实时语音翻译seamless-streaming,支持100多个国家语言
facebook也推出了实时语音翻译系统,支持一百多个国家语音,经实测效果很不错,使用了5G左右显存。
上一篇seamless_communication,facebook推出的开源语音翻译项目讲述的是语音翻译搭建的过程,想实时的要怎么实现呢?
facebook也推出了实时语音翻译系统,支持一百多个国家语音,经实测效果很不错,使用了5G左右显存。

今天就来还原下项目搭建的过程。
先来贴下代码地址:
https://github.com/facebookresearch/seamless_communication
这个是他的语音翻译代码地址,实时语音翻译地址在huggingface上面,需要科技上网。打开上面的地址。
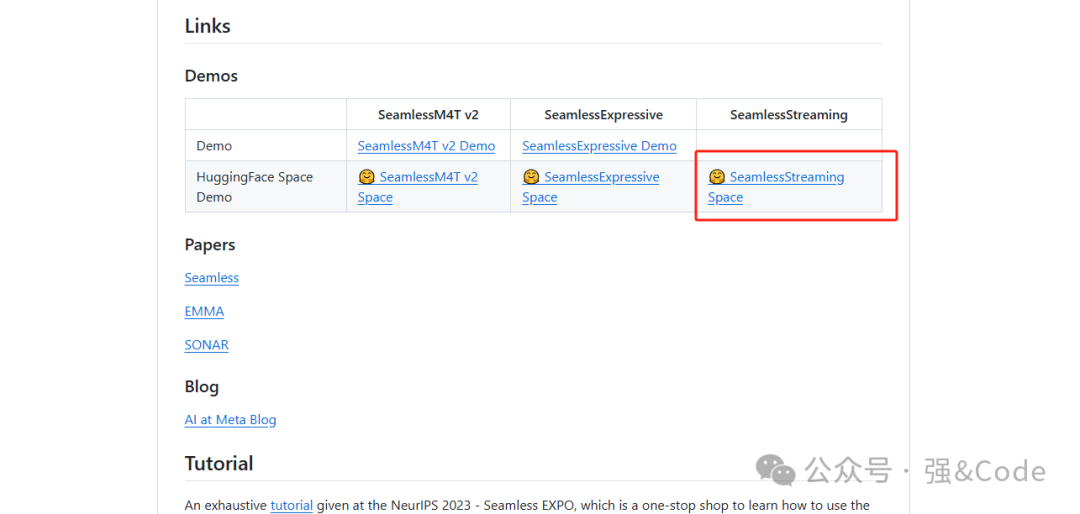
点击此处,可直接跳转到实时语音翻译的地址。https://huggingface.co/spaces/facebook/seamless-streaming
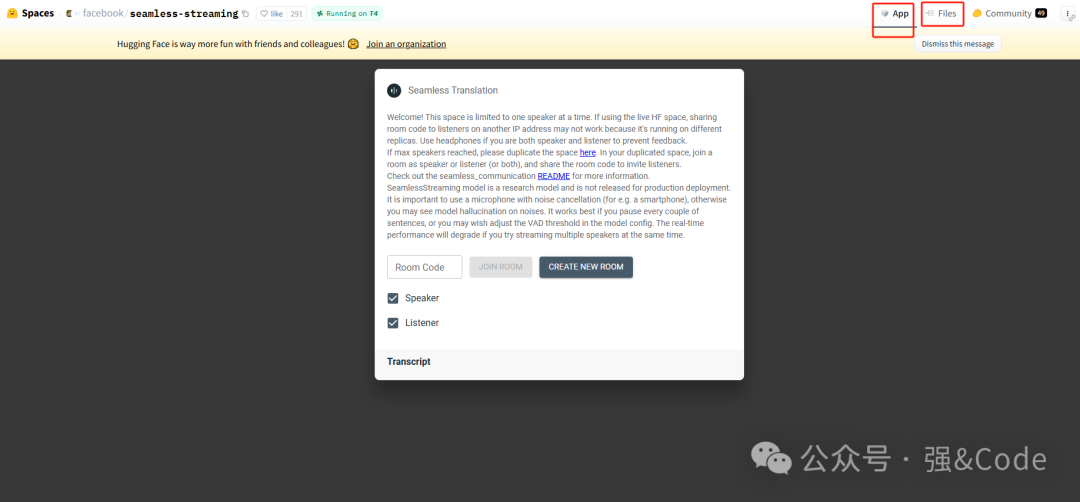
打开后默认显示demo,点击files就是代码了。
国内的镜像地址 :HF_ENDPOINT=https://hf-mirror.com
其实如果在国内要访问huggingface,直接将域名更换成镜像地址即可。如图,完美打开。
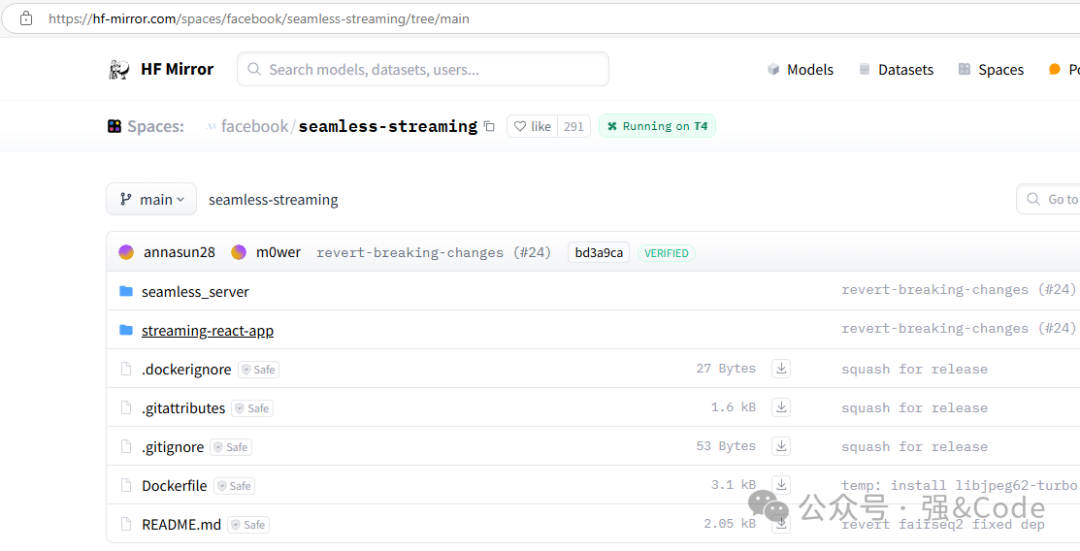
代码和模型文件都已经下载好了,后台回复“实时语音”即可拿到下载链接。
接着开始环境搭建吧。参考readme
1、首先创建环境,官方提供的是3.8,但是3.8后面我这边出现了点问题,所以我改成了3.10
cd seamless_serverconda create --yes --name smlss_server python=3.10 libsndfile==1.0.31conda activate smlss_server
2、下载pytorch,根据自己cuda版本去下载,贴上下载地址https://pytorch.org/get-started/previous-versions/,我刚开始直接按照官方提供的下载的,没想到到第三步安装的时候就报错了,切记根据自己cuda版本安装。
conda install --yes pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia3、安装fairseq2
pip install fairseq2 --pre --extra-index-url https://fair.pkg.atmeta.com/fairseq2/whl/nightly/pt2.1.1/cu118安装到这一步的时候出现错误,如图。这就是我第二步所出现的cuda版本不匹配的问题。当我按照自己cuda版本修改完成后就没问题了。

4、安装环境文件的包
pip install -r requirements.txt5、接着开始安装下前端环境
首先安装node,安装20.x以上版本,不然安装不了yarn
curl -sL https://deb.nodesource.com/setup_22.x -o nodesource_setup.shsudo bash nodesource_setup.shsudo apt install nodejs
验证安装,终端直接输入命令
node -v出现如图即为安装成功。
![]()
6、接着安装yarn,使用yarn 安装前端包
cd streaming-react-appsudo npm install --global yarnyarnyarn build
7、安装成功后试着运行下项目试试。
cd seamless_serveruvicorn app_pubsub:app --host 0.0.0.0
报错了,忘记下载模型文件了。后台回复“实时语音”可以拿到我提前下载好的代码和模型文件。
第一次启动会很慢,我发现代码还会去下载一些其他文件,等下载好后就可以正常启动了。我这边将界面的英文翻译成中文了。
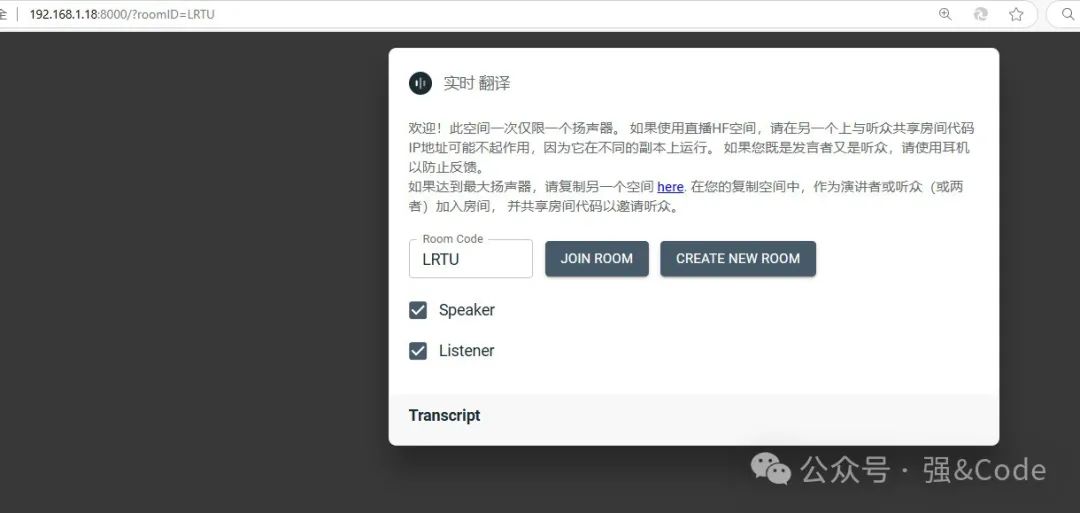
需要将地址映射成https,否则语音功能无法使用。
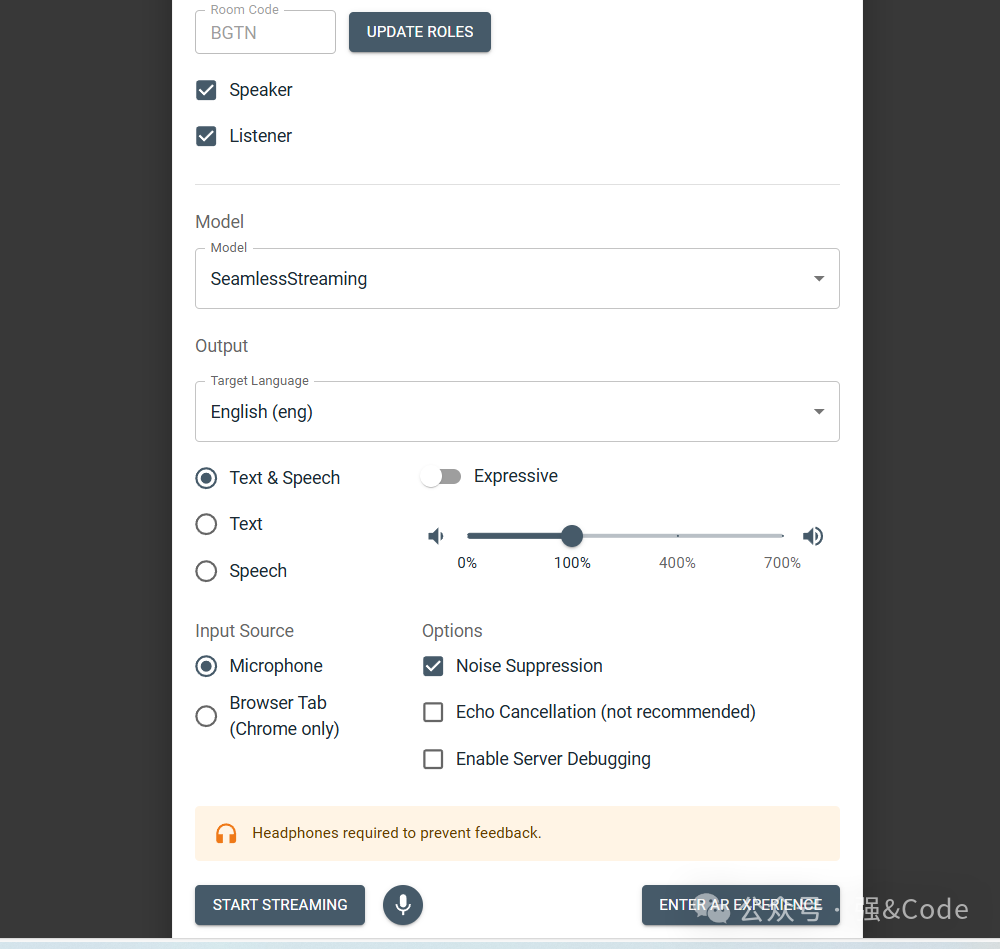
这就是整个实时语音项目搭建的整个过程,大家在搭建的过程中有遇到什么问题的欢迎留言,大家一起来学习讨论。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)