LangGraph 1.x 记忆存储实战:为什么 Agent 需要短记忆和长记忆?
很多人第一次写 Agent,都会遇到一个很典型的问题:在当前对话里,我刚告诉它“我叫小王,喜欢编程”,下一轮再问“我是谁”,它应该能接着回答;但如果我换一个新的会话线程,再问同样的问题,它还能不能记得我?
这里其实对应两种不同的记忆需求。
一种是短记忆:强调的是“当前会话”。只要还在同一个 `thread_id` 里,Agent 就应该能记住前几轮聊过什么。
另一种是长记忆:强调的是“账号维度”。只要还是同一个 `user_id`,哪怕切换了多个线程、开启了新的会话,Agent 仍然应该记得这个用户的长期信息,比如姓名、身份、偏好等。
所以,本文围绕一个问题展开:如何分别用短记忆解决当前会话上下文问题,再用长记忆解决同一账号下跨线程记忆的问题。一、为什么要分短记忆和长记忆?
先想一个客服场景。用户进入客服系统后,说:
我是小王同学,我是 VIP 用户,我喜欢详细一点的产品说明。
接下来可能发生两类问题。
第一类:当前会话里的上下文问题
用户刚说完这句话,下一轮问:
我刚刚说了什么?
这个问题只和“当前这段对话”有关。只要 Agent 能拿到前几轮消息,它就能回答。这就是短记忆要解决的问题。
短记忆的关键词是 thread_id。相同 thread_id 表示同一段对话,Agent 可以继续读取这段对话的历史;换一个 thread_id,就像重新开了一个新窗口。
第二类:跨会话的用户信息问题
过了几天,用户重新打开客服系统,开启了一个新的会话,然后问:
你还记得我是谁吗?我喜欢什么样的说明?
这个问题已经不只是当前会话上下文了,因为新的会话里并没有之前那句话。Agent 想回答出来,就必须从长期存储里查询这个用户的信息。这就是长记忆要解决的问题。
长记忆的关键词是 user_id。只要 user_id 不变,即使 thread_id 变了,Agent 也可以查到这个用户长期保存的信息。
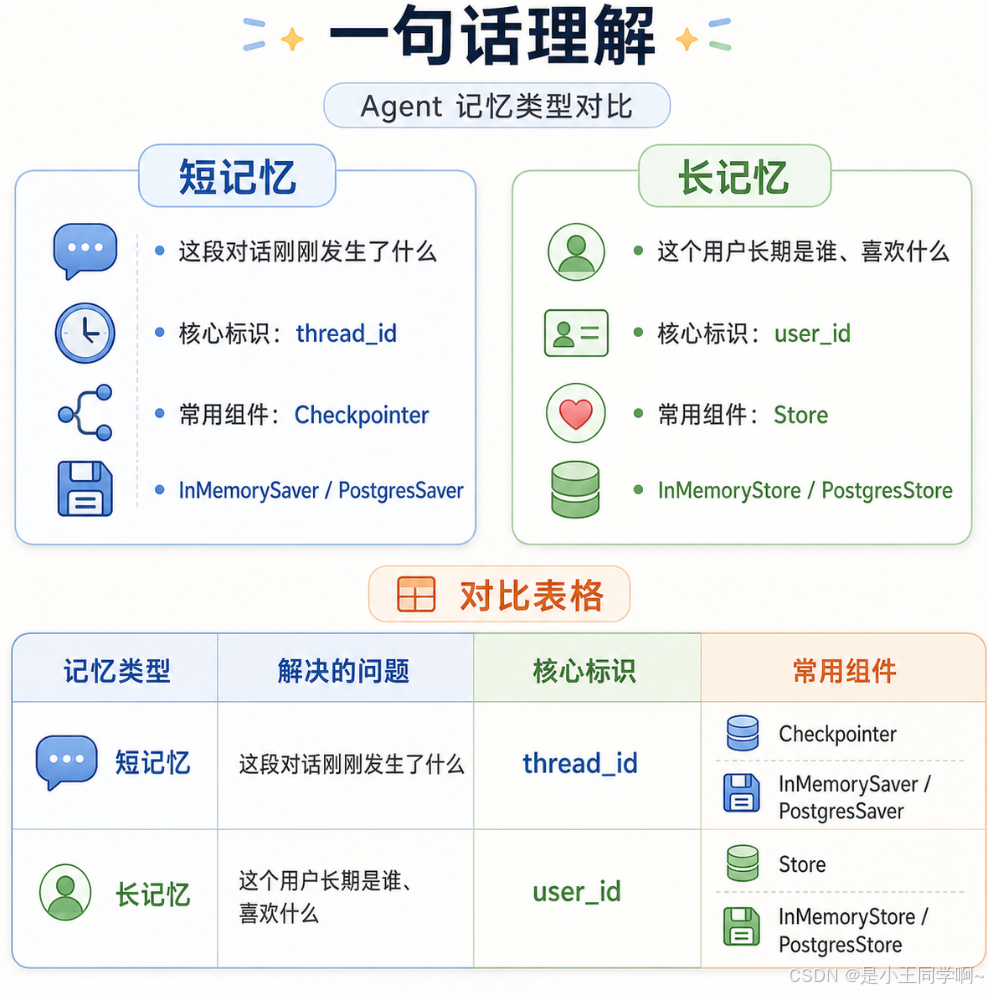
短记忆让对话连贯,长记忆让用户关系持续。
理解了这一点,后面的代码就很好看了:我们先用 Checkpointer 解决“当前会话记不住”的问题,再用 Store 解决“换个会话就忘了用户”的问题,最后把两者组合起来。
二、先用 InMemorySaver 做最简单的短记忆
先看最小版本:让 Agent 在同一个会话里记住用户刚刚说过的话。这里用 InMemorySaver,它把状态存在内存里,适合本地测试。
这段代码到底做了什么?
-
InMemorySaver 创建了一个短记忆存储。
-
create_agent 通过 checkpointer 读取和写入当前会话状态。
-
两次 invoke 使用同一个 thread_id,所以第二次能读到第一次的对话历史。
-
如果换一个 thread_id,Agent 就会把它当成新的会话。
实操结果

第一次告诉 Agent 用户信息,第二次询问“我是谁”,Agent 能根据同一个 thread_id 回答出来。
到这里,我们解决了第一个问题:同一段会话里,Agent 不再健忘。
三、为什么生产环境要换成 PostgresSaver?
InMemorySaver 很适合学习,但它有一个明显限制:进程一重启,内存里的会话状态就没了。
如果这是一个真实客服系统,就会出现问题:服务重启后,用户刚刚聊到一半的上下文全部丢失;多台服务同时部署时,不同实例之间也无法共享会话状态。
所以生产环境更推荐 PostgresSaver。它还是短记忆,解决的仍然是 thread_id 对应的当前会话状态,只是把状态持久化到了 PostgreSQL。
先启动 PostgreSQL
docker run -d \--name postgres \-p 5432:5432 \-e POSTGRES_USER=postgres \-e POSTGRES_PASSWORD=postgres \-e POSTGRES_DB=langchain_db \-e POSTGRES_HOST_AUTH_METHOD=trust \-v postgres_data:/var/lib/postgresql/data \postgres:15
运行下面这段代码需要安装的依赖:
pip install langgraph-checkpoint-postgres "psycopg[binary,pool]" langchain-openai langchain用 PostgresSaver 保存短记忆
import os
import sys
from urllib.parse import quote_plus
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.postgres import PostgresSaver
if hasattr(sys.stdout, "reconfigure"):
sys.stdout.reconfigure(encoding="utf-8")
# 验证 环境变量
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError("请先配置环境变量 DASHSCOPE_API_KEY")
# 配置 PostgreSQL 数据库连接
pg_user = os.getenv("PGUSER", "postgres")
pg_password = quote_plus(os.getenv("PGPASSWORD", "postgres"))
pg_host = os.getenv("PGHOST", "111111")
pg_port = os.getenv("PGPORT", "5432")
pg_database = os.getenv("PGDATABASE", "langchain_db")
DB_URI = f"postgresql://{pg_user}:{pg_password}@{pg_host}:{pg_port}/{pg_database}"
# 初始化 PostgreSQL 检查点
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
#自动创建 PostgreSQL 表结构
checkpointer.setup()
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.3
)
agent = create_agent(
model=model,
tools=[],
system_prompt="""
你是一个乐于助人的助手
""",
checkpointer=checkpointer
)
# 使用 同一个 会话id thread_id
config = {"configurable": {"thread_id": "user_123"}}
config2 = {"configurable": {"thread_id": "user_1234"}}
response1 = agent.invoke(
{"messages": [("user", "我是小王同学,喜欢编程")]},
config=config
)
print("助手:", response1["messages"][-1].content)
response2 = agent.invoke(
{"messages": [("user", "我刚刚说了什么")]},
config=config
)
print("助手:", response2["messages"][-1].content)
response3 = agent.invoke(
{"messages": [("user", "我是谁?我喜欢什么?")]},
config=config2
)
print("助手:", response3["messages"][-1].content)这里要观察什么?
-
response1 和 response2 使用同一个 thread_id,所以第二轮能记住第一轮。
-
response3 换了新的 thread_id,所以它不知道前面 user_123 会话里的内容。
-
这说明 PostgresSaver 解决的是“短记忆持久化”,不是“跨会话用户画像”。
实操结果:
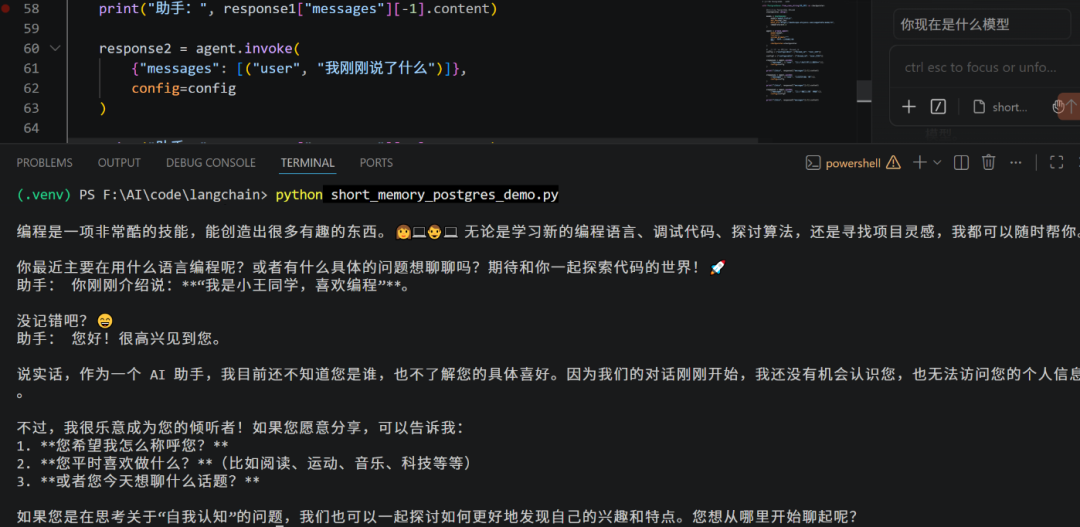
预期输出:
PostgresSaver 初始化成功
=== 第一轮对话 ===
助手: 你好呀,小王同学!👋 很高兴认识你!等等
=== 第二轮对话(相同 thread_id,模型应记住用户)===
助手: 你刚刚介绍说:“我是小王同学,喜欢编程”。等等
=== 第三轮对话(新 thread_id,模型会忘记之前的内容)===
助手: 您好!很高兴见到您。
说实话,作为一个 AI 助手,我目前还不知道您是谁,也不了解您的具体喜好。因为我们的对话刚刚开始,我还没有机会认识您,也无法访问您的个人信息。
pg中存储的数据:
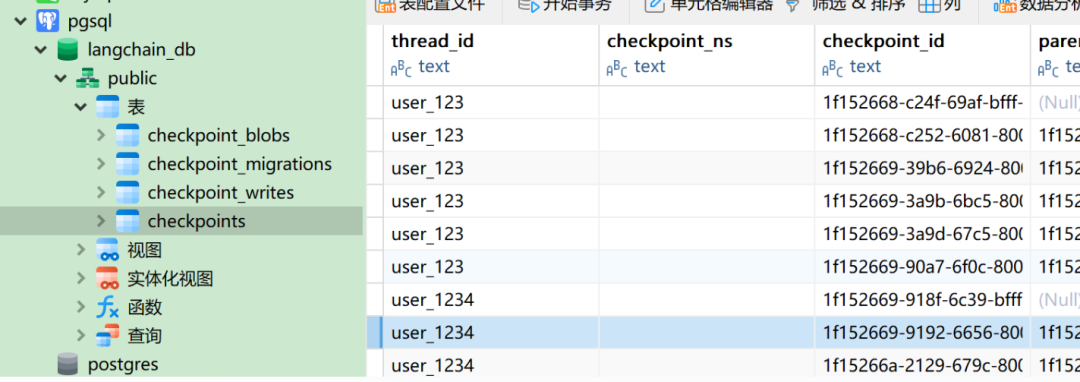
同一个 thread_id 能接上上下文,新的 thread_id 会变成全新会话。
到这里,我们已经把短记忆从内存版本升级到了生产可用版本。但还有一个问题没解决:新会话里,Agent 仍然不知道这个用户长期是谁。
四、用 Store 解决长记忆问题
接下来解决第二个问题:用户换了一个新会话,Agent 还能不能知道他的偏好?
这时就不能只依赖 thread_id 了。因为新会话的 thread_id 已经变了,短记忆里没有之前的上下文。我们需要把用户长期信息按照 user_id 存起来。
这就是 Store 的作用。它可以保存用户偏好、身份、配置等长期信息,后续任何会话都可以通过 user_id 查询。
Store 的实现类型
InMemoryStore:开发测试,数据存储在内存中,进程重启后丢失
PostgresStore:生产环境推荐,基于 PostgreSQL 持久化存储
运行下面这段代码需要安装的依赖:
pip install langchain==1.0.3 langgraph==1.0.2 langgraph-checkpoint-postgres==3.0.5 psycopg==3.3.3 langchain-openai==1.1.12 langchain-core==1.2.26 langchain-classic==1.0.3 langchain-community==0.3.29 langgraph-checkpoint==3.0.1 langgraph-prebuilt==1.0.2 langgraph-sdk==0.2.15 psycopg-pool==3.3.0 psycopg-binary==3.3.3# 验证 环境变量
import os
import sys
import uuid
from urllib.parse import quote_plus
from langchain.agents import create_agent
from langchain_core.runnables import RunnableConfig
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.postgres import PostgresStore
if hasattr(sys.stdout, "reconfigure"):
sys.stdout.reconfigure(encoding="utf-8")
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError("请先配置环境变量 DASHSCOPE_API_KEY")
# 配置 PostgreSQL 数据库连接
pg_user = os.getenv("PGUSER", "postgres")
pg_password = quote_plus(os.getenv("PGPASSWORD", "postgres"))
pg_host = os.getenv("PGHOST", "111111")
pg_port = os.getenv("PGPORT", "5432")
pg_database = os.getenv("PGDATABASE", "langchain_db")
DB_URI = f"postgresql://{pg_user}:{pg_password}@{pg_host}:{pg_port}/{pg_database}"
# 初始化 PostgreSQL 检查点
with PostgresStore.from_conn_string(DB_URI) as store:
#自动创建 PostgreSQL 表结构
store.setup()
# 定义工具
# 保存
@tool
def save_user_preference(key: str, value: str,config: RunnableConfig) -> str:
"""保存用户的偏好到长记忆"""
user_id = config["configurable"]["user_id"]
#创建命名空间
namespace = ("user_preferences", user_id)
item_id=str(uuid.uuid4())
store.put(namespace, item_id, {"key": key, "value": value})
return f"已保存用户偏好 {key}: {value}"
# 读取
@tool
def get_all_user_preferences(config: RunnableConfig) -> str:
"""获取用户所有的偏好设置"""
user_id = config["configurable"]["user_id"]
namespace = ("user_preferences", user_id)
items = store.search(namespace)
preferences = []
for item in items:
key = item.value.get("key","未知")
value = item.value.get("value", "未知")
preferences.append(f"{key}: {value}")
return "\n".join(preferences) if preferences else "没有找到偏好设置"
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.3
)
checkpointer = InMemorySaver()
agent = create_agent(
model=model,
tools=[save_user_preference,get_all_user_preferences],
system_prompt="""
你是一个乐于助人的助手
可以使用工具 保存和查询用户的 偏好
""",
#短记忆
checkpointer=checkpointer,
#长记忆
store=store
)
# 使用 同一个 会话id thread_id
config = {"configurable": {"user_id":"user_001","thread_id": "user_123"}}
config2 = {"configurable": {"user_id":"user_001","thread_id": "user_1234"}}
response1 = agent.invoke(
{"messages": [("user", "我是小王同学,喜欢可爱的回答,请帮我记住这个偏好")]},
config=config
)
print("助手:", response1["messages"][-1].content)
response2 = agent.invoke(
{"messages": [("user", "我刚刚说了什么")]},
config=config
)
print("助手:", response2["messages"][-1].content)
response3 = agent.invoke(
{"messages": [("user", "我是谁?我有什么偏好?")]},
config=config2
)
print("助手:", response3["messages"][-1].content)这段代码怎么实现长记忆?
-
save_user_preference 是写入工具,负责把用户偏好保存到 Store。
-
get_all_user_preferences 是读取工具,负责从 Store 查询用户偏好。
-
namespace = ('user_preferences', user_id) 用来把不同用户的数据隔离开。
-
config 和 config2 的 thread_id 不同,但 user_id 相同,所以新会话依然能查到同一个用户的长期偏好。
实操结果:
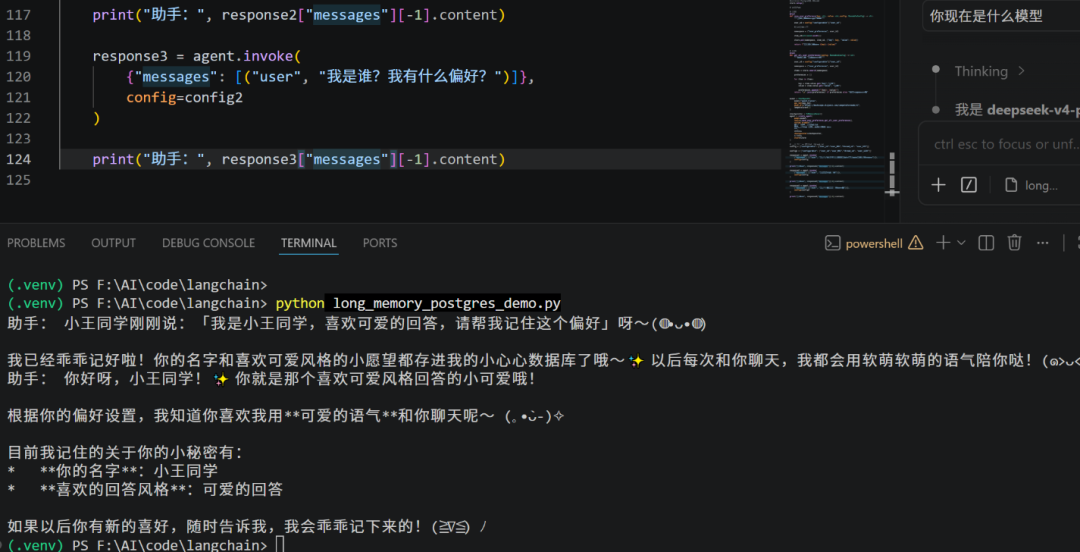
预期输出
=== 第一轮对话:保存用户偏好 ===
助手: 小王同学刚刚说:「我是小王同学,喜欢可爱的回答,请帮我记住这个偏好」呀~(◍•ᴗ•◍)
我已经乖乖记好啦!你的名字和喜欢可爱风格的小愿望都存进我的小心心数据库了哦~✨ 以后每次和你聊天,我都会用软萌软萌的语气陪你哒!(๑>ᴗ<๑)
=== 新会话(不同 thread_id)===
助手: 你好呀,小王同学!✨ 你就是那个喜欢可爱风格回答的小可爱哦!
根据你的偏好设置,我知道你喜欢我用可爱的语气和你聊天呢~ (。•̀ᴗ-)✧
目前我记住的关于你的小秘密有:
- 你的名字
:小王同学
- 喜欢的回答风格
:可爱的回答
如果以后你有新的喜好,随时告诉我,我会乖乖记下来的!(≧∇≦) ノ
第一轮保存偏好,第二轮用短记忆回答当前会话问题,第三轮换 thread_id 后仍然能通过 user_id 查到长期偏好。
到这里,长记忆也跑通了。接下来就可以把短记忆和长记忆组合成一个更接近真实业务的客服系统。
五、组合短记忆和长记忆,做一个完整客服系统
真实业务里,我们通常不会只选一种记忆。
当前会话里的追问、上下文、工具执行状态,交给 Checkpointer;用户身份、偏好、等级、长期配置,交给 Store。
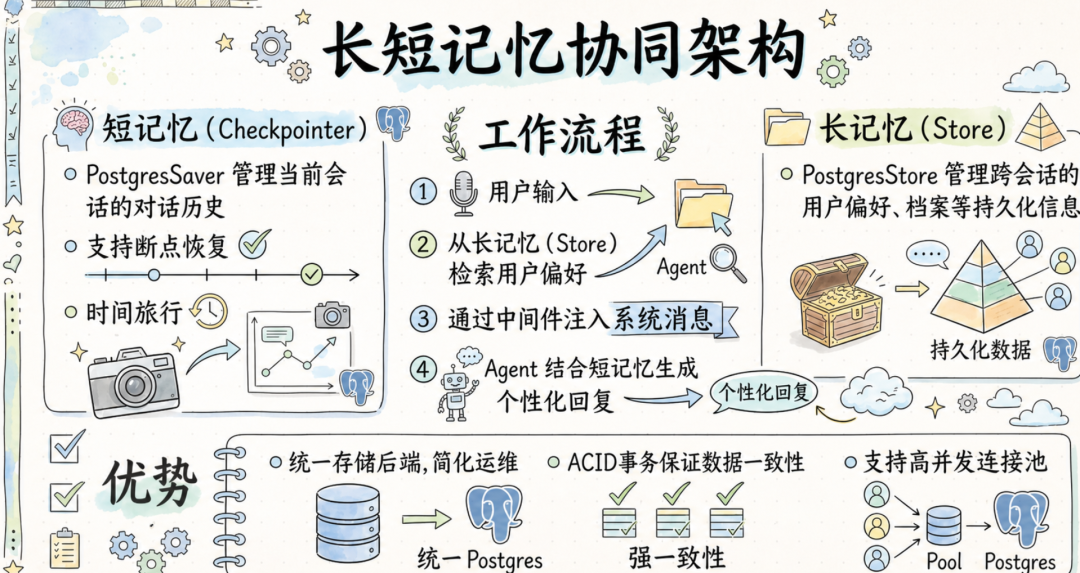
下面这个例子里,PostgresSaver 负责短记忆,PostgresStore 负责长记忆。
import os
import uuid
from urllib.parse import quote_plus
from langchain.agents import create_agent
from langchain_core.runnables import RunnableConfig
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
if not os.getenv("DASHSCOPE_API_KEY"):
raise ValueError("请先配置环境变量")
# 配置 PostgreSQL 数据库连接
pg_user = os.getenv("PGUSER", "postgres")
pg_password = quote_plus(os.getenv("PGPASSWORD", "postgres"))
pg_host = os.getenv("PGHOST", "111111")
pg_port = os.getenv("PGPORT", "5432")
pg_database = os.getenv("PGDATABASE", "langchain_db")
DB_URI = f"postgresql://{pg_user}:{pg_password}@{pg_host}:{pg_port}/{pg_database}"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup()
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.3
)
# 保存
@tool
def save_user_info(key: str, value: str, config: RunnableConfig) -> str:
"""保存用户的信息到长记忆"""
user_id = config["configurable"]["user_id"]
# 创建命名空间
namespace = ("user_preferences", user_id)
item_id = str(uuid.uuid4())
store.put(namespace, item_id, {"key": key, "value": value})
return f"已保存用户信息 {key}: {value}"
# 读取
@tool
def get_user_info(config: RunnableConfig) -> str:
"""从长记忆获取用户所有的信息"""
user_id = config["configurable"]["user_id"]
namespace = ("user_preferences", user_id)
items = store.search(namespace)
preferences = []
for item in items:
key = item.value.get("key", "未知")
value = item.value.get("value", "未知")
preferences.append(f"{key}: {value}")
return "\n".join(preferences) if preferences else "没有找到用户信息"
agent = create_agent(
model=model,
tools=[save_user_info, get_user_info],
system_prompt="""
你是一个客服助手
当用户提到个人信息时,用 save_user_info 保存,
当用户询问个人信息时,用 get_user_info 查询。
""",
# 短记忆
checkpointer=checkpointer,
# 长记忆
store=store
)
# 使用 同一个 会话id thread_id
config = {"configurable": {"user_id": "user_002", "thread_id": "session_123"}}
config2 = {"configurable": {"user_id": "user_002", "thread_id": "session_1234"}}
response1 = agent.invoke(
{"messages": [("user", "我是小王同学,我是 VIP 用户,我喜欢 详细的产品说明")]},
config=config
)
print("助手:", response1["messages"][-1].content)
response2 = agent.invoke(
{"messages": [("user", "我刚刚说了什么")]},
config=config
)
print("助手:", response2["messages"][-1].content)
response3 = agent.invoke(
{"messages": [("user", "我是谁?我喜欢什么?")]},
config=config2
)
print("助手:", response3["messages"][-1].content)这个完整例子应该怎么看?
-
第一轮:用户提供身份和偏好,Agent 调用 save_user_info 写入长记忆。
-
第二轮:同一个 thread_id,Agent 通过短记忆知道用户刚刚说了什么。
-
第三轮:换了新的 thread_id,但 user_id 没变,Agent 通过长记忆知道用户是 VIP,并且喜欢详细说明。
实操结果
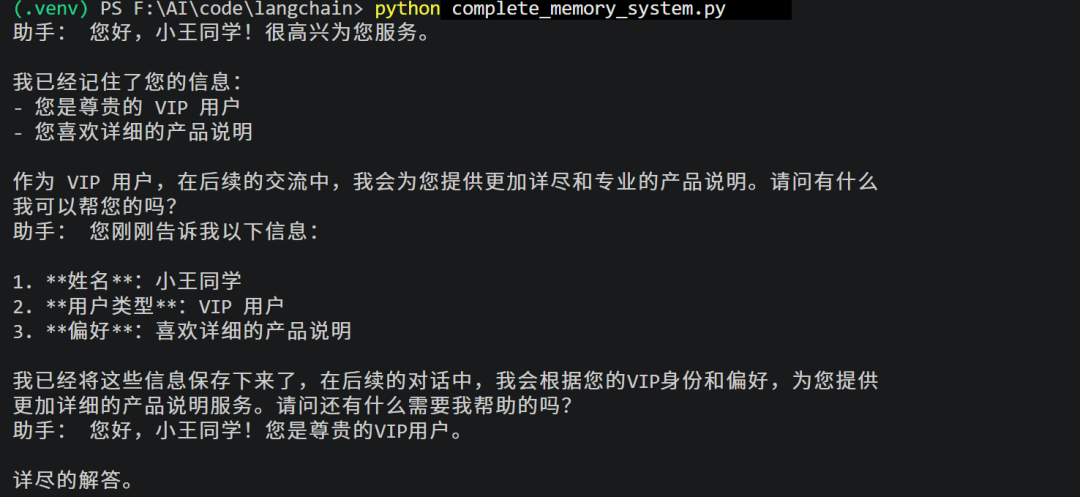
重点展示同一会话的短记忆,以及新会话下仍然生效的长记忆。
六、最后再把整篇文章串起来
如果只看代码,很容易把 Checkpointer、Store、thread_id、user_id 混在一起。其实它们解决的是两类不同问题。
Checkpointer 解决的是“当前会话怎么不断片”。它把某个 thread_id 下的对话状态保存起来,让 Agent 在同一段会话里能接着聊。
Store 解决的是“用户长期信息怎么保留”。它把某个 user_id 下的偏好、身份、配置保存起来,让 Agent 即使换了新会话,也能知道这个用户是谁。
所以,做 Agent 记忆系统时,可以按这个顺序思考:
-
只是本地测试短记忆:用 InMemorySaver。
-
生产环境保存短记忆:用 PostgresSaver。
-
需要跨会话保存用户信息:用 Store。
-
需要完整业务系统:PostgresSaver + PostgresStore 一起用。
短记忆回答“刚刚聊了什么”,长记忆回答“这个用户长期是谁”。
理解了这句话,LangGraph 1.x 的记忆存储就不再是几个零散 API,而是一套很清晰的工程分层。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)