AI智能体为什么总是“答非所问“?——本体论建模缺失的代价
当企业投入大量资源构建AI智能体,却发现它们频繁"答非所问"、"理解偏差"、"协作混乱"。问题的根源不在模型能力,而在于我们从未教过AI什么是"业务"。
本文从企业AI落地的真实痛点出发,系统阐述本体论建模(Ontology Modeling)如何为AI应用构建统一的知识底座,让智能体从"概率匹配工具"进化为"真正理解业务语义的协作者"。
"我们花了几十万买大模型API,训练了专属客服智能体,但它还是经常答非所问。客户问'我的订单什么时候到',它回答'我们的物流合作伙伴包括顺丰和京东'。这到底是怎么回事?"
这是一位企业技术负责人在一次架构师交流会上的真实困惑。在座的二十多位技术管理者中,有超过一半的人点头表示"我们也遇到过类似问题"。
问题的根源是什么?是模型不够大?是Prompt写得不好?是RAG检索不够精准?
都不是。真正的根源是:AI从来没有"理解"过你的业务。它只是在海量文本中寻找概率最高的词序列。
你给了它数据,但没有给它知识结构;你给了它答案,但没有给它语义关系;你给了它能力,但没有给它边界定义。
而这,正是本体论建模(Ontology Modeling)要解决的核心问题。
01 什么是本体论建模?
从哲学到计算机科学
"本体论"(Ontology)一词最早源自哲学领域,研究"存在的本质"。亚里士多德在《形而上学》中试图对"存在"进行分类和定义——这可以说是人类历史上第一次本体论建模尝试。
在计算机科学中,本体论的定义由斯坦福大学知识系统实验室提出:
"本体论是对共享概念化的显式形式化规范。" —— Tom Gruber, 1993
拆解这个定义:
- 概念化(Conceptualization):对某个领域抽象出的概念模型
- 共享(Shared):被某个群体共同认可和理解
- 显式(Explicit):概念和约束被明确定义,而非隐含
- 形式化(Formal):机器可读、可推理的数学表达
- 规范(Specification):一份可参照的标准文档
本体论的五大核心要素
一个完整的领域本体由以下五个要素构成:
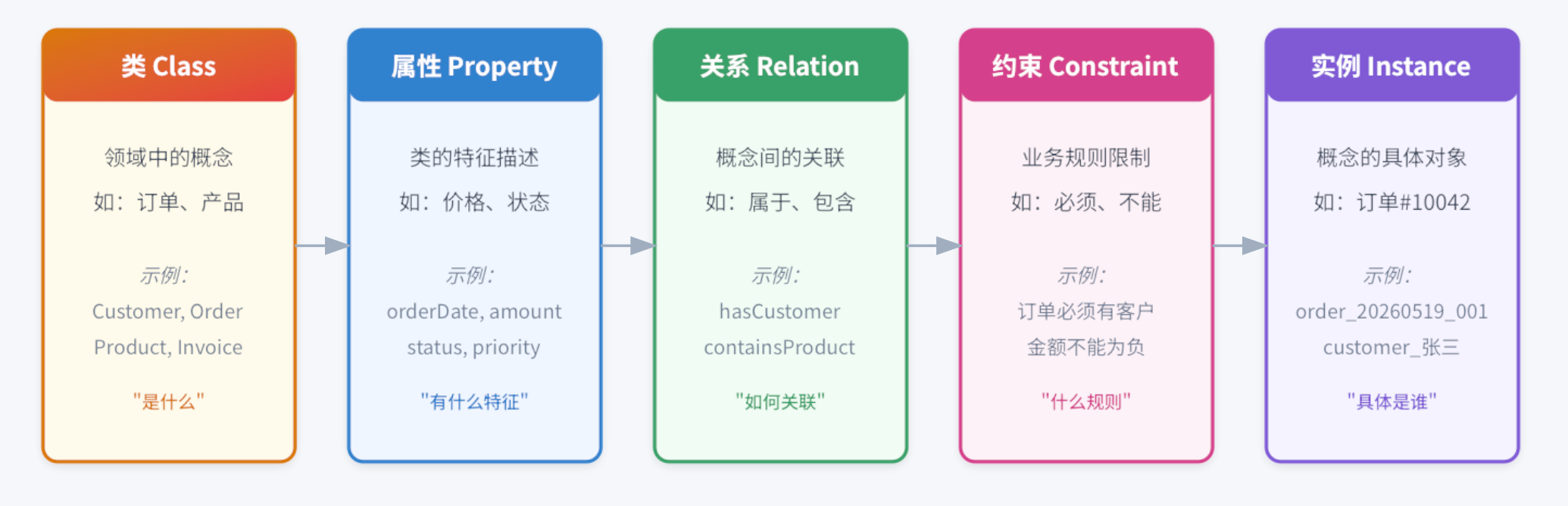
图1:本体论建模的五大核心要素及其关系
一个简单示例:电商订单本体
让我们用一个电商场景来具体理解这五个要素如何协作:
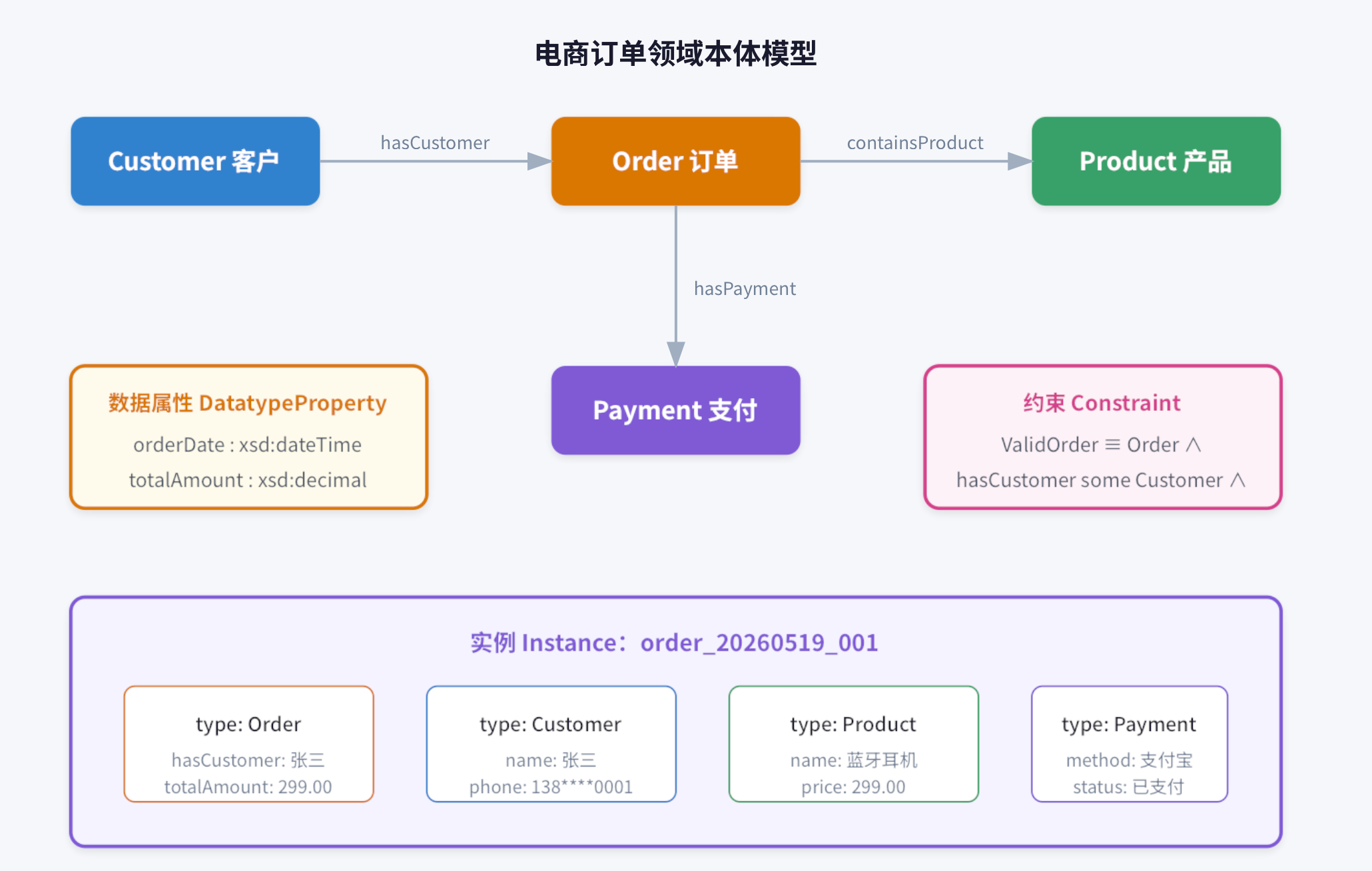
图2:电商订单领域本体模型可视化
这个本体模型告诉AI:订单是什么、订单和客户是什么关系、一个有效订单必须满足什么条件。有了这些知识,AI才能真正"理解"用户问的"我的订单什么时候到"——它知道"我的订单"指的是"与当前用户关联的订单实例",而不是泛泛地谈论物流合作伙伴。
SECTION 02
02 企业AI落地的三大痛点,本体论如何系统性解决
在帮助多家企业落地AI应用的过程中,我观察到三个反复出现的痛点。它们表面上是技术问题,根子上都是知识结构缺失的问题。
痛点一:知识孤岛——数据很多,AI却"找不到"
企业通常有多个系统:CRM、ERP、工单系统、知识库。每个系统都有自己的数据模型和术语。当AI需要回答一个跨系统问题时(如"这个客户最近的订单和投诉记录是什么"),它面临的是语义鸿沟。

痛点二:智能体协作混乱——多个Agent,各干各的
当企业部署多个智能体(客服Agent、分析Agent、执行Agent),如果没有清晰的能力边界定义和任务关系模型,就会出现:任务重复执行、责任推诿、信息不一致。

本体论的解法:通过本体定义Agent的能力类(Capability)、任务类型(TaskType)、输入输出关系(InputOutputRelation),形成Agent协作的"语义协议"。
痛点三:权限与数据隔离——AI知道太多,或者知道太少
企业AI应用必须解决数据隔离问题:不同部门、不同角色的用户,AI应该返回不同的信息。传统的RBAC(基于角色的访问控制)在AI场景下不够用——AI需要理解语义级别的权限边界。
本体论的解法:在本体中建模权限关系,将"谁能访问什么数据"转化为"用户角色-数据类别-操作类型"的三元关系,支持细粒度的语义权限推理。
| 痛点 | 表面症状 | 根本原因 | 本体论解法 |
|---|---|---|---|
| 知识孤岛 | AI找不到跨系统信息 | 缺乏统一语义层 | 领域本体 + 概念映射 |
| 协作混乱 | Agent重复执行或遗漏 | 能力边界未定义 | Agent能力本体 + 任务关系 |
| 权限失控 | AI返回不该看的信息 | 权限模型过于简单 | 语义权限本体 + 推理引擎 |
SECTION 03
03 本体论建模方法论:五步法
本体论建模不是凭空想象,而是一套结构化的方法论。以下是我在实践中总结的"五步法",适用于大多数企业级AI应用场景。

图3:本体论建模五步法流程图
Step 1:界定领域范围与 Competency Questions
目标:明确本体要覆盖的知识边界,以及本体需要回答的问题。
Competency Questions(能力问题)是一组自然语言问题,定义了本体的"功能需求"。例如在供应链领域:"哪些供应商的交货延迟率超过10%?"、"产品A的替代物料有哪些?"。
关键产出:领域范围文档、Competency Questions列表(通常10-30个问题)。
Step 2:抽取核心概念与术语
目标:从业务文档、系统数据模型、专家访谈中抽取领域概念。
方法包括:名词提取法(从需求文档中提取关键名词)、系统逆向工程(从数据库Schema中提取实体)、专家访谈(与领域专家确认概念定义)。
关键产出:概念术语表、概念分类树(Taxonomy)。
Step 3:定义概念间的关系与层次
目标:建立概念之间的语义关系网络。
关系类型包括:继承关系(is-a,如"紧急订单 is-a 订单")、组成关系(part-of,如"订单项 part-of 订单")、关联关系(如"订单 hasCustomer 客户")、等价关系(如"客户 equivalentTo 购买者")。
关键产出:关系矩阵、概念层次图(Hierarchy Graph)。
Step 4:添加约束与规则
目标:定义业务规则,使本体具备推理能力。
约束类型包括:基数约束(如"订单必须有且仅有一个客户")、值域约束(如"订单金额必须大于0")、逻辑约束(如"已取消的订单不能有物流记录")。
关键产出:约束规则集、OWL公理(Axioms)。
Step 5:实例化与验证
目标:用真实数据填充本体,验证模型是否满足Competency Questions。
验证方法:实例测试(导入真实数据看推理结果是否正确)、覆盖度测试(检查所有CQ是否能被回答)、一致性检查(使用推理机检测模型矛盾)。
关键产出:实例数据集、验证报告、模型迭代记录。
- 界定领域范围与 Competency Questions
明确"这个本体要解决什么问题"。用一组自然语言问题(Competency Questions)定义本体的功能边界。例如:"哪些供应商的交货延迟率超过10%?"
- 抽取核心概念与术语
从业务文档、系统数据模型、专家访谈中抽取领域概念,形成术语表和分类树。
- 定义概念间的关系与层次
建立继承(is-a)、组成(part-of)、关联等语义关系,构建概念网络。
- 添加约束与规则
定义基数约束、值域约束、逻辑约束,使本体具备推理能力。
- 实例化与验证
用真实数据填充本体,验证模型是否能正确回答所有Competency Questions。
04 企业级AI中台的本体论架构
在企业级AI应用底座中,本体论不是孤立存在的,而是作为知识基础设施贯穿整个架构。以下是我推荐的三层本体论架构:
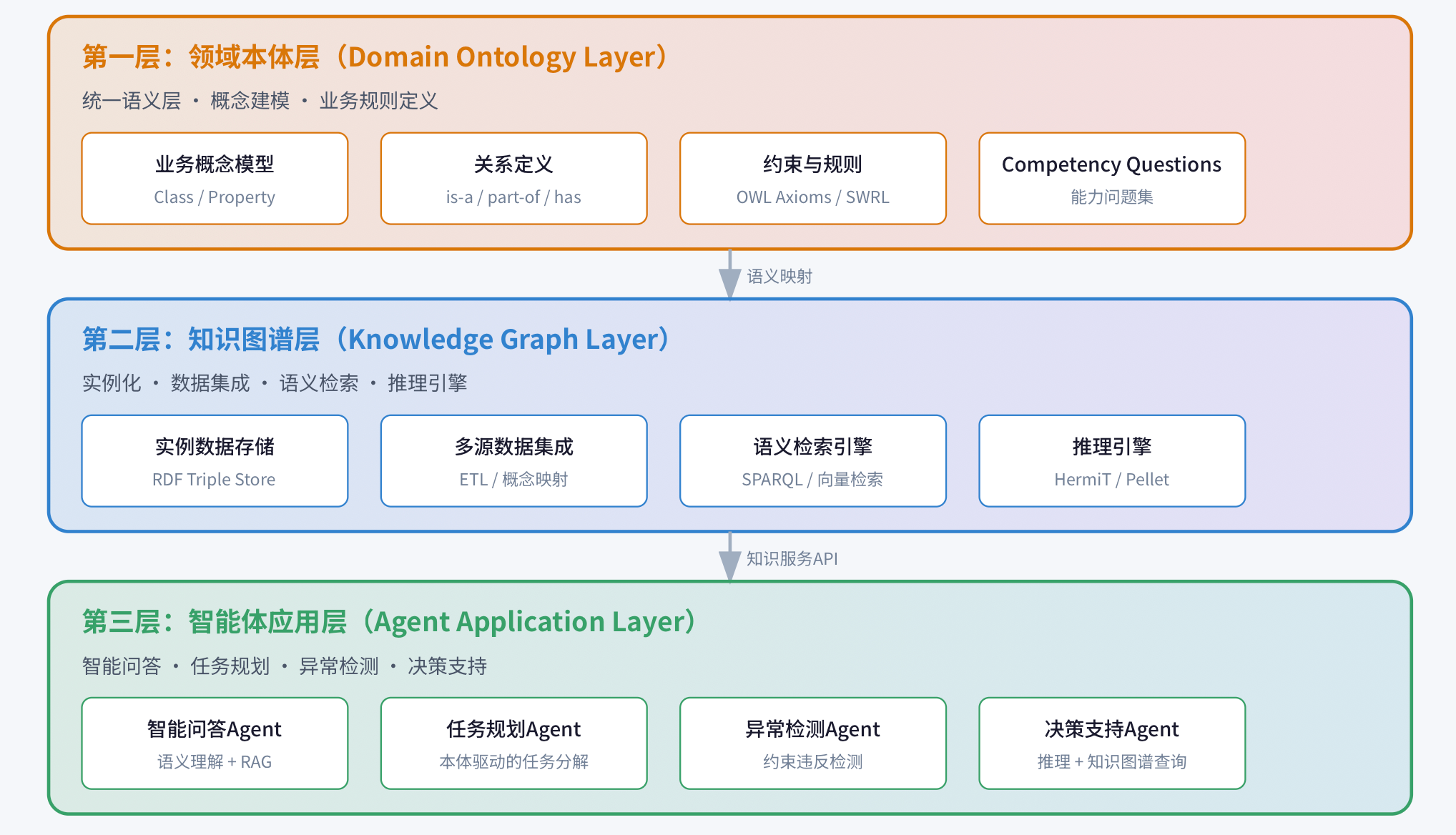
图4:企业级AI中台的本体论三层架构
领域本体层:统一语义层
这是整个架构的基石。领域本体层定义了企业知识的概念模型,包括业务概念、关系、约束和规则。它不存储具体数据,而是定义数据的语义结构。
关键设计原则:与业务对齐(本体必须反映业务人员的思维方式)、可演进(本体需要随业务发展而迭代)、可复用(核心本体应能被多个应用共享)。
技术选型:Protégé(建模工具)、OWL 2(本体语言)、SWRL(规则语言)。
知识图谱层:实例化与推理
知识图谱层将领域本体实例化,接入企业真实数据。它负责将多源异构数据(数据库、API、文档)映射到本体定义的概念和关系中,形成统一的知识图谱。
核心能力:语义检索(基于SPARQL和向量检索的混合查询)、推理(基于本体约束的自动推理,如"如果A是B的上级,B是C的上级,则A是C的上上级")、知识融合(合并来自不同来源的同一实体)。
技术选型:Neo4j / GraphDB(图数据库)、Apache Jena(RDF框架)、Elasticsearch(向量检索)。
智能体应用层:知识驱动的智能服务
智能体应用层直接面向业务场景,利用知识图谱层提供的语义能力,构建各类AI智能体。
智能问答Agent:基于本体语义理解用户意图,结合RAG从知识图谱中检索精准答案。
任务规划Agent:利用本体中定义的任务类型和关系,自动分解复杂任务。
异常检测Agent:基于本体约束规则,自动检测业务数据中的违反约束情况。
决策支持Agent:结合知识图谱推理和业务规则,提供数据驱动的决策建议。
架构设计原则
- 语义优先:先定义"是什么"和"为什么",再考虑"怎么做"
- 分层解耦:本体层、图谱层、应用层各自独立演进
- 可解释性:每个AI决策都能追溯到本体中的知识依据
- 持续演进:本体不是一次性工程,需要随业务发展持续迭代
05 实战案例:供应链领域的本体论建模
让我们用一个完整的供应链场景,演示如何从零开始构建一个领域本体,并让它支撑AI智能体的实际应用。
场景背景
某制造企业希望构建一个供应链智能助手,能够回答以下问题(Competency Questions):
- 哪些供应商的交货延迟率超过10%?
- 产品A的替代物料有哪些?库存是否充足?
- 如果供应商X停产某物料,会影响哪些产品的生产?
- 下个月哪些物料可能出现短缺?
Step 1-2:界定范围与抽取概念
通过与供应链专家访谈和分析现有ERP系统,我们抽取了以下核心概念:
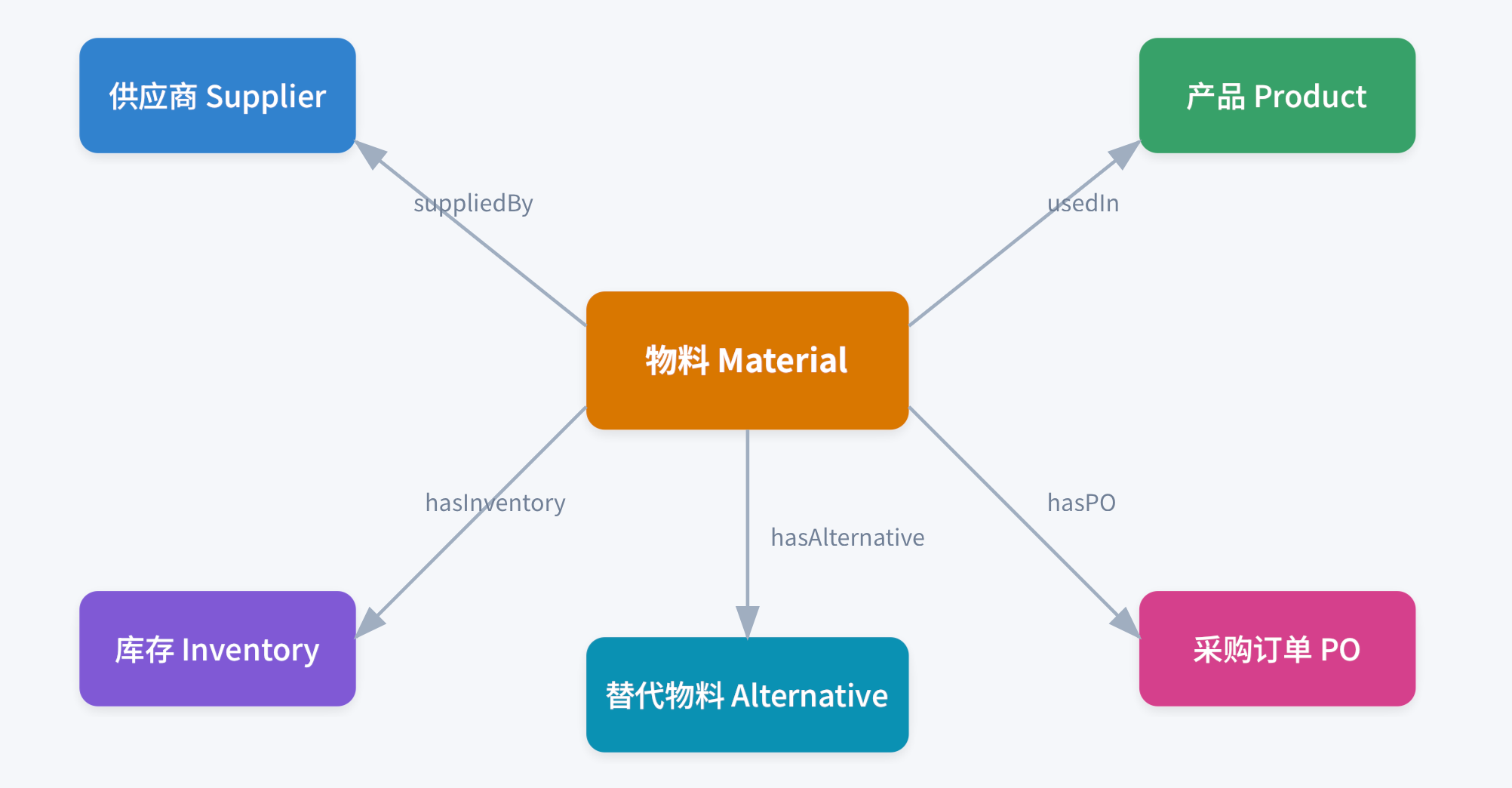
图5:供应链领域本体概念关系图
Step 3-4:定义关系与约束
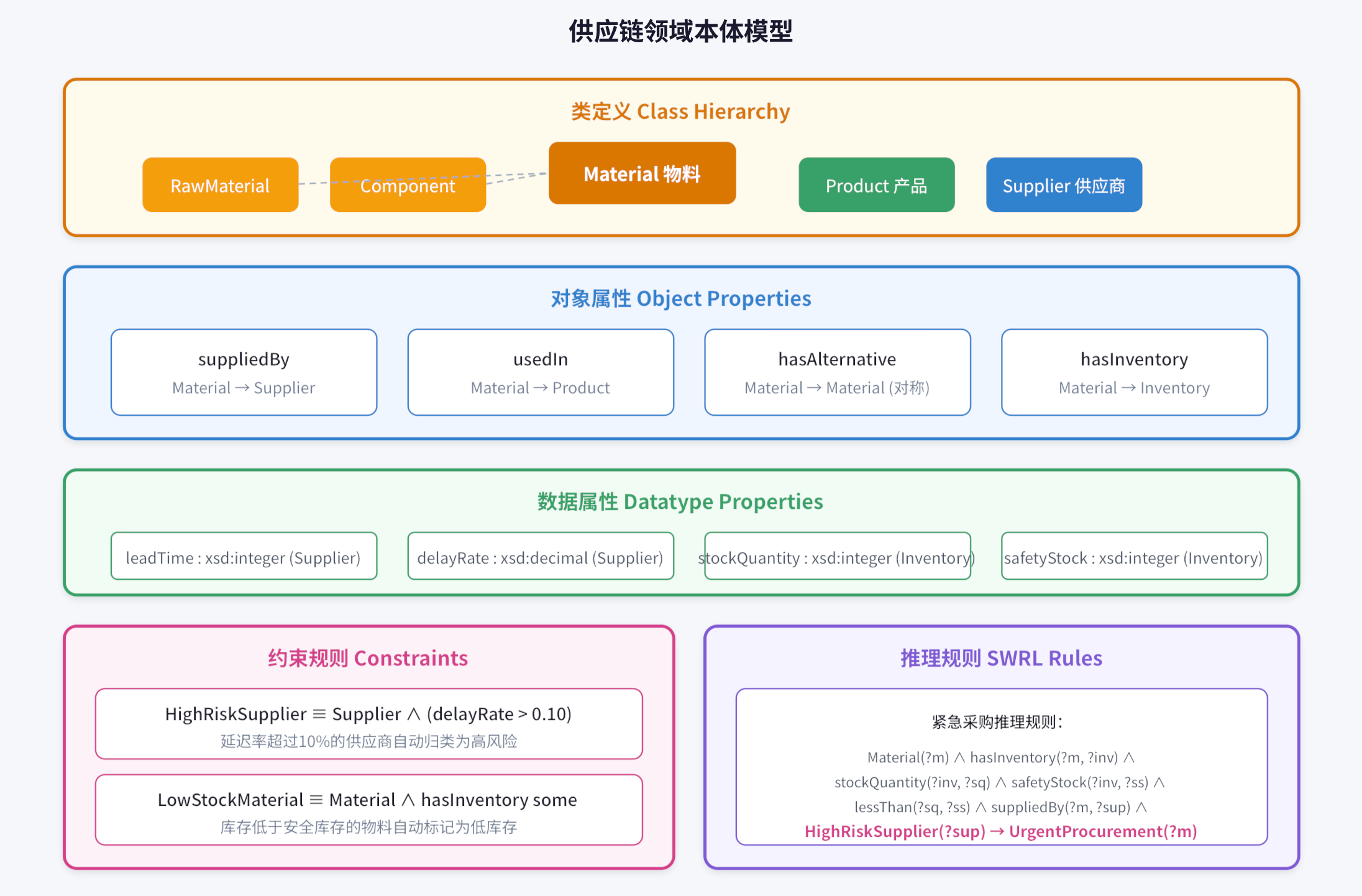
图6:供应链领域本体模型可视化
Step 5:实例化与AI应用
本体构建完成后,我们导入真实数据进行验证。以下是几个AI智能体如何利用本体的实际场景:



06 最佳实践与避坑指南
基于多个企业项目的实践经验,我总结了以下最佳实践和常见陷阱。
常见误区



工具选型建议
| 工具 | 类型 | 适用场景 | 优点 | 局限 |
|---|---|---|---|---|
| Protégé | 开源建模工具 | 本体设计与编辑 | 免费、功能全面、社区活跃 | 学习曲线陡峭、不适合大规模实例 |
| TopBraid Composer | 商业工具 | 企业级本体管理 | 可视化好、支持团队协作 | 授权费用高 |
| Apache Jena | 开源框架 | RDF/OWL数据处理 | Java生态、API丰富 | 需要开发能力 |
| Neo4j + Neosemantics | 图数据库 | 知识图谱存储与查询 | 性能优秀、生态完善 | RDF支持需插件 |
| 自研平台 | 定制开发 | 深度集成企业系统 | 完全贴合业务需求 | 开发成本高、周期长 |
团队能力建设路径
本体论建模需要跨学科能力,建议按以下路径建设团队:
- 第一阶段(认知):团队学习本体论基础概念,理解OWL/RDF标准,掌握Protégé基本操作
- 第二阶段(实践):选择一个小型领域(如产品目录),完成从建模到实例化的完整流程
- 第三阶段(集成):将本体与现有AI应用集成,验证价值,积累经验
- 第四阶段(规模化):建立本体治理机制,培养领域本体专家,推动跨部门复用
关键建议
不要试图让一个团队同时掌握所有能力。本体工程师(建模能力)、知识工程师(数据集成能力)、AI工程师(应用开发能力)可以分工协作,通过明确定义的接口和协议协同工作。
本体论建模不是银弹,而是基础设施
在AI大模型能力飞速进化的今天,很多人会问:模型已经这么强大了,还需要本体论建模吗?
我的回答是:正因为模型越来越强大,本体论建模才越来越重要。
大模型解决了"通用知识"的问题,但企业AI应用的核心竞争力在于领域知识——那些只有你的企业才知道的业务规则、流程关系、经验判断。这些知识不会自动出现在大模型的训练数据中,必须通过本体论建模来显式定义和结构化。
本体论建模不是银弹,它不能解决所有AI问题。但它是企业级AI应用的基础设施——就像数据库之于传统应用,没有数据库,应用也能跑,但永远无法规模化、无法可靠、无法企业级。
当你的AI智能体不再"答非所问",当你的多个Agent能够有序协作,当你的AI应用能够理解业务语义而非仅仅匹配关键词——你会意识到,本体论建模投入的每一分精力,都是值得的。
"AI的未来不在于更大的模型,而在于更好的知识结构。本体论建模,就是构建这个知识结构的基石。"

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)