万字图文:从 Function Calling 到 MCP 再到 Skills:AI 工具调用的三次进化
上期小编挖了个坑——"后面会单独出一个系列介绍工具调用"。坑挖太久容易塌,所以这期赶紧来填。本文带你一口气搞懂 AI 工具调用的三代技术演进:Function Calling → MCP → Agent Skills。看完你就明白,为什么给 AI "装手脚" 这件事,比你想的复杂得多。万字长文,建议收藏。
导读: 上期小编挖了个坑——“后面会单独出一个系列介绍工具调用”。坑挖太久容易塌,所以这期赶紧来填。本文带你一口气搞懂 AI 工具调用的三代技术演进:Function Calling → MCP → Agent Skills。看完你就明白,为什么给 AI “装手脚” 这件事,比你想的复杂得多。万字长文,建议收藏。
一、填坑来了:为什么"工具调用"值得单独写一篇
“后面小编会单独出一个系列介绍工具调用,这里先挖个坑。”
说实话,小编本来想挖着坑慢慢填。但后来发现——这个坑越不填越大。因为最近一年,工具调用领域发生了太多事:
- • Anthropic 发布了 MCP 协议,整个行业跟进
- • OpenAI、Google、微软都宣布支持 MCP
- • Claude Code 引入了 Skills 机制,改变了"工具 vs 知识"的边界
- • 社区开始争论:MCP 是不是过度工程?Function Calling 是不是就够了?
小编想了想,与其分几期零散讲,不如一篇文章把三代技术全部捋清楚。
你只需要记住一条主线:
Function Calling → MCP → Agent Skills (硬连接) (标准接口) (操作手册)
好,开始。
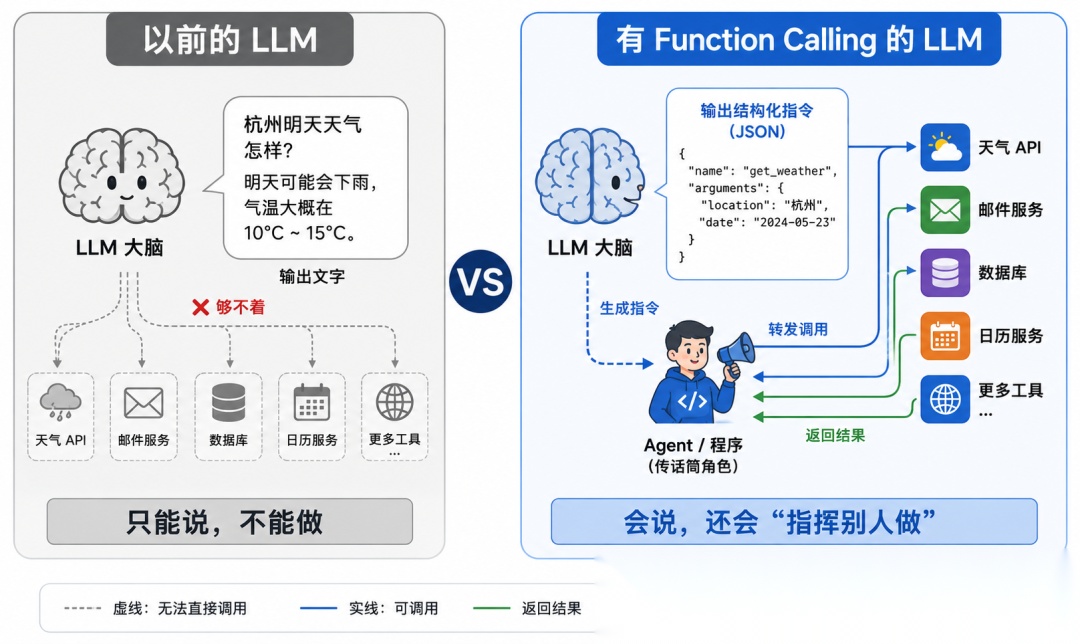
二、Function Calling:AI 从"只会说"到"能动手"
2.1 它解决了什么问题
在 Function Calling 出现之前,LLM 就是一个**“缸中之脑”**——它能推理、能聊天,但:
- • 不知道现在几点
- • 不知道今天天气
- • 不能发邮件
- • 不能查数据库
- • 不能操作任何真实系统
说白了:它有脑子没有手。
💡 一句话定义:Function Calling 让 LLM 学会了"下达结构化指令"——它不直接执行任务,而是告诉你的程序"我想调用哪个函数、传什么参数"。
小编给你打个比方:
想象一个坐在轮椅上的天才指挥官。他不能自己冲锋陷阵,但他可以精确地下达命令:“3 号士兵,用步枪,朝东南方向 200 米的目标射击。”
Function Calling 就是这个"精确下达命令"的能力。模型是指挥官,你的代码是士兵。
2.2 它是怎么工作的——三步走
早期的"工具调用"依赖 Prompt Engineering——开发者苦口婆心地写:“请务必返回 JSON 格式,不要多说废话。”
结果呢?模型经常"抽风",一会儿返回 JSON,一会儿返回散文,程序解析直接崩。
OpenAI 引入 Function Calling 后,把这个过程变成了严格的三步规范。
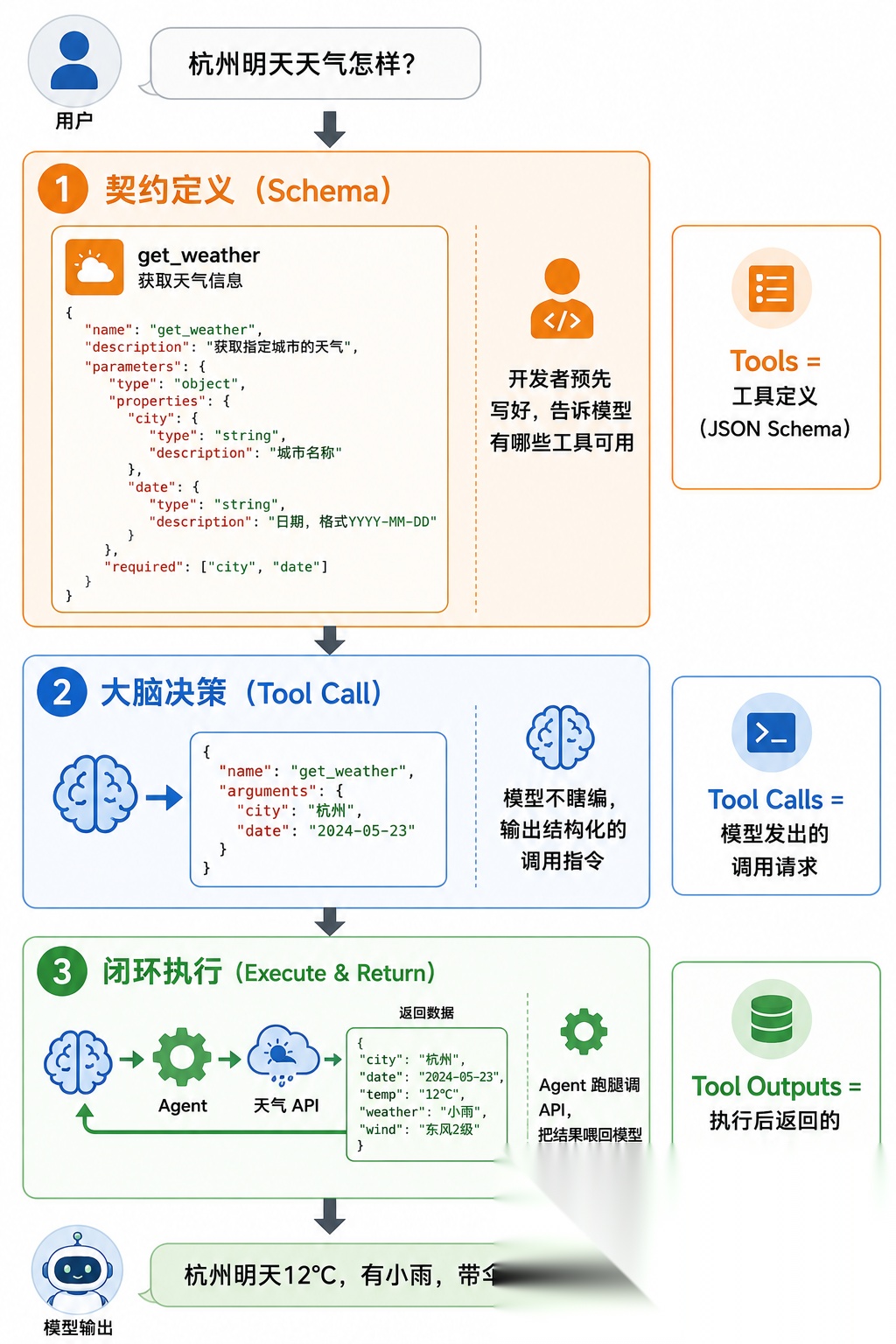
小编用一个场景带你走一遍:你问 Agent:“查一下杭州明天天气”
第一步:契约定义(Schema)——给模型一份"说明书"
开发者预先定义好工具的"名片"——用 JSON Schema 说清楚:
{ "name":"get_weather","description":"查询指定城市的天气预报","parameters":{ "type":"object", "properties":{ "city":{ "type":"string", "description":"城市名称,如 Hangzhou" } }, "required":["city"]}}
这张"名片"告诉模型:我这里有个工具叫 get_weather,你想用它就必须给我一个 city 参数。
第二步:大脑决策——模型下达"订单"
你问"杭州明天天气怎样",模型一看:
- • 我自己没有实时天气数据
- • 但我有一个
get_weather工具可以用 - • 用户提到了"杭州"
于是它不再瞎编,而是输出一份精确的"调用请求":
{ "name": "get_weather", "arguments": "{\"city\": \"Hangzhou\"}"}
注意:此时模型没有联网,没有调 API。它只是精准地提炼了你的意图,翻译成了结构化指令。
第三步:闭环执行——Agent 跑腿 + 模型回复
你的 Agent 程序收到这个 JSON,去调真正的天气 API:
→ 调用 weather_api("Hangzhou")← 返回:"12°C,小雨"
然后把结果塞回给模型。模型拿到真实数据后,组织一段自然语言:
“杭州明天 12°C,有小雨,记得带伞哦~”
整个过程用一张图总结:
你:"杭州明天天气" ↓模型决策:我要调用 get_weather(city="Hangzhou") ↓Agent 执行:调用真实 API → 得到 12°C/小雨 ↓模型回复:"杭州明天12°C,有小雨,带伞"
2.3 Function Calling 的局限
Function Calling 很好,但当你的工具从 3 个变成 30 个、甚至 300 个时——问题来了。
小编自己经历过:
问题 1:重复造轮子
你给 Claude 写了一套工具定义,给 GPT-4 又要重写一遍,给 Gemini 再来一遍。格式不同、字段名不同、行为不同。三个模型三套代码,维护成本爆炸。
问题 2:紧耦合
工具定义硬编码在代码里。换个模型?全部重写。换个应用场景?全部重写。想让别人复用你的工具?把代码 copy 给他。
问题 3:工具描述占上下文
每个工具的 JSON Schema 都要塞进上下文窗口。工具一多,光工具描述就占了几千个 Token——留给真正对话的空间就少了。
“Function Calling 就像有线耳机——好用,但每台设备都要买一根专用线。”
这时候你就会想:能不能有个"标准接口",写一次工具,到处都能用?
这就是 MCP 要解决的问题。
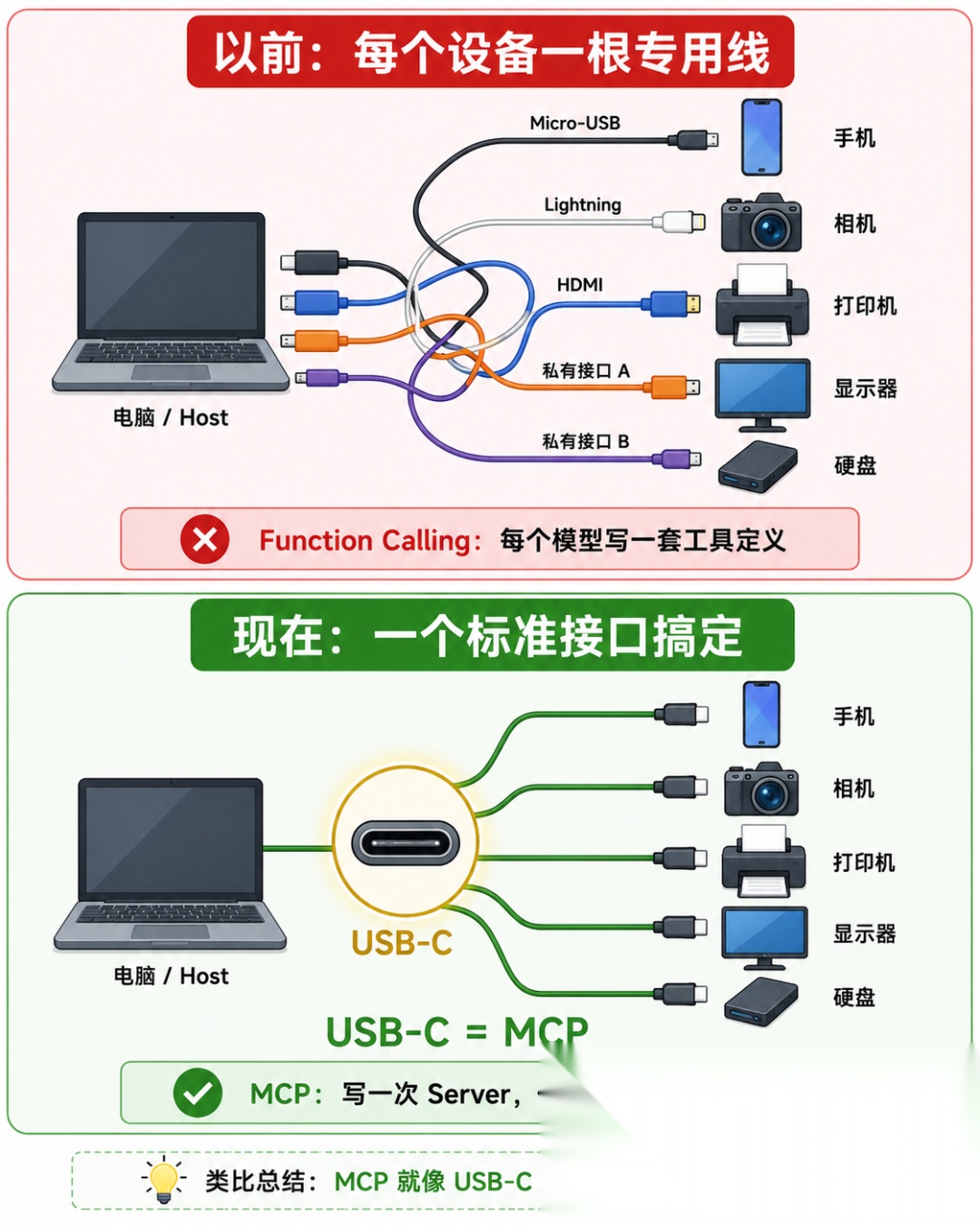
三、MCP:AI 世界的"USB-C 接口"
3.1 它是什么
💡 一句话定义:MCP(Model Context Protocol,模型上下文协议)是 Anthropic 推出的一套开放协议,让 AI 应用可以通过标准化接口连接任何外部工具和数据源——写一次,到处用。
2024 年 11 月,Anthropic 正式发布了 MCP 协议。他们给出的类比是:
MCP 之于 AI 工具,就像 USB-C 之于硬件设备。
以前每个手机充电器都不一样(Micro-USB、Lightning、各种私有接口),USB-C 一出来——一根线搞定所有设备。
MCP 做的是同样的事:以前每个 AI 应用(Claude、GPT、Cursor)接工具都要单独写代码;有了 MCP——写一个 MCP Server,所有支持 MCP 的应用都能直接接入。
3.2 MCP 的三层架构:Host / Client / Server
MCP 不是一个工具,它是一套通信协议。要理解它怎么工作,你得先知道三个角色:
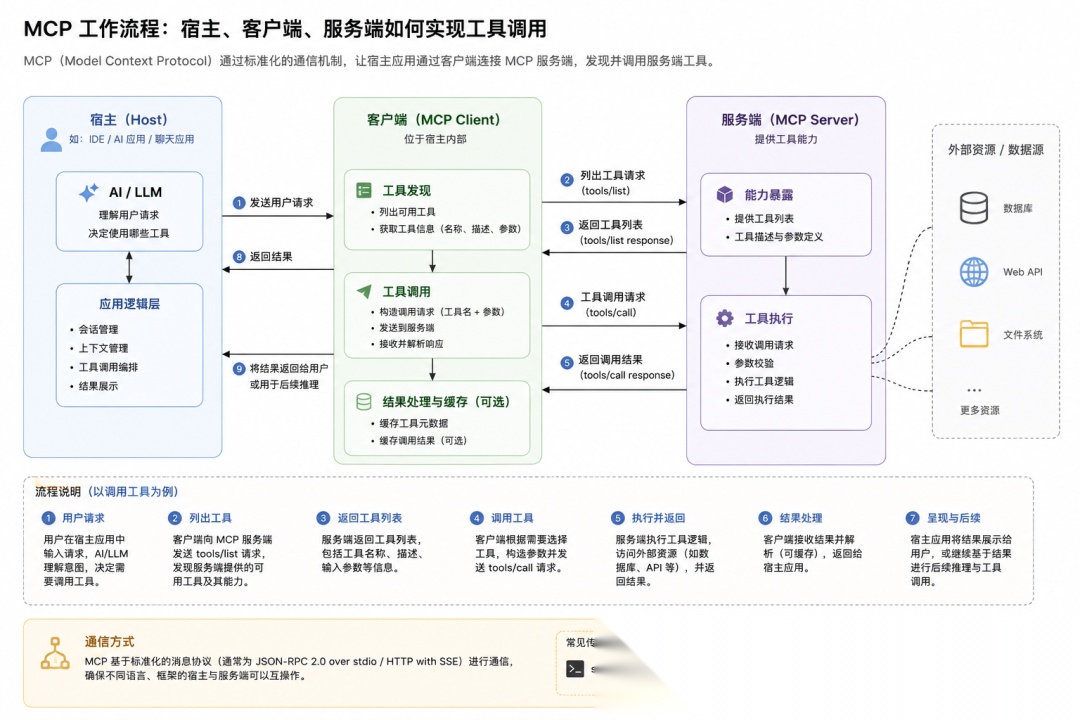
小编用一个类比帮你记住:
- • Host(宿主)= 你家的电脑。它运行 AI 应用,管理所有连接。
- • Client(客户端)= 电脑上的 USB 接口。每个接口对接一个外设。
- • Server(服务端)= 外接设备。键盘、鼠标、硬盘——各管各的功能。
一个 Host 可以连多个 Server。每个 Server 独立提供能力。互不干扰。
3.3 MCP 是怎么通信的
两种传输方式:
| 方式 | 使用场景 | 大白话 |
| stdio(标准输入输出) | 本地server,跑在你自己的电脑上 | 像两个人面对面说话,不用网络 |
| sse/http | 远程server,跑在云端 | 像打电话,通过网络连接 |
通信协议是 JSON-RPC 2.0——说白了就是"用 JSON 格式发消息,按规范办事"。
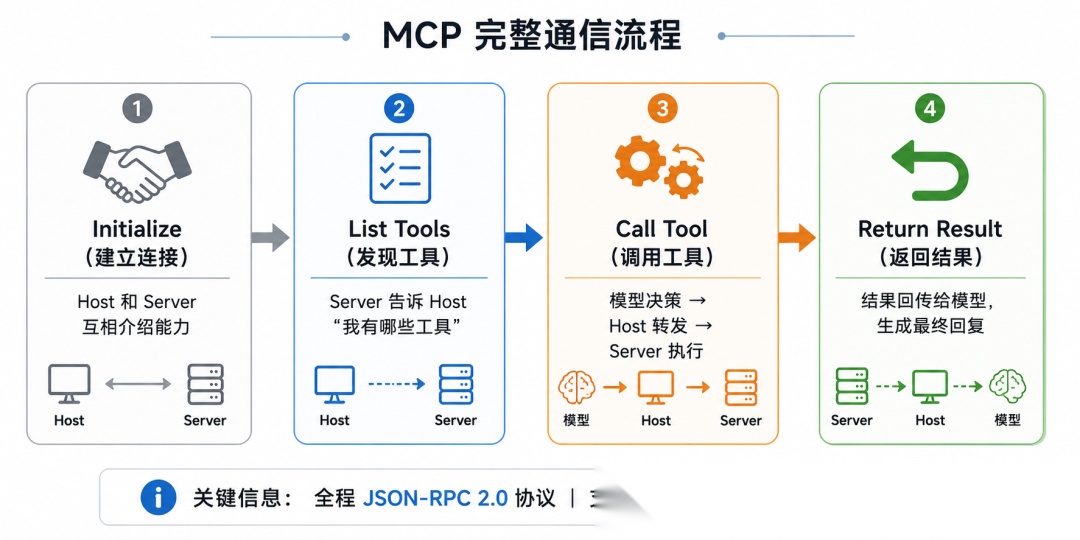
3.4 MCP 的完整工作流
小编用"杭州天气"这个例子,走一遍 MCP 的全流程:
第一步:建立连接(Initialize)
Claude Desktop(Host)启动时,看到配置里有一个天气 MCP Server。于是:
Host → Server:"你好,我是 Claude Desktop,你能干啥?"Server → Host:"我能查天气(get_weather),也能查空气质量(get_air_quality)"
双方握手完成,Host 知道了 Server 有哪些能力。
第二步:发现工具(List Tools)
Host 把 Server 提供的工具列表注入到 LLM 的系统提示词中。现在模型"看到"了:
你有以下工具可用:- get_weather(city: string):查询城市天气- get_air_quality(city: string):查询空气质量
第三步:调用工具(Call Tool)
你问"杭州天气",模型决定调用 get_weather:
模型 → Host:"我想调 get_weather,参数 city=Hangzhou"Host → Client → Server:转发调用请求Server:调真实 API,拿到结果Server → Client → Host → 模型:返回"12°C,小雨"
和 Function Calling 有什么不同? 核心区别在于:
| 维度 | Function Calling | MCP |
| 工具定义在哪 | 硬编码在你代码里 | 独立的server 进程 |
| 换个AI应用 | 重写一遍 | 直接接入,不用改 |
| 别人写的工具 | 复制代码到你项目 | 加个server配置就行 |
| 工具更新了 | 该你的代码 | server自己更新,你不用动 |
3.5 MCP 的三大能力
MCP Server 不只能提供"工具",它实际上有三种能力:
| 能力 | 谁来决定使用 | 大白话 | 类比 |
| Tool(工具) | 模型自主决定调用 | “我能帮你干活”–查天气、发邮件、写文件 | 你桌子上的计算器–你觉得你需要就拿起来用 |
| Resourses(资源) | 应用程序决定注入 | “我有数据给你看”–数据库内容、文件列表 | 领导放你桌子上的参考资料–不是你选的,但是你得看 |
| Prompts(提示模版) | 用户主动选择 | “我又现成的流程”–一键启动特定的工作流 | 用户点击一个“快捷操作”按钮 |
小编觉得这个设计挺聪明的:不是所有东西都让模型自己决定用不用。有些信息是应用自动塞进去的(Resources),有些是用户手动触发的(Prompts)。**分层控制,避免模型"瞎调用"。**
3.6 MCP 的生态有多火
自 2024 年底发布以来,MCP 的生态增长速度超乎想象:
- • 主流大厂全面跟进:Google(Gemini)、OpenAI、微软(VS Code、Copilot)、AWS、Cloudflare 先后宣布支持
- • 第三方 Server 爆发:GitHub、Stripe、Linear、Slack、Notion、Postgres、Docker 等都发布了官方 MCP Server
- • 开发工具原生支持:Cursor、Windsurf、Claude Code、Zed 等 AI 编辑器已原生集成 MCP
- • MCP Registry:社区搭建了中央发现仓库,开发者可以搜索、安装、发布 MCP Server
- • 远程 MCP:Cloudflare Workers 等平台支持将 MCP Server 部署为 Serverless 函数,无需本地运行
小编自己体验下来——MCP 最香的地方是:别人写好的 Server,你加一行配置就能用。
比如要让你的 Agent 操作 GitHub?以前要自己写 GitHub API 封装代码,现在:
{ "mcpServers":{ "github":{ "command":"npx", "args":["-y","@modelcontextprotocol/server-github"], "env":{"GITHUB_TOKEN":"your-token"} }}}
加这么一段配置,Agent 就能创建 PR、查看 Issue、管理仓库了。零开发成本。
这就是"标准化"带来的生态红利——一个人写,所有人用。
四、MCP 出来后,Function Calling 是不是就过时了?
这个问题最近社区争论很热闹。小编先说结论:
没过时。两者是不同层面的解决方案,各有适用场景。
4.1 一个"反常"的案例:龙虾 Agent(OpenClaw)
2025 年有一个现象级的开源项目叫 OpenClaw(中文名:龙虾),做的是本地个人 Agent。
有意思的是——它明确选择了回归 Function Calling,没有用 MCP。
这是在开"历史倒车"吗?
小编研究了他们的设计文档,总结出两个核心原因:
原因 1:开发成本
MCP 需要单独启动 Server 进程,涉及生命周期管理(连接、握手、心跳、断线重连)。
对于一个本地 Agent 就用 5-10 个工具的场景——这太重了。
MCP 方式: 启动 Server A 进程 → 启动 Server B 进程 → 握手 → 注册工具 → 调用 → 管理心跳...Function Calling 方式: 定义 JSON Schema → 写业务逻辑函数 → 搞定
说白了:"能跑就行"远比"符合国际协议"重要。 对很多独立开发者来说,这是大实话。
原因 2:性能延迟
MCP 在动态拉取工具列表(list_tools)时会消耗额外的 Token 和往返时间。在生产环境中,如果工具列表是固定的——
直接把 Function 定义写死在 Prompt 里,速度更快、更省钱。
小编实测过:MCP 的 stdio 模式每次调用多了大约 50-100ms 延迟。单次不明显,但如果一个任务需要连续调 20 次工具——这就是 1-2 秒的额外等待。
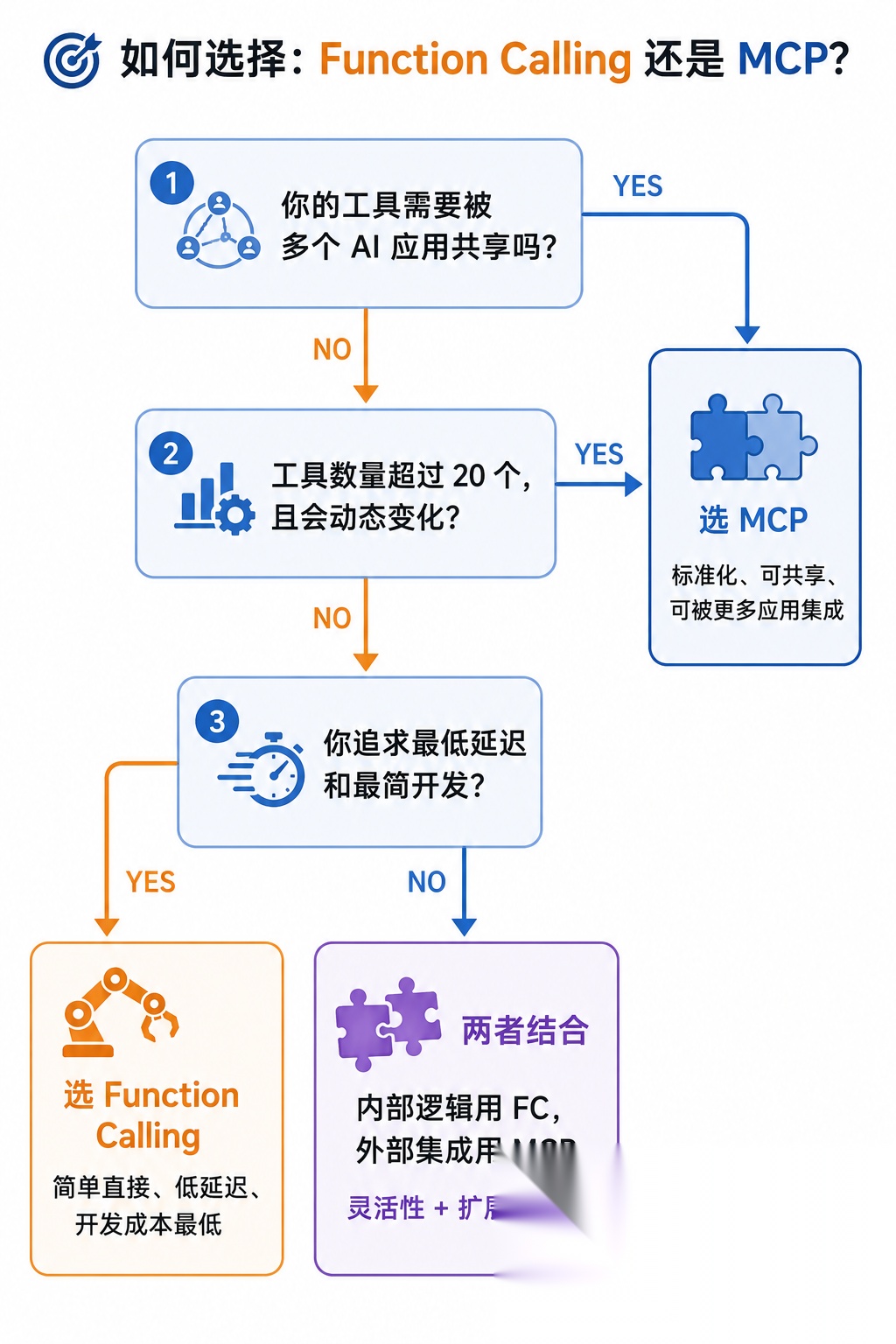
4.2 那什么时候该用 MCP?
| 场景 | function calling | MCP |
| 工具数量少(<10个)且固定不变 | ✅ | 过度工程 |
| 你只是一个模型/应用 | ✅ | 不需要标准化 |
| 追求极致的延迟 | ✅ | 有额外开销 |
| 工具被多个应用共享 | 不够用 | ✅ |
| 工具由第三方提供 | 自己重写?累,不稳定 | ✅ 直接接入 |
| 工具列表动态变化 | 硬编码,不稳定 | ✅动态发现 |
| 需要安全隔离(server独立进程) | 自己做隔离 | ✅天然隔离 |
一句话总结:"MCP 是工具的**分发方案**,Function Calling 是工具的**集成方案**。分发给全世界用 MCP,自己内部用 Function Calling 就够了。"
五、Agent Skills:比"能连接"更重要的是"会使用"
5.1 MCP 的两个痛点
MCP 解决了"标准化连接"的问题。但小编在实际使用中发现了两个新问题:
痛点 1:上下文爆炸
一个 MCP Server 可能暴露几十甚至上百个工具。这些工具的完整 JSON Schema 在连接建立时就会被加载到系统提示词中。
社区开发者实测数据:仅加载一个 Playwright MCP Server 就占用了 200K 上下文窗口的 8%。
你接 3-5 个 Server?20-40% 的上下文就被工具描述占了。留给真正对话的空间严重压缩。
在多轮对话中,这个问题更严重——Token 成本飙升,推理能力下降。
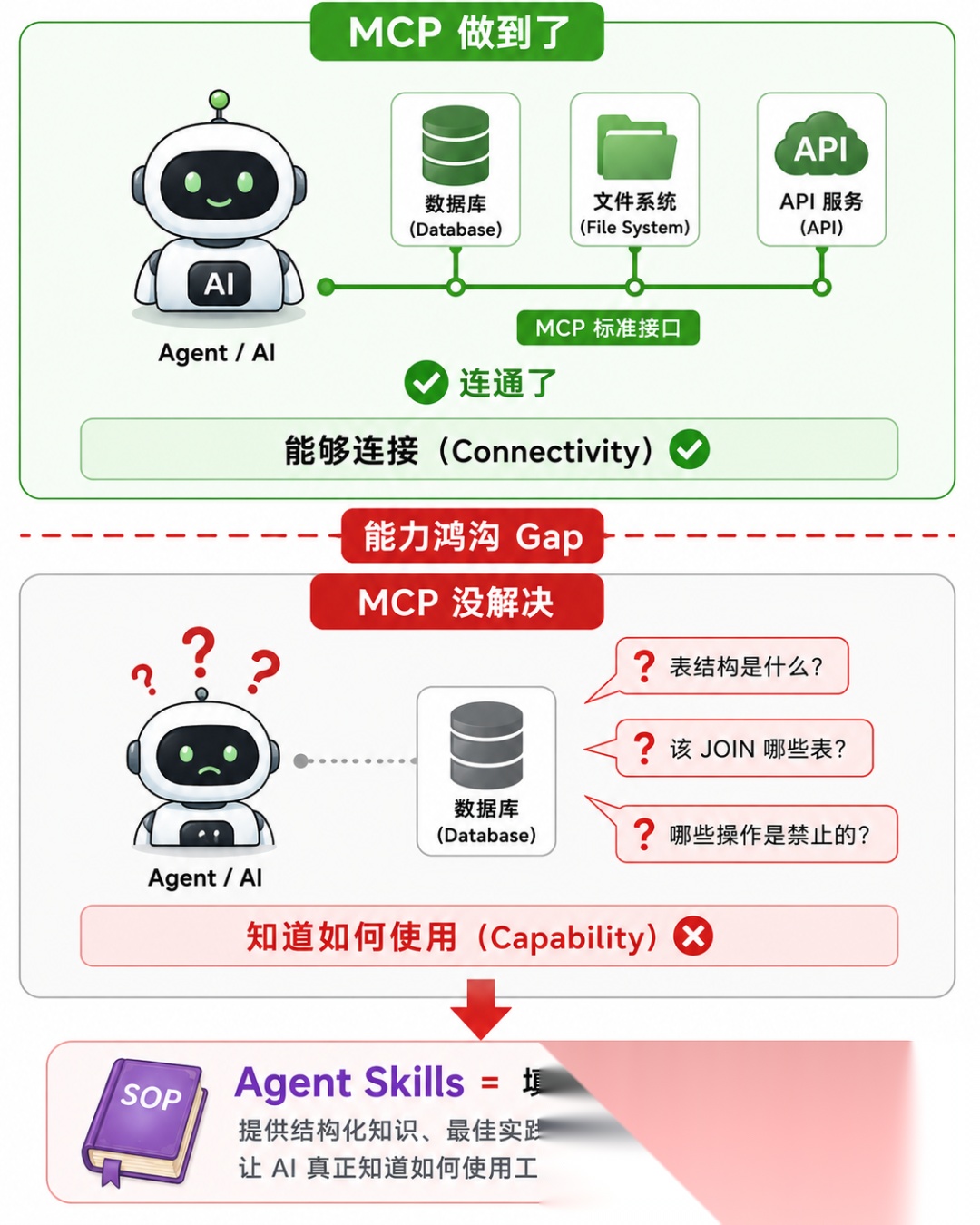
痛点 2:能力鸿沟——“能连上"≠"会用”
MCP 解决了"能够连接"的问题,但没有解决"知道如何使用"的问题。
举个例子:
你给 Agent 接了一个数据库 MCP Server。Agent 现在可以执行 SQL 了。
但它知道:
- • 你的数据库有哪些表?表结构是什么?
- • 查员工信息应该 JOIN 哪几张表?
- • 有哪些查询是绝对不能执行的(比如 DROP TABLE)?
- • 返回结果太多时应该怎么分页?
答案是:它不知道。MCP 只给了它"手",没给"操作手册"。
小编打个比方:
这就像给一个新入职的员工开通了所有系统的访问权限,但没给他任何培训资料和操作规范。他有权限登录 CRM、ERP、数据库——但他完全不知道该怎么用。
5.2 Agent Skills 是什么
💡 一句话定义:Agent Skills 是一种标准化的"程序性知识封装格式"——如果 MCP 给了 AI “手”,Skills 就给了 AI “操作手册”。
Skills 不是工具(不提供 API),不是 Prompt(不只是文字指令)。它是一个知识包,包含:
- • 什么时候该用这个技能
- • 具体怎么一步步做
- • 有哪些注意事项和坑
- • 需要调用哪些工具、怎么组合
- • 可能还有脚本和参考文件
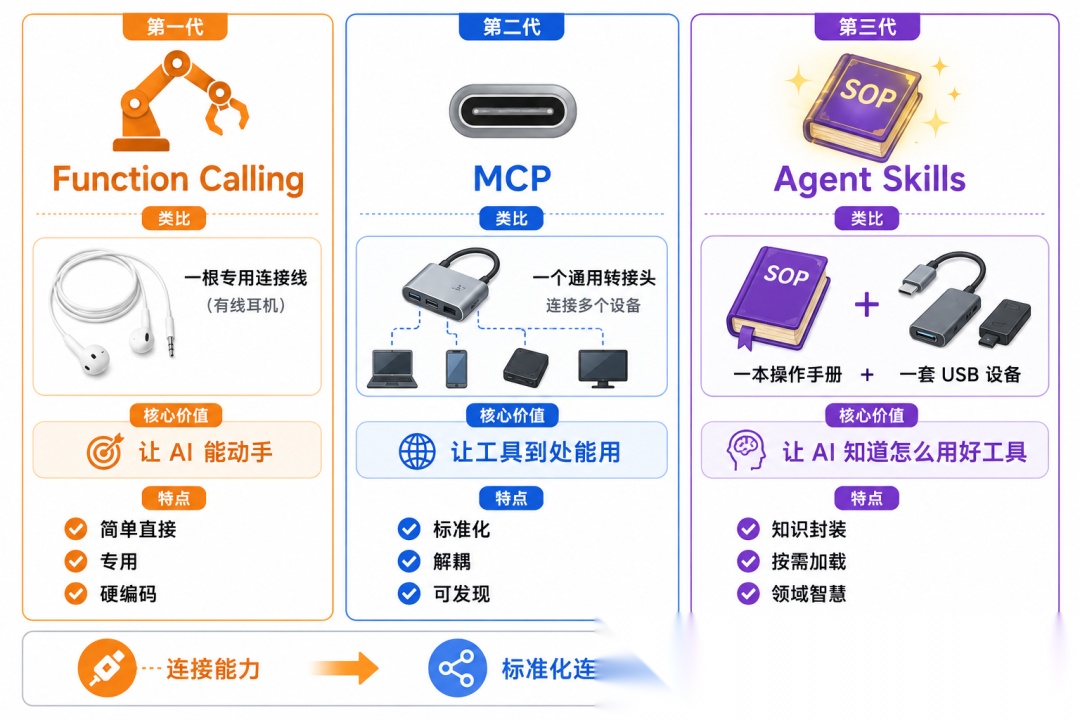
一句话区分三者:
| 属性 | Function Calling | MCP | AgentSkills |
| 本质 | 一次函数调用 | 一个标准化接口 | 一本操作手册 |
| 提供的是 | “手” | “标准化的手” | “大脑里面的SOP” |
| 类比 | 一个按钮 | USE-C接口 | 应用软件 |
小编再展开类比:
- • MCP 像 USB 接口或驱动程序——定义设备如何连接
- • Skills 像应用软件——定义如何使用这些设备完成任务
你可以有一个完善的打印机驱动(MCP),但如果没人告诉你"怎么在 Word 里设置双面打印"(Skill),你还是搞不定。
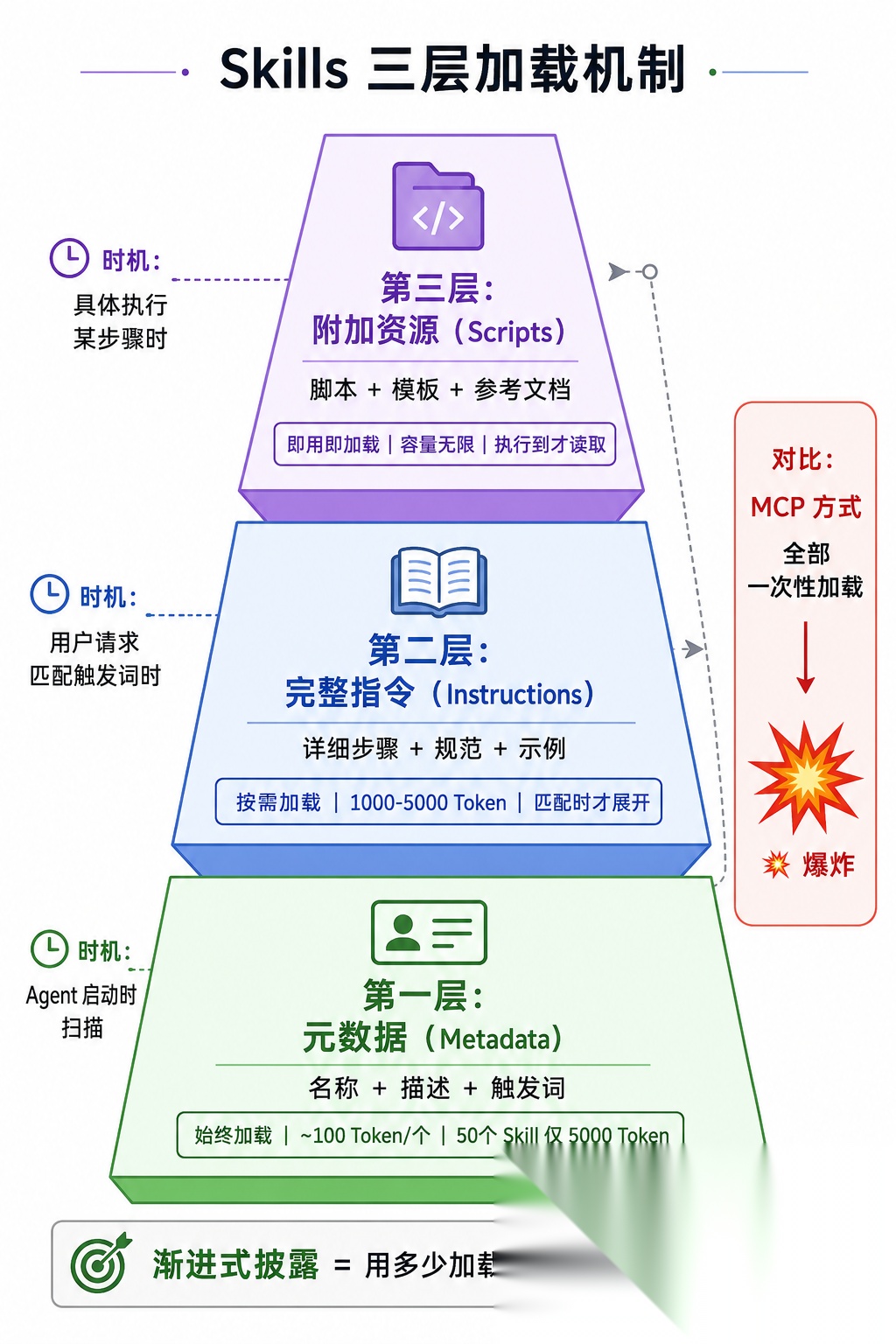
5.3 Skills 最核心的创新:渐进式披露
前面说了,MCP 的一大问题是"上下文爆炸"——所有工具描述一次性全塞进去。
Skills 的解决方案非常聪明:分三层加载,按需逐步披露。
小编用一个比方帮你理解:
想象你新入职一家公司。公司不会在第一天就把所有部门的操作手册、全部流程文档、几百个系统的使用指南全塞给你。那样你会当场崩溃。
合理的做法是:
- • 第一天(入职手册):告诉你公司有哪些部门、各干什么——你大概知道有什么就行
- • 接到任务时(岗位培训):你被分到市场部?OK,现在才给你市场部的详细流程
- • 遇到具体问题时(查手册):你需要用某个系统?这时候才打开那个系统的操作指南
Skills 的三层加载机制一模一样:
第一层:元数据(Metadata)—— “公司有哪些部门”
Agent 启动时,只扫描每个 Skill 的"名片"——名称、一句话描述、触发词。
---name: "wechat-article-writer"description: "撰写微信公众号技术文章时使用此 skill"triggers: - "写公众号文章" - "微信文章" - "改写成公众号"---
每个 Skill 的元数据只占约 100 个 Token。就算你装了 50 个 Skill,初始消耗也只有 ~5000 Token。
对比 MCP:连一个 Playwright Server 就占 16000+ Token。差距是数量级的。
第二层:技能主体(Instructions)—— “岗位培训手册”
当用户的请求匹配到某个 Skill 的触发条件时,Agent 才加载这个 Skill 的完整内容。
比如用户说"帮我写一篇公众号文章",Agent 匹配到 wechat-article-writer,这时才把完整的写作规范、文章结构、风格要求全部加载进上下文。
这部分通常 1000-5000 Token,取决于指令复杂度。
第三层:附加资源(Scripts & References)—— “具体问题查手册”
对于复杂的 Skill,还可以附带脚本、模板、参考文档。Agent 只在具体执行到那一步时才加载。
skills/pdf-processing/├── SKILL.md # 主技能文件├── parse_pdf.py # PDF 解析脚本(需要时才执行)├── forms.md # 表单指南(遇到表单任务才加载)└── templates/ # 模板文件(需要时才访问)
结果:你可以给 Agent 装几十个 Skill,它的初始上下文消耗非常小。只有当任务真正需要某个 Skill 时,才"展开"那个 Skill 的详细内容。
这就是"渐进式披露"的威力——**不是一次性全塞进去,而是用多少加载多少。**
5.4 Skills + MCP:不是竞争,是互补
理解了三代技术的差异后,你会发现——它们不是互相替代,而是各管一层。
最佳实践是把三者组合成分层架构:
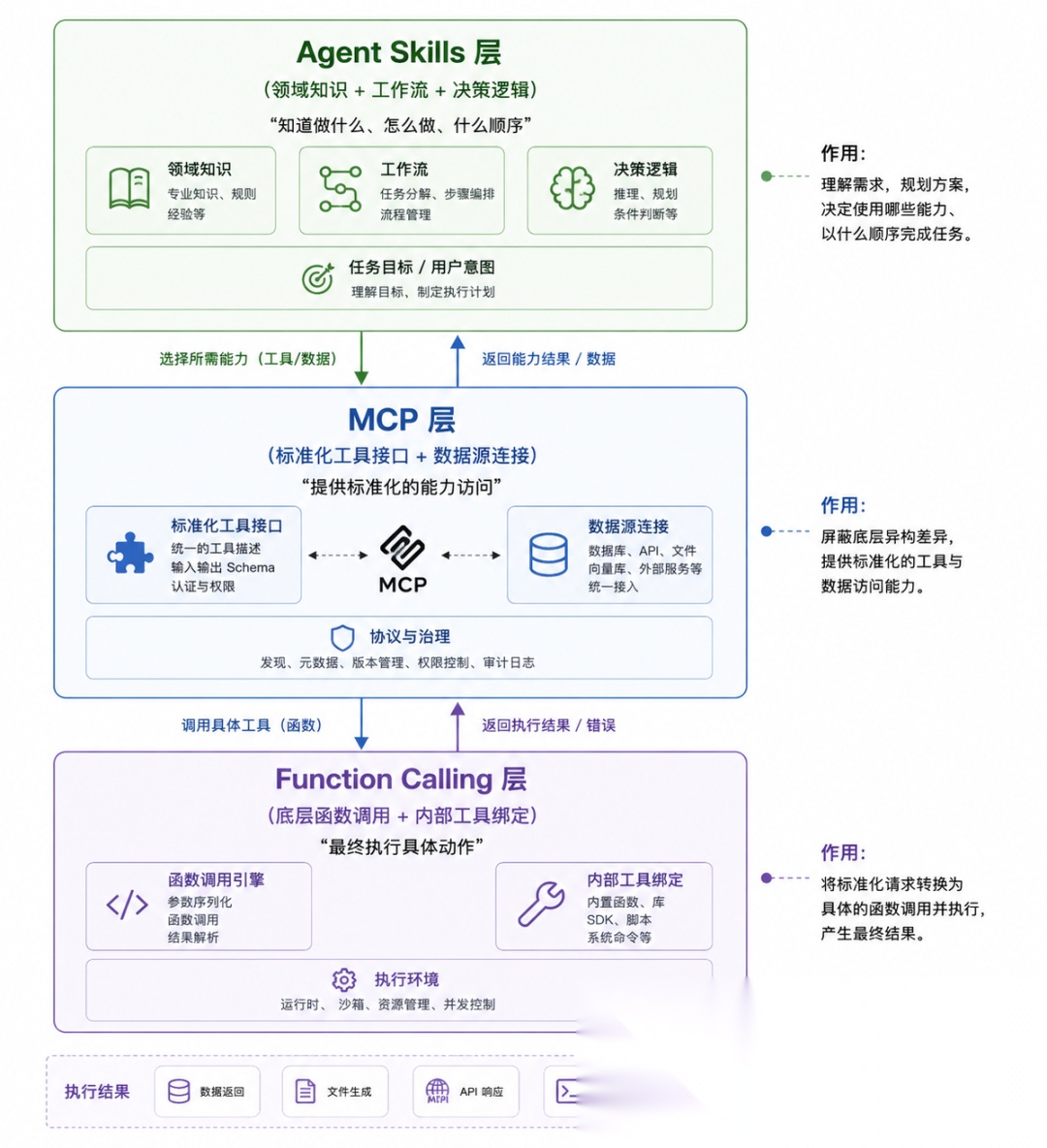
小编用一个实际场景带你走一遍这个分层:
场景:用户问 “分析一下公司里谁的话语权最高”
Skills 层介入:Agent 识别到这是一个"数据分析"类任务,加载 mysql-employees-analysis 技能。Skill 里定义了:
- • 分析话语权需要看哪些维度(管理关系、薪资水平、任职时长、汇报线)
- • 应该查哪些表、怎么 JOIN
- • 返回结果应该怎么解读
MCP 层执行:Skill 指导 Agent 调用数据库 MCP Server,执行具体的 SQL 查询:
- •
SELECT * FROM managers JOIN employees ON ... - •
SELECT salary, title FROM ...
Function Calling 层:MCP Server 底层调用实际的数据库驱动执行 SQL。
最终结果:Agent 基于 Skill 里的领域知识,把原始数据解读为有意义的结论返回给用户。
这种架构的好处:
| 优势 | 说明 |
| 关注点分类 | MCP管“能力连接”,Skills管“领域智慧” |
| 成本优化 | 渐进式加载,token消耗最小化 |
| 可维护性 | 业务逻辑(skills)和基础设施(MCP)解耦 |
| 复用性 | 同一个MCP Server 可被多个skills复用 |
5.5 如何写好一个 Skill
小编总结了几条实战原则(基于自己写代码审查 Skill 的经验):
原则 1:描述要回答"什么时候加载我",不是"我是什么"
# ❌ 坏的描述description: "这是一个代码审查技能"# ✅ 好的描述description: "当用户提交代码要求 Review、检查代码质量、或合并 PR 前审查时使用"
Agent 扫描描述是为了判断"要不要加载你"——所以描述要像触发条件,不像自我介绍。
原则 2:触发词覆盖多种说法
用户可能说"帮我 review 代码",也可能说"看看这段代码有没有问题"。你的触发词要尽量覆盖各种说法:
triggers: -"review 代码"-"代码审查"-"检查代码质量"-"帮我看看这段代码"-"PR review"- "code review"
原则 3:指令要像 SOP,不像散文
# ❌ 坏的指令(散文式)审查代码时要注意安全性、性能和可读性,同时关注命名规范和错误处理...# ✅ 好的指令(SOP式)## Step 1 — 理解上下文1. 确认变更的目的(修 Bug / 新功能 / 重构)2. 查看关联的 Issue 或需求描述3. 了解影响范围(涉及哪些模块)## Step 2 — 逐层审查1. 安全性:是否有 SQL 注入、XSS、硬编码密钥2. 正确性:边界条件、空值处理、并发安全3. 性能:是否有 N+1 查询、内存泄漏、死循环风险4. 可维护性:命名清晰度、函数长度、重复代码...
越结构化、越具体,Agent 执行得越好。
原则 4:声明退出条件——什么算"做完了"
## 完成标准- [ ] 所有文件都已逐一审查- [ ] 安全类问题标记为「必须修复」- [ ] 每条审查意见标注了严重等级(P0/P1/P2)- [ ] 给出总体评价(通过 / 需修改 / 打回重写)
没有退出条件的 Skill,Agent 可能无限循环或提前结束。
原则 5:Skill 内部可以调用 MCP 工具
好的 Skill 不是"替代"MCP,而是编排MCP。在指令里明确说"用什么工具做什么事":
## Step 3 — 提交审查结果1. 使用 GitHub MCP Server 在 PR 上逐行添加 Review Comment2. 对于安全类问题,调用 Jira MCP Server 自动创建 Bug 工单3. 使用消息 MCP Server 通知提交者审查已完成
这样 Skill 负责"决策和编排",MCP 负责"执行具体操作"——职责清晰。
5.6 一个完整的 Skill 工作场景
小编用一个大家都遇到过的场景,带你走一遍"有 Skill 的 Agent"是怎么工作的:
场景:你对 Agent 说"帮我看看这周的 Bug 列表,写封周报邮件发给领导"
这件事你自己做,大概要:打开 Jira 查 Bug → 筛选本周的 → 分类汇总 → 写成邮件 → 发送。30 分钟起步。
现在看 Agent 怎么做——
第一步:元数据匹配
Agent 扫描所有已安装 Skill 的元数据,发现 weekly-report-writer 匹配了:
用户说的:"写封周报邮件"Skill 触发词:["周报", "weekly report", "写周报", "汇报邮件"]→ 匹配!加载这个 Skill
此时消耗:~100 Token。其余几十个 Skill 完全不占上下文。
第二步:加载完整指令
Agent 读取这个 Skill 的完整内容。现在它知道了:
- • 周报的标准格式(本周完成 / 进行中 / 下周计划 / 风险项)
- • Bug 应该按"严重程度"分组,不是按时间
- • 领导喜欢先看结论再看细节(金字塔结构)
- • 邮件标题格式:
[周报] XX团队 第N周工作汇报 - • 语气要求:专业但不啰嗦,重点加粗
没有这个 Skill,Agent 可能写成流水账或格式乱七八糟。有了 Skill,它写出来的周报就像你组里最靠谱的那个同事写的。
第三步:按 SOP 执行(Skill 编排 + MCP 执行)
Skill 定义了清晰的步骤,Agent 依次执行:
Step 1:调用 Jira MCP Server → 查询本周所有 Bug(状态、优先级、负责人)Step 2:按 Skill 指令分类 → P0/P1/P2 分组 + 已解决/进行中/待处理Step 3:调用日历 MCP Server → 看看本周有没有重要会议/里程碑Step 4:根据 Skill 模板组织邮件正文 → 金字塔结构,结论先行Step 5:调用邮件 MCP Server → 发送给领导(抄送组内成员)
注意这里的分工:
- • Skill 负责"怎么做":分组逻辑、格式模板、语气要求
- • MCP 负责"去执行":查 Jira、读日历、发邮件
第四步:退出检查
Agent 对照 Skill 里定义的"完成标准"自检:
- • Bug 数据来源是本周?(不是上周的旧数据)
- • 邮件标题符合格式?
- • 有"风险项"板块?(领导最关心的)
- • 收件人正确?(发给领导,抄送组员)
- • 邮件已成功发送?
全部通过 → 任务完成。你收到 Agent 的回复:“周报已发送,本周共处理 12 个 Bug,其中 P0 级 2 个已修复。”
从你说话到邮件发出,可能就 30 秒。
小编想强调的点是——如果没有 Skill,Agent 也"能"写周报。但它写出来的很可能是:
- • 格式不对(领导看了想打人)
- • 分类混乱(P0 和 P2 混在一起)
- • 重点不突出(埋在一堆细节里)
- • 语气不合适(要么太随意要么太正式)
Skill 的价值不是让 Agent “能做”,而是让它"做得对、做得好"。
"Skill 让 Agent 从'什么都能干但什么都干不精'变成了'接到任务就像老员工一样驾轻就熟'。"

六、全景总结:三代技术一张表
| 维度 | Function Calling | MCP | AgentSkills |
| 诞生时间 | 2023 | 2024年底 | 2025年底 |
| 创造者 | OpenAI | Anthropic | anthrppic |
| 定义 | 让模型输出结构化工具调用 | 让模型通过标准协议被任何应用接入 | 让Agent拥有领域的知识和工作流 |
| 解决的问题 | AI不能动手 | 工具不能被复用 | AI会玲姐但是不会精准的使用工具 |
| 类比 | 有线耳机 | USB-C接口 | 应用软件 |
| 上下文消耗 | 中等(工具定义常驻) | 高(每次都需要加在所有schema) | 低(渐进式加在) |
| 适用场景 | 内部简单工具绑定 | 跨应用工具共享 | 复杂领域任务编排 |
| 关系 | 基础层 | 中间层 | 上层 |
演进关系:Function Calling → MCP → Agent Skills "能动手" "手能通用" "知道怎么用好手"
“从 Function Calling 到 Skills,本质上是从’连接’到’智慧’的跃迁。”
好了,三代工具调用技术全部讲完。回到最开始的问题——该选哪个?
小编的建议很实际:
- • 刚入门、做 Demo:直接用 Function Calling,简单够用
- • 要做跨应用共享、接第三方工具:上 MCP
- • 做复杂的领域任务、需要 Agent “真的懂业务”:写 Skills
- • 生产级系统:三层都用,各管各的层
说实话,小编自己目前的项目就是三层混合的——MCP 接数据库和文件系统,Skills 定义写作流程和质量标准,Function Calling 处理一些简单的内部逻辑。分工明确,各司其职。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)