LangChain vs LangGraph vs Deep Agents技术对比详解
一、核心结论:三者不是竞品,而是同一技术栈的三个分层
很多人把 LangChain、LangGraph、Deep Agents 当作三个互相竞争的方案,这是误解。在 LangChain 官方的概念文档《Frameworks, runtimes, and harnesses》中,官方明确把它们定位为同一智能体(Agent)开发栈的三个不同层级:
| 层级 | 项目 | 官方术语 | 核心价值 |
|---|---|---|---|
| 上层 | Deep Agents | Agent Harness(智能体外壳/装备) | 预置工具、提示词、子智能体,开箱即用 |
| 中层 | LangChain | Agent Framework(智能体框架) | 抽象与集成(模型、工具、Agent 循环、中间件) |
| 底层 | LangGraph | Agent Runtime(智能体运行时) | 持久化执行、流式、人机协同、状态持久化 |
它们的依赖关系是自下而上叠加的,每一层都构建在下一层之上:
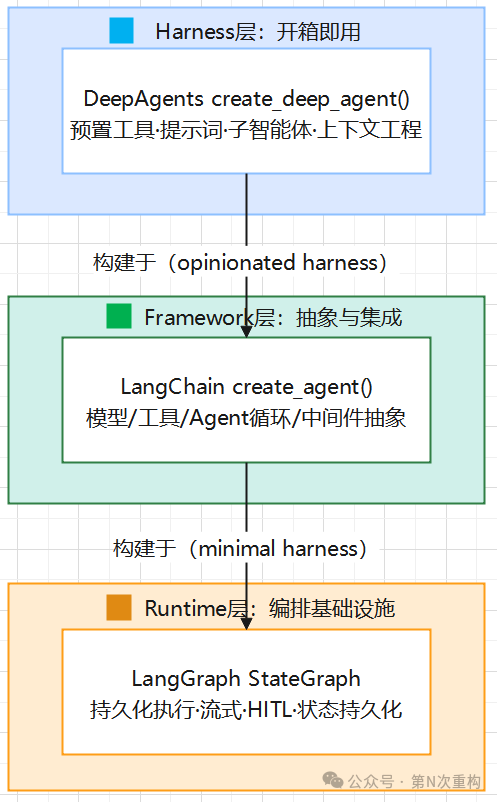
官方在 Deep Agents 仓库中给出了一句精炼的概括:LangGraph 是图运行时;LangChain 的 create_agent 是构建在其上的一个最小化 Agent 外壳;Deep Agents 则是构建在 create_agent 之上、更有主见(opinionated)的外壳——使用相同的构建块,但把文件系统、子智能体、上下文管理、技能(Skills)等能力打包了进去。
理解这个分层模型,是后续所有技术对比的基础。
二、LangGraph:底层编排运行时
2.1 定位
LangGraph 是一个低层级的编排框架与运行时,用于构建、管理和部署长时运行(long-running)、有状态(stateful)的智能体。官方强调它"非常低层级,完全聚焦于智能体的编排(orchestration)"。
LangGraph 由 LangChain Inc 开发,但可以脱离 LangChain 独立使用。官方文档列出了 Klarna、Uber、J.P. Morgan 等公司在生产环境使用 LangGraph。
2.2 技术架构
LangGraph 的设计灵感来源在官方文档中有明确致谢:
-
计算模型受 Google Pregel 与 Apache Beam 启发;
-
公开接口(API 风格)借鉴了 NetworkX。
其核心抽象是有状态图(StateGraph):开发者把智能体逻辑显式建模为节点(Node)和边(Edge),节点是计算单元,边定义控制流。执行模型采用 Pregel / BSP(Bulk Synchronous Parallel,整体同步并行)思路,从而获得确定性的并发行为。
一个最小示例(来自官方文档):
from langgraph.graph import StateGraph, MessagesState, START, END
def mock_llm(state: MessagesState):
return {"messages": [{"role": "ai", "content": "hello world"}]}
# 构建工作流
graph = StateGraph(MessagesState)
# 添加节点
graph.add_node(mock_llm)
# 添加边
graph.add_edge(START, "mock_llm")
graph.add_edge("mock_llm", END)
# 编译工作流
graph = graph.compile()
graph.invoke({"messages": [{"role": "user", "content": "hi!"}]})把一个典型的"模型 + 工具循环"用 LangGraph 的图来表达,结构如下——开发者显式地定义每个节点和每条边(包括基于模型输出的条件边):
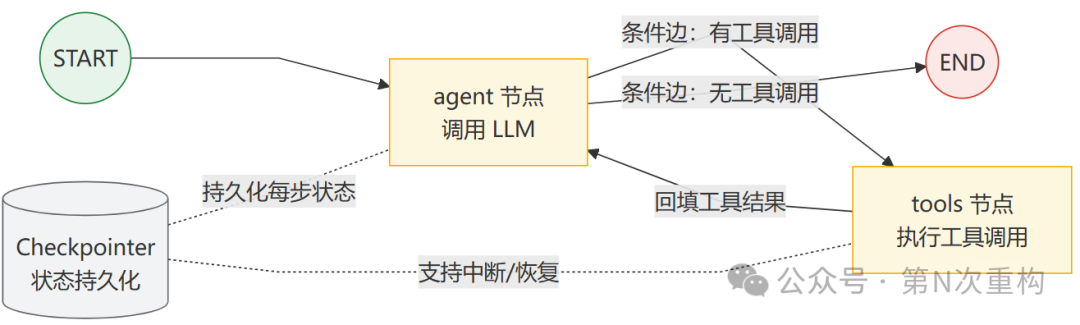
关键点:在 LangGraph 里,控制流(哪个节点之后走哪条边)是显式建模的——这正是它"低层级、强控制"的体现。Checkpointer 在每一步持久化状态,是持久化执行与人机协同(在任意节点中断后恢复)的基础。
2.3 核心能力
官方文档列出 LangGraph 提供的底层基础设施能力:
-
持久化执行(Durable execution):智能体在故障中存活,可长时间运行,并从中断处恢复继续。
-
流式(Streaming):支持工作流与响应的流式输出。
-
人机协同(Human-in-the-loop):通过 interrupt 机制,可在任意节点检查并修改智能体状态。
-
完整记忆体系:短期工作记忆 + 跨会话的长期记忆。
-
生产级部署:为有状态、长时运行工作流设计的可扩展部署基础设施。
需要注意的一点:LangGraph 本身不抽象提示词,也不抽象智能体架构。它只负责"怎么跑",不负责"跑什么"。提示词工程、Agent 形态等都需要开发者自己定义。
2.4 何时选择 LangGraph
官方给出的适用场景:
-
需要对智能体编排进行细粒度、低层级的控制;
-
需要为长时运行、有状态的智能体提供持久化执行;
-
构建混合确定性步骤与智能体步骤(agentic steps)的复杂工作流;
-
需要生产级的智能体部署基础设施。
同类项目(同为 Agent Runtime):Temporal、Inngest 等持久化执行引擎。
三、LangChain:智能体框架
3.1 定位
LangChain 是一个智能体框架,核心价值在于提供抽象(Abstractions)与集成(Integrations)。它构建在 LangGraph 之上,但官方明确表示:使用 LangChain 不需要先懂 LangGraph。
它的目标是"快速上手"——官方宣称可以用不到 10 行代码构建一个智能体。
3.2 LangChain 1.0:中间件架构
LangChain 1.0 于 2025 年 10 月发布,是一次面向生产的重大重构。其最关键的技术变化是引入了 中间件(Middleware)架构。
为什么需要中间件? 官方在博客中坦承:LangChain 的智能体抽象存在近三年,市面上有上百个采用相同核心抽象的框架,它们都有同样的缺点——在需要时无法给开发者足够的上下文工程控制权,导致开发者在任何非平凡的用例中都"毕业"(graduate off)离开这套抽象。中间件就是 1.0 对这个问题的回答。
核心 API:create_agent
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
deepseek_llm = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)
@tool
def search_weather(location: str) -> str:
"""获取指定位置的天气"""
return f" {location}的天气是晴朗的。"
# 创建Agent
agent = create_agent(
model=deepseek_llm,
tools=[search_weather],
system_prompt="你是一个AI智能助手,你可以查询城市的天气情况。",
)
# 调用Agent
resp = agent.invoke({"messages": [{"role": "user", "content": "查询西安的天气"}]})
print(resp)create_agent 是一个工厂函数,它从模型、工具、中间件构造出一个可执行的 Agent 图——其底层正是 LangGraph 的 StateGraph。核心 Agent 循环仍然由一个 model 节点和一个 tool 节点构成。
中间件机制
中间件借鉴 Web 服务器中间件的成熟模式,在 Agent 执行的关键阶段提供拦截钩子(hook),允许在不破坏核心循环的前提下注入自定义逻辑。官方与社区文档提到的拦截点包括:在 Agent 执行前后、在模型调用前后、以及包裹(wrap)模型调用与工具调用等阶段。
下图展示了 create_agent 的核心循环(model 节点 ↔ tool 节点)以及中间件可以介入的拦截点。中间件像"洋葱圈"一样包裹核心循环——请求进入时层层穿过,响应返回时再层层穿出:
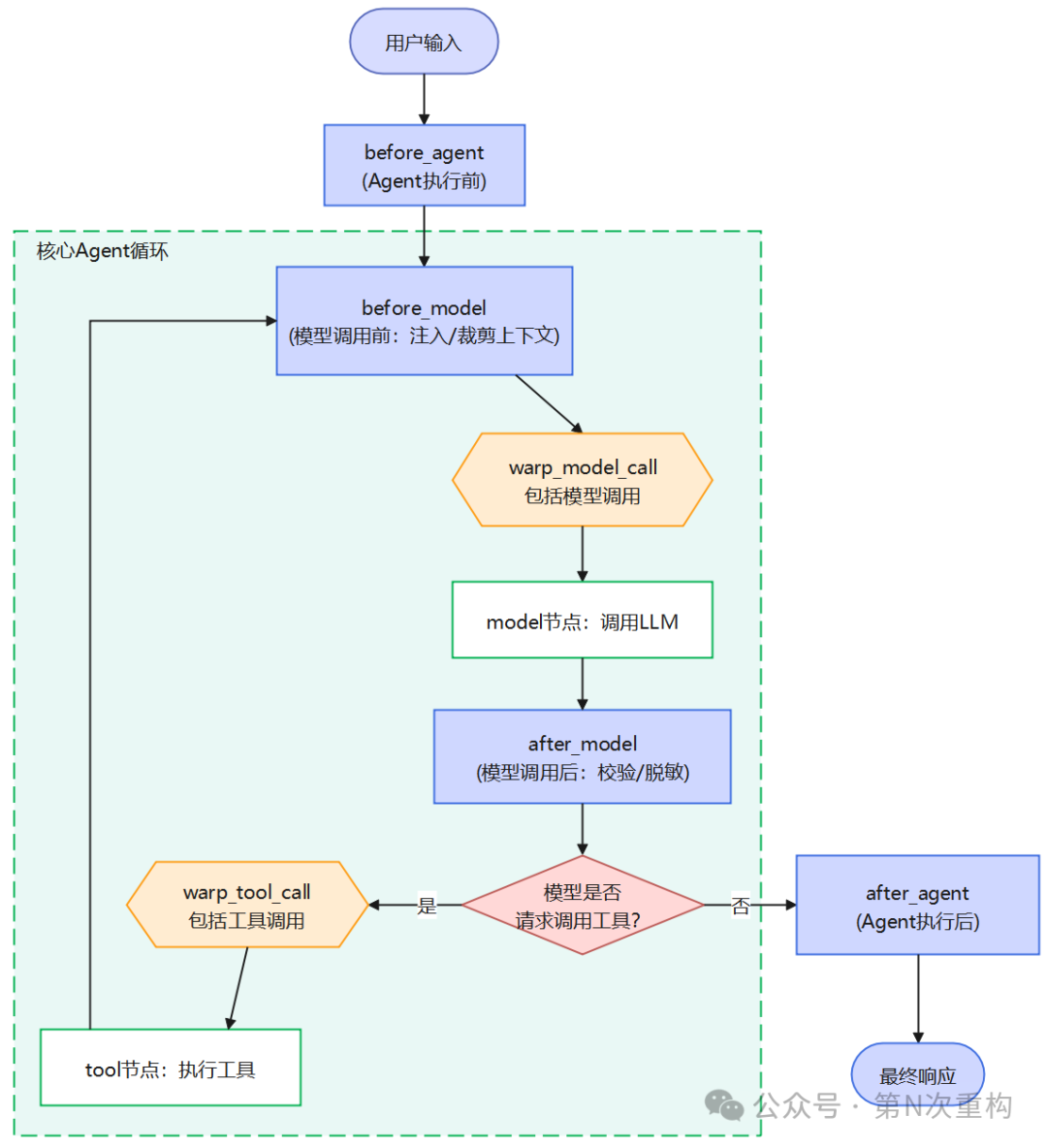
中间件的架构收益:
-
关注点分离:每个中间件专注一件事(如安全、成本控制、摘要);
-
可组合与可复用:像积木一样按任意顺序堆叠,跨项目复用;
-
可独立测试:每个组件可单独验证。
官方与生态提供的预置中间件示例包括:PIIMiddleware(敏感信息检测/脱敏/拦截)、HumanInTheLoopMiddleware(人工审批工作流)、上下文摘要中间件等。例如 PII 中间件的用法:
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.agents.middleware import PIIMiddleware
deepseek_llm = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
)
agent = create_agent(
model=deepseek_llm,
tools=[],
middleware=[
PIIMiddleware("api_key", detector=r"sk-[a-zA-Z0-9]{32}", strategy="block"),
],
)
3.3 其他 1.0 关键变化
-
标准内容块(
content_blocks):消息内容跨不同模型供应商(OpenAI、Anthropic、Google 等)统一标准化,并提供完整类型化视图。 -
结构化输出:结构化输出被纳入主循环,支持
ToolStrategy与ProviderStrategy等策略。 -
命名空间精简:部分旧组件(如旧版检索器)迁移到
langchain-classic/langchain-legacy包。 -
运行环境要求:升级后需
langchain>=1.0,Python 3.10+。 -
后续迭代:LangChain 1.1.0 于 2025 年 11 月 24 日发布(距 1.0 仅约一个月),引入了模型的
.profile属性(Model Profiles,可编程查询模型能力)等改进。
3.4 何时选择 LangChain
官方给出的适用场景:
-
想快速构建智能体与自主应用;
-
需要模型、工具、Agent 循环的标准抽象;
-
想要一个易上手但仍保留灵活性的框架;
-
构建不涉及复杂编排需求的、相对直接的智能体应用。
同类项目(同为 Agent Framework):Vercel AI SDK、CrewAI、OpenAI Agents SDK、Google ADK、LlamaIndex 等。
四、Deep Agents:智能体 Harness
4.1 定位
Deep Agents(PyPI 包名 deepagents)是一个智能体 harness——官方定义为"有主见、开箱即用(batteries-included)的框架,内置工具与能力,用于构建复杂、长时运行的智能体"。
它是构建在 LangChain 核心构建块之上的独立库,并使用 LangGraph 运行时来获得持久化执行、流式、人机协同等能力。官方明确说明其设计受 Claude Code 启发——目标是提炼出"什么让 Claude Code 成为通用型智能体",并把这一点进一步推广。
deepagents 仓库包含三部分:
-
Deep Agents SDK:构建可处理任意任务的智能体的核心包;
-
Deep Agents Code:构建在 SDK 之上的终端编码智能体(类似 Claude Code / Cursor 的终端形态);
-
ACP 集成:Agent Client Protocol 连接器,用于在 Zed 等代码编辑器中使用 deep agents。
创建一个 Deep Agent(来自官方文档):
from deepagents import create_deep_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
agent.invoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]})
4.2 核心能力(Harness Capabilities)
Deep Agents 的本质是一组打包好的能力。以下技术细节均来自官方《Harness capabilities》文档。
下图把 Deep Agent 的组成拆解开——它本身是 LangChain create_agent 之上的一层,再叠加规划、文件系统、子智能体、上下文管理、技能、HITL 等能力模块,而这些能力又共同依赖底层的可插拔后端:
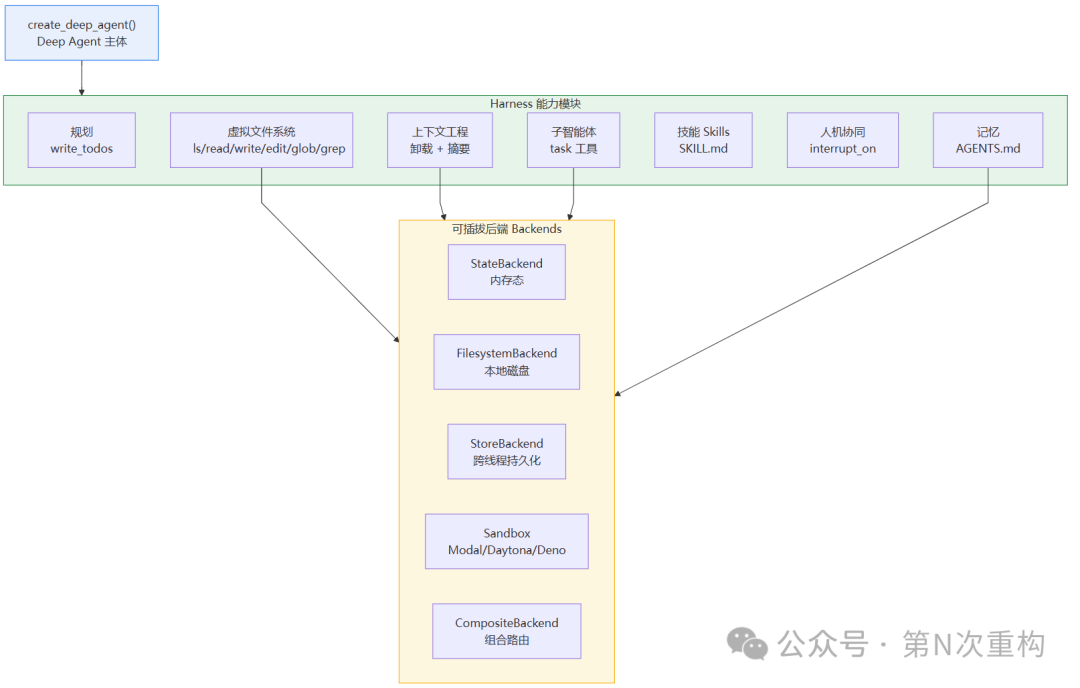
(1) 规划能力
内置 write_todos 工具,让智能体维护一份结构化任务清单:任务带状态(pending / in_progress / completed),持久化在 Agent 状态中,帮助智能体组织复杂的多步工作。
(2) 虚拟文件系统
提供一套可配置的虚拟文件系统工具:
| 工具 | 作用 |
|---|---|
ls |
列目录并带元数据(大小、修改时间) |
read_file |
读文件(带行号,支持 offset/limit 读大文件,也支持读图片返回多模态内容块) |
write_file |
创建新文件 |
edit_file |
精确字符串替换(支持全局替换模式) |
glob |
按模式查找文件(如 **/*.py) |
grep |
搜索文件内容(多种输出模式) |
execute |
执行 shell 命令(仅在沙箱后端下可用) |
(3) 可插拔文件系统后端(Backends)
虚拟文件系统由可替换的后端驱动,官方提供多种选择:
-
StateBackend(内存态,仅在单线程内持久); -
本地磁盘后端(
FilesystemBackend); -
StoreBackend(基于 LangGraph Store,支持跨线程持久化); -
沙箱后端(Modal、Daytona、Deno,用于隔离的代码执行);
-
CompositeBackend(组合多个后端做路由); -
也可实现自定义后端。
(4) 子智能体(Subagents)
主智能体拥有一个 task 工具,可派生临时子智能体。子智能体特性:
-
上下文隔离:子智能体的工作不会污染主智能体的上下文;
-
并行执行:多个子智能体可并发运行;
-
专门化:子智能体可配置不同的工具/中间件;
-
token 高效:大量子任务上下文被压缩为一个最终结果返回;
-
无状态:子智能体执行完返回单一报告,不能多轮往返。
默认提供一个 general-purpose 子智能体;也可定义专门子智能体(如 code-reviewer、web-researcher、test-runner)。
(5) 上下文工程(Context Engineering)
这是 Deep Agents 区别于普通 ReAct 智能体的关键。它采用"上下文压缩"模式,内置两种机制:
-
大工具输入/输出的卸载(Offloading):当工具调用输入或结果超过 20,000 token(可通过
tool_token_limit_before_evict配置)时,把内容卸载到文件系统后端,在对话历史中只保留一个文件路径指针与前 10 行预览;当会话上下文超过模型可用窗口的 85% 时,会截断较旧的工具调用并替换为指针。 -
摘要(Summarization):当上下文逼近模型上下文窗口上限(如
max_input_tokens的 85%)且已无可卸载内容时,触发对话历史摘要——LLM 生成包含会话意图、已产出物、后续步骤的结构化摘要替换工作记忆中的完整历史,同时把完整原始对话写入文件系统作为权威记录。默认保留 10% token 作为近期上下文;若模型 profile 不可用,则回退为 170,000 token 触发阈值 / 保留 6 条消息。
这两种机制如何协同,可以用下面的决策流程来理解——每当上下文增长时,Deep Agent 优先选择"代价更小"的卸载,卸载无可卸载内容时才动用摘要:
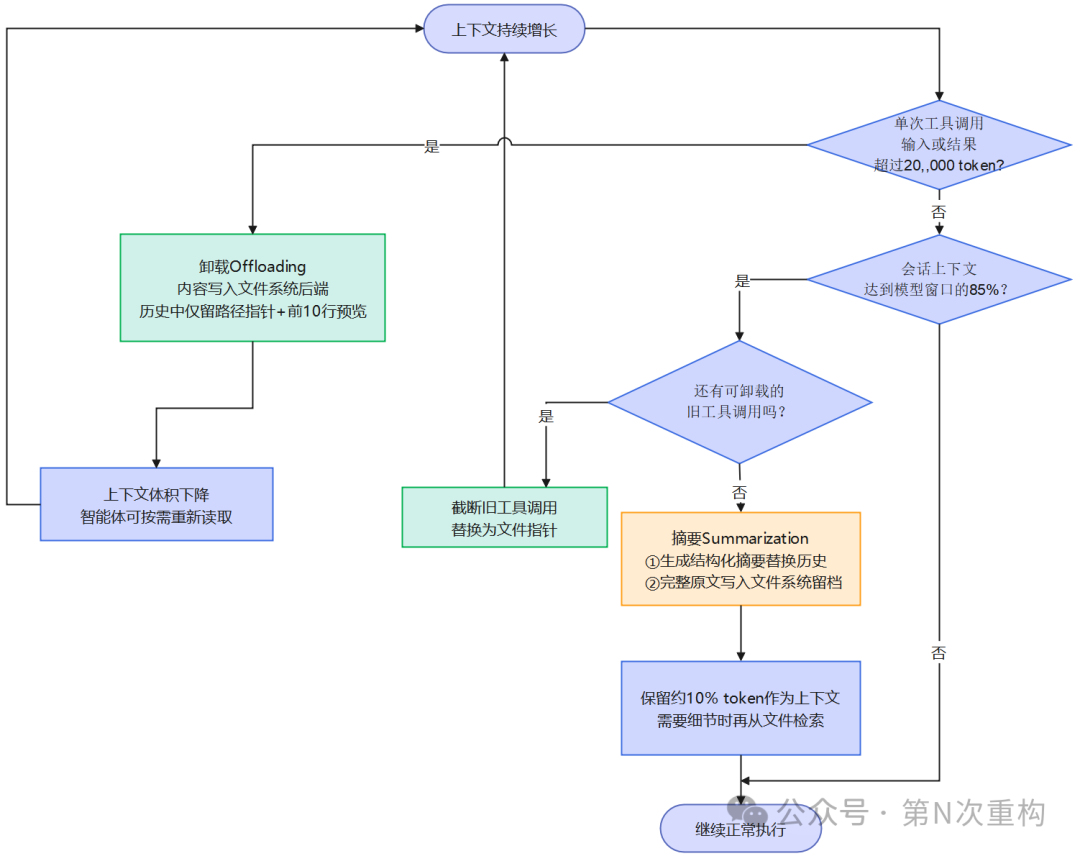
(6) 长期记忆(Long-term Memory)
默认文件系统的工作记忆仅在单线程内有效。要实现跨线程/跨会话持久化,需使用 CompositeBackend 把特定路径(通常是 /memories/)路由到 LangGraph Store。存到长期记忆路径的文件(如 /memories/preferences.txt)可在智能体重启后、任意会话线程中访问。
(7) 代码执行(Code Execution)
使用沙箱后端时,harness 暴露 execute 工具,让智能体在隔离环境中运行 shell 命令(安装依赖、跑脚本、git 操作等)。没有沙箱后端时智能体只有文件系统工具,不能执行命令。此外还可加 Interpreter 在内存运行时中执行 JavaScript(QuickJS),用于工具组合与结构化数据转换。
(8) 人机协同(Human-in-the-loop)
通过 interrupt_on 参数选择性开启,可在指定工具调用前暂停等待人工审批或修改。例如 interrupt_on={"edit_file": True} 会在每次编辑前暂停。底层依赖 LangGraph 的 interrupt 能力。
(9) 技能(Skills)与记忆文件
-
Skills:遵循 Agent Skills 标准(agentskills.io),每个技能是一个含
SKILL.md的目录。采用渐进式披露(progressive disclosure)——启动时只读 frontmatter,需要时才载入完整内容,节省 token。 -
Memory 文件:使用
AGENTS.md文件(agents.md 标准)提供持久上下文,与 Skills 不同,记忆文件总是被加载。
(10) 智能默认值(Smart Defaults)
Deep Agents 附带有主见的系统提示词,教模型如何有效使用工具——先规划后行动、验证工作、管理上下文。最终系统提示词由约 10 个部分拼接而成(自定义提示词、基础 Agent 提示词、todo 提示词、记忆提示词、技能提示词、文件系统提示词、子智能体提示词、自定义中间件提示词、HITL 提示词、本地上下文提示词)。
4.3 安全模型
Deep Agents 遵循"信任 LLM"(trust the LLM)模型——智能体能做其工具允许的任何事。官方明确建议:边界应在工具/沙箱层强制执行,而不是指望模型自我约束。
4.4 何时选择 Deep Agents
官方给出的适用场景:
-
构建需要长时间运行的智能体;
-
构建需要处理复杂、多步、非确定性任务的智能体;
-
想直接使用预置工具(文件系统操作、bash 执行、自动化上下文工程);
-
想直接使用预置的提示词与子智能体。
同类项目(同为 Agent Harness):Anthropic 的 Claude Agent SDK、Manus,以及其他编码 CLI。
五、横向技术对比
5.1 分层与定位
| 维度 | LangChain | LangGraph | Deep Agents |
|---|---|---|---|
| 官方分类 | Agent Framework(框架) | Agent Runtime(运行时) | Agent Harness(外壳) |
| 在栈中的位置 | 中层 | 底层 | 上层 |
| 核心价值 | 抽象 + 集成 | 持久化执行、流式、HITL、持久化 | 预置工具、提示词、子智能体 |
| 抽象层级 | 中等(易上手 + 保留灵活性) | 最低(直接控制编排) | 最高(开箱即用、有主见) |
| 主入口 API | create_agent |
StateGraph |
create_deep_agent |
| 是否抽象提示词/架构 | 部分(提供 Agent 循环抽象) | 否(只管编排,不管提示词) | 是(自带完整系统提示词体系) |
5.2 核心能力的实现方式对比
官方《Feature comparison》表格指出,三者能完成相似任务,但集成的层级不同:
| 能力 | LangChain | LangGraph | Deep Agents |
|---|---|---|---|
| 短期记忆 | Short-term memory | Short-term memory | StateBackend |
| 长期记忆 | Long-term memory | Long-term memory | Long-term memory(基于 Store) |
| 技能(Skills) | Multi-agent skills | —(无原生概念) | Skills(SKILL.md 标准) |
| 子智能体 | Multi-agent subagents | Subgraphs(子图) | Subagents(task 工具) |
| 人机协同 | HITL 中间件 | Interrupts | interrupt_on 参数 |
| 流式 | Agent Streaming | Streaming | Streaming |
可以看出一个规律:越往上层,能力越"产品化"。同样是子智能体,LangGraph 给你的是底层"子图"原语,要自己拼装;LangChain 给你 multi-agent 抽象;Deep Agents 直接给你一个 task 工具和默认的 general-purpose 子智能体。
5.3 上下文工程能力对比
上下文工程是长时智能体的核心瓶颈,三者的支持程度差异最大:
-
LangGraph:提供状态、检查点(checkpointing)等原语,但上下文压缩策略需自己实现。
-
LangChain:通过中间件提供上下文工程的"控制点",可接入摘要等预置中间件,但策略仍需开发者组装。
-
Deep Agents:把上下文工程作为内置能力——自动的工具结果卸载(20,000 token 阈值)、自动摘要(85% 窗口阈值)、虚拟文件系统作为外部记忆、子智能体上下文隔离。这是它面向"长时运行 + 复杂任务"的核心竞争力。
5.4 控制力 vs 便利性的权衡
这是选型时最本质的一组矛盾:
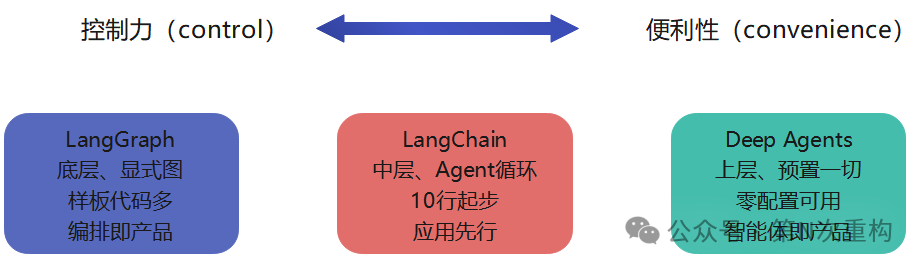
官方与社区的共识是:当"运行时本身"成为你的产品核心关切时,你会想要更直接地使用更底层的 LangGraph;当你只想快速交付一个能用的应用时,LangChain 足够;当任务本身是复杂、非确定、长时运行的(如深度研究、编码智能体),Deep Agents 的预置能力能省下大量基础设施代码。
5.5 模型与供应商支持
三者都是模型供应商无关(provider-agnostic)的。任何支持工具调用(tool calling)的模型都可用——前沿 API(OpenAI、Anthropic、Google)、托管在 Baseten / Fireworks 等平台的开源权重模型、以及通过 Ollama / vLLM / llama.cpp 自托管的模型。Deep Agents 可直接复用任意 LangChain chat model。
5.6 可组合性:三者如何协同
它们并非互斥,而是可组合的分层。官方给出一个关键事实:任何 LangGraph 的 CompiledStateGraph 都可以作为子智能体传入 Deep Agent。这意味着——你可以用 Deep Agents 的默认 harness 处理大部分流程,同时把某个需要精确编排的环节用 LangGraph 自定义图实现,再作为子智能体插入。自定义编排与 harness 默认值可以并存。
六、选型决策指南
把官方建议整理成一个决策流程图,按从上到下的顺序逐个问题判断即可:
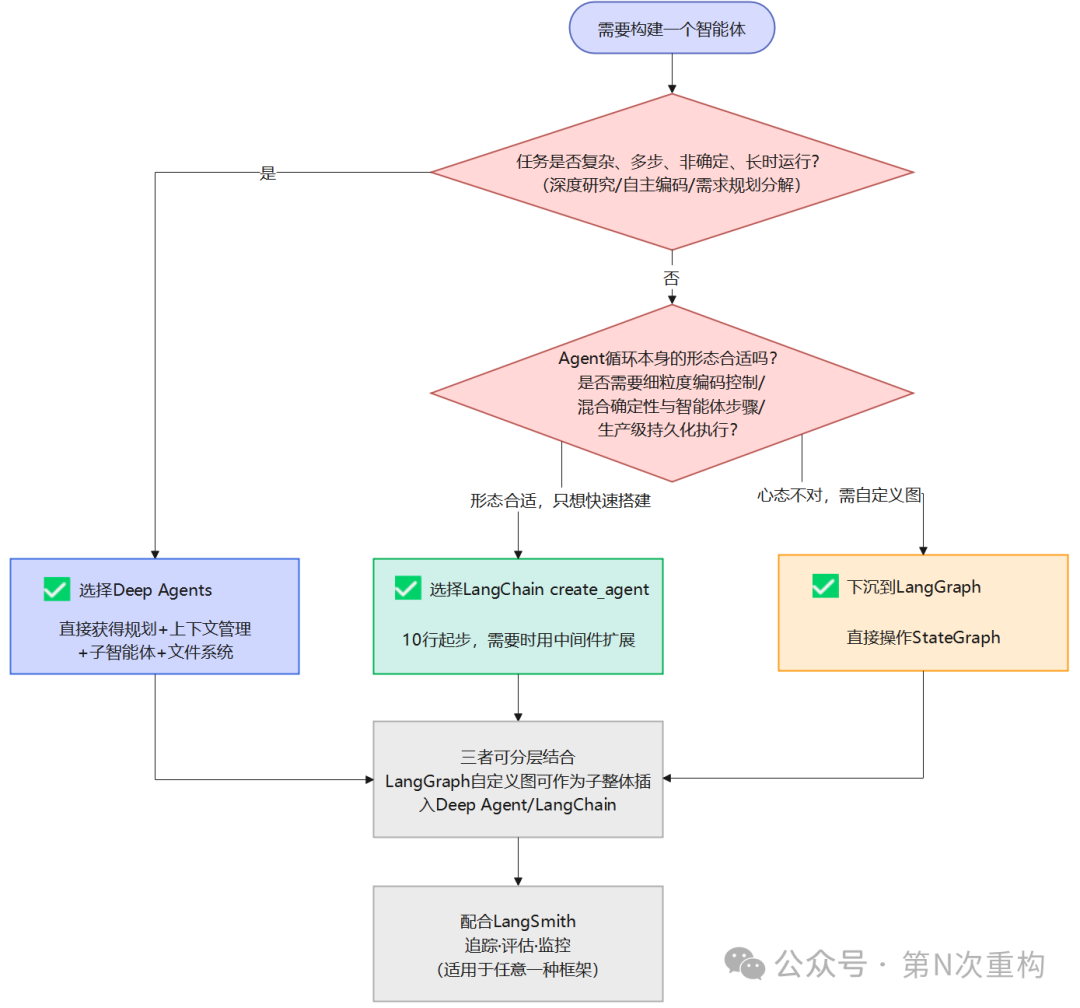
文字版同样的决策流程:
-
任务是否复杂、多步、非确定、长时运行?(如深度研究、自主编码、需要规划与分解的任务)
-
是 → 优先 Deep Agents。直接获得规划、上下文管理、子智能体、文件系统等完整 harness。
-
-
是否需要快速构建、标准化团队的智能体开发方式?(相对直接的 Agent 应用,不需要复杂编排)
-
是 → 使用 LangChain 的
create_agent。轻量、10 行起步,需要时用中间件扩展。
-
-
Agent 循环本身的形态不对,需要自定义图?需要细粒度编排控制、混合确定性与智能体步骤、生产级持久化执行?
-
是 → 下沉到 LangGraph,直接操作
StateGraph。
-
-
三者都需要怎么办?
-
分层组合即可。Deep Agents / LangChain 处理主流程,LangGraph 自定义图作为子智能体插入精确编排环节。
-
配合 LangSmith 做追踪、评估与监控(适用于以上任意一种框架构建的智能体)。
-
一句话总结官方的选择逻辑:
想要完整外壳、开箱即用的规划与上下文管理 → Deep Agents;想要更轻的外壳、不带打包中间件 → LangChain 的
create_agent;当 Agent 循环本身的形态不合适、需要自定义图 → 下沉到 LangGraph。
七、生态与版本信息
-
LangChain 1.0:发布于 2025 年 10 月,面向生产的重构,引入中间件架构、标准内容块、
create_agent;要求 Python 3.10+。 -
LangChain 1.1.0:2025 年 11 月 24 日发布,引入 Model Profiles(
.profile属性)等。 -
LangGraph:底层运行时,可独立使用;被 Klarna、Uber、J.P. Morgan 等公司用于生产。
-
Deep Agents(
deepagents):独立库,含 SDK、Deep Agents Code 终端编码智能体、ACP 集成。 -
LangSmith:贯穿三者的智能体工程平台,负责追踪(tracing)、评估(evaluation)、提示词管理与部署;其中 LangSmith Engine 能检测 Agent trace 中的问题并提议修复(可直接从 Engine 标签页开 PR)。
-
统一 API 参考:reference.langchain.com 覆盖 LangChain、LangGraph、DeepAgents、LangSmith 及集成,提供 Python、TypeScript、Java、Go 等语言的包文档。
八、总结
LangChain、LangGraph、Deep Agents 不是三选一的竞争关系,而是同一智能体技术栈的框架层、运行时层、外壳层:
-
LangGraph 回答"怎么可靠地跑"——图编排、持久化执行、状态管理,控制力最强、最底层;
-
LangChain 回答"怎么快速搭"——模型/工具/Agent 循环的标准抽象 + 中间件,平衡上手速度与灵活性;
-
Deep Agents 回答"怎么处理复杂长任务"——把规划、上下文工程、子智能体、文件系统打包成开箱即用的 harness。
三者层层叠加、可自由组合。选型的核心问题不是"哪个更好",而是"你的应用,运行时本身是否已成为产品的核心关切"——这个问题的答案决定了你应该在哪一层进入这个技术栈。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)