从词袋模型到Transformer:揭秘大语言模型的技术演进之路!
本文系统梳理了自然语言处理技术的演进历程:从早期的词袋模型到Word2Vec词嵌入技术,再到注意力机制的突破,最终发展为Transformer架构。文章深入解析了Transformer的核心组件(自注意力机制、编码器-解码器结构)及其现代改进(分组查询注意力、旋转位置编码等),并介绍了分词器的工作原理。通过技术发展路线的解读,帮助读者理解大语言模型的基础原理与优化方向,为后续的模型应用与开发奠定理
本文带你回顾自然语言处理领域的技术演进,从早期的词袋模型,到Word2Vec的词嵌入技术,再到注意力机制的出现,以及最终的Transformer架构。文章详细解析了Transformer的核心原理,包括自注意力机制、编码器与解码器等,并介绍了现代Transformer的改进,如分组查询注意力、旋转位置编码和混合专家模型。通过吴恩达、Jay Alammar和Martin的讲解,帮助你深入理解大语言模型的技术发展历程,为更好地使用和优化这些模型奠定基础。
从词袋模型到Transformer,从Word2Vec到自注意力机制,跟随吴恩达、Jay Alammar和Martin的讲解,一步步拆解大语言模型的技术演进之路。
引言
Transformer架构自2017年《Attention is All You Need》论文发表以来,彻底改变了自然语言处理领域。ChatGPT、Claude这些主流大语言模型,底层核心都是Transformer。本文将带你从零开始,理解这一技术的完整演进路径。
语言表示的开端:词袋模型
在语言AI的早期,研究者面临一个根本问题:计算机如何处理文本?答案是将语言转化为数值表示。
最朴素的方法是词袋模型(Bag of Words)。它将一段文本拆分为单词(称为"词元"),构建一个包含所有不重复单词的词汇表,然后统计每个词在文本中出现的频率,形成一个数值向量。
例如,“我的猫很可爱"和"这只狗很可爱"两个句子经过分词后,会形成不同的词袋向量。这种方法简单直观,但缺陷也很明显:它完全忽略了词语的顺序和语义,将文本视为"一袋单词”。
词嵌入:让词语拥有"含义"
2013年,Word2Vec的出现改变了这一局面。与词袋模型的稀疏向量不同,Word2Vec通过神经网络学习词语的稠密向量表示(即词嵌入),让语义相近的词语在向量空间中彼此靠近。

Word2Vec的核心思想是:一个词的含义可以通过其上下文来推断。模型在大量文本(如维基百科)上训练,学习预测相邻词语的关系。最终生成的嵌入向量中,"猫"和"狗"这类相关词语会聚集在一起,而"苹果"和"汽车"则相距甚远。
这些嵌入有多个维度(通常数百到上千),每个维度对应词语的某种抽象属性。虽然我们无法精确解释每个维度的含义,但整体上它们代表并捕捉了词语之间的语义关系。
注意力机制:理解上下文的关键
Word2Vec能捕捉词语含义,但它有个问题:使用的是静态嵌入技术。例如多义词、“bank"代表着"河岸"还是"银行”,它的向量表示都相同。这显然是没有办法区分的。
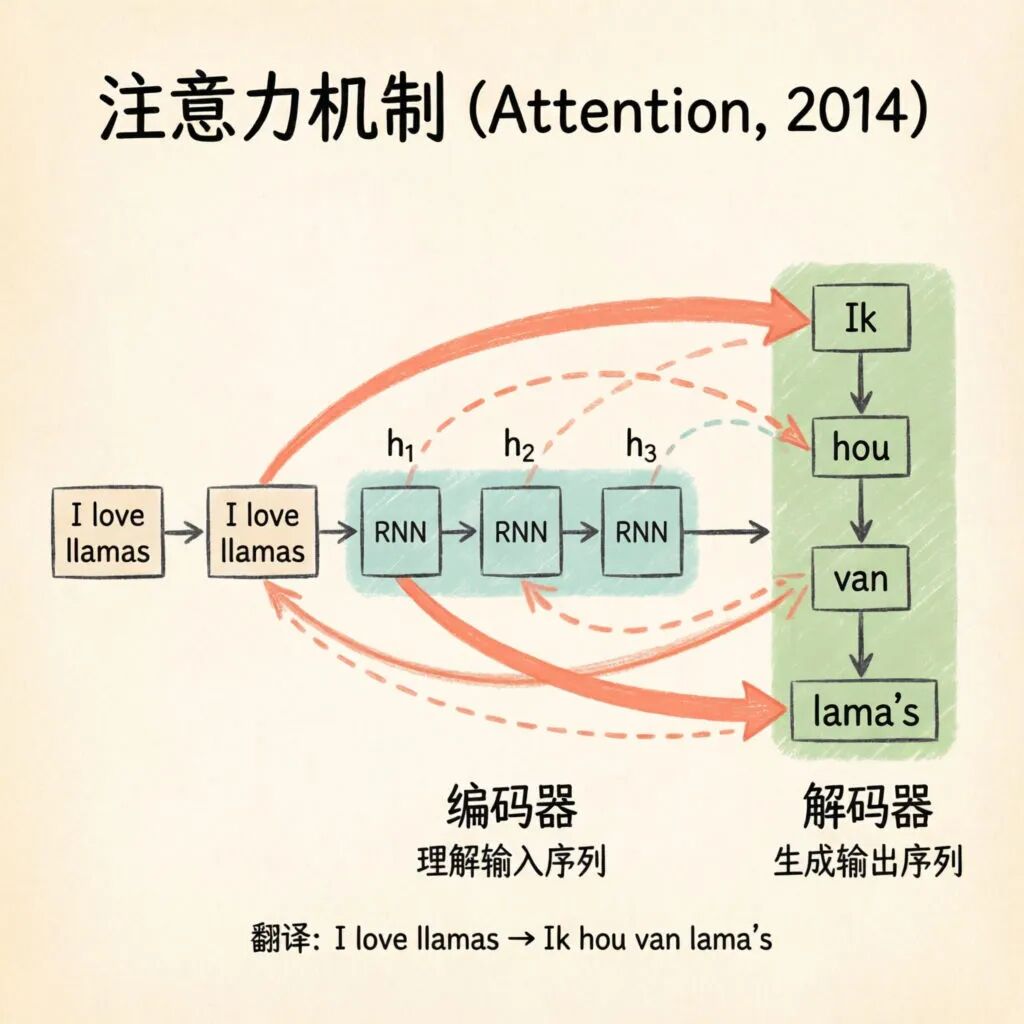
而注意力机制(Attention)的引入正式解决了这一个问题。2014年,研究者将注意力机制与循环神经网络(RNN)结合,让模型在生成每个输出词时,能"关注"输入序列中与之最相关的部分。例如,在翻译"I love llamas"时,生成荷兰语"Ik"时会重点关注"I",生成"llamas"时会重点关注"llamas"。
但RNN有个硬伤:每个词必须等待前一个词处理完毕,限制了训练时的并行化能力。
Transformer:并行化的革命
2017年的论文《Attention is All You Need》提出了彻底摆脱RNN的Transformer架构,核心创新是自注意力机制(Self-Attention)。
自注意力让每个词元都能直接关注序列中的所有其他词元,计算它们之间的相关性得分,然后将相关信息融合到自身的表示中。所有词元的处理可以并行进行,大幅提升了训练效率。
Transformer由两大组件构成:
- • 编码器:用于理解输入文本,生成丰富的上下文表示。BERT等仅编码器模型擅长分类、嵌入等任务。
- • 解码器:用于生成文本,是GPT等生成式模型的基础。
深入理解Transformer块
每个Transformer块包含两个核心层:
自注意力层:通过查询(Query)、键(Key)和值(Value)三个矩阵计算词元之间的相关性。每个词元生成一个查询向量,与所有前序词元的键向量做点积,得到注意力分数,再用这些分数加权聚合值向量。
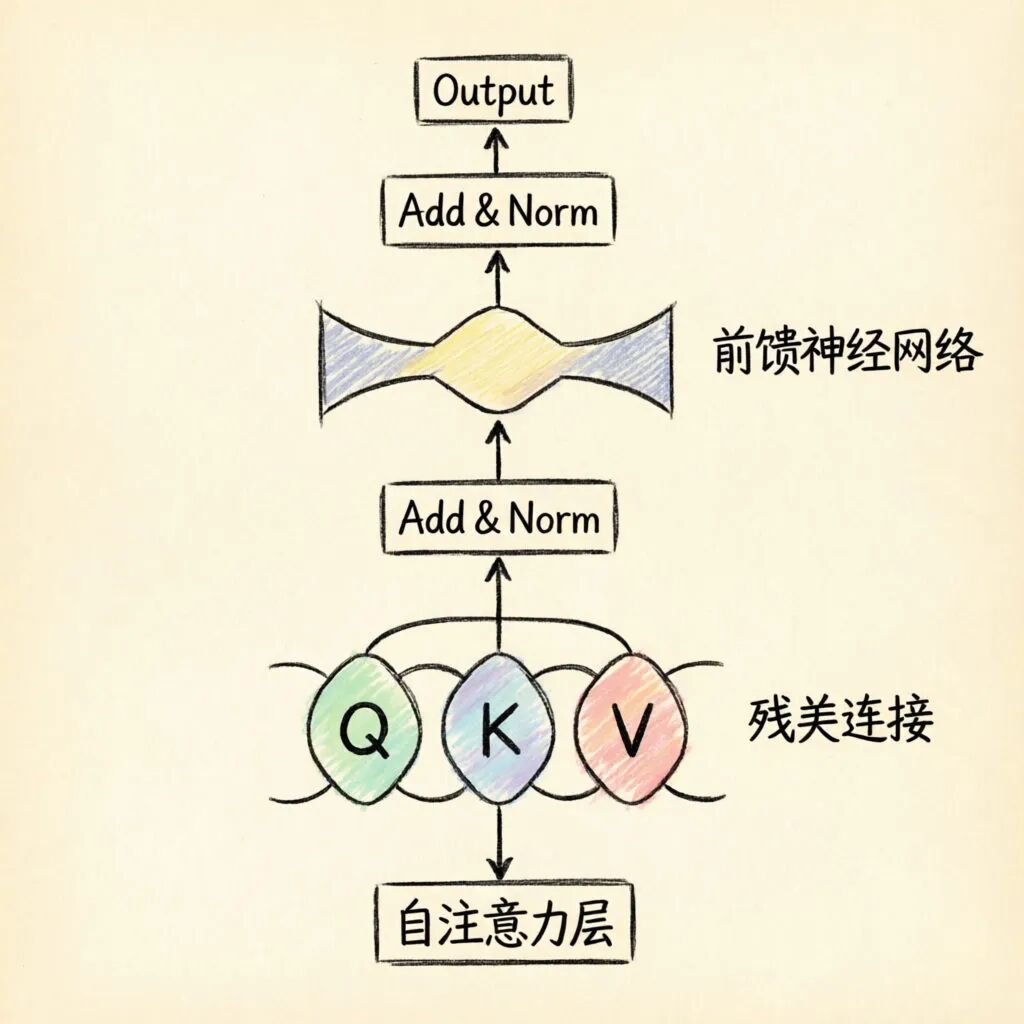
前馈神经网络层:对注意力层的输出进行进一步变换,存储和建模知识。可以理解为模型的"记忆库",负责学习数据中的复杂模式。
现代Transformer还引入了多头注意力(多个并行的注意力头捕捉不同关系)、残差连接(防止梯度消失)和层归一化(稳定训练)。
分词器:语言模型的"入口"
在文本进入Transformer之前,首先需要经过分词器的处理。分词器将文本拆分为词元,每个词元对应一个固定的ID。常见的分词策略包括:
- • 子词分词:如BPE(Byte Pair Encoding),将罕见词拆分为更小的子词单元
- • 词汇表大小决定了模型能表示的词元数量,GPT-4的分词器拥有约10万个词元
分词器的选择直接影响模型的表现:更大的词汇表可以用更少的词元表示文本,但计算嵌入的代价也更高。
现代Transformer的演进
自原始Transformer以来,该架构经历了多项重要改进:
分组查询注意力:在多头注意力的基础上,让多个查询头共享键值对,在保持质量的同时提升推理效率。而Llama 3等模型都是采用了这一种方案。
旋转位置编码:将位置信息融入自注意力计算中,让模型更好地理解词元之间的相对位置关系。
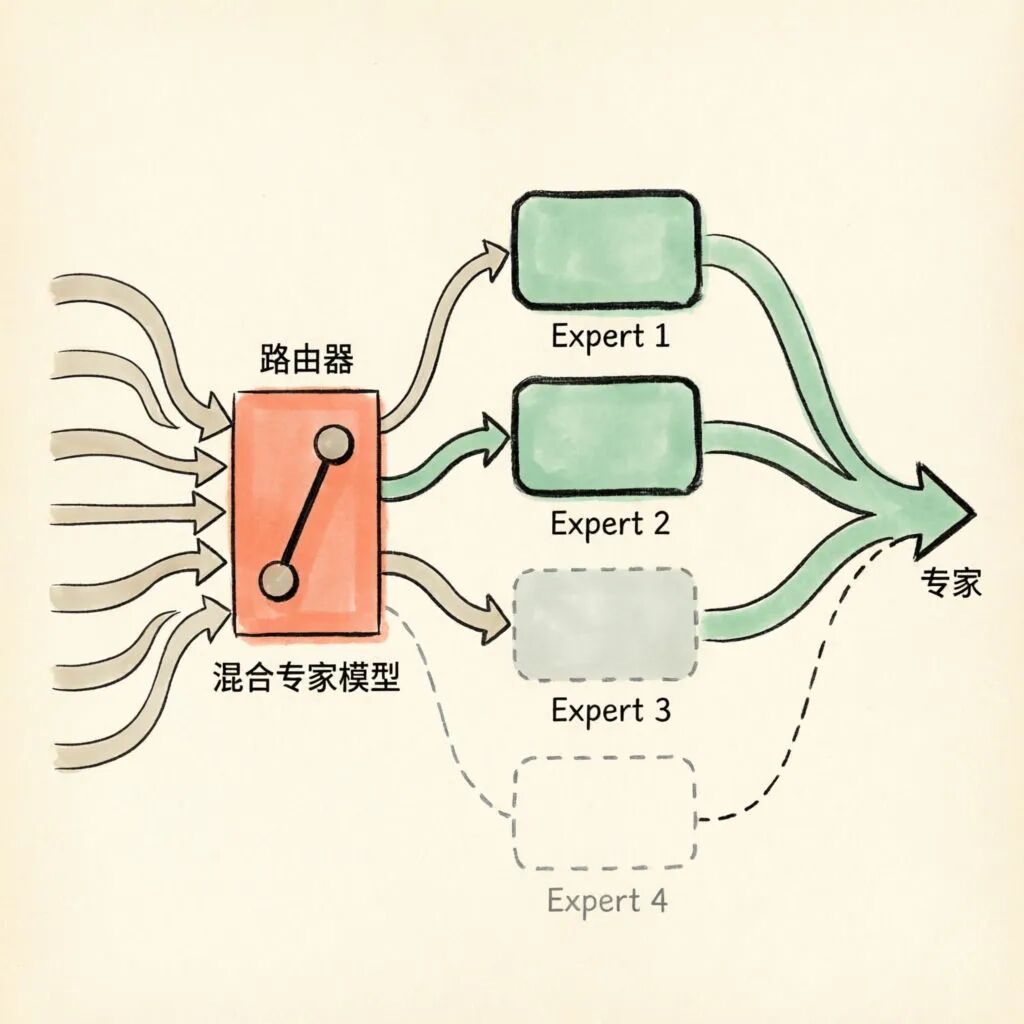
混合专家模型:将前馈网络替换为多个"专家"网络,由路由器动态选择最合适的专家处理每个词元。这使得模型在推理时只激活部分参数,大幅提升效率。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)