DeepSeek-R2 炸裂开源:131B MoE 架构如何吊打国际模型?国产大模型三强横评

2026年5月24日,DeepSeek 正式开源 R2 系列模型,包含 R2-131B(1310亿参数,MoE架构)和 R2-Lite(13B)。48小时 HuggingFace 下载量破 50 万,MMLU 达 92.1%。这不仅是国产开源大模型的历史性时刻,更是一场技术实力的全面展示。
一、DeepSeek-R2 到底强在哪里?
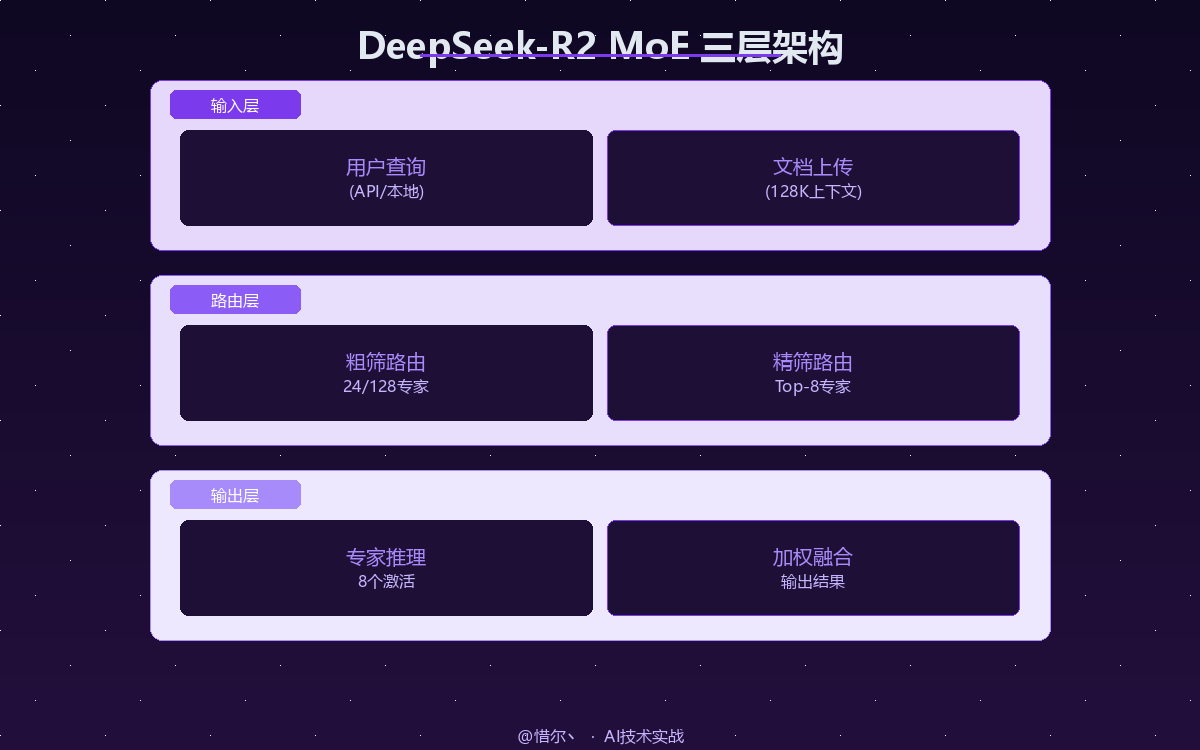
1.1 核心参数一览
DeepSeek-R2 采用了混合专家(MoE)架构,总参数量 131B,但每次推理仅激活约 22B 参数——这就是它既强大又高效的秘密。
| 参数项 | DeepSeek-R2 | DeepSeek-R1 | 提升幅度 |
|---|---|---|---|
| 总参数量 | 131B (MoE) | 671B (MoE) | -80%(更轻量) |
| 激活参数 | ~22B | ~37B | -40% |
| 上下文窗口 | 128K tokens | 128K tokens | 持平 |
| MMLU | 92.1% | 90.5% | +1.6% |
| HumanEval | 89.3% | 85.2% | +4.1% |
| 推理速度 | 3x R1 | 1x(基准) | +200% |
| API价格 | 1.2/1M tokens | 2.0/1M tokens | -40% |
1.2 架构创新:深度优化的 MoE
R2 相比 R1 最大的改进在于专家路由机制。R1 的专家路由比较"蛮力"——所有 token 都要经过几乎所有专家的打分。R2 引入了分层路由。
# 简化的 MoE 路由
class DeepSeekR2_MoE:
def __init__(self):
self.experts = [Expert() for _ in range(128)]
self.router = HierarchicalRouter(top_k=8)
def forward(self, token_embedding):
candidate_ids = self.router.coarse_filter(token_embedding, top_n=24)
selected_ids = self.router.fine_filter(token_embedding, candidate_ids, top_k=8)
outputs = [self.experts[i](token_embedding) for i in selected_ids]
return weighted_sum(outputs)
这种两阶段路由让每次推理的计算量降低了约 40%,同时保持了模型质量。
二、国产大模型三强横向对比
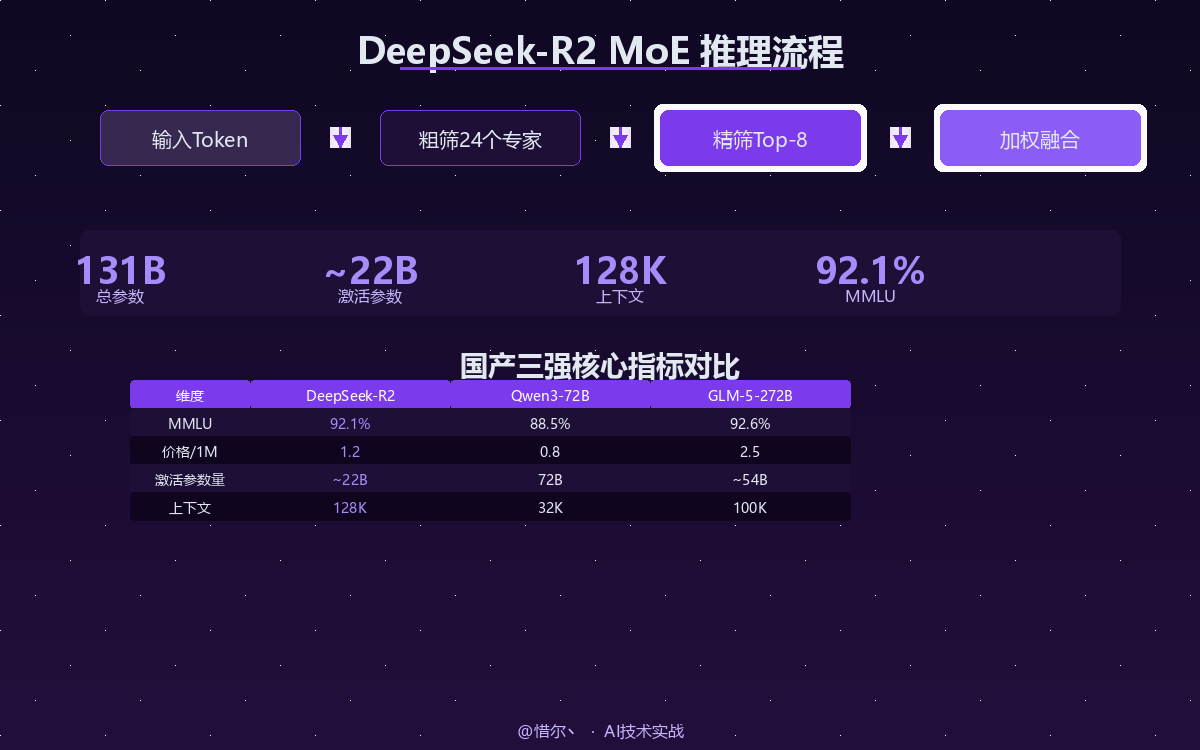
2026年5月的这一周,国产大模型迎来了"神仙打架"的局面。除了 DeepSeek-R2,还有通义千问 Qwen3-72B 和智谱 GLM-5-272B 同期发布。
2.1 三款模型硬核对比
| 对比维度 | DeepSeek-R2 | Qwen3-72B-Instruct | GLM-5-272B |
|---|---|---|---|
| 厂商 | DeepSeek | 阿里云 | 智谱AI |
| 参数量 | 131B (MoE) | 72B (Dense) | 272B (MoE) |
| 激活参数 | ~22B | 72B | ~54B |
| 开源协议 | 开源 | MIT | 开源 |
| MMLU | 92.1% | 88.5% | 92.6% |
| C-Eval | 91.3% | 87.2% | 92.6% |
| 上下文 | 128K | 32K | 100K |
| API价格(1M tokens) | 1.2 | 0.8 | 2.5 |
| 工具调用 | 支持 | 支持 | 支持 |
| 训练数据 | 未公开 | 15T tokens | 未公开 |
2.2 场景化推荐
如果你是个人开发者/小团队:
首选 Qwen3-72B——MIT开源协议最宽松,72B Dense架构部署简单,2张A100就能跑,API价格最低(0.8/1M)
如果你想追求极致性能:
DeepSeek-R2 性价比最高,推理速度快,128K上下文处理长文档能力极强
import requests
response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers={"Authorization": "Bearer YOUR_KEY"},
json={
"model": "deepseek-r2",
"messages": [{"role": "user", "content": "分析这份PDF报告的核心观点"}],
"max_tokens": 4096
}
)
如果你要冲排名/做学术研究:
GLM-5-272B 基准分数最高,但硬件需求也是最大的
三、实战案例:用 DeepSeek-R2 搭建代码审查助手
3.1 准备工作
pip install openai requests
export DEEPSEEK_API_KEY="sk-your-key-here"
3.2 核心代码
import os, json
from openai import OpenAI
client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com/v1")
def code_review(code_snippet, language="python"):
prompt = f"请审查以下 {language} 代码,以JSON格式输出问题和建议:" + code_snippet
response = client.chat.completions.create(
model="deepseek-r2",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
sample_code = """
def calculate(data):
result = []
for i in range(len(data)):
result.append(data[i] * 2)
return result
"""
review = code_review(sample_code)
print(f"质量评分: {review.get('score', 'N/A')}/10")
3.3 优化后的代码
DeepSeek-R2 给出了建议:用列表推导式替代循环、添加类型注解。优化后仅需一行:
def calculate(data: list) -> list:
return [x * 2 for x in data]
四、价格战全面打响:API 成本对比
| 模型 | 输入价格(1M tokens) | 输出价格(1M tokens) | 日均100万tokens成本 |
|---|---|---|---|
| DeepSeek-R2 | 1.2 | 1.2 | 2.4 |
| Qwen3-72B | 0.8 | 0.8 | 1.6 |
| GLM-5-272B | 2.5 | 2.5 | 5.0 |
| GPT-4o | 15.0 | 60.0 | 75.0 |
| Claude Sonnet 4 | 21.0 | 84.0 | 105.0 |
结论:国产大模型的 API 成本仅为国际模型的 1/10 到 1/50!
五、避坑指南
| 常见问题 | 原因 | 解决方案 |
|---|---|---|
| 部署 OOM | 显存不足 | 使用量化版本,或改用 API |
| 推理速度慢 | 未用推理框架 | 用 vLLM + 连续批处理,吞吐量提升 5-10x |
| 中文输出不完整 | max_tokens 太小 | 设置为 4096 或更高 |
| API 返回乱码 | 编码问题 | 确保 header 包含 utf-8 |
六、总结
2026 年 5 月这一周,国产大模型迎来了前所未有的三强争霸。DeepSeek-R2 的 131B MoE 架构、通义千问 Qwen3-72B 的极致性价比、智谱 GLM-5-272B 的基准登顶,共同标志着中国 AI 进入了自主开源、价格亲民、性能一流的新时代。
对于开发者来说,现在是最好的入局时机——开源模型免费部署,API 价格持续下降,生态工具日渐成熟。
#DeepSeek #大模型 #AI开源 #国产大模型 #MoE #Qwen3 #GLM5

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)