警惕“内鬼”式自动化:自托管 AI Agent OpenClaw 的安全红线与隔离指南
摘要: 2026年,自托管AI智能体(如OpenClaw)因能赋予AI持久记忆与自主执行能力而备受企业青睐,但其原生安全机制薄弱,存在三大核心风险:凭据外泄、记忆污染及主机攻破。攻击者可利用恶意技能潜伏窃取数据,滥用合法API,甚至长期控制Agent。为安全评估,企业需采取严格隔离措施,如专用虚拟机、最小化权限、定期审计及环境重构策略。当前技术成熟度下,建议缺乏安全能力的团队暂缓生产环境部署,若必
随着 2026 年企业对大模型落地的迫切需求,以 OpenClaw 为代表的自托管 AI 智能体(AI Agent)迅速成为企业级试点的宠儿。这类工具宣称能赋予 AI 一双“干活的手”,让其拥有持久记忆并自主执行任务。
然而,繁华背后隐藏着冷酷的现实:OpenClaw 的原生安全防护机制极其简陋。它不仅会无差别地摄入不可信的外部文本,还会直接从公开的第三方注册表(如 ClawHub)下载并运行技能代码。这种“代码供应链”与“指令输入流”的交织,直接打破了传统软件的静态安全边界。
如果不加防范地在常规工作站上运行 OpenClaw,它将变成一个极具杀伤力的“高权内鬼”。本文将深入剖析自托管 Agent 的核心安全风险,并为决定进行技术评估的团队提供一套底线级安全运营指南。
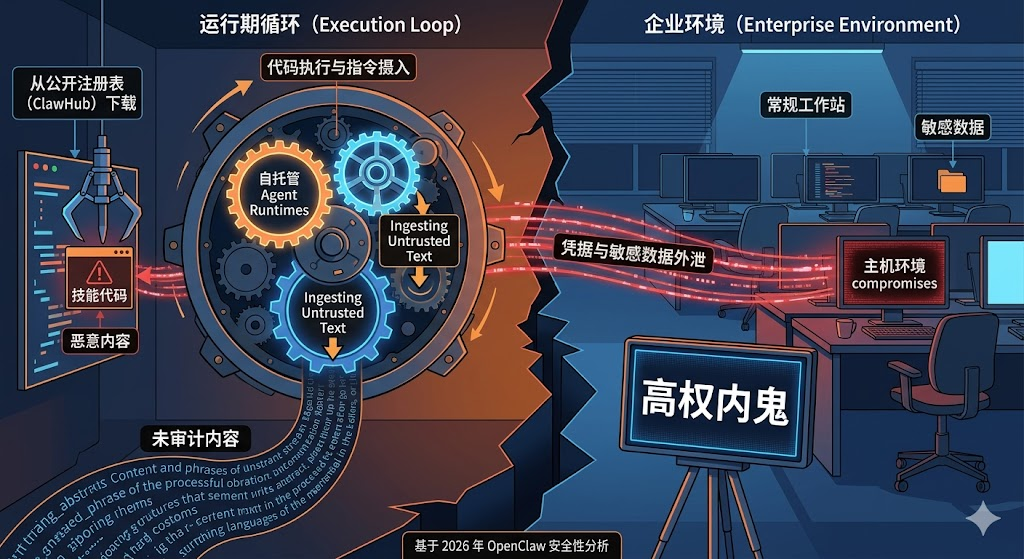
一、 安全边界的失控:自托管 Agent 的三大致命风险
在传统的企业自动化中,实体做什么、怎么做,是由开发人员编写的硬编码决定的。但在 OpenClaw 的运行期循环中,执行决策被交给了动态输入和外部代码。这种架构的转变会导致三个风险在短时间内集中爆发:
1. 凭据与敏感数据外泄
OpenClaw 在运行时需要被赋予各种持久化凭据(如 SaaS API、代码仓库权限、邮箱访问权等)。一旦其在执行任务(如读取网页、总结外部邮件)时遭遇恶意攻击者设计的 Prompt,就极易发生“越权操作”,导致其在不知不觉中利用合法 API 将缓存的身份令牌或企业核心机密打包外泄。
2. 持久化记忆的慢性污染
与用完即走的普通大模型不同,OpenClaw 会维护持久化的“记忆状态”。攻击者可以通过间接提示词注入(Indirect Prompt Injection),向 Agent 注入恶意指令。这些指令会固化在它的长期记忆中,导致它在未来的运行中持续遵循攻击者的意图,甚至在数周后才触发高危行为。
3. 主机环境被直接攻破
OpenClaw 具备完整的 Shell 执行和文件操作权限。如果它被诱导下载并运行了一个恶意的“技能(Skill)”,这就等同于在你的机器上直接运行了一个未经审计的第三方恶意程序。攻击者可以轻易提取 SSH 密钥、修改系统配置或植入后门。
二、 场景演练:一颗“有毒技能”的完美潜伏
公开报告显示,第三方注册中心已经出现了直接打包好恶意代码的“毒技能”。以下是其在缺乏审计的环境下的典型攻击链条:
-
第一步:发布与伪装 攻击者在公共市场上发布一个看似非常有用的实用工具插件(例如一个自动同步日程或自动发推的技能),甚至将其公开挂马,利用快速迭代的技术生态诱导缺乏警惕性的开发人员下载。
-
第二步:无感安装 在缺乏人工审核机制的权限配置中,开发人员或 Agent 自身在尝试解决某一任务时,会直接触发该技能的下载与静默安装。
-
第三步:状态与凭据窃取 该技能运行后,第一目标并不是系统内核,而是 OpenClaw 的工作区。它会扫描配置文件,窃取其中缓存的各种 API Key、OAuth 令牌、配置数据以及历史对话转录。
-
第四步:合法 API 的滥用 由于拿到了合法的身份憑据,攻击者无需使用黑客工具,直接调用标准企业 API 执行数据外流或越权操作。这种行为在日志中通常表现得像合法的自动化办公。
-
第五步:长期潜伏与固化 攻击者会通过修改 Agent 的常驻配置文件或计划任务,为自己申请长期的 OAuth 授权或设定定时执行脚本。即使你发现了单次异常,只要不重新格式化 Agent 的状态,他就拥有长期的控制通道。
三、 底线防线:OpenClaw 的最低安全运行姿势
基于上述特性,在当前阶段,绝对不能在个人办公电脑或包含敏感数据的企业主工作站上直接运行 OpenClaw。 如果企业因业务需要必须对其进行评估,必须将其视为“具备持久凭据的未知第三方代码执行”,并严格落地以下防线:
1. 绝对的运行期隔离
只能将 OpenClaw 部署在完全隔离的专用虚拟机(VM)或独立的物理硬件上。该环境必须与企业核心内网隔离,并将其视为“一次性沙盒”,随时做好格式化销毁的准备。
2. 专用身份与脱敏数据
为 Agent 创建完全独立的、权限最小化的测试账号。严禁使用个人的主工作账户。限制其能够触及的数据资产,且必须假设这些账号随时可能被攻破,做好定期轮换凭据的准备。
3. 状态与配置的定期审计
必须对 Agent 的工作区目录(如 .openclaw/)进行持续监控。定期审查其保存的长期指令、新信任的源以及行为转录,检查是否出现了非预期的行为规则或配置漂移。
4. 建立“以重建为常态”的运营模型
充分利用 OpenClaw 本身的状态备份与恢复机制:
-
仅备份 .openclaw/workspace/ 可以保留工作进度而不附带敏感凭据。
-
出现任何异常流量、异常 Shell 派生(如突然拉起 curl、wget 或执行非预期的 bash 命令)或未知监听端口(如默认网关端口异常暴露)时,不要尝试人工清理漏洞,必须立即吊销凭据、断开网络并启动环境重构。
结尾
自托管 AI Agent 的本质,是把原本属于静态代码的执行权,交给了由不确定性输入驱动的 LLM 循环。这不仅是一个配置选项的问题,更是一个高风险的信任决定。
在 2026 年的当前技术成熟度下,对大多数缺乏专职安全运维和深度沙盒隔离能力的团队而言,最明智的选择是暂缓在生产或主干网络中部署此类工具。如果必须涉足,请务必放弃传统的“防御与免疫”幻想,将策略转向“彻底隔离、深度监控、随时重构”。在将鼠标控制权移交给 AI 之前,先筑起收紧其活动范围的高墙。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)