Claude Code Skills 写作指南:如何写好一个可复用的 SKILL.md
摘要:本文介绍了如何编写高效的ClaudeCode SKILL.md文件,强调其核心在于可触发、可执行和可维护性。作者指出,好的Skill应包含清晰的YAML frontmatter(含name和description)、结构化内容(如MethodsCovered、RoutingTable)以及代码模板和常见陷阱说明。特别针对经管实证研究者,文章建议将复杂内容拆分为子文件,避免主文档过度膨胀,并提
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 林芷涵(首都经济贸易大学)
邮箱: zhihan_lin0211@163.com
- 分类:AI 专题
- Title: Claude Code Skills 写作指南:如何写好一个可复用的 SKILL.md
- Keywords: Claude Code, Skills, SKILL.md, AI Agent, empirical research, Stata, Python, R, reproducible workflow
- 提要:Claude Code Skills 的关键,不是把所有项目经验写进一篇长文档,而是写出一个能被 Claude 正确触发、快速索引、按需加载、稳定执行的
SKILL.md。本文聚焦SKILL.md的写法:如何设计description,如何组织 Methods Covered 和 Routing Table,如何写代码模板、常见陷阱、稳健性检验和检查清单。对经管实证研究者来说,一个好 Skill 的价值在于,让 AI 不只是会写代码,而是更接近按你的研究规范写代码。
编者按
很多研究者已经开始用 Claude Code 写 Stata、Python、R 或 Quarto 代码。但真正影响输出质量的,往往不是某一次提示词有多长,而是 SKILL.md 写得是否清楚。一个 Skill 如果 description 太空泛,Claude 就不容易正确触发;如果缺少索引、流程、代码模板和反例,即便被触发,也很难稳定生成符合研究规范的结果。
本文聚焦 SKILL.md 的写法:如何设计 frontmatter,如何组织 Methods Covered 和 Routing Table,如何写代码模板、常见陷阱、稳健性检验和检查清单。文末附有一份检查清单,可用于对照修改自己的 Skill。
1. 什么是好的 Skill?
好 Skill 的标准是:可触发、可执行、可维护。
很多人第一次写 Claude Code Skill 时,容易把它写成一份很长的项目说明。
背景、原则、文件结构、代码风格、研究方法、注意事项,全都写进去。这样看上去很完整,但未必好用。原因很简单:Claude Code 调用 Skill 时,并不是先完整阅读你的全部知识库,再决定怎么做。
Anthropic 在关于 Agent Skills 的说明中提到,一个 Skill 最简单的形态是包含 SKILL.md 的目录;SKILL.md 需要以 YAML frontmatter 开头,其中包含 name 和 description。Claude 会在启动时预先加载每个 Skill 的 name 和 description,并在判断相关时再读取完整的 SKILL.md。这是一种「渐进式披露」机制:先看入口信息,再按需读取正文和附加文件。(Anthropic) Anthropic 官方 Skills 仓库也把 Skills 定义为由 instructions、scripts 和 resources 组成的文件夹,而不只是单个 Markdown 文件。(GitHub)
因此,一个好 Skill 至少要满足三个条件。
- 可触发:Claude 能从
description判断出什么时候该调用它。 - 可执行:
SKILL.md里有明确流程、代码模板、输出要求和反例。 - 可维护:主文件不应无限膨胀,复杂内容要拆到
references/、scripts/、assets/等子文件。
对经管实证研究者来说,这一点尤其重要。我们写 Skill,不是为了展示「我懂多少规范」,而是为了让 AI 在写 Stata、Python、R、Quarto 或论文复现代码时,少犯那些重复出现的错误。
例如,下面这种写法看似简洁,实际很弱:
---
name: causal-inference
description: Causal inference methods.
---
Claude 很难判断它应该在什么场景下调用:是 DID、IV、RDD、合成控制、匹配,还是一般回归?
更好的写法应该明确任务、工具和触发场景:
---
name: causal-inference-mixtape
description: Use this skill when the user asks to implement DID, event study, IV / 2SLS, RDD, synthetic control, matching, staggered treatment timing, or causal-inference code templates in Stata, Python, or R for empirical economics and finance research.
---
这段 description 不一定完美,但至少让 Claude 知道:这个 Skill 面向因果推断,覆盖多种识别策略,也覆盖 Stata、Python 和 R。
简言之,Skill 的入口不是正文,而是 description。
2. SKILL.md 的基本结构
一个 Skill 通常存放在 .claude/skills/ 目录下。每个 Skill 是一个文件夹,核心文件是 SKILL.md。复杂 Skill 还可以包含子文件,用来存放更详细的代码模板、参考资料、脚本或图形资源。
典型结构如下:
.claude/
└── skills/
└── causal-inference-mixtape/
├── SKILL.md
├── references/
│ ├── method-patterns.md
│ ├── robustness-checks.md
│ └── reporting-standards.md
├── scripts/
│ ├── did_event_study.do
│ └── iv_2sls_template.py
└── assets/
└── event_study_plot_example.png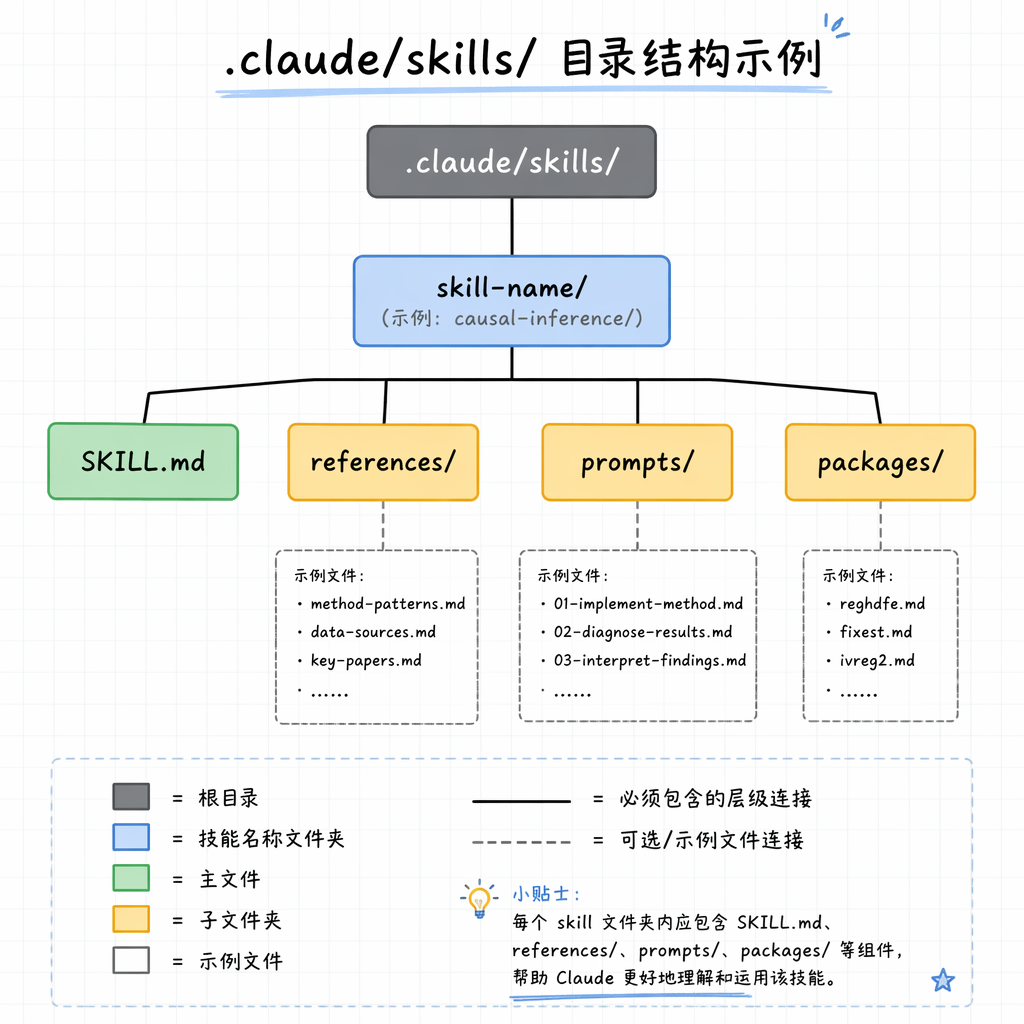
SKILL.md 可以理解为「入口文件」。它不需要写完所有细节,但必须告诉 Claude:
- 这个 Skill 什么时候使用;
- 覆盖哪些方法或任务;
- 执行任务时按什么流程;
- 关键代码模板在哪里;
- 常见错误是什么;
- 输出结果需要满足什么标准。
一个较稳妥的主文件结构可以写成:
---
name: causal-inference-mixtape
description: Use this skill when implementing DID, event study, IV / 2SLS, RDD, synthetic control, matching, or causal-inference code templates in Stata, Python, or R for empirical economics and finance research.
version: 1.0.0
---
# Causal Inference Mixtape
## When to Use
……
## Methods Covered
……
## Core Workflow
## Choose the Right Language
## Key Code Patterns
## Critical Gotchas
## Common Pitfalls
## Robustness Check Patterns
## Output Requirements
## Additional Resources
……需要说明的是,这不是唯一标准。小型 Skill 不必写满这些模块;大型 Skill 则需要通过子文件拆分细节。但不论规模大小,都应尽量避免把 SKILL.md 写成一篇没有索引、没有流程、没有反例的长文档。
3. frontmatter:让 Claude 知道什么时候调用 Skill
frontmatter 是 SKILL.md 的入口信息。Claude 主要根据这里的 name 和 description 判断某个 Skill 是否适合当前任务,因此这一部分不是形式项,而是 Skill 能否被正确触发的关键。
一个简单示例如下:
---
name: stata-regression-style
description: Use this skill when writing, reviewing, or debugging Stata .do files for empirical research, including reghdfe regressions, clustered standard errors, esttab tables, fixed effects, sample filters, logs, and replication-ready outputs.
version: 1.0.0
---
3.1 name:短、准、稳定
name 应该简短、清楚,并尽量使用小写字母、数字和连字符。例如:
stata-regression-style
python-data-cleaning
replication-package-check
quarto-paper-writing
causal-inference-mixtape不建议使用过宽泛的名字,例如:
research
data-analysis
my-rules
project这些名字看起来包容性强,但不利于识别,也不利于后续维护。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)