Claude / GPT / Gemini / DeepSeek 全系模型API价格对比
普通代码任务用 GPT-5.3-Codex 更划算;复杂代码分析、长代码理解,可以上 Claude Sonnet 4.6。
这不是单纯的模型强弱榜单,而是一份给开发者、产品和团队采购看的模型成本地图。
核心问题是:同一个任务,到底该用哪一类模型,官网价和渠道价差在哪里,哪些模型适合大规模调用。
大家是不是都有这有的感觉"每次选模型都要一个一个官网去查价格,价格如果超出我们的预期,还要去挨个找中转站,这真的是太麻烦了。
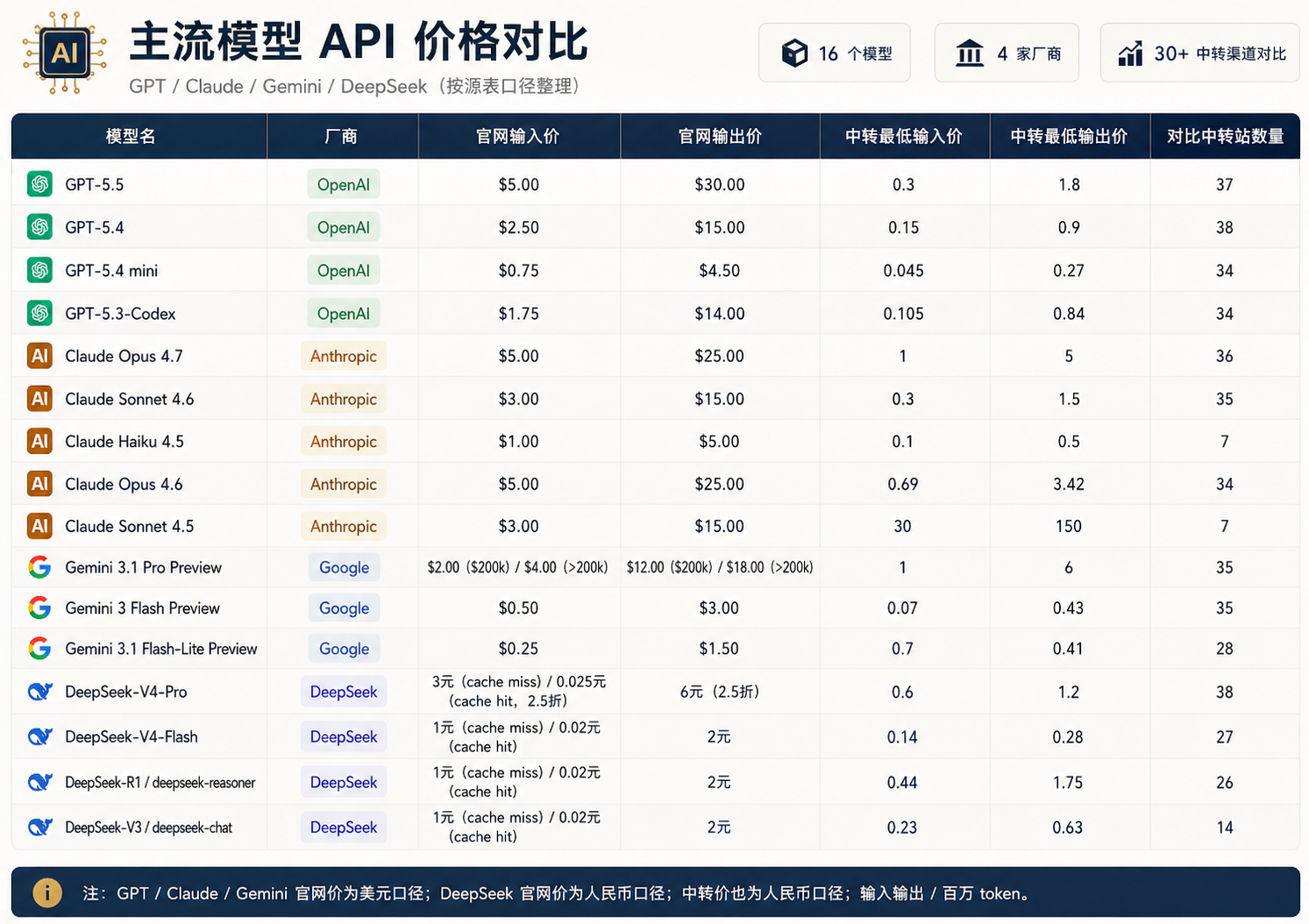
我整理了当前16个主流AI模型在30+渠道的最新价格,计价单位:(输入、输出/百万token)
按场景推荐
写代码场景:优先看Claude Sonnet 4.7 和 GPT-5.5-Codex
GPT-5.3-Codex适合日常开发,比如写函数、改脚本、解释报错、生成 SQL、补测试用例。它的定位更偏代码场景,而且从价格看,中转最低输入价只有 0.105 / 百万 token,输出价 0.84 / 百万 token,比很多旗舰模型更适合高频调用。
Claude Sonnet 4.6适合复杂的代码任务,比如读一整个项目、做架构分析、重构建议、排查多文件逻辑问题。它的官网价比 GPT-5.3-Codex 更高一点,中转最低价也更高,但 Claude 在长文本理解、代码上下文保持、复杂逻辑拆解上通常更稳。
一句话总结: 普通代码任务用 GPT-5.3-Codex 更划算;复杂代码分析、长代码理解,可以上 Claude Sonnet 4.6。
通用对话:优先看 GPT-5.5、Claude Sonnet 4.4、DeepSeek-V4
通用对话包括:日常问答、写文案、总结文章、改表达、做客服助手、做简单知识库问答。
想要综合能力比较强的就选GPT-5.4,它会更稳且它的官网输入价是 $2.50 / 百万 token,输出价是 $15.00 / 百万 token,中转最低输入价是 0.15,输出价是 0.9。从表里看,它对比了 38 个中转站,样本数也比较多,价格参考性更强。
如果你平时要处理很多长文档、长段落、复杂表达整理,比如合同分析、文章改写、会议纪要、需求拆解,选Claude Sonnet 4.6。它不一定是最便宜的,但输出通常更稳,更适合“需要认真读内容”的任务。
DeepSeek-V3 / deepseek-chat适合做中文问答、中文客服、内容总结、简单业务助手,并且非常关注成本。它官网价是 1元输入、2元输出 / 百万 token,中转最低价是 0.23 输入、0.63 输出 / 百万 token,对预算敏感的中文场景比较友好。
一句话总结: 综合稳妥选 GPT-5.4;长文本和复杂表达选 Claude Sonnet 4.6;中文高频低成本选 DeepSeek-V3。
预算优先:优先看 GPT-5.4 mini、Gemini 3 Flash、DeepSeek-V4-Flash
适合处理批量摘要、标签分类、关键词提取、简单客服、评论分析、数据清洗,这类任务更看重成本。
想用GPT,但是又不想成本太高就选GPT-5.4mini,它官网输入价是 $0.75,输出价是 $4.50,中转最低输入价只有 0.045 / 百万 token,输出价 0.27 / 百万 token。适合做大量轻任务,比如分类、摘要、改写、提取字段。
有多模态需求,或者希望在成本和速度之间做平衡,可以看 Gemini 3 Flash Preview。它官网输入价是 $0.50,输出价 $3.00,中转最低输入价 0.07,输出价 0.43。这类 Flash 模型通常更适合高频、低延迟任务。
如果是中文业务,且调用量比较大,选DeepSeek-V4-Flash。它官网价是 1元输入、2元输出 / 百万 token,中转最低价是 0.14 输入、0.28 输出 / 百万 token。它不是单纯追求最强能力,而是更适合“够用、便宜、能跑量”的场景。
一句话总结: OpenAI 低成本选 GPT-5.4 mini;多模态和速度选 Gemini 3 Flash;中文高频低成本选 DeepSeek-V4-Flash。
旗舰性能:优先看 GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro、DeepSeek-V4-Pro
旗舰模型适合真正复杂的任务,比如高难度推理、复杂代码迁移、长上下文分析、多轮 Agent、专业研究、重要决策辅助。
第一梯队当然是GPT-5.5啦,也是我的首选。它官网输入价是 $5.00,输出价是 $30.00,明显比 GPT-5.4、GPT-5.4 mini 贵,适合复杂分析、代码、Agent、多步骤任务,不适合拿来做普通批量调用。
Claude Opus 4.7比较适合复杂代码、长任务、高质量推理,它官网输入价 $5.00,输出价 $25.00,中转最低价是 1 / 5。价格不低,但更适合“少量高价值任务”,比如架构评审、复杂文档理解、代码重构方案。
Gemini 3.1 Pro Preview更适合涉及长上下文、多模态、Google 生态。它官网价分上下文长度,≤200k 时输入 $2.00、输出 $12.00;>200k 时输入 $4.00、输出 $18.00。这说明它更适合需要长上下文的任务,但上下文越长,成本也要重新算。
DeepSeek-V4-Pro是一个成本相对友好的选择,比较适合处理中文复杂推理、中文 Agent、长上下文任务,它官网价是 3元输入、6元输出 / 百万 token,中转最低价是 0.6 输入、1.2 输出 / 百万 token。相比 GPT / Claude 旗舰,它更适合中文场景下控制成本。
一句话总结: 综合旗舰看 GPT-5.5;复杂代码和长任务看 Claude Opus 4.7;长上下文和多模态看 Gemini 3.1 Pro;中文复杂任务看 DeepSeek-V4-Pro。
关键发现 —
关键发现一:Gemini 3 Flash 在预算场景里很有优势
只看官网输入价,Gemini 3 Flash Preview 是 $0.50 / 百万 token,GPT-5.4 是 $2.50 / 百万 token,前者只有后者的 20%。
如果看中转最低输入价,Gemini 3 Flash Preview 是 0.07 / 百万 token,GPT-5.4 是 0.15 / 百万 token,约为 GPT-5.4 的 47%。
所以 Gemini 3 Flash 不一定是所有场景的“最强模型”,但在预算优先、高频调用、低延迟任务里,性价比最高
关键发现二:Claude 系列价格波动很大,选渠道要小心
Claude 不是简单的“贵”或者“便宜”,关键要看具体模型和具体渠道。
比如 Claude Sonnet 4.6 的中转最低价是 0.3 / 1.5,对比中转站数量有 35 个,这个数据相对有参考价值。
但 Claude Sonnet 4.5 的中转最低价却到了 30 / 150,甚至部分价格都比官网要贵了,所以在选的时候一定要和官网做下对比!不过有些中转站会有实际充值10,到账50的情况,具体情况以中转站平台为主。
一句话说就是: Claude 选错渠道,成本差距会非常明显。
结尾
我会保持更新,下期会加入新模型和更多渠道,大家如果有想看的模型对比和中转站对比可以私我或者评论哦!
*数据来源:" 这些数据来自 oken.ai,一个AI模型全网比价平台,可以实时对比30+渠道的价格"

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)