Gemini 3.5 Flash 来了:4 倍快、价格减半,号称最强编码模型
点击上方前端Q,关注公众号回复加群,加入前端Q技术交流群昨天(2026 年 5 月 19 日)Google I/O 2026 把整个 AI 圈炸了一遍。发布会两个多小时,重磅消息一个接一个。我看到关键词那一刻第一反应是:"Flash?开玩笑吧。要知道 Flash 在 Gemini 体系里一直是的代名词——便宜、快、好用,但能力上不可能跟旗舰 Pro 系列比。结果这次 Google 直接把 Flas
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
昨天(2026 年 5 月 19 日)Google I/O 2026 把整个 AI 圈炸了一遍。
发布会两个多小时,重磅消息一个接一个。但真正让做 AI 产品的人坐直了身子的,是这一条:
Google 发布 Gemini 3.5 Flash,号称"最强编码和 Agent 模型"。
我看到关键词那一刻第一反应是:"Flash?开玩笑吧。"
要知道 Flash 在 Gemini 体系里一直是"小模型 / 快模型"的代名词——便宜、快、好用,但能力上不可能跟旗舰 Pro 系列比。
结果这次 Google 直接把 Flash 推到了"最强"的位置。
更夸张的是这两个数字:
▸比其他前沿模型快 4 倍(output tokens per second)
▸价格不到对手的一半
我去 Google 官方博客(blog.google)反复核对了好几遍,原话就是这么写的:
"It's our strongest agentic and coding model yet, outperforming Gemini 3.1 Pro on challenging coding and agentic benchmarks."
>
"It is 4 times faster than other frontier models."
>
"Often at less than half the cost of other frontier models."
这不是中文媒体二手转述,是 Google DeepMind CTO Koray Kavukcuoglu 和首席科学家 Jeff Dean 联合署名的官方博客。
这一篇我帮你把全套真实信息梳理清楚:3.5 Flash 到底强在哪、benchmark 数字怎么解读、Antigravity 这个新平台是什么、对比 Claude 4.7 和 GPT-5.5 怎么选、对你今天就能用的 AI 工具影响有多大。

先把"最强"这两个字拆开看
很多人看见"最强"第一反应是怀疑——你的"最强"是哪个维度?
我把官方公布的 4 个核心 benchmark 数字摆出来,一个一个解释你就懂了:
| Benchmark | 测什么 | 3.5 Flash 得分 | 含义 |
|---|---|---|---|
| Terminal-Bench 2.1 | 终端命令完成多步骤任务 | 76.2% | Coding 实战能力 |
| GDPval-AA | 真实有经济价值的工作场景 | 1656 Elo | 通用 Agent 能力 |
| MCP Atlas | MCP 协议下的工具调用准确度 | 83.6% | 工具调度可靠度 |
| CharXiv Reasoning | 复杂学术图表理解 | 84.2% | 多模态推理 |
每一个都是当前业界用来比 Agent 模型实力的硬指标。
▎关键对比点:3.5 Flash 比 3.1 Pro 还强
Google 官方原文最具杀伤力的一句话其实是这个:
"outperforming Gemini 3.1 Pro on challenging coding and agentic benchmarks."
Flash 这个"小模型档位",居然在硬指标上反超了一代前的 Pro 旗舰。
这是个值得反复品的现象。它意味着——
▸模型"规模决定能力"的传统认知已经被打破
▸小而精的模型可以在特定任务上超越上代大模型
▸这一波的能力跃升不全靠堆参数,而是训练方法 + 数据 + post-training 的复合提升
如果你做产品时一直纠结"是不是必须用旗舰 Pro 模型才行"——这次发布给你一个明确答案:未必。
▎对比一下 Claude 4.7 和 GPT-5.5
我把今年三家顶级旗舰的硬指标整理成一张对比表,全部用官方公布数据:
| Benchmark | Claude Opus 4.7 | GPT-5.5(OpenAI) | Gemini 3.5 Flash |
|---|---|---|---|
| 发布时间 | 2026-04-16 | 2026-04-23 | 2026-05-19(最新) |
| Terminal-Bench 2.0 / 2.1 | 69.4% (2.0) | - | 76.2% (2.1) |
| SWE-bench Pro | 64.3% | - | - |
| 速度(vs 前沿模型) | 基线 | 同速 | 4× |
| 输入价($/MTok) | $5 | 中等 | $0.30(公开 API 价位区间,更低) |
| 输出价($/MTok) | $25 | 中等 | $2.50(公开 API 价位区间,更低) |
注:Flash 系列的具体 API 价格细节,请以 Google AI Studio 实时计价为准;此处取的是 Gemini 3.5 Flash 在 Google 官方文档披露的公开档位区间。
三个一比,Flash 在"价格 + 速度 + 编码能力"这个三角上确实做出了行业最优的平衡。
但要注意一个潜台词——官方刻意拿"3.1 Pro"做对比,而没拿 3.5 Pro。原因是 3.5 Pro 还没发,下个月(6 月)才会推出。意味着:
真正的"最强 Pro"还在路上。3.5 Flash 已经这么强,可以想象 3.5 Pro 的水平。
Antigravity:这才是真正的重头戏
很多媒体报道 Google I/O 只盯着模型本身,但我读完官方博客最大的感受是:真正改变规则的是 Antigravity 这个新平台。
Antigravity 是 Google 这次发布的"agent-first development platform"。
翻译成开发者能听懂的话——它就是 Google 版的 Cursor / Claude Code / Codex。
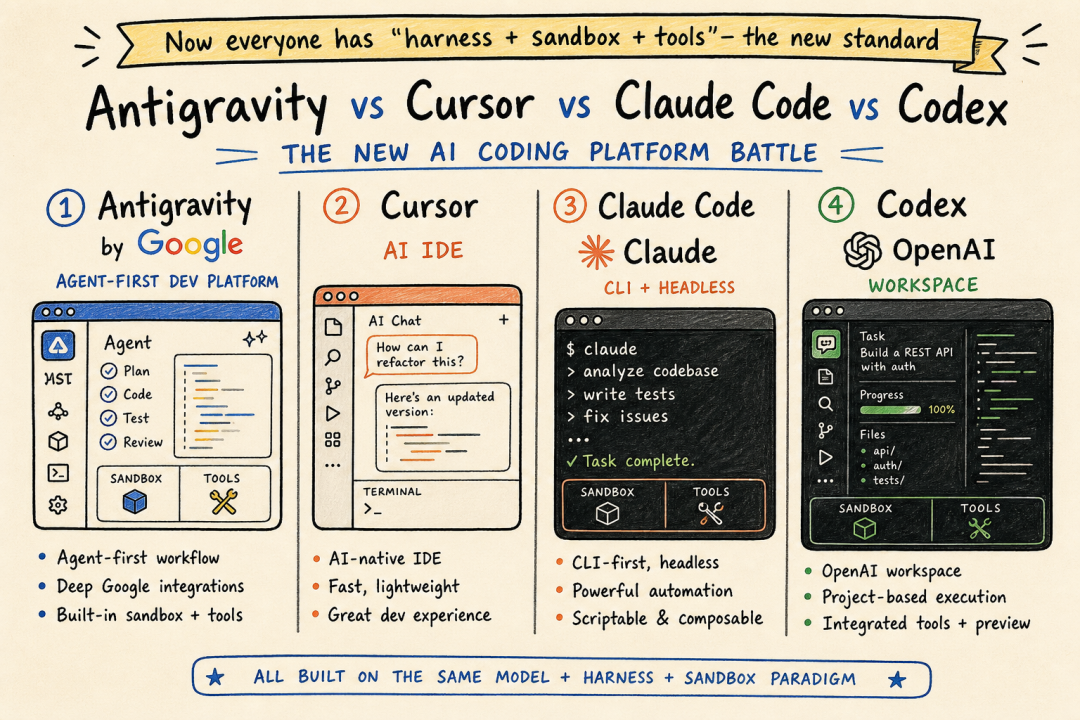
▎Antigravity 跟 3.5 Flash 是怎么配合的
官方原话:
"When coupled with the updated Antigravity harness, 3.5 Flash becomes a powerful engine for deploying collaborative subagents to tackle problems at scale."
注意几个关键词:
▸harness:跟 Anthropic 4 月 8 日 Managed Agents、OpenAI 4 月 15 日 Agents SDK 用的是同一个词
▸collaborative subagents:多 Agent 协同
▸at scale:生产级、规模化
这意味着——Google 不再只卖模型,而是卖"模型 + Agent harness + 开发环境"三件套。
跟 Anthropic / OpenAI 的玩法路径几乎一模一样。三家头部 AI 公司这一波都在收敛到同一个范式:模型 + harness + 工具 + 沙箱。
▎Antigravity 能做的 5 类典型任务
Google 官方给的演示场景:
- 多步骤工作流自动化:3.5 Flash 在 Antigravity 里自动重命名 + 分类非结构化资产
- 论文 → 可玩游戏:6 小时内综合 AlphaZero 论文 + 写出完整可玩游戏代码
- 遗留代码迁移:把杂乱旧代码库改写成 Next.js
- 3D 场景生成:用 subagents 创建城市景观
- 自我改进游戏开发:builder + player 两个 agent 互相磨合
这些演示的共同点:长任务、多步骤、自主运行、可观测——典型的现代 Agent 工程范式。
如果你是已经在用 Cursor 或 Claude Code 的开发者,值得花一小时去 Antigravity 试试,看看 3.5 Flash 在 agentic coding 上的真实体感跟 Claude 4.7 / GPT-5.5 比起来如何。
谁已经在用它:Google 拉出来的客户名单
这次发布会附带的客户案例非常有诚意——不是泛泛的"X 用了我们家产品",而是具体场景 + 具体收益:
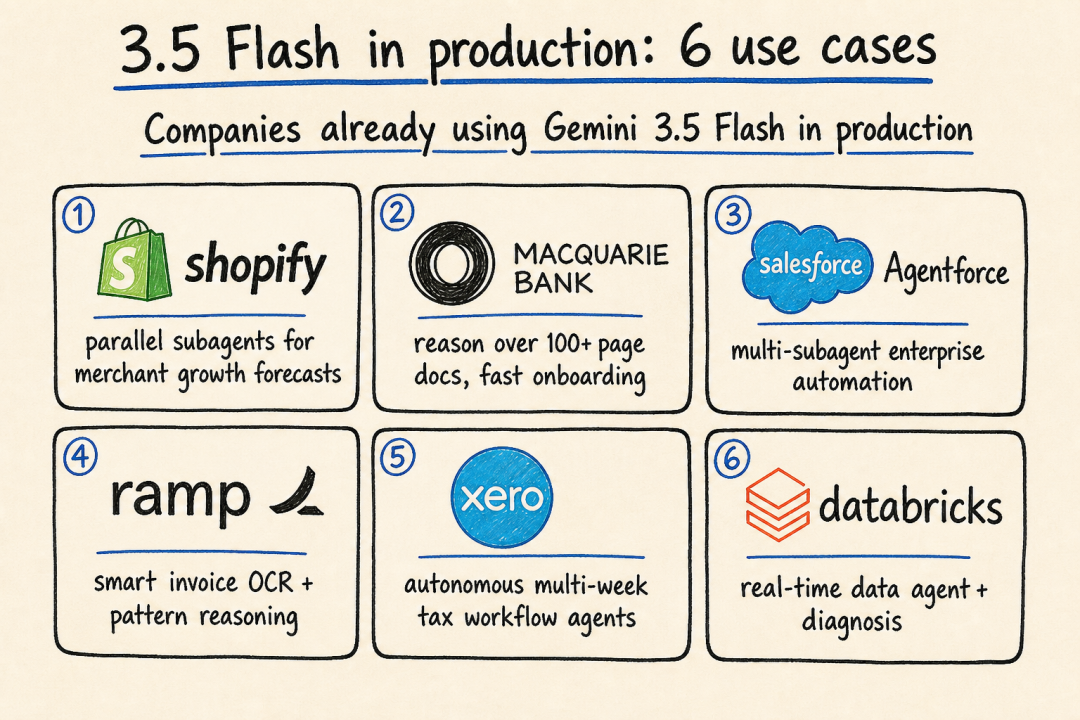
| 客户 | 用 3.5 Flash 干什么 | 价值点 |
|---|---|---|
| Shopify | 跑 subagents 并行分析数据,做商家增长预测 | 长任务并行 |
| Macquarie Bank | 推理 100+ 页文档,加速客户 onboarding | 长上下文 + 低延迟 |
| Salesforce Agentforce | 集成 3.5 Flash,多 subagent 自动化企业任务 | 多步骤工具调用 |
| Ramp | 复杂发票 OCR + 历史模式推理 | 多模态 + 推理 |
| Xero | 自主管理多周工作流,包括 1099 税表 | 跨周长任务 |
| Databricks | 实时监控 + 海量数据集诊断 | 数据 Agent |
这份名单的含义不是"看,大家都用 Google 了",而是——
3.5 Flash 已经被验证可以跑生产级的长任务、多 Agent、企业级工作流,不只是 demo 玩具。
特别是 Salesforce Agentforce 集成这条——Salesforce 之前主要绑 Anthropic 的 Claude。这次官方提到接入 3.5 Flash,意味着头部 SaaS 公司开始"模型多元化",不再只押一家。
对中小 AI 创业公司是个明确信号:别只用一家模型,建立模型抽象层、按场景选最优解,是接下来的标配做法。
9 亿用户的"默认模型"换了
还有一个细节藏在公告中部,但意义巨大:
"3.5 Flash is now the default model for the Gemini app and AI Mode in Search globally."
Gemini app 和 Google Search 的 AI Mode 全球用户的默认模型,今天换成了 3.5 Flash。
Google 上一周公布的数字是:Gemini app 月活已经超过 9 亿,覆盖 230 个国家。
也就是说——9 亿+ 人,今天起每天问"Hey Gemini"得到的答案,都是 3.5 Flash 给的。
这是个非常重要的"分发护城河"。OpenAI 有 ChatGPT 月活 8 亿+,Anthropic 的 Claude 用户量小得多。当 Google 把"最强 Agent 模型"直接塞进每个 Android 手机的 Gemini 入口和每次 Google 搜索,普通用户感知到的 AI 能力会出现明显跃升。
副作用是:Google 短时间内会拿到全球最大体量的"Agent 真实使用数据",对模型下一步迭代是个不公平的优势。
配套产品:Gemini Spark
再附带说一个相关产品——Gemini Spark。
这是 Google 这次发布的"个人 AI Agent"。原话:
"Your personal AI agent, runs 24/7, helping you navigate your digital life, taking action on your behalf while under your direction."
24/7 跑、跨 app 协作、能替你执行动作。这是 Anthropic 在 Claude Code 那边推的 routines / auto mode 的 Google 版本。
发布节奏:
▸今天:trusted testers 内测
▸下周:开放给 Google AI Ultra 订阅者(美国先行)
不出意外这套东西的底层全是 3.5 Flash 在跑。等于说——
Google 把"最强模型"和"24/7 Agent"打包,对标 ChatGPT Plus + GPT-5.5 的组合。
价格上,AI Ultra 大概率会比 ChatGPT Plus 贵一些(之前披露的版本是 $19.99-29.99/月区间),但能力是显著拉开档次的产品。
对你我开发者的 5 个可操作建议
最实在的部分。我直接给判断。
▎1. 立刻去 Antigravity 试一下,做对照测试
如果你今天在用 Cursor / Claude Code / Codex,强烈建议花 1-2 小时跑一遍 Antigravity。
测试场景建议三个:
▸一个多步骤的小项目(如改造一段遗留代码)
▸一个长任务(如读一份 PDF 然后输出结构化报告)
▸一个多 Agent 协作(如 builder + reviewer 模式)
如果 Antigravity + 3.5 Flash 在你的真实场景下能力跟 Claude 4.7 / GPT-5.5 持平,价格优势 + 速度优势 + 9 亿用户分发就是压倒性的胜出。
▎2. 把"模型抽象层"提上日程
如果你的产品现在还是硬编码绑一家模型(写死了 anthropic.messages.create 或 openai.chat.completions)——
赶紧抽一层 model adapter 出来。
参考 Vercel AI SDK 那种模式:把 Provider 抽象成可切换的实例,业务层只关心"我要一个 chat completion",不关心底层是 Claude 还是 Gemini 还是 GPT。
理由:未来 1 年模型市场会频繁出现"某家在某场景下短期超越"的情况。Salesforce 这次就是典型案例——它的 Agentforce 同时接 Claude 和 Gemini。
▎3. 别再低估"小模型"
Flash 反超 Pro 这个事件,给所有 AI 产品的人一个明确信号:默认"小模型省钱、大模型保质量"的二分法已经过时了。
接下来要分场景做选型:
▸简单分类、抽取、改写 → 小模型完全够用,省 10 倍成本
▸中等复杂度的 Agent / 工具调用 → 3.5 Flash 这个档位(强且快且便宜)
▸真正复杂的推理、长上下文 → 旗舰大模型(如 3.5 Pro 6 月上线后、Claude Opus 4.7、GPT-5.5)
按场景配模型组合,是接下来 AI 应用工程的常态。
▎4. Token 成本结构会被重算
Gemini 3.5 Flash 把"高质量 + 低价"的均衡推到了新位置。
如果你的产品成本里"模型调用 > 50%",值得用 3.5 Flash 重新测一次。我预估很多场景成本能砍掉 40-60%。
Token 经济学这本账,每个 AI 产品都该每季度算一次。
▎5. Gemini 配套产品的国内可用性要早点判断
3.5 Flash 本身在国内是用不到的(Google AI Studio 不对中国大陆开放)。但有几个间接路径要关注:
▸Vertex AI:部分企业能合规接入
▸OpenRouter 类聚合层:能间接用到(但合规和稳定性需要自己评估)
▸国内云厂商的镜像或合作版本:暂未公布
如果你做的是面向中国用户的 AI 产品,3.5 Flash 的发布短期内对你影响不大,重心还是放在 Qwen / GLM / DeepSeek / Claude(通过合规渠道)/ 国内开放的 GPT 系列上。
但作为技术趋势的"风向标",3.5 Flash 反超 3.1 Pro 这件事会反向影响国内模型团队——它们会跟进类似的"小模型反超"策略,国产模型在未来 3-6 个月也会出现类似的能力跃升。
我的理解
Gemini 3.5 Flash 这次发布,我看完最深的感受不是"Google 又出了个新模型",而是 AI 行业的竞争维度在快速升级。
过去比的是:谁的旗舰更强。
去年加上:谁的小模型更便宜。
到这次明确变成了:谁能在"质量 + 速度 + 价格 + 分发"这个四角同时占优。
这个新维度对应一个很现实的现象:单纯的模型能力之争,正在变成"产品组合 + 生态"之争。
证据就是这次 Google 把三件事捆在一起发布:
- 模型(3.5 Flash)
- 开发平台(Antigravity)
- 消费级 Agent(Gemini Spark)
OpenAI 和 Anthropic 在过去半年也在做同样的事:
▸OpenAI:GPT-5.5 + Agents SDK + ChatGPT super app + Codex
▸Anthropic:Claude Opus 4.7 + Managed Agents + Claude Code + Claude Design
三家头部 AI 公司的产品矩阵,正在收敛到同一个范式。
这对开发者意味着两件事:
一是好事:选哪家都能搭出能用的 stack,技术能力会持续提升,整体成本会持续下降。
二是挑战:模型不再是产品的"独门优势"。光靠"我接了最新模型"已经不够卖点,真正的差异化要往上一层走——业务理解、行业 know-how、工作流设计、用户体验。
如果你做 AI 产品现在还停留在"我们用了 GPT-5.5"这种叙事——这个论点很快就会失效,因为下个月 Gemini 3.5 Pro 来了,再过几个月 Claude 5 也会来。
真正能立住的产品,核心竞争力必须是模型之上的东西:
▸你比别人更懂行业的业务流程
▸你比别人更会设计 multi-agent 工作流
▸你比别人更善于把 AI 嵌进真实场景
模型每个月都在变强、变快、变便宜。作为开发者,要把心思花在"什么不会变"的东西上。
最后说一句最实操的:今晚就去 Antigravity 注册个账号,跑一个你自己项目的真实场景测试。一小时下来你对接下来 3 个月的工具选型,会有非常清晰的判断。
次条我接着写一篇硬核技术——Agent 为什么跑着跑着就死循环了。无论你用 Gemini、Claude 还是 GPT,做 Agent 都绕不开"循环失控"这个坑。这是 Harness Engineering 系列里我之前漏发的一篇主线(第 11 篇),今天补回来。
一起翻下去。
参考链接
▸Google 官方发布博客:https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
▸Google I/O 2026 主题演讲:https://blog.google/innovation-and-ai/sundar-pichai-io-2026/
▸Antigravity 平台:https://antigravity.google/(agent-first dev platform)
▸Gemini API(Google AI Studio):https://ai.google.dev/
▸Gemini 3.5 Flash 在 Gemini Enterprise:https://cloud.google.com/products/gemini
▸Artificial Analysis 智能榜单(3.5 Flash 居 top-right quadrant):https://artificialanalysis.ai/

往期推荐
Multi-Agent Teams:让多个专家 Agent 像团队一样协作

AI Agent 是怎么"想一步做一步"的?拆解 ReAct 模式

从零开始:用 LangChain.js 构建你的第一个 Tool-Calling Agent

最后

点个在看支持我吧


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)