面试官灵魂拷问:RAG Embedding 选模型,你真的会吗?别再说 OpenAI 最好了!
本文深入解析了 RAG 技术中 Embedding 的核心原理,强调其通过语义压缩将文本映射为向量,实现语义相近文本向量距离近的关键特性。文章对比了 OpenAI、BGE 系列及多语言模型,提出选型需关注中文支持度、数据合规与向量维度,并警示通用排行榜(如 MTEB)的局限性,主张在业务数据上用 Hit@K 指标进行真实场景评估。面试总结指出,正确回答需阐明 Embedding 语义匹配机制、场景化选型依据及数据驱动评估的重要性。
👔面试官:RAG 里的 Embedding 是什么?你是怎么选模型的?
🙋♂️我:Embedding 就是把文本变成向量,用 OpenAI 的模型就行了,效果最好。
👔面试官:「把文本变成向量」说了等于没说。向量的关键特性是什么?为什么语义相似的文本向量就靠近?这个原理你能解释吗?而且 OpenAI 的模型在中文场景上效果就一定好吗?
🙋♂️我:那我就选排行榜分数最高的模型,MTEB 排行榜第一名应该没问题吧?
👔面试官:MTEB 用的是通用数据集,你的业务是做医疗问答还是法律咨询?通用排行榜能代表你的场景效果?你有没有在自己的数据上做过评估?Hit@K 是什么指标你知道吗?
🙋♂️我:呃……Hit@K 没听过,我们就直接用 OpenAI 的,没测过别的。
👔面试官:选模型不测试,全靠感觉和排行榜,这样做出来的系统能好用就怪了。
好吧,Embedding 这块看似只是调个 API,但选型不当整个 RAG 的检索质量都会受影响。下面我来讲清楚。
💡 简要回答
Embedding 我理解就是把一段文本转成一串数字向量的过程。它有一个很关键的特性,就是语义相近的文本,转出来的向量在数学空间里的距离也近。RAG 里的语义检索就是靠这个实现的,不是关键词匹配,而是看两段内容的意思相不相近。选模型的话,我主要看三个维度:第一是中文支持,中文场景我会优先选 BGE 系列,效果其实比 OpenAI 的模型还要好;第二是向量维度,维度越高精度越好,但存储成本也越大;第三是最大输入长度,这个决定了能处理多长的 chunk。评估这块我的建议是不要只看通用排行榜,一定要在自己的业务数据上跑召回测试,那个才是真正有参考价值的。
📝 详细解析
Embedding 是什么?
Embedding 模型做的事情本质上是「语义压缩」,把一段自然语言文本映射成一个固定长度的浮点数向量。比如一个 1024 维的 Embedding 模型,不管输入的文本是 10 个字还是 500 个字,输出都是一个长度为 1024 的数字列表。
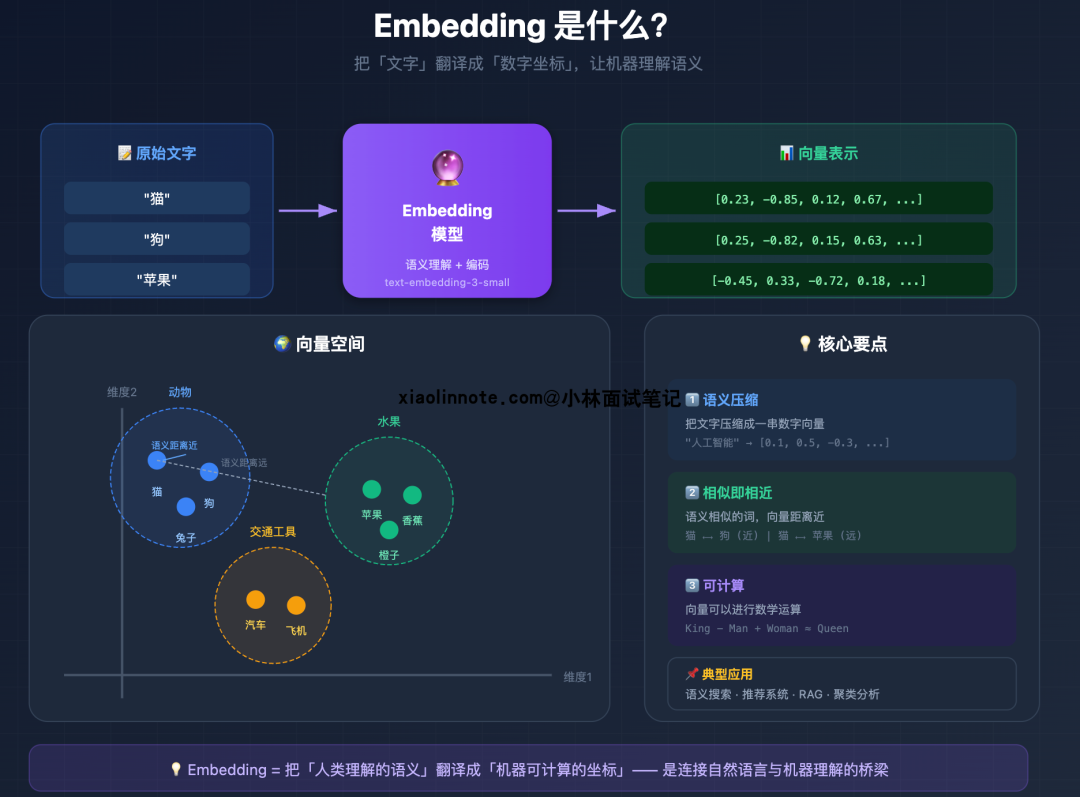
这个映射最关键的性质是:语义相近的文本,向量的余弦相似度高。余弦相似度衡量的是两个向量的方向有多接近,方向越一致,余弦值越接近 1,说明语义越相近。你可以把它理解成:两段话如果「指向同一个意思」,它们的向量箭头就朝着同一个方向。
你可能会觉得这没什么了不起的,关键词搜索不也能找到相关内容吗?还真不一样。比如「苹果手机怎么截图」和「iPhone 如何截屏」,这两句话一个字都不一样,关键词搜索根本匹配不上,但经过 Embedding 之后,两个向量的余弦相似度可能高达 0.95;而「苹果手机」和「苹果汁」虽然都有「苹果」,但语义相差很远,向量距离也会拉开。这就是语义检索比关键词匹配强的核心原因,它能处理同义词、近义词和不同的表达方式。很多人以为向量检索就是高级的关键词匹配,其实完全不是一回事,它是从「意思」层面在做匹配。
常见 Embedding 模型对比
理解了 Embedding 的原理,接下来就是选模型了。目前主流的选择大概分三类。
- 第一类是 OpenAI 的 text-embedding 系列,
text-embedding-3-small是性价比最高的,1536 维,支持降维到 256 维来节省存储,调用方便,英文效果非常好;缺点是 API 调用有费用,而且数据要发到 OpenAI 服务器,有些企业有数据出境合规问题。 - 第二类是 BGE 系列(北京智源研究院出品),这是目前中文 RAG 场景的首选开源模型,
bge-large-zh在中文语义检索上的效果甚至超过 OpenAI 的模型,1024 维,可以本地部署,数据不出境。如果你的知识库主要是中文内容,BGE 几乎是最优解。 - 第三类是多语言模型,比如
bge-m3,同时支持中英日等多种语言,向量维度 1024,适合知识库里中英文混排的场景。
如何选择 Embedding 模型?
聊完了模型分类,具体到你自己的项目,该怎么选?选模型的时候主要看这几个判断点。
- 第一是中英文比例:知识库以中文为主,选
bge-large-zh;中英混合,选bge-m3;纯英文或追求省事,选text-embedding-3-small。 - 第二是数据合规要求:数据不能出境,就必须用可以本地部署的开源模型,BGE 系列是最优选择。
- 第三是向量维度对存储和检索速度的影响:维度越高精度越好,但存储空间和检索时间都会增加。百万量级的知识库,1024 维是个合理的平衡点;如果规模很小,1536 维也无所谓。
如何评估 Embedding 模型?
这里有一个常见的误区:很多人拿 MTEB 这类通用排行榜的分数来选模型,觉得分数高就一定好。MTEB 是一个权威的文本 Embedding 通用排行榜,用多种标准数据集评测模型的语义搜索能力,是好的参考。但它用的是通用数据集,你的业务场景(比如医疗问诊、法律文档、客服知识库)和通用数据分布差异很大,排行榜第一的模型不一定适合你。就好比高考状元不一定擅长你那个行业的专业考试,测评的数据分布不对,分数就没有参考意义。
正确的评估方法是在自己的业务数据上测:准备几百条业务相关的「问题 + 正确答案 chunk」对,分别用候选模型做检索,看正确的 chunk 有没有出现在前 K 条结果里。这个指标叫 Hit@K,Hit@5 = 0.8 的意思就是,80% 的问题,它对应的答案都出现在了检索结果的前 5 条里。通常 Hit@5 低于 0.7 就要考虑换模型或者改进 Chunking 策略了。这种贴近真实场景的评估,比排行榜分数更有参考价值。
把常见的选型维度汇总对比一下:
| 模型 | 维度 | 中文效果 | 是否开源 | 适用场景 |
|---|---|---|---|---|
| text-embedding-3-small | 1536(可降维) | 一般 | 否(API) | 英文为主、快速上手 |
| text-embedding-3-large | 3072(可降维) | 一般 | 否(API) | 英文为主、精度要求高 |
| bge-large-zh | 1024 | 很好 | 是 | 中文知识库首选 |
| bge-m3 | 1024 | 好 | 是 | 中英混合、多语言场景 |
🎯 面试总结
回到开头那段面试,Embedding 这个问题考察的是你对 RAG 检索层基础的理解。
回答要讲清三点。第一,Embedding 不只是「文本变向量」,关键是语义相近的文本向量距离近,这才是语义检索的基础。第二,选模型要看场景:中文首选 BGE,中英混合用 bge-m3,有数据合规要求就用开源模型本地部署。第三,评估模型不要只看 MTEB 排行榜,要在自己的业务数据上跑 Hit@K 测试,这才是真正有参考价值的。
如果面试官追问「你用的什么模型,为什么选它」,你就说「中文场景用 bge-large-zh,在自己的业务数据上 Hit@5 达到 0.8 以上」,这个回答有理有据。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
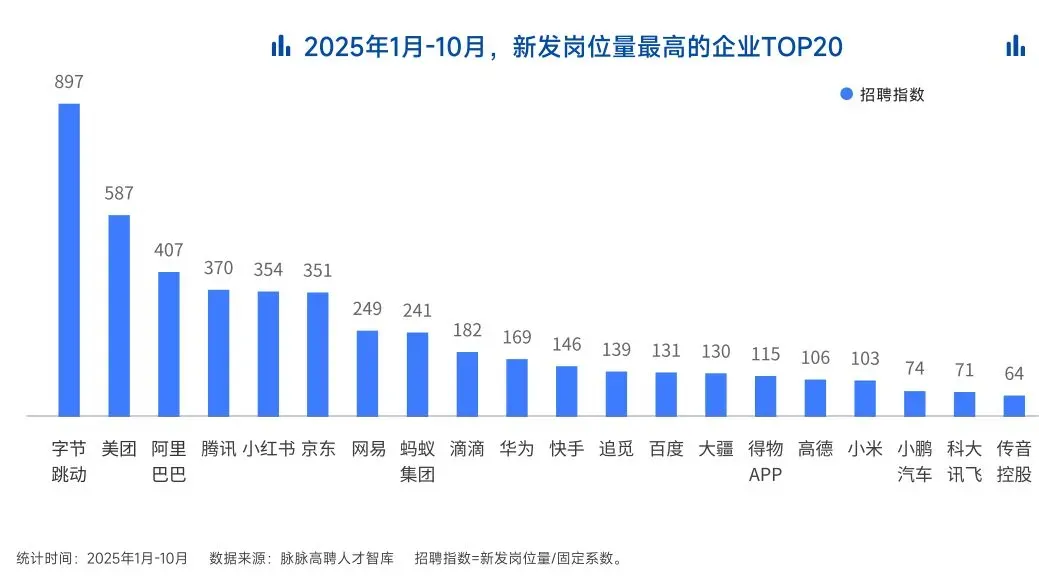
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 5
5 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)