长会话不爆窗:Hermes Agent 是如何压缩上下文的?
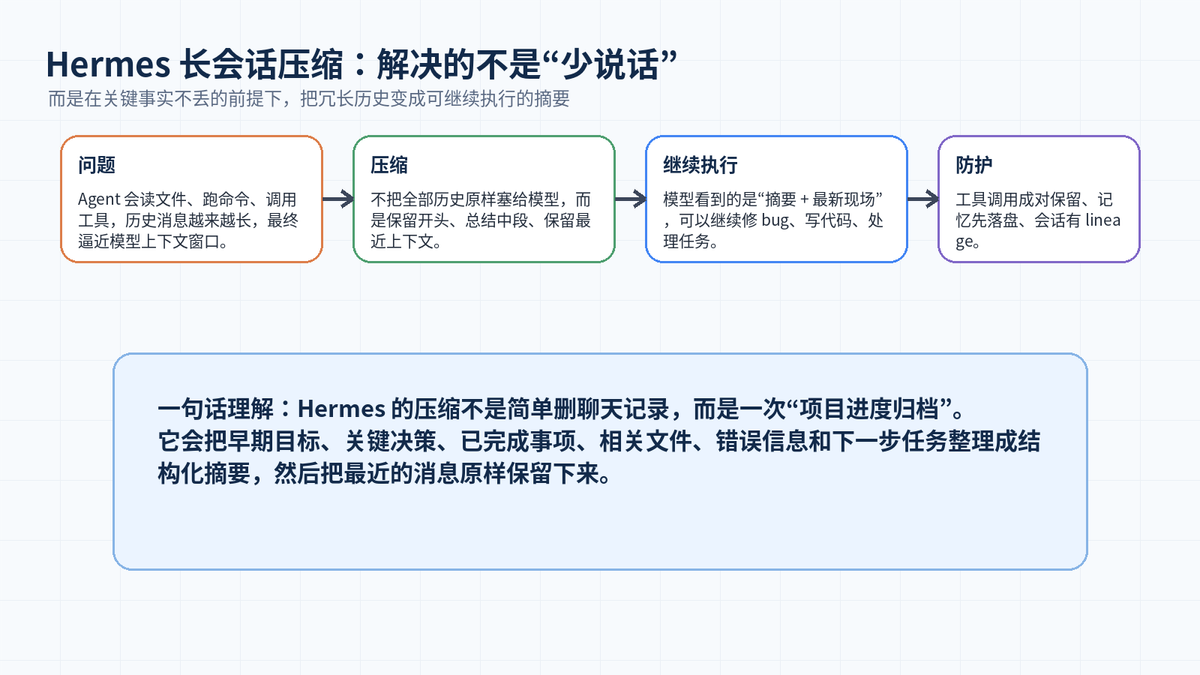
如果你只是和一个 Chatbot 闲聊,上下文变长最多是“记不住前面说过什么”。但 Hermes Agent 不一样,它会读文件、跑命令、调用工具、改代码、搜索网页,还可能从 Telegram、Discord、Slack 等入口持续接收任务。这样的 Agent 一旦长期运行,消息历史会不断膨胀,最后逼近模型上下文窗口。
因此,Hermes 的上下文压缩不是简单把聊天记录缩短,而是把一段长任务的历史执行过程整理成“可继续工作的任务状态”。它要保留目标、约束、进度、关键文件、错误信息和下一步,还要确保工具调用协议不被破坏。
一、先看结论:Hermes 压缩到底在解决什么问题?
长会话超过上下文后,Agent 面临三个问题:第一,模型放不下完整历史;第二,即使勉强放下,输入成本也会变高;第三,粗暴删除历史会导致模型忘记项目目标、当前进度和关键约束。Hermes 的做法是:不保留所有细节,但保留能够继续执行任务的“状态”。
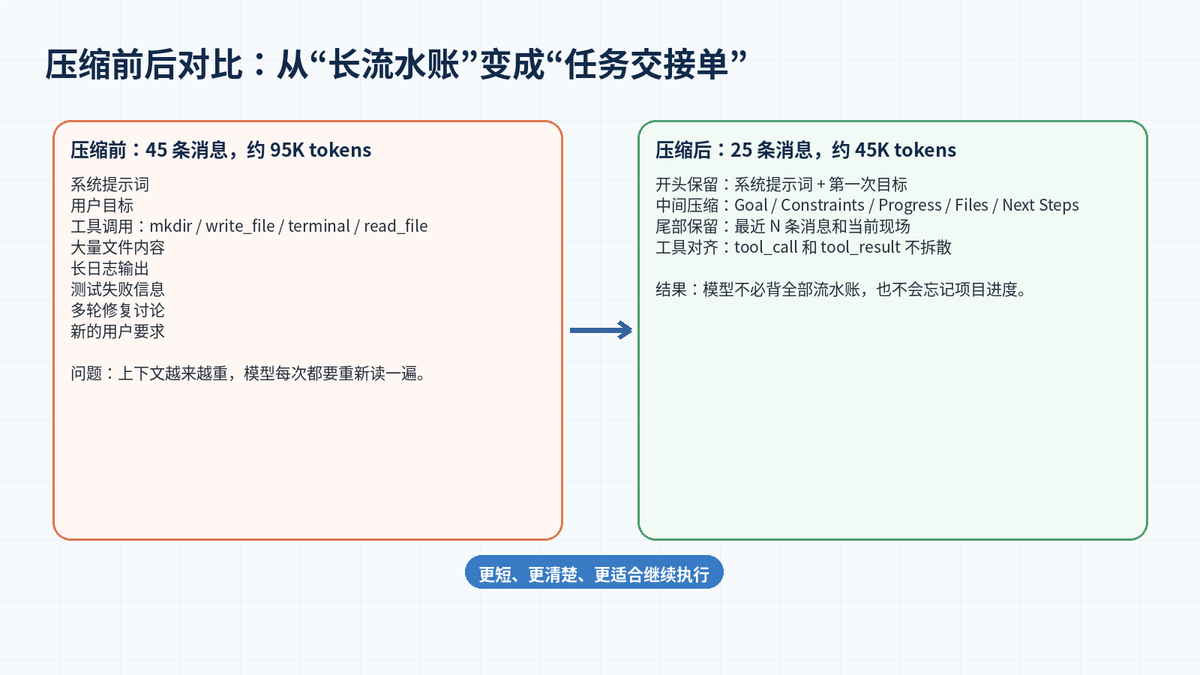
1.1 压缩不是“删聊天记录”,而是“生成任务交接单”
普通摘要往往只回答“前面聊了什么”。Hermes 的压缩摘要更像项目交接单:用户目标是什么,已经做了哪些操作,哪些文件被创建或修改,测试结果如何,当前还有哪些 blocker,下一步应该继续做什么。
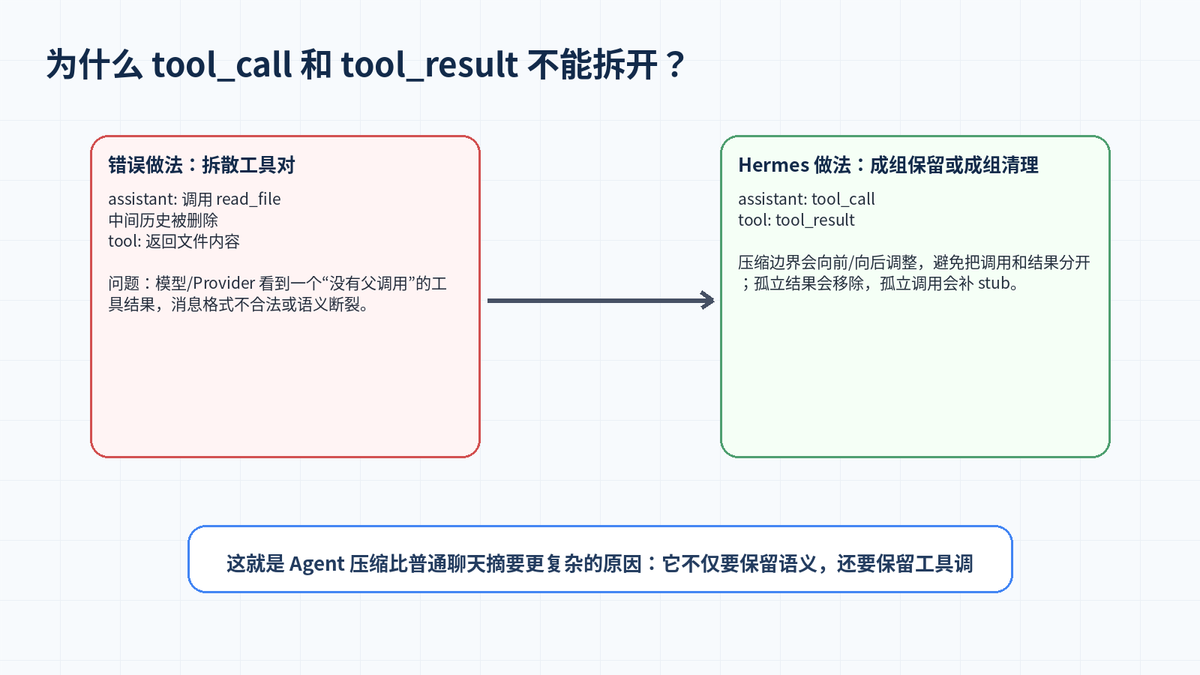
这就是为什么长任务 Agent 的压缩比普通对话摘要复杂得多。因为它不仅要总结文字,还要保留执行状态、代码路径、命令结果和工具调用关系。
1.2 为什么不能把所有历史都塞给模型?
因为上下文窗口不是无限的。一次复杂任务可能包含几十轮工具调用、上万行日志、多个文件内容和反复调试记录。把这些内容全部保留,会让每次模型调用都越来越重,速度、成本和稳定性都会受到影响。
更重要的是,超长上下文不等于高质量理解。很多旧日志、旧文件片段、重复终端输出,已经不再是当前任务的关键。与其让模型每次重新读大量旧材料,不如把中段历史转成结构化任务摘要。
二、双层压缩:Gateway 85% 兜底,Agent 50% 主力
Hermes 官方文档把压缩设计成两层:Gateway Session Hygiene 和 Agent ContextCompressor。前者更像安全网,防止跨平台长会话在进入 Agent 前就过大;后者是主压缩器,在 Agent Loop 里根据更准确的 token 信息判断是否压缩。
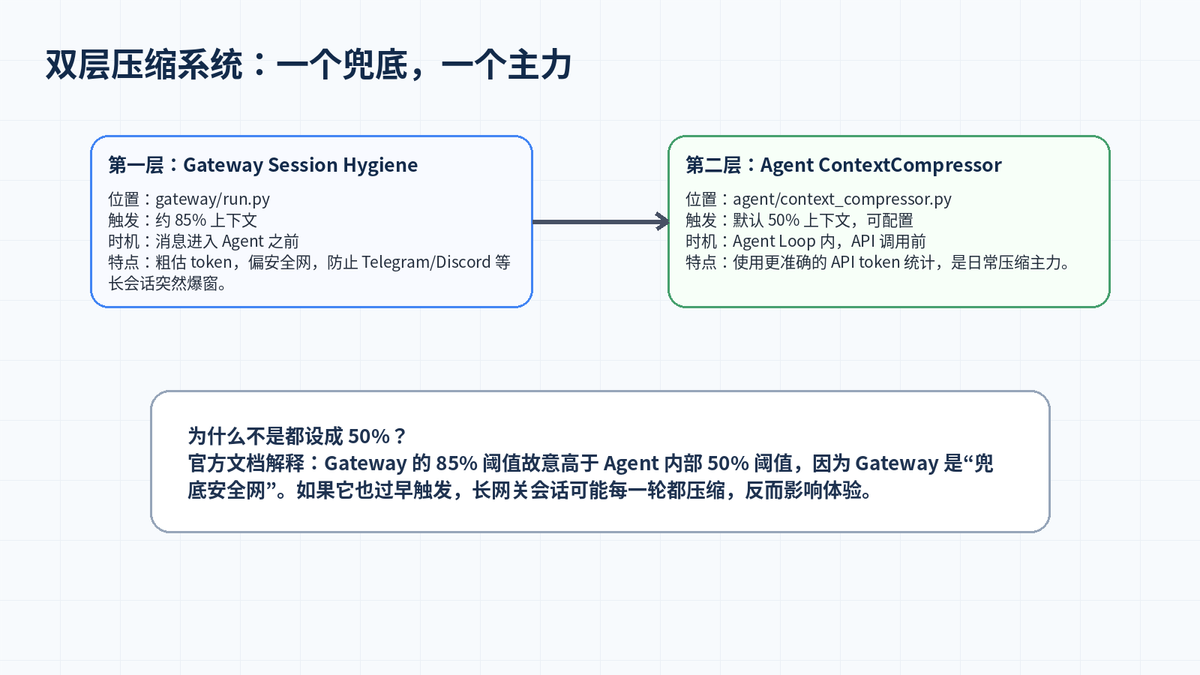
2.1 Gateway Session Hygiene:入口侧的安全网
Gateway 层通常服务于 Telegram、Discord、Slack、WhatsApp 等长连接入口。用户可能隔几个小时再发一条消息,历史却已经积累很多。Gateway Session Hygiene 会在消息进入 Agent 前做一次高阈值检查,官方文档给出的固定阈值是大约 85% 上下文窗口。
它的作用不是频繁压缩,而是防止“上一次还正常,这一次突然爆上下文”。因此它的阈值比 Agent 内部压缩更高。
2.2 Agent ContextCompressor:真正的日常压缩主力
Agent ContextCompressor 位于 agent/context_compressor.py,是默认的上下文压缩引擎。它在 Agent Loop 内部运行,能够拿到更准确的 API token 统计。默认情况下,当 prompt tokens 达到模型上下文窗口的 50% 左右时,就会触发预检压缩。
这意味着 Hermes 不会等到模型彻底报错才处理,而是在 API 调用前先做 preflight check。这样既能减少调用失败,也能让后续工具调用继续顺畅运行。
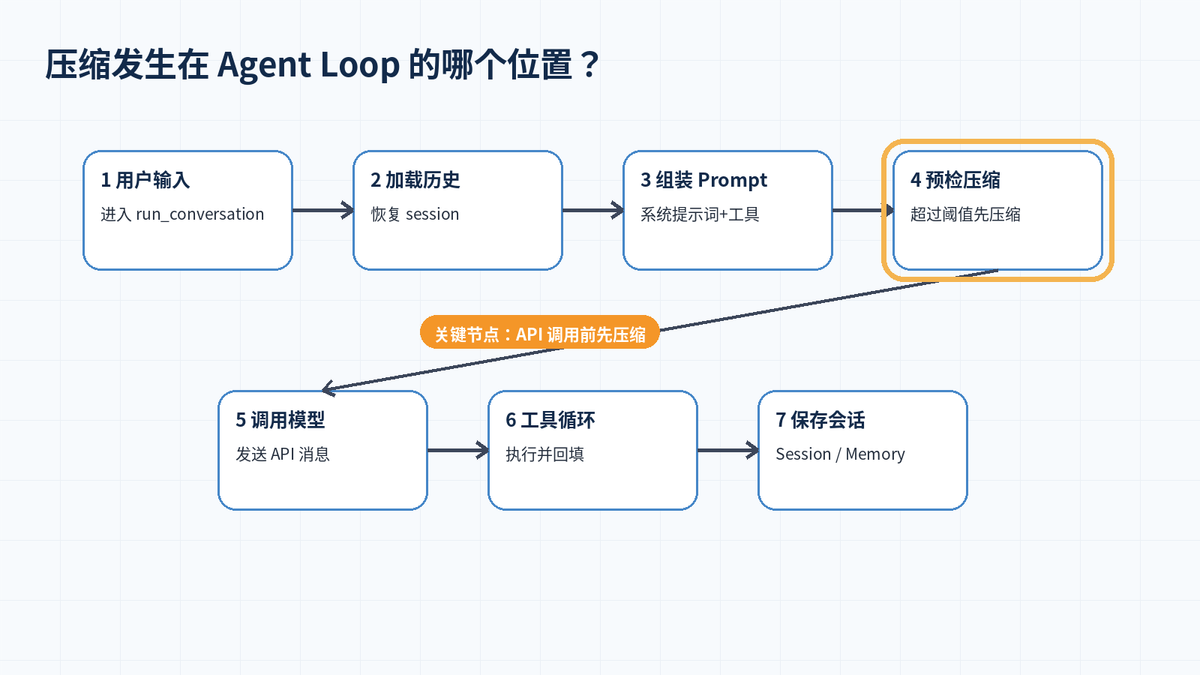
三、ContextCompressor 的四阶段算法
Hermes 的压缩并不是一句“把前文总结一下”这么简单。官方文档把默认 ContextCompressor 的 compress() 描述为四阶段流程:先清理旧工具输出,再确定哪些消息保留和压缩,接着生成结构化摘要,最后重新组装合法消息列表。
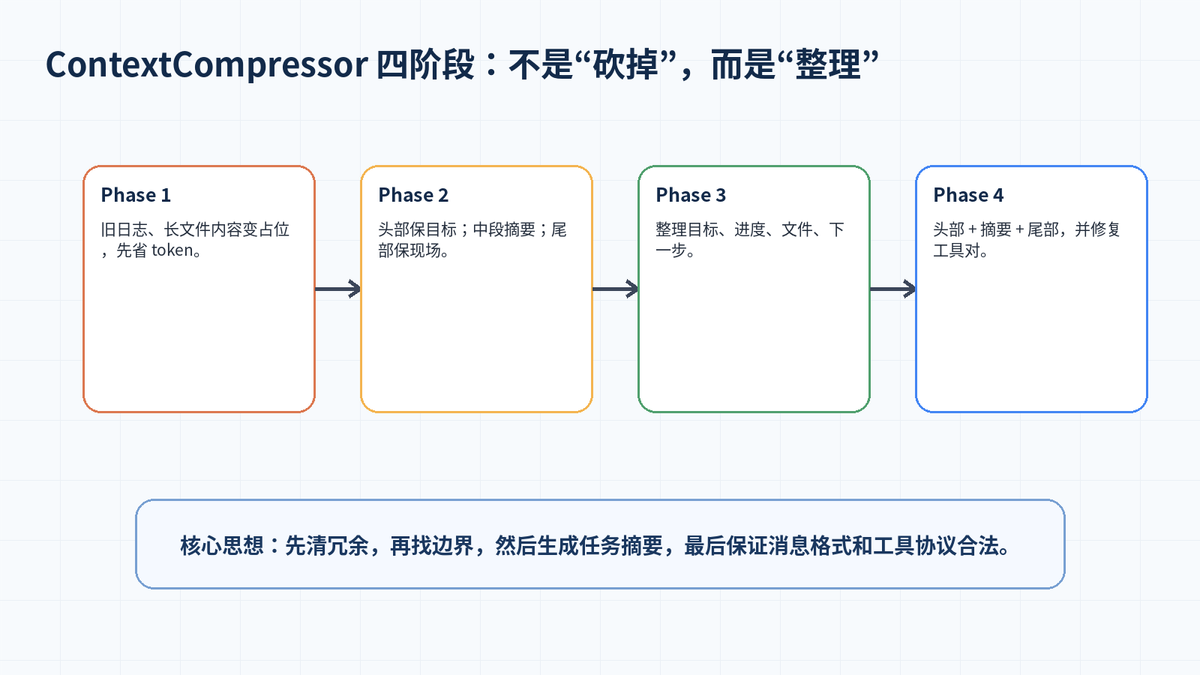
3.1 第一阶段:先清理最占 token 的旧工具输出
长任务里最占空间的,往往不是用户提问,而是工具结果。例如 read_file 读出的长文件、terminal 返回的长日志、web_extract 抓取的网页正文。Hermes 会先把受保护尾部之外、超过一定长度的旧工具输出替换成占位内容。
这一步很便宜,不需要额外 LLM 调用,却能立刻减少大量 token。它相当于先把“历史垃圾输出”清掉,再决定后面是否需要模型总结。
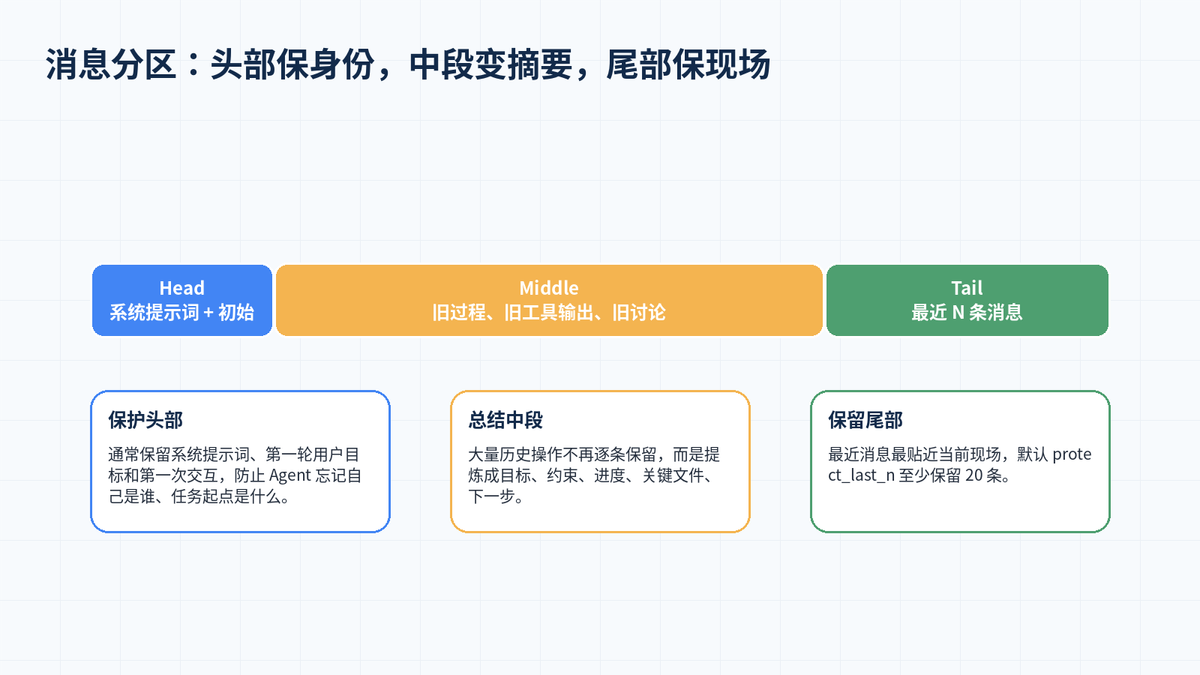
3.2 第二阶段:确定边界,分出 Head、Middle、Tail
压缩的关键是边界。Hermes 会保护最前面的系统提示词和早期目标,保留最近一段对话作为当前现场,中间较旧的过程则交给摘要模型压缩。
Tail 的保留不是简单按消息条数,而是先按 token 预算从后往前累积;如果这样保护的消息太少,则回退到 protect_last_n,默认至少保留最近 20 条消息。
3.3 第三阶段:用辅助模型生成结构化摘要
中段历史不会被一句话带过,而是会按结构化模板进行总结。摘要里会包含 Goal、Constraints & Preferences、Progress、Key Decisions、Relevant Files、Next Steps、Critical Context 等内容。
这类结构化摘要对 Agent 特别重要。因为 Agent 接下来不是要“回忆聊天”,而是要继续工作:继续修测试、继续改文件、继续执行命令。

3.4 第四阶段:重新组装消息,保证协议合法
最终压缩后的消息列表通常是:头部消息 + 压缩摘要消息 + 最近尾部消息。这里还有一个容易被忽略的工程细节:工具调用消息必须合法。
如果 assistant 发起了 tool_call,就必须有对应 tool_result。压缩时不能把调用留在前面、结果删掉,也不能把结果留下、调用删掉。Hermes 会对边界进行对齐,并清理孤立工具对。
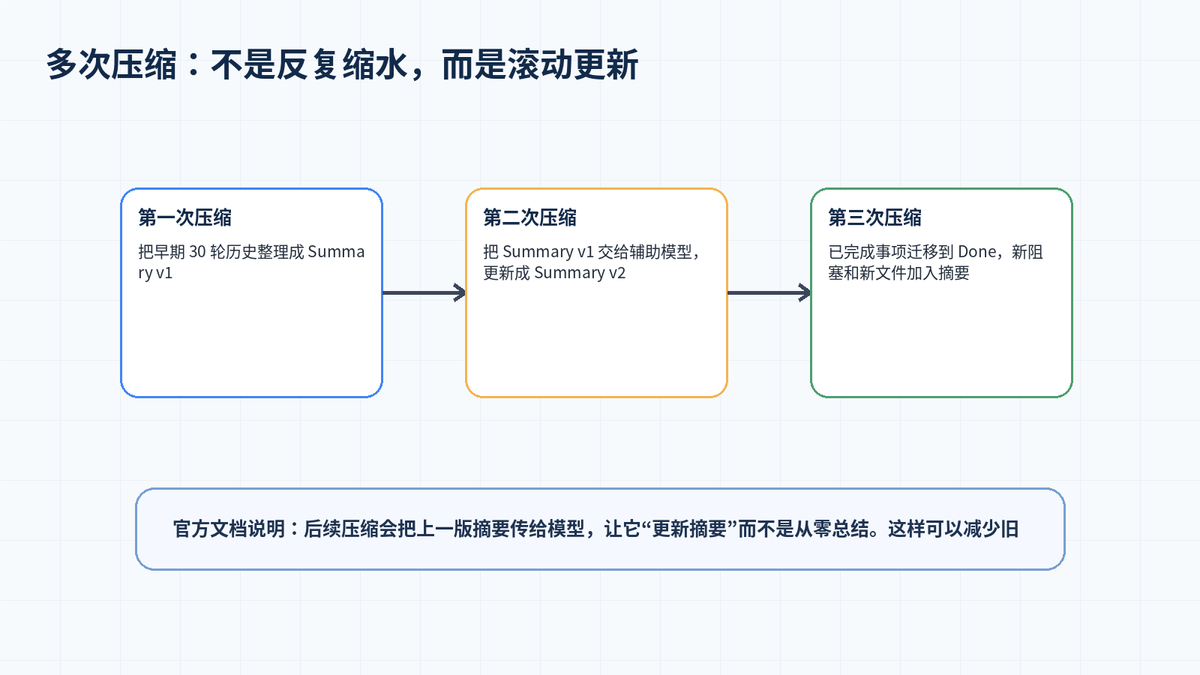
四、二次、三次压缩时,摘要如何继续更新?
长任务不会只压缩一次。一个运行几个小时的 Agent,可能多次接近上下文阈值。Hermes 的处理方式不是每次都从零开始总结,而是把上一版摘要传给辅助模型,让它更新摘要。
这样做有两个好处:一是旧关键信息不会因为多轮压缩不断衰减;二是任务状态可以自然演进,例如“正在修复的 bug”变成“已修复”,“新发现的错误”加入 Critical Context。
4.1 压缩摘要要像“项目状态板”,不是像“聊天记录摘要”
如果摘要只写“用户让助手修复项目,助手做了一些操作”,下一轮模型几乎无法继续工作。好的压缩摘要要写清楚:项目目录、改过的文件、跑过的命令、失败的测试、关键错误信息、下一步要做的具体动作。
这也是 Hermes 把 Progress、Relevant Files、Next Steps、Critical Context 作为固定结构的原因。它让摘要更适合工程续接。
五、Context References 与压缩:大文件不要整份塞
Hermes 支持通过 @file、@folder、@url 等方式把文件、目录、网页材料注入上下文。这个能力很方便,但也容易让上下文膨胀。官方文档说明,当会话后续被压缩时,展开后的引用内容也会进入压缩摘要,而不是永久以原文形式保留。
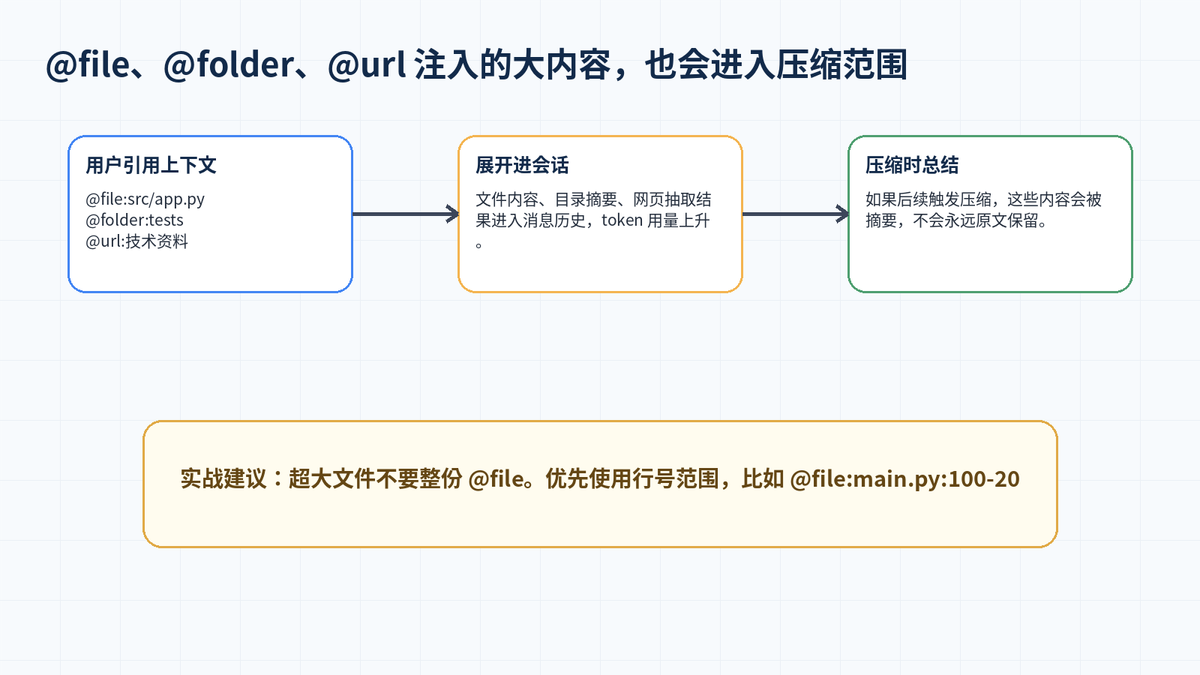
实战中,不建议把超大文件整份 @file 进去。更好的方式是使用行号范围,只把当前问题需要的代码片段加入上下文。这样可以减少压缩频率,也能降低摘要丢失关键细节的风险。
六、压缩和 Prompt Caching 的区别
Hermes 的 Context Compression and Caching 页面同时讲了压缩和缓存,但两者解决的问题不同。压缩解决“上下文放不下”,缓存解决“稳定前缀反复发送太贵”。
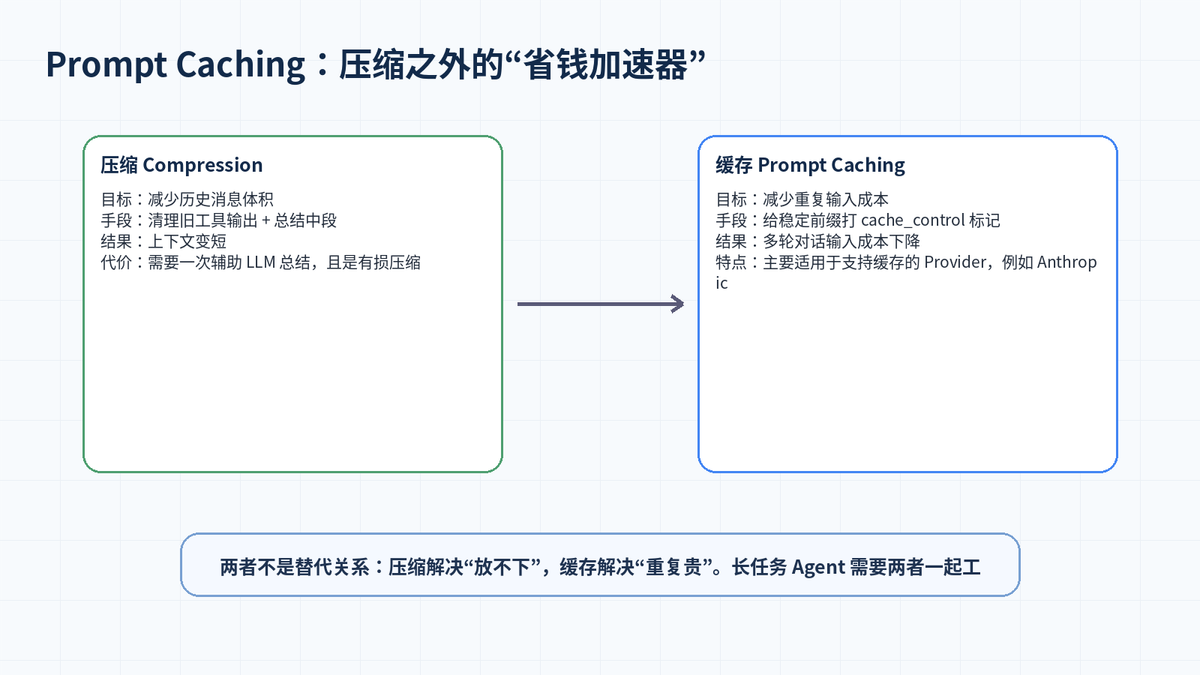
压缩会改变消息历史,把旧的中段内容变成摘要,因此它是有损的。Prompt Caching 不改变内容,它只是告诉支持缓存的模型服务:这些稳定内容可以复用缓存,减少重复输入成本。
对长任务 Agent 来说,二者是互补关系:缓存让多轮调用更省,压缩让超长任务不会超过上下文。
七、配置项:如何控制压缩策略?
Hermes 的压缩配置主要写在 config.yaml。核心参数包括 enabled、threshold、target_ratio、protect_last_n、hygiene_hard_message_limit,以及辅助压缩模型 auxiliary.compression。

配置示例:
compression:
enabled: true
threshold: 0.50
target_ratio: 0.20
protect_last_n: 20
hygiene_hard_message_limit: 400
auxiliary:
compression:
provider: auto
model: "google/gemini-3-flash-preview"
base_url: null
threshold 越低,越早压缩;threshold 越高,越晚压缩。protect_last_n 越大,最近上下文保留越完整,但压缩后消息也会更长。辅助压缩模型要特别注意上下文窗口,官方配置文档提醒:摘要模型的上下文窗口最好不小于主模型,因为中段内容会一次性送给摘要模型。
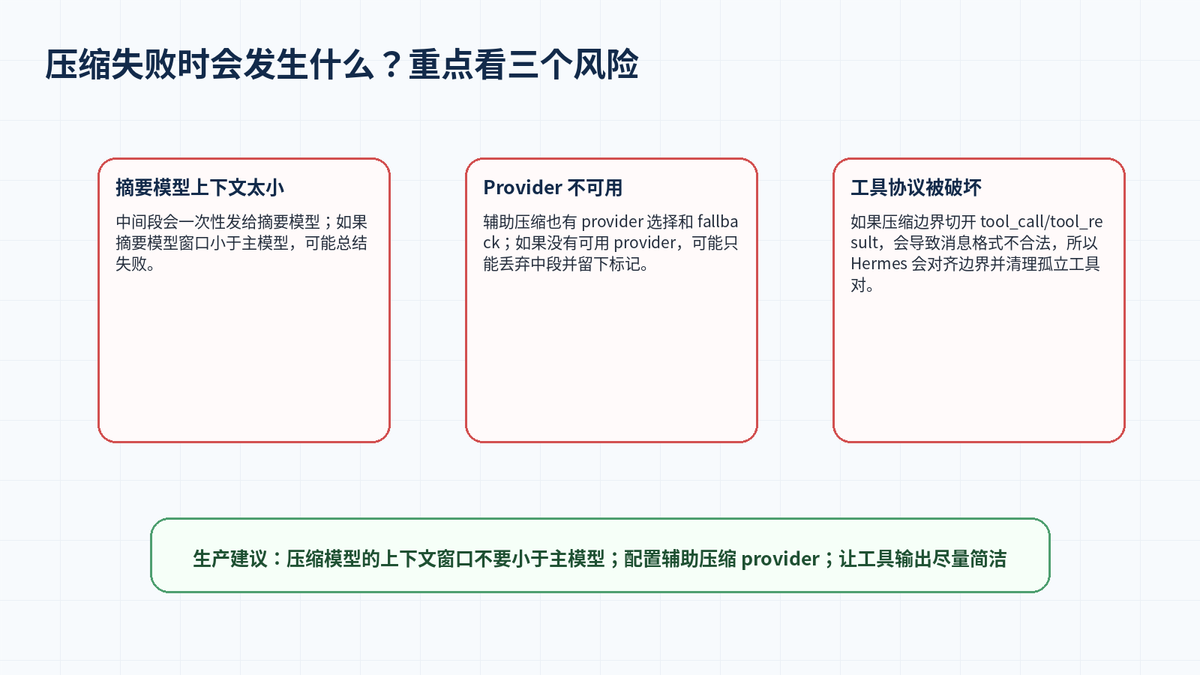
八、Fallback:压缩模型失败时怎么办?
长任务最怕在关键时刻出错:主模型限流,压缩模型也限流,或者辅助模型窗口太小导致总结失败。Hermes 的 Fallback Providers 文档说明,主模型可以配置 fallback,辅助任务也有独立 provider 链,压缩任务使用 auxiliary.compression 控制摘要模型和 provider。
对于主模型,Fallback 通常在 429、5xx、401/403、404 或无效响应等场景触发;触发后会解析备用 provider 凭证、创建新 API client、切换 model/provider/client,并继续当前对话。Fallback 是 turn-scoped:下一次用户消息会重新尝试主模型。
对于压缩任务,如果没有任何可用 provider,官方文档说明 Hermes 会丢弃中段会话而不是让整个 session 失败。这种设计保住了会话继续运行,但也意味着上下文质量会下降。
九、预算控制:为什么压缩还要配合 max_turns?
压缩可以让上下文继续装得下,但不能让 Agent 无限循环。因此 Hermes 还通过 IterationBudget 控制 Agent 循环次数。官方 Agent Loop 文档说明,默认迭代预算是 90 次,可通过 agent.max_turns 配置;子 Agent 有独立预算,默认受 delegation.max_iterations 控制。
这说明 Hermes 的长任务稳定性不是只靠压缩。压缩负责“上下文续航”,Fallback 负责“模型故障切换”,预算负责“防止无限循环和成本失控”。三者合在一起,才是一个可生产运行的 Agent Loop。
9.1 三个控制机制的分工
|
机制 |
主要解决 |
触发点 |
结果 |
|
Context Compression |
上下文过长 |
超过阈值,默认 50% 或 Gateway 85% |
中段历史变结构化摘要 |
|
Fallback |
模型或 provider 故障 |
429、5xx、401/403、404、无效响应等 |
切换备用 provider/model |
|
Iteration Budget |
无限循环和成本失控 |
达到 max_turns 或子 Agent 预算 |
停止并返回已完成摘要 |
十、源码阅读路线:想真正看懂,按这个顺序读
如果你想从源码理解长上下文压缩,不建议一上来通读 run_agent.py。更高效的路线是先看架构,再看触发点,再看压缩器本体,最后看辅助模型与缓存。

阅读顺序建议:先看官方 Context Compression and Caching 文档建立全局概念,再看 run_agent.py 中压缩触发位置,然后看 agent/context_engine.py 的接口,再看 agent/context_compressor.py 的四阶段压缩逻辑,最后看 agent/auxiliary_client.py 和 agent/prompt_caching.py。
十一、给开发者的实战建议
11.1 不要把压缩当作万能补丁
压缩能缓解上下文压力,但它是有损的。真正好的 Agent 工程应该从源头减少无效 token:工具结果要精简,终端日志要截断,大文件要按需读取,网页抽取要控制长度。
11.2 把关键事实写入 Memory,把固定流程沉淀成 Skills
如果某些信息非常关键,不应该只依赖压缩摘要。例如项目的部署方式、用户长期偏好、代码规范,可以进入 Memory 或 Context Files;重复的排查流程,可以沉淀成 Skills。压缩摘要更适合保存“当前任务进度”,不适合充当永久知识库。
11.3 给压缩模型配置足够大的上下文窗口
辅助压缩模型不是越便宜越好。它至少要能吃下待压缩的中段历史,否则可能总结失败。成本、速度和上下文长度需要平衡。
11.4 保留最近现场,减少“断片感”
protect_last_n 不宜过小。长任务里最近几轮往往包含当前错误、刚改的文件和最新工具结果,保留尾部原文可以显著提高后续执行的连贯性。
十二、总结:Hermes 压缩机制的核心价值
Hermes 的上下文压缩,本质是让长期运行的 Agent 获得“续航能力”。它不是把历史简单砍掉,而是通过双层触发、四阶段压缩、结构化摘要、工具调用对齐、滚动更新、Prompt Caching、Fallback 和预算控制,让 Agent 在长任务中保持可继续执行的状态。
从工程角度看,这套机制最值得学习的不是某个参数,而是整体思路:模型负责推理,Agent Runtime 负责整理上下文、保留关键状态、控制成本和处理异常。只有这些工程机制齐全,Agent 才能从“会聊天”走向“能长期干活”。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)