调试多 Agent 最怕黑盒:LangSmith 如何追踪 LangGraph 全流程
当 LangGraph 多 Agent 系统变复杂后,难点往往不是“跑起来”,而是“看清楚它怎么跑”。
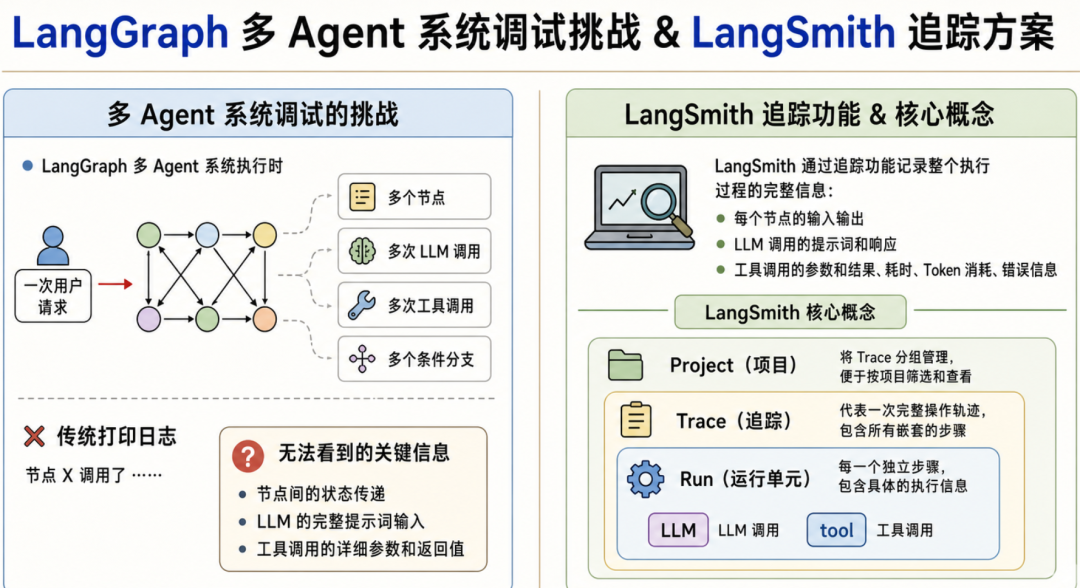
一次请求可能经过多个节点、多次 LLM 调用和工具调用,还会在条件分支里跳转。只靠 `print`,很难判断状态从哪里传坏、Prompt 实际是什么、工具返回了什么、错误发生在哪一步。
LangSmith 解决的就是这个问题:它会把一次 Graph 执行记录成 Trace,把节点、LLM 调用、工具调用拆成一个个 Run,并用 Project 统一管理。
这篇文章会讲清楚:多 Agent 为什么难调试,Project / Trace / Run 是什么,以及如何用一个“研究员、写作者、审阅者”的示例开启追踪,在控制台里定位问题。
多 Agent 系统为什么难调试
单个 Agent 出问题时,排查路径通常还算清楚:输入是什么,模型怎么回答,工具有没有调用成功。
但多 Agent 系统不一样。一次请求进来后,流程可能会被拆成很多独立步骤:
-
coordinator 负责判断下一步该交给谁;
-
researcher 负责搜索和整理资料;
-
writer 负责根据资料生成文章;
-
reviewer 负责审阅和提出修改建议;
-
条件边决定流程继续、跳转还是结束。
这些步骤之间共享同一个 State。也就是说,每个节点不只是“执行自己的函数”,还会读取前面节点留下的信息,并把新的结果写回状态里。只看打印日志,很难完整还原状态是如何一步步变化的。
更麻烦的是,多 Agent 流程里通常还会有多次 LLM 调用和多次工具调用。一个节点看起来只是“研究一下主题”,背后可能已经调用了搜索工具、整理了网页结果、再交给模型总结。真正影响结果质量的,往往就藏在这些嵌套步骤里。
所以,调试多 Agent 系统的关键,不是单纯多打几行日志,而是先把执行链路结构化地记录下来。接下来要看的 LangSmith,正是围绕这条链路展开的。
LangSmith 追踪的核心:Project、Trace、Run
理解 LangSmith 的追踪体系,可以先记住三个词:Project、Trace、Run。
Project 是项目。它负责把相关 Trace 分组管理,便于你按项目筛选、查看和对比。比如我们可以把这个多 Agent 写作团队的追踪都放到 `multi_agent_course` 项目下。
Trace 是一次完整操作的轨迹。一次用户请求触发一次 Graph 执行,就会生成一个 Trace。它代表这次任务从开始到结束的完整执行路径,里面包含所有嵌套步骤。
Run 是运行单元。Trace 中的每一个独立步骤都可以是一个 Run,例如一次节点执行、一次 LLM 调用、一次工具调用。换句话说,Trace 像一棵树,Run 就是树上的每个节点。
用多 Agent 工作流来对应:
-
一次
graph.invoke()生成一个 Trace; -
coordinator、research、write、review 等节点执行会成为 Run;
-
节点内部的 LLM 调用和工具调用也会继续成为子 Run;
-
每个 Run 都会记录输入、输出、耗时、Token、错误等信息。
理解了 Project、Trace、Run 的关系之后,下一步就是把追踪真正打开,让 LangGraph 的执行过程自动进入 LangSmith。
准备工作:开启 LangSmith 追踪
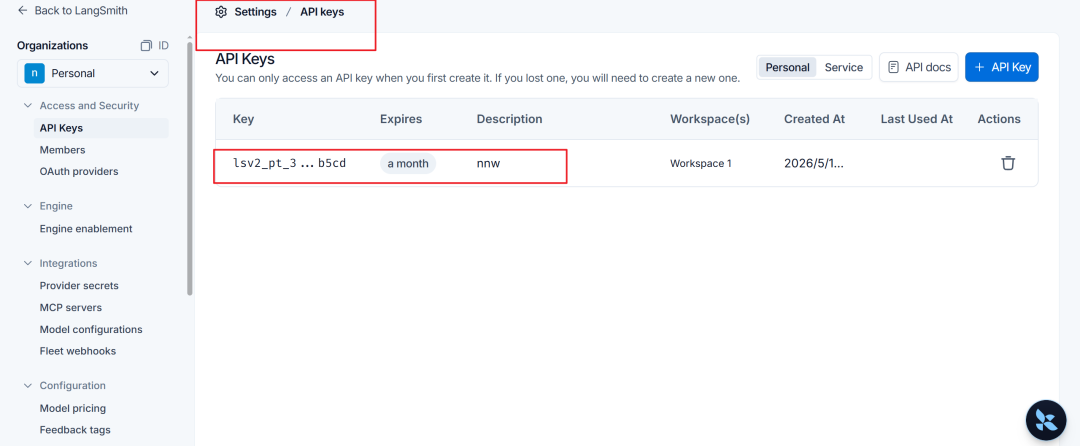
接入 LangSmith 前,需要先注册并获取 API Key。
访问 `https://smith.langchain.com`,
登录后进入 Settings / API Keys 页面,创建一个新的 API Key。实际项目中不要把 Key 写进代码仓库,建议放在 `.env` 或部署平台的环境变量里。
先安装需要的依赖:
pip install langgraph langsmith python-dotenv
如果你的项目里还会用到 LangChain 的模型封装、Agent 创建工具或外部搜索工具,也需要安装对应依赖,例如:
pip install langchain-openai tavily-python

模型或工具服务配置:
DASHSCOPE_API_KEY=sk-你的_模型服务_Key
TAVILY_API_KEY=tvly-你的_搜索服务_Key
可以直接在代码里设置环境变量,但更推荐使用 `.env` 或部署环境配置:
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls__你的_LangSmith_API_Key"
os.environ["LANGCHAIN_PROJECT"] = "multi_agent_course"到这里,追踪的基础配置就完成了。接下来我们用一个研究写作团队示例,把这些配置放进真实的多 Agent 流程里看一遍。
示例:给研究写作团队接入追踪
下面这个例子模拟一个常见的多 Agent 流程:用户给一个主题,研究员先收集资料,写作者根据资料写初稿,审阅者再检查文章质量。
State 是整个工作流的共同记忆,节点之间靠它传递结果:
# ---------- 3. 定义 State ----------
class ResearchState(TypedDict):
topic: str
research_notes: Optional[str]
draft: Optional[str]
review_feedback: Optional[str]
final_article: Optional[str]
next_step: str这个 State 里既有用户输入的 `topic`,也有中间产物:`research_notes`、`draft`、`review_feedback` 和最终文章。调试时最需要看的,正是这些字段如何在节点之间变化。
接下来定义几个节点。为了便于理解,这里保留核心结构:
# ---------- 4. 定义节点函数 ----------
def coordinator(state: ResearchState) -> ResearchState:
step = state.get("next_step", "research")
return {"next_step": step}
def research_node(state: ResearchState) -> ResearchState:
topic = state["topic"]
print(f"研究员正在搜索主题:{topic}")
response = researcher_agent.invoke({"messages": [("user", topic)]})
notes = response["messages"][-1].content
print(f"研究员完成,收集到 {len(notes)} 字符的资料")
return {"research_notes": notes, "next_step": "write"}
def write_node(state: ResearchState) -> ResearchState:
notes = state["research_notes"]
print("写作者正在撰写文章...")
response = writer_agent.invoke({"messages": [("user", f"根据以下资料写文章:\n{notes}")]})
draft = response["messages"][-1].content
print(f"写作者完成,撰写 {len(draft)} 字符的文章")
return {"draft": draft, "next_step": "review"}
def review_node(state: ResearchState) -> ResearchState:
draft = state["draft"]
print("审阅者正在审阅文章...")
response = reviewer_agent.invoke({"messages": [("user", f"请审阅以下文章:\n{draft}")]})
feedback = response["messages"][-1].content
print(f"审阅者完成,反馈 {len(feedback)} 字符")
final = draft if "严重问题" not in feedback else draft + "\n\n【修改建议】\n" + feedback
return {"review_feedback": feedback, "final_article": final, "next_step": "end"}这里的 `print` 只能告诉我们“研究员完成”“写作者完成”。但 LangSmith 记录的信息会更细:它能看到每个节点的输入 State、输出 State、节点内部的 LLM 请求、模型响应、工具调用参数、耗时和异常。
然后构建 Graph:
# ---------- 5. 构建 Graph ----------
builder = StateGraph(ResearchState)
builder.add_node("coordinator", coordinator)
builder.add_node("research", research_node)
builder.add_node("write", write_node)
builder.add_node("review", review_node)
builder.set_entry_point("coordinator")
builder.add_conditional_edges(
"coordinator",
lambda s: s["next_step"],
{
"research": "research",
"write": "write",
"review": "review",
"end": END
}
)
builder.add_edge("research", "coordinator")
builder.add_edge("write", "coordinator")
builder.add_edge("review", "coordinator")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)最后执行:# ---------- 6. 执行并自动生成 Trace ----------
config = {"configurable": {"thread_id": "writing_team_with_tracing"}}
initial_state = {"topic": "人工智能在医疗领域的应用", "next_step": "research"}
print("=== 开始研究写作流程 ===")
print("注意:本次执行会自动在 LangSmith 中生成 Trace")
result = graph.invoke(initial_state, config=config)
print("\n=== 最终文章 ===")
print(result["final_article"])
print("\n请登录 LangSmith 控制台查看完整的 Trace")
print("LangSmith 控制台地址: https://smith.langchain.com")执行完成后,LangSmith 控制台中就会出现一条新的 Trace。它不是简单记录“程序跑完了”,而是把研究写作流程拆成可展开的执行树,方便我们继续查看每个节点和每次调用。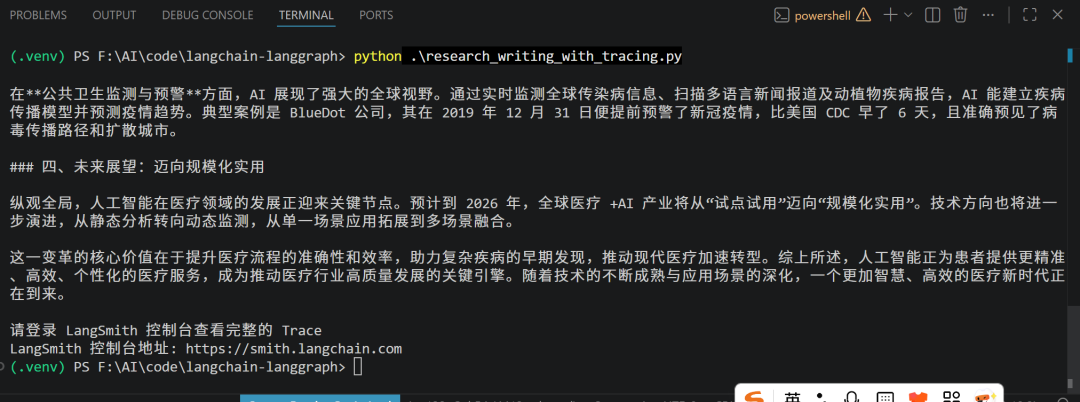
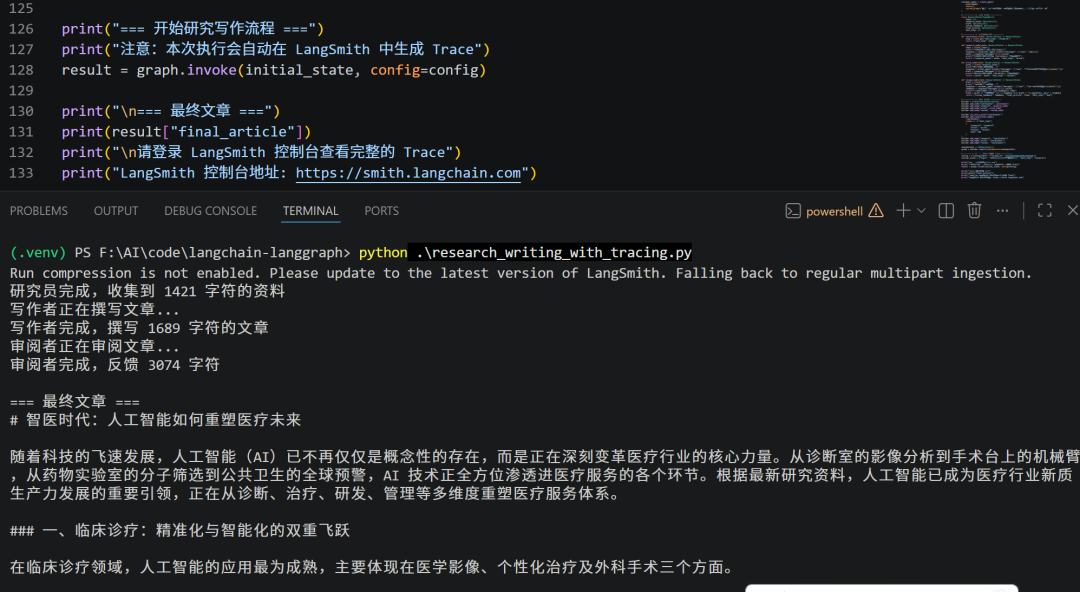
完整代码:
import os
from typing import TypedDict, Optional
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import InMemorySaver
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_core.tools import tool
from tavily import TavilyClient
from dotenv import load_dotenv
# 加载环境变量(包括 LangSmith 配置)
# load_dotenv()
# 在代码中直接设置 LangSmith 环境变量
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "你的langsmith key"
os.environ["LANGCHAIN_PROJECT"] = "research_writing_demo"
# ---------- 1. 初始化 ----------
if not os.getenv("DASHSCOPE_API_KEY"):
raise ValueError("请先设置环境变量 DASHSCOPE_API_KEY")
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
tavily = TavilyClient(api_key='tvly-dev-222222222')
@tool
def web_search(query: str) -> str:
"""搜索互联网获取资料"""
result = tavily.search(query, max_results=2)
summaries = [item["content"] for item in result.get("results", [])]
return "\n".join(summaries) if summaries else "未找到相关信息"
# ---------- 2. 创建各 Agent ----------
researcher_agent = create_agent(
model=model,
tools=[web_search],
system_prompt="你是一个研究员。根据用户主题,使用搜索工具收集资料,并整理成要点列表。"
)
writer_agent = create_agent(
model=model,
tools=[],
system_prompt="你是一个专业写作者。根据研究员提供的资料,撰写一篇结构清晰、语言流畅的文章。"
)
reviewer_agent = create_agent(
model=model,
tools=[],
system_prompt="你是一个审阅编辑。检查文章的逻辑、语法和风格,提出修改建议。"
)
# ---------- 3. 定义 State ----------
class ResearchState(TypedDict):
topic: str
research_notes: Optional[str]
draft: Optional[str]
review_feedback: Optional[str]
final_article: Optional[str]
next_step: str
# ---------- 4. 定义节点函数 ----------
def coordinator(state: ResearchState) -> ResearchState:
step = state.get("next_step", "research")
return {"next_step": step}
def research_node(state: ResearchState) -> ResearchState:
topic = state["topic"]
print(f"研究员正在搜索主题:{topic}")
response = researcher_agent.invoke({"messages": [("user", topic)]})
notes = response["messages"][-1].content
print(f"研究员完成,收集到 {len(notes)} 字符的资料")
return {"research_notes": notes, "next_step": "write"}
def write_node(state: ResearchState) -> ResearchState:
notes = state["research_notes"]
print("写作者正在撰写文章...")
response = writer_agent.invoke({"messages": [("user", f"根据以下资料写文章:\n{notes}")]})
draft = response["messages"][-1].content
print(f"写作者完成,撰写 {len(draft)} 字符的文章")
return {"draft": draft, "next_step": "review"}
def review_node(state: ResearchState) -> ResearchState:
draft = state["draft"]
print("审阅者正在审阅文章...")
response = reviewer_agent.invoke({"messages": [("user", f"请审阅以下文章:\n{draft}")]})
feedback = response["messages"][-1].content
print(f"审阅者完成,反馈 {len(feedback)} 字符")
final = draft if "严重问题" not in feedback else draft + "\n\n【修改建议】\n" + feedback
return {"review_feedback": feedback, "final_article": final, "next_step": "end"}
# ---------- 5. 构建 Graph ----------
builder = StateGraph(ResearchState)
builder.add_node("coordinator", coordinator)
builder.add_node("research", research_node)
builder.add_node("write", write_node)
builder.add_node("review", review_node)
builder.set_entry_point("coordinator")
builder.add_conditional_edges(
"coordinator",
lambda s: s["next_step"],
{
"research": "research",
"write": "write",
"review": "review",
"end": END
}
)
builder.add_edge("research", "coordinator")
builder.add_edge("write", "coordinator")
builder.add_edge("review", "coordinator")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# ---------- 6. 执行并自动生成 Trace ----------
config = {"configurable": {"thread_id": "writing_team_with_tracing"}}
initial_state = {"topic": "人工智能在医疗领域的应用", "next_step": "research"}
print("=== 开始研究写作流程 ===")
print("注意:本次执行会自动在 LangSmith 中生成 Trace")
result = graph.invoke(initial_state, config=config)
print("\n=== 最终文章 ===")
print(result["final_article"])
print("\n请登录 LangSmith 控制台查看完整的 Trace")
print("LangSmith 控制台地址: https://smith.langchain.com")在 LangSmith 控制台里看什么
进入 LangSmith 控制台后,选择对应的 Project,例如 `multi_agent_course`,再点开最近一次 Trace。
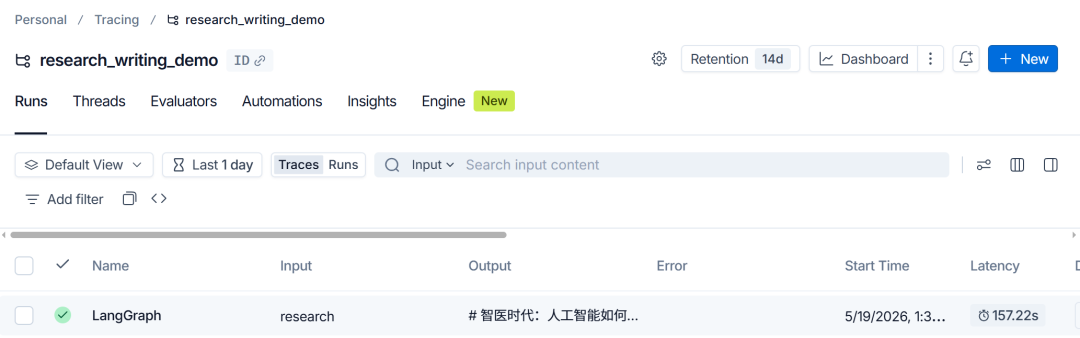
打开 Trace 后,不需要一上来就看所有字段。调试时可以先抓住下面几类信息。
第一是 Timeline。它展示各个节点执行的先后顺序和耗时。你可以快速判断流程是否按预期推进,也能发现哪一步最慢。
第二是 Tree。它展示 Run 的嵌套结构。根 Run 下面可能包含 `coordinator`、`research`、`write`、`review` 等子 Run;如果某个节点内部又调用了 LLM 或工具,还可以继续展开查看。
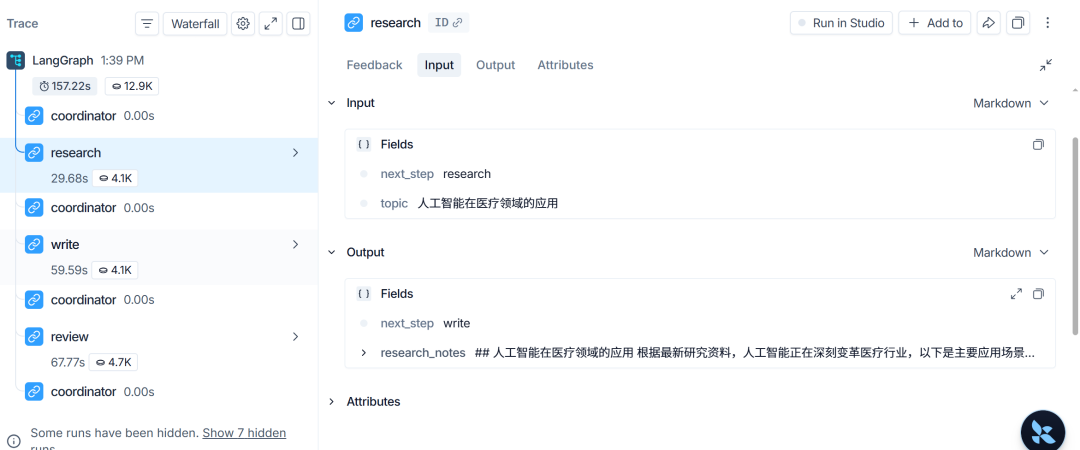
第三是每个节点的输入和输出。点击任意节点,可以看到它接收到的 State,以及它返回了哪些字段。这对排查“为什么下一个节点拿不到数据”“为什么状态没有更新”特别有用。
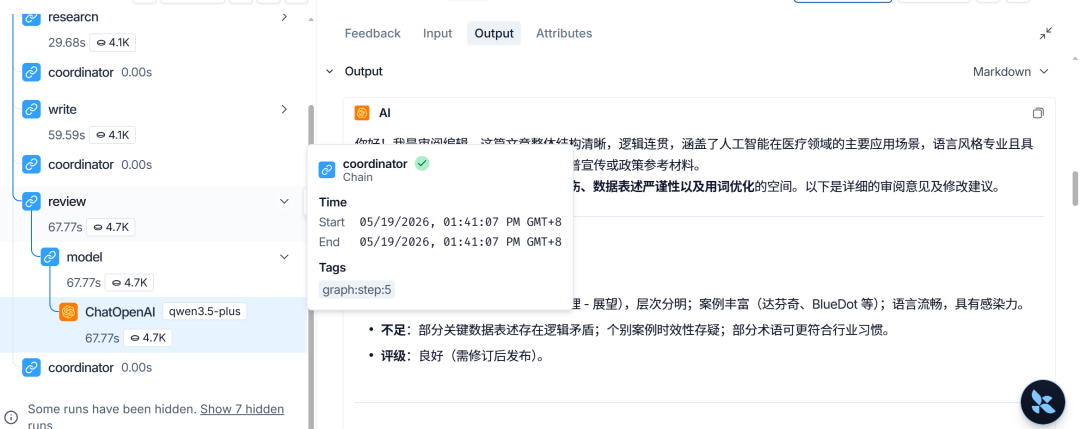
第四是 LLM 调用详情。只要节点内部调用了模型,就可以查看完整提示词、模型响应、Token 消耗和耗时。很多生成质量问题并不是模型本身的问题,而是前面传入的上下文已经不完整或不准确。
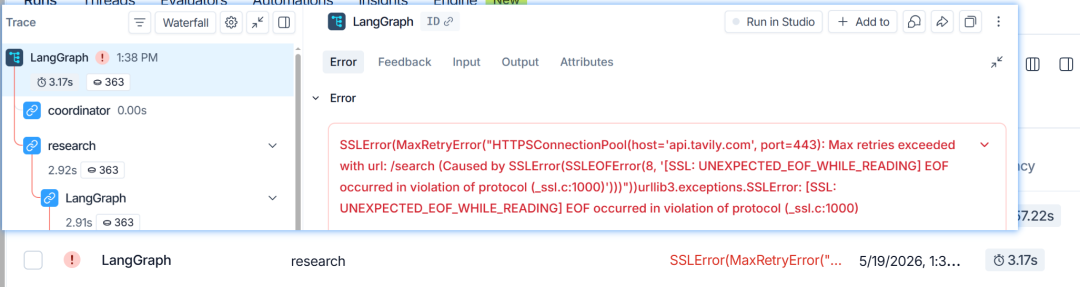
第五是错误信息。如果某个节点、模型调用或工具调用失败,Trace 中会记录异常详情。相比只看终端报错,Trace 能告诉你错误发生在整条执行链路的哪个具体 Run 上。
用 Trace 反推多 Agent 问题
前面我们已经能在控制台里看到完整 Trace,接下来就可以反过来用这些信息定位具体问题。
如果最终文章质量不好,先看 `research` 节点输出的 `research_notes` 是否足够完整。资料本身太薄,后面的写作节点通常也很难写好。
如果写作节点没有按预期使用研究资料,点开对应 LLM Run,检查完整 Prompt。很多时候问题出在 prompt 拼接、字段为空、上下文过长被截断,而不是 Agent “不听话”。
如果流程没有进入某个节点,检查 Graph 的边和 `next_step`。多条件分支里,路由函数返回值和节点名称不一致,是很常见的问题。
如果执行很慢,先看 Timeline,再展开耗时最长的 Run。多 Agent 系统里性能瓶颈常常不在 Graph 本身,而在某次工具调用、某个搜索请求,或某个模型响应过慢。
如果工具返回结果异常,直接点开工具 Run,看输入参数和返回值。这样能避免在业务代码里反复加日志、重跑、猜测。
追踪不是日志替代品,而是执行地图
打印日志仍然有价值,尤其适合记录一些业务侧的简短状态。但在 LangGraph 多 Agent 系统里,日志更像路边标记,LangSmith Trace 更像一张完整地图。
它记录的不只是“发生了什么”,还包括:
-
每一步从哪里来;
-
带着什么输入执行;
-
调用了哪个模型或工具;
-
返回了什么输出;
-
花了多少时间;
-
消耗了多少 Token;
-
如果失败,失败在哪个具体步骤。
这也是为什么在多 Agent 项目里,LangSmith 往往不是上线后才接入的监控工具,而是开发阶段就应该打开的调试工具。先看清执行链路,再谈优化效果,排查才会有方向。
小结
回到开头的问题:LangGraph 让我们可以把复杂任务拆成多个 Agent 和多个节点协作完成,但复杂度也随之从“单次模型调用”变成了“多步骤执行链路”。
要调试这样的系统,只靠打印日志很难看清全貌。LangSmith 通过 Project、Trace、Run 三层结构,把一次完整请求拆成可查看、可展开、可分析的执行轨迹。
可以用一句话记住:
Project 管一组任务,Trace 记录一次完整执行,Run 记录其中每一个具体步骤。
当你能看到每个节点的输入输出、每次 LLM 调用的提示词和响应、每次工具调用的参数和结果,多 Agent 系统就不再是一个黑盒。它会变成一条可以顺着排查、可以定位瓶颈、也可以持续优化的工作流。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)