微软 1000 行代码,把 Claude Opus 干翻了 15 分
点击上方前端Q,关注公众号回复加群,加入前端Q技术交流群5 月 24 日,微软研究院 AI Frontiers 实验室在 GitHub 扔出了一个名叫的开源项目。我第一眼看到 README 的时候,反应是有点没看懂——这玩意儿真的就只有 1000 行核心代码?而 Webwright 本身只有大约 1000 行 Python 代码,没有多 Agent 编排、没有 graph engine、没有 pl
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
5 月 24 日,微软研究院 AI Frontiers 实验室在 GitHub 扔出了一个名叫 Webwright 的开源项目。
我第一眼看到 README 的时候,反应是有点没看懂——这玩意儿真的就只有 1000 行核心代码?
往下翻到 benchmark,我又愣了一下:
| 模型 / 框架 | Odysseys 得分 |
|---|---|
| Webwright + GPT-5.4 | 60.1% |
| Claude Opus 4.6(4 月 leaderboard 第一) | 44.5% |
| 基线 GPT-5.4(裸调) | 33.5% |
Webwright 加上 GPT-5.4,把 Claude Opus 4.6 干翻了 15.6 个百分点。
而 Webwright 本身只有大约 1000 行 Python 代码,没有多 Agent 编排、没有 graph engine、没有 plugin layer,依赖只有 httpx、pydantic、playwright、typer 四个。
我读完整套源码和论文页(microsoft.github.io/Webwright),有个非常强烈的感受:
这是过去半年我看到的最像"工程范式宣言"的一篇 paper。它在告诉所有人:Web Agent 这个赛道,过去一年大家都做得太复杂了。
这一篇我把这件事完整梳理一遍:Webwright 到底干了什么、它凭什么 1000 行就能反超 Claude、它背后的设计哲学是什么、对你今天做 AI Agent 的方式意味着什么。

先把 benchmark 数字拆开看
很多人看到"开源框架反超 Claude"会怀疑:是不是 cherry-pick 了某个特殊场景?
我把微软官方公布的 4 个测试数字摆出来,你就知道这次不是营销话术。
▎Odysseys:长链路多网站任务
Odysseys 是个相对硬的 benchmark,任务平均 272.3 个词的指令长度,要跨多个网站完成长链路操作。
▸Webwright + GPT-5.4:60.1%
▸4 月份 leaderboard 第一名 Claude Opus 4.6:44.5%
▸单跑 GPT-5.4 基线:33.5%
也就是说——给 GPT-5.4 套上 Webwright 这层 harness,相对提升 79.4%。
▎Online-Mind2Web:100 步预算的真实网页
这是另一个广泛使用的 Web Agent 测试集:
▸Webwright + GPT-5.4:86.7%
▸Webwright + Qwen3.5-9B(小开源模型)在 hard split 上:66.2%
注意第二条数据——一个只有 9B 参数的开源模型,套上 Webwright + 几条预置工具脚本,就能在 hard split 上跑到 66.2%。这意味着 harness 这一层的设计,可以让小模型的工程效用直接对齐大模型。
▎我自己最在意的一个数字
微软在 paper 里有一段话我反复看了好几遍:
"the harness is approximately 1,000 lines of code across three modules: Runner, Model Endpoint, and Environment."
Runner ~450 行,Playwright Environment ~570 行,CLI ~150 行。
加起来 ~1170 行 Python。
对比一下:
| 项目 | 代码量级 |
|---|---|
| LangGraph | 数十万行 |
| CrewAI | 数万行 |
| OpenAI Agents SDK | 数万行 |
| Claude Code (源码泄露版) | 51 万行 |
| Webwright | ~1000 行 |
它在做减法做到了一种极致。
Webwright 的设计哲学:把模型当成程序员,不是当成点击工人
这才是真正值得反复品的部分。
过去一年所有的浏览器 Agent,思路是这样的:
▸给 Agent 一个有状态的浏览器会话
▸每一步让 Agent 预测一个离散动作(点击哪里、输入什么、滚到哪)
▸用 DOM 或者无障碍树作为模型的输入
▸模型一步一步指挥浏览器
Cursor 的 BrowserUse、OpenAI 的 Operator、Anthropic 的 Computer Use,本质上都是这一套。
Webwright 反着来。
它的核心思路用一句话讲:
"A terminal is all you need for web agents."(一个终端就够了)
具体怎么做:
▸给 Agent 一个 本地终端 + 工作目录
▸Agent 不预测"点击/输入"动作,而是 写 Playwright 代码 + bash 命令
▸执行完之后 Agent 看终端输出(日志、截图、错误栈),然后继续写下一段代码
▸任务跑完,留下的是一个可重跑的 Python 脚本
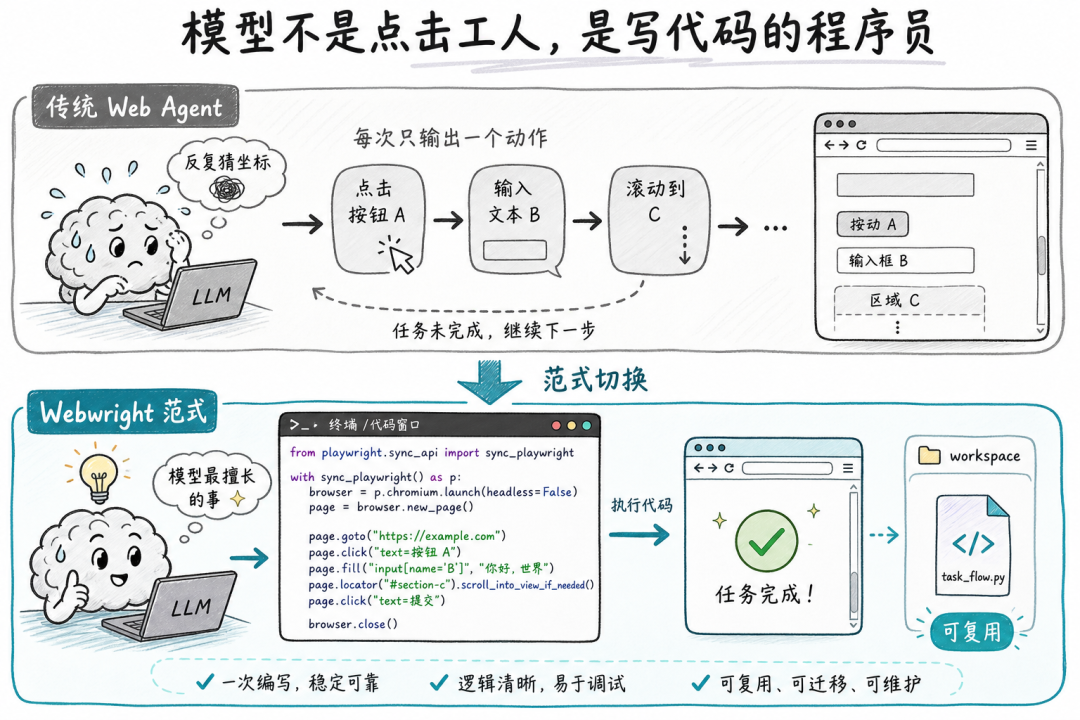
它不是把 Agent 当点击工人,而是当成了一个能写代码的实习生——你说要爬什么,它写脚本去爬。
这种切换看起来只是一个工程选择,但带来的效果是降维的:
▎优势 1:模型擅长的事,让模型做
LLM 本来就是为写代码训练出来的。让它一步一步预测"在 (124, 480) 点击"这种事,是在用自己最不擅长的能力做事。
让它写 Python 脚本?这是它训练时见过几亿次的场景。
GPT-5.4 在裸调时 Odysseys 33.5%,套上 Webwright 跳到 60.1%——这个 26.6 个百分点的差距,本质上是从"让模型做不擅长的事"换成了"让模型做最擅长的事"。
▎优势 2:每次任务都留下可复用的脚本
传统 Agent 跑完一个任务,你得到的是:
▸一堆点击记录
▸一份 DOM 快照
▸几个截图
▸任务完成的消息
下次想做同样的事,还得让 Agent 再跑一遍。
Webwright 跑完一个任务,你得到的是:
▸一个 Python 脚本
▸可以直接重跑
▸可以被人手改
▸可以扔进 Claude Code / Codex / OpenClaw 当工具复用
这是真正的 "task → tool" 的转化。
▎优势 3:调试时不像在抓鬼
传统 Web Agent 出错你看不出错在哪——模型说"我点了这个按钮",但 DOM 早就变了,你没法精确还原。
Webwright 出错是正常的代码报错:
▸Playwright timeout error
▸元素 selector 找不到
▸网络请求 4xx / 5xx
这些都是程序员日常处理的报错,直接贴日志给 Agent 它自己就能改。
微软在论文里偷偷讲了一句很狠的话
我读 paper 时被一句话戳到了:
"No multi-agent system, no graph engine, no plugin layer, no hidden orchestration — just a terminal, a browser, and a model."
翻译过来:没有多 Agent、没有 graph engine、没有 plugin 层、没有隐藏编排——就一个终端、一个浏览器、一个模型。
这一句话其实是对过去一年整个 Agent 圈的隐含批评。
很多框架(LangGraph、CrewAI、AutoGen)都在做"复杂编排"——多 Agent 协同、planner-worker 模式、reflection-critique 循环。
微软研究院的答案是:这些都不需要。最少的 harness 就是最好的 harness。
把模型当成有能力的执行者,给它合适的工具,剩下让它自由发挥。
这个理念其实和我之前写 Harness Engineering 系列时反复强调的"让模型在能用的层面尽可能简单"完全一致。但 Webwright 把这件事做到了极致。
它跟 Cursor / Claude Code 的关系
聊到这里,你可能在想:Webwright 这种东西,能用在我每天的工具里吗?
答案是:已经可以了。
Webwright README 里有一行字:
"Scripts reusable in Claude Code, Codex, OpenClaw"
意思是 Webwright 跑出来的 Python 脚本,直接可以扔进 Claude Code / Codex / OpenClaw 当工具用。
我自己已经在想几个落地场景:
- 批量爬数据:让 Webwright 跑一遍,写出脚本,扔到定时任务里
- 网页回归测试:让 Webwright 写一遍 e2e 流程脚本,commit 进项目
- 数据迁移脚本:从老后台批量导出数据到新后台
- 跨平台监控:每天跑一遍多个网站,输出结构化数据给 BI
这些都是过去用 puppeteer / playwright 手写脚本要花半天的事,Webwright 跑一次就能拿到可复用脚本。
它对你今天做 Agent 的方式意味着什么
我把这件事的信号梳理给你看,三个层面:
▎信号 1:harness 这个层正在被重新评估
过去一年的 Agent 框架都在做"加法"——加更多节点、加更多 agent、加更多记忆机制、加更多 reflection。
Webwright 用一组 benchmark 数字证明:做减法可能效果更好。
这不是说 LangGraph / CrewAI 没用。它们在某些场景(复杂的多角色协同)依然有意义。但单个 Agent + 强工具,可能在 80% 的工程场景里就够了。
▎信号 2:让模型写代码,比让模型预测动作更强
这是更深一层的信号。
未来你做任何 Agent 系统,先问自己一个问题:
这件事能不能让模型直接写代码搞定,而不是让模型一步一步指挥工具?
如果能,优先选写代码这条路。模型的 IQ 在这条路上发挥得最足。
▎信号 3:开源 Agent 框架要重新洗牌
5 月份发生的事情其实是连着的:
▸5 月 14 日,Claude Code 上线 /goal——把 harness 思想做成一行命令
▸5 月 18 日,Cursor 发 Composer 2.5——价格腰斩 + 自研模型路线
▸5 月 24 日,微软开源 Webwright——1000 行代码反超 Claude
三件事连在一起,告诉你 Agent 工程范式正在收敛:让模型写代码 + 简洁的 harness + 极致的成本控制。
那些往"复杂编排"方向走的项目,接下来 3 个月会比较难。
我的看法
Webwright 这次出来,我个人觉得是 2026 年到目前为止最重要的一篇开源工程作品。
它不是一个新模型,不是一个新产品,只是一篇 paper + 1000 行代码。但它做了一件更难的事:用数据证明了一个反直觉的设计选择是对的。
过去做 Web Agent 的所有人,都默认"浏览器 Agent 应该和浏览器深度耦合"。Webwright 把这个假设打穿了:
浏览器 Agent 应该和浏览器解耦,让模型在自己最舒服的语言(代码)里工作,浏览器只是个被驱动的工具。
这个思路其实可以拓展到所有 Agent 场景:
▸桌面 Agent → 让模型写 AppleScript / PowerShell,不要让它预测点击
▸数据 Agent → 让模型写 SQL / Python,不要让它一行一行扫表
▸API Agent → 让模型写完整的 fetch 脚本,不要让它一个一个调端点
Webwright 是这个范式转换的第一个完整证明。
接下来 3 个月最值得跟的方向,我猜是:
▸Microsoft Research 会继续在这条 minimalist Agent 路线上发新东西
▸OpenAI / Anthropic 的官方 Agents SDK 大概率会内置类似的"写脚本"模式
▸更多垂直 Agent(CRM、运营、客服)会借鉴 Webwright 的"任务即脚本"思路
如果你想第一时间感受这种范式的差异,clone 一下仓库自己跑:
git clone https://github.com/microsoft/Webwright
cd Webwright
pip install -e .
playwright install chromium
跑完第一个 demo 你大概率会有一种感觉——原来 Agent 可以做得这么轻、这么稳、这么干净。
这才是工程的本来样子。

往期推荐
Multi-Agent Teams:让多个专家 Agent 像团队一样协作

AI Agent 是怎么"想一步做一步"的?拆解 ReAct 模式

从零开始:用 LangChain.js 构建你的第一个 Tool-Calling Agent

最后

点个在看支持我吧


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)