7 个实用技巧,让 Claude Code 的 Token 消耗暴降 80%
我之前开了 6 个 MCP Server:chrome-devtools、github、filesystem、brave-search、puppeteer、database。有一次用 /context 看了一下,
兄弟们,见字如面,我是阳哥。
最近有个学员跑来跟我吐槽:「阳哥,Claude Code 太香了,但账单也太香了——一天烧了 40 多刀,我差点以为信用卡被盗刷了。」
我让他把使用习惯说了一下:一个会话聊了 3 小时没清过上下文,提示词写得像写作文,MCP 服务器开了 6 个全挂在后台……我直接说:你这不是 Claude Code 贵,是你用得太「奢侈」了。
说实话,这确实是大多数人的状态。用 Claude Code 写代码,刚开始觉得便宜得像白嫖,聊着聊着账单就上去了。有人 7 美金能用 2 小时,有人 7 美金 20 分钟就没了——差距不在工具,在用法。
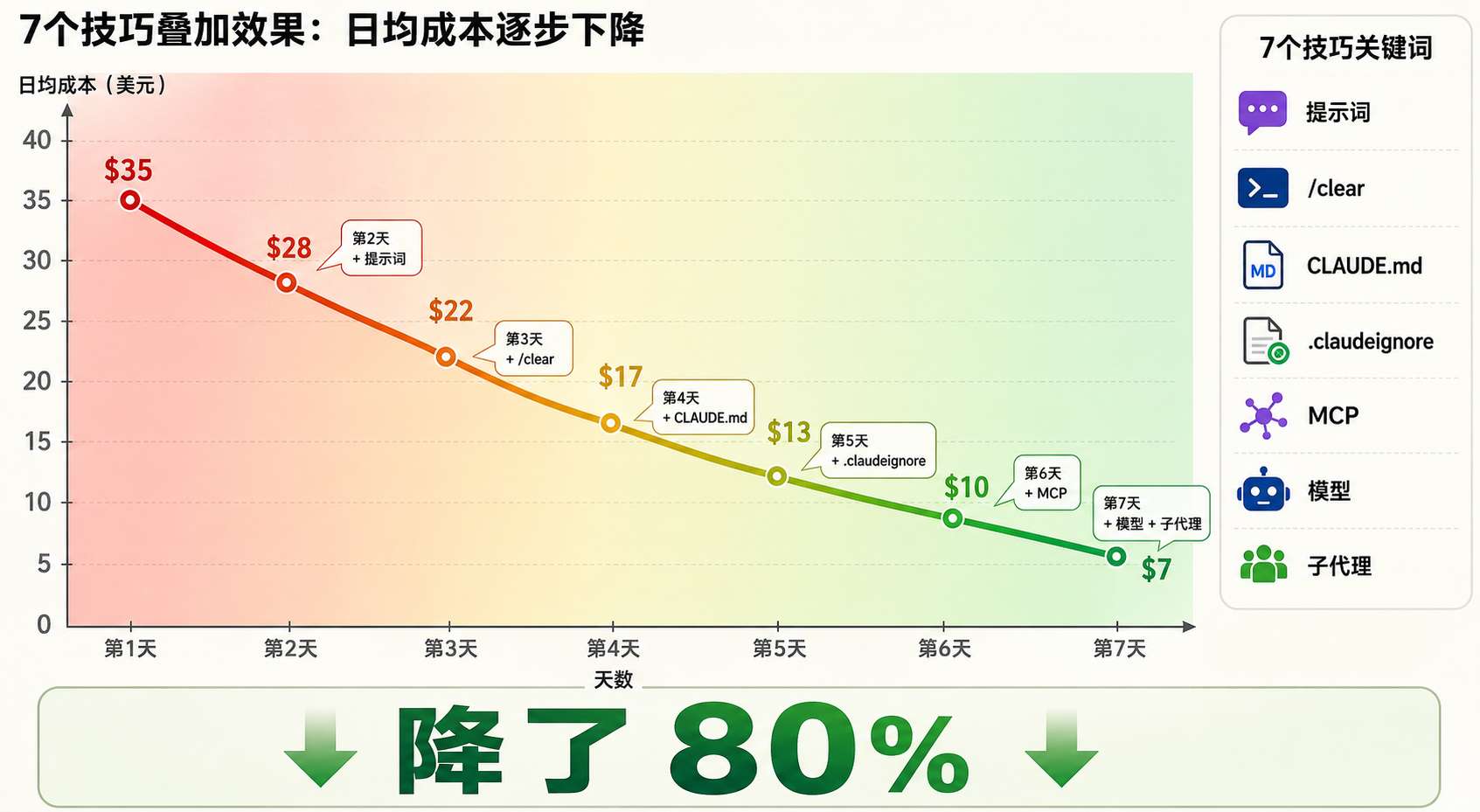
今天我把实测 200+ 小时踩出来的 7 个省 Token 技巧整理出来,每一条都是我自己验证过的,组合使用,Token 消耗降 80% 真不是吹的。
先搞懂一件事:你的 Token 花在哪了?
在讲技巧之前,你得先知道钱花在了哪儿。
Token 是 AI 的计价单位,你就当它是"燃料"——用多少烧多少钱。1000 Token 大约等于 750 个英文单词,或者 500 个汉字。一行代码大概 5 到 15 个 Token。
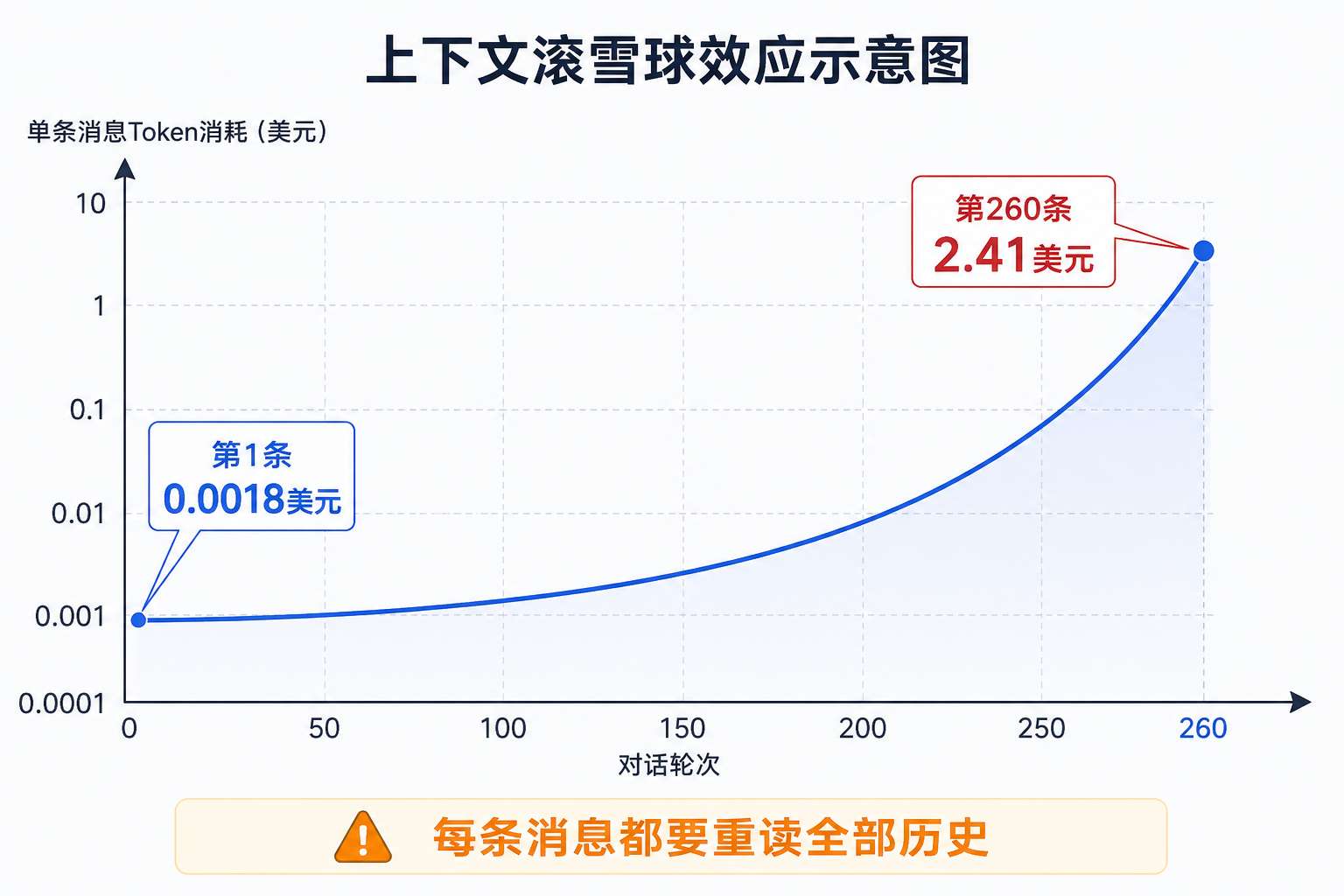
但关键不在于"一问一答花了多少",而在于一个隐藏的机制:上下文滚雪球。
每次你跟 Claude Code 对话,它都会把之前所有的聊天记录带上。你聊了 2 小时,发了 30 条消息,第 31 条哪怕只问了"改个颜色",Claude 读取的却是整个 2 小时的完整上下文。有人做过实测:同一个三词提问,第 1 条消息花费 0.0018 美元,到第 260 条消息,花费变成了 2.41 美元——1338 倍的差距,就因为上下文在滚雪球。
更扎心的是,输出 Token 的价格是输入的 5 倍。以 Claude Sonnet 4.5 为例,输入 3 美元/百万 Token,输出 15 美元/百万 Token。让 AI 说废话,是最昂贵的浪费。
搞懂了这个底层逻辑,后面 7 个技巧就很好理解了——说白了,都是在给上下文"减肥"。
技巧一:精准提示词——一句话干掉 80% 的探索开销
这是投入产出比最高的一个技巧,改一下提问方式,立竿见影。
很多人的习惯是这么问的:
帮我看看登录功能有什么问题
这句话在 Claude 看来等于:我不知道问题在哪,你帮我在整个项目里找找看。然后它就开始 Glob 扫目录、Grep 搜关键词、Read 读文件,一轮探索下来,消耗 15000 到 25000 Token,最后还可能理解偏了。
换一种写法:
查看 src/auth/login.ts 第 45 行,JWT 验证里 exp 字段没检查,加上过期时间校验,过期时抛 AuthExpiredError
同样的目的,Claude 只需要 Read 一次文件、Edit 一次代码,3000 到 5000 Token 搞定。省了 70% 到 80%。
我总结了一个公式,每次提问照着填就行:
做什么 + 在哪个文件 + 具体改什么 + 用什么方式
还有一个很多人忽略的招:告诉 Claude 不要做什么。主动限制行为范围,能大幅砍掉无用输出。
修改 login.ts 中的密码校验逻辑。不需要修改其他文件,不需要添加测试,不需要解释原理,直接给出修改后的代码。
一句"不需要解释",少则省 500 Token,多则省 2000 Token。一张表记住常用限制语:
| 限制语 | 效果 |
|---|---|
| 不需要解释 | 减少 500-2000 输出 Token |
| 只修改这个文件 | 避免 Claude 连带改其他文件 |
| 不需要写测试 | 省掉测试代码生成 |
| 简洁回复 | 整体输出减少 30%-50% |
| 不要读取其他文件 | 阻止不必要的文件读取 |
| 只看这个函数 | 避免读取整个文件 |
一句话原则:你给的信息越精准,Claude 浪费的 Token 越少。

技巧二:/compact 和 /clear——对话管理的黄金节奏
如果说技巧一是在"少花钱",那这个技巧就是在"及时止损"。
Claude Code 提供了两个关键命令:/compact 和 /clear。很多人要么不知道,要么想不起来用,结果上下文越滚越大,每一句话都在为之前的废话买单。
/compact 是有损压缩。它会把之前的对话历史压缩成一段摘要,从 25000 Token 压到 3000 Token 左右,节省 80% 以上。但压缩是有损的,一些细节可能丢失,所以你可以指定保留什么:
/compact 保留所有代码修改记录和文件路径,丢弃分析过程
什么时候用 /compact?我自己的节奏是:对话超过 5 轮、完成一个子任务准备开始下一个、或者感觉 Claude 响应变慢了——上下文太长会拖慢速度。
/clear 是彻底清空,直接归零。当你完全切换任务时用它,比如从项目 A 切到项目 B,或者从写功能切到修 Bug。
一个很多人踩的坑:一个会话用到底,从早聊到晚。上下文积累到 10 万 Token 以上,Claude 开始"失忆"——忘了最初的设定,开始重复甚至胡编。最后不得不回滚重来,前面花的 Token 全白费了。
我自己的习惯是:一个会话只解决一个独立任务。任务完成,/compact 或 /clear,绝不拖泥带水。
还有一个进阶用法:阶段性总结后重置。当你完成一个重要模块,对 Claude 说:"总结当前项目状态到 progress.md,然后我将开新会话继续。"关键信息沉淀到文件里,新会话通过 @progress.md 快速恢复认知,用极低 Token 实现无缝衔接。
一句话原则:每一条消息都在为整个上下文买单,及时清理就是省钱。

技巧三:CLAUDE.md 瘦身 + Skills 迁移——一次配置,永久省 Token
CLAUDE.md 是 Claude Code 的项目级记忆文件,放在项目根目录,Claude 每次启动都会自动读取。很多人把这个文件当成了"项目百科全书",什么都往里塞——技术栈、代码规范、目录结构、部署流程、常见问题……一个文件写了 3000 Token。
问题是:CLAUDE.md 里的每一个字,都会在每次对话时被读取。你写了 3000 Token 的背景介绍,等于每条消息都多花 3000 Token 的输入成本。聊 50 轮,就是 15 万 Token 的纯浪费。
怎么做?两步就够。
第一步:给 CLAUDE.md 瘦身。 只放最核心、最频繁使用的规则,比如项目技术栈、关键目录、禁止使用的技术。那些"偶尔会用到"的信息,别放进去。
第二步:把指令迁移到 Skills 里。 这是 Claude Code 官方推荐的做法。Skills 是一种按需加载的指令系统——只有当你触发特定任务时,对应的指令才会被加载到上下文里。不触发就不消耗。
举个实际例子。你之前在 CLAUDE.md 里写了 500 字的"代码审查规范",每次对话都带着。现在把它迁移到一个叫 code-review 的 Skill 里,只有你让 Claude 做代码审查时,这 500 字才会被读取。其他时候,零消耗。
Anthropic 官方文档明确说了:把 CLAUDE.md 里的指令迁移到 Skills,是减少 Token 消耗的推荐方式。 实测效果:CLAUDE.md 从 3000 Token 瘦到 500 Token,每次对话直接省 2500 输入 Token。
一句话原则:CLAUDE.md 只放高频规则,低频指令全扔进 Skills。
技巧四:.claudeignore——从源头掐断噪音
这个技巧太简单了,但用的人少得离谱。
你的项目里,有多少文件是 Claude 永远不需要看的?node_modules、dist、build、.git、vendor、lock 文件、生成的 protobuf 代码、第三方 SDK……这些文件又大又没用,但 Claude Code 如果不告诉它,它就有可能去读。
.claudeignore 的作用和 .gitignore 一模一样——放在项目根目录,告诉 Claude Code 哪些文件和目录不需要关注。被忽略的文件不会被读取、不会被搜索、不会进入上下文。
一份实用的 .claudeignore 模板:
node_modules/
dist/
build/
.git/
vendor/
*.lock
*.min.js
*.min.css
*.map
*.pb.go
coverage/
__pycache__/
效果有多明显?拿一个中型前端项目来说,node_modules 加上 dist 和 lock 文件,可能有几万个文件、数百万 Token 的内容。加上 .claudeignore 之后,Claude Code 的"视野"瞬间干净了,搜索代码更快,读取文件更精准,上下文污染大幅降低。
一句话原则:不让 Claude 看垃圾,它就不会花 Token 读垃圾。
技巧五:MCP Server 按需开关——每个工具都在偷你的 Token
这个坑我踩过,而且踩得很疼。
MCP(Model Context Protocol)服务器是 Claude Code 的插件系统,可以连接浏览器、数据库、GitHub、搜索引擎等外部工具。很强大,但有一个隐藏代价:每个 MCP Server 的工具定义,都会在每次对话时被加载到系统提示词里。
我之前开了 6 个 MCP Server:chrome-devtools、github、filesystem、brave-search、puppeteer、database。有一次用 /context 看了一下,MCP tools 占了 19200 Token——占了整个上下文的快 10%。而那次对话,我实际只用了 filesystem 一个工具。其他 5 个的 Token,纯纯浪费。
更离谱的是,chrome-devtools 一个服务器就占了 651 Token 的工具定义,但如果你做的是纯后端开发,它完全用不上。
怎么做?按需开关。
如果你当前任务只用文件系统,就只开 filesystem 这一个 MCP Server。做前端调试时再开 chrome-devtools,用完关掉。
Claude Code 最近还推出了 MCP-CLI 模式——工具定义不再全量加载到系统提示词里,而是按需获取。**这个功能可以把 MCP 相关的 Token 消耗降低 85%。**如果你的 Claude Code 版本支持,强烈建议开启。
另外,定期用 /context 命令看一下你的 MCP 工具占了多少 Token,心里有数才能对症下药。
一句话原则:不用的 MCP Server 就关掉,每个工具都在悄悄偷你的 Token。
技巧六:模型分层调用——别用大炮打蚊子
Claude Code 支持多个模型,不同模型的能力和价格天差地别。
以当前主流模型为例:Haiku 便宜快速,适合简单任务;Sonnet 能力和速度均衡,是日常开发的主力;Opus 最强最贵,适合复杂架构设计和深度推理。
很多人的习惯是全程用 Sonnet 甚至 Opus,不管什么任务都上最强的。改个 CSS 颜色用 Opus?那是用大炮打蚊子。
正确的做法是按任务复杂度选模型:
简单任务——改个变量名、修个拼写错误、格式化代码、写个简单函数——用 Haiku 就够了,成本是 Sonnet 的十分之一,速度还快。
日常开发——写功能、修 Bug、重构代码——用 Sonnet,性价比最高。
复杂推理——架构设计、技术选型、多系统联调——上 Opus,该花的时候不省。
在 Claude Code 里切换模型很简单,用 /model 命令就行。你也可以在 CLAUDE.md 里设置默认模型,日常开发默认用 Sonnet,需要的时候手动切。
还有一个小技巧:Extended Thinking(扩展思考)按需开启。这个功能让 Claude 在回答前进行深度推理,对复杂任务很有用,但会显著增加 Token 消耗——思考过程的 Token 也要算钱。简单任务别开,开了就是白烧钱。
一句话原则:杀鸡用鸡刀,杀牛用牛刀,别什么都上最贵的。
技巧七:子代理拆解大任务——主对话保持干净
这是 7 个技巧里最"高级"的一个,但一旦理解了,效果极其明显。
Claude Code 支持子代理(sub-agent),它们跑在独立的上下文里,完成阶段性工作后自动退出,不污染主对话。
什么意思呢?假设你在做一个大功能,需要先搜索整个代码库找到所有用到某个函数的地方,然后逐一修改。如果直接在主对话里做,搜索结果会塞满上下文,后面每条消息都带着这些"临时垃圾"。
换一种方式:把"搜索所有用到 x 的地方"这种一次性探索任务扔给子代理。它跑完给你一个精简的结果列表,然后退出。主对话的上下文保持干净,只留下你真正需要的信息。
哪些任务适合交给子代理?我总结了几类:
搜索探索类——在代码库里找所有引用、搜索特定模式、统计代码行数。这些任务会产生大量中间结果,但最终只需要一个摘要。
信息收集类——读取多个文件并汇总、分析项目依赖关系、检查配置一致性。读完就完了,不需要留在上下文里。
独立验证类——跑测试看结果、检查代码风格、验证构建是否成功。结果只有通过/不通过,不需要保留完整日志。
实测效果:一个复杂任务,直接在主对话做,上下文可能膨胀到 8 万 Token;用子代理拆解后,主对话始终控制在 3 万 Token 以内。
一句话原则:脏活累活交给子代理,主对话只留精华。
7 个技巧的叠加效应
这 7 个技巧是独立的、可叠加的。你不需要一口气全用上,先从最简单的提示词和 /clear 开始,效果立竿见影,再慢慢加上其他技巧就行。
最后给你一张速查表:
| 技巧 | 核心动作 | 预估节省 |
|---|---|---|
| 精准提示词 | 用公式写提示词 + 限制范围 | 单次请求省 70%-80% |
| /compact 和 /clear | 定期压缩和清空上下文 | 上下文省 50%-80% |
| CLAUDE.md 瘦身 | 只放高频规则,低频迁移到 Skills | 每次对话省 2000+ Token |
| .claudeignore | 排除无关文件和目录 | 避免数万 Token 的垃圾读取 |
| MCP 按需开关 | 只开当前任务需要的 MCP Server | MCP Token 省 50%-85% |
| 模型分层调用 | 简单用 Haiku,日常用 Sonnet,复杂用 Opus | 简单任务成本降 90% |
| 子代理拆解 | 搜索探索类任务交给子代理 | 主对话上下文省 60%+ |
省 Token 不是抠门,是让每一分钱都花在刀刃上。上下文越干净,Claude 的回答越精准。省钱和提效,从来都是一件事。
如果你也在用 Claude Code,试试这 7 个技巧,回来告诉我你省了多少。评论区聊聊你的省 Token 妙招,我会在评论区补充一些实测数据和更细节的配置方法。
关注我,后面还会出更多 AI 相关的实用技巧,咱们一起把 AI 编程的性价比拉满。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)