RHEL 10.1 从零部署 Ollama + Gemma4:e4b + Hermes Agent
API Key: 留空,或随便填一个本地占位值ollama这是本地占位值,不会产生费用。
RHEL 10.1 从零部署 Ollama + Gemma4:e4b + Hermes Agent
本文档适用于在 Red Hat Enterprise Linux 10.1 虚拟机中,完全本地、零 API 费用地部署:
- Ollama
gemma4:e4b本地模型- Hermes Agent
- 通过 Hermes 接入本地 Ollama 模型
目标环境:
- 系统:Red Hat Enterprise Linux 10.1
- 虚拟机配置:4 vCPU / 6GB RAM
- 模型运行方式:CPU + swap
- 费用:不使用 OpenAI、Anthropic、OpenRouter、Nous Portal、Ollama Cloud 等付费 API
重要说明:6GB 内存跑
gemma4:e4b属于极限方案。可以尝试运行,但速度会很慢,系统可能明显卡顿。swap 只能防止内存不足导致程序直接退出,不能替代真实内存性能。
1. 推荐虚拟机设置
在虚拟机软件中建议这样设置:
| 项目 | 推荐值 |
|---|---|
| CPU | 4 核,能给 6-8 核更好 |
| 内存 | 当前 6GB 可尝试,推荐 16GB 以上 |
| 磁盘 | 最少 60GB,推荐 100GB |
| 磁盘类型 | SSD/NVMe 上的虚拟磁盘 |
| 网络 | NAT 即可 |
| 固件 | UEFI |
如果宿主机使用机械硬盘,不建议靠 swap 跑模型,体验会非常差。
2. 系统初始化
登录 RHEL 10.1 后,先更新系统:
sudo dnf update -y
安装基础工具:
sudo dnf install -y curl git tar gzip xz zstd ca-certificates findutils which procps-ng
确认系统资源:
free -h
df -h
nproc
3. 配置大 swap
由于当前虚拟机只有 6GB 内存,建议创建 24GB swap 文件。
查看当前 swap:
swapon --show
free -h
创建 swap 文件:
sudo fallocate -l 24G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
确认 swap 已启用:
swapon --show
free -h
设置开机自动启用:
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
降低系统主动使用 swap 的倾向:
echo 'vm.swappiness=10' | sudo tee /etc/sysctl.d/99-local-swappiness.conf
sudo sysctl --system
再次确认:
cat /proc/sys/vm/swappiness
正常应输出:
10
4. 安装 Ollama
国内网络环境下,官方安装脚本可能在下载 Ollama 压缩包时非常慢。推荐先在 Windows 宿主机浏览器中下载压缩包,再传到 RHEL 虚拟机中手动安装。
下载地址:
https://ollama.com/download/ollama-linux-amd64.tar.zst
假设下载后的文件已经传到 RHEL 的 /root/ollama-linux-amd64.tar.zst。
进入文件所在目录:
cd /root
ls -lh ollama-linux-amd64.tar.zst
安装解压工具:
sudo dnf install -y zstd tar
解压到 /usr/local:
sudo tar -C /usr/local -I zstd -xf ollama-linux-amd64.tar.zst
查找 Ollama 可执行文件:
find /usr/local -name ollama -type f
如果看到 /usr/local/bin/ollama,创建系统命令软链接:
sudo ln -sf /usr/local/bin/ollama /usr/bin/ollama
查看版本:
ollama -v
创建 systemd 服务:
sudo tee /etc/systemd/system/ollama.service >/dev/null <<'EOF'
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="PATH=/usr/local/bin:/usr/bin:/bin"
Environment="OLLAMA_HOST=127.0.0.1:11434"
[Install]
WantedBy=default.target
EOF
启动 Ollama 服务:
sudo systemctl enable --now ollama
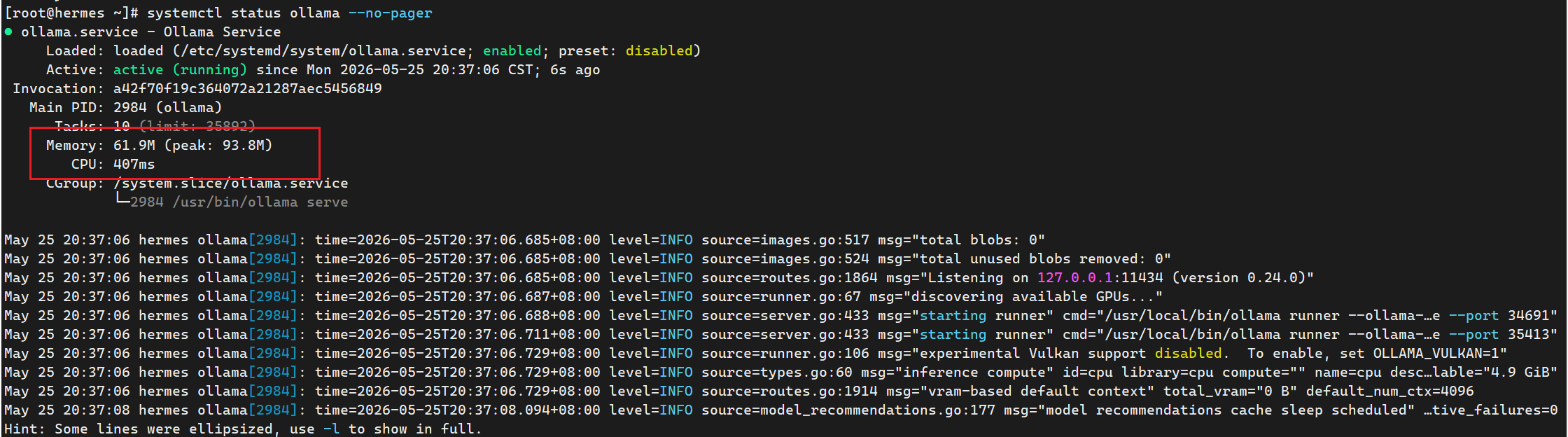
查看服务状态:
systemctl status ollama --no-pager
如果你网络能直接访问 Ollama,也可以使用官方安装脚本作为替代方式:
curl -fsSL https://ollama.com/install.sh | sh
测试 Ollama API:
curl http://localhost:11434/api/tags
如果能返回 JSON,说明 Ollama 服务正常。
5. 配置 Ollama context
Hermes Agent 使用工具时会占用较多上下文。先配置 Ollama 默认上下文长度为 64000。
编辑 systemd 覆盖配置:
sudo systemctl edit ollama
填入以下内容:
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=64000"
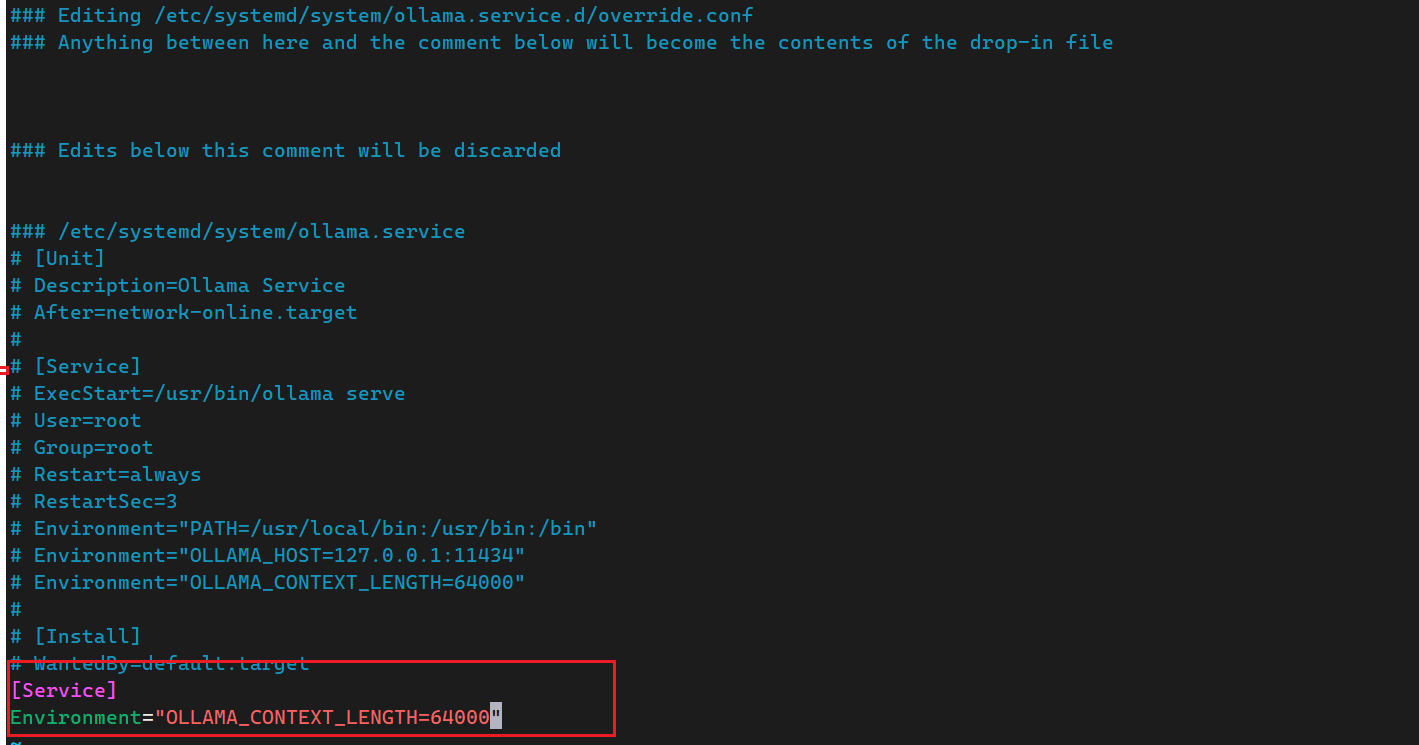
保存后执行:
sudo systemctl daemon-reload
sudo systemctl restart ollama
确认服务恢复:
systemctl status ollama --no-pager
如果 6GB 内存 + swap 下运行特别慢,可以后续把
64000改成32768或16384,速度和稳定性会更好,但 Hermes 的长任务能力会变弱。
6. 下载并测试 Gemma4:e4b
拉取模型:
ollama pull gemma4:e4b

运行模型:
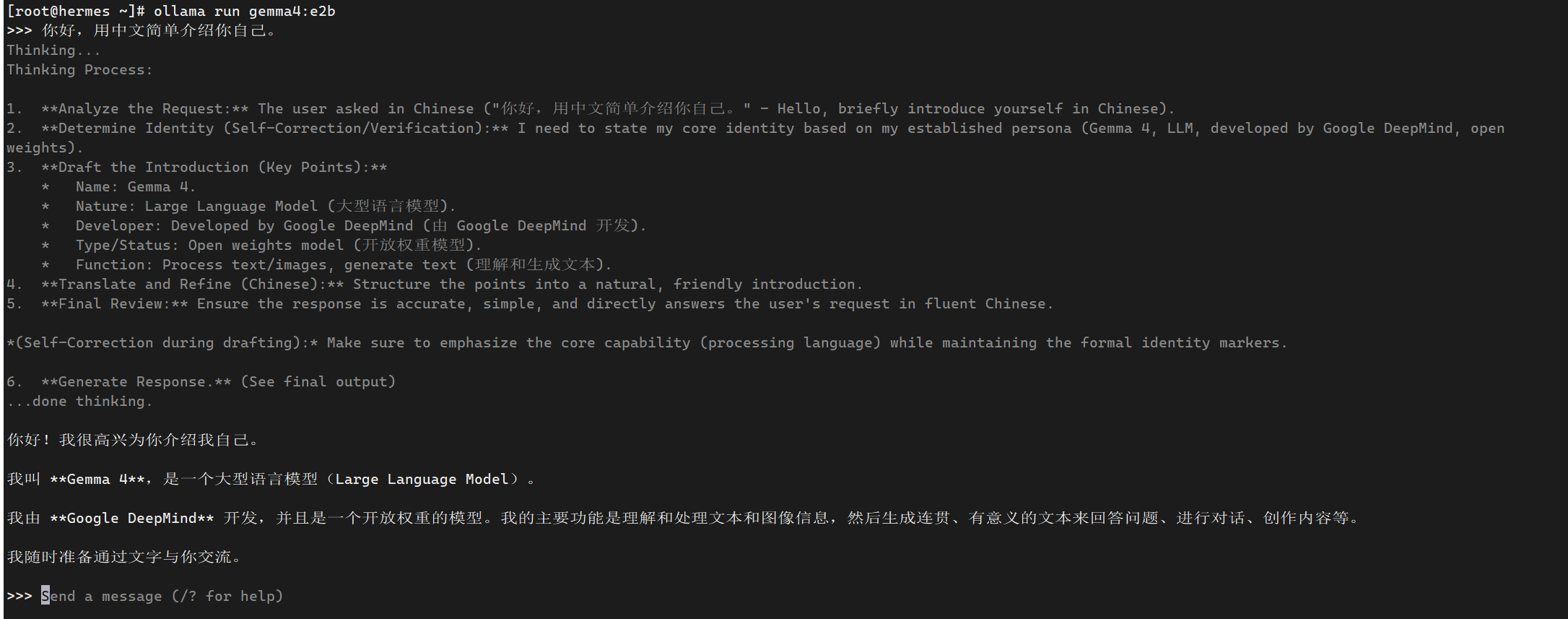
ollama run gemma4:e4b
进入交互界面后输入:
你好,请用中文简单介绍你自己。

这里加载很慢,由于配置很低,所以需要多等一会儿时间
如果模型能回复,说明模型可用。
另开一个终端查看模型状态:
ollama ps
重点看:
- 模型名是否是
gemma4:e4b - CONTEXT 是否接近设置值
- CPU/内存是否已经明显吃满
退出 Ollama 交互:
/bye
这里因为加载恢复很慢,换成更小的gemma4:e2b模型
重启 Ollama,清掉当前加载状态:
sudo systemctl restart ollama
把 context 也建议先降到 16384,更适合你这个内存:
sudo systemctl edit ollama
填或改成:
[Service] Environment="OLLAMA_CONTEXT_LENGTH=16384"
保存后:
sudo systemctl daemon-reload sudo systemctl restart ollama
然后拉取 e2b:
ollama pull gemma4:e2b
运行测试:
ollama run gemma4:e2b
进去后输入:
你好,用中文简单介绍你自己。
后面 Hermes 里模型名也改成:
gemma4:e2b
Base URL 还是:
http://localhost:11434/v1
如果 gemma4:e2b 还是慢,再把 context 降到:
[Service] Environment="OLLAMA_CONTEXT_LENGTH=8192"
7. 安装 Hermes Agent
国内网络环境下,Hermes 官方安装脚本可能会卡在 GitHub clone。推荐先在 Windows 下载源码包,再传到 RHEL 手动安装。
Windows 下载地址:
https://github.com/NousResearch/hermes-agent/archive/refs/heads/main.tar.gz
假设文件已传到 RHEL:
/root/hermes-agent-main.tar.gz
解压到 /usr/local/lib/hermes-agent:
cd /root
rm -rf /usr/local/lib/hermes-agent
tar -xzf hermes-agent-main.tar.gz -C /usr/local/lib
mv /usr/local/lib/hermes-agent-main /usr/local/lib/hermes-agent
cd /usr/local/lib/hermes-agent
使用安装脚本前面已安装好的 uv 创建环境并安装依赖:
/root/.local/bin/uv sync --extra all --locked
如果这一步成功,会看到类似:
Installed ... packages
hermes-agent==0.14.0
创建全局 hermes 命令。注意 Hermes 实际环境目录是 .venv,不是 venv:
cat >/usr/local/bin/hermes <<'EOF'
#!/usr/bin/env bash
unset PYTHONPATH PYTHONHOME
exec /usr/local/lib/hermes-agent/.venv/bin/hermes "$@"
EOF
chmod +x /usr/local/bin/hermes
检查 Hermes:
hermes --version
hermes doctor
如果输出 Hermes Agent v0.14.0,说明安装成功。
如果 hermes doctor 提示缺少 ~/.hermes/.env,继续执行:
hermes setup
配置时选择本地 OpenAI-compatible endpoint:
Base URL: http://localhost:11434/v1
API Key: ollama
Model: gemma4:e2b
Context length: 8192
8. 让 Hermes 接入本地 Ollama
Ollama 提供 OpenAI-compatible API,地址是:
http://localhost:11434/v1
方式一:使用 Ollama 的 Hermes 启动方式
可以先尝试:
ollama launch hermes --model gemma4:e2b
如果能正常进入 Hermes,就优先使用这种方式。
方式二:通过 Hermes 选择自定义模型
运行:
hermes model
选择自定义 endpoint 或 self-hosted provider,然后填写: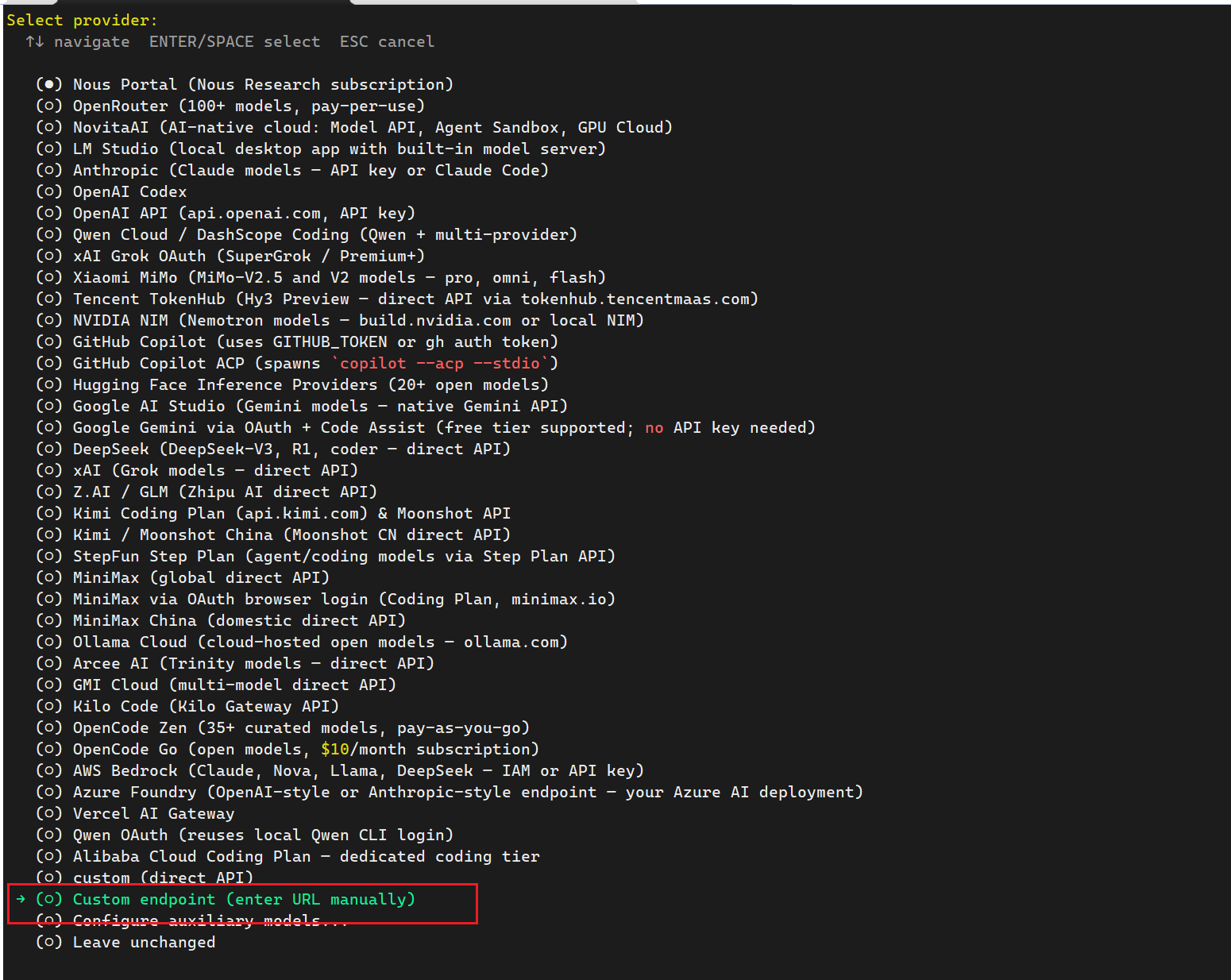

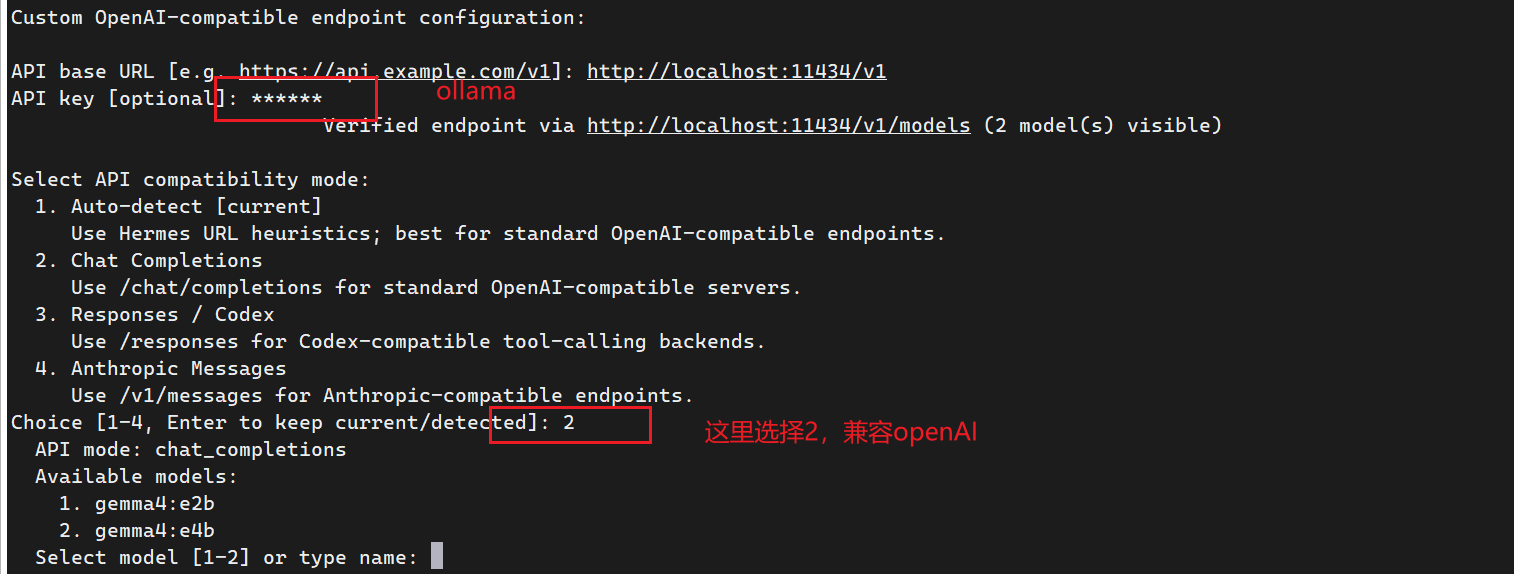
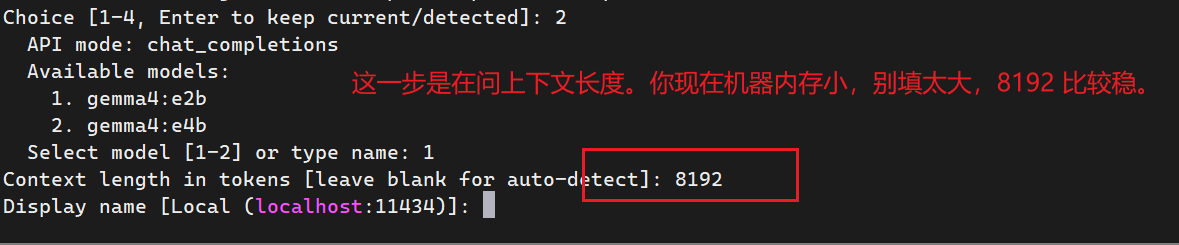

Provider: custom / self-hosted / OpenAI-compatible
Base URL: http://localhost:11434/v1
API Key: 留空,或随便填一个本地占位值
Model: gemma4:e2b
Context length: 64000
如果 Hermes 要求 API key 非空,可以填:
ollama
这是本地占位值,不会产生费用。
完整配置如下: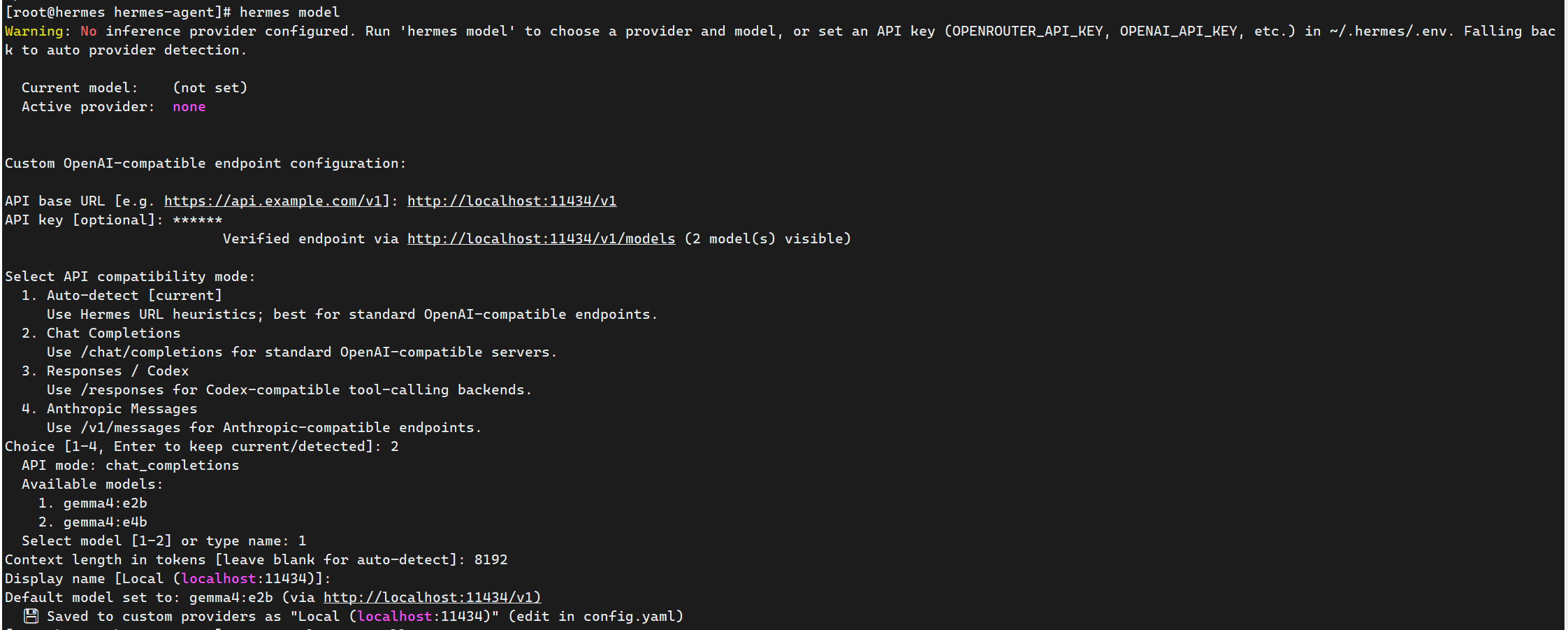
方式三:手动编辑 Hermes 配置
如果上面的交互配置不可用,可以查找 Hermes 配置目录:
ls -la ~/.hermes
常见配置文件可能是:
~/.hermes/config.yaml
可参考以下配置:
model:
default: gemma4:e4b
provider: custom
base_url: http://localhost:11434/v1
api_key: ollama
context_length: 64000
不同 Hermes 版本的配置字段可能略有变化。如果 Hermes 提供 hermes model,优先使用交互式配置。
9. 启动 Hermes
确保 Ollama 服务正在运行:
systemctl status ollama --no-pager
启动 Hermes:
hermes
测试输入:
请用中文回复:你现在是否正在使用本地 Ollama 模型?
报错了
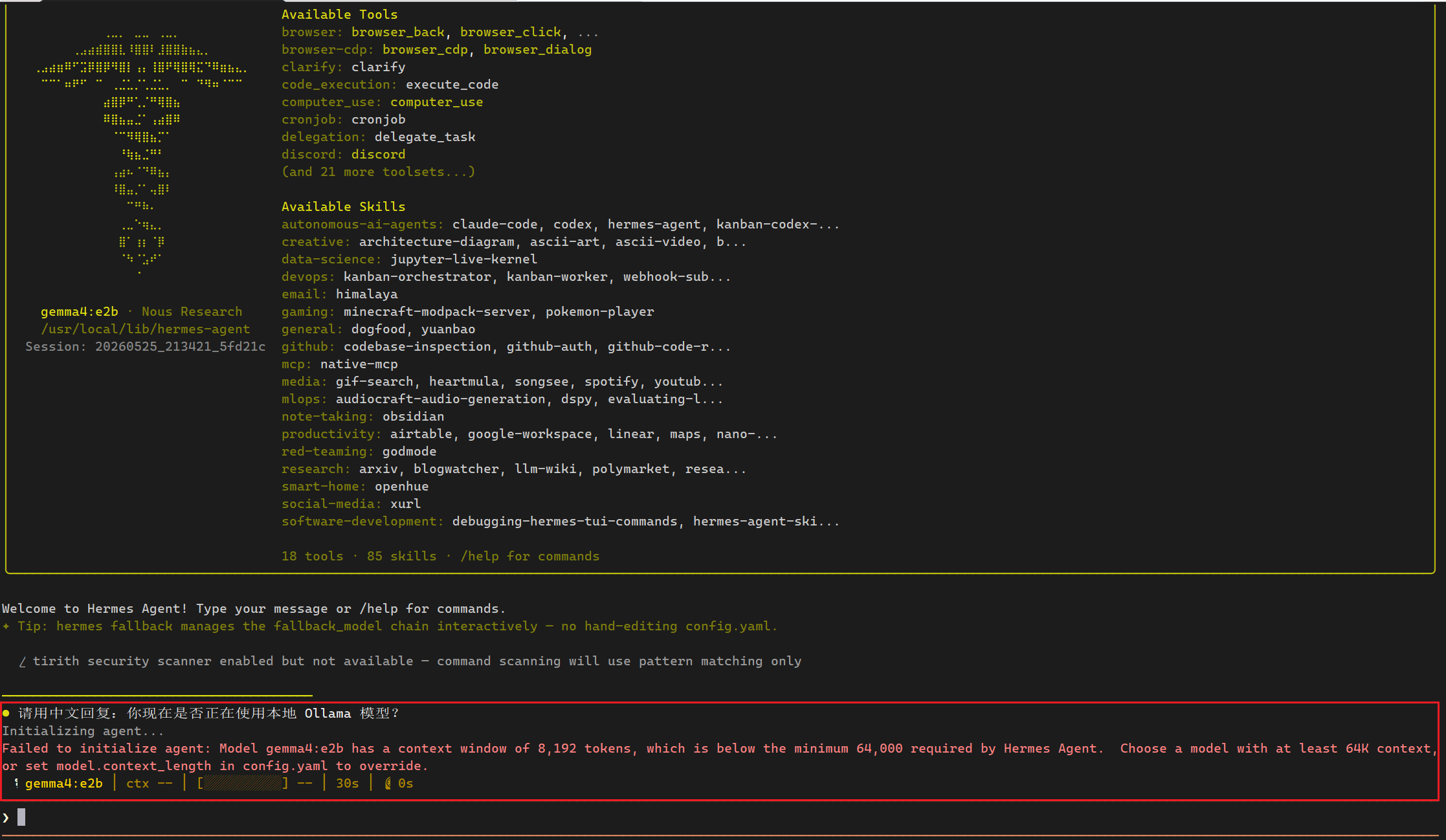
这是 Hermes 的限制:它要求主模型至少 64K context。你刚刚填了 8192,所以 Hermes 拒绝启动。
方案 A:先骗过 Hermes,能跑起来
编辑配置:
vi ~/.hermes/config.yaml
找到 model: 这一段,加上或改成:
model:
default: gemma4:e2b
provider: custom
base_url: http://localhost:11434/v1
api_key: ollama
api_mode: chat_completions
context_length: 64000
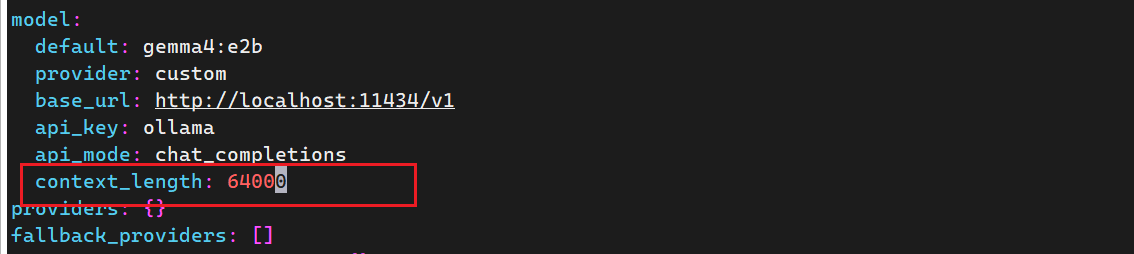
保存后再启动:
hermes
这个能绕过 Hermes 的 64K 检查,但你的机器还是慢。短问题可以用,长任务容易卡。
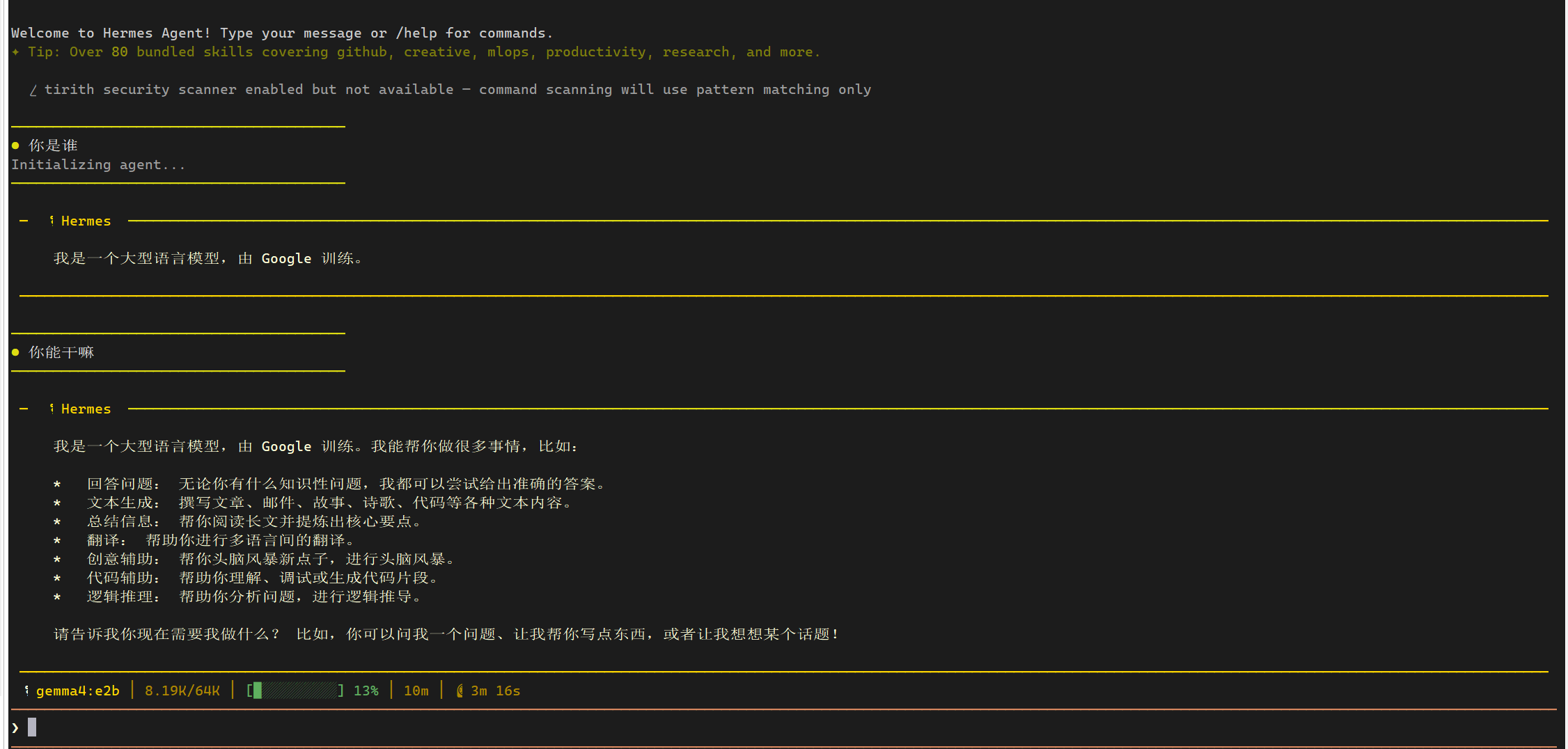
现在我们尝试对话,可以了,但是每次回复都很慢,由于内部需要加载大量的skills,所以ollama跑模型加载初始化都很慢,接着调用第三方的云端模型。
同时另开终端观察 Ollama:
ollama ps
如果看到 gemma4:e4b 正在运行,说明 Hermes 已经接入本地 Ollama。
9.1 可选:使用 API Key 调用云端模型加速
如果本地 gemma4:e2b 初始化和回答都很慢,可以改用云端 API。这样速度通常会快很多,但可能产生费用,具体以 API 服务商计费为准。
下面命令会直接写入 ~/.hermes/config.yaml 和 ~/.hermes/.env。只需要把 YOUR_API_KEY_HERE 改成自己的 key,把 MODEL_NAME_HERE 改成对应平台的模型名。
方式一:OpenAI API
mkdir -p ~/.hermes
cat > ~/.hermes/.env <<'EOF'
OPENAI_API_KEY=YOUR_API_KEY_HERE
EOF
cat > ~/.hermes/config.yaml <<'EOF'
model:
default: MODEL_NAME_HERE
provider: openai
base_url: https://api.openai.com/v1
api_key_env: OPENAI_API_KEY
api_mode: chat_completions
context_length: 128000
EOF
hermes doctor
hermes
方式二:OpenRouter
mkdir -p ~/.hermes
cat > ~/.hermes/.env <<'EOF'
OPENROUTER_API_KEY=YOUR_API_KEY_HERE
EOF
cat > ~/.hermes/config.yaml <<'EOF'
model:
default: MODEL_NAME_HERE
provider: openrouter
base_url: https://openrouter.ai/api/v1
api_key_env: OPENROUTER_API_KEY
api_mode: chat_completions
context_length: 128000
EOF
hermes doctor
hermes
方式三:任意 OpenAI-compatible API
如果服务商提供 OpenAI-compatible endpoint,可以使用这个通用模板:
mkdir -p ~/.hermes
cat > ~/.hermes/.env <<'EOF'
CUSTOM_API_KEY=YOUR_API_KEY_HERE
EOF
cat > ~/.hermes/config.yaml <<'EOF'
model:
default: MODEL_NAME_HERE
provider: custom
base_url: https://YOUR_API_BASE_URL/v1
api_key_env: CUSTOM_API_KEY
api_mode: chat_completions
context_length: 128000
EOF
hermes doctor
hermes
方式四:阿里云百炼 DashScope
阿里云百炼支持 OpenAI-compatible 接口,可以直接作为 Hermes 的 custom provider 使用。
只需要把 YOUR_BAILIAN_API_KEY_HERE 改成自己的百炼 API Key:
mkdir -p ~/.hermes
cp ~/.hermes/config.yaml ~/.hermes/config.yaml.bak.$(date +%Y%m%d%H%M%S) 2>/dev/null || true
cat > ~/.hermes/config.yaml <<'EOF'
model:
default: qwen-plus
provider: custom
base_url: https://dashscope.aliyuncs.com/compatible-mode/v1
api_key: YOUR_BAILIAN_API_KEY_HERE
api_mode: chat_completions
context_length: 128000
EOF
hermes doctor
hermes
常用模型名:
qwen-turbo
qwen-plus
qwen-max
推荐先用 qwen-plus。如果想更省,可以换成 qwen-turbo;如果想更强,可以换成 qwen-max。
如果要切回本地 Ollama,把配置改回:
mkdir -p ~/.hermes
cat > ~/.hermes/config.yaml <<'EOF'
model:
default: gemma4:e2b
provider: custom
base_url: http://localhost:11434/v1
api_key: ollama
api_mode: chat_completions
context_length: 64000
EOF
hermes doctor
hermes
10. 确保完全不花钱
配置 Hermes 时不要选择:
- OpenAI
- Anthropic
- OpenRouter
- Nous Portal
- Ollama Cloud
- Gemini API
- Groq
- Together AI
- Fireworks AI
只使用:
http://localhost:11434/v1
本地模型:
gemma4:e4b
确认没有设置云 API key:
env | grep -Ei 'OPENAI|ANTHROPIC|OPENROUTER|GEMINI|GOOGLE|NOUS|TOGETHER|FIREWORKS'
如果输出了相关 key,可以临时取消:
unset OPENAI_API_KEY
unset ANTHROPIC_API_KEY
unset OPENROUTER_API_KEY
unset GEMINI_API_KEY
unset GOOGLE_API_KEY
11. 性能优化建议
当前 4 核 6GB + swap 的重点是让系统尽量稳定。
建议关闭不必要的桌面环境和后台程序。如果使用 RHEL Server 无桌面版,会比带 GUI 的系统更适合。
查看内存:
free -h
查看 swap 使用:
swapon --show
查看 CPU 和内存占用:
top
如果响应非常慢,可以降低 context:
推荐直接覆盖 systemd drop-in 配置,不需要进入编辑器:
sudo mkdir -p /etc/systemd/system/ollama.service.d
sudo tee /etc/systemd/system/ollama.service.d/override.conf >/dev/null <<'EOF'
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=8192"
EOF
sudo systemctl daemon-reload
sudo systemctl restart ollama
systemctl show ollama -p Environment
最后一行应该看到:
Environment=OLLAMA_CONTEXT_LENGTH=8192
如果仍然太慢,可以继续降到 4096:
sudo tee /etc/systemd/system/ollama.service.d/override.conf >/dev/null <<'EOF'
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=4096"
EOF
sudo systemctl daemon-reload
sudo systemctl restart ollama
systemctl show ollama -p Environment
12. 低内存替代方案
如果 gemma4:e4b 实际不可用,建议先换更小模型验证完整流程:
ollama pull gemma4:e2b
ollama run gemma4:e2b
Hermes 中把模型名改为:
gemma4:e2b
如果 gemma4:e2b 也慢,可以使用更小模型先测试 Hermes 接入链路:
ollama pull gemma3:1b
ollama run gemma3:1b
Hermes 模型名改为:
gemma3:1b
13. 常见问题
13.1 curl localhost:11434 失败
检查服务:
systemctl status ollama --no-pager
重启:
sudo systemctl restart ollama
查看日志:
journalctl -u ollama -n 100 --no-pager
13.2 ollama pull 很慢
确认虚拟机网络正常:
curl -I https://ollama.com
如果 DNS 有问题,检查虚拟机网络模式是否为 NAT,以及 RHEL 是否能访问外网。
13.3 模型运行时系统卡住
这是 6GB 内存 + swap 下的常见现象。
可以尝试:
sudo systemctl restart ollama
降低 context:
sudo systemctl edit ollama
把 OLLAMA_CONTEXT_LENGTH 改小,例如:
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=16384"
然后:
sudo systemctl daemon-reload
sudo systemctl restart ollama
13.4 Hermes 不走 Ollama,提示云模型错误
重新配置:
hermes model
确保 base URL 是:
http://localhost:11434/v1
模型名是:
gemma4:e4b
不要选择 OpenAI、Anthropic、OpenRouter 等云服务。
13.5 Hermes 要求 API key
本地 Ollama 不需要真实 key。如果界面强制要求,填:
ollama
13.6 提示模型不存在
确认模型已拉取:
ollama list
如果没有:
ollama pull gemma4:e4b
14. 完整命令速查
以下命令适合全新 RHEL 10.1 环境按顺序执行。
sudo dnf update -y
sudo dnf install -y curl git tar gzip xz zstd ca-certificates findutils which procps-ng
sudo fallocate -l 24G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
echo 'vm.swappiness=10' | sudo tee /etc/sysctl.d/99-local-swappiness.conf
sudo sysctl --system
cd /root
# 先在 Windows 下载 https://ollama.com/download/ollama-linux-amd64.tar.zst
# 再把文件传到 RHEL 的 /root/ollama-linux-amd64.tar.zst
ls -lh ollama-linux-amd64.tar.zst
sudo tar -C /usr/local -I zstd -xf ollama-linux-amd64.tar.zst
find /usr/local -name ollama -type f
sudo ln -sf /usr/local/bin/ollama /usr/bin/ollama
ollama -v
sudo tee /etc/systemd/system/ollama.service >/dev/null <<'EOF'
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
Environment="PATH=/usr/local/bin:/usr/bin:/bin"
Environment="OLLAMA_HOST=127.0.0.1:11434"
[Install]
WantedBy=default.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable --now ollama
sudo systemctl edit ollama
在 editor 中填入:
[Service]
Environment="OLLAMA_CONTEXT_LENGTH=64000"
然后继续:
sudo systemctl daemon-reload
sudo systemctl restart ollama
ollama pull gemma4:e4b
ollama run gemma4:e4b
cd /root
# 先在 Windows 下载 https://github.com/NousResearch/hermes-agent/archive/refs/heads/main.tar.gz
# 再把文件传到 RHEL 的 /root/hermes-agent-main.tar.gz
rm -rf /usr/local/lib/hermes-agent
tar -xzf hermes-agent-main.tar.gz -C /usr/local/lib
mv /usr/local/lib/hermes-agent-main /usr/local/lib/hermes-agent
cd /usr/local/lib/hermes-agent
/root/.local/bin/uv sync --extra all --locked
cat >/usr/local/bin/hermes <<'EOF'
#!/usr/bin/env bash
unset PYTHONPATH PYTHONHOME
exec /usr/local/lib/hermes-agent/.venv/bin/hermes "$@"
EOF
chmod +x /usr/local/bin/hermes
hermes doctor
hermes setup
hermes model
hermes
Hermes 模型配置填写:
Base URL: http://localhost:11434/v1
API Key: ollama
Model: gemma4:e4b
Context length: 64000
15. 最终验证
执行:
ollama ps
再执行:
hermes
在 Hermes 中输入:
请用中文回答,并说明你当前是否通过本地 Ollama 模型运行。
如果 Hermes 正常回复,并且 ollama ps 里显示 gemma4:e4b 正在运行,则部署完成。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)