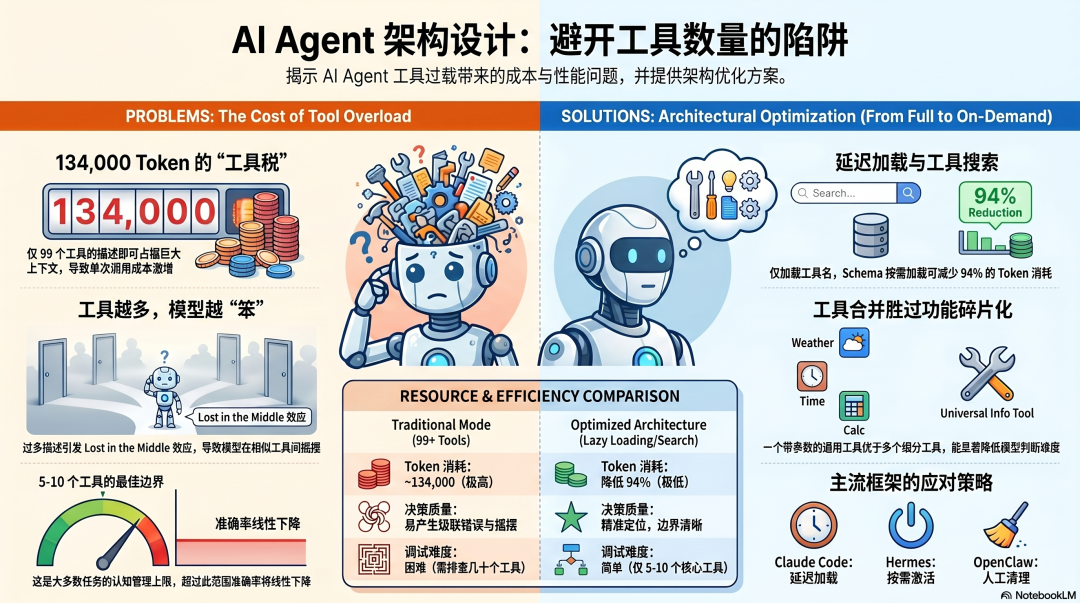
134,000 Token 的工具税
Anthropic 在工具设计指南里给出了一个让人警醒的计算:
一个典型的五服务器 MCP 配置:
GitHub → 35 个工具 → 约 26,000 TokenSlack → 11 个工具 → 约 21,000 TokenSentry → 20 个工具 → 约 31,000 TokenGrafana → 15 个工具 → 约 28,000 TokenJira → 18 个工具 → 约 28,000 Token
合计:99 个工具,约 134,000 Token。
对话还没开始,上下文窗口已经用掉了 134,000 Token——全是模型永远不会在当前任务里用到的工具描述。
按 Claude Sonnet 的定价计算,这 134,000 Token 每次调用成本约 0.4 美元。一个任务执行 20 轮推理,光工具税就是 8 美元,还没算实际的任务处理成本。
这不是夸张的极端案例。这是很多团队在做"大而全的 Agent 平台"时会真实踩到的坑。

工具太多,不只是贵,而是让 Agent 变笨
成本是可见的问题,更隐蔽的问题是:工具太多会系统性地降低 Agent 的决策质量。
有三个机制在同时发挥作用:
机制一:注意力被工具描述分散
上下文里有 134,000 Token 的工具描述,真正用于任务推理的注意力就相应减少。Lost in the Middle 问题(第二十一篇讲过的)在这里会特别严重——任务的关键约束被淹没在大量工具描述里。
机制二:相似工具导致决策摇摆
功能相近的工具,模型会在它们之间摇摆——这次用这个,下次用那个,结果不一致。
一个真实案例:Anthropic 在发布 Claude 的网页搜索工具时,发现模型会无缘无故地在搜索查询里加上"2025",导致搜索结果出现年份偏差,性能下降。根本原因不是模型能力问题,而是工具描述里没有明确说明什么时候不应该加年份约束。一个工具描述里的模糊,会系统性地出现在所有调用这个工具的任务里。
机制三:错误的工具选择会级联放大
一次错误的工具调用,其结果会注入上下文,影响后续的推理。工具越多,错误选择的概率越高,级联错误的风险越大。
Anthropic 给出的量化答案:工具上限在哪里
Anthropic 在工具设计指南里给出了明确建议:
5-10 个边界清楚的工具,是大多数任务的最优配置。
不是不能有更多工具,而是同时在上下文里出现的工具不应该超过这个范围。
超过这个范围之后:
-
工具选择的准确率开始下降
-
Token 成本线性增长,但任务完成质量不增长
-
调试变得困难——一个工具出问题,你需要在十几个工具里找原因
这个数字和另一个研究结论高度吻合:Google DeepMind 在多 Agent 研究里发现,超过一定规模之后,增加 Agent 数量开始产生负收益。工具和 Agent 的逻辑是一样的——超过认知管理上限,增加数量反而增加了混乱而不是能力。
解决方案:工具搜索,按需加载
工具太多的问题,Anthropic 在 2025 年底提出了一个架构级解法:Tool Search Tool(工具搜索工具)。
原理很简单:
❌ 旧模式:把所有工具定义一次性塞进上下文→ 99 个工具 → 134,000 Token → 模型淹没在工具描述里✅ 新模式:只放工具搜索工具,其他工具按需发现→ 1 个搜索工具 → 几百 Token → 需要某个工具时再加载
模型先调用工具搜索,找到相关的工具,再加载该工具的完整定义,然后执行。
一个社区的实测数据:三个 MCP 服务器(71 个工具,约 11,600 Token)使用工具搜索后,上下文中的工具 Token 消耗减少了 94%。
Claude Code 的 defer_loading: true 是同一个思路的实现——MCP 工具连接时只加载工具名称列表,完整 Schema 只在真正需要时才加载。这让 Claude Code 可以连接 200+ 工具而不撑爆上下文。
三个框架各自怎么处理工具数量问题
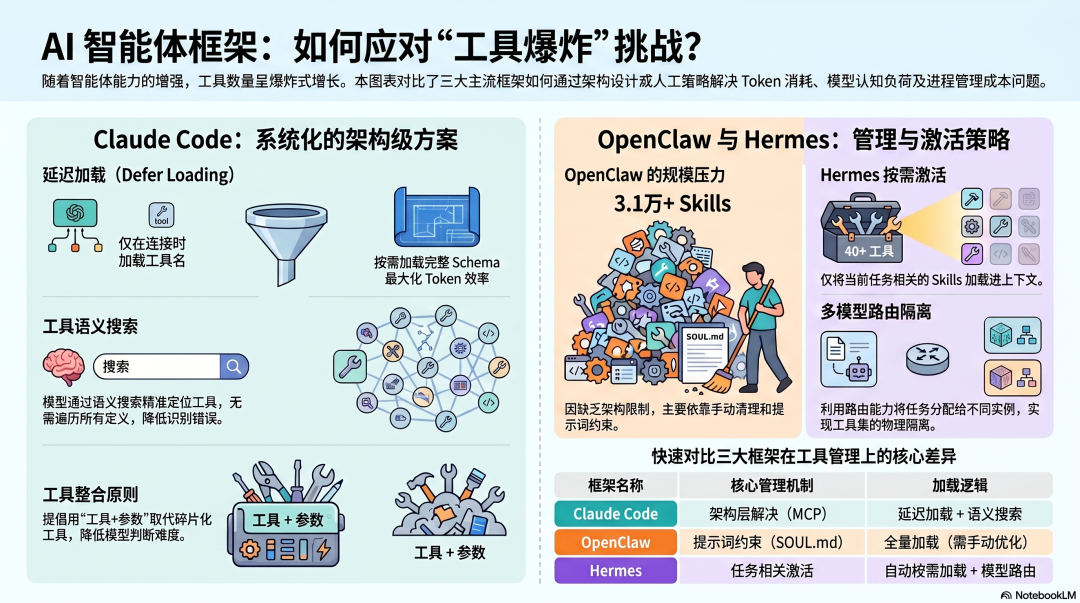
Claude Code:工具搜索 + 延迟加载,架构层解决
Claude Code 对工具数量问题有最系统的架构应对。
延迟加载(defer_loading):MCP 服务器连接时,默认只把工具名称列表加载进上下文,完整 Schema 按需加载。这是 Token 效率最高的方案——平时只花几百 Token 告诉模型"有哪些工具可用",用到时再加载完整定义。
Tool Search:语义搜索工具列表,模型不需要遍历所有工具,直接搜索相关工具,精准定位。
推荐的 MCP 服务器上限:官方建议 5-6 个活跃 MCP 服务器,不是技术限制,而是每个服务器启动一个子进程,超过这个范围进程管理成本开始显著增加。
Claude Code 在工具整合上也有明确原则:能合并的工具合并,不要为每个细分场景都创建单独的工具。
举一个具体例子:
❌ 碎片化:read_file_first_100_linesread_file_lines_100_to_200read_file_last_100_lines✅ 整合:read_file(start_line, end_line)# 一个工具处理所有场景,通过参数区分
碎片化工具让模型需要先判断"用哪个",整合工具让模型只需要判断"参数填什么"——后者对模型更友好,错误率更低。
OpenClaw:工具数量由 Skills 作者决定,质量参差不齐
OpenClaw 的工具扩展主要通过 ClawHub 的 Skills,ClawHub 上有 31,000+ 个 Skills,每个 Skill 可以定义和暴露工具。
问题在于:没有任何机制约束一个 Skill 能暴露多少工具,也没有任何机制控制总工具数量。
一个重度 OpenClaw 用户安装了 20 个 Skills,每个 Skill 暴露 5-10 个工具,轻松积累 100-200 个工具定义。全部加载进上下文,Token 消耗和认知混乱都会随之爆炸。
OpenClaw 目前没有类似 Claude Code 的延迟加载机制,也没有工具搜索功能。社区的补偿方案是建议用户在 SOUL.md 里明确指定"当前任务只使用哪些工具"——用提示词约束减少工具的激活数量。这是软约束,不是架构层面的解决。
安装 OpenClaw Skills 的实用建议:把功能相近的 Skills 合并,定期清理不再使用的 Skills,避免让不相关的工具同时出现在工作上下文里。
Hermes:40+ 内置工具 + 任务相关工具激活
Hermes 内置 40+ 工具,覆盖文件管理、浏览器自动化、终端执行、邮件日历等。
40 个工具听起来很多,但 Hermes 有一个重要的设计:Skills 按需加载。当前任务相关的 Skills 才被加载,不相关的 Skills 不进上下文。这意味着即使整个系统有大量工具,单次推理时上下文里的工具数量是受控的。
Hermes 通过 MCP 扩展外部工具时,和 OpenClaw 类似,没有原生的延迟加载机制。接入多个 MCP 服务器时,工具 Token 的管理主要靠配置层面的人工控制。
社区的实践建议:每个任务场景只激活必要的 MCP 服务器,不要把所有服务器同时保持连接。Hermes 的多模型路由能力在这里有一个意外的帮助——把不同工具集的任务路由给不同的 Agent 实例,每个实例只看它需要的工具。
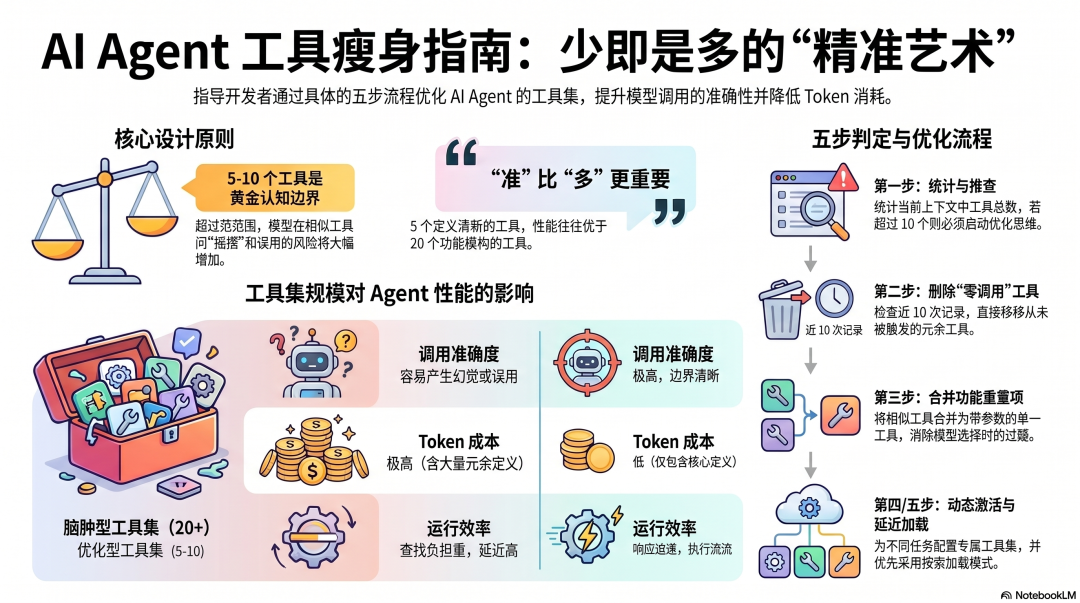
工具数量的实际判断标准
综合三个框架的实践和 Anthropic 的建议,给出一个具体的判断流程:
第一步:数当前上下文里有多少工具
打开一个真实任务,数上下文里同时存在多少个工具定义。超过 10 个,就需要思考是否可以减少。
第二步:找出没有被使用的工具
看最近 10 次任务的工具调用记录,哪些工具从来没有被调用?没有被用到的工具,是纯 Token 浪费,直接移除。
第三步:合并功能相近的工具
找到功能有重叠的工具对,考虑能否合并成一个有参数的工具。合并之后,既减少了工具数量,也消除了模型在相似工具之间摇摆的问题。
第四步:对剩下的工具,按当前任务启用
不是所有工具都需要在所有任务里可用。为不同的任务类型配置不同的工具集,任务开始时只激活相关工具。
第五步:考虑延迟加载
如果必须连接大量 MCP 服务器,优先使用支持延迟加载的框架和配置,让工具按需出现而不是全量预加载。
工具不是越多越好,是越准越好
一个外科医生做手术,手术台上摆着 200 种器械,不会让手术更顺利——找对器械的时间本身就成了负担。
Agent 也一样。
工具的价值不在数量,在于:模型在需要它的时候能准确找到它,在不需要它的时候不会误用它。 这个标准,5 个定义清晰的工具,往往比 20 个模糊的工具更容易达到。
Anthropic 的工具设计指南里有一句话直接点出了这件事:
"更多工具并不总是意味着更好的性能。开发者经常直接把已有的函数或 API 包装成工具,而没有考虑它是否真的适合 Agent 使用。"
适合 Agent 使用的工具,不是功能最全的工具,而是在 Agent 的认知边界内能被精准使用的工具。这个认知边界,目前大约在 5-10 个。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)