LangGraph Reducer 深度应用:为什么你的 State 合并总是出问题?
这篇文章帮你搞定 LangGraph Reducer 的高级用法,从源码解析到生产级模式,从并发安全到测试策略
这篇文章帮你搞定 LangGraph Reducer 的高级用法,从源码解析到生产级模式,从并发安全到测试策略
阅读提示
- 适合谁看:已读过 State 设计模式基础,想深入 Reducer 机制的工程师
- 看完能做什么:能实现生产级 Reducer,处理复杂的 State 合并场景
- 不适合谁:还没了解 Reducer 基础概念的纯新手
先给结论
- Reducer 不是"合并函数",而是"定义 State 语义的核心机制"
add_messages基于message_id去重,不是简单的列表拼接- 生产级 Reducer 必须考虑:幂等性、线程安全、版本兼容
01 add_messages 源码解析:不只是列表拼接
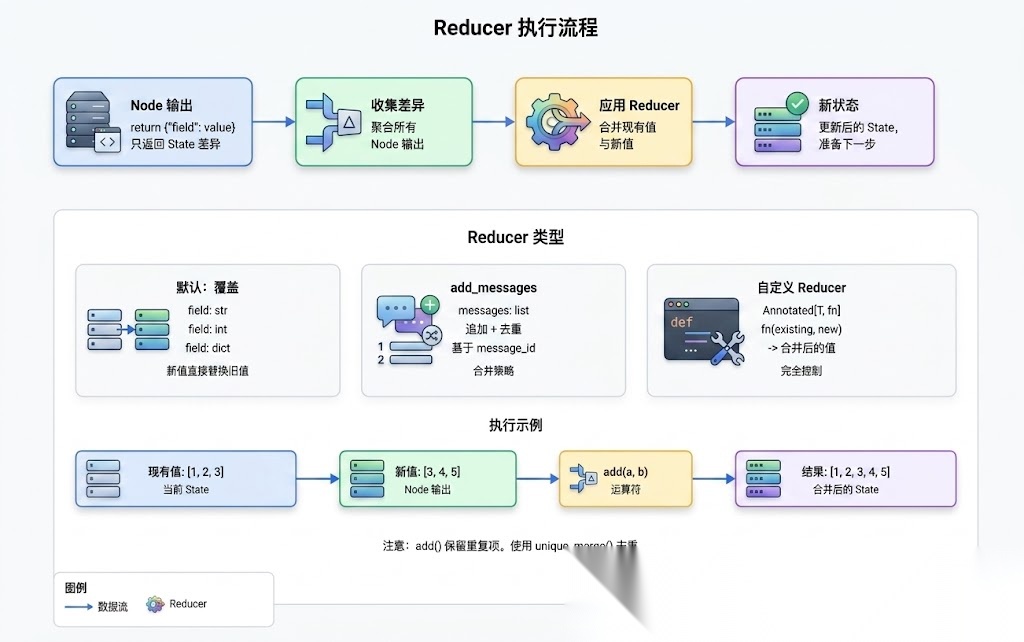
很多人以为 add_messages 就是 list.extend(),其实它做了更多事情。
完整实现
from langgraph.graph.message import add_messagesfrom langchain_core.messages import BaseMessagefrom typing import List, Sequence, Union# add_messages 的生产级实现(简化版)def add_messages( left: Sequence[BaseMessage], right: Union[Sequence[BaseMessage], BaseMessage]) -> List[BaseMessage]: """合并消息列表,基于 message_id 去重 行为: 1. 右侧消息追加到左侧 2. 相同 id 的消息会被更新(不是重复) 3. 保持消息的时间顺序 """ # 规范化输入 if isinstance(right, BaseMessage): right = [right] # 转换为字典,基于 id 去重 left_map = {msg.id: msg for msg in left} # 合并右侧消息 for msg in right: left_map[msg.id] = msg # 相同 id 会覆盖 # 保持原始顺序 return list(left_map.values())
关键洞察:基于 id 去重
from langchain_core.messages import HumanMessage, AIMessage# 示例:相同 id 的消息会被更新msg1 = HumanMessage(content="hello", id="msg-1")msg2 = AIMessage(content="hi", id="msg-2")msg3 = HumanMessage(content="hello updated", id="msg-1") # 同一个 idexisting = [msg1, msg2]new = [msg3]result = add_messages(existing, new)# 结果: [msg1_updated, msg2]# msg3 替换了 msg1(因为 id 相同)
为什么这样设计? 因为在多轮对话中,消息可能会被重新生成(比如 LLM 重试),需要用 id 来标识同一条消息。
02 Reducer 与 Annotated 的交互机制
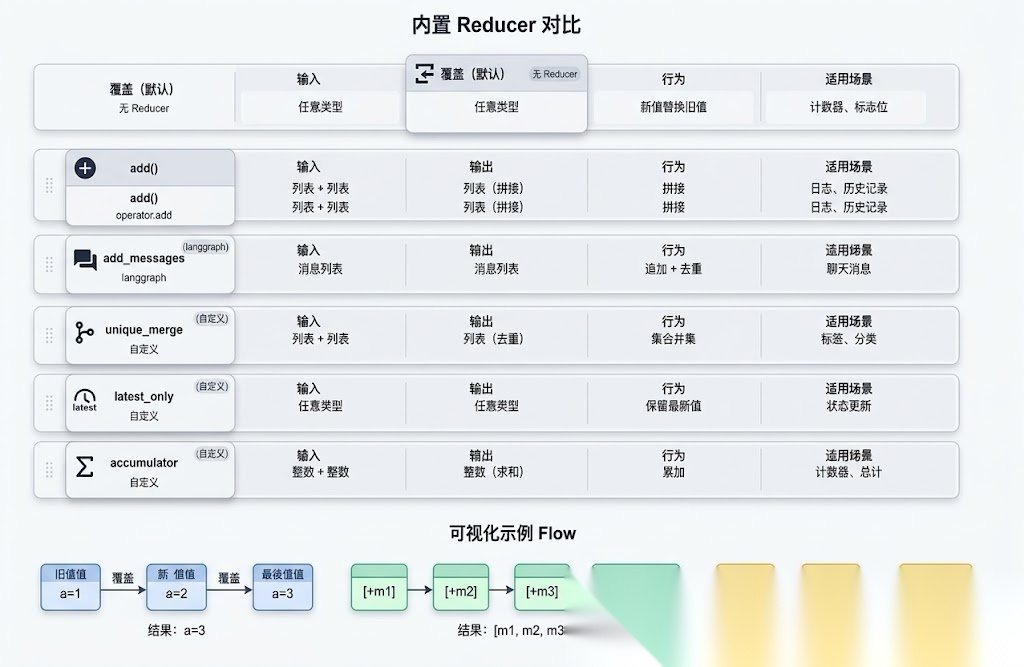
Annotated 的第二个参数就是 Reducer。但很多人不理解这个机制是怎么工作的。
底层原理
from typing import Annotated, get_type_hints, get_args# LangGraph 内部如何提取 Reducer(简化版)def extract_reducer(state_class): """从 State 类中提取 Reducer""" reducers = {} for field_name, field_type in state_class.__annotations__.items(): if hasattr(field_type, '__metadata__'): # Annotated 类型,提取 Reducer metadata = field_type.__metadata__ if len(metadata) >= 2: reducers[field_name] = metadata[1] # 第二个参数是 Reducer return reducers# 使用示例class AgentState(TypedDict): messages: Annotated[list, add_messages] # Reducer 是 add_messages count: Annotated[int, lambda old, new: old + new] # Reducer 是 lambdareducers = extract_reducer(AgentState)# reducers = {# "messages": add_messages,# "count": <lambda># }
Reducer 的调用时机
# LangGraph 内部执行流程(简化版)class StateManager: def __init__(self, state_class): self.reducers = extract_reducer(state_class) self.state = {} def apply_update(self, node_output: dict): """应用 Node 输出,使用 Reducer 合并""" for key, value in node_output.items(): if key in self.reducers: # 有 Reducer,调用 Reducer 合并 reducer = self.reducers[key] self.state[key] = reducer( self.state.get(key), # 现有值 value # 新值 ) else: # 没有 Reducer,直接覆盖 self.state[key] = value
03 生产级 Reducer 模式
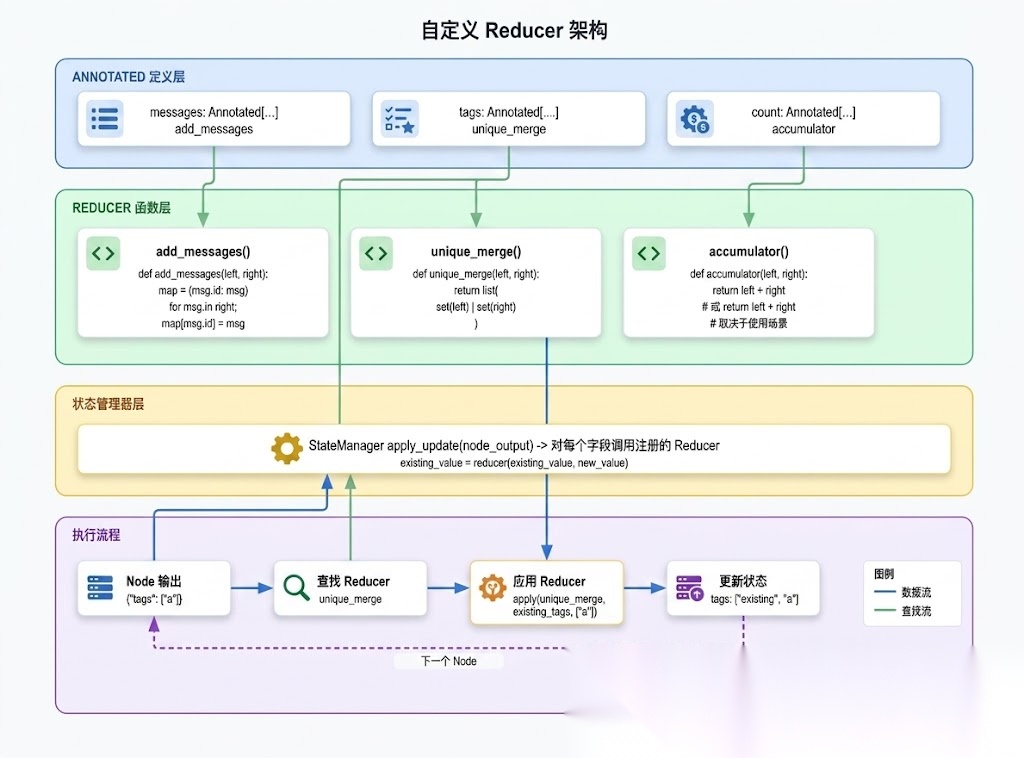
图 3|Custom Reducer Architecture
模式 1:条件更新
def conditional_update(existing: dict, new: dict, only_if_exists: bool = True) -> dict: """条件更新:只更新已存在的字段""" if only_if_exists: return {k: v for k, v in new.items() if k in existing} return {**existing, **new}# 在 State 中使用class AgentState(TypedDict): config: Annotated[dict, lambda old, new: conditional_update(old, new, only_if_exists=True)]
模式 2:带版本控制
def versioned_merge(existing: dict, new: dict) -> dict: """带版本号的合并:只接受更高版本""" if new.get("version", 0) > existing.get("version", 0): return new return existing# 在 State 中使用class AgentState(TypedDict): config: Annotated[dict, versioned_merge]
模式 3:深度合并
def deep_merge(existing: dict, new: dict) -> dict: """深度合并:递归合并嵌套字典""" result = existing.copy() for key, value in new.items(): if key in result and isinstance(result[key], dict) and isinstance(value, dict): result[key] = deep_merge(result[key], value) else: result[key] = value return result# 在 State 中使用class AgentState(TypedDict): config: Annotated[dict, deep_merge]
04 并发安全:生产环境必须考虑
import threadingfrom typing import Any# ❌ 危险:非线程安全的 Reducerclass UnsafeReducer: def __init__(self): self.cache = {} # 共享状态 def __call__(self, existing: Any, new: Any) -> Any: # 多线程同时访问 cache 会导致数据竞争 key = str(existing) + str(new) if key notin self.cache: self.cache[key] = existing + new return self.cache[key]# ✅ 安全:无状态 Reducer(推荐)def safe_reducer(existing: Any, new: Any) -> Any: """无状态 Reducer:不依赖外部变量""" return existing + new# ✅ 安全:带锁的 Reducer(需要缓存时)class ThreadSafeReducer: def __init__(self): self.lock = threading.Lock() self.cache = {} def __call__(self, existing: Any, new: Any) -> Any: with self.lock: key = str(existing) + str(new) if key notin self.cache: self.cache[key] = existing + new return self.cache[key]
并发安全检查清单:
| 检查项 | 说明 |
|---|---|
| 无全局变量 | Reducer 不应该依赖 global 变量 |
| 无共享状态 | Reducer 不应该有实例变量(除非加锁) |
| 无 I/O 操作 | Reducer 不应该读写文件、网络等 |
| 纯函数 | 相同输入相同输出,无副作用 |
05 Reducer 测试策略
import pytestclass TestReducer: """Reducer 测试套件""" def test_basic_merge(self): """测试基本合并""" reducer = unique_merge result = reducer([1, 2], [2, 3]) assert result == [1, 2, 3] def test_idempotent(self): """测试幂等性:多次调用结果相同""" reducer = unique_merge result1 = reducer([1, 2], [3]) result2 = reducer(result1, [3]) # 重复添加 assert result1 == result2 def test_type_preservation(self): """测试类型保持:输入输出类型相同""" reducer = unique_merge existing = [1, 2] new = [3] result = reducer(existing, new) assert type(result) == type(existing) def test_empty_input(self): """测试空输入""" reducer = unique_merge result = reducer([], [1, 2]) assert result == [1, 2] result = reducer([1, 2], []) assert result == [1, 2] def test_concurrent_safety(self): """测试并发安全""" import threading reducer = ThreadSafeReducer() results = [] def run_reducer(): for _ in range(100): result = reducer([1], [2]) results.append(result) threads = [threading.Thread(target=run_reducer) for _ in range(10)] for t in threads: t.start() for t in threads: t.join() # 所有结果应该相同 assert all(r == [1, 2] for r in results)
06 最小实验:跑通一个生产级 Reducer
实验条件
- 环境:Python 3.11 + langgraph 1.1.10
- 输入:一个使用深度合并 Reducer 的 Agent
- 预期观察:嵌套字典正确合并
代码 1
from langgraph.graph import StateGraph, MessagesState, START, ENDfrom langgraph.checkpoint.memory import MemorySaverfrom typing import Annotated, TypedDict# 深度合并 Reducerdef deep_merge(existing: dict, new: dict) -> dict: result = existing.copy() for key, value in new.items(): if key in result and isinstance(result[key], dict) and isinstance(value, dict): result[key] = deep_merge(result[key], value) else: result[key] = value return result# 定义 Stateclass AgentState(TypedDict): messages: Annotated[list, add_messages] config: Annotated[dict, deep_merge]# 定义 Nodedef update_config(state: AgentState): return {"config": {"llm": {"model": "gpt-4", "temperature": 0.7}}}def update_more_config(state: AgentState): # 应该深度合并,而不是覆盖 return {"config": {"llm": {"max_tokens": 1000}, "timeout": 30}}# 构建图graph = StateGraph(AgentState)graph.add_node("update_config", update_config)graph.add_node("update_more_config", update_more_config)graph.add_edge(START, "update_config")graph.add_edge("update_config", "update_more_config")graph.add_edge("update_more_config", END)# 运行checkpointer = MemorySaver()app = graph.compile(checkpointer=checkpointer)config = {"configurable": {"thread_id": "user-123"}}result = app.invoke({"messages": [], "config": {}}, config)# 验证:config 应该深度合并print(result["config"])# 预期: {"llm": {"model": "gpt-4", "temperature": 0.7, "max_tokens": 1000}, "timeout": 30}assert"model"in result["config"]["llm"] # 保留了 modelassert"max_tokens"in result["config"]["llm"] # 添加了 max_tokensassert result["config"]["timeout"] == 30# 添加了 timeout
如果结果不符合预期,先看哪里
- 检查 Reducer 是否递归处理嵌套字典
- 检查是否使用了
existing.copy()避免修改原对象 - 检查 Annotated 的参数顺序是否正确
07 调试 Reducer:快速定位问题
def debug_reducer(reducer, existing, new): """调试 Reducer""" print(f"Input: existing={existing}, new={new}") try: result = reducer(existing, new) print(f"Output: {result}") print(f"Type preserved: {type(existing) == type(result)}") return result except Exception as e: print(f"ERROR: {e}") return None
常见问题排查:
| 问题 | 现象 | 排查步骤 |
|---|---|---|
| 类型丢失 | 恢复后类型变了 | 检查 Reducer 是否返回正确类型 |
| 数据丢失 | 字段被覆盖 | 检查是否用了覆盖而不是合并 |
| 并发错误 | 数据不一致 | 检查 Reducer 是否线程安全 |
| 内存泄漏 | 内存持续增长 | 检查是否有缓存未清理 |
08 什么时候该用,什么时候别急着上
更适合自定义 Reducer:
- 嵌套字典需要深度合并
- 需要去重(tags, categories)
- 需要版本控制(配置更新)
- 需要条件更新(只更新存在的字段)
不需要自定义 Reducer:
- 简单覆盖(counters, flags)
- 使用
add_messages(聊天消息) - 开发环境(用默认覆盖)
3 问判断法
- 你的字段是否需要合并(而不是覆盖)?
- 合并时是否需要去重或深度合并?
- 是否有并发写入的场景?
如果 3 个问题大多是否定,先用默认覆盖。
09 给读者一个真正能用来做决策的结论
决策帮助
- 如果你是个人项目:用
add_messages或unique_merge,够用就行- 如果你是小团队 PoC:用
deep_merge或versioned_merge,处理复杂场景- 如果你是生产系统:必须做并发安全测试 + 幂等性测试
Reducer 设计的核心原则:
- 纯函数:无副作用,相同输入相同输出
- 线程安全:支持并发调用
- 类型一致:输入输出类型相同
- 幂等性:多次调用结果相同
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 10
10 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)