Qwen3-VL-Seg 深度解读:当多模态大模型学会“像素级精准手术“,仅用0.4%参数碾压8B模型
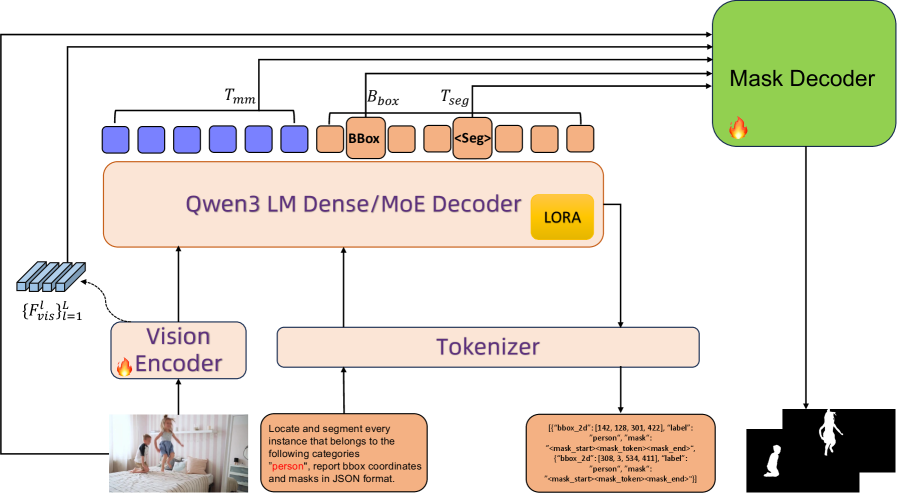
本文提出Qwen3-VL-Seg,一个参数高效的框架,将MLLM预测的边界框视为语义锚定的结构先验,通过轻量级边界框引导的掩码解码器将其解码为像素级分割。Qwen3-VL-Seg相比backbone Qwen3-VL,分割任务的训练让定位精度也提升了——RefCOCO Val从90.7%→92.7%,RefCOCO+ TestB从75.6%→82.2%(+6.6%)。当你对AI说"把图片里那个穿着

向AI转型的程序员都关注公众号 机器学习AI算法工程
当你对AI说"把图片里那个穿着米色帽子、背着蓝色背包的人抠出来"——现有的多模态大模型能精准地画个矩形框告诉你"人在这儿",但当你需要像素级的精确轮廓(比如做图像编辑、机器人抓取、医学影像分析)时,那个粗糙的矩形框完全不够用。
这就是 Open-World Referring Segmentation(开放世界指代分割)要解决的问题:将自然语言描述锚定到精确的像素级区域。而阿里通义实验室最新发布的 Qwen3-VL-Seg,给出了一个令人惊艳的答案。
论文:Qwen3-VL-Seg: Unlocking Open-World Referring Segmentation with Vision-Language Grounding
地址:https://arxiv.org/abs/2605.07141
机构:阿里巴巴通义实验室(Tongyi Lab)
发布时间:2026年5月8日
一、痛点:从"画框"到"描边"的鸿沟
过去的方法走两条极端路线:
- 🔴 SAM外挂派
(LISA、GSVA等):MLLM出框,SAM出mask。效果好,但SAM带来巨大参数开销和部署复杂度。
- 🔵 原生轻量派
(Text4Seg、UFO等):直接在MLLM上加轻量分割头,但边界恢复能力差,"切不准"。
Qwen3-VL-Seg 的核心洞察:MLLM预测的边界框不是终点,而是一个语义grounded的结构先验。与其把框扔掉再让SAM重猜,不如让框全程引导mask解码过程。
💡 一句话总结创新:基于此,作者设计了一个仅17M参数(占基础模型0.4%)的轻量级Box-Guided Mask Decoder,在4B参数规模上实现了超越8B模型的分割精度,且无需任何外部分割模型。
二、论文摘要:一句话看懂
开放世界指代分割要求将不受约束的语言表达锚定到精确的像素级区域。现有MLLM展现出强大的开放世界视觉定位能力,但输出仍局限于稀疏边界框。本文提出Qwen3-VL-Seg,一个参数高效的框架,将MLLM预测的边界框视为语义锚定的结构先验,通过轻量级边界框引导的掩码解码器将其解码为像素级分割。仅引入17M参数(基础模型的0.4%)。同时构建了SA1B-ORS(299万样本)训练集和ORS-Bench评测基准,在开放世界和封闭集设置下均表现强劲。
三、核心原理:Box 不是终点,而是先验
传统思路把MLLM的box输出当作"副产品"——模型既然要分割,那box就顺手预测一下。但Qwen3-VL-Seg反其道而行:Box是MLLM对"目标在哪里"的最强语义-空间耦合表达,它同时携带了:
- 语义信息:
框内的内容与语言描述对齐
- 空间信息:
目标的位置、尺度、长宽比
- 实例身份:
在复杂场景中区分不同实例
因此,作者提出边界框引导的掩码解码范式:让边界框作为结构先验,贯穿mask解码的全过程——从查询构建、像素融合到迭代精炼。这相当于告诉解码器:"目标大概在这个区域,语义上是'那个人',请在这个约束下精细描边。"
四、架构深潜:四大模块的精密协作
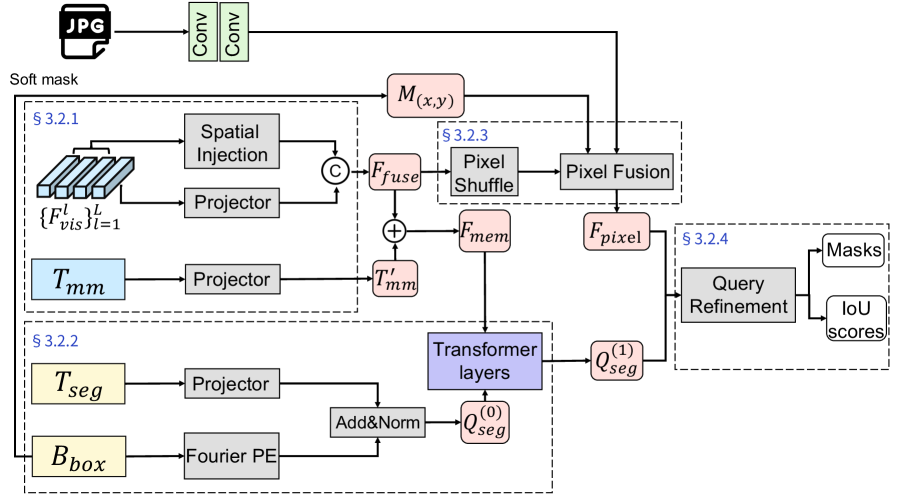
4.1 多尺度空间特征注入
高层MLLM特征太粗糙,无法支撑精确的边界描绘。作者提取中间层的视觉特征,通过轻量级的SpatialFeatureInjector适配:
F̃ₗ = X₀⁽ˡ⁾ + s · GELU(DWConv(GroupNorm(X₀⁽ˡ⁾)))其中 s 是一个可学习的标量参数,初始化为 10⁻³,这种近零初始化使适配器在微调初期近似于恒等映射,稳定优化过程。最终记忆特征融合多层级空间信息与语言对齐的多模态语义,为解码器提供密集表征。
4.2 空间-语义查询构建
目标查询需要同时捕获语义信息和空间身份。作者利用MLLM预测的边界框作为显式条件信号:
Bbox = (x₁, y₁, x₂, y₂)Ebox = γ(x₁) ⊕ γ(y₁) ⊕ γ(0.2·log w + 0.5) ⊕ γ(0.2·log h + 0.5)Qseg⁰ = LayerNorm(MLPbox(Ebox) + Wseg·Tseg)Qseg¹ = Decoder(Qseg⁰, Fmem)查询不再是仅依赖语言来"检索"目标,而是从一个已经grounded的空间先验出发,极大降低了在复杂场景中定位目标的难度。
4.3 Box引导的高分辨率像素融合
为恢复精细的边界细节,模型从原始输入图像提取浅层CNN特征,然后利用边界框构造软空间门控:
M(x,y) = σ(α(x-x'₁)) · σ(α(x'₂-x)) · σ(α(y-y'₁)) · σ(α(y'₂-y))
四个sigmoid项分别控制左、右、上、下方向的衰减:在扩展框内部接近1,外部被抑制。最终将门控后的浅层特征与上采样视觉特征融合:
Fpixel = Fup ⊕ (M(x,y) ⊙ Fcnn)
这种设计注入高频率局部细节,同时抑制grounded区域外的背景干扰。
4.4 迭代Mask感知查询精炼
单轮mask预测对细薄结构或杂乱场景来说往往不够。模型先用初始mask对像素特征进行目标感知池化,提取精炼信号再"回注"到查询中:
Ftar = Σ(σ(Mlogit¹) ⊙ Fpixel) / (Σσ(Mlogit¹) + ε) Qseg² = LayerNorm(Qseg¹ + φref(Ftar)) Mlogit² = Ψ(Qseg², Fpixel)
这种"预测→反馈→再预测"的迭代循环,建立了查询预测与像素证据之间的显式交互,类似人类先圈出大致范围,再基于第一次描边结果精细修正。
五、数据引擎:SA1B-ORS 与 ORS-Bench
好模型需要好数据。开放世界指代分割的最大瓶颈是缺乏大规模、多样化、语言-像素对齐的训练数据。
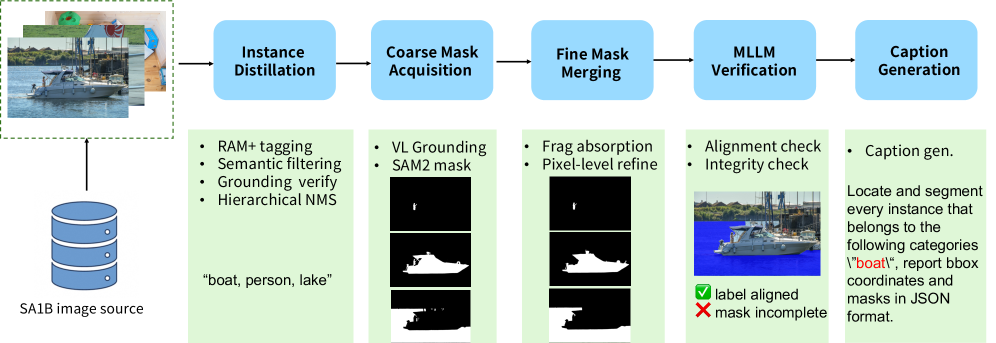
5.1 SA1B-ORS 训练集
从SA-1B的200万张原始图像中,作者构建了两个互补子集,总计299万样本:
|
子集 |
样本数 |
特点 |
构建流程 |
|---|---|---|---|
| SA1B-CoRS |
105万 |
类别导向,一个表达可指代同类多个实例 |
实例蒸馏 → 粗mask获取 → 细mask合并 → MLLM验证 → 指代标题生成 |
| SA1B-DeRS |
194万 |
描述性实例级,需属性/关系/上下文区分 |
指令策划(五维度)→ 认知验证(IoU>0.8过滤)→ 显著性选择 |
描述性指令占比高达64.8%,词云显示大量空间介词(in, above, left)和属性形容词(blue, dark, visible),确保开放世界特性。
5.2 ORS-Bench 评测基准
现有基准词汇封闭,无法评估真正的开放世界能力:
- ORS-ID-Bench:
9,055人工筛选样本,覆盖4种指令格式
- ORS-OOD-Bench:
6种分布偏移维度(类别/尺度/指令复杂度/遮挡/光照/风险敏感场景),每维约200个挑战性样本
⚠️ 重点:风险敏感场景包括自动驾驶和医学诊断,这些场景在训练数据中几乎完全不存在,是所有方法的共同挑战。

六、实验条件与训练策略
6.1 两阶段训练
|
阶段 |
目标 |
训练设置 |
数据配比 |
|---|---|---|---|
| Stage 1 |
建立指代分割能力 |
LLM用LoRA,Vision Encoder和Mask Decoder全可调 |
RefCOCO系列 + SA1B-ORS |
| Stage 2 |
恢复通用能力,保持分割性能 |
合并LoRA权重,LLM backbone和Mask Decoder全微调,Vision Encoder冻结 |
指代分割:通用理解:多模态推理 = 3:1:2 |
Stage 2中,推理数据通过 Qwen3-VL-Instruct进行离线蒸馏生成STEM聚焦数据。这种设计确保模型不会变成"只会分割的偏科生"。
6.2 评测指标
- 分割任务:
mIoU(每样本平均IoU)、cIoU(全局IoU)、P@t(mask IoU超过阈值 t ∈ {0.5, 0.7, 0.9} 的样本比例)
- 定位任务(REC):
Prec@0.5(预测框与GT IoU > 0.5的比例)
- 多实例设置:
匈牙利算法匹配预测与GT mask后计算指标
七、实验结果:硬核数据说话
7.1 封闭集指代分割(RES)
|
方法 |
RefCOCO Val |
TestA |
TestB |
RefCOCO+ Val |
TestA |
TestB |
RefCOCOg Val |
Test |
|---|---|---|---|---|---|---|---|---|
|
LISA-7B |
74.9 |
79.1 |
72.3 |
65.1 |
70.8 |
58.1 |
79.3 |
80.4 |
|
GSVA-7B |
86.3 |
89.2 |
83.8 |
72.8 |
78.8 |
68.0 |
81.6 |
81.8 |
|
UFO-8B |
91.4 |
93.8 |
88.2 |
85.7 |
90.7 |
79.7 |
86.8 |
87.4 |
|
Text4Seg-8B |
90.3 |
93.4 |
87.5 |
85.2 |
89.9 |
79.5 |
85.4 |
85.4 |
| Qwen3-VL-Seg-4B | 92.7 | 94.6 | 89.8 | 87.8 | 92.1 | 82.2 | 89.1 | 89.0 |
关键发现:Qwen3-VL-Seg-4B在6/8个评测split上取得最佳,是唯一在4B规模超越8B模型(UFO-8B、Text4Seg-8B)的方法。相比SAM-based的LISA,在RefCOCO Val上提升7.4分,RefCOCO+ TestB提升12.7分。
7.2 视觉定位(REC)
Qwen3-VL-Seg相比backbone Qwen3-VL,分割任务的训练让定位精度也提升了——RefCOCO Val从90.7%→92.7%,RefCOCO+ TestB从75.6%→82.2%(+6.6%)。这说明像素级监督能反向精炼MLLM的空间感知能力。
7.3 开放世界指代分割
|
方法 |
单实例cIoU |
多实例cIoU |
短语指令cIoU |
描述性指令cIoU |
|---|---|---|---|---|
|
Gemini-2.5-pro |
77.7 |
75.9 |
58.7 |
44.6 |
|
Seed-2.0-pro |
65.4 |
66.4 |
63.8 |
61.0 |
|
UFO-8B |
72.4 |
- |
52.1 |
73.7 |
|
SAM3 |
94.2 |
94.6 |
66.6 |
75.5 |
| Qwen3-VL-Seg | 96.0 | 93.2 | 82.8 | 91.0 |
碾压级表现:7/8指标最佳。语言密集型场景优势巨大:短语指令cIoU超越最佳基线+19.0,描述性指令cIoU超越+15.5。通用MLLM在简单类别指令上尚可,遇到复杂描述(如"从底部数第二个瓶子")性能断崖式下跌。
7.4 分布外泛化
ORS-OOD-Bench六维度评测:类别偏移53.49%、实例尺度59.30%、指令复杂度86.22%、光照变化78.9%、遮挡83.45%、风险敏感场景8.64%。尽管全面领先,但在自动驾驶、医学诊断等风险敏感场景中,所有方法都"翻车"(cIoU仅8.64%),揭示了开放世界分割在安全关键领域仍有巨大提升空间。
7.5 通用多模态能力保持
Stage 2训练后,模型在MMStar、MMMU、MathVision等推理基准上基本恢复了原始backbone水平,在CharXiv(图表解析)和RealWorldQA上甚至超越了原始backbone。证明两阶段策略成功——不是"偏科生",而是"全能选手"。
7.6 消融实验
|
变体 |
RefCOCO cIoU |
P@0.5 |
P@0.7 |
P@0.9 |
|---|---|---|---|---|
|
Qwen box+SAM |
70.3 |
83.2 |
76.9 |
39.6 |
|
Ours (freeze vit) |
80.9 |
92.8 |
87.0 |
44.1 |
|
Ours (w/o multivit) |
81.9 |
92.7 |
88.7 |
49.0 |
|
Ours (w/o image) |
81.9 |
92.8 |
88.7 |
48.0 |
| Ours (full) | 82.3 | 92.8 | 88.7 | 50.2 |
关键结论:冻结ViT严重损害精度(P@0.9掉6.1分);多尺度特征和浅层图像分支缺一不可;各组件的增益在严格阈值P@0.9最明显,说明它们共同作用于边界质量而非粗略定位。

八、实战代码:用Qwen3-VL做指代分割
虽然Qwen3-VL-Seg的官方代码尚未开源(截至2026年5月25日),但我们可以用Qwen3-VL的grounding能力 + SAM2实现一个类似效果的全流程demo,体验"语言描述→像素级分割"的完整链路:
方案一:Qwen3-VL + SAM2 指代分割(推荐尝鲜)
# 安装依赖# pip install torch transformers opencv-python pillow# pip install git+https://github.com/facebookresearch/sam2.gitimport torchimport numpy as npimport cv2from PIL import Imagefrom transformers import AutoProcessor, Qwen3VLForConditionalGeneration# 1. 加载 Qwen3-VL (用于目标检测和定位)model = Qwen3VLForConditionalGeneration.from_pretrained( "Qwen/Qwen3-VL-4B-Instruct", device_map="auto", torch_dtype=torch.bfloat16, attn_implementation="sdpa")processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Instruct")image_path = "demo.jpg"image = Image.open(image_path)# 2. 用自然语言描述目标prompt = "Locate and segment the person wearing a red hat in the image"messages = [ { "role": "user", "content": [ {"type": "image", "image": image_path}, {"type": "text", "text": prompt + ", return bbox coordinates in JSON format."} ] }]# 3. 获取边界框inputs = processor.apply_chat_template( messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt").to(model.device)generated_ids = model.generate(**inputs, max_new_tokens=256)output = processor.batch_decode( [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)], skip_special_tokens=True)[0]print("检测结果:", output)# 解析JSON获取bbox: [x1, y1, x2, y2]# 4. 将bbox送入SAM2得到精确mask# from sam2.build_sam import build_sam2# from sam2.sam2_image_predictor import SAM2ImagePredictor## sam2_model = build_sam2(config, checkpoint)# predictor = SAM2ImagePredictor(sam2_model)## image_cv = cv2.imread(image_path)# predictor.set_image(image_cv)## masks, scores, _ = predictor.predict(# box=bbox_array,# multimask_output=False# )# cv2.imwrite("output_mask.png", masks[0].astype(np.uint8) * 255)方案二:模拟Qwen3-VL-Seg思路(PyTorch伪代码)
"""以下代码演示Qwen3-VL-Seg的Box-Guided Mask Decoder核心设计思路,帮助理解其"框即先验"的哲学"""import torchimport torch.nn as nnimport torch.nn.functional as Fclass BoxGuidedMaskDecoder(nn.Module): """Box-Guided Mask Decoder (17M params)""" def __init__(self, hidden_dim=256): super().__init__() # 1. 多尺度空间特征注入 self.spatial_injectors = nn.ModuleList([ self._make_spatial_injector(hidden_dim) for _ in range(4) # 4个scale ]) self.fuse_conv = nn.Conv2d(hidden_dim * 4, hidden_dim, 1) # 2. 空间-语义查询构建 self.box_mlp = nn.Sequential( nn.Linear(256, hidden_dim), nn.LayerNorm(hidden_dim) ) self.query_proj = nn.Linear(hidden_dim, hidden_dim) # 3. 解码器Transformer decoder_layer = nn.TransformerDecoderLayer( d_model=hidden_dim, nhead=8, dim_feedforward=1024, dropout=0.0 ) self.decoder = nn.TransformerDecoder( decoder_layer, num_layers=3 ) # 4. 高分辨率像素融合 self.stem = nn.Sequential( # 轻量CNN提取浅层特征 nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.GELU(), nn.Conv2d(64, hidden_dim, kernel_size=3, padding=1) ) self.upsample = nn.PixelShuffle(2) # 5. 迭代Mask预测 self.dynamic_head = nn.Linear(hidden_dim, hidden_dim) self.refine_proj = nn.Linear(hidden_dim, hidden_dim) def _make_spatial_injector(self, dim): return nn.Sequential( nn.GroupNorm(32, dim), nn.Conv2d(dim, dim, 3, padding=1, groups=dim), # DWConv nn.GELU() ) def build_box_encoding(self, boxes): """傅里叶编码边界框""" x1, y1, x2, y2 = boxes.unbind(-1) w, h = x2 - x1, y2 - y1 # 对数尺度变换 + 傅里叶编码 box_feat = torch.stack([ x1, y1, 0.2 * torch.log(w + 1e-6) + 0.5, 0.2 * torch.log(h + 1e-6) + 0.5 ], dim=-1) return box_feat # 实际应使用sin/cos编码 def build_spatial_gate(self, boxes, H, W, device): """构建软空间门控 (公式12)""" x1, y1, x2, y2 = boxes.unbind(-1) # 扩展15%容差 margin = 0.15 cx, cy = (x1 + x2) / 2, (y1 + y2) / 2 half_w, half_h = (x2 - x1) / 2, (y2 - y1) / 2 x1_e = cx - half_w * (1 + margin) y1_e = cy - half_h * (1 + margin) x2_e = cx + half_w * (1 + margin) y2_e = cy + half_h * (1 + margin) ys = torch.linspace(0, 1, H, device=device).view(-1, 1) xs = torch.linspace(0, 1, W, device=device).view(1, -1) alpha = 20.0 gate = (torch.sigmoid(alpha * (xs - x1_e)) * torch.sigmoid(alpha * (x2_e - xs)) * torch.sigmoid(alpha * (ys - y1_e)) * torch.sigmoid(alpha * (y2_e - ys))) return gate.unsqueeze(0) # [1, H, W] def forward(self, multi_scale_feats, text_feat, mm_feat, boxes, image): """ Args: multi_scale_feats: ViT多尺度特征列表 text_feat: 分割token特征 [1, dim] mm_feat: 多模态视觉嵌入 [1, N, dim] boxes: MLLM预测框 [1, 4] image: 原始图像 [1, 3, H, W] """ # Step 1: 多尺度空间特征注入 adapted = [] for feat, injector in zip( multi_scale_feats, self.spatial_injectors ): adapted.append(injector(feat)) fused = self.fuse_conv(torch.cat(adapted, dim=1)) # Step 2: 构建解码器记忆 B, C, H, W = fused.shape mm_map = mm_feat.view(B, -1, H, W) # 重塑为2D memory = mm_map + fused # 多模态+空间特征 # Step 3: 构建空间-语义查询 box_enc = self.build_box_encoding(boxes) box_query = self.box_mlp(box_enc) seg_query = self.query_proj(text_feat) query = F.layer_norm(box_query + seg_query, [query_dim]).unsqueeze(0) # Step 4: Transformer解码 memory_flat = memory.flatten(2).permute(2, 0, 1) decoded = self.decoder(query.permute(1, 0, 2), memory_flat) # Step 5: Box引导的高分辨率像素融合 shallow = self.stem(image) gate = self.build_spatial_gate( boxes, H*2, W*2, image.device ) up_fused = self.upsample(fused) pixel_feat = up_fused + gate * shallow # Step 6: 动态mask预测 kernel = self.dynamic_head(decoded[-1]) mask_logit = torch.einsum( 'bd,bdhw->bhw', kernel, pixel_feat ) # Step 7: 迭代精炼 pooled = (torch.sigmoid(mask_logit).unsqueeze(1) * pixel_feat).sum(dim=(2, 3)) / \ (torch.sigmoid(mask_logit).sum() + 1e-6) refined = decoded[-1] + self.refine_proj(pooled) refined = F.layer_norm(refined, [refined.size(-1)]) kernel2 = self.dynamic_head(refined) mask_refined = torch.einsum( 'bd,bdhw->bhw', kernel2, pixel_feat ) return F.interpolate( mask_refined.unsqueeze(0), size=image.shape[-2:], mode='bilinear' )📌 说明:官方Qwen3-VL-Seg代码尚未公开。以上方案一使用现有开源工具实现了"检测+分割"的全流程;
方案二基于论文公式还原了核心架构设计,帮助理解原理。关注GitHub仓库 github.com/QwenLM/Qwen3-VL 获取官方代码更新。
九、创新点总结
|
创新维度 |
具体贡献 |
|---|---|
| 范式创新 |
提出面向开放世界指代分割的全链路Box结构先验机制 |
| 架构创新 |
17M参数Box-Guided Mask Decoder的SAM-free轻量化架构,4B基座精度达同期8B级SAM-free方法水平 |
| 数据创新 |
构建SA1B-ORS(约299万样本),含类别导向和描述性双轨监督 |
| 评测创新 |
ORS-Bench首个系统评测开放世界指代分割的ID/OOD基准,覆盖6种分布偏移 |
| 训练创新 |
分割适应与通用能力协同的两阶段训练策略 |
十、应用场景
- 🖼️ 智能图像编辑:
"把左边穿红衣服的人抠出来换背景" → 直接输出精确mask
- 🤖 机器人视觉抓取:
"拿起桌子上那个带把手的蓝色杯子" → 像素级mask引导机械臂
- 🏥 医学影像分析:
"分割CT中左肺上叶那个不规则结节" → 开放世界描述+精确边界
- 🚗 自动驾驶感知:
ORS-OOD-Bench已包含自动驾驶场景
- 🛒 电商/内容审核:
"标记图片中所有未授权的品牌Logo"
- 🥽 AR/VR交互:
自然语言描述选中虚拟场景中的物体进行交互
十一、结论与展望
Qwen3-VL-Seg证明了一个重要命题:MLLM的开放世界理解能力与像素级精确分割之间,并非必须依赖SAM这样的"重型桥梁"。通过将边界框作为全链路的结构先验加以系统化利用,作者以仅17M参数的轻量decoder实现了高质量的像素级分割。
这项工作也为未来指明了几个方向:
- 风险敏感场景的OOD泛化
仍是全行业痛点(cIoU仅8.64%),需要更强的领域自适应
- 多模态能力的进一步统一:
Stage 2的恢复策略已验证可行,未来或许实现"分割-理解-推理"的真正三位一体
- 更小规模的部署:
4B模型已能在边缘设备运行,17M的decoder开销极低,为手机端实时开放世界分割提供了可行路径
对于关注多模态大模型落地的朋友,这篇论文展示了重要的技术进展,更是"轻量专用模块+强大基础模型"这一范式的优秀范例——避免了参数堆砌与外挂重型模型,而是通过巧妙的架构设计对现有能力进行充分挖掘与高效利用。
📎 论文原文链接
HTML全文:https://arxiv.org/html/2605.07141v1
PDF下载:https://arxiv.org/pdf/2605.07141v1
GitHub:https://github.com/QwenLM/Qwen3-VL
HuggingFace:huggingface.co/Qwen/Qwen3-VL-4B-Instruct
阅读过本文的人还看了以下文章:
14.7M参数,小目标AP达到13.9%!FSDETR用频空融合重新定义目标检测
skill刚开源就斩获 1.7K Star!web-access让AI真正"上网"
引入小目标注意力模块改进YOLO12用于无人机视角下的岸边人员玩水检测
pdf2skill:让计算机视觉初学者把PDF文档变成AI技能包
next-ai-draw-io 用这款AI 画图几十秒就搞定了
10 万文档 RAG 落地实战:从 Demo 到生产,我踩过的所有坑
YOLO12改进引入DINOv3少样本目标检测精度飙升,分享训练自定义数据集代码
Ultralytics & lightly-train:简化计算机视觉模型训练,无需标签
【医学影像分割】UN-SAM:一种高效且通用的细胞核分割模型
【模型高效部署】tensorrtx 深度解读,yolov11高性能推理实战案例
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)