直播带货视频批量处理方案:AI 换句、音色克隆与智能剪辑
随着直播带货逐渐进入长时间、多账号、矩阵化运营阶段,传统人工剪辑已经很难满足直播素材的处理需求。尤其是长视频直播场景,一场直播往往持续数小时,如果依赖人工逐句修改文案、手动剪辑画面以及重新处理音频,不仅效率低,而且很难实现批量化处理。因此,目前越来越多直播团队开始使用 AI 自动化剪辑流程,对直播内容进行统一处理。;相比传统剪辑软件,这类系统更偏向:自动化直播素材处理工作流。
随着直播带货逐渐进入长时间、多账号、矩阵化运营阶段,传统人工剪辑已经很难满足直播素材的处理需求。尤其是长视频直播场景,一场直播往往持续数小时,如果依赖人工逐句修改文案、手动剪辑画面以及重新处理音频,不仅效率低,而且很难实现批量化处理。
因此,目前越来越多直播团队开始使用 AI 自动化剪辑流程,对直播内容进行统一处理。整个流程通常包括:AI换句、音色克隆、音频重组、视频抽帧、字幕重组、自动推流;
相比传统剪辑软件,这类系统更偏向:自动化直播素材处理工作流。
一、为什么直播带货开始依赖 AI 批量处理?
传统直播剪辑通常需要:手动导出字幕、手动修改直播话术、手动重新配音、手动调整画面结构、手动重新推流,如果只是处理单条视频,问题并不明显。
但在:店播挂机、无人直播、多账号矩阵、长视频循环直播等场景下。人工处理成本会明显增加。尤其是平台对直播内容识别越来越严格后,简单的:裁剪、镜像、滤镜、变速,已经很难满足实际需求。
目前平台已经开始从:画面特征、音频内容、字幕文本、语义结构、时间轴节奏等多个维度识别内容相似度。因此,AI 自动化处理开始成为直播录播领域的新方向。
二、AI 换句是如何工作的?
目前很多 AI 剪辑系统,都会先对直播语音进行识别。
系统会自动:提取主播语音、生成字幕文本、建立时间轴、分析直播话术结构随后进入 AI 换句阶段。例如:原直播内容:这个裙子特别显瘦 —— 这款半裙整体会更修饰身材。
这里并不是简单关键词替换。而是结合:近义词替换、语序调整、口语化改写、节奏同步等进行整体语义重组。
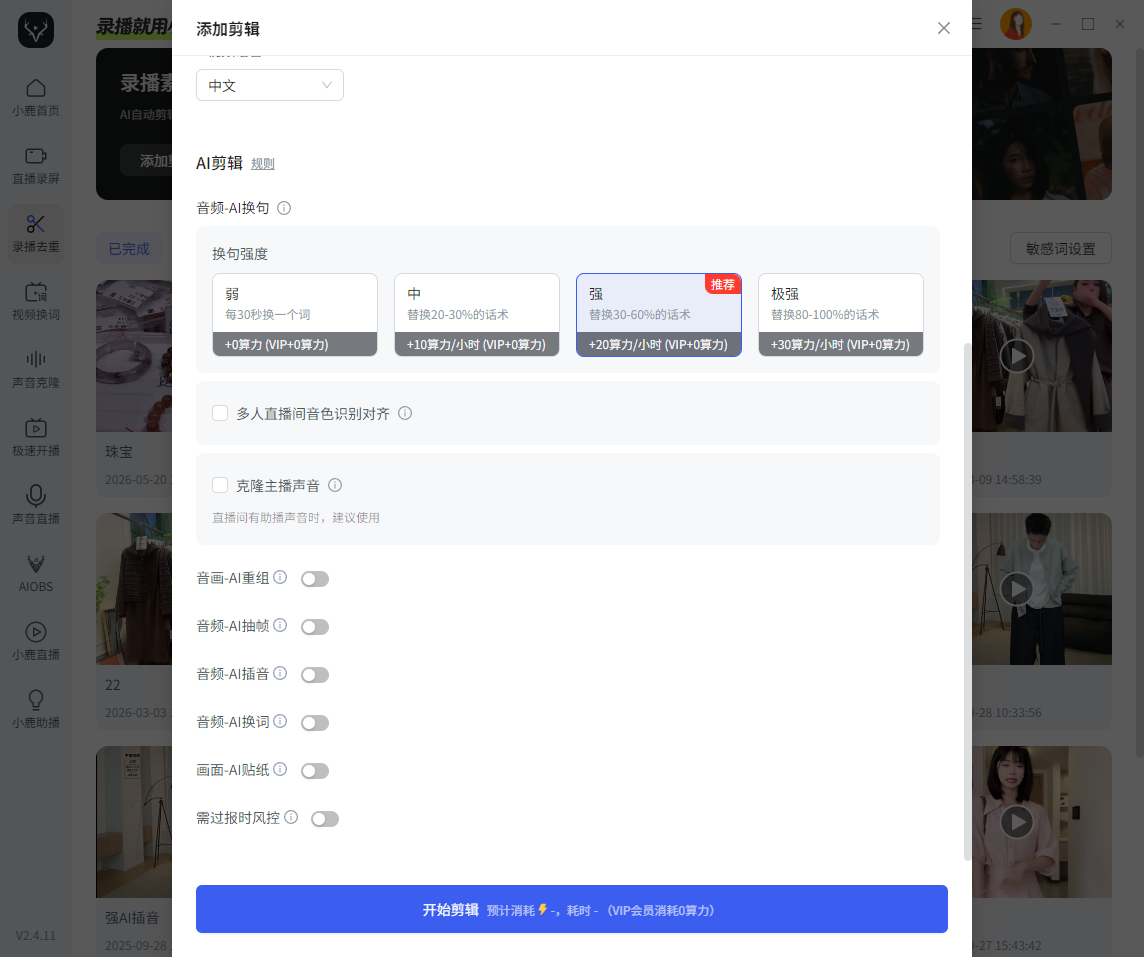
同时系统还需要保证:字幕长度、配音时长、语音节奏、停顿逻辑等保持相对稳定。
否则容易出现:配音读不完、字幕错位、音频停顿异常等问题。因此很多系统会限制:替换前后字数尽量接近。本质上属于语音时长控制问题。
三、音色克隆与音频重组
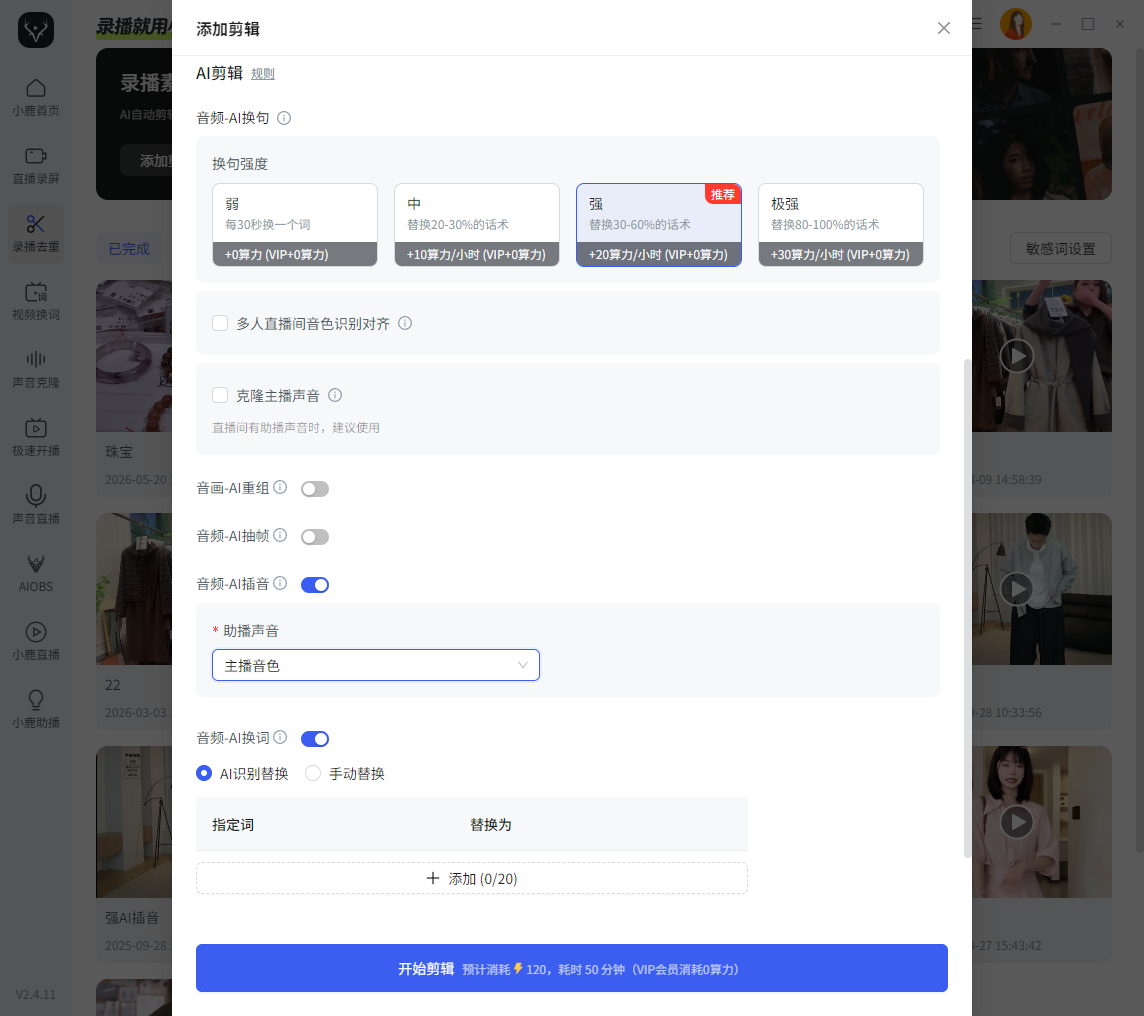
除了文案层面的改写。目前 AI 系统还会同步处理音频内容。
常见功能包括:音色克隆、AI插音、语气词补全、音频重组、多人声音识别等其核心目的,是建立:音频层面的差异化。
例如部分直播场景中,主播语速较快、口语化严重或者多人同时讲话。系统会先进行:人声分离、声纹识别、音频对齐等再进行后续 AI 配音与语音重组。
目前一些直播处理工具(如小鹿播这类 AI 剪辑系统)已经支持:多人直播声音识别、AI换句、AI插音、AI抽帧、AI贴纸等功能。整体逻辑已经逐渐从“传统剪辑”,转向:AI 自动化内容处理。
四、直播带货视频批量处理的完整流程
目前较常见的 AI 工作流,通常包括:首先通过直播录制模块采集直播内容,随后系统自动提取语音与字幕,并建立时间轴结构。接着进入 AI 换句阶段,对直播话术进行语义重组,同时同步处理音频、字幕以及画面内容。完成后,系统会自动生成多个不同版本的视频素材,并进入推流或循环直播阶段。
相比传统人工剪辑。现在很多直播团队更偏向:自动化批量处理。因为长视频直播场景下,真正消耗时间的并不是开播,而是:内容整理、文案修改、视频重组、多版本生成等AI 工作流最大的意义,其实是降低人工干预,提高直播素材处理效率。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)