cli-trainer Skill 上线,在 AI Agent 里一键微调大模型
⚠️有两个步骤依赖浏览器自动化:数据集仓库创建(自动在星河社区建仓,省去手动填表),以及训练完成后的模型标签设置(语言、任务类型、训练框架等元信息)。安装后,在对话框里描述你的需求,它会自动完成从环境检测、数据上传到训练提交、模型卡片生成的整个链路——不需要写任何训练代码,训练好的模型直接可通过API调用。必须用方括号:{"src": ["问题"], "tgt": ["回答"]},不能 {"src

上篇「星河实战派」,我们聊了星河社区的CLI训练能力:发一条命令,云端帮你跑完微调。但那条命令挺长的——baseModel要记全名,trainData要填仓库路径,超参数类型传错直接报错,光把参数搞对就得对着文档看两遍。
别急,cli-trainer正式上线了。如果你对微调大模型感兴趣、想动手体验但不想从零配环境写代码,并且你正在使用AI IDE工具,可以直接把这篇文章发给你的 AI Agent,让它帮你完成整个流程。
cli-trainer是一个面向本地AI IDE(Cursor、Claude Code 等)的Skill。安装后,在对话框里描述你的需求,它会自动完成从环境检测、数据上传到训练提交、模型卡片生成的整个链路——不需要写任何训练代码,训练好的模型直接可通过API调用。其底层是AI Studio星河社区,云端提供算力和训练环境,支持文心系列和主流开源模型。
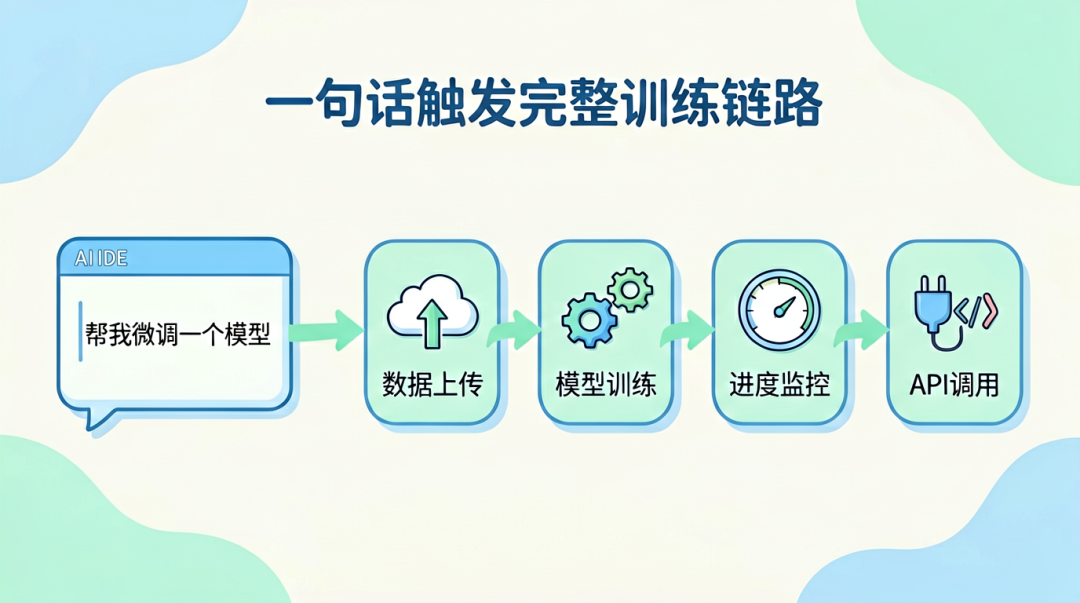
一句话触发完整训练链路
今天这篇,我们用一套数据集从零走一遍完整流程。
前期准备
1. 星河社区账号——aistudio.baidu.com注册,免费
2. Access Token——登录后访问aistudio.baidu.com/account/accessToken 获取。注意必须是这个页面的令牌,不是API Key或SDK缓存token——后两者没有训练所需的写权限,会鉴权失败。获取后推荐设为环境变量:
export AISTUDIO_ACCESS_TOKEN="your_token"
3. 训练数据集——数据集没有白名单限制。三种来源都可以用:Skill内置了一批公开数据集(--list-datasets查看),可直接用于快速体验;也可以直接指定星河社区上已有的数据集仓库路径;或者通过CLI将本地文件上传到星河社区,Skill会自动完成建仓和上传,不需要手动填表单。
💡小提示:创建数据集仓库时建议把可见性设为公开,私密数据集在平台侧有一定的挂载限制
安装
cli-trainer已在星河社区Skill学习与教程专区(aistudio.baidu.com/skillhub)正式上线。进入平台首页下滑至Skill专区即可找到(文末附专区入口)。

或者更快捷的方式——直接在AI IDE对话框里发送:
帮我把github.com/liuyunlin/cli-trainer安装到本地
安装完成后重启会话,IDE即可自动识别新Skill。
支持模型
平台对模型进行白名单管理,目前支持ERNIE系列、DeepSeek系列、Qwen2.5系列等主流模型,后续会持续扩充。安装Skill后运行 --list-models可查看当前完整列表。
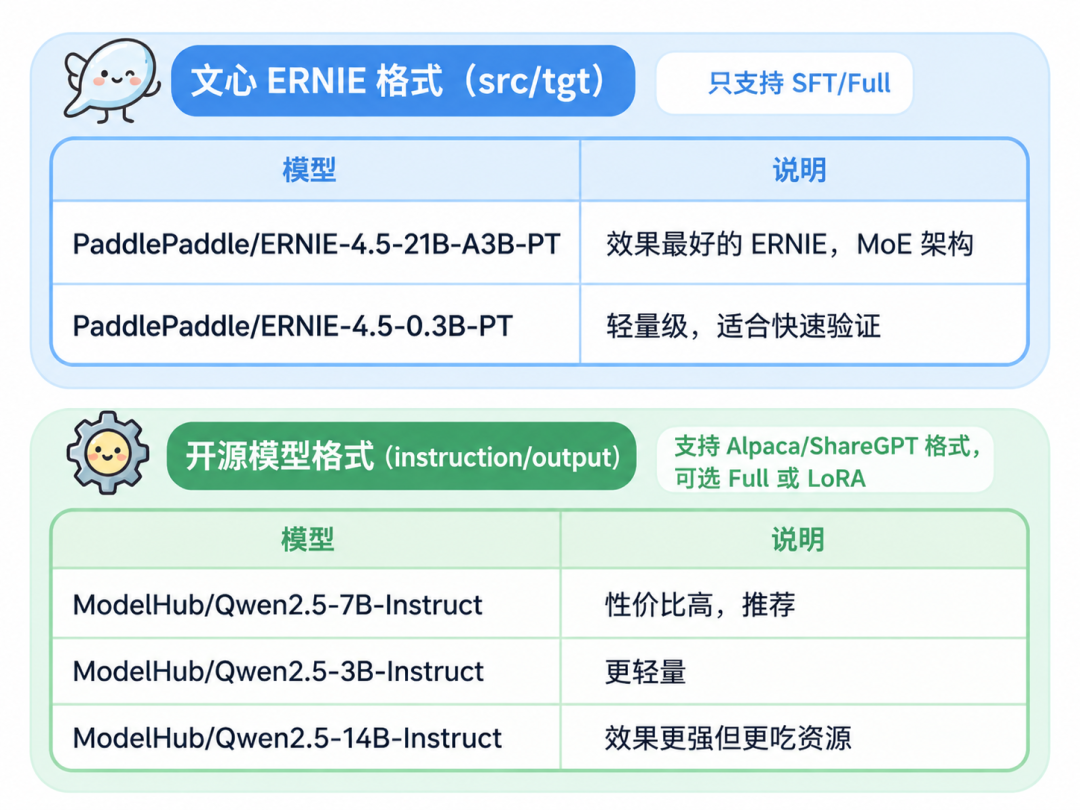
部分主流白名单模型
数据格式
文心系列使用PaddleFormers框架,格式为src/tgtJSONL,其中src和tgt的值必须是列表:
{"src": ["输入/问题"], "tgt": ["期望输出/回答"]}⚠️ 写成裸字符串是最常见的错误,会报"非ERNIE格式"。必须用方括号:{"src": ["问题"], "tgt": ["回答"]},不能 {"src": "问题", "tgt": "回答"}。
开源模型使用 LlamaFactory,支持 Alpaca 和 ShareGPT 两种格式:
{"instruction": "问题", "input": "", "output": "回答"}{"conversations": [{"from": "human", "value": "问题"}, {"from": "gpt", "value": "回答"}]}也支持JSON数组文件。数据量参考:50–500条够跑通流程,1,000–10,000 条适合垂直领域微调,10,000条以上才谈全面提升。
使用流程
触发Skill后,整个微调流程按以下顺序自动推进:
-
环境自检 — 检测 Python 版本、依赖包、网络连通性
-
Token 验证 — 确认 Access Token 有效
-
选模型 — 展示白名单,从中选择
-
验数据 — 检查数据格式,提前拦截不匹配的情况
-
准备数据集 — 若需上传本地数据,自动完成建仓和上传
-
推荐超参 — 根据数据量和模型大小给出推荐参数,等确认后才提交
-
提交训练 — 获得 Job ID
-
监控进度 — 自动轮询状态;进入训练后可打开 Tensorboard 看板
-
完成收尾 — 输出训练报告、给出模型仓库地址、推送模型卡片 README、设置元信息标签。
✨整个流程中,Skill不会在未经确认的情况下自动提交训练任务
⚠️有两个步骤依赖浏览器自动化:数据集仓库创建(自动在星河社区建仓,省去手动填表),以及训练完成后的模型标签设置(语言、任务类型、训练框架等元信息)。Skill优先使用Playwright MCP(本地 IDE 通常已集成),也支持web-access Skill(需要用户 Chrome 开启远程调试授权)以及其他基于CDP协议的浏览器自动化工具。两者都不可用时,Skill会引导用户手动完成这两步。
👉推荐在本地AI IDE(Cursor、Claude Code)中使用,网页端AI产品浏览器权限受限,相关功能可能无法运行。
下面用一个真实的潮汕话问答数据(507条,src/tgt格式)微调ERNIE-4.5-0.3B,走一遍关键步骤。
环境自检→Token验证→选模型
Skill 先检查本地环境是否就绪,然后验证你的 Access Token。Token 来源优先级:环境变量 > 命令行参数 > SDK 缓存,如果环境变量里存的是旧 Token,可能会和缓存冲突导致鉴权失败——遇到 401 的话,先检查是不是 Token 过期了。
环境通过后,Skill 会展示模型白名单让你选择。平台对模型做了白名单管理,只有列表里的模型才能提交训练。
验数据
选好模型之后,Skill 会对你的数据做格式检测。ERNIE 模型需要 src/tgt 格式,开源模型需要 Alpaca 或 ShareGPT 格式——格式不对的话训练阶段才会报错,白等半天。Skill 在提交之前就会帮你拦住。
文件容器: JSONL记录数: 507检测到格式: ERNIE 格式(src/tgt)格式检查: 全部通过 [OK]准备数据集
如果用自己的数据,Skill 会帮你上传到星河社区的数据集仓库。上传方式优先走浏览器自动化(Playwright MCP),不可用的话会引导你手动创建仓库再通过 SDK 上传。
⚠️ 注意:新建的数据集仓库默认 .gitattributes 里会把 *.jsonl 和 *.json 文件走 LFS 存储,导致训练时平台拉到的是 LFS 指针而非真实文件,任务会卡在 waiting_data。Skill 在上传后会自动校验(--verify-upload),如果发现 LFS 问题会帮你修复——编辑 .gitattributes、删除指针文件、重新上传。
如果不想用自己的数据,Skill 内置了 11 个推荐数据集(--list-datasets 查看),直接选一个就能跑通。
推荐超参
Skill 根据你的数据特征和选择的模型自动算一组推荐参数,不是给万能默认值——比如根据数据平均字符长度推算 max_seq_len,根据模型大小推荐学习率。确认后才提交,不会跳过确认直接动手。
样本数:507平均字符长度:65 -> 建议 max_seq_len:128推荐超参数: num_train_epochs: 3 per_device_train_batch_size: 4 learning_rate: 5e-05 max_seq_len: 128 warmup_steps: 50 bf16: true快速选参心法:
效果差/loss 不降 → 先查数据质量再调小 learning_rate;
OOM → 调小 batch_size 或 max_seq_len;
想多训几轮 → 调大 num_train_epochs。
提交训练 → 监控进度
确认参数后提交,任务在云端执行。提交成功后会拿到 Job ID,Skill 自动轮询状态:
waiting_data → pending → running → succeeded / failedwaiting_data 超过 10 分钟的话,Skill 会自动检查系统日志帮你定位问题。
完成收尾
训练成功后,Skill 会输出训练报告(loss 趋势和收敛分析)、给出模型仓库网页地址、推送模型卡片 README、设置元信息标签。
我们本次微调的训练信息👉507 条数据、ERNIE-4.5-0.3B、3 个 epoch,从提交到完成大约 5 分钟。
训练好的模型自动上传到你的星河社区模型库(aistudio.baidu.com → 右上角头像 → 个人主页 → 左侧「模型」),API 直接调用。
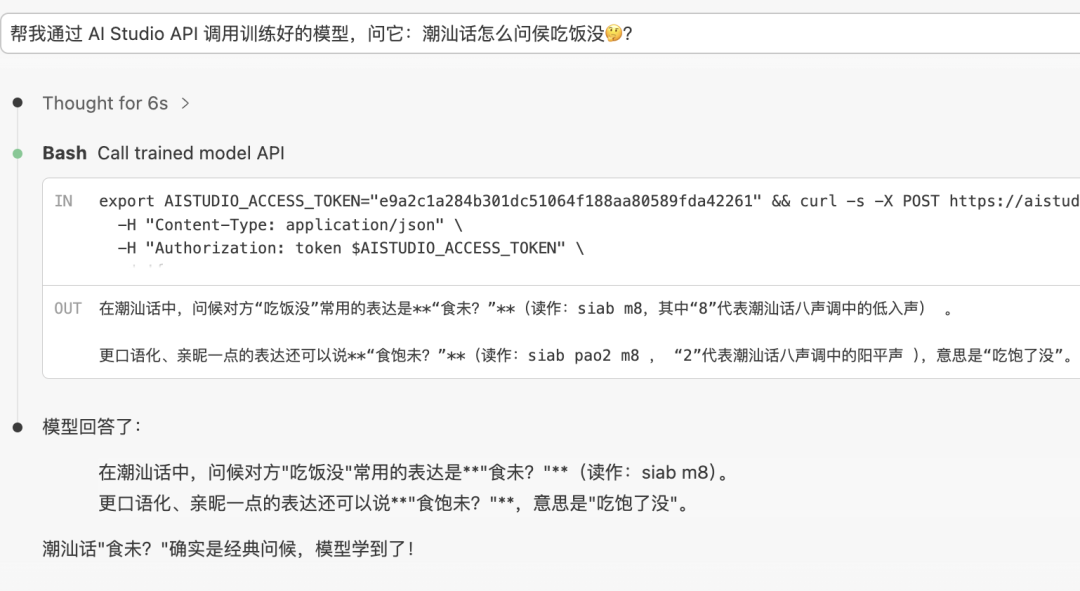
完成后,不需要切浏览器,即可在 IDE 对话框里完成对话,AI 会自动构造请求,模型回复直接就会出现在对话里。
帮我通过 AI Studio API 调用训练好的模型,问它:潮汕话怎么问侯吃饭?
重要限制
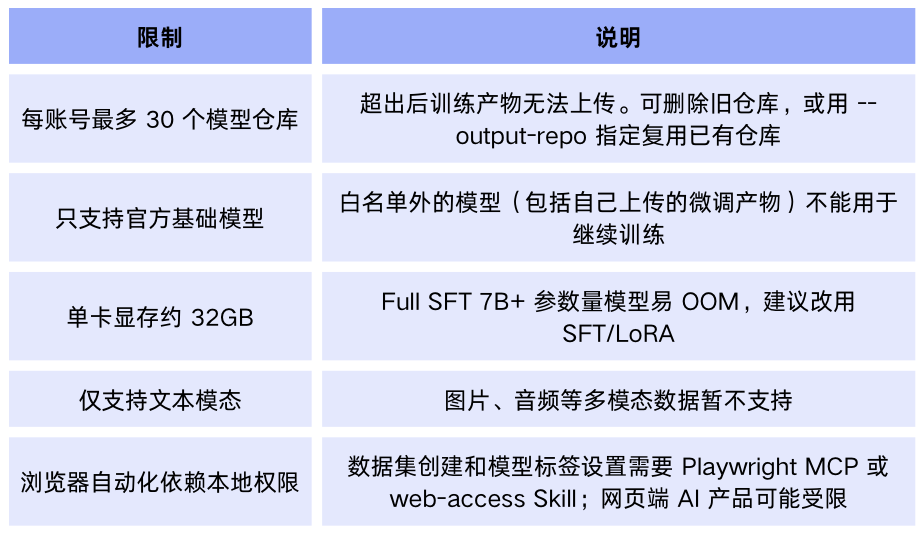
常用命令速查
# 环境与鉴权
python3 train.py --env-check
python3 train.py --verify-token
# 查看可用资源
python3 train.py --list-models
python3 train.py --list-datasets
# 数据检验与超参推荐
python3 train.py --check-data train.jsonl
python3 train.py --suggest-params train.jsonl --model-type llama
# 提交训练
python3 train.py --submit \
--base-model 'hetiechao/Qwen2.5-0.5B-Instruct' \
--train-type 'SFT/LoRA' \
--train-data 'your_gitlogin/your_dataset' \
--train-file 'train.jsonl' \
--params '{"num_train_epochs": 3, "learning_rate": 5e-5, "lora_rank": 8, "fp16": true}'
# 监控与诊断
python3 train.py --status JOB_ID
python3 train.py --logs JOB_ID
python3 train.py --diagnose JOB_ID
python3 train.py --train-summary JOB_ID
python3 train.py --cancel JOB_ID
常见问题
waiting_data 超过 10 分钟?
Skill 会自动诊断,按顺序排查:repo_id 是否来自详情页;--train-file 是否和仓库实际文件名一致;文件是否被 LFS 劫持(需 is_lfs: false)。如果日志持续循环"正在等待数据集下载完成",通常是平台内部挂载问题,保留 Job ID 联系平台排查。
ERNIE 模型报"非 ERNIE 格式"?
src 和 tgt 的值必须是列表:{"src": ["问题"], "tgt": ["回答"]}。
超参数提交时报类型错误?
超参数值不能加引号,3 而非 "3",5e-5 而非 "5e-5"。
SFT/LoRA 训练完成但模型调用失败?
需确认平台完成了 LoRA 合并导出,模型仓库中应有 model.safetensors、config.json、tokenizer.json 等完整权重文件,而非仅 adapter 文件。
遇到问题如何排查?
提供 Job ID 和报错截图,在评论区留言或联系官方即可。Job ID 格式如 aistudio_train_job_20260515xxxxxx_xxxx,Skill 提交训练时会在对话中输出;找不到可以直接问 AI IDE:"帮我查一下刚才提交的训练任务 Job ID"。
写在最后
上篇说"发一条命令就能训模型",这篇把这个命令也省了,强烈推荐大家亲自体验一下。
cli-trainer Skill 解决的不是一个技术难题,它解决的是一个体验断裂:你每天在 IDE 里写代码,但想让模型更懂你的业务,得打开浏览器、去另一个平台、填一堆表单。现在不用了——在对话框里说一句话,Skill 即可帮你跑完全流程,训好的模型 API 直接调。
评判一个工具好不好,标准其实很简单:它能不能让你在正在做的事情上少跳出去一步。
👉 星河社区:aistudio.baidu.com
👉 两种Skill获取途径:
①星河社区skill学习与教程专区:
aistudio.baidu.com/skillhub
②在 AI IDE 中发送"帮我把 github.com/liuyunlin/cli-trainer 安装到本地"
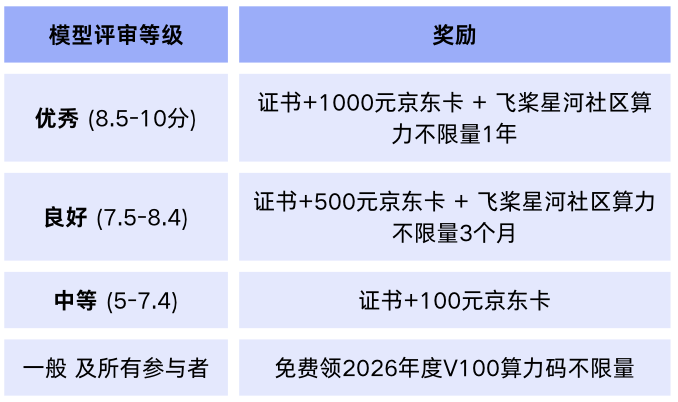
🎁 训完别急着关——ERNIE衍生模型还能赢好礼👇👇👇
ERNIE衍生模型激励计划
CLI Trainer Skill微调ERNIE,赢京东卡!
即日起,上传你用Skill训练的ERNIE衍生模型,即可赢奖励!
📌 模型提交链接:
https://paddle.wjx.cn/vm/YlUbBvE.aspx#
📅 活动截止至 2027年6月30日,每季度评审一次,无上限名额。
⬇️ 扫码加入官方活动群,获取活动最新消息:

别让它躺在模型库里吃灰了,赶快行动起来吧👏
相关推荐:



关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)