LangGraph 流式处理:为什么你的 Agent 输出总是“卡顿”?
这篇文章帮你搞定 LangGraph 流式处理的底层原理,从 asyncio 流到 Token 级输出
这篇文章帮你搞定 LangGraph 流式处理的底层原理,从 asyncio 流到 Token 级输出
阅读提示
- 适合谁看:有 LangGraph 或 LLM 应用开发经验,正在做实时输出、流式响应的工程师
- 看完能做什么:能设计可扩展、可恢复、可监控的流式处理系统
- 不适合谁:还没理解 LangGraph State/Graph 基础概念的纯新手
先给结论
- 流式处理不是“print 一行”,而是asyncio 流 + Token 级输出 + 背压控制
- 输出卡顿不是“网络慢”,而是缓冲区满、背压未处理、Token 生成不及时
- 生产级流式必须考虑:Token 流、背压控制、异常处理、可观测性
很多人做 Agent 时,demo 阶段跑得很顺,一上生产就发现输出卡顿:
- 用户等半天才看到第一个 Token
- 输出中间突然卡住
- 长文本生成时内存暴涨
看起来是性能问题,本质上是流式处理架构没设计好。
01 流式处理的本质:Token 级输出
 图 1|流式处理架构
图 1|流式处理架构
流式处理的核心思想是Token 级输出:
- Token:LLM 输出的最小单位(一个词或子词)
- 流:Token 逐个生成并输出
- 缓冲区:暂存未输出的 Token
这意味着:
- 流式不是“等全部生成完再输出”,而是“边生成边输出”
- 用户可以更快看到第一个 Token
- 内存占用更可控
为什么不能用 print 代替?
# 误区:用 print 输出def generate_response(prompt): response = llm.invoke(prompt) print(response) # 等全部生成完才输出 return response
这种写法的问题在于:
- 用户等待时间长,体验差
- 内存占用高,长文本可能 OOM
- 无法做背压控制
LangGraph 的解法是把输出变成Token 流 + 缓冲区 + 背压控制:
- Token 流:LLM 逐个生成 Token
- 缓冲区:暂存未输出的 Token
- 背压控制:下游处理不过来时暂停上游
场景代码示例:流式输出配置
import asynciofrom typing import AsyncGenerator# 1) 定义流式输出函数asyncdef stream_tokens(prompt: str) -> AsyncGenerator[str, None]: """流式输出 Token""" for token in generate_tokens(prompt): yield token await asyncio.sleep(0.01) # 模拟网络延迟# 2) 运行入口:验证流式输出if __name__ == "__main__": asyncdef main(): asyncfor token in stream_tokens("测试"): print(token, end="", flush=True) asyncio.run(main())
02 背压控制的底层原理:生产者-消费者模型
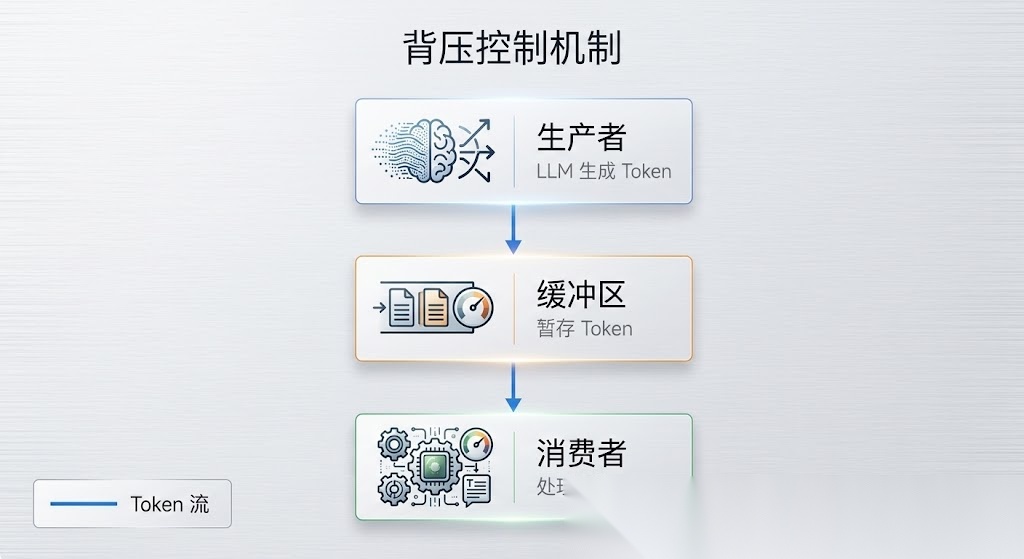
图 2|背压控制机制
背压控制的核心是生产者-消费者模型:
- 生产者:LLM 生成 Token
- 消费者:下游处理 Token(渲染、存储、网络发送)
- 缓冲区:暂存未处理的 Token
这意味着:
- 生产者速度 > 消费者速度时,缓冲区会满
- 缓冲区满时,生产者应该暂停
- 背压控制就是“缓冲区满时暂停生产者”
场景代码示例:背压控制实现
import asyncioclass BackpressureQueue: def __init__(self, max_size: int = 100): self.queue = asyncio.Queue(maxsize=max_size) asyncdef put(self, item): """生产者:放入 Token(缓冲区满时阻塞)""" await self.queue.put(item) asyncdef get(self): """消费者:取出 Token(缓冲区空时阻塞)""" returnawait self.queue.get()# 最小验证if __name__ == "__main__": print("BackpressureQueue ready")
03 异常处理与恢复:生产级流式的关键
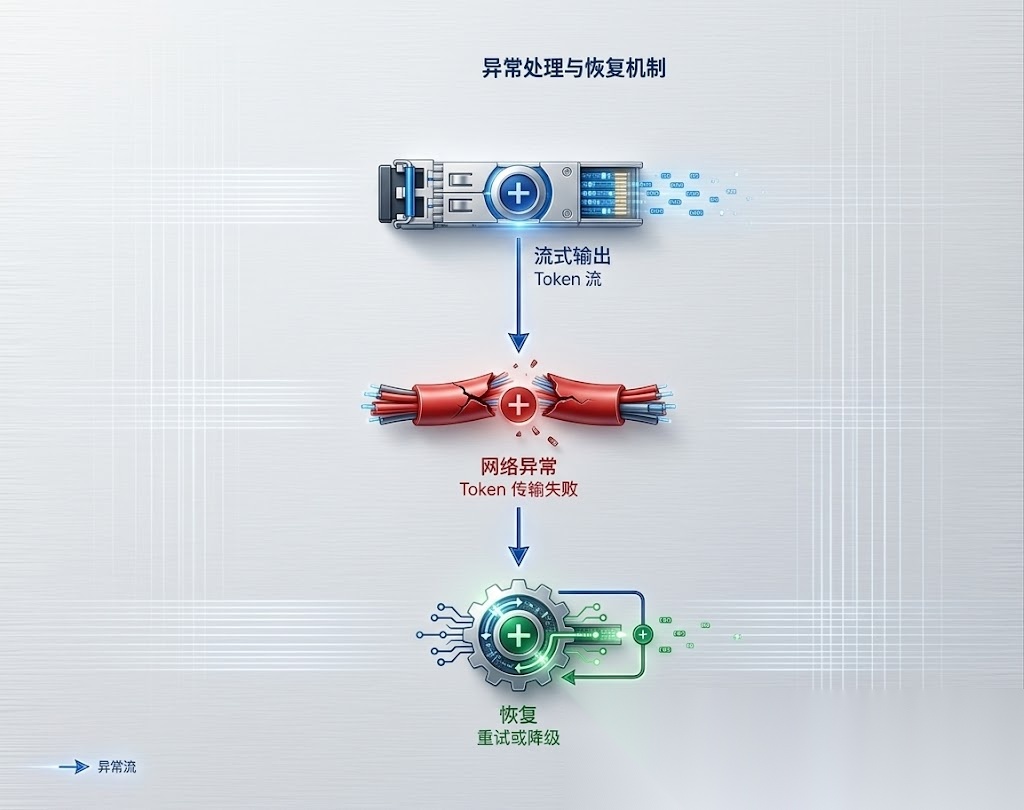
图 3|异常处理与恢复机制
异常处理是流式的核心:
- 网络异常:Token 传输失败
- LLM 异常:Token 生成失败
- 消费者异常:下游处理失败
这意味着:
- 流式不是“输出就完事”,而是“每一步都要容错”
- 异常不是“抛出就结束”,而是“恢复后继续”
场景代码示例:异常处理实现
import asyncioasyncdef safe_stream(prompt: str): """安全的流式输出""" try: asyncfor token in stream_tokens(prompt): yield token except Exception as e: print(f"Stream error: {e}") yield"[ERROR]"# 最小验证if __name__ == "__main__": print("safe_stream ready")
04 最小实验:观察流式输出如何工作
实验条件
- 环境:LangGraph latest,Python 3.10+
- 输入:一个简单任务,包含流式输出
- 预期观察:Token 逐个输出,而不是一次性输出
- 先准备什么:定义
stream_tokens函数 - 先跑什么:调用流式输出,观察 Token 逐个输出
- 你应该看到什么:Token 逐个输出,而不是一次性输出
代码 1
import asynciofrom typing import AsyncGeneratorasyncdef stream_tokens(prompt: str) -> AsyncGenerator[str, None]: tokens = ["你", "好", "世", "界"] for token in tokens: yield token await asyncio.sleep(0.5) # 模拟生成延迟asyncdef main(): print("Output: ", end="") asyncfor token in stream_tokens("测试"): print(token, end="", flush=True) print()# 测试# asyncio.run(main())
如果结果不符合预期,先看哪里
async for是否正确使用yield是否正确返回 Tokenawait asyncio.sleep()是否正确模拟延迟- 输出是否逐个 Token 打印
05 跑出来不对时,先看这几件事
- 现象 1:输出卡顿 → 可能缓冲区满,先检查
BackpressureQueue - 现象 2:内存暴涨 → 可能缓冲区太大,先检查
max_size - 现象 3:异常后中断 → 可能异常未被捕获,先检查
try-except - 现象 4:Token 丢失 → 可能消费者处理异常,先检查消费者逻辑
06 什么时候该用,什么时候别急着上
- 更适合:实时输出、流式响应、长文本生成
- 不适合:短文本、批处理、无用户交互
- 成本会突然变高的点:Token 流、背压控制、异常处理、可观测性
3 问判断法
- 你的应用是否需要实时输出?
- 是否存在长文本生成场景?
- 是否需要流式响应?
如果 3 个问题大多是否定,先不要上复杂方案。
07 小结:从“批量输出”到“流式协同”
流式处理的底层原理可以总结成三句话:
- Token 流是核心:边生成边输出,用户体验更好
- 背压控制是关键:生产者-消费者模型,避免内存暴涨
- 异常处理是保障:每一步都要容错,恢复后继续
当你把输出从“批量”升级为“流式”,系统才真正具备实时性、可恢复性和可维护性。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 7
7 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)