30 分钟,让Claude code 运行成本减少最高60%!
—这个项目用什么语言、什么框架、什么包管理器。
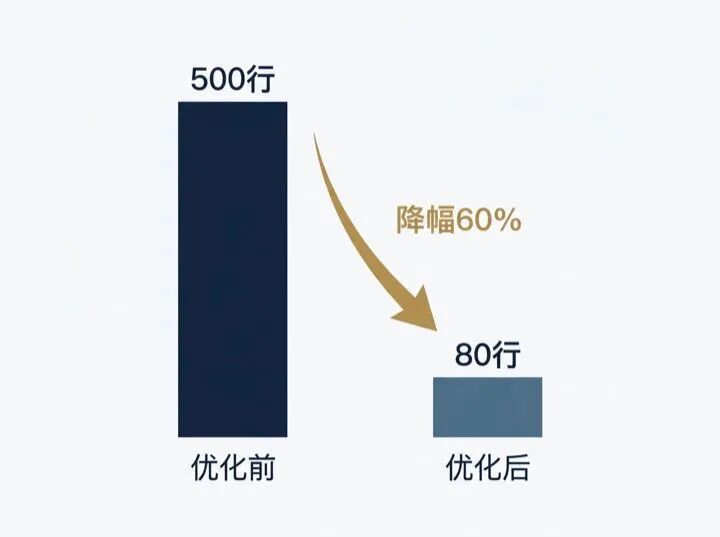
把 CLAUDE.md 从 500 行砍到 80 行,token 消耗降了 60% 以上。
不是因为写少了什么。是因为之前写的那 500 行,有 80% 是在给 Claude Code 喂垃圾。
这篇文章要讲的,不是"CLAUDE.md 的入门教程"——你搜一下有一千篇。我要讲的是:一个合格的 CLAUDE.md 究竟长什么样,哪种写法是在帮 Claude Code,哪种是在拖它的腿。
先快速对一下:CLAUDE.md 到底是什么
如果你之前用过 Claude Code 但没碰过 CLAUDE.md,先用一段话对齐。CLAUDE.md 就是你项目根目录里一个普通的 Markdown 文本文件,名字叫 CLAUDE.md。不是插件,不是命令,就是一个文件。每次你在这个项目目录下启动 Claude Code 开始一次新对话,它会自动把这个文件的内容读进来——相当于你在开口之前,先递给 Claude Code 一张说明卡:这个项目是什么、有哪些必须遵守的规则。它可以放在根目录管全局,也可以放在子目录里只管那个模块(后面会讲)。
听起来就是个普通配置文件。
但只要你长期用 Claude Code,这个文件的质量就会直接拖你后腿。规则写得乱,它反复犯同一个错。写得太长,每次对话都在烧 token。多人协作时,它还会变成冲突源。
它不是可写可不写的可选项。它是 Claude Code 工程化的核心基础设施,和目录结构、命名规范是一个量级的事。
阶段 1:问题是怎么来的
第一次接触 CLAUDE.md 的时候,大多数人的反应是"哦,就是个说明文件",然后开始往里塞东西。
项目背景塞进去。技术栈塞进去。API 调用规范塞进去。代码风格塞进去。然后某天团队里来了个新成员,说"我看不懂你们项目怎么跑",又往里补了一大段部署说明。
三个月后,这个文件长到 500 行。
你以为这是"规范越来越完整"。但 Claude Code 每次启动一个对话,它都把这 500 行注入到上下文里。不管这次对话是改一个 CSS 还是重写后端服务,500 行全进来。
这带来两个问题:
第一个问题是 token 消耗。 每次对话你都在为那 350 行你根本不需要的内容付费。月度累计下来,Sonnet 用户的浪费在十美元上下,Opus 重度使用者能到几十美元——更别说团队多人并行跑的情况。
第二个问题是信噪比。 Claude Code 的上下文窗口是有限的。你塞进去 500 行说明,它就少了 500 行来理解你当前这次对话的真实需要。有时候它会忘记你在这次对话里说的重要约束,但记住了上个月你在 CLAUDE.md 里随手写进去的一个废弃接口规范。
问题不在于"写多了",在于你把所有信息都堆在同一层,让它每次都全量注入。
阶段 2:什么样的 CLAUDE.md 才算合格
先说结论:合格的 CLAUDE.md 是分层的,不是堆叠的。
Anthropic 官方 best-practices 文档反复强调"保持精简、可读"——但没给具体行数。开发者社区基于大量实战沉淀出一个经验基线:根目录的 CLAUDE.md 控制在 80-120 行以内。这不是官方明示数字,是社区共识,也是工程化约束。超过这个范围,你就在用一个本该让你提速的工具,给自己制造阻力。
但为什么是 80-120 行?凭什么?
因为 CLAUDE.md 的加载机制决定了它的写法。
Claude Code 在每次对话启动时,会从当前目录向上递归查找所有 CLAUDE.md——根目录的必然加载,子目录的只在 Claude Code 进入那个目录或读取该目录下文件时才追加到上下文。
这个机制意味着:放在根目录的,是全局通用规则;放在子目录的,是当前模块规则。不是所有规则都要塞给根目录。
一个合格的多层级结构是这样的:
项目根目录/ ├── CLAUDE.md ← 全局规则(80 行以内):目录约定、技术栈、环境管理方式 ├── frontend/ │ └── CLAUDE.md ← 前端模块规则:组件命名、样式规范、打包约定 └── backend/ └── CLAUDE.md ← 后端模块规则:虚拟环境、API 规范、数据库操作约束
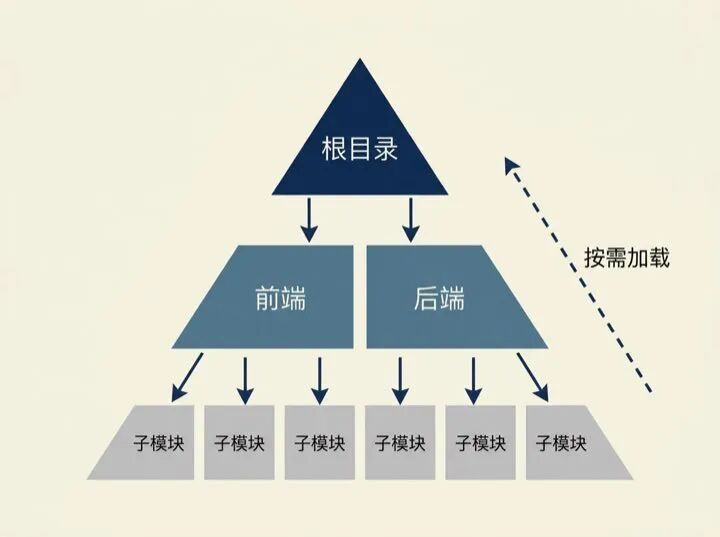
根目录的 CLAUDE.md 只写三类信息:
-
目录约定
——前端代码放哪,后端放哪,环境变量怎么管理
-
技术栈定义
——这个项目用什么语言、什么框架、什么包管理器
-
启动约束
——哪些事情每次都必须注意(比如"不要把 .env 提交到 git")
就这三类。其他的,移到子目录的 CLAUDE.md 里。
好坏标准:
-
合格:根目录 CLAUDE.md 80 行以内,只写跨模块都要遵守的内容;子目录 CLAUDE.md 按模块写,按需加载
-
不合格:所有信息堆在根目录,500 行大杂烩,每次对话全量注入
判断口径很简单——你现在打开自己的 CLAUDE.md,数一下行数。超过 120 行?你有问题需要解决了。
阶段 3:真做出来什么样
说说我实际用的结构。
做一个前后端分离的项目,根目录的 CLAUDE.md 大概是这样的:
# 项目结构 - frontend/:所有前端代码(React + TypeScript) - backend/:所有后端代码(Python + FastAPI) - docs/:设计文档和规范文档 - .env:环境变量,不要提交到 git # 技术约定 - 后端服务必须用 uv 创建独立虚拟环境 - 包管理:前端用 pnpm,后端用 uv - 启动前端:cd frontend && pnpm dev - 启动后端:进入 backend 子目录查看对应 CLAUDE.md # 强制约束 - .env 文件禁止提交 git,gitignore 里必须有 - 新建服务前先看 docs/ 下的接口规范文档 - 不要修改其他模块的代码来迁就当前模块的 bug
这大概 20 行出头——但这是最小骨架。真实项目里通常还要加:monorepo 子包说明、CI/CD 触发约束、本地工具链版本(Node 版本 / Python 版本 / uv 版本)、调试快捷命令清单。这些加完,60-80 行很正常——但仍不该破 120 行。然后 backend/CLAUDE.md 里写虚拟环境的激活方式、API 测试怎么跑、哪个端口、依赖安装命令。frontend/CLAUDE.md 里写组件规范、Figma 导出的代码放哪里、样式约定。
关键点在于:这两个子模块的 CLAUDE.md,只有当我的对话涉及到这个模块时才会被加载。 我在改后端接口的时候,Claude Code 不会把前端的组件命名规范也塞进来——那些信息在这个上下文里没用。
还有一个常被忽略的工程化细节:CLAUDE.md 要与规范文档分开。
很多人会把详细的接口设计文档、系统架构说明、API 参数表都往 CLAUDE.md 里塞。这是错的。CLAUDE.md 写的是"规则",不是"内容"。规范文档应该放在 docs/ 下面,然后在 CLAUDE.md 里写一行"详细的后端接口规范在 docs/backend-spec.md"。
Claude Code 在需要的时候会去读那个文档。让它自己去找,不要提前全塞进来。
这个区别,是文档驱动开发心法里的核心——上下文是稀缺资源,不是垃圾桶。
阶段 4:真用起来什么样
按多层级结构重新整理完之后,变化是实质性的。
token 消耗层面:
改之前,每次对话冷启动大约消耗 3000-4000 token 仅用于 CLAUDE.md 的注入(500 行均摊算)。
改之后,根目录 CLAUDE.md 80 行约 600-800 token,子目录按需加载,多数对话额外加载 200-400 token。
月度累计(按每天 20-30 次有效对话估算),token 消耗降幅大约在 55%-65% 之间。这不是拍脑袋的数字,是可以从 Claude Code 的使用量记录里查到的趋势。
注意这里 60% 是"根目录 + 子目录按需加载"叠加之后的总注入降幅,不是 500 行→80 行单文件对比。
单文件维度行数降了 84%,但叠加子目录后实际节省到 55%-65%——这才是真实账。
协作层面:
多层级结构的另一个好处是团队协作时规则不打架。之前一个文件里所有规范堆在一起,前端改了规范就会影响后端看到的内容,后端加了一段说明前端开发者也要看着这些不相关的内容。
改成多层级之后,每个模块的负责人只维护自己那个 CLAUDE.md。根目录的全局规则由项目主理人维护。互不干扰。
迭代层面:
这个结构也更容易迭代。某个模块的开发规范变了,只改那个子目录的 CLAUDE.md,不用担心改坏其他模块的上下文。
我用过一次"边做边调 CLAUDE.md"的方式:发现 Claude Code 反复在后端虚拟环境上犯错(每次跑测试都先 pip install 一遍,巨慢)。
我在 backend/CLAUDE.md 里加了一行:“所有后端命令必须先 source .venv/bin/activate,禁止用全局 Python”。
之后同类错误消失了。这比改全局 CLAUDE.md 精准得多——你知道是哪一层的规则在起作用。
收尾:3 件可以马上动手的事
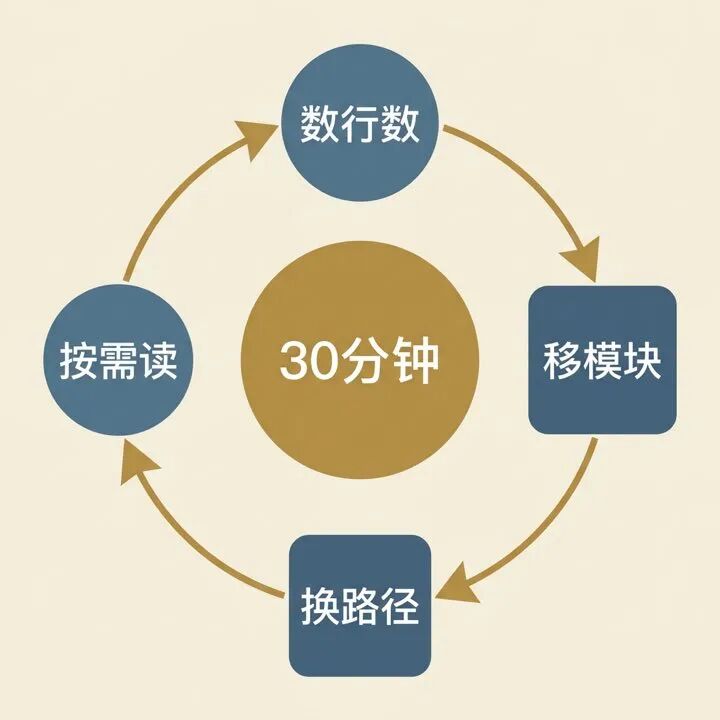
你不需要推倒重来。30 分钟内能做的三件事:
第一件:计算你的 CLAUDE.md 行数。
打开当前项目的根目录 CLAUDE.md,数一数行数。超过 120 行的,标记出来,准备重构。不超过的,进入第二步。
第二件:把模块专属规范移出根目录。
根目录里有前端专属规范?移到 frontend/CLAUDE.md 里。有后端虚拟环境说明?移到 backend/CLAUDE.md 里。只留跨模块必须共守的那三类内容。
第三件:把详细文档从 CLAUDE.md 里抽出来,换成一行路径引用。
如果你的 CLAUDE.md 里有详细的 API 接口说明、长段的背景介绍、完整的架构设计文档,把它们移到 docs/ 里单独放,在 CLAUDE.md 里留一行"详见 docs/xxx.md"。
这三步做完,CLAUDE.md 的工程化就有了基础。后面的优化——比如给不同任务类型配不同的子目录规则、利用 Plan 模式先规划再生成——都是在这个基础上叠加的。
CLAUDE.md 不是越长越好,不是越全越安全。它是一个需要像代码一样被设计和维护的文件。
合格的 CLAUDE.md 是:根目录精简(80 行以内)、子目录分层、规范文档分离、按需加载。
这四条,是用 Claude Code 做工业级项目的研发心法里绕不过去的基础设施。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)