DeepSeek V4 VS GPT 5.5,开发者该怎么选
两种注意力交替叠用,再加滑动窗口分支处理邻近 token 的细节依赖,效果是惊人的:100 万 token 场景下,V4-Pro 的单 token 推理 FLOPs 只有 V3.2 的 27%,KV 缓存用量只有 10%。V4-Flash 输出价格不到 GPT-5.5 Pro 的千分之二,V4-Pro 也仅为后者的约 1/7。真正拉开差距的不是某个单项 benchmark,而是各自擅长的场景切片—

4 月 24 日,OpenAI 发布 GPT-5.5,DeepSeek 发布 V4。两份技术报告几乎同时出现在开发者时间线上,一个闭源一个开源,一个强调全能智能体一个强调架构效率。
这不是巧合。大模型竞赛已经从"谁更强"转向"谁更聪明地强"——比的是在更长的上下文里、用更少的算力、跑出更聪明的推理。
01
版本矩阵与基础能力
DeepSeek V4 分为两个版本。
V4-Pro 总参数 1.6 万亿,激活参数 49B;
V4-Flash 总参数 2840 亿,激活参数 13B。
两个版本都支持 100 万 token 上下文和 384K 最大输出,同时提供 Non-think 直出、Think High 常规深度思考、Think Max 榨取上限三档推理强度。
1.6 万亿参数是上一代 V3.2(6600 亿)的 2.4 倍,但激活参数只从 37B 增加到 49B。模型内部设有上千个专家节点,每次推理只激活约 3% 的核心参数,其余 97% 处于静默。这样规模的模型,单次训练成本被控制在约 558 万美元,同级别通常过亿。

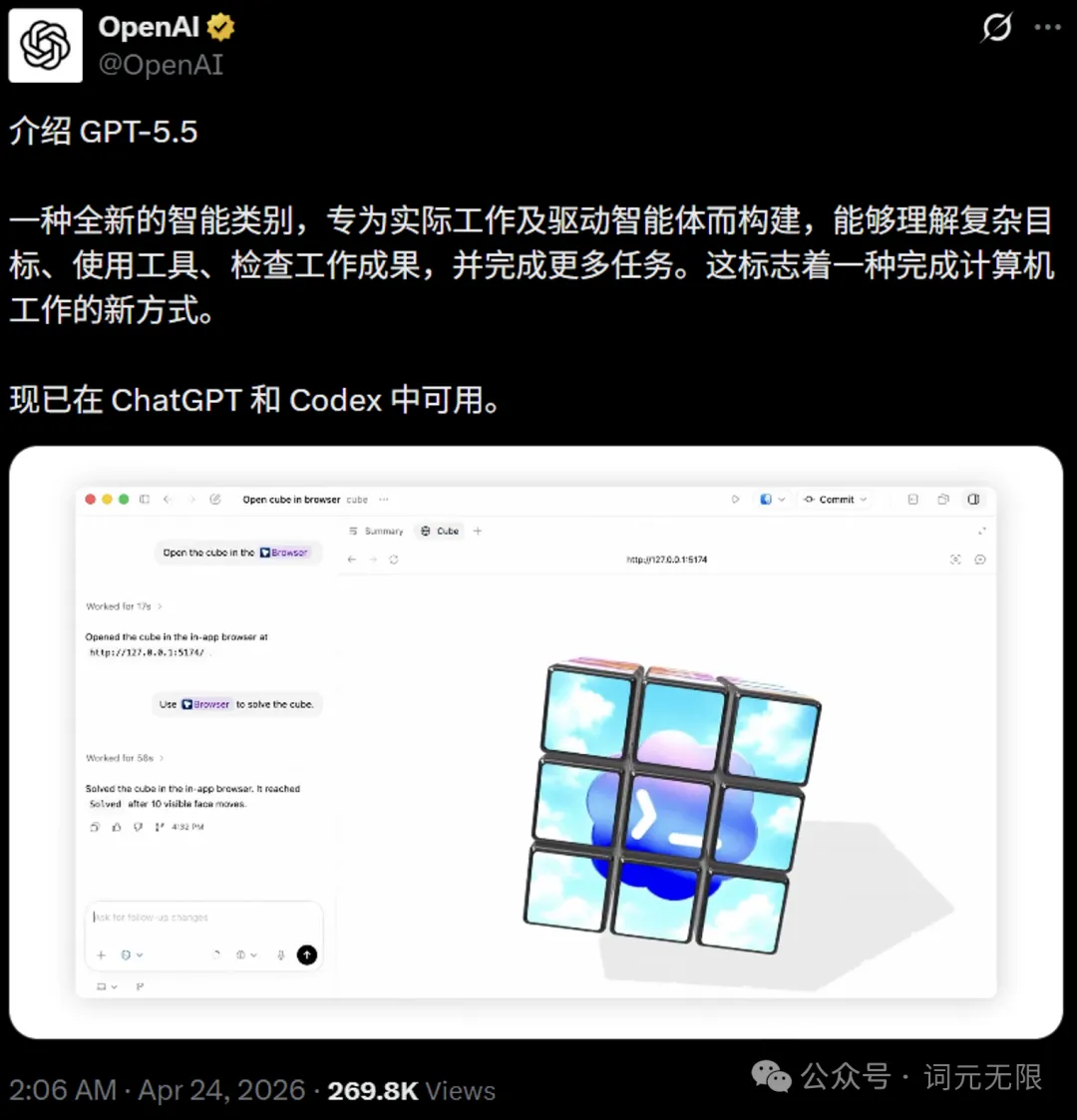
GPT-5.5 的内部代号是"Spud",距离 GPT-5.4 发布仅七周。它的核心定位不再是传统语言模型,而是"前沿智能体编码模型"(Frontier Agentic Coding Model)。
模型不再只是给出更聪明的回答,而是能在复杂任务中自主规划、调用工具、检查结果并持续推进。
API 定价输入 $5/百万 token、输出 $30/百万 token,Pro 版输入 $30、输出 $180,对比 GPT-5.4 翻了一倍。
OpenAI 的逻辑是 token 使用效率大幅提升,部分任务消耗降至原来的 1/35。
DeepSeek V4 的定价则延续了"价格屠夫"路线。V4-Flash 输入 1 元/百万 token、输出 2 元;V4-Pro 输入 12 元、输出 24 元。V4-Flash 的输出价格约为 GPT-5.5 Pro 的千分之一点五。当前 Pro 版价格受限于高端算力产能,官方表示下半年昇腾 950 超节点批量部署后会大幅下调。
从版本策略上看,DeepSeek 给了开发者一个清晰的阶梯:Flash 追求极致性价比,Pro 追求能力上限。GPT-5.5 则用标准版和 Pro 版覆盖不同深度需求,但整体价位远高于 DeepSeek。
02
核心技术:两条路线,两种解法
两个模型最本质的差异,在于发力点不同。DeepSeek V4 从架构底层做效率创新,GPT-5.5 从产品形态做能力扩展。
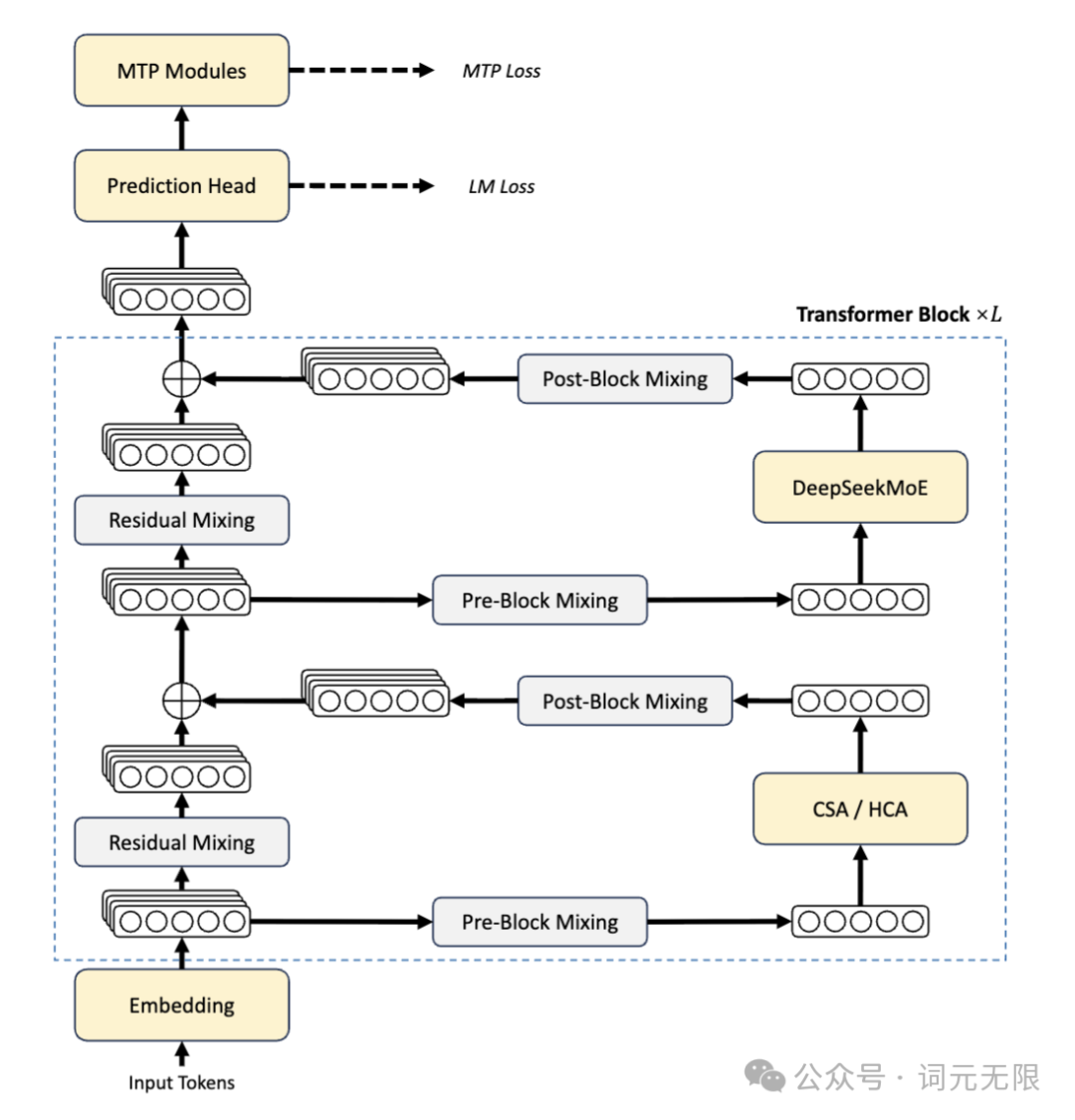
DeepSeek V4 最值得细读的创新在注意力机制。传统 Transformer 的自注意力计算量随序列长度平方增长,序列翻倍算力变四倍,100 万 token 在传统架构下几乎无法商业化。
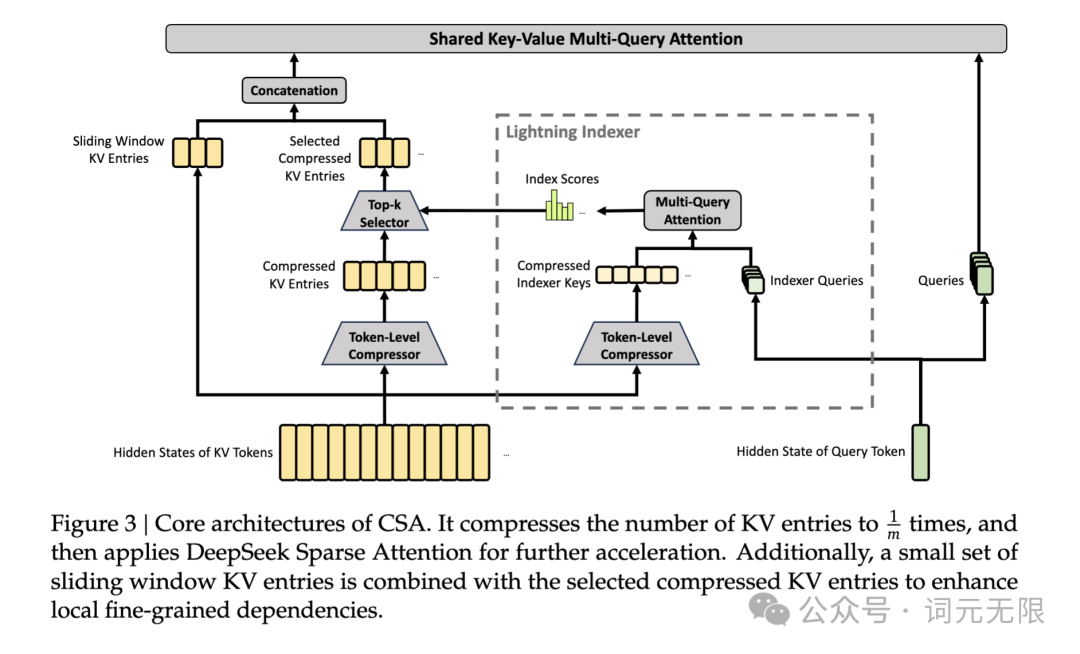
V4 的解法是把注意力拆成两种交替叠用。第一种 CSA(压缩稀疏注意力)先用轻量级索引器对所有 token 对做粗筛,每 4 个 token 的 KV 缓存合并成一条摘要,然后每个 query 只挑最相关的 top-k 条计算注意力。关键在于这个稀疏结构是可训练的——模型自己学出了哪里需要高密度注意力、哪里可以稀疏处理,不是人工规则。
第二种 HCA(重压缩注意力)在 V3 时代 MLA 的基础上继续推进,每 128 个 token 合并成一条,压缩率更激进,对剩余摘要做稠密注意力,同时把 KV 向量映射到低维潜空间推理时再解压。
两种注意力交替叠用,再加滑动窗口分支处理邻近 token 的细节依赖,效果是惊人的:100 万 token 场景下,V4-Pro 的单 token 推理 FLOPs 只有 V3.2 的 27%,KV 缓存用量只有 10%。V4-Flash 更极端,分别压到 10% 和 7%。叠加 FP4+FP8 混合精度,KV 缓存显存占用再砍一半,同等算力下长上下文并发量约为原来的 3 到 4 倍。
这不是简单的压缩。CSA 的可训练稀疏索引意味着模型通过梯度下降学会了"哪些上下文值得仔细看",HCA 的 128:1 压缩之所以不丢信息,是因为低维潜空间本身就是训练出来的。这套方案让百万上下文从实验室 demo 变成了可实际部署的产品能力。
训练层面,V4 也做了几件关键的事。优化器从业界默认的 AdamW 换成了 Muon——基于矩阵正交化更新,超大规模训练里收敛更快更稳定。残差连接加上了流形约束 mHC,专门解决 1.6T 参数超深度模型的跨层信号衰减。
后训练范式也换了思路。V3.2 用混合 RL 一次性优化多个目标,V4 换成"分化再统一":先针对数学、代码、Agent、指令跟随等不同领域各自训练专家模型,用 GRPO 做强化学习跑到最优;然后用 On-Policy Distillation 把多个专家合成回一个学生模型,通过 logit 级对齐吸收能力。工程难点在于同时加载多个万亿参数教师不现实,DeepSeek 把教师权重卸载到分布式存储,只缓存最后一层 hidden state,按教师索引排序样本,保证任意时刻显存里只驻留一个 teacher head。
GPT-5.5 的技术路线完全不同。它没有在 Transformer 基础架构上做大手术,而是在产品化层面做深度整合。四个方向是重点:编程领域,OpenAI 称其为"最强的 agentic coding model",Terminal-Bench 2.0 达到 82.7%,Expert-SWE 达到 73.1%;计算机使用上,结合 Codex 平台能理解屏幕内容、操作界面,支持 400K 上下文窗口;知识工作上,文档生成、表格建模、运营研究等任务表现优异,OpenAI 内部超过 85% 员工每周使用 Codex;科研领域,帮助发现了拉姆齐数的新数学证明并在 Lean 中完成验证。
GPT-5.5 还做了一件有意思的事:它和 Codex 参与了自身基础设施的优化,通过分析生产流量数据生成更优的负载均衡算法,token 生成速度提升超过 20%。这种"用模型优化模型"的闭环,是 OpenAI 在工程层面的差异化打法。
简单说,DeepSeek V4 回答的问题是"怎么用更少的算力做更多的事",GPT-5.5 回答的问题是"怎么让模型从聊天框变成任务引擎"。两个问题都重要,但解法完全不同。
03
实测表现:各有擅长,差距在缩小
官方 benchmark 只是一面,第三方实测和社区反馈是另一面。
DeepSeek V4 在数学与竞赛推理上表现突出。V4-Pro-Max 在 Codeforces 评分 3206,Apex Shortlist 90.2,均超过 GPT-5.4 xHigh 和 Gemini 3.1 Pro High。Agent 能力上 SWE Verified 80.6,与 Claude Opus 4.6 和 Gemini 3.1 Pro High 持平。长上下文召回准确率 97%。
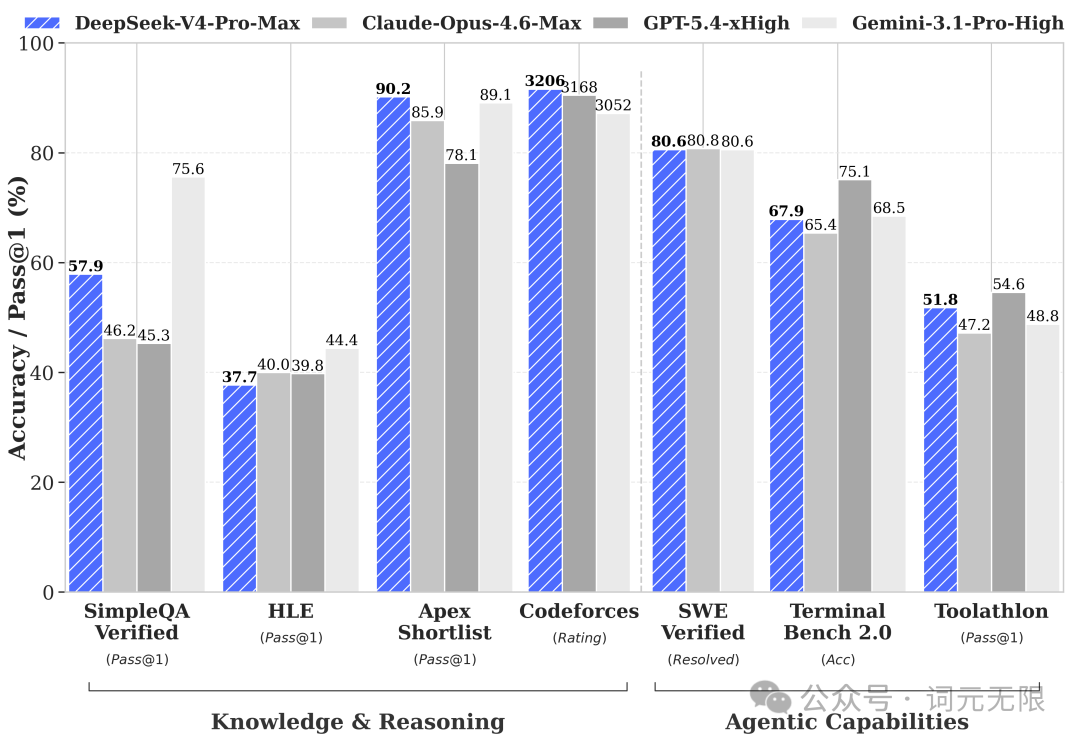
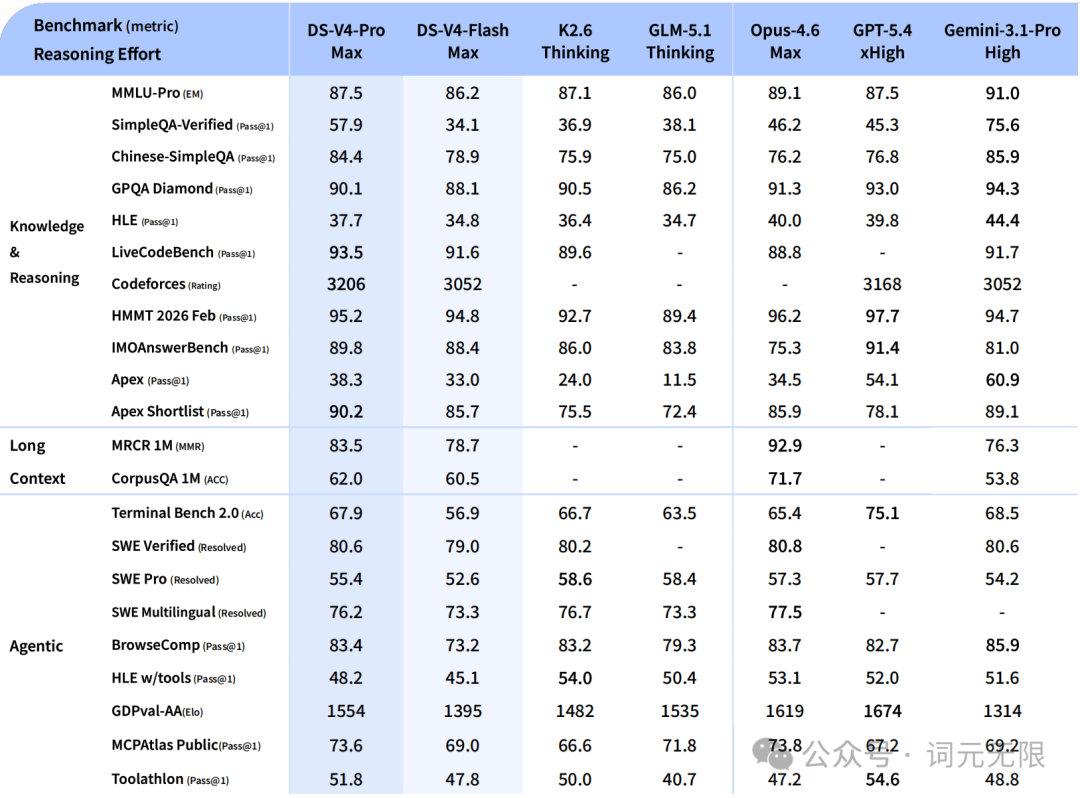
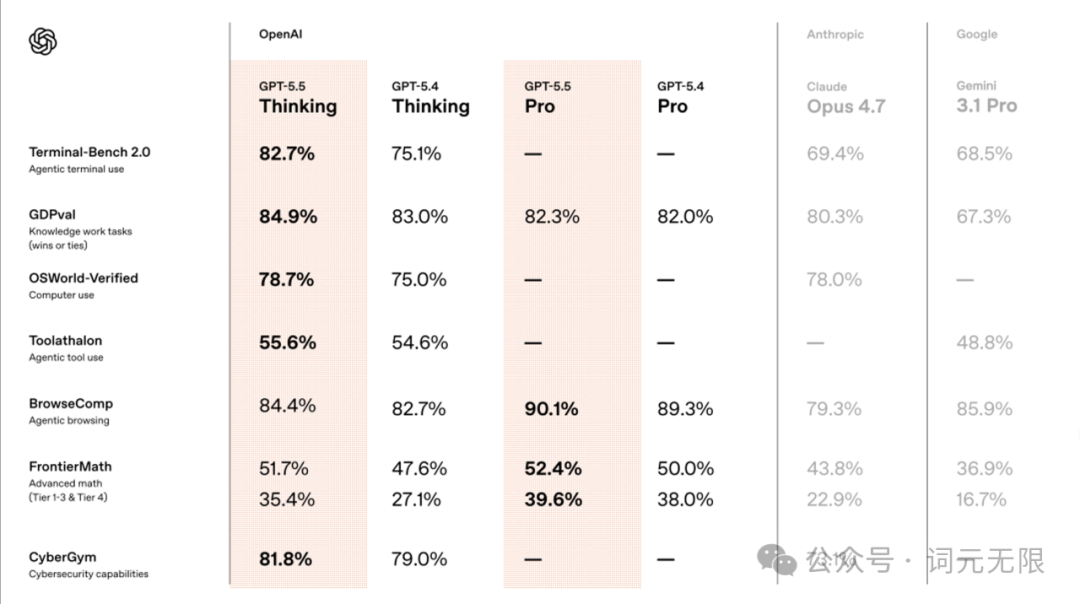
GPT-5.5 在 Terminal-Bench 2.0 上以 82.7% 领先,Expert-SWE 73.1%,GDPval 84.9%,OSWorld-Verified 78.7%。但在 SWE-Bench Pro 上,Claude Opus 4.7 仍以 64.3% 保持领先,GPT-5.5 为 58.6%,说明软件工程能力上各家各有擅长。
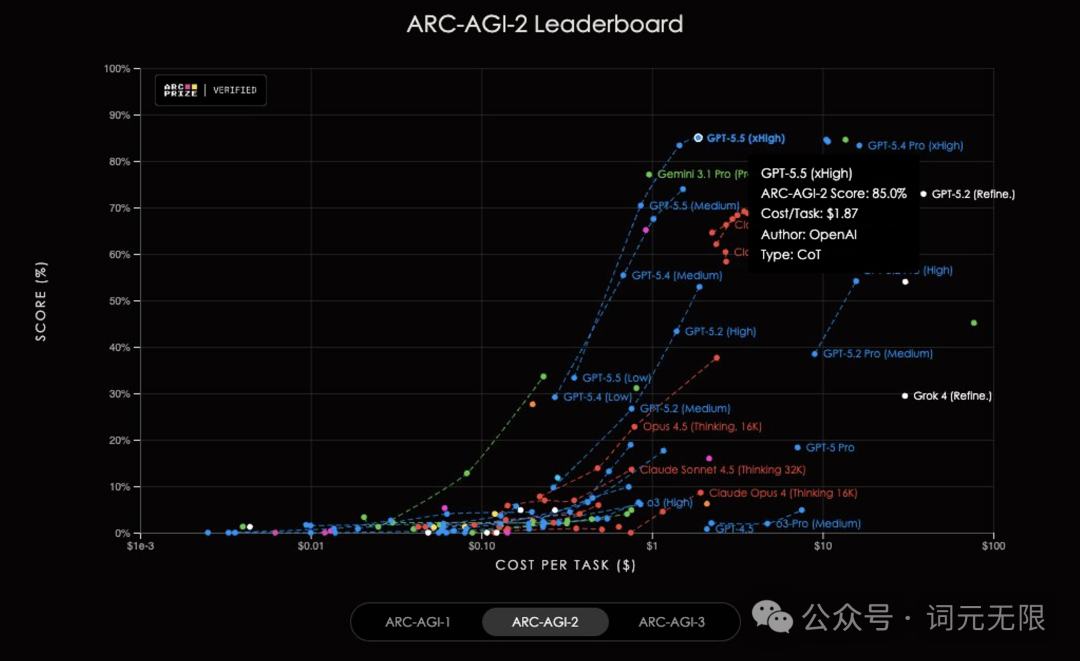
第三方榜单上的反馈也值得参考。arena.ai 榜单上 V4 文本能力位列第 20,编程能力位列第 14,国产最强是 GLM-5.1 排第 5。vals.ai 榜单上 V4 开源第一、全球第九,但跟前三分差还有距离。Linux.do 社区有评测认为 V4 Pro 表现甚至比 GLM-5.1 稍差,距离 TOP3 仍有差距。
DeepSeek 官方的内部评价也很诚实:V4 已成为员工 Agentic Coding 的主力模型,使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在差距。
通用知识问答和前沿科学推理是 V4 相对薄弱的环节。SimpleQA-Verified 57.9,HLE 37.7。GPT-5.5 在这些维度上目前仍有优势,FrontierMath Tier4(Pro 版)39.6%,BixBench 80.5%。
客观地说,两个模型在编程和 Agent 能力上的差距已经很小。真正拉开差距的不是某个单项 benchmark,而是各自擅长的场景切片——V4 在长上下文和成本效率上有压倒性优势,GPT-5.5 在任务自动化和工具链整合上更成熟。
04
开发者怎么选
选型取决于你在解决什么问题。
如果你的核心需求是处理超长文档、长代码库分析、或者需要百万 token 级别的上下文窗口,DeepSeek V4 在成本效率上有着压倒性优势。V4-Flash 输出价格不到 GPT-5.5 Pro 的千分之二,V4-Pro 也仅为后者的约 1/7。而且 CSA+HCA 架构让长上下文不再是"能用但贵得离谱",而是可以日常使用的标配能力。
如果你需要端到端的任务自动化——让模型自主操作电脑、完成多步骤工作流——GPT-5.5 配合 Codex 平台目前提供了更成熟的方案。400K 上下文窗口、计算机使用能力、85% 内部员工渗透率,这些产品化指标说明它已经过了"demo 阶段"。
如果你是研究团队或希望深度定制模型,DeepSeek V4 的 Apache 2.0 开源协议和 58 页技术报告提供了完整的二次开发基础。1.6 万亿参数的权重完整开源,Muon 优化器、mHC 残差连接、CSA/HCA 注意力架构等核心创新全部披露,任何团队都可以站在这些成果之上继续往前走。
如果你的业务对通用知识问答和前沿科学推理有极高要求,GPT-5.5 在这些维度上目前仍有优势。
还有一个容易被忽略的维度:国产算力适配。这是 DeepSeek 首次在正式技术文档中将华为昇腾与英伟达并列写入硬件验证清单。V4-Pro 在昇腾 950 上实现了 20ms 低时延推理,单卡 Decode 吞吐 4700TPS,MoE 专家权重采用 FP4 精度恰好是昇腾 950PR 的原生支持精度。寒武纪也完成了 Day 0 适配。对于有国产化需求的团队来说,这是一个实际的影响因子。
DeepSeek 在 V4 技术报告标题里用了"Towards"——“迈向高效百万 Token 上下文智能”。这个措辞很诚实,不是终点,是方向。GPT-5.5 同样展示了闭源路线的价值:当模型能力足够强时,产品化的深度和工具链的完整度可以成为真正的竞争壁垒。
4 月 24 日这一天,两个团队用各自的方式证明了一件事:大模型竞赛的下半场,比的不是谁堆的参数更多,而是谁用更聪明的方式让有限算力产出更大价值。对开发者来说,选择变多了,成本在下降,天花板还在不断被抬高。
DeepSeek 官方在发布时引用了《荀子·非十二子》的一句话:"不诱于誉,不恐于诽,率道而行,端然正己。"放在当下的大模型竞赛里,意外地贴切。
若您希望深入了解词元无限或希望了解 InfCode 如何为您的团队赋能,请扫码访问官网获取免费体验资格;或者添加客服微信,我们将会进一步为您提供详细说明。


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)