厦门大学:语音大模型——从语音识别到全双工语音交互 2026
主流端到端模型:Moshi、GLM-4-Voice、Qwen-Omni、Kimi-Audio、Step-Audio2,均实现低延迟语音对话,支持情感、方言等副语言理解。未来方向:聚焦全双工端到端对话、语音思维链(CoT)、Voice Agent,推动语音大模型更自然、智能地服务人机交互。技术演进:历经模板匹配、统计模型、深度学习、大模型四个阶段;落地场景:涵盖语音转写、多语种翻译、实时语音对话,已
这份文档由厦门大学洪青阳于 2026 年 5 月撰写,围绕语音大模型从语音识别到全双工语音交互展开,从背景、技术、模型、交互到应用系统梳理行业进展,核心总结如下:
一、背景:语种、方言与交互范式演进
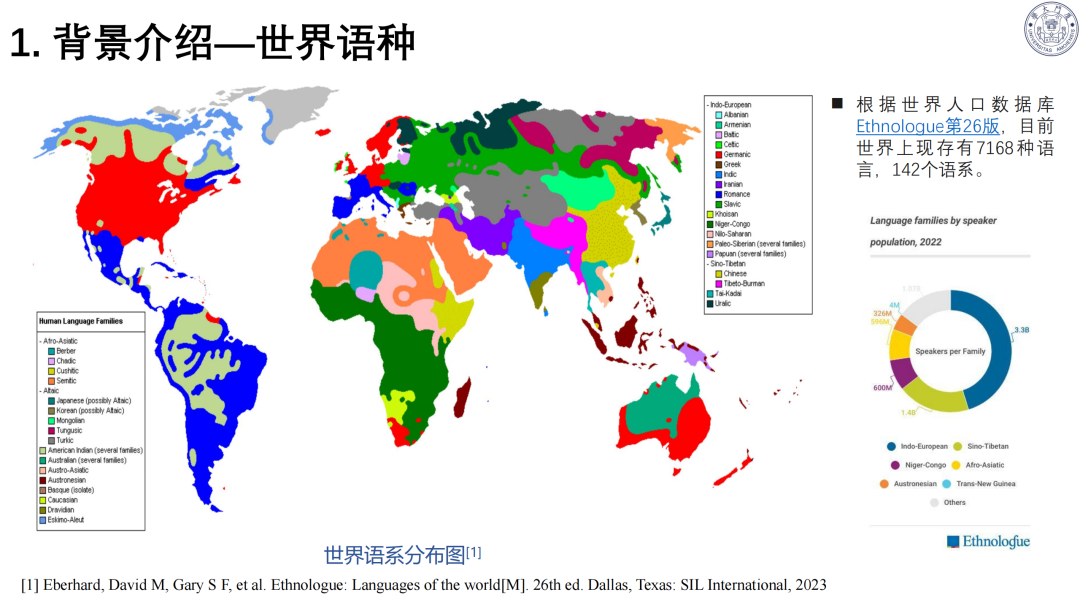
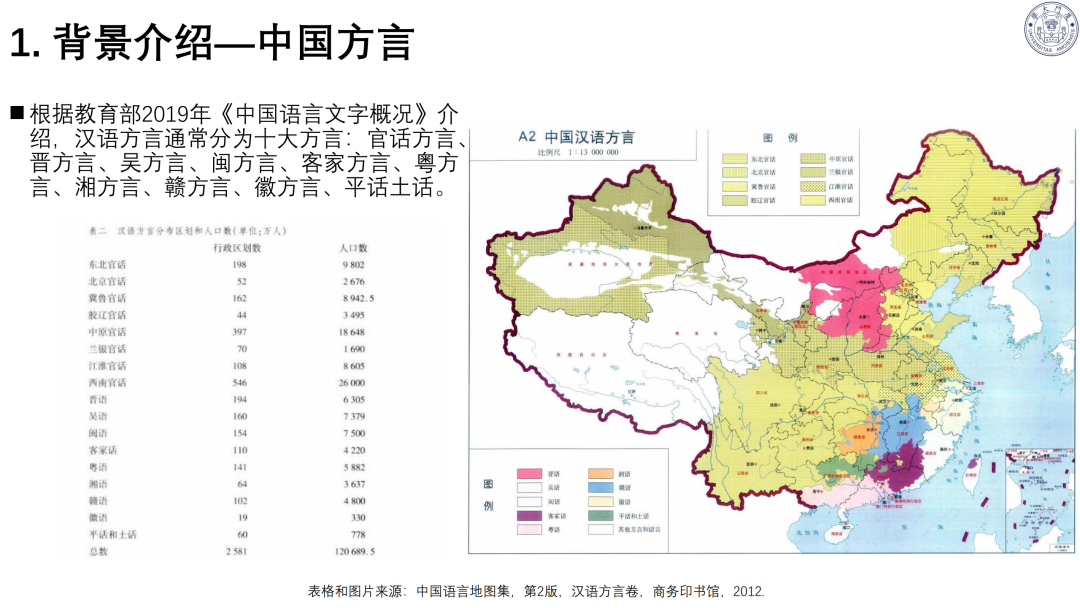
语言基础:全球现存 7168 种语言、142 个语系;汉语分十大方言,方言识别是语音模型重要方向。
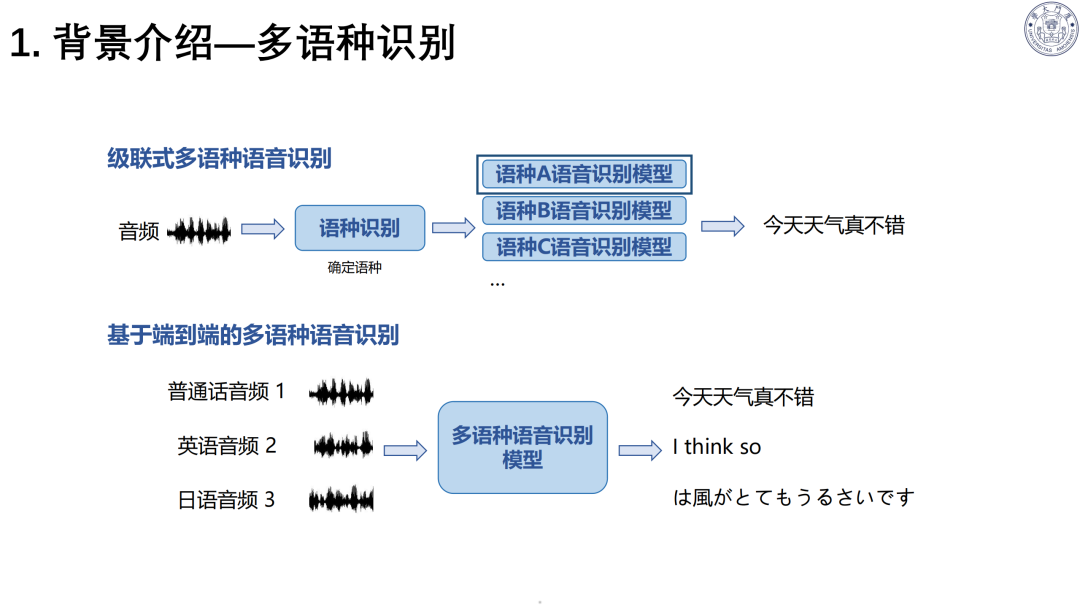
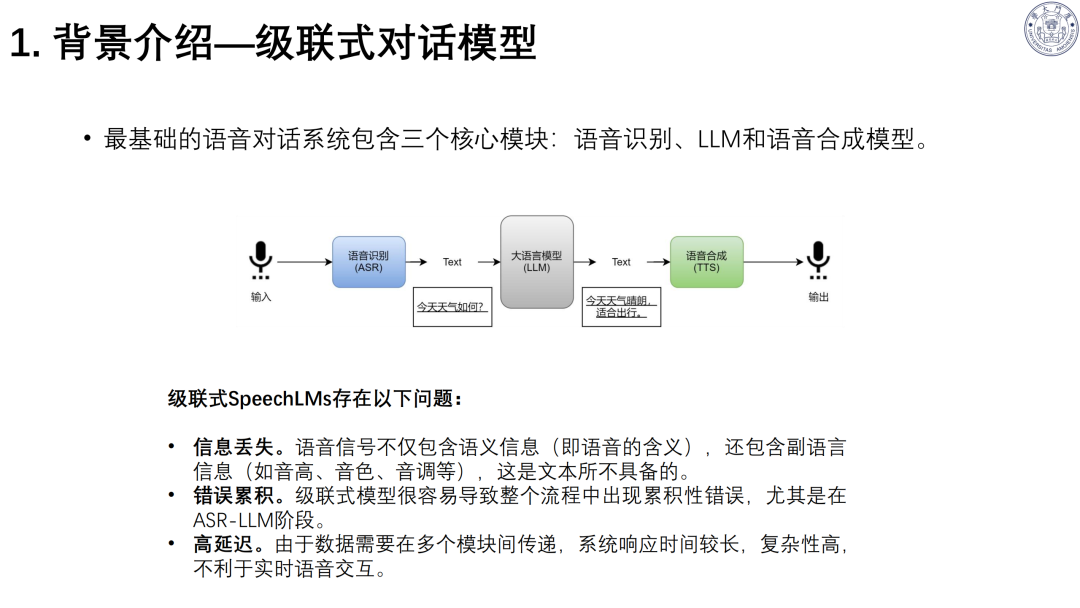
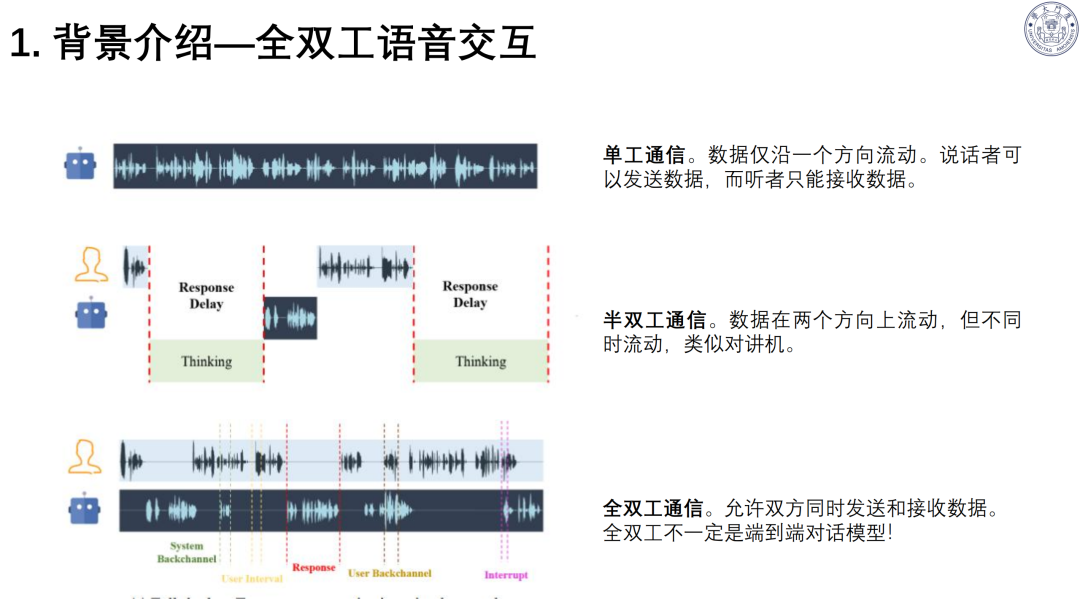
交互痛点:传统级联式对话模型(ASR→LLM→TTS)存在信息丢失、错误累积、高延迟三大问题。
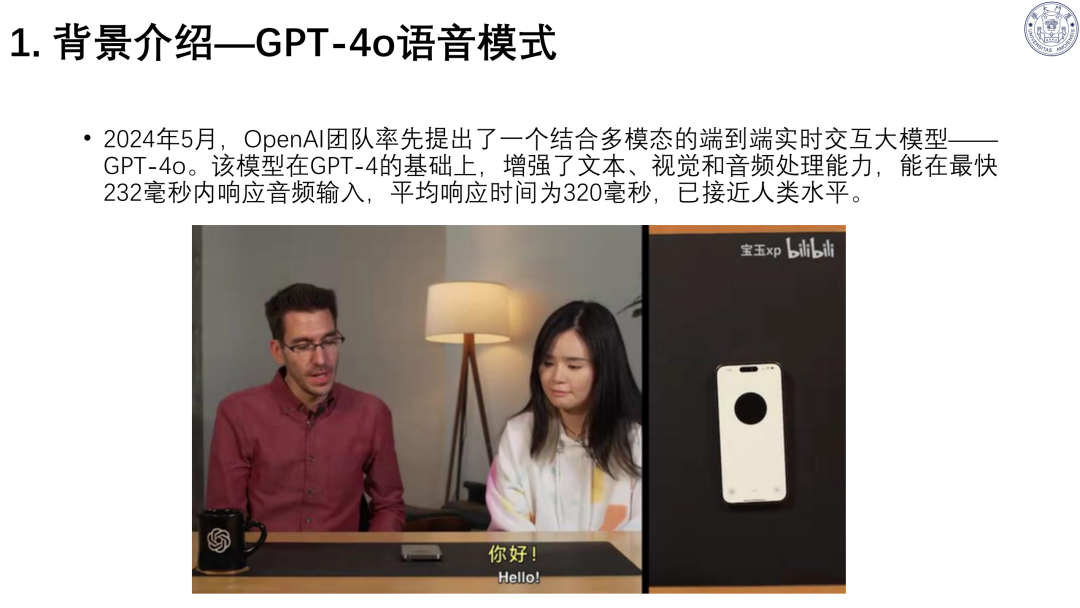
范式升级:从单工、半双工迈向全双工语音交互,支持双方同时收发数据;GPT-4o、豆包等推动实时交互,响应接近人类水平。
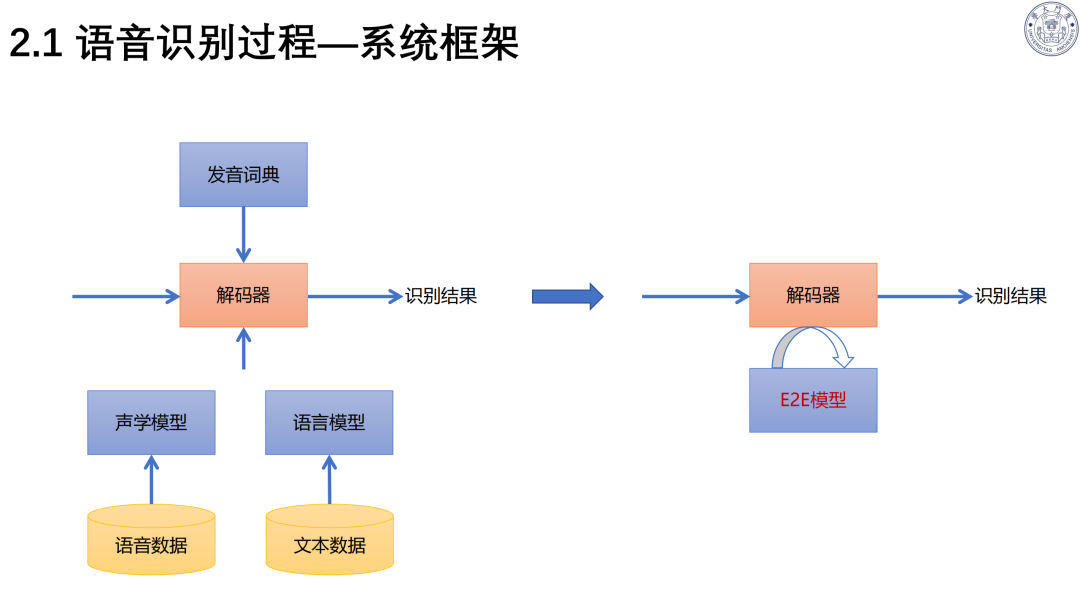
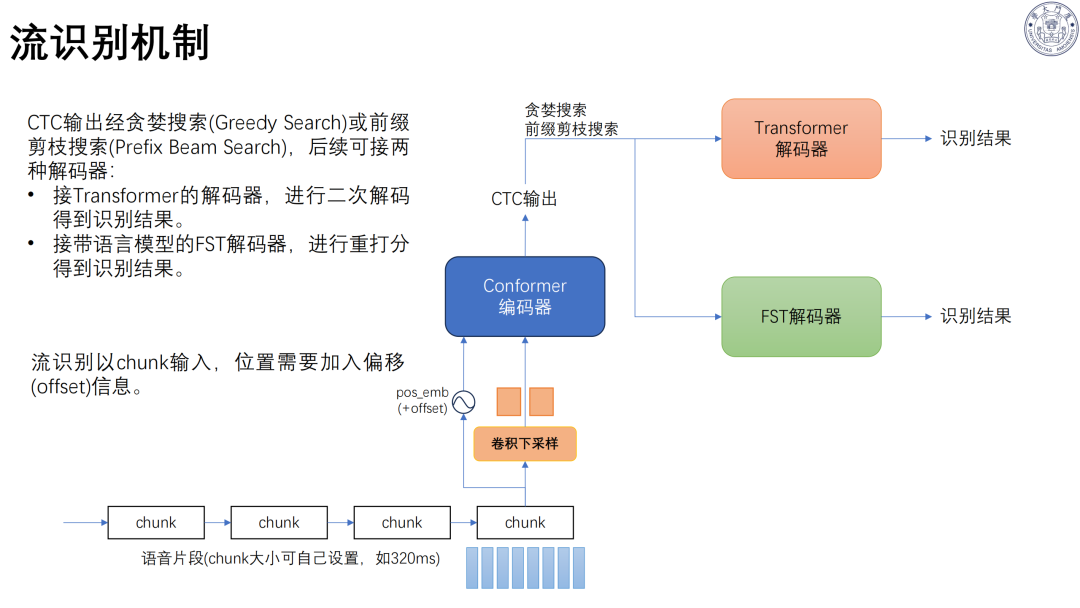
二、语音识别大模型:从传统到 LLM 融合
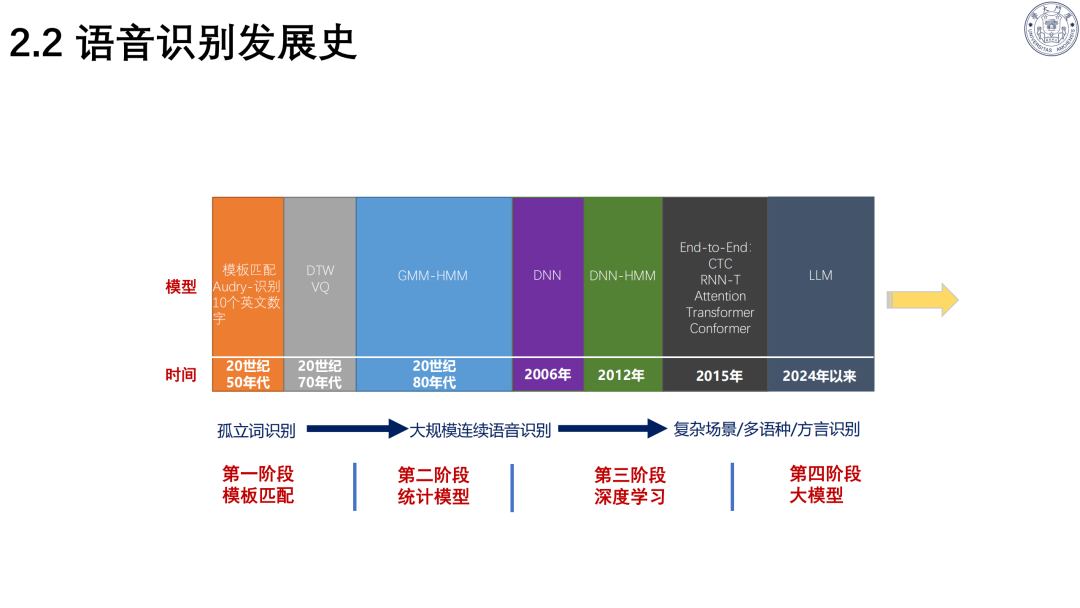
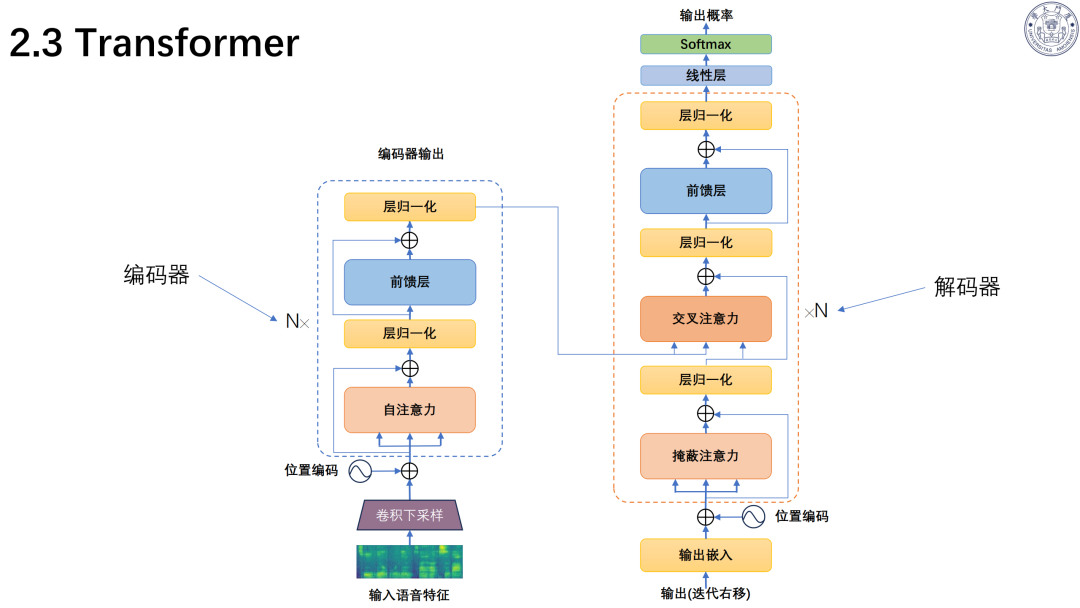
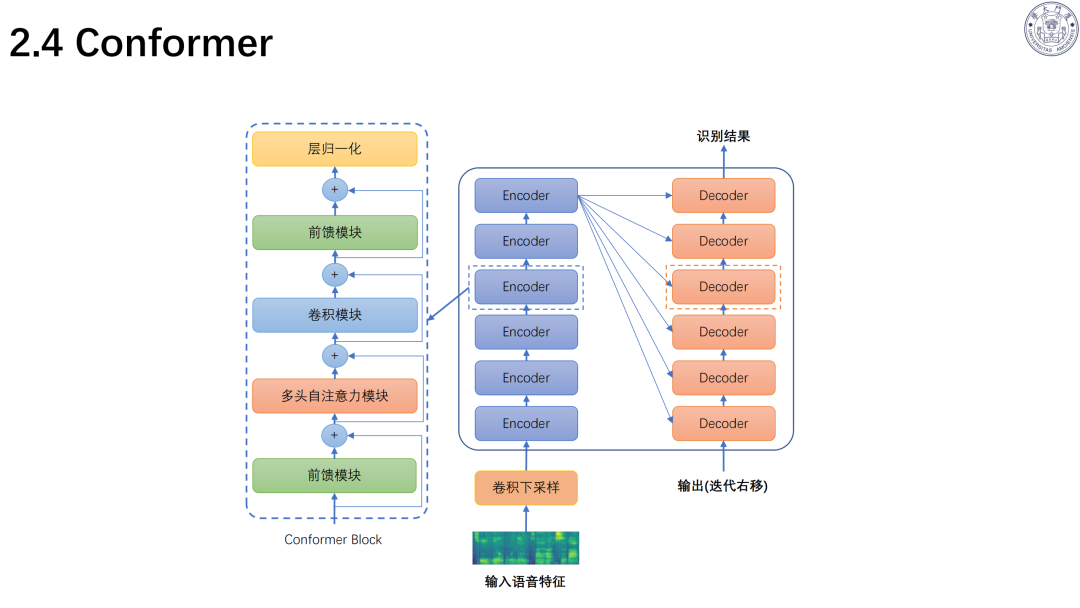
技术演进:历经模板匹配、统计模型、深度学习、大模型四个阶段;主流架构为Transformer、Conformer。
核心技术:
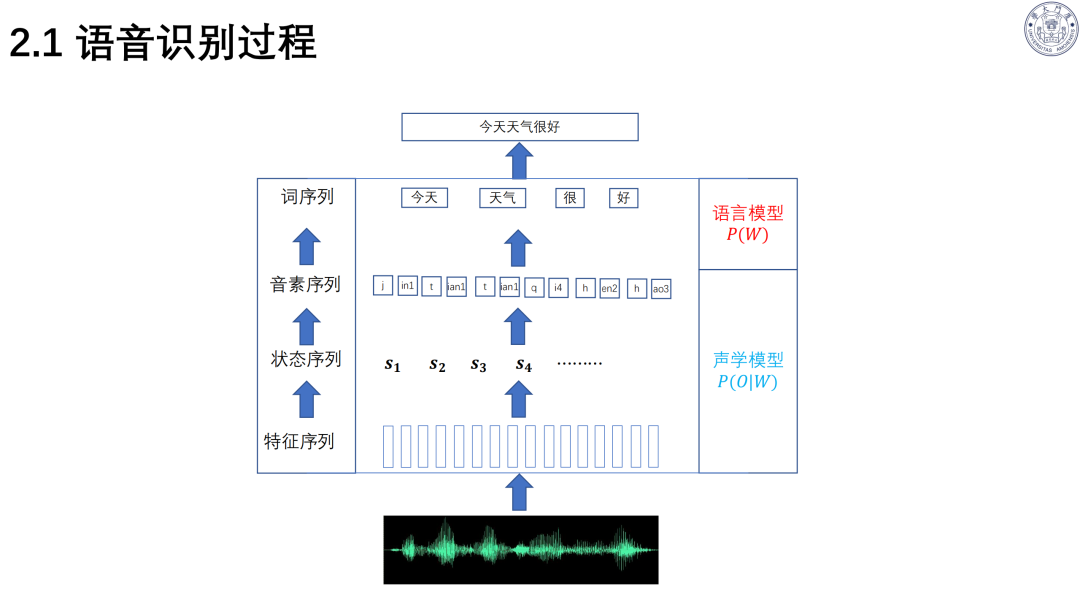
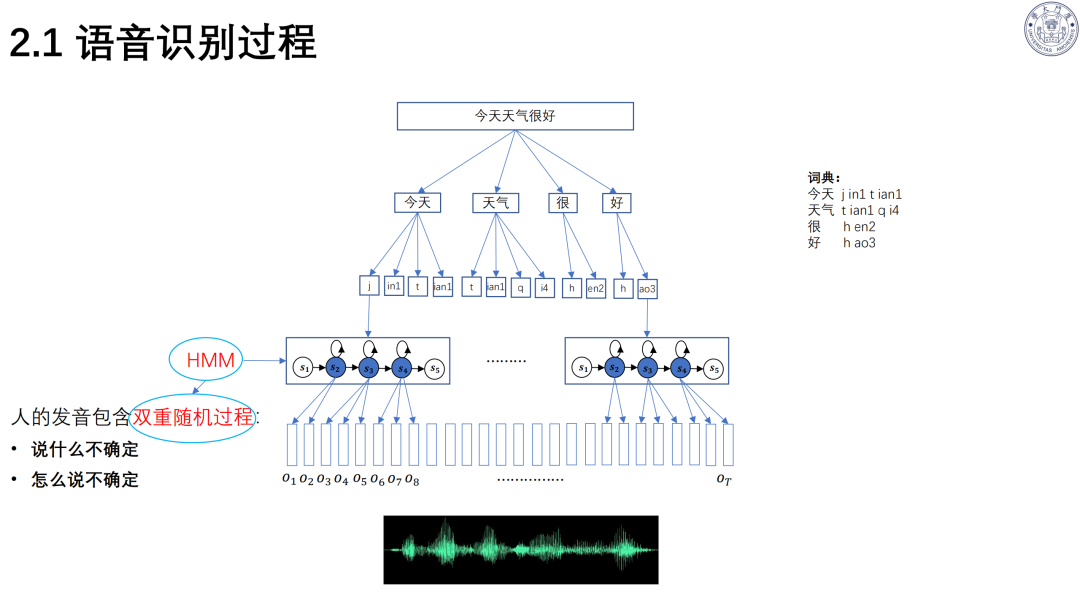
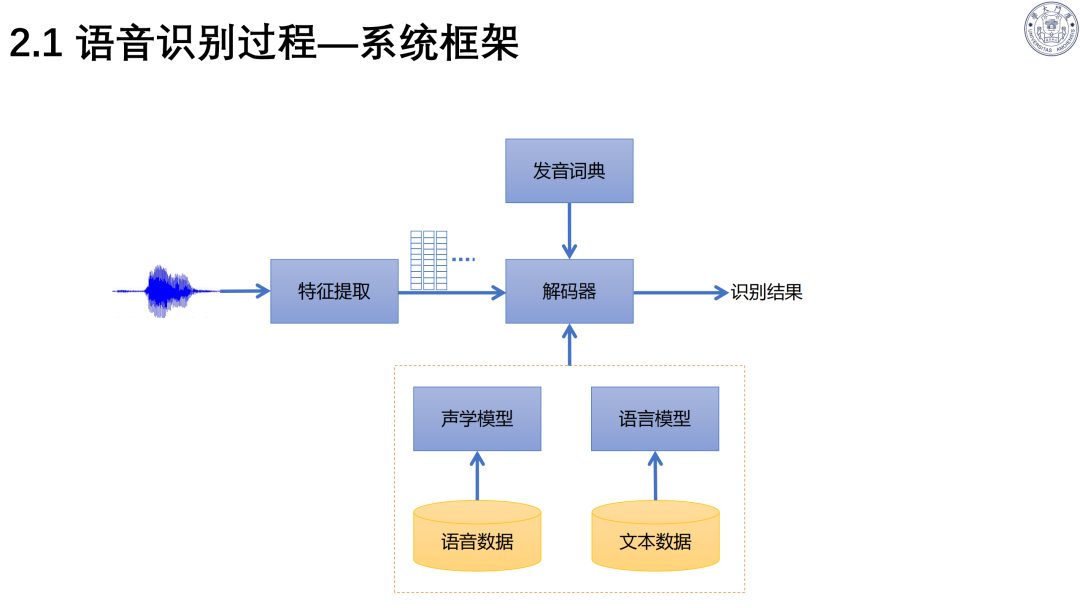
语音识别基于贝叶斯准则,依赖声学模型与语言模型;
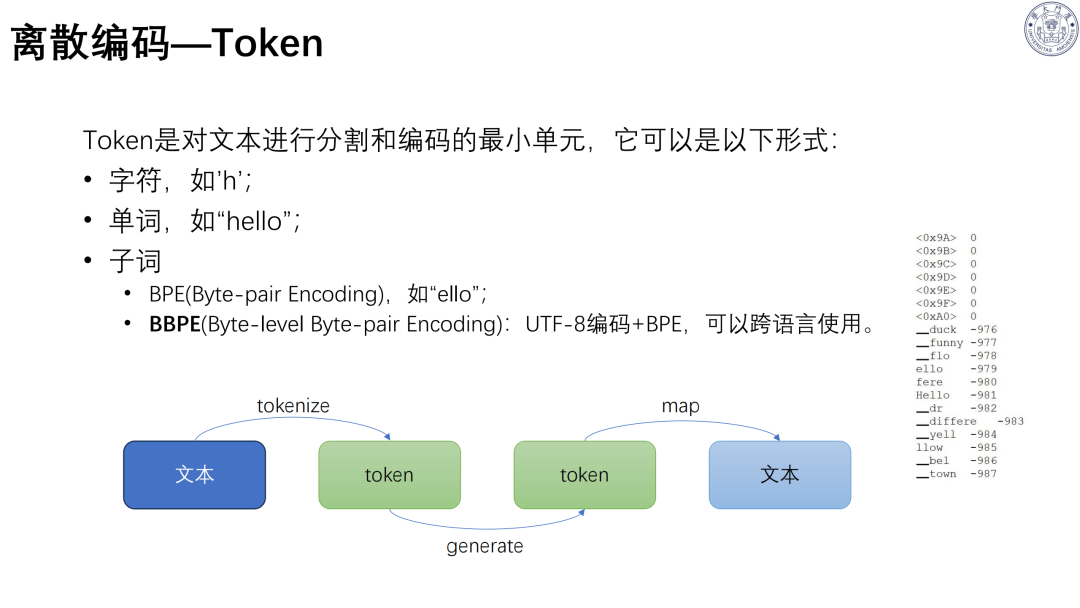
BBPE 编码解决多语种 / 方言建模,实现跨语言统一表征。
主流开源模型:
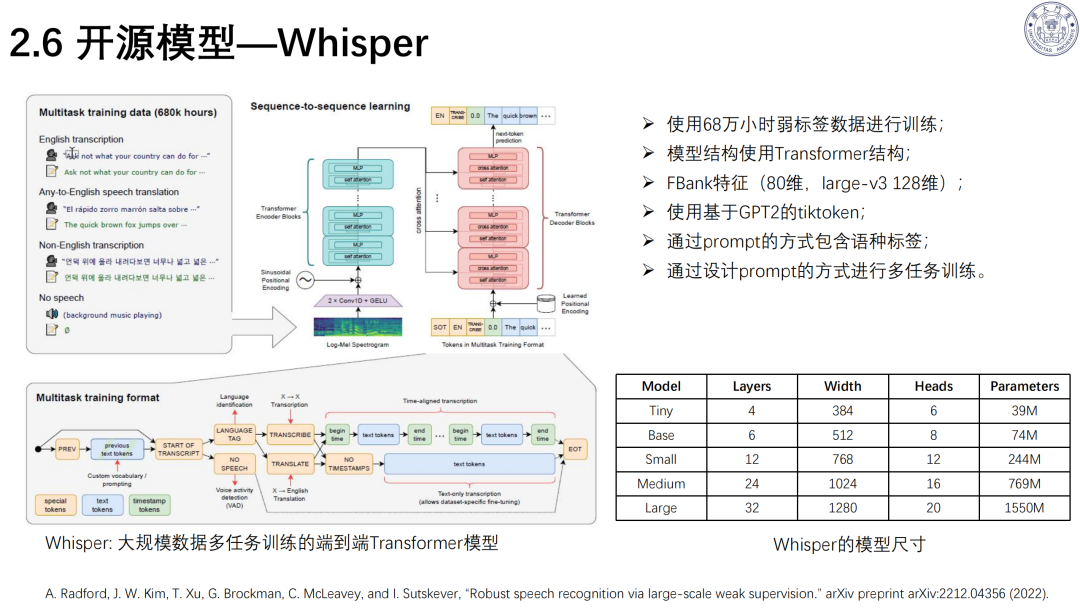
Whisper:68 万小时数据训练,支持多语种识别;
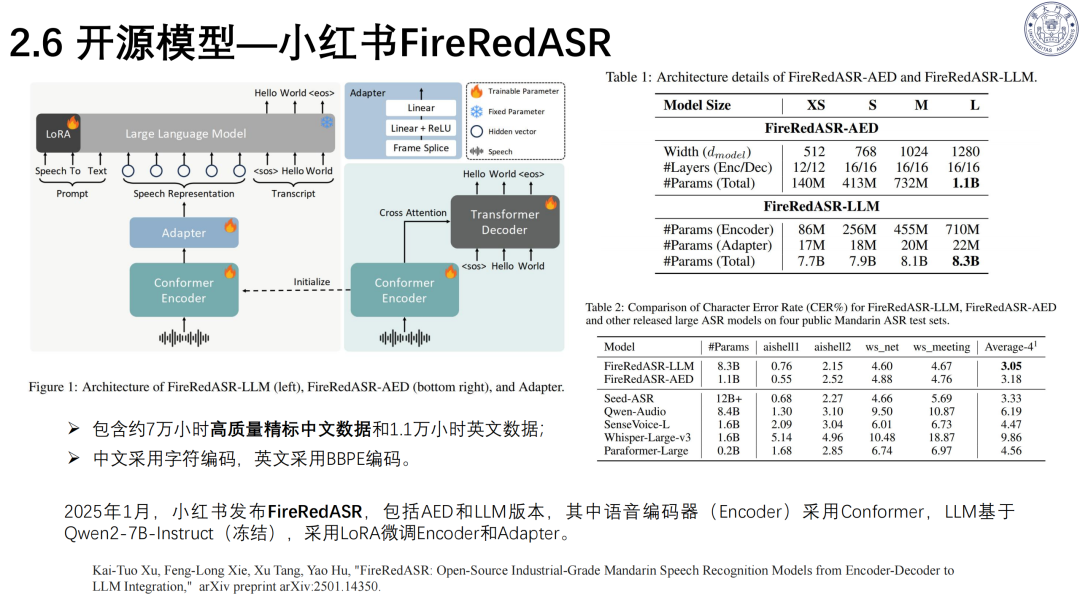
FireRedASR:中文工业级模型,中文识别精度领先;
Qwen3-ASR:支持 30 语种、22 种方言,适配流式场景。
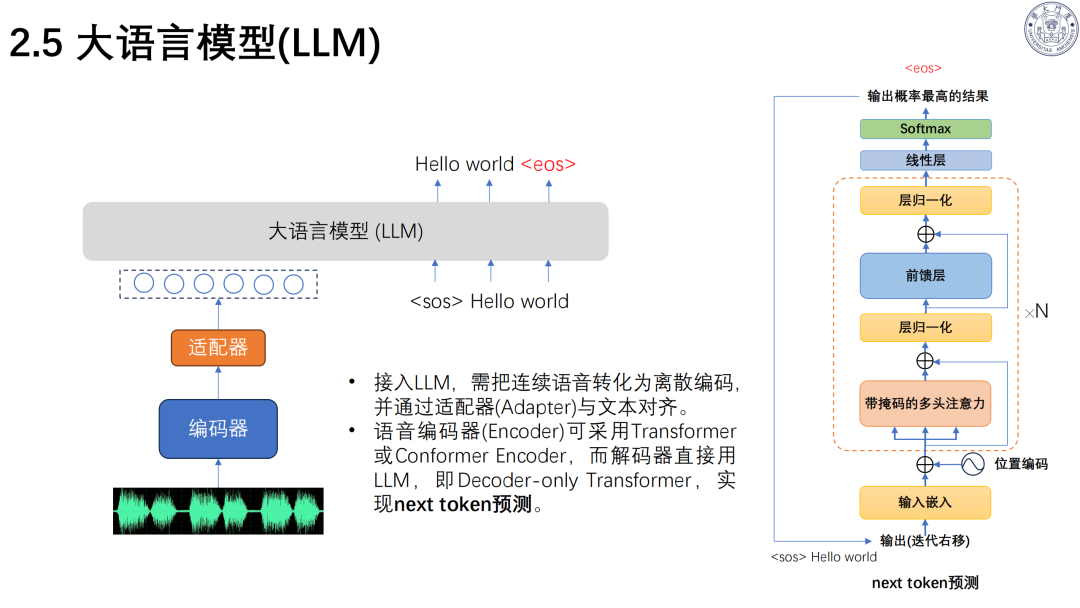
三、端到端对话模型:Speech Tokenizer+LLM + 解码器
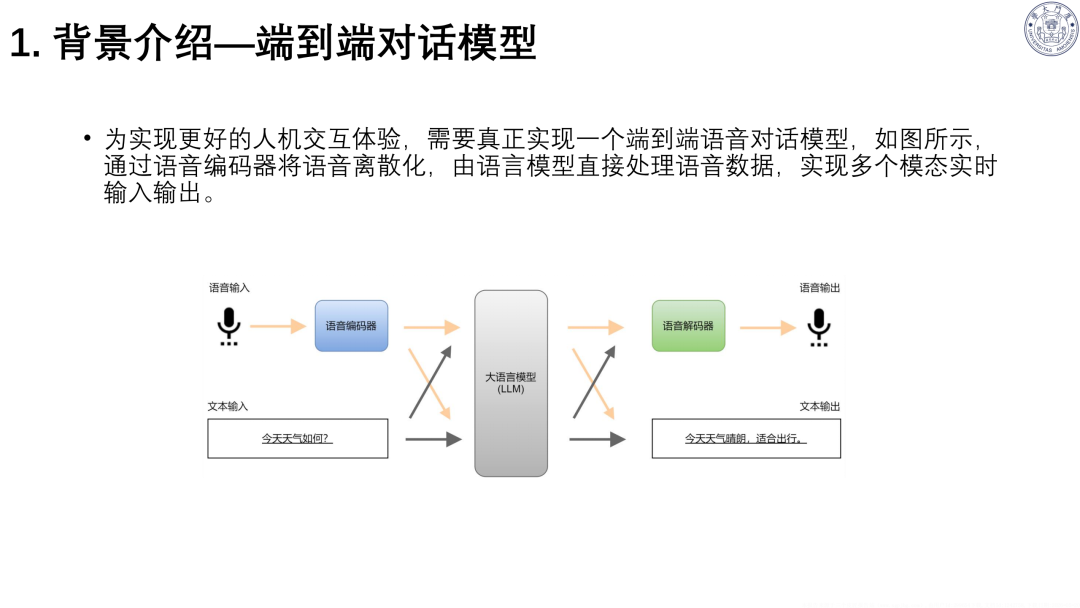
核心架构:语音 Tokenizer(编码器)→LLM→语音 Detokenizer(解码器),直接处理语音信号,保留声学与语义信息。
语音 Tokenizer 分类:
-
语义 Token:捕捉内容信息,代表模型 Whisper、HuBERT;
-
声学 Token:保留语气、情感等信息,用RVQ/FSQ 量化,代表模型 SoundStream、EnCodec;
-
统一 Token:兼顾语义与声学,代表模型 SpeechTokenizer、X-Codec。
关键生成技术:Flow Matching(流匹配),将 LLM 输出 Token 转为梅尔谱,再经声码器生成语音,提升生成自然度。
主流端到端模型:Moshi、GLM-4-Voice、Qwen-Omni、Kimi-Audio、Step-Audio2,均实现低延迟语音对话,支持情感、方言等副语言理解。
四、全双工语音交互:打断、判停与实时交互
核心挑战:用户打断、语义判停,需准确识别用户是否说完、支持随时插话。
实现方案:
-
声学 VAD:基于声音活动检测,延迟高、易误判;
-
语义 VAD:EasyTurn、Phoenix-VAD、SoulX-Duplug,融合声学与语义,判断对话状态(完整 / 不完整 / 回应 / 等待);
-
端到端建模:Moshi、Freeze-Omni、Covo-Audio 等,直接建模用户与模型双音频流,支持实时打断。
延迟优化:级联式延迟 840-3550ms;端到端模型可降至 200ms 内,接近人类交互速度。
五、落地应用与未来展望
落地场景:涵盖语音转写、多语种翻译、实时语音对话,已有声云转写、天聪语音翻译、StepAudio 交互系统等产品。
未来方向:聚焦全双工端到端对话、语音思维链(CoT)、Voice Agent,推动语音大模型更自然、智能地服务人机交互。
点击文后阅读原文,可获得下载资料的方法。









欢迎加入智能交通技术群!扫码进入。

点击文后阅读原文,可获得下载资料的方法。

联系方式:微信号18515441838

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)