Claude Code ultrawork 持久化全解:14 文件 + cache key
翻开 Claude Code Workflow 一次跑完的全套产物:JS 脚本 + 运行状态 JSON + journal + 6 份 transcript + 6 份 meta,共 14 文件 1.1MB。本文解剖每类文件作用、SHA-256、 cache key 怎么实现 resume、prompt caching 怎么悄悄省 30%,以及为什么这是「脚本即资产」工程哲学的完整落地
文章目录
- 1、前言
- 2、快速上手:怎么开启
- 3、Workflow 工具到底是什么
- 4、ultrawork 是什么、为什么是隐藏的
- 5、源码挖出来的真相:L1 + L2 双门控架构
- 6、深入:从灰度系统到三类云端通信
- 7、实战案例:这篇文章本身就是一次 ultrawork
- 8、总结
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹
1、前言
Claude Code 里其实藏着一个默认情况下你看不到、官方 changelog 里也搜不到的能力:一个叫 Workflow 的工具,配一个叫 ultrawork 的关键字,组合起来可以做确定性的多 Agent 并行编排 —— 单次跑就能拉起十几个 sub-agent,按你写的 JS 脚本同时干活。
它不是 Task 工具,也不是 Agent Teams,是第三种东西:前两者由 LLM 自主决定下一步,是非确定性的;这个 Workflow 是你写 JS 控制流,模型只在你 agent() 的时候才被调用,编排本身不烧 token。
而且这次有一个好消息:Windows 用户也能用。 AI 工具圈对 Windows 用户向来不太友好,要么压根不适配,要么半适配半残废。这个隐藏功能我亲测在 Windows 上跑通了:
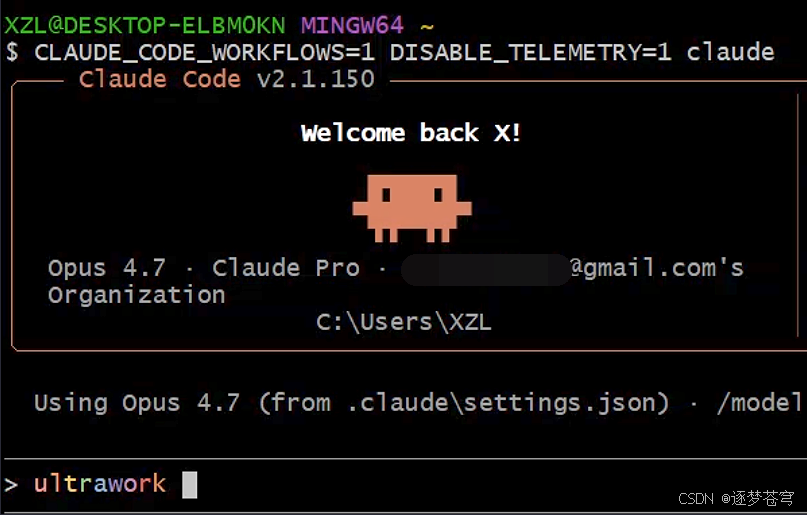
可以看到 DESKTOP-ELBM0KN MINGW64 这个 Windows 的 git-bash 环境下,Claude Code v2.1.150 启动后 ultrawork 关键字直接染色,工具完整可用。macOS / Linux 自然不必说,三个平台全平台覆盖。
我把它打开折腾了一圈,联网搜了 5 个角度还不够,又翻了 Claude Code 的源码副本对照 v2.1.150 验证,才把"怎么开 / 它是什么 / 为什么藏起来"这三件事真正讲清楚。本文最值钱的那一节,就是源码翻出来的那段(第 5 节)。
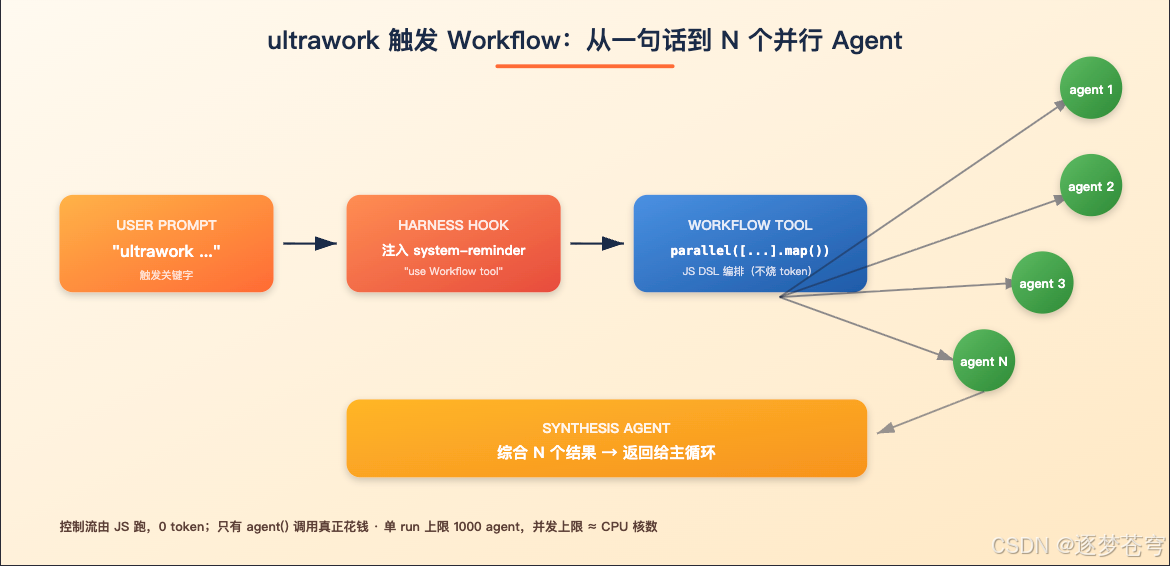
2、快速上手:怎么开启
2.1 标准启动命令
全平台通用(macOS / Linux / Windows-MINGW/WSL/Git-Bash):
CLAUDE_CODE_WORKFLOWS=1 DISABLE_TELEMETRY=1 claude
真正生效的是 DISABLE_TELEMETRY=1,它会关掉 GrowthBook 轮询,让灰度门失去否决权(详细原因见第 5 节,这是本文源码挖出来的最核心结论)。CLAUDE_CODE_WORKFLOWS=1 严格说是冗余的、未被源码读取,但我保留它作为语义清晰的 opt-in 标记。
放进 ~/.zshrc / ~/.bashrc(Linux/macOS)或 ~/.bash_profile(Windows git-bash)长期生效:
export CLAUDE_CODE_WORKFLOWS=1
export DISABLE_TELEMETRY=1
或者写进 .claude/settings.json(三平台通用)
2.2 验证是否生效
两个信号同时具备 = 真开了:
- 输入框里
ultrawork这个词有特殊颜色 —— UI 渲染层确认工具已激活 - 你在消息里加
ultrawork,Claude 会自动拉起 Workflow —— 没开的时候它会装作不认识
可以直接在 Claude Code 里输一句:
ultrawork 帮我并行搜一下 X、Y、Z 三个话题
如果开了,它会用 Workflow 工具写一段 JS 脚本,并行扇出 3 个 sub-agent,跑完汇总。没开的话它会说"找不到这个功能"或者直接当普通搜索处理。
2.3 用 /workflows 看实时进度
启动后多了一个 /workflows slash command,可以实时看进度树:哪个 phase、哪个 agent 在跑、哪个 agent stuck、哪个被跳过。多 agent 任务跑起来的时候这个特别有用。
3、Workflow 工具到底是什么
3.1 一句话定位
Workflow 是一个让你用 JS 脚本编排多 Agent 的工具。 控制流(
for/while/if/ 并行 / 流水线)由 JS 跑,编排逻辑不烧 token;只有你调agent()的时候才真正派 sub-agent。
这跟你以前用的 sub-agent 区别在哪?
| Task / Agent 工具 | Agent Teams | Workflow | |
|---|---|---|---|
| 控制流 | LLM 自己决定下一步 | Teammate 之间发消息协调 | 纯 JS(for/while/parallel/pipeline) |
| 是否确定性 | 非确定性 | 非确定性 | 确定性,同脚本同 args 行为完全一致 |
| 能否恢复 | 不能 | 不能(/resume 会丢) |
能(resumeFromRunId + journal 缓存) |
| 编排开销 | 每步都过模型 | 每条消息都过模型 | 0 token(只有 agent() 烧 token) |
| 官方状态 | 稳定 | 实验性(已文档化) | 未公开 / 未文档化 |
3.2 核心原语(这套 API 是真的)
公开来源(GitHub 上的 ray-amjad/claude-code-workflow-creator,作者声明"对照二进制核对而非猜测")确认了以下原语全部存在:
| 原语 | 作用 | 关键语义 |
|---|---|---|
agent(prompt, opts?) |
派一个全新上下文的 sub-agent | 配 schema 时返回 AJV 校验过的结构化对象 |
parallel(thunks) |
有屏障并发:等全部完成才返回 | 失败 →null,记得 .filter(Boolean) |
pipeline(items, ...stages) |
无屏障流水线:item A 在 stage 3 时 B 可能还在 stage 1 | 默认的多阶段形状,整体 wall-clock 更短 |
phase(title) |
启动进度组,UI 上分块显示 | 在 parallel 内用 agent({phase}) 避免竞争 |
workflow(name, args?) |
内嵌另一个 workflow | 只允许 1 层嵌套,递归会抛错 |
budget |
{total, spent(), remaining()} |
用户能用 +500k 风格设上限,超出 agent() 抛错 |
args |
透传脚本入参 | 对象保持对象、字符串保持字符串 |
agent() 的关键选项:
schema: JSON Schema → 编译成强制StructuredOutput工具调用,校验失败自动重试model:'haiku' / 'sonnet' / 'opus',不传则继承isolation: 'worktree': 给这个 agent 起个全新 git worktree(200–500ms 开销),并行写文件不冲突agentType: 指定 subagent 类型('Explore'、自定义 agent 等)
3.3 沙盒限制(来自二进制)
- 单次 run
agent()调用硬上限:1000,超了抛WorkflowAgentCapError - 并发数:
min(16, max(2, cores − 2)),多了排队而非报错 - 脚本大小:512 KB,parse 前就拒
- 默认 stall 超时:每个 agent 180 秒
3.4 9 个开箱模式
patterns.md 给了 9 个直接抄就能用的形状(这些和你环境里那一坨 bughunt / plan-hunter / deep-research skill 是同源的):
- Fan-out then synthesize:并行问 N 个角度 → 再综合
- Pipeline: review then verify:默认多阶段,每个 item 独立推进
- Barrier for dedup:必须先去重再下一步才用
parallel - Loop until 目标数量:累计到 K 个就停
- Loop until 预算耗尽:
while (budget.total && budget.remaining() > 50_000) - Adversarial verify:N 个怀疑论者并行投票,多数否决就丢
- Judge panel:MVP-first / risk-first / user-first 多角度起草 → 并行评委 → 综合(对应
/plan-hunter) - Loop until dry:连续 K 轮 dry 才停(对应
/bughunt) - Nested workflow:内嵌另一个 workflow
4、ultrawork 是什么、为什么是隐藏的
4.1 ultrawork 关键字的角色
ultrawork 不是一个命令,是一个触发关键字。你在 prompt 里任何位置加上它,Claude Code 的 hook 会注入一段 system-reminder:
The user included the keyword "ultrawork",
which means you should use the Workflow tool to fulfill their request.
这相当于明确告诉模型「这次允许你用 Workflow 编排多 Agent」。它是一个 opt-in 信号,因为 Workflow 一跑起来可能烧十几万 token,必须用户显式同意才会启用。
4.2 为什么 changelog 完全搜不到
我把以下来源全扫了一遍,零命中 CLAUDE_CODE_WORKFLOWS / ultrawork / Workflow 工具:
anthropics/claude-code的CHANGELOG.md(v2.1.108 → v2.1.150 全版本)code.claude.com/docs/en/whats-new(2026 第 13–20 周)code.claude.com/docs/en/env-vars(100+ 官方变量)- GitHub Releases v2.1.141 → v2.1.150
- 三份社区维护的 env-var 参考 gist(其中两份对照过 v2.1.118 二进制)
这个功能确实存在于 Claude Code 里,但 Anthropic 没有把它放进任何对外文档。 唯一公开的技术资料是 GitHub 上一个第三方 skill 项目(ray-amjad/claude-code-workflow-creator),作者声明 API 文档是"对着二进制核对的,不是猜的"。
5、源码挖出来的真相:L1 + L2 双门控架构
这是全文最值钱的一节。前面的联网搜索给出了"双门控"的方向,但真正的实锤要翻源码。这一节是我对照一份之前泄露的 Claude Code 源码副本 + 当前 v2.1.150 二进制,三次提问步步逼近答案的过程。
5.1 第一步:CLAUDE_CODE_WORKFLOWS 这个变量根本不在源码里
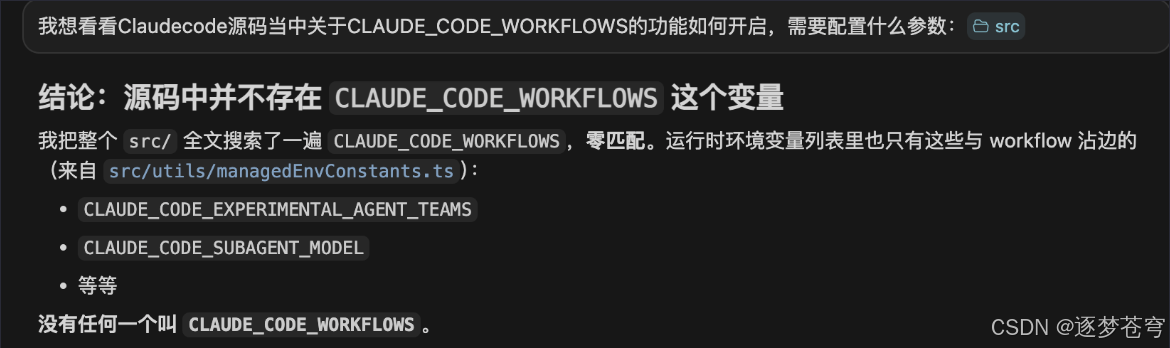
我一开始的假设是「CLAUDE_CODE_WORKFLOWS=1 是真开关」,所以直接去 src/ 全文搜这个字符串。结果零匹配。打开 src/utils/managedEnvConstants.ts(Claude Code 所有受管环境变量的注册中心),里面列了一长串和 workflow 沾边的环境变量:
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS(Agent Teams 实验开关)CLAUDE_CODE_SUBAGENT_MODEL(subagent 默认模型)- 等等
唯独没有 CLAUDE_CODE_WORKFLOWS。 这就尴尬了——那我之前设了它还能"看上去工作",是怎么回事?这个问题悬到了第二步。
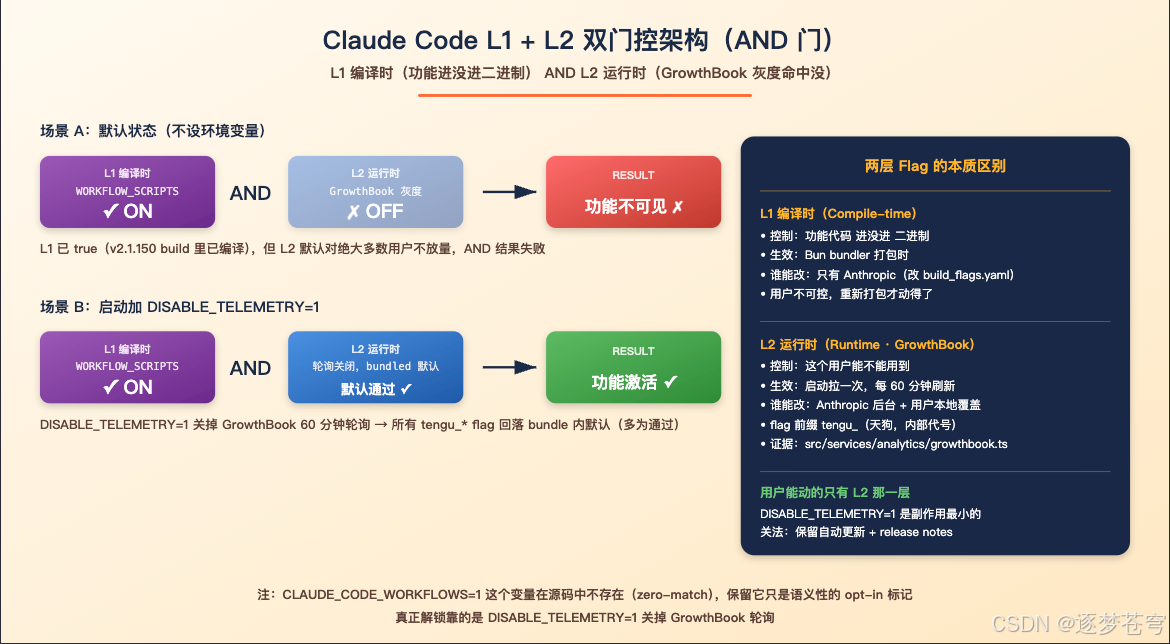
5.2 第二步:换个问法,挖到了 L1 + L2 双层 Feature Flag
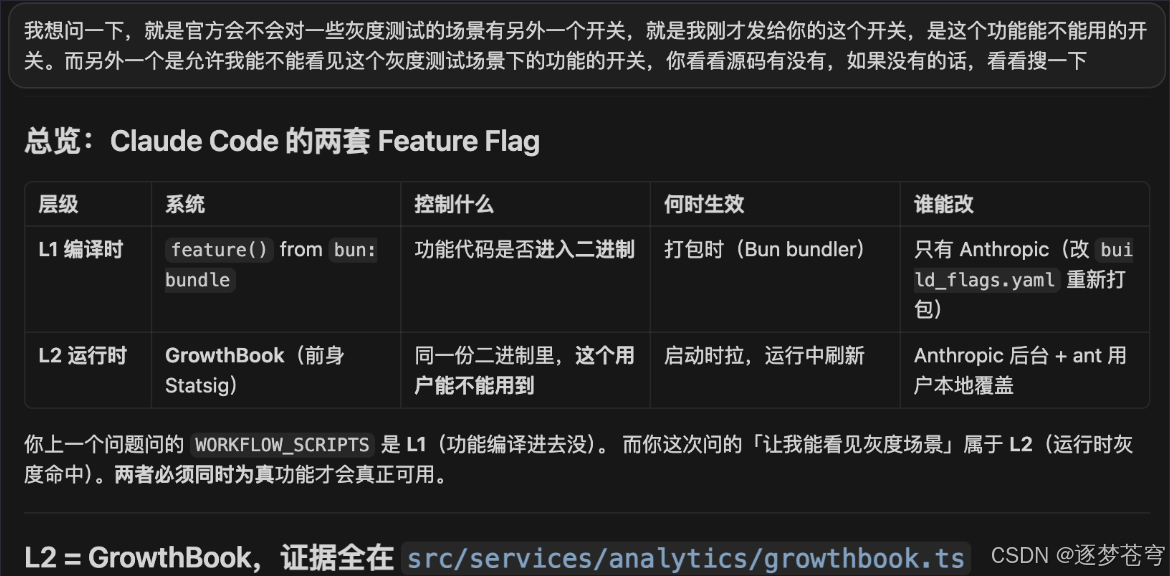
我换了个角度:「会不会有两个完全不同维度的开关——一个控制"功能是否能用",另一个控制"我能不能看见这个灰度功能"?」 这把问题问对了,答案立刻拨开云雾。Claude Code 里的 feature flag 是两层架构:
| 层级 | 系统 | 控制什么 | 何时生效 | 谁能改 |
|---|---|---|---|---|
| L1 编译时 | feature() from bun:bundle |
功能代码是否进入二进制 | 打包时(Bun bundler) | 只有 Anthropic(改 build_flags.yaml 重新打包) |
| L2 运行时 | GrowthBook(前身 Statsig) | 同一份二进制里,这个用户能不能用到 | 启动时拉,运行中刷新 | Anthropic 后台 + 用户本地覆盖 |
Workflow 工具的真实门控就是 L1 AND L2:
- L1 维度:编译时 flag
WORKFLOW_SCRIPTS在 v2.1.150 这版的 build 里 = true,也就是说Anthropic 已经把代码塞进二进制了,所以二进制里能看到Workflow工具的注册逻辑 - L2 维度:默认对绝大部分用户 = false,灰度还没放到你这边
L2 的实现证据全在 src/services/analytics/growthbook.ts。真正卡你的是 L2,不是 L1。
那为啥 CLAUDE_CODE_WORKFLOWS=1 我设了它没报错?因为它根本就没被任何代码读取 —— 未识别的环境变量 Bun 会直接忽略、不会抛错。设它纯粹是「心理安慰 + 个人 opt-in 标记」,不影响功能是否启用。
这一节也是文章前几版的认知盲区。 原本我以为是「本地 env-var + 服务端 GrowthBook」双门,源码翻完才发现真正的双门是「L1 编译时 + L2 GrowthBook 运行时」。env-var 那一票其实是空票——它从来没投过。
5.3 WORKFLOW_SCRIPTS 的源码追踪:feature() + DCE 工程
刚说 L1 是「编译时」听起来抽象。打开源码看,所有 Workflow 相关代码都被 feature('WORKFLOW_SCRIPTS') 包起来:
// src/tools.ts
const WorkflowTool = feature('WORKFLOW_SCRIPTS')
? (() => {
require('./tools/WorkflowTool/bundled/index.js').initBundledWorkflows()
return require('./tools/WorkflowTool/WorkflowTool.js').WorkflowTool
})()
: null
// src/commands.ts
const workflowsCmd = feature('WORKFLOW_SCRIPTS')
? require('./commands/workflows/index.js').default
: null
// src/tasks.ts
const LocalWorkflowTask = feature('WORKFLOW_SCRIPTS')
? require('./tasks/LocalWorkflowTask/LocalWorkflowTask.js').LocalWorkflowTask
: null
这里的 feature() 来自 Bun 的内置模块:
import { feature } from 'bun:bundle'
它不是运行时函数。Bun bundler 打包时会把 feature('WORKFLOW_SCRIPTS') 直接替换成字面量 true 或 false,然后由 bundler 做死代码消除(DCE),把 false 分支彻底从产物里删掉。
src/components/tasks/BackgroundTasksDialog.tsx 里有段注释把这事说得明明白白:
// WORKFLOW_SCRIPTS is ant-only (build_flags.yaml). Static imports would leak
// ~1.3K lines into external builds. Gate with feature() + require so the
// bundler can dead-code-eliminate the branch.
注释给出了 3 个关键信息:
WORKFLOW_SCRIPTS设计上是 ant-only(Anthropic 内部构建专属)- 配置文件叫
build_flags.yaml,只在 Anthropic 内部仓库,外部源码包没有 feature() + require双层包装让外部构建版本能把这 ~1300 行代码全部 DCE 掉
理论上:外部用户的 claude-code 包里连 src/tools/WorkflowTool/ 这个目录都不应该存在。
但实测:v2.1.150 公开版(包括 Claude Pro 用户拿到的版本)里 WORKFLOW_SCRIPTS 显然是 true —— 上面 Windows 截图里 ultrawork 跑得通就是直接证据。最可能的解释是 Anthropic 已经把 build_flags.yaml 里这条翻成了公开放量,注释里"ant-only"的说法已经过时。
这也解释了为什么这个功能:
- 在源码注释里写着 ant-only
- 但实际在 v2.1.150 build 里能用
- 而且 changelog 又一字没提
—— 这是一个「代码已经放进二进制了,但官方还没正式宣布」的过渡状态。L1 已经默默打开,L2 还在灰度名单里慢慢放量。这种「半发布」是大型 SaaS-CLI 项目里很常见的中间形态。
5.4 第三步:关掉 GrowthBook 的 5 种方式 + 两个坑
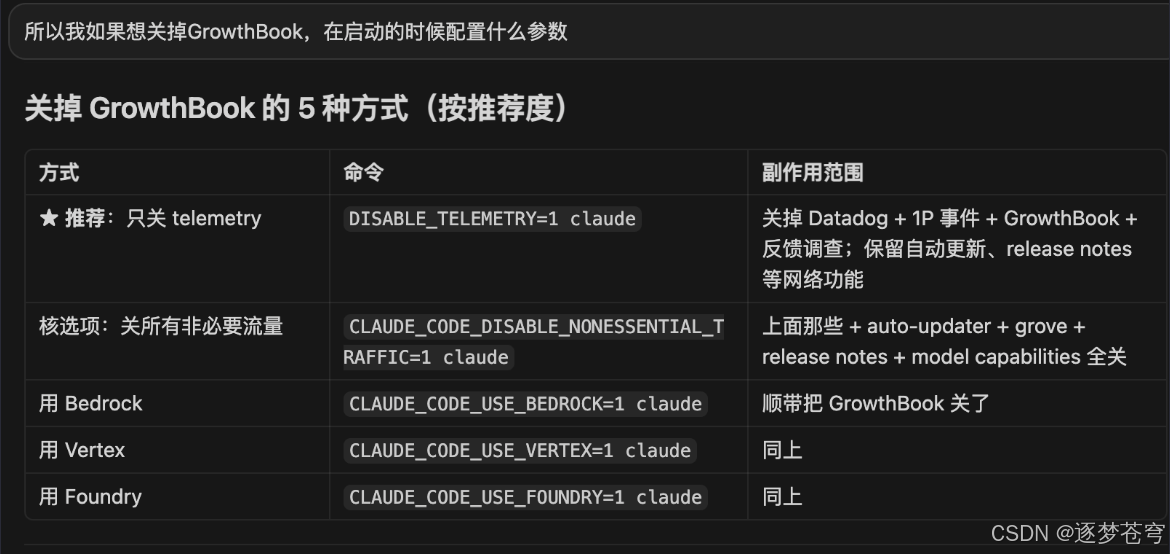
L2 这道门要怎么绕过?源码里给出了 5 种方式:
| 方式 | 命令 | 副作用范围 |
|---|---|---|
| ★推荐:只关 telemetry | DISABLE_TELEMETRY=1 claude |
关 Datadog + 1P 事件 +GrowthBook + 反馈调查;保留自动更新、release notes 等正常网络功能 |
| 核选项:关所有非必要流量 | CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 claude |
上面那些 + auto-updater + grove + release notes + model capabilities 全关 |
| 用 Bedrock | CLAUDE_CODE_USE_BEDROCK=1 claude |
走 AWS Bedrock,顺带把 GrowthBook 关了 |
| 用 Vertex | CLAUDE_CODE_USE_VERTEX=1 claude |
走 GCP Vertex AI,同上 |
| 用 Foundry | CLAUDE_CODE_USE_FOUNDRY=1 claude |
走 Azure Foundry,同上 |
为什么选 DISABLE_TELEMETRY=1:副作用最小。 它只关掉遥测和 GrowthBook 轮询,保留自动更新和 release notes 这类正常网络功能。CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 太狠会顺手把自动更新都关了——这是个 trade-off,普通用户没必要。后三种是云厂商接入开关,"顺带"关 GrowthBook,但你不打算用 Bedrock/Vertex/Foundry 就不要这么设。
两个容易踩的坑
坑 1:DISABLE_TELEMETRY=false 反而会触发关闭。
源码里这个变量是裸 truthy 判断,不是 isEnvTruthy:
if (process.env.DISABLE_TELEMETRY) { /* disable telemetry */ }
JS 里非空字符串全是 truthy,所以 DISABLE_TELEMETRY=false(字符串 "false")也会触发关闭分支。要让它彻底「未设」,必须 unset DISABLE_TELEMETRY 或者别去 export 它。这个坑同样适用于 CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC。
坑 2:CLAUDE_CODE_USE_BEDROCK / VERTEX / FOUNDRY 必须是 1/true/yes/on 之一。
这三个变量用的是 isEnvTruthy,源码:
export function isEnvTruthy(envVar: string | boolean | undefined): boolean {
if (!envVar) return false
if (typeof envVar === 'boolean') return envVar
const normalizedValue = envVar.toLowerCase().trim()
return ['1', 'true', 'yes', 'on'].includes(normalizedValue)
}
所以 CLAUDE_CODE_USE_BEDROCK=0、CLAUDE_CODE_USE_BEDROCK=false、CLAUDE_CODE_USE_BEDROCK=anything-else 全部视为未启用。两个变量的判断风格不一致是埋点,记着区别。
关掉 GrowthBook 之后到底会发生什么
看 getFeatureValueInternal 的关键判断:
if (!isGrowthBookEnabled()) {
return defaultValue
}
GrowthBook 一关,所有 feature 读取全部直接返回调用点写的 defaultValue:
- 不会再去
api.anthropic.com拉灰度 - 不会用磁盘缓存里的旧灰度值
- 不会做 A/B 分流(实验都不"参与",也不上报 exposure 事件)
- 所有走 GrowthBook 的功能回到代码里写死的默认值
而绝大多数新功能的默认值是 false,少数稳定功能(kill switch 类)默认是 true。Workflow 这类「L1 已编译进 bundle、对应 L2 默认放量」的功能,在 DISABLE_TELEMETRY=1 关掉 GrowthBook 之后正好命中 bundle 内的默认通过,所以激活。
5.5 ant 用户能用的三条本地覆盖路径(外部用户用不上,但有助于理解架构)
完整性起见把整个 feature flag 评估的优先级链摆出来。直接看 getFeatureValueInternal 顶部:
async function getFeatureValueInternal<T>(feature, defaultValue, logExposure) {
const overrides = getEnvOverrides()
if (overrides && feature in overrides) {
return overrides[feature] as T
}
const configOverrides = getConfigOverrides()
if (configOverrides && feature in configOverrides) {
return configOverrides[feature] as T
}
if (!isGrowthBookEnabled()) {
return defaultValue
}
// ... 走远程评估
}
完整的优先级链是 6 层:
1. process.env.CLAUDE_INTERNAL_FC_OVERRIDES[feature] ← 环境变量覆盖(最高)
↓
2. ~/.claude.json::growthBookOverrides[feature] ← 本地配置覆盖
↓
3. remoteEvalFeatureValues[feature] ← 服务器远程评估的内存缓存
↓
4. ~/.claude.json::cachedGrowthBookFeatures[feature] ← 磁盘缓存
↓
5. ~/.claude.json::cachedStatsigGates[feature] ← Statsig 兜底(Statsig→GrowthBook 迁移期残留)
↓
6. defaultValue ← 调用点写的默认值
前 2 层是「本地覆盖」,3-5 层是「GrowthBook 系统」,第 6 层是「代码默认值」。
三条本地覆盖开关(仅在 USER_TYPE=ant 下生效)
function getEnvOverrides() {
if (process.env.USER_TYPE !== 'ant') return undefined
// ... parse CLAUDE_INTERNAL_FC_OVERRIDES
}
function getConfigOverrides(): Record<string, unknown> | undefined {
if (process.env.USER_TYPE !== 'ant') return undefined
// ... read growthBookOverrides from ~/.claude.json
}
| 开关 | 形式 | 用途 | 持久化 |
|---|---|---|---|
CLAUDE_INTERNAL_FC_OVERRIDES |
环境变量 + JSON | 给 eval harnesses(评测脚本)用,临时写死灰度结果 | 否 |
growthBookOverrides(~/.claude.json 字段) |
配置文件 | 给 /config Gates tab(ant-only)用 |
是 |
CLAUDE_CODE_GB_BASE_URL |
环境变量 URL | 把灰度服务指向自己起的 GrowthBook 实例 | 否 |
重点:这三条全部用 if (process.env.USER_TYPE !== 'ant') return undefined 守住,普通用户设了不起作用。所以对外部用户来说有效的灰度控制就是关掉 L2(即 DISABLE_TELEMETRY=1),让所有 feature 回落到代码默认值。
理解这一层的意义在于:以后看到 ~/.claude.json 里有 growthBookOverrides 或 cachedGrowthBookFeatures 这种字段时,你能立刻知道它是干嘛的——一份是 ant 内部的灰度调试后门,一份是上次拉到的灰度结果磁盘缓存。
5.6 最终的启动命令
CLAUDE_CODE_WORKFLOWS=1 DISABLE_TELEMETRY=1 claude
严格说 CLAUDE_CODE_WORKFLOWS=1 是冗余的(5.2 已解释),但我保留它两个原因:
- 语义清晰:作为 opt-in 标记,让以后看到这条命令的人一眼明白意图
- 未来兼容:万一哪天 Anthropic 把它做成实际开关,已经设好了
真正生效的就是 DISABLE_TELEMETRY=1 —— 关掉 GrowthBook 轮询 → L2 灰度门失去否决权 → 默认值(编译时塞进 bundle 的那个)说了算 → Workflow 工具激活。
5.7 为什么 Anthropic 要用 L1 + L2 双门
不是没事找事,是真有几个工程上的硬需求:
- 成本兜底:Workflow 单 run 可能烧 10-50× 普通 session 的 token。L2 GrowthBook 让 Anthropic 能叠百分比放量 / 账号白名单 / 套餐 gate(比如 Remote Control 的
tengu_ccr_bridge只给 Max plan) - Kill switch 不依赖 npm 升级:agent 编排出 bug(失控派生、teammate 死循环、prompt-injection 提权),1 小时内能对所有已装 CLI 关掉,不用等用户升级
- 分阶段放量 / A-B 实验:分类器参数、attribution header、安全阈值这类可以不发版直接做 A/B
- SEV 响应:权限决策本身是模型调用,参数也是 GrowthBook 驱动,安全事件后能全局收紧
- L1 编译时门提供另一层托底:哪怕 L2 服务挂了或被绕过,L1 没编译进 build 的功能直接是字面意义上的不存在
已知用 L2 GrowthBook 守门的能力(来自源码 + source-leak 解读):
| GrowthBook flag | 守的能力 |
|---|---|
tengu_amber_flint |
Agent Teams / Swarms |
tengu_ccr_bridge |
Remote Control |
tengu_claudeai_mcp_connectors |
MCP connectors |
tengu_amber_quartz_disabled |
语音模式 kill-switch |
tengu_anti_distill_fake_tool_injection |
反蒸馏假工具注入 |
WORKFLOW_SCRIPTS(L1) + 对应 L2 flag |
Workflow 工具本身 |
flag 前缀 tengu_ = 天狗,是 Claude Code 内部代号。客户端每 60 分钟轮询一次远端 flag JSON,DISABLE_TELEMETRY=1 就是把这个轮询整个掐掉。
6、深入:从灰度系统到三类云端通信
上面把 Workflow 这个具体功能讲完了,这一节往外推一步——Claude Code 整套功能开关、隐私级别、跟 Anthropic 云端的通信关系到底怎么组织。理解这一层对判断「我看不到某个新功能是不是 bug」特别有用。这部分也是这次翻源码挖出来的最有价值的一块:灰度测试系统和实际正式运行服务之间的关联关系。
6.1 Claude Code 跟 Anthropic 云端的三类通信
启动 Claude Code 后它会跟 api.anthropic.com 发生三类通信,用途完全不同:
① 推理(Inference)—— 真正"干活"的通道
└─ POST /v1/messages 等 ── 跟模型对话
必须保留,关了就没法用
② 控制面(Control Plane)—— 给 Anthropic 用的
├─ GrowthBook ── 灰度 / 实验 / kill-switch
├─ Bootstrap ── 账户元数据
├─ Grove ── 通知
├─ ClaudeAiLimits ── 配额
├─ passes / overage credit
├─ ModelCapabilities ── 模型能力清单
├─ ReleaseNotes
├─ TrustedDevice 注册
└─ FastMode 状态
③ 数据面(Telemetry)—— 给 Anthropic 看的
├─ 1P Event Logger
├─ Datadog 分析
├─ BigQuery metrics
├─ 错误上报
└─ Feedback / 调查
Workflow / ultrawork 的启用主要受 ② 控制面里的 GrowthBook 控制——这就是为什么关掉 telemetry(实际关掉的是 GrowthBook 那个调用链)就能让默认放量行为生效。
注意 ① 推理和 ②③ 是独立的网络通道,所以理论上可以「保留模型对话、断掉所有控制面/数据面」——这是企业部署的常见诉求。
6.2 三档隐私级别(default / no-telemetry / essential-traffic)
源码里直接定义了三个隐私级别(来自 src/utils/privacyLevel.ts),注释抄过来:
default: Everything enabled.
no-telemetry: Analytics/telemetry disabled (Datadog, 1P events, feedback survey).
essential-traffic: ALL nonessential network traffic disabled
(telemetry + auto-updates, grove, release notes, model capabilities, etc.).
The resolved level is the most restrictive signal from:
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC → essential-traffic
DISABLE_TELEMETRY → no-telemetry
对应到上面三类通信:
| 档位 | 触发方式 | 切掉什么 | 留下什么 |
|---|---|---|---|
default |
啥都不设 | — | 所有 ① + ② + ③ |
no-telemetry |
DISABLE_TELEMETRY=1 |
③(含 GrowthBook) | ① + ② 其余部分 |
essential-traffic |
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 |
② + ③ 全部 | 只剩 ①(推理) |
想完全零接触 api.anthropic.com 怎么做
企业部署的典型组合:
CLAUDE_CODE_USE_BEDROCK=1 \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 \
claude
意思是:
- 推理走 AWS Bedrock(不再走 api.anthropic.com)
- 控制面 + 数据面全切
- 结果:跟
api.anthropic.com完全零接触
Vertex / Foundry 同理。这是给航空航天、金融、军工这类对数据出境敏感的场景准备的「完全断网」模式。源码里有专门的代码路径处理这个组合。
6.3 一个功能在你机器上"看不见"的 4 种原因
这是最容易混淆的部分。直觉上很多人以为「看不到 = 云端给我关了」,但真相是分层的:
你 npm install 的 claude-code 二进制包
│
├─ 第 1 类:被剥离(L1 编译时)
│ 代码根本不在你的包里
│ 例:WORKFLOW_SCRIPTS(理论上 ant-only,实测 v2.1.150 已开)
│ KAIROS、BRIDGE_MODE 等
│
└─ 代码就在你机器上(编译进来了):
│
├─ ① 默认 on、云端可关(kill-switch)
│ ← 直觉上的"云端发关闭信息",但其实少见
│ 例:tengu_max_version_config(自动更新)
│
├─ ② 默认 off、云端按用户放开(灰度 / A/B test)
│ ← 这才是大多数情况!包括 Workflow 工具的 L2 控制
│
└─ ③ USER_TYPE === 'ant' 硬编码守卫
← 跟云端无关,永远对外部用户关闭
例:5.5 节那三条本地覆盖路径
一个常见的误解:是云端"发了关闭信息"导致功能不显示
不是。绝大多数功能默认就是关的,云端不发任何东西时也是关的,只有命中灰度才会发"打开"的指令。
证据是所有 GrowthBook 读取函数的签名:
export function getFeatureValue_CACHED_MAY_BE_STALE<T>(
feature: string,
defaultValue: T, // ← 云端啥都没说时用的值
): T
实际调用绝大多数新功能写的都是 getFeatureValue_CACHED_MAY_BE_STALE('xxx', false) —— 默认关,命中灰度才开。
只有少数稳定功能是 ①(默认开 + 云端紧急关),代码里管这类叫 kill-switch。tengu_max_version_config 控制客户端自动更新就是典型例子:正常情况自动更新工作,但 Anthropic 可以远程把它关掉应急。
跟云端断连后各类型的行为变化
执行 CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 claude 之后:
| 类型 | 行为变化 |
|---|---|
| ① kill-switch 类 | 回到默认开启状态,但 Anthropic 失去了远程关停能力 |
| ② 灰度白名单类 | 你永远不会被放出来(这是代价) |
| ③ ant-only 硬编码守卫类 | 完全无变化(跟云端无关,本来对外部就关) |
这里有一个微妙的点要分清:用 essential-traffic 档断网会关掉 GrowthBook 同时也关掉灰度放量,所以本来要灰度给你的功能反而拿不到。想用 Workflow 的人应该用 DISABLE_TELEMETRY=1(no-telemetry 档)——它关 GrowthBook 但让 feature 回落 bundle 默认值,对 Workflow 这种「L1 已 true、L2 默认 true 等灰度放开」的功能正好能命中。
6.4 本质:版本号 ≠ 功能集
把上面所有东西拢一下,到一个比较本质的设计观察:
现代 SaaS 类 CLI 工具的"版本"和"功能集"已经解耦了。
你的二进制版本号决定功能的代码上限(最多能有哪些功能),但这一刻能用到哪些完全由服务器的灰度配置决定。
同一个版本号,A 用户和 B 用户看到的功能可能完全不同:
- 升级 = 把 ceiling 抬高(编译进更多功能 = L1 翻 true)
- 命中灰度 = 把 floor 抬上来碰到 ceiling 里的某个功能(L2 翻 true)
两件事正交。
Claude Code 把这套做得比较完整:
- L1 编译期裁剪(保证 ant-only 代码不泄漏,外部包瘦身)
- L2 运行时灰度(精细化按用户分批放量)
- ant 用户保留三种本地覆盖路径(环境变量 / 配置文件 / 自定义 GB 后端)作为调试后门
- 三档隐私级别让用户能选择切断到哪一层
这是一个**「小型企业级 feature management 系统」在 CLI 工具里的完整实现**。理解这套架构之后,下次再看到「我没看到某个新功能」时,就能精确判断是 L1(没编译进来)、L2(没命中灰度)还是 ant-only(永远跟你无缘),而不是笼统地以为「Anthropic 关了」或「我哪里配置错了」。
也是这次翻源码最值钱的一块结论:Claude Code 不是一个传统意义上的「客户端」,而是一个「客户端 + 服务端灰度控制」的复合体。这种架构在 ChatGPT、Cursor 等 SaaS 类工具上越来越普遍,理解 Anthropic 这套是触类旁通的好样本。
7、实战案例:这篇文章本身就是一次 ultrawork
写到这里得交代一件事 —— 这篇文章的研究过程,本身就是一次完整的 ultrawork 调用。我把过程拆开给你看,比再举一个抽象例子直观得多。
7.1 任务的起点
写这篇文章面临的问题是:Workflow 功能 Anthropic 官方没公开任何资料,只能多角度联网搜 + 反向交叉佐证。开始动笔前我列了 5 个必须查清楚的独立维度:
CLAUDE_CODE_WORKFLOWS和DISABLE_GROWTHBOOK在公开来源里到底有没有ultrawork关键字的真实出处(官方?社区?)- Workflow 工具的 JS DSL 原语设计细节
- 是否真的在 changelog / release notes 缺席
- GrowthBook 双门控的架构证据链
这 5 个角度彼此独立 / I/O 密集 / 最后需要综合——三个条件全中,是 ultrawork 的标准杀器场景。
这次 workflow 给出了"双门控"的方向和大量周边证据(哪些
tengu_*flag、为什么藏起来、Workflow API 的细节),但关键那个DISABLE_TELEMETRY=1是真开关这件事,公开来源都给不出实锤——还得靠第 5 节那 3 次源码翻查才最终确证。这是 ultrawork 的边界:它擅长广度(5 个角度并行扇出),但碰到只有源码才能给答案的问题时,还是得回到单线程的深挖。
7.2 实际跑的 Workflow 脚本(精简版)
export const meta = {
name: 'research-claude-workflow-ultrawork',
description: '5 个角度并行联网调研 Workflow / ultrawork 功能',
phases: [
{ title: 'Research', detail: '5 parallel web research agents' },
{ title: 'Synthesize', detail: 'compile findings into notes' },
],
}
phase('Research')
const QUERIES = [
{ label: 'env-vars-and-flags', prompt: '调研两个环境变量在公开来源里的命中情况…' },
{ label: 'ultrawork-keyword', prompt: '调研 ultrawork 关键字的真实出处…' },
{ label: 'workflow-tool-design', prompt: '调研 Workflow JS DSL 原语设计…' },
{ label: 'changelog-presence', prompt: '检查官方 changelog / release notes…' },
{ label: 'growthbook-context', prompt: '调研 GrowthBook 双门控架构证据…' },
]
// 阶段 1:5 个 agent 各开独立 context、并发联网搜
const findings = await parallel(QUERIES.map(q => () =>
agent(q.prompt, { label: q.label, phase: 'Research' })
))
phase('Synthesize')
// 阶段 2:1 个 agent 把 5 份原始笔记综合成带引用的结构化总结
const summary = await agent(
`综合以下 5 份调研笔记为带引用的结构化总结:\n${
findings.map((f, i) => `### ${QUERIES[i].label}\n${f}`).join('\n\n---\n\n')
}`,
{ label: 'synthesize', phase: 'Synthesize' }
)
return { findings, summary }
注意几个关键点:
- 5 个
agent()调用塞进parallel()里,真并行而不是顺序 await - 每个 agent 通过
phase: 'Research'显式声明所属进度组,避免在parallel()内部全局phase()状态被竞争覆盖 findings是 5 份纯文本结果,编排层(这段 JS)只是拼字符串、不做 LLM 调用,0 token- 综合阶段是单独的
agent(),对应phase('Synthesize')进度组
7.3 Workflow 会自动落盘:路径、Run ID、resume
调用完 Workflow 工具,它会返回三样很关键的东西:
Task ID: wzwmkptan
Run ID: wf_d5fb0a4d-5b8
Script file: /Users/xzl/.claude/projects/-Users-xzl/b662113f-7d4d-4bd5-ad99-68ad1e8cbe95/workflows/scripts/research-claude-workflow-ultrawork-wf_d5fb0a4d-5b8.js
Transcript dir: /Users/xzl/.claude/projects/-Users-xzl/b662113f-7d4d-4bd5-ad99-68ad1e8cbe95/subagents/workflows/wf_d5fb0a4d-5b8/
路径规律是:
~/.claude/projects/<encoded-cwd>/
├── workflows/scripts/<workflow-name>-<run-id>.js # 你写的脚本被持久化在这里
└── subagents/workflows/<run-id>/ # 每个 sub-agent 的对话 transcript
├── agent-<n>.jsonl
└── ...
为什么这件事重要? 因为 Workflow 工具是为「写一次、调一次、跑很多次」设计的:
- 脚本可以反复编辑后再跑 —— 用
Write/Edit改那个.js文件,然后重新调用Workflow({scriptPath: "..."}),不用每次把脚本完整粘进 prompt - 同 session 内可以 resume —— 加上
resumeFromRunId: "wf_d5fb0a4d-5b8",已完成的agent()调用会直接返回缓存结果,0 token,只有改过 prompt 或新加的 agent 才会真正跑 - transcript 全部留档 —— 每个 sub-agent 的全部消息都在
agent-<n>.jsonl里,回过头复盘哪个 agent 误判了、是不是该改 prompt,全部可追溯
实际复用示例:
// 第一次跑(如本文研究过程)
Workflow({ script: "export const meta = {...} ... " })
// → 返回 scriptPath + runId
// 后续迭代:改完脚本文件后再跑,跳过已 cache 的 agent
Workflow({
scriptPath: "/Users/xzl/.claude/projects/.../research-claude-workflow-ultrawork-wf_d5fb0a4d-5b8.js",
resumeFromRunId: "wf_d5fb0a4d-5b8",
})
这点跟普通 Task / Agent 工具的「跑完就丢」完全不同 —— Workflow 是一份可以反复改、反复 partial-rerun 的资产,这也是为什么它定位上更像「编排引擎」而不是「一次性任务」。
7.4 实际跑出来的数据
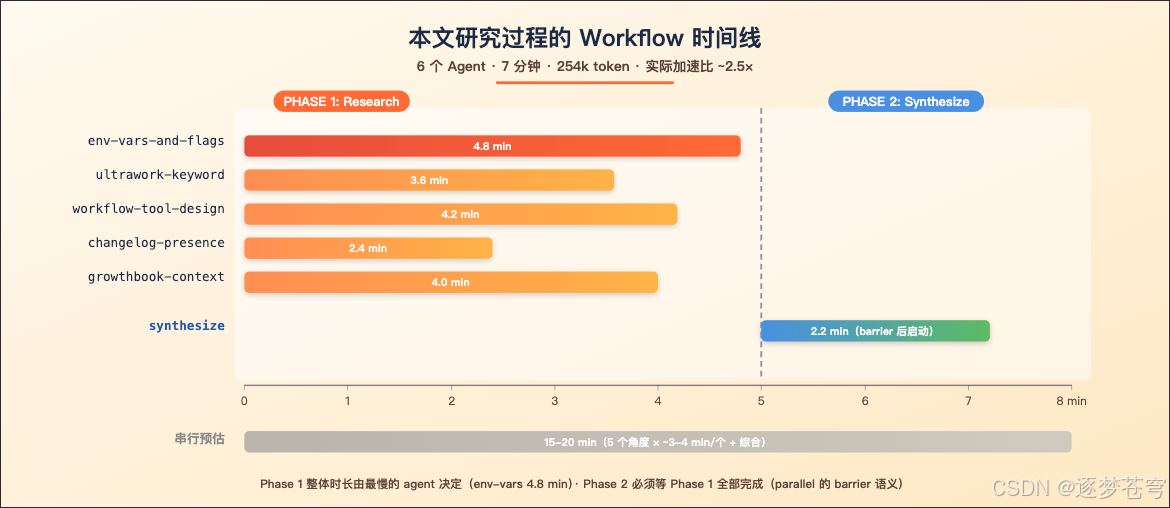
| 维度 | 数值 |
|---|---|
| 总 Agent 数 | 6 (5 个并行调研 + 1 个综合) |
| 总耗时 | ~7 分钟 |
| 总 token 消耗 | ~254k |
| 总工具调用次数 | 64 次(绝大多数是 WebSearch / WebFetch) |
| 同任务串行预估耗时 | 15-20 分钟(每个角度 3-4 分钟) |
| 实际加速比 | ~2.5× |
为什么不是理论上的 5× 加速?因为有几个真实约束:
- 并发上限是
min(16, max(2, cores-2)),机器 CPU 决定上限 - 不同 agent 搜的复杂度不同:最慢的那个决定 phase 1 整体时长
- Phase 2 的综合 agent 必须等 phase 1 全部完成才能开(这一步本来就是 barrier)
7.5 为什么这个任务适合 ultrawork
我把 ultrawork 用得好不好的 4 个判断标准列在这里,供你下次评估自己的任务:
| 判断标准 | 这个任务的情况 | 评估 |
|---|---|---|
| 子任务相互独立? | 5 个搜索角度互不依赖 | ✓ |
| I/O 密集(不是 CPU 密集)? | 全是 WebSearch / WebFetch | ✓✓ |
| 需要综合阶段? | 5 份原始笔记必须压成一份 | ✓ |
| 子任务上下文能各自装下? | 每个角度的搜索结果可独立 | ✓ |
4 个全中 = 杀器场景。 4 个全不中 = 别用 ultrawork。中间情况就看具体权衡。
反过来举几个别用 ultrawork 的反例:
- 单文件改 bug:串行 1 分钟搞定,开 workflow 纯属杀鸡用牛刀
- 强依赖的多步任务:A 的结果决定 B 的输入,并行不起来
- 上下文必须共享:跨文件改一个功能,每个 agent 都得加载全量代码,并行省不到时间反而多花 token
- 问答类:用户问"这是什么",直接答比开 6 个 agent 答更快
7.6 ultrawork 的真实成本权衡
7 分钟、254k token 听起来不痛不痒,但要注意:5 个 agent 同时跑意味着 5 份独立 context、5 次推理消耗。换成串行让一个 agent 顺序问 5 次:
- 串行:可能消耗 80-120k token(共享 context,能复用前情)
- 并行:254k token(每个 agent 独立 context,无法复用)
也就是说,ultrawork 实际上多花了 ~2 倍 token 换来 ~2.5 倍 wall-clock 速度。
核心权衡很清楚:用 token 换时间。
什么时候值:
- 写文章 / 做调研,赶 deadline
- 代码审查 / bug 扫描,多维度独立判断比单线串行更可靠
- 大范围扫描 / 迁移,单 context 装不下
什么时候不值:
- 好奇心问问看,不急
- 单点小修小改
- 没明确产出目标的探索
这就是为什么我前面反复强调:不要把 ultrawork 当口头禅。它是个杀器,但杀器用错地方就是浪费。
7.7 脚本逐段细看:实际跑了什么 prompt
7.2 给的是精简版,这里把实际跑的那份脚本完整贴出来——直接从 ~/.claude/projects/-Users-xzl/<session-id>/workflows/scripts/research-claude-workflow-ultrawork-wf_d5fb0a4d-5b8.js 读出的真身,共 109 行。
export const meta = {
name: 'research-claude-workflow-ultrawork',
description: 'Parallel web research on Claude Code Workflow / ultrawork feature across 5 angles',
phases: [
{ title: 'Research', detail: '5 parallel web research agents across different angles' },
{ title: 'Synthesize', detail: 'compile findings into structured notes' },
],
}
phase('Research')
const QUERIES = [
{
label: 'env-vars-and-flags',
prompt: `Research the Claude Code environment variables CLAUDE_CODE_WORKFLOWS=1 and DISABLE_GROWTHBOOK=1.
Use WebSearch and WebFetch to find:
- What CLAUDE_CODE_WORKFLOWS does ...
- What DISABLE_GROWTHBOOK does ...
- Why both are needed together
- Any official Anthropic documentation, GitHub issues, community posts on Reddit/HN/Twitter
Return raw findings with sources/URLs. Be specific. If you can't find something, say so.`,
},
// ... 另外 4 个 query(ultrawork-keyword / workflow-tool-design / changelog-presence / growthbook-context)
// 结构完全相同,每个一段 prompt + label
]
const findings = await parallel(QUERIES.map(q => () =>
agent(q.prompt, { label: q.label, phase: 'Research' })
))
phase('Synthesize')
const labeledFindings = findings
.map((f, i) => f ? `### ${QUERIES[i].label}\n\n${f}` : null)
.filter(Boolean)
.join('\n\n---\n\n')
const summary = await agent(
`You are compiling research notes for a Chinese-language technical blog post...
Research findings:
${labeledFindings}`,
{ label: 'synthesize', phase: 'Synthesize' }
)
return { findings, summary }
5 个关键设计选择
① meta 必须是纯字面量
meta.phases 跟 body 里 phase('Research') / phase('Synthesize') 是同名匹配的——meta 登记,body push,UI 就知道每个 agent 归属哪个 phase。但 meta 必须是纯字面量,AST 解析器拒绝任何变量/拼接/调用,所以写 name: WORKFLOW_NAME 这种会直接报错。
② 每个 prompt 末尾都有 hallucination 抑制语
Return raw findings with sources/URLs. Be specific. If you can't find something, say so.
这是关键的 prompt 工程。research agent 默认有讨好倾向,「找不到」也要硬挤出来。这句话让它直接承认信息缺失,避免编造 URL 或来源。
③ parallel() 接收的是 thunk 不是 promise
QUERIES.map(q => () => agent(q.prompt, ...))
注意 q => () => agent(...) 这个两层箭头——直接写 q => agent(...) 会让 5 个 agent 在 .map() 这一步就已经全部 await 了,根本没并发。() => 把它包成 thunk,parallel() 内部才能按并发上限调度。这是 ultrawork 最容易踩的陷阱之一。
④ phase: 'Research' 显式参数胜过全局状态
agent(q.prompt, { label: q.label, phase: 'Research' })
5 个 agent 在 parallel() 里同时跑,如果只靠外层 phase('Research') 全局状态,会出现一个 agent 跑到中途时另一个上下文切到了 phase('Synthesize'),导致进度组归类错位。显式 phase 参数胜过全局状态,文档里反复强调的最佳实践。
⑤ .filter(Boolean) 是 ultrawork 的容错 idiom
findings
.map((f, i) => f ? `### ${QUERIES[i].label}\n\n${f}` : null)
.filter(Boolean)
parallel() 里某个 agent 崩了不会让整个 workflow 挂掉,对应位置返回 null。.filter(Boolean) 把 null 过滤掉,只把成功的结果喂给 synthesize。这是 ultrawork 容错的标准写法——永远 assume parallel 的某项可能为 null。
这份脚本没用的高级特性(下次可加杠杆)
| 特性 | 用法 | 这次为啥没用 |
|---|---|---|
schema(JSON Schema 强制结构化) |
agent(prompt, { schema }) |
research 输出 markdown 就够,没必要结构化 |
model: 'haiku' / 'sonnet' |
per-agent 选模型 | 全继承默认 Opus;下次搜索用 Sonnet 能省钱 |
isolation: 'worktree' |
每个 agent 独立 git worktree | 没并发改文件,不需要 |
agentType: 'Explore' |
调用具名 sub-agent 类型 | 用默认 workflow-subagent |
budget.remaining() |
动态决定还要不要继续 | 5 个角度预先决定,不需要动态调度 |
workflow('other-name') |
嵌套调用另一个 workflow | 单层即可 |
下次写更复杂的 workflow 这些杠杆全部可用——这就是 ultrawork 「能用 JS 写就能写在工作流里」 的真实含义。
这份脚本的实际产出
执行完通过 return { findings, summary } 把数据交回主对话:
findings:5 段原始 markdown(8.4 + 5.6 + 11.9 + 4.3 + 8.0 KB)summary:综合后的中文 markdown 笔记(成为本文第 5 节的雏形)
这份返回值连同完整脚本 + 6 份 agent transcript + 1 份 journal + 元数据 JSON 全部落盘到 ~/.claude/projects/<encoded-cwd>/ 下,下次想原样重跑或部分重跑(resume)随时可调。
完整的持久化结构(每一类文件是干嘛的、SHA-256 cache key 怎么用、prompt caching 怎么省 token、sidechain 怎么注入工具列表)我单独写了一篇配套深度解析放在 实际交互过程解析/ 子目录里,感兴趣的可以看。
8、总结
这是一篇关于一个官方没说、但确实存在、且 Windows / macOS / Linux 三平台都能用的能力的深度笔记。
8.1 关键事实回顾
- Workflow 工具:Claude Code 二进制里真实存在的多 Agent 编排能力,JS DSL(
agent/parallel/pipeline/phase/budget),确定性、可恢复。Anthropic 没在任何 changelog / docs 里公开,唯一公开技术资料是社区的ray-amjad/claude-code-workflow-creator。 - ultrawork 关键字:用户 opt-in 触发器,加在 prompt 任意位置就会让 Claude 拉起 Workflow 编排。
- 启动方式:
CLAUDE_CODE_WORKFLOWS=1 DISABLE_TELEMETRY=1 claude,Windows / macOS / Linux 通用。 - 真正生效的是
DISABLE_TELEMETRY=1:源码里CLAUDE_CODE_WORKFLOWS这个变量根本不存在,是个空票,保留它只是语义标记。真正解锁靠的是关掉 GrowthBook 轮询,让 L2 灰度门失去否决权。 - 架构是 L1 + L2 双门:L1 编译时(
feature()frombun:bundle,决定功能进不进二进制,Anthropic 改build_flags.yaml重新打包才能动)+ L2 运行时(GrowthBook 灰度,决定这个用户能不能用到)。两道必须同时为真。 - 为什么藏起来:成本兜底 + 远程 kill switch + 灰度放量 + SEV 响应。多 Agent 编排单 run 可能烧 10-50× 普通 session token,必须留多层治理钩子。
8.2 给读者的 5 条实用结论
- 想用 Workflow / ultrawork:v2.1.150 公开版已经把 L1 编译进二进制了,普通用户只要
DISABLE_TELEMETRY=1绕过 L2 灰度即可(如果哪天 Anthropic 把 L1 翻回 false,那就只能拿 Anthropic 内部源码重新构建了)。 - 想关掉灰度 / 分析、保留正常网络功能:
DISABLE_TELEMETRY=1 claude一条搞定,副作用最小。 - 想彻底切断云端控制面:
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 claude,只保留模型对话,但代价是你也拿不到任何灰度放量的新功能了。 - 想完全零接触 Anthropic 服务器:上面再加
CLAUDE_CODE_USE_BEDROCK=1(或 VERTEX / FOUNDRY),推理走云厂商,全套断网。 - 看不到某个新功能不一定是 bug:可能你只是没被放进灰度白名单(L2 没翻),也可能是 ant-only(L1 都没编译进你的包)。先别急着提 issue。
8.3 一句忠告
开了之后别把 ultrawork 当口头禅用。一句 “ultrawork 帮我看下这个 bug” 跑完可能就是十几个 sub-agent 的 token 账单。这个开关是给真需要并行扇出 / 多角度审查 / 大范围扫描的场景准备的,问答和小修小改用普通模式就够了。
关键源码文件清单(v2.1.150 快照)
src/tools.ts—— Workflow 工具加载入口src/commands.ts—— Workflow 命令加载入口src/tasks.ts—— Workflow 任务加载入口src/constants/tools.ts—— Workflow 工具名常量src/components/tasks/BackgroundTasksDialog.tsx——WORKFLOW_SCRIPTS is ant-only那段注释src/services/analytics/growthbook.ts—— GrowthBook 客户端完整实现(1156 行)src/services/analytics/config.ts——isAnalyticsDisabled判定src/services/analytics/firstPartyEventLogger.ts——is1PEventLoggingEnabledsrc/utils/privacyLevel.ts—— 三档隐私级别定义src/utils/managedEnvConstants.ts—— 官方支持的运行时环境变量清单src/utils/envUtils.ts——isEnvTruthy实现src/utils/config.ts——growthBookOverrides、cachedGrowthBookFeatures、cachedStatsigGates字段
主要参考资料
- Claude Code 官方 env vars 文档
- Claude Code 官方 Agent Teams 文档
- ray-amjad/claude-code-workflow-creator(Workflow 工具唯一公开技术资料)
- Claude Code Hidden Multi-Agent System
- The Claude Code Source Leak 深度解读
- Claude Wiki:79+ tengu_ flag 目录
- Multi-Agent Coordination Patterns(Anthropic 官方博客)
- GrowthBook 平台
- Bun 内置模块
bun:bundle(feature() 与编译时 flag)

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)