LangGraph 持久化(Persistence)[ 1 ]
本文深入讲解了LangGraph中的持久化能力,分为线程级和跨会话持久化两大类型。线程级持久化通过Thread和Checkpoint机制实现单次会话内的状态保存与恢复,支持断点续跑和流程回滚。文章详细介绍了检查点的生成时机、数据结构及使用方法,包括内存存储和PostgreSQL数据库存储的配置方式,并演示了状态快照获取、历史记录查询、流程重放和状态更新等核心操作。这些功能为AI系统提供了稳定的记忆

接下来我们一起来学习LangGraph中一项核心且至关重要的能力 —— 持久化能力。可以说,持久化能力是整个 LangGraph 知识板块里优先级最高的核心能力,没有之一。
这块内容涉及的概念偏多,讲解过程中我会多用生活化实例辅助理解,大家务必吃透相关定义。整体学习特点可以提前说明:持久化相关的代码编写难度很低,但底层概念逻辑比较抽象,所以接下来我们会花费较多时间拆解概念,区分线程级持久化、跨会话持久化等细分类型,弄懂原理之后再上手编码就会轻松很多。
1. 什么是持久化能力?
首先我们先来搞懂核心定义,究竟什么是持久化能力?通俗来讲,持久化本质就是数据存储。放到 LangGraph 搭建的 AI 系统场景中,持久化就是留存运行过程里的各类关键数据,以此保障 AI 程序稳定运行、具备记忆特性。

我们结合智能对话助手的实际案例直观感受。在单次对话窗口中,我们向 AI 自我介绍姓名、年龄等信息,后续再次提问相关内容,AI 能够准确应答,这就说明系统记录下了本次对话的聊天内容。
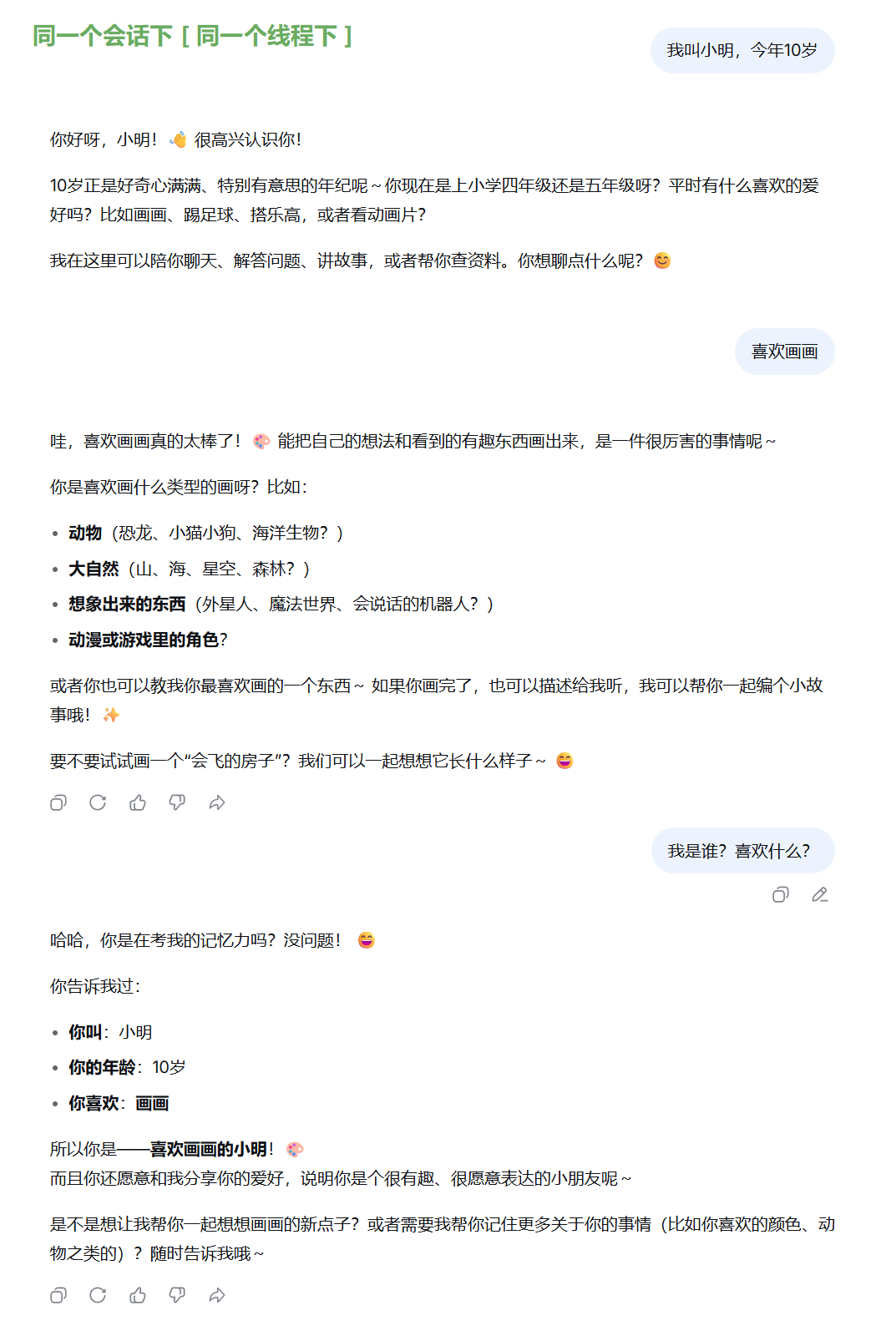
这里要理清一个细节:每向 AI 发起一次提问请求,都会触发一次 LangGraph 流程图执行,页面仅展示问答最终结果,流程内部产生的各类消息、工具调用日志不会对外呈现。
从实际使用场景能总结出第一类持久化作用:单一会话内记忆留存。在同一个对话窗口里,系统可以完整保存全程聊天记录,即便刷新页面、短暂关闭页面再重新打开,依旧能调取历史对话内容;但如果新建独立对话窗口,此前的聊天信息就无法被识别调取,会话之间相互隔离。
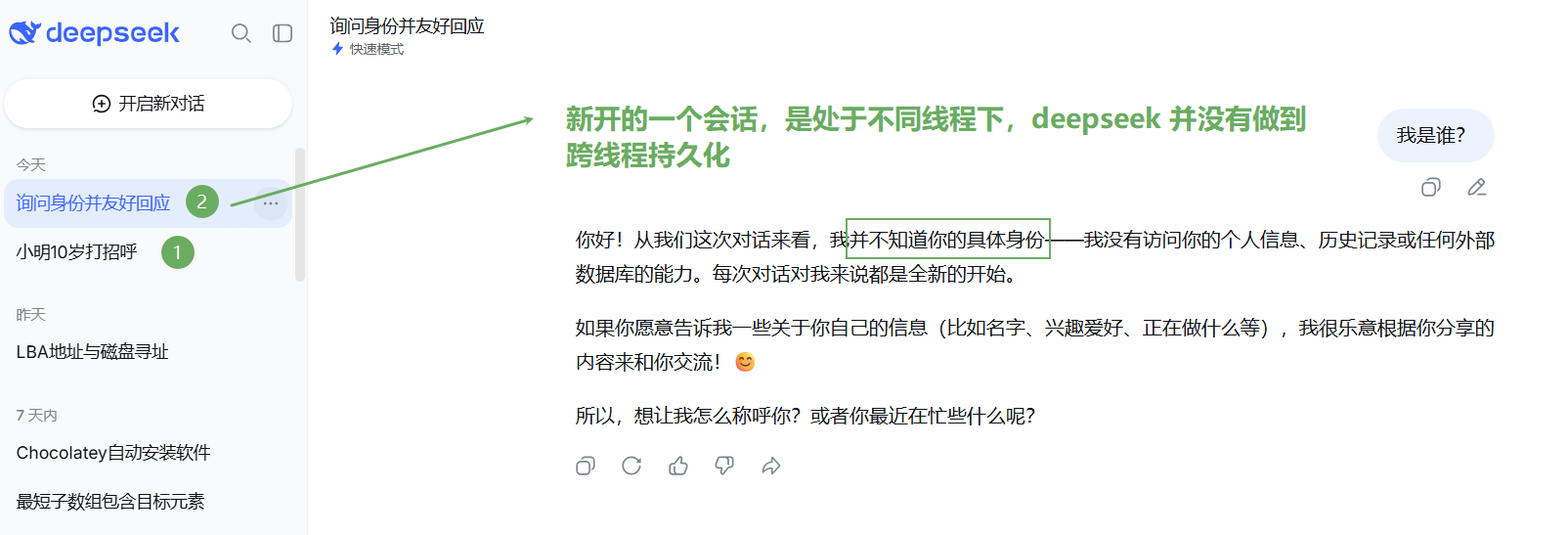
除此之外,持久化还能保障系统运行稳定性。假设 AI 正在生成回答的过程中,后端服务意外崩溃、程序中断重启,借助持久化机制,系统可以记录流程图当下的运行状态,标记已执行完毕的节点、待执行的流程步骤,重启后就能从中断位置继续运行,无需从头重新执行整个工作流。【这个是 Checkpoints 的相关概念知识】
这里记录的流程图运行状态,和我们之前学习的State状态并非等同概念,但运行状态会囊括State数据。流程节点执行中会不断更新状态信息,想要断点续跑,就必须同步留存状态数据与流程执行进度。
这类仅作用于单个对话窗口、保存会话聊天记录与流程运行状态的能力,官方命名为线程级持久化。大家注意区分,这里的线程和操作系统里的线程概念并不相同,仅用作会话隔离标识,一个线程对应独立对话窗口,不同线程代表互不干扰的会话场景。线程级持久化无需手动编写复杂存储逻辑,LangGraph 已经完成封装配置,简单设置参数即可自动完成数据保存。
了解完线程级持久化,我们再学习第二种类型:跨会话持久化。结合前面的案例就能发现,线程级机制会隔离不同对话,新建窗口无法读取过往会话信息,但实际业务中存在跨窗口调取用户数据的需求。【这个是 store 相关知识】
以医疗 AI 助手为例,用户的年龄、性别、既往病史、药物过敏史等关键个人信息,需要在任意新建对话中都能被系统识别调用。用户无需每次开启会话重复报备个人情况,AI 可自动调取留存信息,结合用户基础数据给出诊疗建议,这类不受会话窗口限制、全局共用数据的存储方式,就是跨会话持久化。
它的底层原理和常规后端数据库存储逻辑一致,将用户固定核心信息统一存入数据库。无论开启多少个会话、触发多少次流程图运行,系统都可以随时查询数据库中的留存数据,实现多会话之间信息共享。
整体总结下来,LangGraph 的持久化能力分为两大板块:一是线程级持久化,作用于单一会话,负责保存聊天历史、流程运行状态,实现会话记忆与故障断点恢复;二是跨会话持久化,依托数据库存储用户固定信息,打破会话隔离,实现多窗口数据共用。
下面我们会进一步探究线程级持久化的底层运行机制,现阶段大家先牢牢分清两类持久化的概念、作用场景与核心特点即可。
2. 线程级持久化
2.1 线程级持久化是怎么工作的?
当我们开始执行工作流,过程中可能会发生 崩溃或重启导致的中断 等异常情况。
根据 LangGraph 的持久化机制,线程级持久化表示能够【自动保存】工作流执行过程中的【状态快照】,维持单次会话的完整上下文。当工作流执行到某一步时,它会自动保存当前步骤的状态快照。这个状态包含了所有必要的上下文信息,比如:已经调用过哪些工具、用户的输入、聊天历史、下一步要执行的节点等等。
因此,工作流在执行过程中会发生如下图所示的流程:
- 正常执行:紫色 / 蓝色节点和实线箭头
- 异常恢复:红色 / 绿色节点和虚线箭头
- 检查点回滚:橙色节点和虚线箭头
【注意:这里其实有点小问题,就是在初始状态之后,也是需要有一个 状态0 的检查点快照的!】
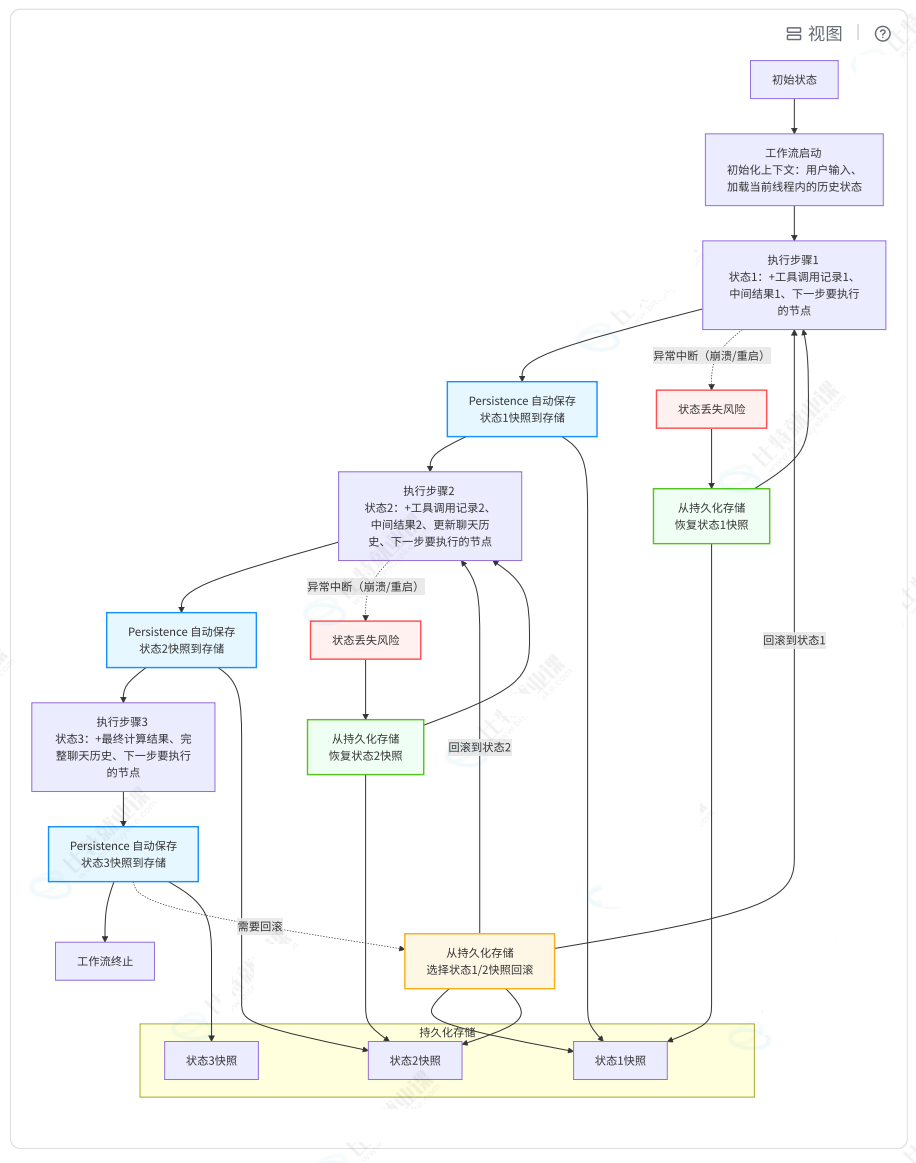
线程级持久化机制确保了:
-
状态不丢失:即使应用程序崩溃、重启,或者一个长时间的流程被中断,当它恢复时,可以从上次停止的地方继续执行,而不是从头开始。
-
支持长时间运行的任务:对于需要与用户进行多轮交互(如多步对话助手)或处理耗时极长的流程(如等待外部 API 回调),持久化是必不可少的。
-
检查点和回滚:我们可以将状态保存到某个时间点(检查点),并在需要时回滚到该状态。
2.2 核心概念
接下来我们继续深入 LangGraph 线程级持久化。这一部分我们重点拆解线程级持久化的两大核心概念,同时完整梳理它的底层工作流程与运行原理。大家之前已经知道线程级持久化可以在单一会话中保存流程图的运行状态、实现崩溃恢复,但具体它是怎么保存状态、什么时候保存、如何完成恢复的,我们下面全部讲透。
首先我们学习线程级持久化的两大核心概念:分别是 线程(Thread) 和 检查点(Checkpoint)。弄懂这两个概念,我们就能彻底读懂线程级持久化的完整工作逻辑。
LangGraph 的持久化机制 ——线程级持久化是其核心功能,它通过【线程】和【检查点】这两个核心部分来实现。具体如下:
2.2.1 Threads(线程)
第一,我们再来巩固什么是 线程(Thread)。大家对这个概念已经不陌生了,在 LangGraph 中,线程和操作系统的线程完全无关,大家千万不要混淆。LangGraph 里的线程,指代的是一次独立的工作流执行会话。
简单理解:我们在 DeepSeek 中开启一个对话窗口,在这个窗口里无论问多少个问题、进行多少次问答交互,所有操作都属于同一个线程、同一个会话。一个线程对应一次完整的用户对话,或者一次独立的任务执行过程。
所以:在 LangGraph 中,Thread 代表一个独立的工作流执行会话。可以把它想象成【与某个用户的一次完整对话历史】或【处理某个特定任务的一次完整执行过程】。例如在 DS 中的一次完整对话:
这里有个关键细节:一个线程内,可以执行多次工作流。我们每输入一次问题、得到一次回答,就代表执行了一次完整的 LangGraph 工作流。比如我们在同一个对话里问了三个问题,就相当于在同一个线程中,触发了三次工作流执行。这是区分线程和工作流的核心关键点。
Thread 的关键特性如下:
- 隔离性:每个
Thread都是完全独立的,它们的状态互不干扰 - 持久化单元:
Thread是状态持久化的基本单位 - 标识符:通过唯一的
thread_id来识别【代码成面的体现】
2.2.2 Checkpoints(检查点)
第二,我们重点讲解核心概念 检查点(Checkpoint)。通俗来说,检查点就是我们之前提到的流程图运行状态快照。当程序崩溃、服务中断重启后,系统就是依靠检查点保存的快照数据,恢复中断前的运行状态。
想要实现断点恢复,快照中必须保存两类核心数据:
-
一是当前流程图的完整状态 State;
-
二是程序中断后需要继续执行的下一个节点。
这组记录了特定时刻流程状态的数据,在 LangGraph 中的专业名称,就叫做检查点(Checkpoint)。
可能有人会有疑问:一个线程中只有一个检查点吗?答案是否定的。检查点是在线程运行的各个特定时刻持续生成的,一个线程下会存在大量的历史检查点快照。系统崩溃重启后,会默认读取最新的检查点,从中断位置继续执行流程。
那我们核心要搞懂:检查点到底在哪些时机生成?
首先我们做第一层思考:最直观的时机,就是每一次完整工作流执行结束后生成检查点。每次问答结束、工作流跑完闭环,系统就保存一次最新状态快照。这样哪怕系统崩溃,再次提问时,AI 也能基于本次会话的历史上下文正常应答。
但只靠这个时机,是存在缺陷的。假设我们的工作流包含多个节点,流程执行到中间节点、还未走完整个工作流时,服务突然崩溃。按照“工作流结束才保存快照”的规则,当前中断的进度不会被保存,重启后系统只能从头执行整个工作流,无法实现断点续跑。
所以 LangGraph 采用了更完善的策略:工作流中,每一个节点执行完成后,都会立即生成一个全新的检查点快照。
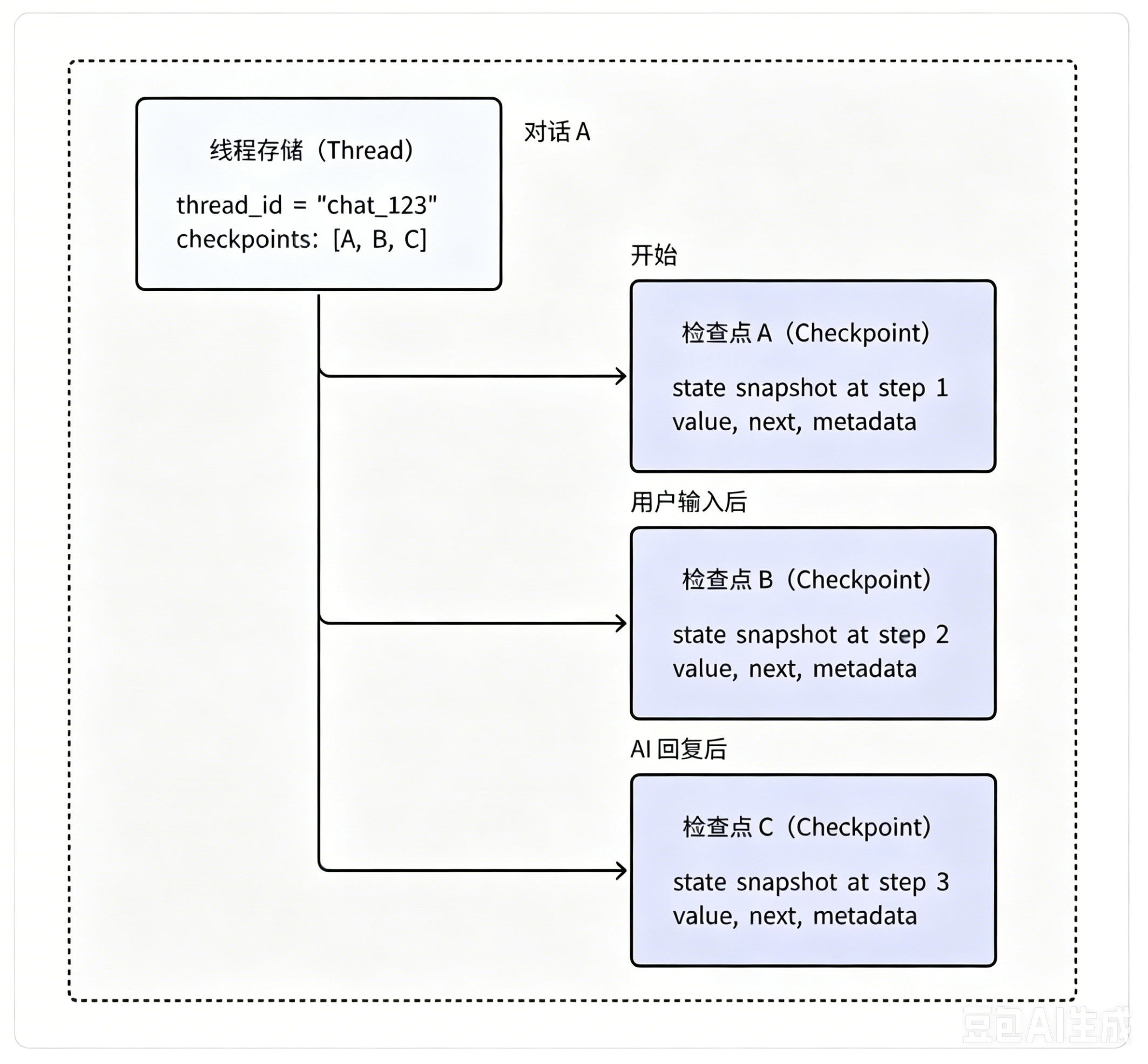
所以:Checkpoint 是 Thread 在特定时刻的【状态快照】。它记录了工作流执行到某个节点时的完整状态。例如在刚才的会话中,每一次用户输入和对话结束后,都可以保存一个最新的【状态快照】:

Checkpoint 的关键特性:
状态快照(StateSnapshot):保存了工作流在某个时间点的完整状态。包含【状态值】、【下一步要执行的节点】、【与此检查点关联的配置】和【与此检查点关联的元数据】等信息。
版本历史与可恢复点:一个 Thread 可以有多个 Checkpoints,形成执行历史,使得同一个会话的历史状态可以从任意 Checkpoint 追溯和访问。
Threads 与 Checkpoints 关系如下:
这个策略可以完美解决中途崩溃的问题。比如工作流包含节点1、节点2、节点3:
-
执行前生成一个快照,记录"待执行节点1"
-
节点1执行完成后生成快照,记录"节点1已完成,待执行节点2"
-
节点2执行完成后生成快照,记录"节点2已完成,待执行节点3"
如果程序在节点2快照生成之后、节点3执行之前崩溃,重启后系统会读取最新的快照(节点2完成时的快照),识别出下一个待执行节点是节点3,直接从断点处继续执行,无需从头重试节点1和节点2。
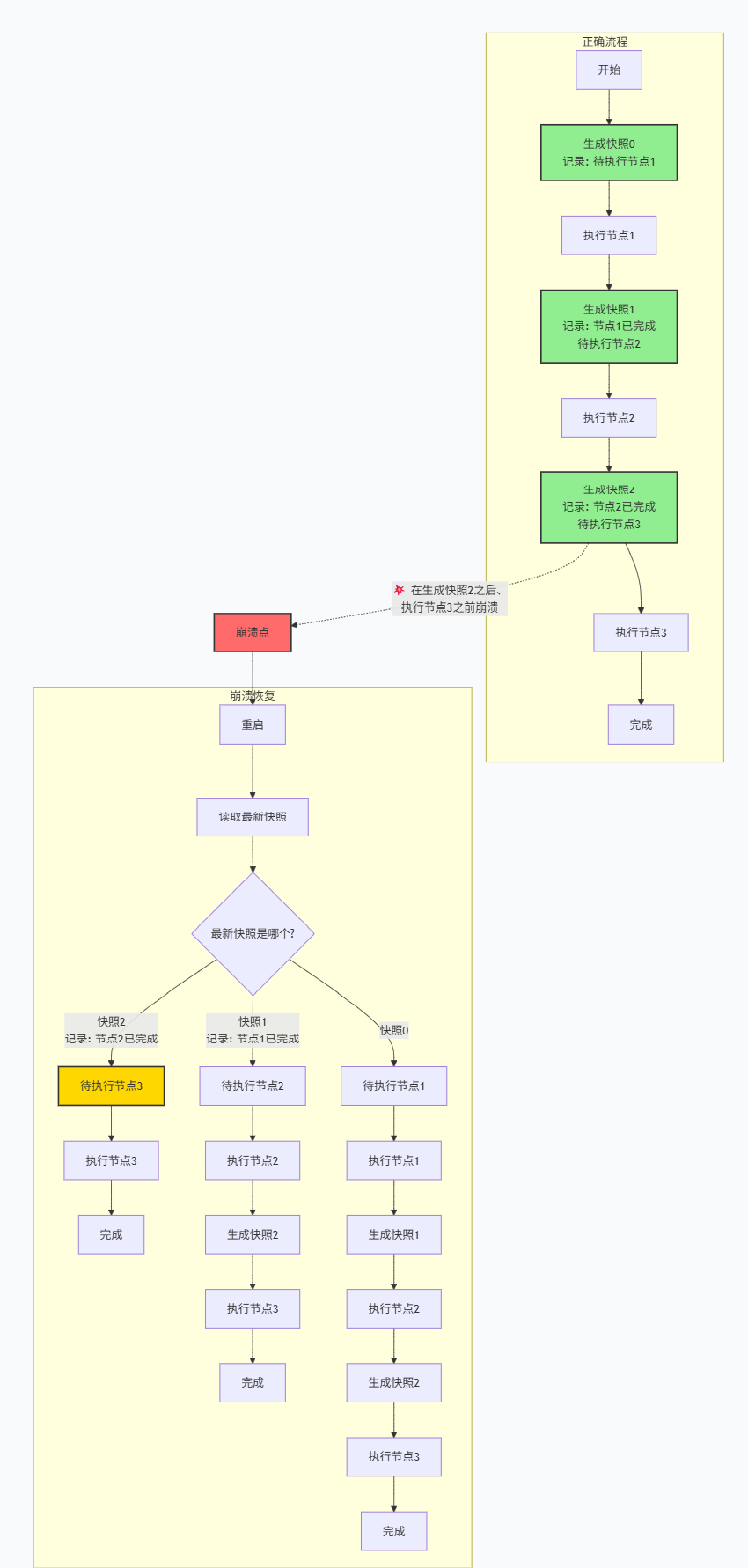
基于这个机制,我们就能理清 线程与检查点的对应关系:一个线程会维护一个检查点历史列表,该会话下所有工作流、所有节点执行产生的快照,都会持续追加到这个列表中,不会新建列表隔离。
举个例子:同一个线程中,第一个问题的工作流执行三个节点,会生成3个检查点;第二个问题的工作流同样执行三个节点,会继续追加3个新检查点。所有快照按执行顺序统一存储,完整记录整个会话的全部运行轨迹。【快照 0,1,2】
这套机制不仅能实现崩溃恢复,还衍生出了高级能力:流程回滚与重放。因为系统完整保存了所有历史版本的检查点,我们可以随时指定任意一个历史快照,让工作流从该节点位置重新执行,原理和 Git 的版本回滚、版本管理完全一致。
接下来我们拆解 检查点(状态快照)的完整结构,每一个快照都包含核心五大字段,支撑所有持久化、恢复、回滚能力:
StateSnapshot 结构如下:
StateSnapshot(
# 当前状态值(如对话消息列表)
values={'messages': [用户消息, AI回复, 用户消息...]},
# 接下来要执行的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写入信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# 父检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id': 'def...'}},
# 创建时间
created_at=''
)
具体示例:
StateSnapshot(
values={
'messages': [
HumanMessage(
content='你好',
additional_kwargs={},
response_metadata={}
),
AIMessage(
content='你好!有什么我可以帮助你的吗?',
additional_kwargs={'refusal': None},
response_metadata={
'token_usage': {
'completion_tokens': 11,
'prompt_tokens': 130,
'total_tokens': 141,
'completion_tokens_details': {
'reasoning_tokens': None,
'rejected_prediction_tokens': None
},
'prompt_tokens_details': {
'audio_tokens': None,
'cached_tokens': None
},
'model': 'gpt-4o-mini-2024-07-18',
'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_99421c6c6b',
'chatml': None,
'finish_reason': 'stop',
'logprobs': None,
'id': 'run-...',
'usage': {
'input_tokens': 130,
'output_tokens': 11,
'total_tokens': 141
},
'input_token_details': {},
'output_token_details': {}
}
},
'id': '...',
'index': 0,
'checkpoint_id': '1',
'checkpoint_config': {
'configurable': {
'thread_id': '1',
'checkpoint_id': '...'
}
},
'metadata': {
'source': 'loop',
'step': 1,
'writes': {},
'created_at': '2025-12-02T08:57:37.559330+00:00',
'parent_config': {
'configurable': {
'thread_id': '1',
'checkpoint_id': '...'
}
}
}
)
]
},
next=('llm_checkpoint',),
config={
'configurable': {
'thread_id': '1',
'checkpoint_id': '...'
}
},
created_at='2025-12-02T08:57:37.559330+00:00',
parent_config={
'configurable': {
'thread_id': '1',
'checkpoint_id': '...'
}
},
metadata={
'source': 'input',
'step': 0,
'writes': {},
'created_at': '2025-12-02T08:57:37.550240+00:00',
'parent_config': None,
'task': PregelTask(
id='...',
name='task...',
path=...,
args=[
HumanMessage(content='你好', ...),
...
],
id='...',
interrupts=()
)
},
interrupts=()
)-
第一,values:对应我们自定义的图状态 State,保存当前节点执行完成后的完整最新状态。我们的对话历史、用户信息、流程数据全部存在这里,也是系统恢复上下文的核心依据。
-
第二,next:记录当前节点执行完毕后,下一个待执行的节点名称。恢复流程时,系统依靠这个字段确定下一步执行逻辑。
-
第三,config 配置信息:记录当前快照所属的线程 ID、快照唯一 ID,实现线程与检查点的精准绑定,保证不同会话的数据互相隔离。
-
第四,metadata 元数据:记录流程执行的步骤序号、执行来源、操作日志等细节信息,用于精准溯源。
-
第五,父检查点配置与创建时间:记录上一级快照信息和当前快照生成时间,串联成完整的执行链路,形成闭环的版本链。
这里补充一个关键细节:结束节点(end)执行完成后,不会生成新的检查点。因为结束节点执行完毕后,整个工作流终止,不存在 next 下一个执行节点,无需生成快照,多余的快照没有任何意义。而流程图初始化、开始节点执行后,都会生成初始快照,保证流程启动状态可被记录。
最后我们串起 线程级持久化的完整工作流程,结合官方流程图整体复盘:
首先,工作流启动,初始化会话上下文、清空初始状态,生成初始检查点快照;开始节点执行完成后,再次生成快照,标记首个待执行节点。
随后流程图逐个执行业务节点,每执行完一个节点,自动生成、持久化一个检查点,所有快照统一存入底层数据库,全程自动保存,无需我们手动编码实现,这也是“概念难、代码简单”的核心原因,LangGraph 已完全封装持久化逻辑,我们只需简单配置即可开启。
如果流程执行中出现服务崩溃、程序中断(流程图红色异常流程),内存状态丢失,但数据库中已持久化所有历史快照。重启后系统自动读取当前线程的最新检查点,通过 values 恢复状态、通过 next 定位下一节点,实现断点续跑,保障系统稳定性。
除此之外,线程级持久化还支持检查点回滚能力(流程图橙色回滚流程)。我们可以主动读取任意历史快照,让工作流从指定的历史节点重新执行,实现流程重放、版本回溯,支撑更多高阶业务场景。
大家可以直观看到数据库底层存储效果:
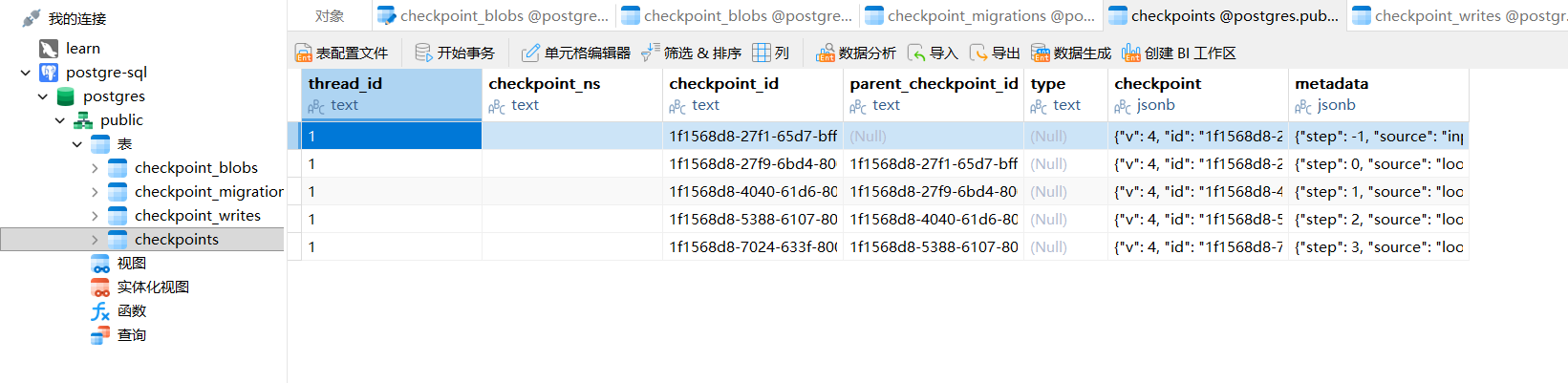
数据库中存在专门的 Checkpoint 数据表,每一条数据对应一个检查点快照,通过 Thread_ID 区分不同会话。同一个线程 ID 下,会对应多条不同时间、不同节点的检查点数据,完美印证了我们讲的所有原理。
到这里,线程级持久化的所有核心概念、生成时机、底层结构、完整工作原理就全部讲解完毕。后续我们不再讲解理论,直接上手编码,通过实操配置开启线程级持久化,验证状态自动存储、崩溃恢复、流程回滚的完整效果。
2.3 线程级持久化使用姿势
结合前面的原理我们清楚,LangGraph 会在每一个节点执行完毕后,自动保存状态快照,这套保存逻辑由框架内部完成,无需开发者手动编写保存代码。而我们开发人员只需完成核心配置,为流程图指定对应的持久化存储位置即可。只要绑定好存储介质,状态快照自动留存、流程自动记录,至于异常恢复、流程回滚这类拓展操作,下面拓展使用会逐一讲解,这里我们先掌握快照自动保存的基础配置。
2.3.1 步骤一:配置 checkpointer 持久化存储
在定义图时,我们需要指定 checkpointer。LangGraph 支持多种 checkpointer 的定义方式:
LangGraph 主要提供两类持久化存储方案。
-
第一种是内存级存储,数据仅存于程序运行内存中,一旦程序崩溃、重启或者设备断电,内存数据就会全部清空,保存的检查点也随之丢失。
-
第二种是第三方数据库存储,数据持久化落地到数据库当中,即便程序关停、设备故障,历史数据也不会丢失,能够稳定留存会话记录。
2.3.1.1 方式 1:内存存储
我们先基于内存存储开展实操演示,沿用之前具备搜索调用能力的案例代码。
回顾案例二逻辑:项目中先定义搜索工具,并将工具绑定到大语言模型;自定义图状态,包含对话消息与接口调用次数两类数据;拆分业务节点,模型调用节点识别到工具调用指令就执行搜索节点,无指令则直接返回应答结果,同时搭配框架自带的条件分支方法,按照规则流转节点,最终组装节点与边结构完成流程图构建。
我们先在无持久化配置的情况下测试效果。连续发起两轮对话,第一轮询问西安当日天气,模型正常返回气象信息;第二轮追问过往聊天内容,程序无法调取历史会话,不能回忆上一轮对话信息。
agent = agent_builder.compile()
# 运行测试
if __name__ == "__main__":
print("🔍 开始查询天气...\n")
# 调用 Agent
result = agent.invoke({
"messages": [
HumanMessage(content="今天西安的天气如何?")
]
})
print(result["messages"][-1].content)
print("="*30)
result = agent.invoke({
"messages": [
HumanMessage(content="我们刚刚聊了什么?")
]
})
print(result["messages"][-1].content)🔍 开始查询天气...
根据中国气象局官网(weather.cma.cn)的数据,以下是西安今天(2025年7月15日)的天气情况:
## 🌤️ 西安今日天气(2025年7月15日)
| 时间 | 气温 | 天气状况 | 风向风力 |
|------|:----:|:--------:|:--------:|
| **08:00** | **22.3℃** | 多云 | 东北风 3.3m/s |
| **11:00** | **25℃** | 多云 | 东北风 3.2m/s |
| **14:00** | **25.2℃** | 多云 | 东北风 3.3m/s |
| **17:00** | **27.5℃** | 多云,有少量降水(0.3mm) | 东北风 2.7m/s |
| **20:00** | **23.7℃** | 有小雨(1.6mm) | 东南风 3.1m/s |
### 📊 天气概况:
- **今日气温范围**:约 **18.7℃ ~ 27.5℃**
- **天气状况**:白天以多云为主,下午到傍晚可能有零星小雨
- **风向风力**:东北风为主,风力2-3级
- **湿度**:较高,约75%~95%
### 💡 温馨提示:
- 今天西安天气较为舒适,最高温约27.5℃,不算太热
- 下午到傍晚时段可能有小雨,建议**随身携带雨具**🌂
- 空气湿度较大,体感可能有些闷热
希望这些信息对你有帮助!😊
==============================
我们刚刚还没有开始对话呢!😊 这是我们第一次交流,所以还没有聊过什么内容。
有什么我可以帮你的吗?无论是搜索信息、解答问题,还是其他任何需要,我都很乐意帮忙!
进程已结束,退出代码为 0出现该现象主要有两点原因。
-
第一,代码没有配置任何持久化存储,流程运行产生的状态没有地方留存,无法记录聊天记录;
-
第二,两次独立调用没有归属同一个线程,没有设定统一的线程标识,系统判定为两次互不相关的会话,自然无法串联上下文内容。
针对性解决这两个问题,就能实现会话记忆功能。首先配置内存存储,导入框架内置的InMemorySaver内存存储类,实例化得到存储对象。在编译流程图时,新增checkpointer参数,把内存存储对象传入其中,仅一行配置代码,就完成流程图与内存存储的绑定。
这种状态保存在程序内存中。适用于开发和测试,程序重启后状态会丢失。用法如下所示:
使用操作很简单这里在在编译图时,直接添加编译参数 checkpointer
from langgraph.checkpoint.memory import InMemorySaver
# 定义存储方式
checkpointer = InMemorySaver()
# 用 checkpointer 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
其次统一会话线程,依靠线程 ID区分独立会话。定义配置字典,在配置内指定固定的thread_id,在调用执行工作流时,将配置参数一同传入。两轮对话使用同一个线程 ID,就代表两次交互归属于同一会话线程。
# 运行测试
if __name__ == "__main__":
print("🔍 开始查询天气...\n")
config = {"configurable": {"thread_id": "1"}}
# 调用 Agent
result = agent.invoke(
{"messages": [ HumanMessage(content="今天西安的天气如何?")]},
config=config
)
print(result["messages"][-1].content)
print("="*30)
result = agent.invoke(
{"messages": [HumanMessage(content="我们刚刚聊了什么?")]},
config=config
)
print(result["messages"][-1].content)完成两项配置后重新运行程序,再次先后询问天气、追问聊天记录,模型成功调取历史对话上下文,完整回忆此前交流内容。
🔍 开始查询天气...
根据搜索结果,我为你整理了今天(2025年7月)西安的天气情况:
---
### 🌤️ 西安今日天气概况
根据西安气象发布的信息(截至7月3日):
- **天气状况**:多云,偏南偏东地区有分散性阵雨或雷阵雨
- **气温范围**:**25℃~29℃**(傍晚至夜间)
- **白天气温**:城区气温约 **27.4℃~32.5℃**
- **湿度**:较高,体感较为闷热
### ⚠️ 温馨提示
1. **高温高湿**:近期西安受副热带高压影响,天气高温高湿,体感会比较闷热。
2. **注意强对流**:今天傍晚至夜间可能有分散性阵雨或雷阵雨,局地可能伴有短时暴雨和雷暴大风,出门建议带伞。
3. **未来几天**:7月4日-8日最高气温可达 **36~39℃**,会非常炎热,注意防暑降温。
建议你出门带好雨具,同时注意防暑防晒哦!☂️🧴
==============================
我们刚刚聊的是关于**今天西安的天气情况**。我帮你查询并介绍了西安今天的天气状况,包括:
- 天气为多云,有分散性阵雨或雷阵雨
- 气温范围在25℃~32.5℃左右
- 湿度较高,体感闷热
- 以及未来几天高温可达36~39℃的预警和出行建议
请问还有什么我可以帮你的吗?😊2.3.1.2 方式 2:使用 Postgres 存储库
不过内存存储存在明显短板,单次程序运行期间会话可以正常记忆,一旦程序终止运行,内存数据直接销毁。重新启动程序再次查询历史对话,依旧无法读取过往记录,想要实现断电、重启后数据不丢失,就需要使用第三方数据库存储。
LangGraph 提供了几个检查点存储实现,所有这些都通过独立的、可安装的库实现。适用于生产环境或需要状态持久化的场景。
-
SQLite 存储(
langgraph-checkpoint-sqlite):使用 SQLite 数据库(SqliteSaver/AsyncSqliteSaver)的 LangGraph 检查点的实现。非常适合实验和本地工作流程。需要单独安装。 -
Postgres 存储(
langgraph-checkpoint-postgres):使用 Postgres 数据库中(PostgresSaver/AsyncPostgresSaver)的 LangGraph 检查点的实现。非常适合在生产中使用。需要单独安装。
本次实操选用PostgreSQL数据库存放检查点数据。它属于主流开源关系型数据库,整体性能、功能完整性优于常用数据库,支持 JSON、地理位置、全文检索等特殊数据类型,还可搭载向量检索插件,适配多样化业务场景。同时 LangGraph 对 PostgreSQL 原生兼容性极佳,集成难度低,也是框架官方部署环境的首选数据库。
本地开发可以选用轻量的 SQLite 存储,生产环境则优先使用 PostgreSQL 保障稳定性。我们借助 Docker 快速搭建数据库环境,拉取官方镜像,通过端口映射、账号密码配置启动数据库容器,启动完成后使用可视化工具测试数据库连通性,确保服务正常运行。
使用 Docker 快速安装并启动 postgres:
# 1. 拉取 PostgreSQL 镜像
docker pull postgres:latest
# 2. 运行 PostgreSQL 容器
# -p 5432:5432:将容器的5432端口映射到宿主机的5432端口
# -e POSTGRES_PASSWORD=bit:设置 PostgreSQL 的 postgres 用户密码
# --name postgres-sql:给容器命名
# -d:后台运行
docker run --name postgres-sql -e POSTGRES_PASSWORD=bit -p 5432:5432 -d postgres
可以使用 Navicat 测试链接:注意默认连接 postgres 初始数据库,如果有其他数据库也可以对应配置连接。
安装 langgraph-checkpoint-postgres 包
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
环境就绪后,安装 PostgreSQL 对应的检查点依赖包。按照标准格式编写数据库连接字符串,填入账号、密码、服务器地址、端口与数据库名称。调用PostgresSaver类,通过连接字符串建立程序与数据库的连接,首次使用数据库存储时,必须调用setup方法初始化数据表结构。
-
设置 PostgreSQL 连接字符串(URI)PostgreSQL URI 通常遵循以下格式:
postgresql://<user>:<password>@<host>:<port>/<database_name> -
使用 Postgres 存储库作为检查点使用
PostgresSaver.from_conn_string()方法从连接字符串创建一个新的PostgresSaver实例。注意:第一次使用 Postgres 检查点时需要调用checkpointer.setup()
初始化完成后,编译流程图时替换存储对象,将数据库存储绑定到图中,后续流程调用方式和内存存储完全一致,执行工作流时依旧通过配置指定线程 ID。
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# ...后续调用...
2.3.2 步骤二:使用 Thread 进行执行
首次运行程序,需要调用【Checkpointer.setup()】,数据库会自动生成多张底层数据表,根据节点执行流程依次创建对应的检查点。一轮完整问答流程,会在初始化、起始节点、模型调用、工具执行、结果汇总等环节生成多个状态快照,所有快照都会关联同一个线程 ID,统一归档存储。
当我们编译好图并准备运行时,我们需要通过一个 Thread ID 来标识这次执行。
- 如果
Thread ID不存在:LangGraph 会创建一个新的Thread,并从初始状态开始执行。 - 如果
Thread ID已存在:LangGraph 会从Checkpointer中加载该Thread的最后一次保存的状态,并从这个状态继续执行。
这里依旧使用 postgres 存储,进行第一次执行:创建一个新的 Thread(thread_id="1")
from langchain.messages import HumanMessage
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# 第一次执行:创建一个新的 Thread (thread_id="1")
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天气如何?")]},
config
)
print(f"调用 LLM 总次数: {result1['llm_calls']}次")
for m in result1["messages"]:
m.pretty_print()
运行后,可以看到 postgres 库中,已经存储了检查点信息:
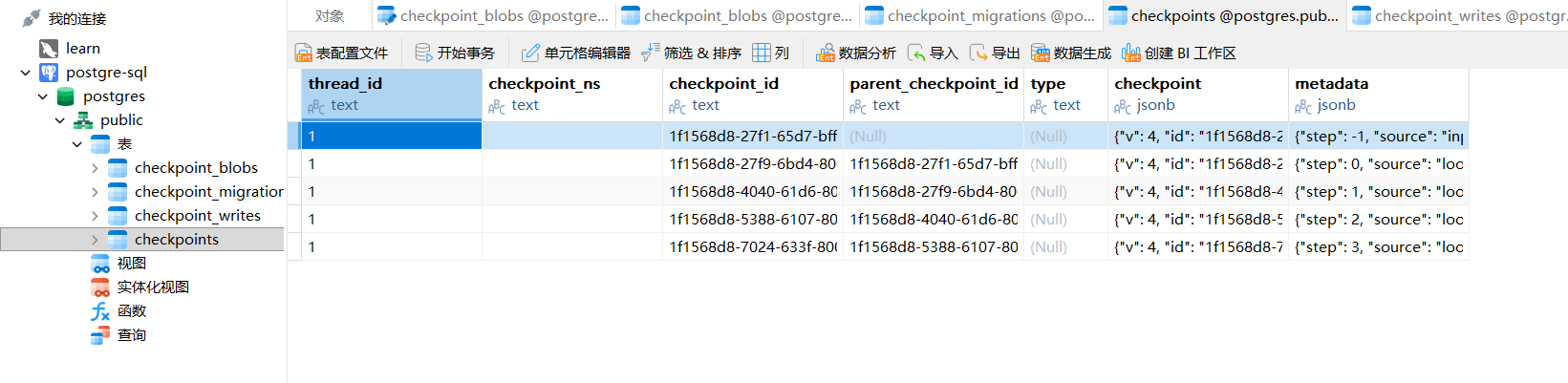
终止程序后注释初始化方法,保留存储与线程配置,再次发起对话查询历史内容,程序会自动从数据库读取对应线程的历史检查点,加载过往状态数据,顺利接续上下文完成应答。
更换全新的线程 ID 发起对话,等同于新建空白会话,数据库会独立新增一组检查点数据,不同线程的会话数据相互隔离,不会出现内容混淆。
一段时间后,再次使用相同的 thread_id 调用:
from langchain.messages import HumanMessage
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
# checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# ------------------ 一段时间后,程序可能重启了(使用postgres存储) ------------------
# 再次使用相同的 thread_id 调用
# LangGraph 会从上次的状态继续,而不是重新开始
config = {"configurable": {"thread_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="我们刚才聊到哪了?")]},
config
)
print(f"调用 LLM 总次数: {result2['llm_calls']}次")
for m in result2["messages"]:
m.pretty_print()
第二次调用结果如下:
调用 LLM 总次数: 3次
================================ Human Message =================================
今天西安的天气如何?
================================== Ai Message ==================================
好的,我来查一下今天西安的天气情况。
Tool Calls:
tavily_search (call_00_ckIOpF1jaXYFSo7TjWtZ6125)
Call ID: call_00_ckIOpF1jaXYFSo7TjWtZ6125
Args:
query: 西安今天天气 2025年
================================= Tool Message =================================
# 省略...
================================== Ai Message ==================================
根据搜索结果,我来为你介绍一下今天(2025年5月7日)西安的天气情况:
## ☀️ 西安今日天气(2025年5月7日)
| 项目 | 详情 |
|------|------|
| **天气状况** | ☀️ 晴转多云 |
| **气温范围** | **9℃ ~ 17℃** |
| **当前气温** | 早晨6时约 **9℃** |
| **风力** | 微风 |
| **相对湿度** | 约 92%(早晨较潮湿) |
### 📋 详细预报:
- **白天**:多云,最高气温约 **16.8℃**,微风
- **夜间**:多云,最低气温约 **9℃**
### 💡 温馨提示:
- 早晚温差较大(约8℃),建议**洋葱式穿搭**,早晚出门带件外套
- 早晨湿度较高,可能有轻雾,开车出行注意安全
- 西安已于4月29日正式入夏,白天体感较为舒适
总体来看,今天西安天气不错,适合外出活动!😊
================================ Human Message =================================
我们刚才聊到哪了?
================================== Ai Message ==================================
我们刚才聊的是**今天(2025年5月7日)西安的天气情况**。
我为你查询了西安今天的天气,主要内容包括:
- **天气状况**:晴转多云
- **气温范围**:9℃ ~ 17℃
- **风力**:微风
- **温馨提示**:早晚温差较大,建议洋葱式穿搭
请问还有什么需要我帮忙的吗?比如你想了解未来几天的天气,或者有其他问题?😊
进程已结束,退出代码为 0查看流程返回的状态数据能够发现,result2 的上下文会包含之前的对话历史。LangGraph 会从上次的状态继续,而不是重新开始。也就是说新的用户提问会追加到历史消息列表末尾,框架整合全部上下文信息后给出应答。每一次节点流转、每一轮会话交互,都会按照规则生成检查点归档入库,完整记录整个会话的运行轨迹。
至此线程级持久化的基础使用方法就讲解完毕,我们分别实操了内存存储与 PostgreSQL 数据库存储两种模式,验证了线程绑定、状态留存、上下文记忆的核心效果。下面我们将基于已保存的检查点,讲解状态读取、流程回滚、历史回放等进阶用法。
2.3.3 其他基本用法
下面我们针对线程级持久化中,检查点对应的各类基础用法,了解拿到检查点后能够实现哪些操作。
2.3.3.1 获取状态快照
首先先来获取状态快照,查看线程运行后留存的状态数据。
当使用 checkpointer 编译图时,执行时就会在每个步骤处保存状态快照。在 LangGraph 中状态快照就是 StateSnapshot 对象,其具有以下关键属性:
StateSnapshot(
# 当前状态值(如对话消息列表)
values={'messages': [用户消息, AI回复, 用户消息...]},
# 接下来要执行的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写入信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# 父检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id': 'def...'}},
# 创建时间
created_at=''
)
依托之前已经完成两次运行的工作流,数据库里也已经生成对应的检查点记录。我们可以编写代码,获取编号为1线程下最新的状态快照。调用agent.get_state()方法,同时传入对应的线程配置参数,就能精准取出当前线程最后的快照信息。
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
# 调用前的状态快照
snapshot = agent.get_state(config)
print(snapshot)
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 调用后的状态快照
snapshot = agent.get_state(config)
print(snapshot)
打印结果:
StateSnapshot(
values={},
next=(),
config={'configurable': {'thread_id': '1'}},
metadata=None,
created_at=None,
parent_config=None,
tasks=(),
interrupts=()
)
StateSnapshot(
values={'messages': [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}), AIMessage(content='你好!有什么我可以帮助你的吗?', additional_kwargs={}, response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 130, 'total_tokens': 141, 'completion_tokens_details': {'reasoning_tokens': None, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f92cd2c60b', 'id': 'chatcmpl-...', 'finish_reason': 'stop', 'logprobs': None}, id='...', usage_metadata={'input_tokens': 130, 'output_tokens': 11, 'total_tokens': 141, 'input_token_details': {}, 'cache_read': 0, 'output_token_details': {}})], 'llm_calls': 1},
next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f0cf5a3-b6ff-6b2e-8001-5dc083ad82'}},
metadata={'source': 'loop', 'step': 1, 'writes': {}, ...},
created_at='2025-12-02T08:38:09.968610+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f0cf5a3a7a5-6cf8-8000-ec666fd226fe'}},
tasks=(),
interrupts=()
)
打印快照内容可以看到,内部包含多项核心数据。
-
values对应我们自定义的状态结构,存放对话消息、大模型调用次数等业务数据; -
next标识后续待执行的节点; -
config存储配置信息,并且每条快照都会自动生成专属的检查点 ID; -
除此之外还有元数据、创建时间、父级配置等附属信息。
当next字段为空时,就代表当前流程已经执行完毕,这份快照也就是最新状态。结合消息列表里的对话内容,也能直观佐证快照记录了完整的交互上下文。
2.3.3.2 获取状态历史记录
拿到单份最新快照后,我们还可以调取当前线程下全部的历史快照记录。使用agent.get_state_history()方法,就能检索出该线程所有执行节点对应的快照集合。这将返回与配置中提供的线程 ID 关联的 StateSnapshot 对象列表。
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 查看状态历史记录
history = list(agent.get_state_history(config))
print(history)
返回结果将按时间顺序排序,列表中的第一个检查点(StateSnapshot)是最新的。结果如下:
[
StateSnapshot(
values={'messages': [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}), AIMessage(content='你好!有什么我可以帮助你的吗?', additional_kwargs={}, response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 130, 'total_tokens': 141, ...}, ...}], 'llm_calls': 1},
next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_id': '1f0cf5a3-b6ff-6b2e-8001-5dc083ad82'}},
metadata={'source': 'loop', 'step': 1, 'writes': {}, ...},
created_at='2025-12-02T08:57:39.533882+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_id': '1f0cf5a3a7a5-6cf8-8000-ec666fd226fe'}},
tasks=(),
interrupts=()
),
StateSnapshot(
values={'messages': [HumanMessage(content='你好', additional_kwargs={}, response_metadata={})], 'llm_calls': 0},
next=('llm_call',),
config={'configurable': {'thread_id': '1', 'checkpoint_id': '1f0cf5cf-38d4-6c00-bfff-6ce6b2a2dd01'}},
metadata={'source': 'loop', 'step': 0, 'writes': {}, ...},
created_at='2025-12-02T08:57:37.855302+00:00',
parent_config=None,
tasks=(...),
interrupts=()
),
StateSnapshot(
values={'messages': []},
next=('__start__',),
config={'configurable': {'thread_id': '1', 'checkpoint_id': '1f0cf5cf-38d4-6c00-bfff-6ce6b2a2dd01'}},
metadata={'source': 'input', 'step': -1, ...},
parent_config=None,
tasks=(...),
interrupts=()
)
]
我们可以自定义格式打印关键信息,提取每条快照的检查点 ID 与下一执行节点。历史快照列表遵循时间排序规则,列表首位是最新生成的数据,末尾则是流程初始状态。顺着快照顺序,能够完整梳理出从启动节点、模型调用、工具执行到结果汇总的全流程执行轨迹。
掌握历史快照查询能力后,就能拓展出多种实际应用场景。第一种是故障恢复场景,倘若流程运行中途突发断电、系统崩溃,未完成的节点不会生成新快照,数据库仅留存已执行完成的记录。系统重启后,读取最后一条有效快照,便可接续断点继续执行任务,保障业务不会中断。
第二种是流程回溯场景,依托完整历史快照,可以定位任意一个时间节点的运行状态。既能查看当时留存的聊天记录,也能获知后续将要执行的节点,基于指定快照,就能从该节点位置向后重新运行流程,这项功能就是重放。
2.3.3.3 重放
LangGraph 原生支持重放操作,实操时先筛选并保存目标位置的快照配置。调用agent.invoke()执行流程,首个入参空置,将选中的快照配置作为参数传入。配置里包含线程编号与检查点 ID,框架会根据标识从数据库读取对应状态数据,从指定节点开始向后执行剩余逻辑。
重放运行结束后,再次查询历史快照列表,会发现列表末尾追加出新的记录。框架不会覆盖原有历史数据,所有重放产生的流程痕迹都会新增归档,完整保留全部执行记录,方便后续追溯核查。借助重放功能,不仅可以实现故障断点续跑,也能反复调试中间节点的运行效果。
具体来说:如果我们用一个 thread_id 和一个 checkpoint_id(表示检查点标识符,用于指代线程内的特定检查点)来调用一个图,那么我们将重新执行对应于 checkpoint_id 之后的步骤。如下例所示:
- 先执行一次完整的流程,获取一次完整历史记录;
- 保存中间过程某一次快照,并重新执行快照后的步骤;
- 获取第二次调用后的完整历史记录,验证是否重放成功;
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
# 第一次执行
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天气如何?")]},
config
)
# 保存调用工具前的状态
print("-" * 80)
print("第一次执行历史:")
to_replay = None
for state in agent.get_state_history(config):
print("消息数:", len(state.values['messages']), end=" ")
print("下一节节点:", state.next, end=" ")
print("checkpoint_id:", state.config['configurable']['checkpoint_id'])
if len(state.values['messages']) == 2: # 保存调用工具前的状态
to_replay = state
print("-" * 80)
print(f"从 {to_replay.next} 节点开始重新执行, 重放配置: {to_replay.config}")
# 第二次执行: 重放
result2 = agent.invoke(None, config=to_replay.config)
print("-" * 80)
print("第二次执行历史: 重放后")
# 查看新的历史记录
for state in agent.get_state_history(config):
print("消息数:", len(state.values['messages']), end=" ")
print("下一节节点:", state.next, end=" ")
print("checkpoint_id:", state.config['configurable']['checkpoint_id'])
result2['messages'][-1].pretty_print()
执行结果也证明了重放成功。可以看到历史记录中帮我们记录所有的执行过程,包括重放前和重放后的步骤:
第一次执行历史:
checkpoint_id: 1f0cf6bc-cb09-61e3-8003-1a74660e9324 消息数: 4 下一节节点: ()
checkpoint_id: 1f0cf6bc-b148-624e-8002-f696045e5a58 消息数: 3 下一节节点: ('tool_node',)
checkpoint_id: 1f0cf6bc-8a86-625-8001-38aa0c3d8d80 消息数: 2 下一节节点: ('llm_call',)
checkpoint_id: 1f0cf6bc-7abe-6d9a-8000-ef816c492e36 消息数: 1 下一节节点: ('__start__',)
checkpoint_id: 1f0cf6bc-7abc-6ce5-bfff-5241076b5574 消息数: 0 下一节节点: ()
从 ('tool_node',) 节点开始重新执行, 重放配置: {'configurable': {'thread_id': '1', 'checkpoint_id': '1f0cf6bc-62a2-8001-5a001-38aa0c3d8d80'}}
第二次执行历史: 重放后
checkpoint_id: 1f0cf6bd-0370-6c6f-8002-9c656bd5577a 消息数: 4 下一节节点: ()
checkpoint_id: 1f0cf6bc-b148-624e-8003-1a74660e9324 消息数: 4 下一节节点: ()
checkpoint_id: 1f0cf6bc-8a86-625-8001-38aa0c3d8d80 消息数: 2 下一节节点: ('tool_node',)
checkpoint_id: 1f0cf6bc-7abe-6d9a-8000-ef816c492e36 消息数: 1 下一节节点: ('__start__',)
checkpoint_id: 1f0cf6bc-7abc-6ce5-bfff-5241076b5574 消息数: 0 下一节节点: ()
=============================== Ai Message ===============================
今天西安的天气情况如下:
- **天气**: 晴
- **温度**: 最高温度约为 13℃, 最低温度约为 2℃
- **风速**: 东北风 约 6 英里/小时
...
重放功能实际应用为时间旅行,详见下文【时间旅行(Time Travel)】篇章。
2.3.3.4 更新状态
在重放的基础上,还可以进一步实现状态更新操作。我们可以读取指定快照里保存的状态数据,手动修改其中的内容,再基于修改后的状态重新执行流程。
举例来说,原有快照中存储的用户提问为指定内容,我们可以调用update_state()方法,依据快照配置锁定目标状态,替换消息文本,修改完成后会生成全新的配置标识。将新配置传入执行方法,流程就会按照改动后的问题内容重新运算,最终输出对应的应答结果。修改状态后同样会生成新的快照,不会篡改原始历史记录。
具体来说:我们还可以编辑图的状态。我们使用 update_state() 方法来做到这一点。
- 我们可以更新用户的输入、或使用其他搜索内容;
- 先执行一次完整的流程,获取一次完整历史记录;
- 保存第一次调用 LLM 前的步骤快照,修改用户输入来更新快照,并重新执行更新后快照步骤;
from langchain.messages import HumanMessage
from langgraph.types import Overwrite
config = {"configurable": {"thread_id": "1"}}
# 第一次执行
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天气如何?")]},
config
)
# 找到调用 LLM 前的步骤
print("第一次执行历史:")
selected_state = None
for state in agent.get_state_history(config):
print("checkpoint_id:", state.config['configurable']['checkpoint_id'], end=" ")
print("消息数:", len(state.values['messages']), end=" ")
print("下一节节点:", state.next)
if len(state.values['messages']) == 1: # 此时消息数为1, 下一节点是'llm_call'
selected_state = state
print("-" * 80)
print("更新前配置:", selected_state.config)
# 根据指定的 config, 更新对于步骤的值
new_config = agent.update_state(
config=selected_state.config,
values={"messages": Overwrite([HumanMessage(content="今天北京的天气如何?")])} # 清空消息, 重新写入
)
print("-" * 80)
print("更新后配置:", new_config)
# 第二次执行: 重放更新后的配置
result2 = agent.invoke(None, config=new_config)
for message in result2['messages']:
message.pretty_print()
执行结果如下:
第一次执行历史:
checkpoint_id: 1f0cf6bc-7444-6c8d-8003-cd8a180c4560 消息数: 4 下一节节点: ()
checkpoint_id: 1f0cf6bc-7444-6c8d-8003-cd8a180c4560 消息数: 4 下一节节点: ()
checkpoint_id: 1f0cf6bc-1b1c-62a0-800-42b9d34b01bd 消息数: 2 下一节节点: ('tool_node',)
checkpoint_id: 1f0cf6bc-1b1c-62a0-800-42b9d34b01bd 消息数: 1 下一节节点: ('__start__',)
更新前配置: {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': 'abc'}}
更新后配置: {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f0cf6bc-8a86-62a0-8001-5a001-34cb4b001'}}
=============================== Human Message ===============================
今天北京的天气如何?
=============================== Ai Message ===============================
...
=============================== Tool Calls ===============================
tavily_search (call_FlFuwThpNBTioVJnMmWtMr)
Args:
query: 北京天气
=============================== Tool Message ===============================
...
=============================== Ai Message ===============================
今天北京的天气情况如下:
- **天气**: 晴
- **温度**: 最高温度约为 23℃, 最低温度约为 16℃
- **风速**: 南风 2-5 km/h
...重放与状态更新属于 LangGraph 持久化的底层基础能力,这些底层功能可以进一步封装,衍生出 AI 系统的上层应用能力。类比数据库原理,数据库提供增删改查基础指令,开发者依托指令开发出业务系统的相关功能;而重放、状态修改这类底层能力,能够搭建出记忆存储、人机交互、时间旅行等实用功能。
其中重放能力可以封装为时间旅行功能,支持流程回退、节点复盘;状态更新则可以实现人工介入流程,手动干预对话内容与业务数据。LangGraph 已经将这类上层应用接口封装完毕,后续我们可以直接调用封装方法开发业务功能,无需反复编写底层状态操作逻辑。
至此,线程级持久化涵盖的获取状态快照、查询历史记录、流程重放、状态更新这几项基础操作,就全部讲解完毕。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)